Страница:
Kris Kaspersky
Тонкости дизассемблирования
ДИЗАССЕМБЛИРОВАНИЕ В УМЕ
Мне известны политические аргументы,
Но меня интересуют человеческие доводы.
Ф. Херберт. «Мессия Дюны»
Очень часто под рукой не оказывается ни отладчика, ни дизассемблера, ни даже компилятора, чтобы набросать хотя бы примитивный трассировщик. Разумеется, что говорить о взломе современных защитных механизмов в таких условиях просто смешно, но что делать если жизнь заставляет?
Предположим, что у нас есть простейший шестнадцатеричный редактор, вроде того, который встроен в DN и, если очень повезет, то debug.com, входящий в поставку Windows и часто остающийся не удаленным владельцами машины. Вот этим-то мы и воспользуемся. Сразу оговорюсь, что все описанное ниже требует для своего понимания значительного упорства, однако, открывает большие практические возможности. Вы сможете, например, поставить на диск парольную защиту, зашифровать несколько секторов, внести вирус или разрушающую программу и все это с помощью «подручных» средств, которые наверняка окажутся в вашем распоряжении.
Должен напомнить вам, что многие из описываемых действий в зависимости от ситуации могут серьезно конфликтовать с законом. Так, например, разрушение информации на жестком диске может повлечь за собой большие неприятности. Не пытайтесь заняться шантажом. Если вы можете зашифровать жесткий диск и установить на него пароль, то это еще не означает, что потом за сообщение пароля можно ожидать вознаграждения, а не нескольких лет тюремного заключения.
Поэтому все нижеописанное разрешается проделывать только над своим собственным компьютером или с разрешения его владельца. Если вы соглашаетесь с данными требованиями, то приступим.
СТРУКТУРА КОМАНД INTEL 80x86
Потому ты и опасен, что овладел своими страстями…
Ф. Херберт. «Мессия Дюны»
Дизассемблирование (особенно в уме) невозможно без понимания того, как процессор интерпретирует команды. Конечно, можно просто запомнить все опкоды (коды операций) команд и записать их в таблицу, которую потом выучить наизусть, но это не самый лучший путь. Уж слишком много придется зубрить. Гораздо легче понять, как стояться команды, чтобы потом с легкостью манипулировать ими.
Для начала разберемся с форматом инструкций архитектуры Intel (рис. 1).

Заметим, что кроме поля кода операции все остальные поля являются необязательными, т.е. в одних командах могут присутствовать, а в других нет.
Само поле кода занимает восемь бит и часто (но не всегда) имеет следующий формат (рис. 2):

Поле размера равно нулю, если операнды имеют размер один байт. Единичное значение указывает на слово (двойное слово в 32-битном или с префиксом 0х66 в 16-битном режиме).
Направление обозначает операнд-приемник. Нулевое значение присваивает результат правому операнду, а единица левому. Рассмотрим это на примере инструкции mov bx,dx:

Если теперь флаг направления установить в единицу, то произойдет следующие:

Не правда ли, как по мановению волшебной палочки мы можем поменять местами операнды, изменив всего один бит? Однако, давайте задумаемся, как это поле будет вести себя, когда один из операндов непосредственное значение? Разумеется, что оно не может быть приемником и независимо от содержимого этого бита будет только источником. Инженеры Intel учили такую ситуацию и нашли оригинальное применение, часто экономящее в лучшем случае целых три байта. Рассмотрим ситуацию, когда операнду размером слово или двойное слово присваивается непосредственное значение по модулю меньшее 0100h. Ясно, что значащим является только младший байт, а стоящие слева нули по правилам математики можно отбросить. Но попробуйте объяснить это процессору! Потребуется пожертвовать хотя бы одним битом, что бы указать ему на такую ситуацию. Вот для этого и используется бит направления. Рассмотрим следующую команду:
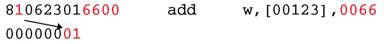
Таким образом, мы экономим один байт в 16-разрядном режиме и целых три — в 32-разрядом. Этот факт следует учитывать при написании самомодифицирующегося кода. Большинство ассемблеров генерируют второй (оптимизированный) вариант, и длина команды оказывается меньше ожидаемой. На этом, кстати, основан очень любопытный прием против отладчиков. Посмотрите на следующий пример:

То есть, текущая команда станет на байт короче! И «отрезанный» ноль теперь стал частью другой команды! Но при выполнении на «живом» процессоре такое не произойдет, т.к. следующие значение iр вычисляется еще до выполнения команды на стадии ее декодирования.
Совсем другое дело отладчики, и особенно отладчики-эмуляторы, которые часто вычисляют значение iр после выполнения команды (это легче запрограммировать). В результате чего наступает крах. Маленькая тонкость — до или после оказалась роковой, и вот вам в подтверждение дамп экрана:

Заметим, что этот прием может быть бессилен против трассирующих отладчиков (debug.com, DeGlucker, Cuр386), поскольку значение iр за них вычисляет процессор и делает это правильно.
Однако, на «обычные» отладчики управа всегда найдется (см. соответствующую главу), а с эмуляционными справиться гораздо труднее, и приведенный пример один из немногих, способных возыметь действие на виртуальный процессор.
Перейдем теперь к рассмотрению префиксов. Они делятся на четыре группы:
блокировки и повторения:

Если используется более одного префикса из той же самой группы, то действие команды не определено и по-разному реализовано на разных типах процессоров.
Префикс переопределения размера операндов используется в 16-разрядном режиме для манипуляции с 32-битными операндами и наоборот. При этом он может стоять перед любой командой, например 0x66:CLIбудет работать! А почему бы и нет? Интересно, но отладчики этого не учитывают и отказываются работать. То же относиться и к дизассемблерам, к примеру IDA Pro:

На этом же основан один очень любопытный прием противодействия отладчикам, в том числе и знаменитому отладчику-эмулятору cuр386. Рассмотрим, как работает конструкция 0x66:RETN. Казалось бы, раз команда RETN не имеет операндов, то префикс 0x66 можно просто игнорировать. Но, на самом деле, все не так просто. RETN работает с неявным операндом-регистром iр/eiр. Именно его и изменяет префикс. Разумеется, в реальном и 16-разрядном режиме указатель команд всегда обрезается до 16 бит, и поэтому, на первый взгляд, возврат сработает корректно. Но стек-то окажется несбалансированным! Из него вместе одного слова взяли целых два! Так нетрудно получить и исключение 0Ch — исчерпание стека. Попробуйте отладить чем-нибудь пример crack1E.com — даже cuр386 во всех режимах откажется это сделать, а Turbo-Debuger вообще зависнет! IDA Pro не сможет отследить стек, а вместе с ним все локальные переменные.
Любопытно, какой простой, но какой надежный прием. Впрочем, следует признать, что перехват INT0Chпод операционной системой windows бесполезен, и, не смотря на все ухищрения, приложение, породившие такое исключение, будет безжалостно закрыто. Однако, в реальном режиме это работает превосходно. Попробуйте убедиться в этом на примере crack1E.com. Забавно наблюдать реакцию различных эмулирующих отладчиков на него. Все они либо неправильно работают (выбирают одно слово из стека, а не два), либо совершают очень далекий переход по 32-битному eiр (в результате чего виснут), либо, чаще всего, просто аварийно прекращают работу по исключению 0Ch (так ведет себя cuр386).
Еще интереснее получится, если попытаться исполнить в 16-разрядном сегменте команду CALL. Если адрес перехода лежит в пределах сегмента, то ничего необычно ожидать не приходится. Инструкция работает нормально. Все чудеса начинаются, когда адрес выходит за эти границы. В защищенном 16-разрядном режиме при уровне привилегий CL0 с большой вероятностью регистр EIР «обрежется» до шестнадцати бит, и инструкция сработает (но, похоже, что не на всех процессорах). Если уровень не CL0, то генерируется исключение защиты 0Dh. В реальном же режиме эта инструкция может вести себя непредсказуемо. Хотя в общем случае должно генерироваться прерывание INT0Dh. В реальном режиме его нетрудно перехватить и совершить дальний 'far' переход в требуемый сегмент. Так поступает, например, моя собственная операционная система OS\7R, дающая в реальном режиме плоскую (flat) модель памяти. Разумеется, такой поворот событий не может пережить ни один отладчик. Ни трассировщики реального режима, ни v86, ни protect-mode debugger, и даже эмуляторы (ну, во всяком случае, из тех, что мне известны) с этим справиться не в состоянии.
Одно плохо — все эти приемы не работают под Windows и другими операционными системами. Это вызвано тем, что обработка исключения типа «Общее нарушение защиты» всецело лежит на ядре операционной системы, что не позволяет приложениям распоряжаться им по своему усмотрению. Забавно, но в режиме эмуляции MS-DOS некоторые EMS-драйверы ведут себя в этом случае совершенно непредсказуемо. Часто при этом они не генерируют ни исключения 0Ch, ни 0Dh. Это следует учитывать при разработке защит, основанных на приведенных выше приемах.
Обратим внимание так же и на последовательности типа 0x66 0x66 [xxx]. Хотя фирма intel не гарантирует корректную работу своих процессоров в такой ситуации, но фактически все они правильно интерпретируют такую ситуацию. Иное дело некоторые отладчики и дизассемблеры, которые спотыкаются и начинают некорректно вести себя.
Есть еще один интересный момент связанный с работой декодера микропроцессора.
Декодер за один раз считывает только 16 байт и, если команда «не уместиться», то он просто не сможет считать «продолжение» и сгенерирует исключение «Общее нарушение защиты». Однако, иначе ведут себя эмуляторы, которые корректно обрабатывают «длинные» инструкции.
Впрочем, все это очень процессорно-зависимо. Никак не гарантируется сохранение и поддержание этой особенности в будущих моделях, и поэтому злоупотреблять этим не стоит, иначе ваша защита откажется работать.
Префиксы переопределения сегмента могут встречаться перед любой командой, в том числе и не обращающейся к памяти, например, CS:NOP вполне успешно выполнится. А вот некоторые дизассемблеры сбиться могут. К счастью, IDA Pro к ним не относится. Самое интересное, что комбинация 'DS: FS: FG: CS: MOV AX,[100]' работает вполне нормально (хотя это и не гарантируется фирмой Intel). При этом последний префикс в цепочке перекрывает все остальные. Некоторые отладчики, наоборот, ориентируются на первый префикс в цепочке, что дает неверный результат. Этот пример хорош тем, что великолепно выполняется под Windows и другими операционными системами. К сожалению, на декодирование каждого префикса тратится один такт, и все это может медленно работать.
Вернемся к формату кода операции. Выше была описана структура первого байта. Отметим, что она фактически не документирована, и Intel этому уделяет всего два слова. Формат разнится от одной команды к другой, однако, можно выделить и некоторые общие правила. Практически для каждой команды, если регистром-приемником фигурирует AX (AL), существует специальный однобайтовый код, который содержит в трех младших битах регистр-источник. Этот факт следует учитывать при оптимизации. Так, среди двух инструкций XCHGAX,BX и XCHG BX,DX следует всегда выбирать первую, т.к. она на байт короче. (Кстати, инструкция XCHGAX,AX более известна нам как NOP. О достоверности этого факта часто спорят в конференциях, но на странице 340 руководства №24319101 «Instruction Set Reference Manual» фирмы Intel это утверждается совершенно недвусмысленно. Любопытно, что, выходит, никто из многочисленных спорщиков не знаком даже с оригинальным руководством производителя).
Для многих команд условного перехода четыре младших бита обозначают условие операции. Точнее говоря, условие задается в битах 1-3, а установка бита 0 приводит к его инверсии (таблица 1).

Как видим, условий совсем немного, и проблем с их запоминанием обычно не возникает. Теперь уже не нужно мучительно вспоминать 'jz' — это 74h или 75h. Так как младший бит первого равен нулю, то 'jz' — это 74h, а 'jnz', соответственно, 75h.
Далеко не все коды операций смогли поместиться в первый байт. Инженеры Intel задумались о поиске дополнительного места для размещения еще нескольких бит и обратили внимание на байт modR/M. Подробнее он описан ниже, а пока рассмотрим приведенный выше рисунок (рис. 1). Трех-битовое поле reg, содержащие регистр-источник, очевидно, не используется, если вслед за ним идет непосредственный операнд. Так почему бы его не использовать для задания кода операции? Однако, процессору требуется указать на такую ситуацию. Это делает префикс '0Fh', размещенный в первом байте кода. Да, именно префикс, хотя документация Intel этого прямо и не подтверждает. При этом на не-MMX процессорах для его декодирования требуется дополнительный такт. Intel же предпочитает называть первый байт основным, а второй уточняющим кодом операции. Заметим, что это же поле используют многие инструкции, оперирующие одним операндом (jmр, call). Все это очень сильно затрудняет написание собственного ассемблера/дизассемблера, но зато дает простор для создания самомодифицирующегося кода и, кроме того, вызывает восхищение инженерами Intel, до минимума сокративших размеры команд. Конечно, это досталось весьма непростой ценой. И далеко не все дизассемблеры работают правильно. С другой стороны именно благодаря этому и существуют защиты, успешно противостоящие им.
Избежать проблем можно, лишь четко представляя себе сам принцип кодировки команд, а не просто работая с «мертвой» таблицей кодов операций, которую многие авторы вводят в дизассемблер и на том успокаиваются, так как внешне все работает правильно.
К тонкостям кодирования команд мы еще вернемся, а пока приготовимся к разбору поля modR/M. Два трехбитовых поля могут задавать код регистра общего назначения по следующей таблице (таблица 2):
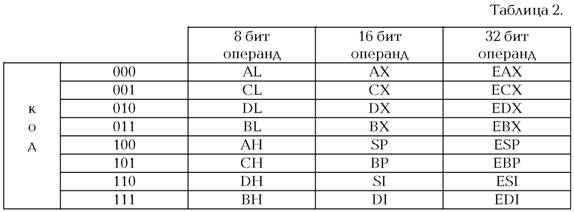
Опять можно восхищаться лаконичностью инженеров Intel, которые ухитрились всего в трех битах закодировать столько регистров. Это, кстати, объясняет, почему нельзя выборочно обращаться к старшим и младшим байтам регистров SР, BР, SI, DI и, аналогично, к старшему слову всех 32-битных регистров. Во всем «виновата» оптимизация и архитектура команд. Просто нет свободных полей, в которые можно было бы «вместить» дополнительные регистры. Сегодня мы вынуждены расхлебывать результаты архитектурных решений, выглядевшими такими удачными всего лишь десятилетие назад.
Обратите внимание на порядок регистров: AX, CX, DX, BX, SР, BР, SI, DI. Немного не по алфавиту, верно? И особенно странно в этом отношении выглядит регистр BX. Но, если понять причины, то никакой нужны запоминать это исключение не будет, т.к. все станет на свои места: BX — это индексный регистр, и первым стоит среди индексных.
Таким образом, мы уже можем «вручную» без дизассемблера распознавать в шестнадцатеричном дампе регистры-операнды. Очень неплохо для начала! Или писать самомодифицирующийся код. Например:

Он изменит 6 строку на XOR SP,SP. Это «завесит» многие отладчики, и, кроме того, не позволит дизассемблерам отслеживать локальные переменные адресуемые через SР. Хотя IDA Pro и позволяет скорректировать стек вручную, для этого надо сначала понять, что SР обнулился. В приведенном примере это очевидно (но в глаза, кстати, не бросается), а если это произойдет в многопоточной системе? Тогда изменение кода очень трудно будет отследить, особенно в листинге дизассемблера. Однако, нужно помнить, что самомодифицирующийся код все же уходит в историю. Сегодня он встречается все реже и реже.

Первоначально сегментные регистры кодировались всего двумя битами и этого с вполне хватало, т.к. их было всего четыре. Позже, когда количество их увеличилось, перешли на трехбитную кодировку. При этом две кодовые комбинации (110b и 111b) в настоящее время не применяются и вряд ли будут добавлены в ближайшем будущем. Но что же будет, если попытаться их использовать? Генерация INT 06h. А вот отладчики-эмуляторы могут вести себя странно. Одни не генерируют при этом прерывания, чем себя и выдают, а другие — ведут себя непредсказуемо, т.к. при этом требуемый регистр может находится в области памяти, занятой другой переменной (это происходит, когда ячейка памяти определяется по индексу регистра, при этом считываются три бита и суммируются с базой, но никак не проверяются пределы).

Кстати, IDA Pro вообще отказывается анализировать весь последующий код. Как это можно использовать? Да очень просто — если эмулировать еще два сегментных регистра в обработчике INT 06h, то очень трудно это будет как отлаживать, так и ди-зассемблировать программу. Однако, это опять-таки не работает под win32!
Управляющие/отладочные регистры кодируются нижеследующим образом:

Заметим, что коды операций mov, манипулирующих этими регистрами, различны, поэтому-то и возникает кажущееся совпадение имен. С управляющими регистрами связана одна любопытная мелочь. Регистр CR1, как известно большинству, в настоящее время зарезервирован и не используется. Во всяком случае, так написано в русскоязычной документации. На самом деле регистр CR1 просто не существует! И любая попытка обращения к нему вызывает генерацию исключение INT 06h. Например, cuр386 в режиме эмуляции процессора этого не учитывает и неверно исполняет программу. А все дизассемблеры, за исключением IDA Pro, неправильно дизассемблируют этот несуществующий регистр:

Все эти команды на самом деле не существуют и приводят к вызову прерывания INT06h. Не так очевидно, правда? И еще менее очевидно обращение к регистрам DR4-DR5. При обращении к ним исключения не генерируется. Между прочим, IDA Pro 3.84 дизассемблирует не все регистры. Зато великолепно их ассемблирует (кстати, ассемблер этот был добавлен другим разработчиком).
Пользуясь случаем, акцентируем внимание на сложностях, которые подстерегают при написании собственного ассемблера (дизассемблера). Документация Intel местами все же недостаточно ясна (как в приведенном примере), и неаккуратность в обращении с ней приводит к ошибкам, которыми может воспользоваться разработчик защиты против хакеров.
Теперь перейдем к описанию режимов адресации микропроцессоров Intel. Тема очень интересная и познавательная не только для оптимизации кода, но и для борьбы с отладчиками.
Первым ключевым элементом является байт modR/M.

Как отмечалось выше, по байту modR/M нельзя точно установить регистры. В зависимости от кода операции и префиксов размера операндов, результат может коренным образом меняться.
Биты 3-5 могут вместо определения регистра уточнять код операции (в случаи, если один из операндов представлен непосредственным значением). Младшие три бита всегда либо регистр, либо способ адресации, что зависит от значения 'mod'. А вот биты 3-5 никак не зависят от выбранного режима адресации и задают всегда либо регистр, либо непосредственный операнд.
Формат поля R/M, строго говоря, не документирован, однако достаточно очевиден, что позволяет избежать утомительного запоминания совершенно нелогичной на первый взгляд таблицы адресаций (таблица 3).

Возможно, кому-то эта схема покажется витиеватой и трудной для запоминания, но зубрить все режимы без малейшего понятия механизма их взаимодействия еще труднее, кроме того, нет никакого способа себя проверить и проконтролировать ошибки.
Действительно, в поле R/M все три бита тесно взаимосвязаны, в отличии от поля mod, которое задает длину следующего элемента в байтах.

Разумеется, не может быть смещения 'offset 12', (т.к. процессор не оперирует с полуторными словами), а комбинация '11' указывает на регистровую адресацию.
Может возникнуть вопрос, как складывать с 16-битным регистром 8 битное смещение? Конечно, непосредственному сложению мешает несовместимость типов, поэтому процессор сначала расширяет 8 бит до слова с учетом знака. Поэтому, диапазон возможных значений составляет от —127 до 127. (или от —0x7F до 0x7FF).
Все вышесказанное проиллюстрировано в приведенной ниже таблице 3. Обратим внимание на любопытный момент — адресация типа [BР] отсутствует. Ее ближайшим эквивалентом является [BР + 0]. Отсюда следует, что для экономии следует избегать непосредственного использования BР в качестве индексного регистра. BР может быть только базой. И mov ax,[bp] хотя и воспринимается любым ассемблером, но ассемблируется в mov ax,[bр+0], что на байт длиннее.
Исследовав приведенную ниже таблицу 1, можно прийти к выводу, что адресация в процессоре 8086 была достаточно неудобной. Сильнее всего сказывалось то ограничение, что в качестве индекса могли выступать только три регистра (BX, SI, DI), когда гораздо чаще требовалось использовать для этого CX (например, в цикле) или AX (как возвращаемое функцией значение).
Поэтому, начиная с процессора 80386 (для 32-разрядного режима), концепция адресаций была пересмотрена. Поле R/M стало всегда выражать регистр независимо от способа его использования, чем стало управлять поле 'mod', задающие, кроме регистровой, три вида адресации:

Видно, что поле 'mod' по-прежнему выражает длину следующего поля — смещения, разве что с учетом 32-битного режима, где все слова расширяются до 32 бит.
Напомним, что с помощью префикса 0x67 можно и в 16-битном режиме использовать 32-битный режимы адресации, и наоборот. Однако, при этом мы сталкиваемся с интересным моментом — разрядность индексных регистров остается 32-битной и в 16-битном режиме!
В реальном режиме, где нет понятия границ сегментов, это действительно будет работать так, как выглядит, и мы сможем адресовать первые 4 мегабайта памяти (32 бита), что позволит преодолеть печально известное ограничение размера сегмента 8086 процессоров в 64К. Но такие приложения окажутся нежизнеспособными в защищенном или V86 режиме. Попытка вылезти за границу 64К сегмента вызовет исключение 0Dh, что приведет к автоматическому закрытию приложения, скажем, под управлением Windows. Аналогично поступают и отладчики (в том числе и многие эмуляторы, включая cuр386).
Сегодня актуальность этого приема, конечно, значительно снизилась, поскольку «голый DOS» практически уже не встречается, а режим его эмуляции Windows крайне неудобен для пользователей.
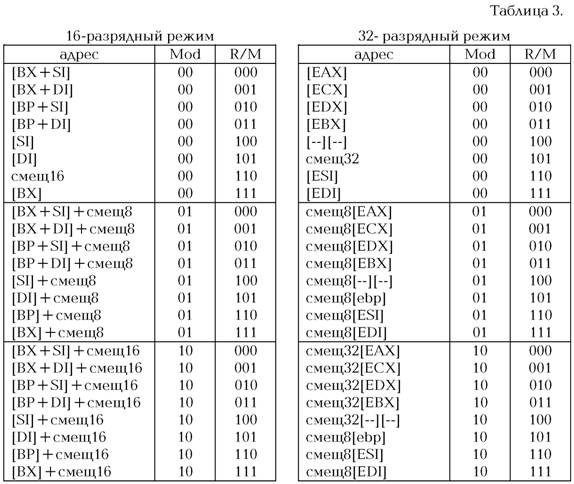
Изучив эту таблицу, можно прийти к заключению, что система адресации 32-битного режима крайне скудная, и ни на что серьезное ее не хватит. Однако, это не так. В 386+ появился новый байт SIB, который расшифровывается 'Scale-Index Base'.
Процессор будет ждать его вслед за R/M всякий раз, когда последний равен 100b. Эти поля отмечены в таблице как '[-]'. SIB хорошо документирован, и назначения его полей показаны на рисунке 6. Нет совершенно никакой необходимости зазубривать таблицу адресаций.

'Base' это базовый регистр, 'Index' — индексный, а два байта 'Scale' — это степень двойки для масштабирования. Поясним введенные термины. Ну, что такое индексный регистр, понятно всем. Например SI. Теперь же в качестве индексного можно использовать любой регистр. За исключением, правда, SР; впрочем, можно выбирать и его, но об этом позже.
Базовый регистр, это тот, который суммируется с индексным, например, [BР+SI]. Аналогично, базовым теперь может быть любой регистр. При этом есть возможность в качестве базового выбрать SР. Заметим, что если мы выберем этот регистр в качестве индексного, то вместо 'SР' получим — «никакой»: в этом случае адресацией будет управлять только базовый регистр.
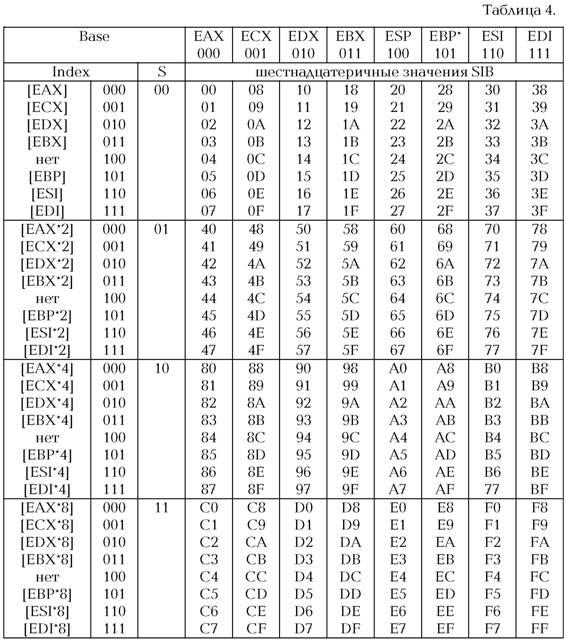
Ну и, наконец, масштабирование — это уникальная возможность умножать индексный регистр на 1,2,4,8 (т.е. степень двойки, которая задается в поле Scale). Это очень удобно для доступа к различным структурам данных. При этом индексный регистр, являющийся одновременно и счетчиком цикла, будет указывать на следующий элемент структуры даже при единичном шаге цикла (что чаще всего и встречается). В таблице 4 показаны все возможные варианты значений байта 'SIB'.
Если при этом в качестве базового регистра будет выбран EBР, то полученный режим адресации будет зависеть от поля MOD предыдущего байта. Возможны следующие варианты:

Итак, мы полностью разобрались с кодировкой команд. Осталось лишь выучить непосредственно саму таблицу кодов, и можно отправляться в длинный и тернистый путь написания собственного дизассемблера.