Страница:
Концепция проста и элегантна: громадный массив контента, привлекательный для максимально широкого пласта Рунет-тусовки, выкладывается на два файлохранилища — Rapidshare и FileFactory. Все линки — в открытом доступе, никакой регистрации на портале и членства не требуется. Хотите — качайте, сколько душа просит, через фриварные аккаунты. Кто пробовал, тот знает: мизерный лимит на объем скачивания и часовые ожидания допуска быстро заставляют душу ничего больше не хотеть. В этот момент и включается бизнес-модель: Пуля продает премиум-аккаунты Rapidshare и FileFactory по льготной цене (4—10 WMZ в зависимости от длительности подписки). Цены меньше, чем у самих файлохранилищ, плюс — удобная для Рунета оплата не кредитной картой, а WebMoney. Источник аккаунтов на продажу — пойнты, которые зарабатываются официально на файлохранилищах за счет гигантских объемов того самого трафика, что создается контентом, выложенным на портале. Эдакий perpetuum mobile и, на мой взгляд, ценная модель для изучения на предмет адаптации.
Второй сайт, который хочется представить читателям, называется «Война и мир» (www.warandpeace.ru). Посвящен геополитике, причем в том бесконечно редком ключе, что идеально вписывается в мою собственную модель современного мира. Небольшая выдержка из «Основных принципов информационной политики» сайта, проливающая свет на весь подход: «Игнорирование новостного мусора из СМИ — „светской жизни“, будней „реалити-шоу“ и прочих явлений массовой культуры; криминальной хроники; скандальных сюжетов о чиновниках, проституции и „сексуальных меньшинствах“. Принципиальное неприятие „желтизны“ в любых видах». Освещаемая тематика — романс Америки с Осамой, трения с Грузией, война в Ираке, доктрина Блэра, исламский банкинг (тот самый, в котором нельзя начислять проценты за кредит), политика Уго Чавеса и т. п.
Теперь — обещанная софтина. Пару лет назад я рассказывал читателям об одной из замечательных астрономических (не путать с астрологическими!) программ — Starry Night канадской компании Imaginova. Речь шла о релизе Starry Night Enthusiast 5 (категория New To Astronomy), которым я наслаждался несколько лет. Не так давно программа обновилась до версии 6, и мне посчастливилось тестировать ее самый полный вариант — Starry Night Pro Plus 6 (категория Experts).
Сказать, что я потрясен, значит ничего не сказать. Добавление одной цифры к номеру релиза в случае Starry Night служит пожизненным укором всем тем шареварным халтурщикам, что штампуют обновления, отличающиеся лишь новыми алгоритмами и ухищрениями защиты. Шестой релиз Starry Night — самая настоящая революция! Список нововведений огромен и занимает несколько страниц, поэтому я не буду утомлять читателя, тем более что он вряд ли подготовлен к адекватному восприятию астрономических реалий. Назову лишь главное — то самое революционное — новшество: полноцветовое цифровое фотографическое изображение всего звездного неба, видимого с Земли! Если в предыдущих версиях Starry Night, как и во всех прочих астрономических программах, мы имели дело с векторной симуляцией, то теперь видим так называемую AllSky CCD mosaic — цельную панораму неба, составленную из двадцати тысяч снимков, сделанных мощнейшим телескопом, размером 6,44 млрд. пикселов (съемка велась с разрешением 12 арксекунд на пиксел)! Просмотр любого уголка Вселенной возможен на пяти уровнях зуммирования, открывающих совсем уж неописуемые зрелища: как вам 24-битная цветная фотокарта всей поверхности Марса, снятая с высоты полета космического зонда? Или матушка Земля с разрешением до 1 км (здравствуй, GoogleEarth!)? Неудивительно, что пять лет усилий, направленных на создание нового революционного релиза, отлились в 11 Гбайт информации, ложащейся божественно желанным грузом на жесткий диск.
Специально не дописываю последнюю тысячу знаков «Голубятни», оставляя место для лишнего скриншота!
SIGKDD — исследовательское общество по открытию знаний и датамайнингу. В 2007 году в Сан-Хосе (Калифорния) пройдет уже 13-я конференция KDD. Воркшоп KDD в 1989 году был единственным в мире, а сейчас каждый год собирается дюжина конференций и встреч по этой теме.
Второй сайт, который хочется представить читателям, называется «Война и мир» (www.warandpeace.ru). Посвящен геополитике, причем в том бесконечно редком ключе, что идеально вписывается в мою собственную модель современного мира. Небольшая выдержка из «Основных принципов информационной политики» сайта, проливающая свет на весь подход: «Игнорирование новостного мусора из СМИ — „светской жизни“, будней „реалити-шоу“ и прочих явлений массовой культуры; криминальной хроники; скандальных сюжетов о чиновниках, проституции и „сексуальных меньшинствах“. Принципиальное неприятие „желтизны“ в любых видах». Освещаемая тематика — романс Америки с Осамой, трения с Грузией, война в Ираке, доктрина Блэра, исламский банкинг (тот самый, в котором нельзя начислять проценты за кредит), политика Уго Чавеса и т. п.
Теперь — обещанная софтина. Пару лет назад я рассказывал читателям об одной из замечательных астрономических (не путать с астрологическими!) программ — Starry Night канадской компании Imaginova. Речь шла о релизе Starry Night Enthusiast 5 (категория New To Astronomy), которым я наслаждался несколько лет. Не так давно программа обновилась до версии 6, и мне посчастливилось тестировать ее самый полный вариант — Starry Night Pro Plus 6 (категория Experts).
Сказать, что я потрясен, значит ничего не сказать. Добавление одной цифры к номеру релиза в случае Starry Night служит пожизненным укором всем тем шареварным халтурщикам, что штампуют обновления, отличающиеся лишь новыми алгоритмами и ухищрениями защиты. Шестой релиз Starry Night — самая настоящая революция! Список нововведений огромен и занимает несколько страниц, поэтому я не буду утомлять читателя, тем более что он вряд ли подготовлен к адекватному восприятию астрономических реалий. Назову лишь главное — то самое революционное — новшество: полноцветовое цифровое фотографическое изображение всего звездного неба, видимого с Земли! Если в предыдущих версиях Starry Night, как и во всех прочих астрономических программах, мы имели дело с векторной симуляцией, то теперь видим так называемую AllSky CCD mosaic — цельную панораму неба, составленную из двадцати тысяч снимков, сделанных мощнейшим телескопом, размером 6,44 млрд. пикселов (съемка велась с разрешением 12 арксекунд на пиксел)! Просмотр любого уголка Вселенной возможен на пяти уровнях зуммирования, открывающих совсем уж неописуемые зрелища: как вам 24-битная цветная фотокарта всей поверхности Марса, снятая с высоты полета космического зонда? Или матушка Земля с разрешением до 1 км (здравствуй, GoogleEarth!)? Неудивительно, что пять лет усилий, направленных на создание нового революционного релиза, отлились в 11 Гбайт информации, ложащейся божественно желанным грузом на жесткий диск.
Специально не дописываю последнюю тысячу знаков «Голубятни», оставляя место для лишнего скриншота!
SIGKDD — исследовательское общество по открытию знаний и датамайнингу. В 2007 году в Сан-Хосе (Калифорния) пройдет уже 13-я конференция KDD. Воркшоп KDD в 1989 году был единственным в мире, а сейчас каждый год собирается дюжина конференций и встреч по этой теме.
Кто заказывает вашей фирме KDnuggets датамайнинговые проекты? Насколько они масштабны (по количеству участников, ресурсам, времени выполнения)? Требуют ли разработки нового ПО специально для каждого проекта?
— Многие думают, что Kdnuggets — большая компания с веб-программистами, редакторами, менеджерами по развитию бизнеса, отделом кадров и т. п. На самом деле она состоит из одного человека — меня самого, а все ее дела я веду при помощи множества скриптов, автоматически выполняющих большинство необходимых действий.
Время от времени я получаю интересные заказы на консалтинговые проекты, которые тоже обычно выполняю самостоятельно. Главное, что требуется от консультанта по датамайнингу, — интуиция, которая подсказывает, как найти интересные объекты в массиве данных и как при помощи существующих методов и технологий обнаруживать именно то, что принесет пользу заказчику.
 К сожалению, многие успешные датамайнинговые проекты, в том числе и часть моих, связаны с деликатными вопросами бизнеса — такими, как выявление мошенничества и обмана, — и поэтому о них нельзя подробно рассказать в прессе. Однако недавно состоялся воркшоп, специально посвященный «историям успеха» технологий датамайнинга. Там были представлены статьи, против публикации которых заказчики проектов не возражали. Лучшей была признана работа Бхарата Рао (Bharat Rao) из Siemens, в которой описывалась очень интересная система. Она позволяет автоматически повысить качество лечения и ухода за пациентами кардиологических отделений благодаря тому, что извлекает важную медицинскую информацию из невнятно написанных и неточных записей в историях болезни [Гм-гм. Недавно мы упоминали о том, как широко применяется распознавание речи при надиктовывании врачами историй болезни. Может быть, система Рао исправляет ошибки не только врачей, но и той системы, которая записывала их диктовку? — Л.Л.-М.].
К сожалению, многие успешные датамайнинговые проекты, в том числе и часть моих, связаны с деликатными вопросами бизнеса — такими, как выявление мошенничества и обмана, — и поэтому о них нельзя подробно рассказать в прессе. Однако недавно состоялся воркшоп, специально посвященный «историям успеха» технологий датамайнинга. Там были представлены статьи, против публикации которых заказчики проектов не возражали. Лучшей была признана работа Бхарата Рао (Bharat Rao) из Siemens, в которой описывалась очень интересная система. Она позволяет автоматически повысить качество лечения и ухода за пациентами кардиологических отделений благодаря тому, что извлекает важную медицинскую информацию из невнятно написанных и неточных записей в историях болезни [Гм-гм. Недавно мы упоминали о том, как широко применяется распознавание речи при надиктовывании врачами историй болезни. Может быть, система Рао исправляет ошибки не только врачей, но и той системы, которая записывала их диктовку? — Л.Л.-М.].
Среди кандидатов в «Великие вызовы KDD» (см. врезку) есть задачи, близкие к тесту Тьюринга. Есть ли надежда, что техники ДМ помогут существенно продвинуться в решении такого рода классических проблем искусственного интеллекта? С другой стороны — можно ли в задачах протеомики надеяться на то, что только за счет ДМ появятся ответы на важные вопросы биологии?
— Из кандидатов в «Великие вызовы» ближе всего к Тьюринг-тесту предложение Ронена Фельдмана (Ronen Feldman) — выдвинуть в качестве вызова создание текст-майнинговых систем, которые смогут сдавать стандартные экзамены на понимание текстов, — SAT, GRE, GMAT, причем обучаться системы будут, исследуя веб.
Лично я думаю, что это вполне решаемая в течение пяти-десяти лет задача, а когда она будет решена, это полностью изменит существующую практику вступительных экзаменов.
Недавно Ларри Пейдж, сооснователь Google, объявил, что Google серьезно работает над ИИ, а использование сосредоточенной там вычислительной мощности и базы знаний может серьезно ускорить движение в сторону ИИ.
Для продвижения в биологии (протеомике, геномике) критически важно понимание предметной области. Однако и без инновационных алгоритмов датамайнинга прогресс там невозможен.
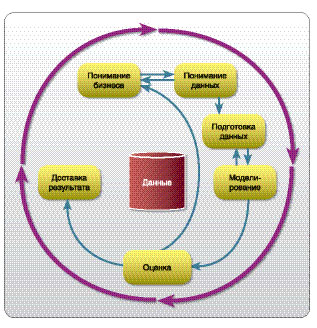
Как устроены системы датамайнинга? Много ли общего у этих технологий с технологиями поисковых машин типа Гугла?
— Системы датамайнинга устроены не так, как системы поиска по вебу (Google, Yahoo), поскольку датамайнинг работает обычно с цифровыми базами данных и задает другие вопросы, нежели Google. Обычно эти системы реализуют различные методы очистки и препроцессинга, а затем применяется основное ядро алгоритмов. Самые важные задачи, решаемые этими алгоритмами, — классификация, кластеризация, визуализация. Процесс датамайнинга требует множества итераций, как показано на рисунке. Важнейшая алгоритмическая часть — использование алгоритмов машинного обучения, то есть построение модели; для датамайнинговой системы это так же важно, как двигатель для спортивного автомобиля. Однако основные усилия обычно уходят на подготовку данных. Заинтересованных читателей приглашаю познакомиться с моими (свободно доступными) лекциями.
Кандидаты в великие
На конференции KDD-2006 несколько известных исследователей в области извлечения знаний из данных предложили задачи, которые в будущем могут претендовать на роль «великих вызовов», бросаемых повседневной практикой.
• Провести аннотацию 1000 Часов цифрового видео в течение одного часа. Согласно автору предложения Шабану Джерабе (Chabane Djeraba), в настоящее время это требует тысяч человеко-часов при ручной работе. Под аннотацией подразумевается краткое описание происходящего. Например, сегодня невозможно без выполненной человеком аннотации выделить в записи баскетбольного матча эпизоды атаки и обороны каждой команды. Ручная аннотация одной фотографии для Национального географического общества требует двадцать минут.
• ВикипедиЯя-тест (Lise Getoor, Лиз Гетур). По сборнику статей, созданному либо в режиме партисипативной журналистики (то есть по принципу наполнения Википедии), либо с использованием автоматических инструментов поиска линков по требуемой тематике, определить, какой из этих двух методов использовался: то есть составлен ли сборник машиной или людьми (и в каком случае качество оказалось выше)? Автор предложения указывает на связь этого вызова с другим, брошенным специалистам по сжатию информации: сжать 100 мегабайт Википедии до 18 мегабайт, не потеряв ни единого бита (за это уже назначен приз Хаттера в 50 тысяч долларов).
• Оценить миллиард прогнозирующих моделей (Robert Grossman, Роберт Гроссман). В ходе многолетней практики датамайнинга было построено великое множество статистических моделей для различных типов и конкретных ансамблей данных. Во многих случаях для одних и тех же массивов данных строится несколько моделей, чтобы ухватить их характеристики разных видов. Пример: имеется информация от 833 датчиков движения транспорта в Чикаго. Задача состоит в автоматическом определении ситуаций, когда в транспортном потоке возникают аномалии, происходит что-то необычное (но не простая пробка!). Данные сегментировались по дням, часам и участкам дороги, что приводило к появлению 7х24х250 = 42000 автоматически генерируемых статистических моделей — хотелось бы значительно сократить их число! Подобная ситуация возникает и в онлайновом маркетинге (отдельная модель поведения для каждого клиента), в перспективных подходах к оценке эффективности лекарств на основе индивидуального генотипа и т. д. Так что миллиард набирается легко — вопрос в том, как радикально уменьшить это число.
• Разработка систем анализа текстов (text mining), способных сдать обыЧные экзамены на понимание текста SAT, GRE, GMAT (Ronen Feldman, Ронен Фелдман). Эту задачу с оптимизмом комментирует в своих ответах Григорий Пятецкий-Шапиро. Она покруче даже стандартного теста Тьюринга (определить, машина или человек отвечает на ваши вопросы), по поводу которого тоже было много оптимизма, в том числе и у его гениального автора. Однако не будем забывать, что этот вызов — лишь планка, которую автор предложения поднимает так высоко в надежде на достижение более приземленных практических целей: довести точность реализации реляционных запросов с нынешних 70—80% до 98—100%, причем в самой общей ситуации.
Кроме этого, был предложен еще один весьма важный вызов — функциональная аннотация белков. Однако формулировка здесь так сложна, а задач так много, что мы ограничимся лишь констатацией — это направление, датамайнинг в геномике и протеомике, тоже служит источником великих вызовов (напомним, кстати, что недавно назначен приз X PRIZE за снижение стоимости сканирования генома до 10 тысяч долларов при повышении производительности до ста геномов за десять дней).
Ну а для полноты картины упомянем и конкурс, который состоится на конференции KDD-2007. Участникам предоставляется тренировочный массив данных Netflix, в котором собрано больше 100 млн. рейтингов (по пятибалльной шкале) по 18 тысячам фильмов от 480 тысяч случайно выбранных анонимных пользователей Netflix (то есть людей, бравших у Netflix DVD напрокат), с 1998 по 2005 год. Вот одна из двух задач, по которым будет проводиться состязание:
Дан список из 100 тысяч пар вида «номер_пользователя, номер_фильма», относящийся к 2006 году (то есть не входящий в тренировочный массив). Для каждой такой пары нужно указать вероятность, что данный пользователь хоть как-то рейтинговал данный фильм в 2006 году.
Денежные призы не предусмотрены — в отличие от основного конкурса Netflix. Там, чтобы заработать миллион долларов, требуется превзойти точность действующей сейчас на фирме системы рекомендаций Cinematch™ всего лишь на 10% (на исторических данных); ежегодно разыгрывается приз в скромные 50 тысяч долларов просто за самое большое уточнение прогноза. Прогноз состоит в том, чтобы угадать по предшествующим оценкам фильмов клиентами, какие из фильмов они высоко оценят в будущем. По состоянию на 14 марта 2007 года лучший результат в конкурсе Netflix уже 6,75%, то есть две трети пути к миллиону пройдено.
ЦИФРА ЗАКОНА: Письмо несчастья: Может ли «покаянное письмо» спасти системного администратора?
Автор: Павел Протасов
Среди обилия заблуждений, бродящих по умам наших соотечественников, одно из первых мест занимают те, что связаны с законодательством. Об одном из них я и хочу сейчас поговорить. Оно периодически всплывает то тут, то там в ходе разнообразных обсуждений судьбы тех бедолаг, что попали под кампанию борьбы нашего государства с пиратством, однако наиболее активно его начали пропагандировать в связи с недавним судебным процессом по обвинению в «пиратстве» директора сельской школы Александра Поносова. Связано оно с вопросом о том, как обезопасить себя от милицейского «наезда», если на вверенной абстрактному системному администратору территории обнаружилось что-то контрафактное.
Директор школы Поносов — все-таки исключение, а типичной является ситуация, когда за «пиратку» привлекают к ответственности компьютерных дел мастера, обслуживающего какую-нибудь контору. В один прекрасный день приходит проверка, которая обнаруживает на конторских компьютерах пиратские программы и интересуется: а кто же их установил. Такой человек находится довольно быстро, а поскольку речь идет об организации и компьютеров несколько, то контрафакта на «уголовный» размер обычно набирается. Следствие, суд, условный срок, заметка в местной газете об очередной победе борцов с высокими технологиями и о вреде пиратства. Стандартный набор.
Правда, сперва я хочу испортить вам удовольствие от предвкушения развязки этой статьи и дать искомый ответ в самом начале. Он прост: чтобы избежать ответственности за «пиратство», не нужно ставить ничего «пиратского». А теперь — можете читать дальше.
Вообще, склонность соотечественников давать советы в тех областях, в которых они ничего не соображают, меня всегда поражала. Любопытно, много ли из советчиков пытались применить этот прогрессивный метод на практике? Боюсь, таковых не обнаружится. А если и обнаружатся, то чутье подсказывает, что о встрече с милицией, которой было предъявлено такое письмо, предъявлявший предпочтет не вспоминать очень долго.
Давайте посмотрим, как, собственно, происходит привлечение к уголовной ответственности. Следствию необходимо, среди прочего, доказать умысел подозреваемого на совершение преступления, то есть подтвердить его осведомленность о том, что устанавливаемые программы — контрафактные, и сознательно желание их установить. Тут есть несколько способов.
Среди обилия заблуждений, бродящих по умам наших соотечественников, одно из первых мест занимают те, что связаны с законодательством. Об одном из них я и хочу сейчас поговорить. Оно периодически всплывает то тут, то там в ходе разнообразных обсуждений судьбы тех бедолаг, что попали под кампанию борьбы нашего государства с пиратством, однако наиболее активно его начали пропагандировать в связи с недавним судебным процессом по обвинению в «пиратстве» директора сельской школы Александра Поносова. Связано оно с вопросом о том, как обезопасить себя от милицейского «наезда», если на вверенной абстрактному системному администратору территории обнаружилось что-то контрафактное.
Директор школы Поносов — все-таки исключение, а типичной является ситуация, когда за «пиратку» привлекают к ответственности компьютерных дел мастера, обслуживающего какую-нибудь контору. В один прекрасный день приходит проверка, которая обнаруживает на конторских компьютерах пиратские программы и интересуется: а кто же их установил. Такой человек находится довольно быстро, а поскольку речь идет об организации и компьютеров несколько, то контрафакта на «уголовный» размер обычно набирается. Следствие, суд, условный срок, заметка в местной газете об очередной победе борцов с высокими технологиями и о вреде пиратства. Стандартный набор.
Правда, сперва я хочу испортить вам удовольствие от предвкушения развязки этой статьи и дать искомый ответ в самом начале. Он прост: чтобы избежать ответственности за «пиратство», не нужно ставить ничего «пиратского». А теперь — можете читать дальше.
«Отмазка» найдена?
Пальму первенства в дискуссиях о том, как выйти сухим из воды, удерживает предложение обратиться к вышестоящему начальству с письмом и предупредить о недопустимости использования на рабочих местах контрафакта. Следует вручить оное письмо под роспись и наслаждаться жизнью. Дающие такой совет уверены, что это позволит переложить ответственность на начальника, оставив непосредственного исполнителя чистым. Вот на этом устойчивом и вредном заблуждении я бы и хотел остановиться поподробнее.Вообще, склонность соотечественников давать советы в тех областях, в которых они ничего не соображают, меня всегда поражала. Любопытно, много ли из советчиков пытались применить этот прогрессивный метод на практике? Боюсь, таковых не обнаружится. А если и обнаружатся, то чутье подсказывает, что о встрече с милицией, которой было предъявлено такое письмо, предъявлявший предпочтет не вспоминать очень долго.
Давайте посмотрим, как, собственно, происходит привлечение к уголовной ответственности. Следствию необходимо, среди прочего, доказать умысел подозреваемого на совершение преступления, то есть подтвердить его осведомленность о том, что устанавливаемые программы — контрафактные, и сознательно желание их установить. Тут есть несколько способов.