Страница:
С точки зрения автора, это иллюзия. Вопрос о структуризации данных по-прежнему важен, меняется лишь технология его решения. Далее предлагается один из возможных способов структуризации данных.
Показатели
Необходимость структуризации
Технология структуризации
Пример структуризации данных
Проектирование логической структуры базы данных
Распределение полей по файлам
Файлы и связи между ними
Резюме
Глава 3
Варианты создания таблиц
Формирование таблицы в режиме ввода
Ввод данных
Создание таблицы в режиме конструктора
Окно конструктора таблиц
Показатели
Рассмотрим утверждение, которое, согласно нашей классификации, принадлежит к классу фактографической информации. Например, «объем капитальных вложений равен 2,5 млн. руб.» или «стоимость „Мерседеса“ больше, чем стоимость „Жигулей“». Для этого класса данных под показателем понимается единица информации, которая включает ряд реквизитов-признаков и единственный реквизит-основание. Каждый реквизит-признак является мельчайшей неделимой информационной единицей и отражает какой-либо атрибут (свойство) объекта. Например, в энергетике такими реквизитами-признаками являются мощности, электростанции, линии электропередач, организации, расход топлива и т. д. Любой объект характеризуется перечнем свойств, которые выражаются через реквизиты.
Реквизит состоит из имени и значения. Именем реквизита будет название какой-либо качественной (наименование, местонахождение) или количественной характеристики объекта, явления, процесса (объем, размер и т. д.).
Значение реквизита представляет собой элемент данных, например: мощность (реквизит) – 500 МВт (его значение), электростанция (реквизит) – Красноярская ГЭС (значение), линия электропередач (реквизит) – Экибастуз-Центр (значение), расход топлива (реквизит) – 350 тонн (значение).
Совокупность реквизитов-признаков образует наименование показателя, а реквизит-основание представляет количественное или логическое значение показателя. Например, для приведенного выше показателя (мощность Красноярской ГЭС) реквизит-основание – 500 МВт. Очевидно, каждый реквизит-основание описывается одной фразой. В данном случае эта фраза выглядит так: «установленная мощность Красноярской ГЭС в 1998 году равна 500 МВт». (Это не значит, что вся база данных состоит из единственного предложения – такой случай представляется исключительным упрощением!) В следующем разделе будет показано, что реквизиты-признаки, в свою очередь, делятся на ряд категорий.
В общем случае ни один из реквизитов-признаков не может считаться обязательным. Характерной особенностью показателя является то, что он содержит определенный минимум информации, достаточный для создания документа. Ни один из перечисленных выше реквизитов, взятый в отдельности, не позволяет сформировать документ, а вот показатель может быть выдан в качестве справки при ответе на какой-либо запрос – скажем, о мощности Красноярской ГЭС. Верно и обратное – информационную совокупность любой сложности (отчет и т. д.) можно представить как определенную группу различных показателей.
Из сказанного ясно, зачем нужна предварительная структуризация информации пользователям, работающим с конкретной базой данных в определенной предметной области. Им необходима возможность формировать по единым правилам разнообразные запросы и получать на них ответы. (Примеры таких запросов и ответов будут приведены в главе 9.) Отсюда, между прочим, следует, что структуризация данных имеет свои разумные пределы. Разработчик банка данных, разбив исходную информацию на ряд категорий-реквизитов, уверен, что дальше делить данный реквизит не имеет смысла, потому что такие запросы пользователя маловероятны. Можно и остановиться. Однако, если впоследствии пользователю действительно потребуется задать специфический запрос, сделать это будет гораздо сложнее. Подобные варианты тоже будут рассмотрены ниже. Поэтому искусство разработчика состоит, в частности, в том, чтобы определить требуемую «золотую середину».
Реквизит состоит из имени и значения. Именем реквизита будет название какой-либо качественной (наименование, местонахождение) или количественной характеристики объекта, явления, процесса (объем, размер и т. д.).
Значение реквизита представляет собой элемент данных, например: мощность (реквизит) – 500 МВт (его значение), электростанция (реквизит) – Красноярская ГЭС (значение), линия электропередач (реквизит) – Экибастуз-Центр (значение), расход топлива (реквизит) – 350 тонн (значение).
Совокупность реквизитов-признаков образует наименование показателя, а реквизит-основание представляет количественное или логическое значение показателя. Например, для приведенного выше показателя (мощность Красноярской ГЭС) реквизит-основание – 500 МВт. Очевидно, каждый реквизит-основание описывается одной фразой. В данном случае эта фраза выглядит так: «установленная мощность Красноярской ГЭС в 1998 году равна 500 МВт». (Это не значит, что вся база данных состоит из единственного предложения – такой случай представляется исключительным упрощением!) В следующем разделе будет показано, что реквизиты-признаки, в свою очередь, делятся на ряд категорий.
В общем случае ни один из реквизитов-признаков не может считаться обязательным. Характерной особенностью показателя является то, что он содержит определенный минимум информации, достаточный для создания документа. Ни один из перечисленных выше реквизитов, взятый в отдельности, не позволяет сформировать документ, а вот показатель может быть выдан в качестве справки при ответе на какой-либо запрос – скажем, о мощности Красноярской ГЭС. Верно и обратное – информационную совокупность любой сложности (отчет и т. д.) можно представить как определенную группу различных показателей.
Из сказанного ясно, зачем нужна предварительная структуризация информации пользователям, работающим с конкретной базой данных в определенной предметной области. Им необходима возможность формировать по единым правилам разнообразные запросы и получать на них ответы. (Примеры таких запросов и ответов будут приведены в главе 9.) Отсюда, между прочим, следует, что структуризация данных имеет свои разумные пределы. Разработчик банка данных, разбив исходную информацию на ряд категорий-реквизитов, уверен, что дальше делить данный реквизит не имеет смысла, потому что такие запросы пользователя маловероятны. Можно и остановиться. Однако, если впоследствии пользователю действительно потребуется задать специфический запрос, сделать это будет гораздо сложнее. Подобные варианты тоже будут рассмотрены ниже. Поэтому искусство разработчика состоит, в частности, в том, чтобы определить требуемую «золотую середину».
Необходимость структуризации
В качестве примера в книге рассматривается информация о фактически происшедших ЧС. Эти сведения могут поступать в виде сообщений по различным информационным каналам:
• по телефону из соответствующих региональных структур (телефонограммы). В этом случае информация вручную вводится в БД;
• по телефонному каналу связи, когда информация автоматически вводится в БД;
• по электронной почте, когда информация, при необходимости, может быть переформирована в памяти компьютера перед вводом в БД;
• по почте. Данные вводятся в БД вручную.
Информация поступает в самой различной форме, например в таком произвольном виде (реальное сообщение): «На ж/д станции Ангасолка ВосточноСибирской железной дороги (ВСЖД) в ночь с 23 на 24 марта 1999 г. допущен сход двух нефтеналивных цистерн по 60 тонн каждая, с разливом сырой нефти в одной из цистерн от 30 до 40 тонн. Произошло самовоспламенение. Основная часть нефти разлилась на северной части балластной призмы в кювете счетной стороны, примыкающей к горе, и в кармане водоотводной канавы объемом 3x4x3,5 м. Кроме того, разлитая нефть выгорела на ж/д полотне площадью 230x9 м. На другой стороне ж/д полотна (на откосе) площадью 30x50 м происходило сжигание нефти под контролем пожарного надзора ВСЖД. Нефть застыла на снежном покрове двумя рукавами длиной по 100 метров и шириной 0,5 до 1 метра. Дополнительно выявлено еще два очага загрязнения площадью 5x2 и 5x10 м. К очистке рельефа местности от нефти привлечено 70 человек. Выдано предписание о ликвидации загрязнения с решением вопроса утилизации нефти. После проведения работ по зачистке загрязненной территории провести ее обследование комиссионно». (Имеется в виду, что обследование должно проводиться комиссией.)
Можно включать подобные сведения в БД в том виде, в каком они пришли. Такое решение вполне приемлемо, но только на начальном этапе. Рано или поздно поступившую информацию придется обрабатывать, а иметь дело с такими «сырыми» данными довольно трудно.
Конечно, можно регламентировать форму входных сообщений так, чтобы содержащиеся в них сведения были структурированы. Этот способ используется довольно широко, но он не гарантирует четкой формализации исходных данных. Дело в том, что первичное заполнение стандартных бланков производят рядовые сотрудники на местах, поэтому неизбежна значительная доля субъективизма. Это приводит к необходимости централизованной структуризации показателей при разработке и формировании банка данных.
• по телефону из соответствующих региональных структур (телефонограммы). В этом случае информация вручную вводится в БД;
• по телефонному каналу связи, когда информация автоматически вводится в БД;
• по электронной почте, когда информация, при необходимости, может быть переформирована в памяти компьютера перед вводом в БД;
• по почте. Данные вводятся в БД вручную.
Информация поступает в самой различной форме, например в таком произвольном виде (реальное сообщение): «На ж/д станции Ангасолка ВосточноСибирской железной дороги (ВСЖД) в ночь с 23 на 24 марта 1999 г. допущен сход двух нефтеналивных цистерн по 60 тонн каждая, с разливом сырой нефти в одной из цистерн от 30 до 40 тонн. Произошло самовоспламенение. Основная часть нефти разлилась на северной части балластной призмы в кювете счетной стороны, примыкающей к горе, и в кармане водоотводной канавы объемом 3x4x3,5 м. Кроме того, разлитая нефть выгорела на ж/д полотне площадью 230x9 м. На другой стороне ж/д полотна (на откосе) площадью 30x50 м происходило сжигание нефти под контролем пожарного надзора ВСЖД. Нефть застыла на снежном покрове двумя рукавами длиной по 100 метров и шириной 0,5 до 1 метра. Дополнительно выявлено еще два очага загрязнения площадью 5x2 и 5x10 м. К очистке рельефа местности от нефти привлечено 70 человек. Выдано предписание о ликвидации загрязнения с решением вопроса утилизации нефти. После проведения работ по зачистке загрязненной территории провести ее обследование комиссионно». (Имеется в виду, что обследование должно проводиться комиссией.)
Можно включать подобные сведения в БД в том виде, в каком они пришли. Такое решение вполне приемлемо, но только на начальном этапе. Рано или поздно поступившую информацию придется обрабатывать, а иметь дело с такими «сырыми» данными довольно трудно.
Конечно, можно регламентировать форму входных сообщений так, чтобы содержащиеся в них сведения были структурированы. Этот способ используется довольно широко, но он не гарантирует четкой формализации исходных данных. Дело в том, что первичное заполнение стандартных бланков производят рядовые сотрудники на местах, поэтому неизбежна значительная доля субъективизма. Это приводит к необходимости централизованной структуризации показателей при разработке и формировании банка данных.
Технология структуризации
Проведенные исследования показали, что обычно в обязательный минимум реквизитов-признаков входят следующие:
• П – процесс – основное наименование деятельности органа управления (операция, состояние). Это суть показателя (расход, остатки, поставка, капитальные вложения, мощность, ущерб и т. д.);
• Ф – формальная характеристика, то есть выраженный в наименовании способ расчета показателя (доля, темп роста, отклонение, сумма, прирост, среднее и средневзвешенное значения и т. п.), который может быть как относительным, так и абсолютным и тесно связан с процессом (иногда задан в нем неявно);
• О – объект, предмет операции; то, над чем она выполняется (материалы, изделия, полуфабрикаты, строительная продукция и т. д.);
• Е – единица измерения;
• С – субъект (тот, кто производит действия над объектом). Если, например, объект (О) – продукция, а основное наименование деятельности (П) – производство, то в роли субъекта (С) может выступать, например, предприятие, отрасль и т. д.;
• В – время (дата, период);
• Ф – функция управления (проектное, прогнозное или фактическое значение, норматив и т. п.).
Естественно, все многообразие реальных признаков не укладывается в приведенный краткий перечень. Поэтому каждый из названных реквизитов допускает практически неограниченное количество любых категорий-уточнений, которые должны удовлетворять единственному условию – представлять собой списки, состоящие из однородных терминов. Обычно уточняются следующие вопросы:
• где – в этом случае список уточнений характеризует место действия;
• как – список уточнений характеризует обстоятельства действия;
• какой – список уточнений характеризует свойство.
Сформированные таким образом списки при проектировании банка данных рассматриваются как словари. По сути, цель структуризации – создание словарей. При последующей разработке логической структуры БД они служат как бы осями координат, по которым организуется, «раскладывается» реальная информация.
Эти соображения, как уже говорилось, определяют ту границу, до которой имеет смысл проводить структуризацию. Если выясняется, что какие-то словосочетания слишком индивидуальны, уникальны и не поддаются классификации, их не следует включать в словари. В приведенном выше сообщении это формулировки типа «на северной части балластной призмы в кювете с четной стороны, примыкающей к горе, и в кармане водоотводной канавы»; «на другой стороне ж/д полотна (на откосе)». Для таких данных надо использовать специальные поля примечаний, прикрепленных к соответствующей конкретной записи.
При простой структуре исходной информации первый этап структуризации – выделение основных реквизитов-признаков – можно пропустить и сразу формировать словари. Однако учтите, что о простоте или сложности структуры исходной информации нельзя говорить вообще – это понятие имеет смысл только с одной точки зрения: легко ли будет пользователю получать ответы на запросы к БД. Поэтому прежде чем приступать к анализу первичной информации, подумайте: кто будет работать с проектируемой базой данных, какие сведения понадобятся пользователю и какими будут его запросы. В этом требовании нет ничего нового – это одно из классических положений проектирования баз данных. Но уже на начальных стадиях, при введении некоторой формализации в структуры данных, вы убедитесь, насколько важно следовать этому правилу.
• П – процесс – основное наименование деятельности органа управления (операция, состояние). Это суть показателя (расход, остатки, поставка, капитальные вложения, мощность, ущерб и т. д.);
• Ф – формальная характеристика, то есть выраженный в наименовании способ расчета показателя (доля, темп роста, отклонение, сумма, прирост, среднее и средневзвешенное значения и т. п.), который может быть как относительным, так и абсолютным и тесно связан с процессом (иногда задан в нем неявно);
• О – объект, предмет операции; то, над чем она выполняется (материалы, изделия, полуфабрикаты, строительная продукция и т. д.);
• Е – единица измерения;
• С – субъект (тот, кто производит действия над объектом). Если, например, объект (О) – продукция, а основное наименование деятельности (П) – производство, то в роли субъекта (С) может выступать, например, предприятие, отрасль и т. д.;
• В – время (дата, период);
• Ф – функция управления (проектное, прогнозное или фактическое значение, норматив и т. п.).
Естественно, все многообразие реальных признаков не укладывается в приведенный краткий перечень. Поэтому каждый из названных реквизитов допускает практически неограниченное количество любых категорий-уточнений, которые должны удовлетворять единственному условию – представлять собой списки, состоящие из однородных терминов. Обычно уточняются следующие вопросы:
• где – в этом случае список уточнений характеризует место действия;
• как – список уточнений характеризует обстоятельства действия;
• какой – список уточнений характеризует свойство.
Сформированные таким образом списки при проектировании банка данных рассматриваются как словари. По сути, цель структуризации – создание словарей. При последующей разработке логической структуры БД они служат как бы осями координат, по которым организуется, «раскладывается» реальная информация.
Эти соображения, как уже говорилось, определяют ту границу, до которой имеет смысл проводить структуризацию. Если выясняется, что какие-то словосочетания слишком индивидуальны, уникальны и не поддаются классификации, их не следует включать в словари. В приведенном выше сообщении это формулировки типа «на северной части балластной призмы в кювете с четной стороны, примыкающей к горе, и в кармане водоотводной канавы»; «на другой стороне ж/д полотна (на откосе)». Для таких данных надо использовать специальные поля примечаний, прикрепленных к соответствующей конкретной записи.
При простой структуре исходной информации первый этап структуризации – выделение основных реквизитов-признаков – можно пропустить и сразу формировать словари. Однако учтите, что о простоте или сложности структуры исходной информации нельзя говорить вообще – это понятие имеет смысл только с одной точки зрения: легко ли будет пользователю получать ответы на запросы к БД. Поэтому прежде чем приступать к анализу первичной информации, подумайте: кто будет работать с проектируемой базой данных, какие сведения понадобятся пользователю и какими будут его запросы. В этом требовании нет ничего нового – это одно из классических положений проектирования баз данных. Но уже на начальных стадиях, при введении некоторой формализации в структуры данных, вы убедитесь, насколько важно следовать этому правилу.
Пример структуризации данных
Рассмотрим практический пример. Вы занимаетесь структуризацией информации при проектировании базы данных по контрольно-измерительным приборам, которые выпускаются различными фирмами. Это довольно простая БД, и каждая запись в ней выглядит так: «Прибор (название), с номером модели (номер), произведенный в (год) году фирмой (название), которая находится в стране (название) по адресу (приводится адрес) и имеет филиал по адресу (приводится адрес), предназначенный для (целевое назначение), имеющий характеристики (перечень технических характеристик), включенный в каталог под номером (номер в каталоге) и обслуживаемый менеджером (данные о менеджере), имеет цену (приводится цена)». Конечно, фраза громоздкая и не слишком гладкая. Поэтому ее стоит разбить на более простые фрагменты. Любой пользователь, заказчик или разработчик базы данных легко может внести в нее необходимые изменения. Ниже будет показано, как это делается.
Итак, информация о приборах включает следующие пункты:
• О (объект) – название прибора;
• У (уточнение сведений об объекте) – номер модели. Если при анализе сообщения возникает необходимость в нескольких уточнениях, то им можно присвоить номера;
• У (уточнение сведений об объекте) – год выпуска прибора;
• У (уточнение сведений об объекте) – номер прибора по каталогу;
• У (уточнение сведений об объекте) – характеристика прибора, содержащая данные о его функциях, портативности, технических особенностях, весе, точности, способе питания, диапазоне измерений, совместимости с другими приборами;
• С (субъект) – название фирмы, производящей прибор;
• У (уточнение сведений о субъекте) – страна, в которой находится фирма;
• У (уточнение сведений о субъекте) – адрес фирмы;
• У (уточнение сведений о субъекте) – адрес филиала или дочерней фирмы, если такая есть;
• У (уточнение сведений о субъекте) – данные о менеджерах фирмы (фамилия, имя, отчество и адрес);
• Р (реквизит-основание) – цена прибора.
Предположим, пользователя в первую очередь интересует не только цена, но и вес прибора. Этот параметр можно выделить из общего массива «характеристика» и придать ему статус еще одного реквизита-основания. Тогда приведенная выше фраза-описание будет содержать две однородные фразы с параллельными реквизитами-основаниями – цена и вес.
В рассмотренном примере структура информации достаточно проста, и нужные словари могут быть сформированы практически сразу, на первом этапе проектирования. Создавая их и уточняя перечень основных реквизитов-признаков, руководствуйтесь следующим критерием: часто ли у пользователя будет необходимость запрашивать информацию по данному признаку. Если да, то имеет смысл выделить его как отдельный реквизит и сформировать соответствующий словарь. Такой признак называется ключевым значением, или дескриптором. В базе данных ему лучше выделить отдельный файл или поле в файле; этим вы существенно облегчите работу будущему пользователю. Конечно, если какой-либо признак «спрятан» в общем тексте, по нему тоже можно сделать запрос, но сформировать последний в этом случае сложнее.
В нашем примере можно сразу выделить те признаки, по которым следует ожидать частого обращения к базе данных:
• название прибора;
• название фирмы, производящей прибор;
• страна, в которой находится фирма;
• адрес фирмы;
• адрес филиала или дочерней фирмы;
• данные о менеджерах фирмы – фамилия, имя, отчество и адрес;
• номер модели;
• год выпуска прибора;
• номер прибора по каталогу;
• цена прибора;
• функциональное назначение прибора;
• вес прибора;
• категория прибора (переносной, портативный и т. п.);
• характеристика прибора.
Параметры, которые для пользователя второстепенны, остаются в общем тексте раздела.
Возьмем пример посложнее, который представлен в разделе «Необходимость структуризации». Здесь описание включает не одну, а несколько фраз, и анализ, подобный предыдущему, надо провести отдельно для каждой из них. В результате мы получим следующий набор признаков:
• П (показатели) – «выявлено», «выдано», «сжигание» и др.;
• О1 (объект) – источники загрязнения (нефтеналивные цистерны);
• О2 (объект) – загрязняющие вещества (нефть);
• О3 (объект) – объекты загрязнения (рельеф местности);
• О4 (объект) – документы (предписание о ликвидации последствий аварии);
• У1 (уточнение места действия 1) – железнодорожные станции (Ангасолка);
• У2 (уточнение места действия 2) – железные дороги (Восточно-Сибирская);
• У3 (обстоятельство действия 1) – под контролем комиссии;
• П (примечания) – как уже говорилось, в этих полях должны содержаться данные – уточнения, специфичные для конкретных сообщений.
Таким образом, по мере накопления новых сообщений будут появляться и новые реквизиты, а количество параметров, указанных в скобках, тоже будет расти.
Итак, информация о приборах включает следующие пункты:
• О (объект) – название прибора;
• У (уточнение сведений об объекте) – номер модели. Если при анализе сообщения возникает необходимость в нескольких уточнениях, то им можно присвоить номера;
• У (уточнение сведений об объекте) – год выпуска прибора;
• У (уточнение сведений об объекте) – номер прибора по каталогу;
• У (уточнение сведений об объекте) – характеристика прибора, содержащая данные о его функциях, портативности, технических особенностях, весе, точности, способе питания, диапазоне измерений, совместимости с другими приборами;
• С (субъект) – название фирмы, производящей прибор;
• У (уточнение сведений о субъекте) – страна, в которой находится фирма;
• У (уточнение сведений о субъекте) – адрес фирмы;
• У (уточнение сведений о субъекте) – адрес филиала или дочерней фирмы, если такая есть;
• У (уточнение сведений о субъекте) – данные о менеджерах фирмы (фамилия, имя, отчество и адрес);
• Р (реквизит-основание) – цена прибора.
Предположим, пользователя в первую очередь интересует не только цена, но и вес прибора. Этот параметр можно выделить из общего массива «характеристика» и придать ему статус еще одного реквизита-основания. Тогда приведенная выше фраза-описание будет содержать две однородные фразы с параллельными реквизитами-основаниями – цена и вес.
В рассмотренном примере структура информации достаточно проста, и нужные словари могут быть сформированы практически сразу, на первом этапе проектирования. Создавая их и уточняя перечень основных реквизитов-признаков, руководствуйтесь следующим критерием: часто ли у пользователя будет необходимость запрашивать информацию по данному признаку. Если да, то имеет смысл выделить его как отдельный реквизит и сформировать соответствующий словарь. Такой признак называется ключевым значением, или дескриптором. В базе данных ему лучше выделить отдельный файл или поле в файле; этим вы существенно облегчите работу будущему пользователю. Конечно, если какой-либо признак «спрятан» в общем тексте, по нему тоже можно сделать запрос, но сформировать последний в этом случае сложнее.
В нашем примере можно сразу выделить те признаки, по которым следует ожидать частого обращения к базе данных:
• название прибора;
• название фирмы, производящей прибор;
• страна, в которой находится фирма;
• адрес фирмы;
• адрес филиала или дочерней фирмы;
• данные о менеджерах фирмы – фамилия, имя, отчество и адрес;
• номер модели;
• год выпуска прибора;
• номер прибора по каталогу;
• цена прибора;
• функциональное назначение прибора;
• вес прибора;
• категория прибора (переносной, портативный и т. п.);
• характеристика прибора.
Параметры, которые для пользователя второстепенны, остаются в общем тексте раздела.
Возьмем пример посложнее, который представлен в разделе «Необходимость структуризации». Здесь описание включает не одну, а несколько фраз, и анализ, подобный предыдущему, надо провести отдельно для каждой из них. В результате мы получим следующий набор признаков:
• П (показатели) – «выявлено», «выдано», «сжигание» и др.;
• О1 (объект) – источники загрязнения (нефтеналивные цистерны);
• О2 (объект) – загрязняющие вещества (нефть);
• О3 (объект) – объекты загрязнения (рельеф местности);
• О4 (объект) – документы (предписание о ликвидации последствий аварии);
• У1 (уточнение места действия 1) – железнодорожные станции (Ангасолка);
• У2 (уточнение места действия 2) – железные дороги (Восточно-Сибирская);
• У3 (обстоятельство действия 1) – под контролем комиссии;
• П (примечания) – как уже говорилось, в этих полях должны содержаться данные – уточнения, специфичные для конкретных сообщений.
Таким образом, по мере накопления новых сообщений будут появляться и новые реквизиты, а количество параметров, указанных в скобках, тоже будет расти.
Проектирование логической структуры базы данных
Итак, мы определили состав дескрипторов, то есть ключевых полей для поиска, по которым чаще всего (по нашему прогнозу) будут формироваться запросы к базе данных. Теперь начнем разработку логической структуры БД. Под логической структурой понимается та совокупность файлов, содержащихся в них полей и связей между файлами, которую «видит» пользовательская программа, обрабатывающая базу данных.
Распределение полей по файлам
В предыдущем разделе мы постарались объяснить, почему и как необходимо выделять дескрипторные поля, по которым ожидаются запросы со стороны пользователя. Мы исходили из того, что каждому такому полю должен соответствовать словарь. Если вы в этом еще сомневаетесь, вспомните, что между элементами информации существуют различные типы отношений: «один-к-одному», «один-ко-многим», «многие-ко-многим». Очевидно, когда между какими-то элементами информации (полями) существует отношение «один-к-одному», они жестко и однозначно взаимосвязаны. В таком случае достаточно иметь один словарь на всю эту группу. Но тогда она должна находиться в одном файле, потому что иначе отношение «один-к-одному» не будет реализовано без применения каких-либо дополнительных средств. Как видите, логика довольно проста. Теперь у нас есть критерий для распределения полей по файлам: в одном файле следует размещать те поля, которые связаны между собой отношением «один-к-одному». Файлы, объединяющие такие группы полей, будут находиться друг с другом в отношении «один-ко-многим» и составят иерархическую структуру. Отметим, что файлы, находящиеся в отношениях типа «многие-ко-многим», не должны быть непосредственно взаимосвязанными. Обобщим сказанное в табл. 2.1.
В этой таблице символы Х и и обозначают соответственно стороны «многие» и «один» в отношениях между реквизитами.
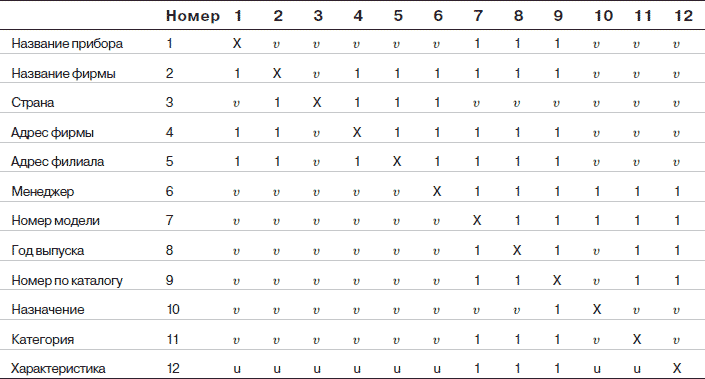
В этой таблице символы Х и и обозначают соответственно стороны «многие» и «один» в отношениях между реквизитами.
Таблица 2.1
Файлы и связи между ними
Из табл. 2.1 видно: чтобы формировать файлы, следует сгруппировать в них поля, представляющие реквизиты-признаки, находящиеся друг с другом, как сказано выше, в отношении «один-к-одному». Таким образом, будут созданы следующие файлы:
• Страны (содержит поле Название страны);
• Приборы (содержит поля Номер модели, Категория, Год выпуска, Характеристика, Номер по каталогу, Цена, Вес);
• Фирмы (содержит поля Название фирмы, Адрес фирмы, Адрес филиала);
• Менеджер (содержит поле Данные о менеджере);
• Назначение (содержит поле Назначение прибора);
• Типы приборов (содержит поле Название прибора).
Мы перечислили здесь основные – так сказать, «титульные» – поля, составляющие каркас конкретной таблицы. В нее могут также входить вспомогательные поля: Примечания, Адрес и др. Соединив эти файлы связями типа «один-ко-многим», мы получим логическую структуру базы данных, условный вид которой показан на рис. 2.1. О практической реализации таких связей речь пойдет в конце следующей главы.
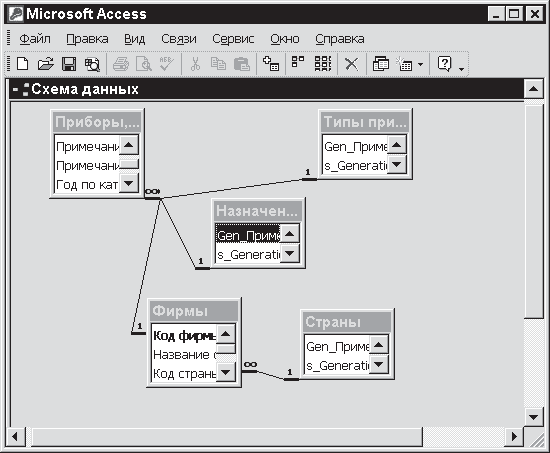 Рис. 2.1
Рис. 2.1
• Страны (содержит поле Название страны);
• Приборы (содержит поля Номер модели, Категория, Год выпуска, Характеристика, Номер по каталогу, Цена, Вес);
• Фирмы (содержит поля Название фирмы, Адрес фирмы, Адрес филиала);
• Менеджер (содержит поле Данные о менеджере);
• Назначение (содержит поле Назначение прибора);
• Типы приборов (содержит поле Название прибора).
Мы перечислили здесь основные – так сказать, «титульные» – поля, составляющие каркас конкретной таблицы. В нее могут также входить вспомогательные поля: Примечания, Адрес и др. Соединив эти файлы связями типа «один-ко-многим», мы получим логическую структуру базы данных, условный вид которой показан на рис. 2.1. О практической реализации таких связей речь пойдет в конце следующей главы.
Резюме
1. Безусловный прогресс, достигнутый в развитии программных средств СУБД и расширении их функциональных возможностей, не устранил проблему обоснованности выбора структур баз данных – от продуманности этих структур во многом зависит эффективность работы с базами данных (БД).
2. Основным элементом фактографической информации является показатель. Он, в свою очередь, состоит из множества реквизитов-признаков и единственного реквизита-основания.
3. Для того чтобы формировать по единым правилам разнообразные пользовательские запросы к БД и получать на них ответы, перед проектированием конкретных баз данных необходимо провести структуризацию информации.
4. В настоящей главе предлагается и иллюстрируется на конкретном примере технология такой структуризации и – на ее основе – последующего проектирования логической структуры БД.
2. Основным элементом фактографической информации является показатель. Он, в свою очередь, состоит из множества реквизитов-признаков и единственного реквизита-основания.
3. Для того чтобы формировать по единым правилам разнообразные пользовательские запросы к БД и получать на них ответы, перед проектированием конкретных баз данных необходимо провести структуризацию информации.
4. В настоящей главе предлагается и иллюстрируется на конкретном примере технология такой структуризации и – на ее основе – последующего проектирования логической структуры БД.
Глава 3
Создание таблиц новой базы данных
Как уже было сказано в главе 2, разработка новой базы данных «Контрольно-измерительные приборы» производится в программной среде Access 2002.
Формирование БД в Access состоит из ряда последовательных этапов, описываемых ниже. Первый этап этого процесса – создание таблиц. Таблицы в Access являются теми первичными, исходными файлами, на основе которых в дальнейшем строится все здание базы данных. Access 2002, как и предыдущие версии, предоставляет пользователю несколько разных вариантов построения таблиц, а также возможность применения дополнительных аналитических табличных структур.
Порядок создания всех таблиц одинаков и не зависит от их названия и конкретного содержания. Мы рассмотрим этот процесс на примере таблицы Страны.
Формирование БД в Access состоит из ряда последовательных этапов, описываемых ниже. Первый этап этого процесса – создание таблиц. Таблицы в Access являются теми первичными, исходными файлами, на основе которых в дальнейшем строится все здание базы данных. Access 2002, как и предыдущие версии, предоставляет пользователю несколько разных вариантов построения таблиц, а также возможность применения дополнительных аналитических табличных структур.
Порядок создания всех таблиц одинаков и не зависит от их названия и конкретного содержания. Мы рассмотрим этот процесс на примере таблицы Страны.
Варианты создания таблиц
Формирование таблицы начинается с того, что вы открываете окно базы данных и в нем выбираете пункт Таблицы в разделе Объекты – рис. 3.1.
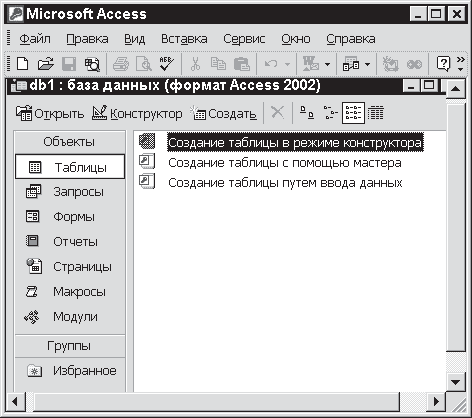 Рис. 3.1
Рис. 3.1
Дальше следует щелкнуть по кнопке
 на панели окна БД. В диалоговом окне Новая таблица, показанном на рис. 3.2, представлены все возможные параметры создания таблицы:
на панели окна БД. В диалоговом окне Новая таблица, показанном на рис. 3.2, представлены все возможные параметры создания таблицы:
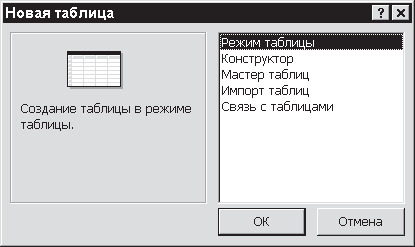 Рис. 3.2
Рис. 3.2
• Режим таблицы;
• Конструктор;
• Мастер таблиц;
• Импорт таблиц;
• Связь с таблицами.
Последние два варианта создания таблиц – импорт таблиц и связь с таблицами – рассматриваются в том разделе главы 7, который посвящен объединению разнородных баз данных.
Дальше следует щелкнуть по кнопке
• Режим таблицы;
• Конструктор;
• Мастер таблиц;
• Импорт таблиц;
• Связь с таблицами.
Последние два варианта создания таблиц – импорт таблиц и связь с таблицами – рассматриваются в том разделе главы 7, который посвящен объединению разнородных баз данных.
Формирование таблицы в режиме ввода
Войти в этот режим можно двумя способами: либо выбрав пункт Режим таблицы в окне Новая таблица (см. рис. 3.2) и щелкнув по кнопке ОК, либо выбрав опцию Создание таблицы путем ввода данных в окне базы данных (см. рис. 3.1). В результате на экране появится таблица, готовая к вводу информации (рис. 3.3).
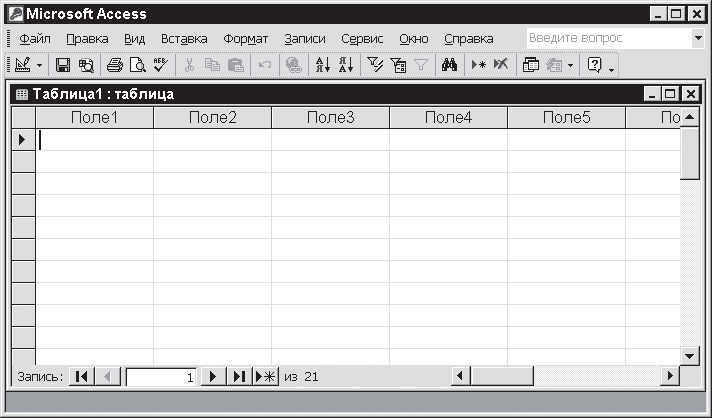 Рис. 3.3
Рис. 3.3
Ввод данных
Чтобы осуществить ввод данных, сначала надо заменить имеющиеся заголовки столбцов, а затем уже ввести сведения в поля таблицы. Рассмотрим эту операцию на примере создания таблицы Страны.
Заменим имена полей Поле1 и Поле2 на Код и Страна. Для этого дважды щелкните мышью в ячейке с именем соответствующего поля, а затем введите нужные значения. Записав первые данные (см. рис. 3.4), попробуйте выйти из созданной таблицы (кнопка в правом верхнем углу). Сначала Access 2002 спросит вас, надо ли сохранять произведенные в таблице изменения (если вы не хотите этого делать, она вообще сотрется из памяти). Затем вам будет предложено назвать таблицу (или согласиться с предлагаемым именем, которое присваивается автоматически). Все таблицы программа называет именем Таблица с добавлением текущего номера.
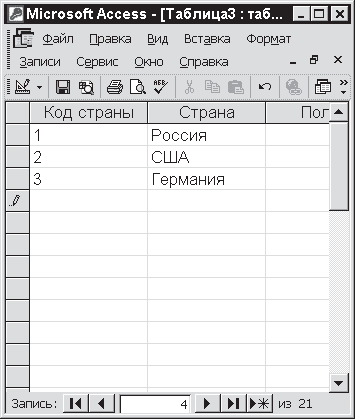 Рис. 3.4
Рис. 3.4
 Рис. 3.5
Рис. 3.5
Если вы отказываетесь установить ключевые поля и отвечаете Нет, программа запомнит таблицу в том виде, в каком она показана на рис. 3.4. Однако вопрос о ключевых полях все равно возникнет на следующем этапе работы – когда вы будете формировать связи между файлами, и уж тогда без ключевых полей система не справится с этой задачей. Если вы поддались на уговоры и сразу согласились создать первичный код, выбрав ответ Да, то программа сама сделает это. В результате таблица будет выглядеть так, как показано на рис. 3.6.
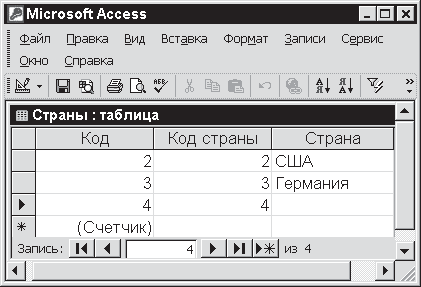 Рис. 3.6
Рис. 3.6
Если вы выберете пункт Отмена, таблица вновь примет тот вид, который показан на рис. 3.4. Однако это промежуточное состояние, из которого все равно надо как-то выходить. Внимательно посмотрите на первичные коды, созданные системой в поле Код. Здесь они ничем не отличаются от кодов, созданных пользователем в поле Код страны. Но в общем случае коды, введенные в это поле, совсем не обязаны быть такими же упорядоченными, как коды поля Код, – таблица, показанная на рис. 3.6, представляет собой словарь, и коды могут периодически изменяться. Поэтому для надежного контроля за файлами в Access предусмотрен механизм системных первичных кодов. Иногда (как, например, сейчас) они вводятся только по желанию пользователя. В других случаях при отсутствии этих кодов ряд функций Access 2002 выполняться не будет.
Поэтому, если у пользователя нет каких-то серьезных причин отказываться от введения первичных кодов, желательно их все-таки создать.
Отметим, что в словарном файле совсем не обязательно ограничиваться тем минимумом полей, которые показаны в нашем примере. Это было сделано исключительно в методических целях. На практике количество полей в файле вообще не ограничивается, следует лишь соблюдать единственное требование: поля должны находиться в отношениях «один-к-одному».
Заменим имена полей Поле1 и Поле2 на Код и Страна. Для этого дважды щелкните мышью в ячейке с именем соответствующего поля, а затем введите нужные значения. Записав первые данные (см. рис. 3.4), попробуйте выйти из созданной таблицы (кнопка в правом верхнем углу). Сначала Access 2002 спросит вас, надо ли сохранять произведенные в таблице изменения (если вы не хотите этого делать, она вообще сотрется из памяти). Затем вам будет предложено назвать таблицу (или согласиться с предлагаемым именем, которое присваивается автоматически). Все таблицы программа называет именем Таблица с добавлением текущего номера.
Первичный код
Когда все это будет сделано, вы получите предупреждение о том, что ключевые поля не заданы, как показано на рис. 3.5.Если вы отказываетесь установить ключевые поля и отвечаете Нет, программа запомнит таблицу в том виде, в каком она показана на рис. 3.4. Однако вопрос о ключевых полях все равно возникнет на следующем этапе работы – когда вы будете формировать связи между файлами, и уж тогда без ключевых полей система не справится с этой задачей. Если вы поддались на уговоры и сразу согласились создать первичный код, выбрав ответ Да, то программа сама сделает это. В результате таблица будет выглядеть так, как показано на рис. 3.6.
Если вы выберете пункт Отмена, таблица вновь примет тот вид, который показан на рис. 3.4. Однако это промежуточное состояние, из которого все равно надо как-то выходить. Внимательно посмотрите на первичные коды, созданные системой в поле Код. Здесь они ничем не отличаются от кодов, созданных пользователем в поле Код страны. Но в общем случае коды, введенные в это поле, совсем не обязаны быть такими же упорядоченными, как коды поля Код, – таблица, показанная на рис. 3.6, представляет собой словарь, и коды могут периодически изменяться. Поэтому для надежного контроля за файлами в Access предусмотрен механизм системных первичных кодов. Иногда (как, например, сейчас) они вводятся только по желанию пользователя. В других случаях при отсутствии этих кодов ряд функций Access 2002 выполняться не будет.
Поэтому, если у пользователя нет каких-то серьезных причин отказываться от введения первичных кодов, желательно их все-таки создать.
Отметим, что в словарном файле совсем не обязательно ограничиваться тем минимумом полей, которые показаны в нашем примере. Это было сделано исключительно в методических целях. На практике количество полей в файле вообще не ограничивается, следует лишь соблюдать единственное требование: поля должны находиться в отношениях «один-к-одному».
Создание таблицы в режиме конструктора
Описанная в предыдущем разделе таблица создавалась, можно сказать, стихийно. Теперь мы будем придерживаться строгой последовательности действий, заблаговременно обосновывая все дальнейшие операции, задавая необходимые данные и их форматы.
Окно конструктора таблиц
Войти в этот режим можно двумя способами. Первый: выберите пункт Конструктор в окне Новая таблица – рис. 3.2, затем щелкните по кнопке ОК. Другой вариант: выберите пункт Создание таблицы в режиме конструктора в окне базы данных (см. рис. 3.1). На экране появится окно конструктора таблиц (см. рис. 3.7), содержащее три раздела:
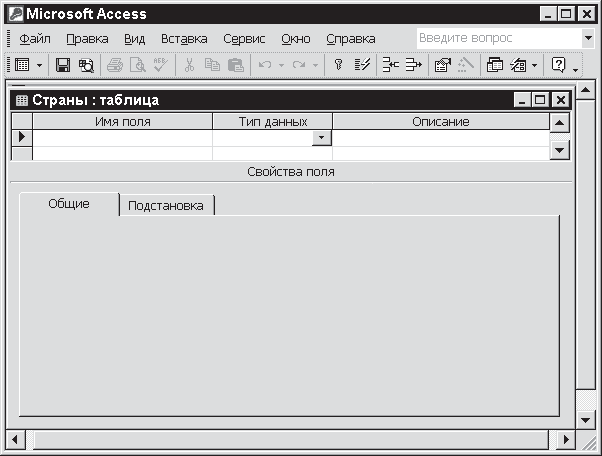 Рис. 3.7
Рис. 3.7
• Имя поля;
• Тип данных – обязательный раздел;
• Описание – необязательный раздел.
В разделе Имя поля следует указать имена полей – те самые, которые в предыдущем разделе вводились в заголовки столбцов таблицы. Ситуация с первичным кодом совершенно аналогична.
Чтобы начать работу с разделом Тип данных, надо щелкнуть мышью в его пределах. Как только это произойдет, в его правой части появится стрелка прокрутки. Щелкните по ней – увидите список типов данных, которые поддерживаются в Access 2002 (см. рис. 3.8). Характеристика типов данных приводится в следующем разделе этой главы.
• Имя поля;
• Тип данных – обязательный раздел;
• Описание – необязательный раздел.
В разделе Имя поля следует указать имена полей – те самые, которые в предыдущем разделе вводились в заголовки столбцов таблицы. Ситуация с первичным кодом совершенно аналогична.
Чтобы начать работу с разделом Тип данных, надо щелкнуть мышью в его пределах. Как только это произойдет, в его правой части появится стрелка прокрутки. Щелкните по ней – увидите список типов данных, которые поддерживаются в Access 2002 (см. рис. 3.8). Характеристика типов данных приводится в следующем разделе этой главы.