Страница:
Формы: семинар.
Приемы решения поставленных задач:
1. Мультимедийная презентация.
2. Рецензирование презентаций.
3. Проверка определений ключевых понятий в интернет-источниках.
Глава II.
Первый урок
Материалы для урока
Второй урок
Материалы для урока
Третий урок
Материалы к уроку
Тезаурус (от греч. thesaures «сокровище, сокровищница») – 1) словарь, в котором максимально полно представлены все слова языка с исчерпывающим перечнем примеров их употребления в текстах; 2) идеографический словарь, в котором показаны семантические отношения (родовидовые, синонимические и др.) между лексическими единицами. Тезаурус в первом значении в полном объеме осуществим лишь для мертвых языков. Структурной основой для тезауруса во втором значении обычно служит иерархическая система понятий, обеспечивающая поиск от смыслов к лексическим единицам, т. е. поиск слова, исходя из обозначенного им понятия. Тезаурусы обычно издаются как иллюстрированные словари: приводится изображение с пронумерованными по-чертежному деталями, в текстовой части нумерованный список сопровождается названиями (иногда на нескольких языках). Поиск в тезаурусе ведется по иерархическому дереву: от более общего наименования к более частному. Например, чтобы выяснить наименование (или внешний вид) кокошника, необходимо обратится к предметной области «одежда», далее выбрать рубрику «головные уборы».
В тезаурусах преодолевается один из весьма существенных недостатков традиционных словарей. Ведущий отечественный специалист по прикладной лингвистике А.И. Новиков полно охарактеризовал этот недостаток в предисловии к монографии «Семантика информационных технологий» Ю. Филипповича и А. Прохорова: «Традиционный словарный способ представления лексики характеризуется тем, что слова в нем организуются на основе какого-либо формального принципа (например, алфавитное расположение). Вследствие этого и значения, которые задаются в таких словарях в виде дефиниций, также оказываются разобщенными и в явном виде не обнаруживают своей системности. Ее можно установить в результате специальной деятельности, заключающейся в обнаружении некоторых общих компонентов в этих значениях, или других признаках их связности. Иногда сделать это бывает достаточно трудно. Это дает основания считать, что традиционный словарь, являясь инструментом представления лексического состава языка, как правило, не отражает достаточно полно и эксплицитно внутреннюю системность языка. Он может служить материалом для такой системности, для чего требуется специальная деятельность лингвиста и соответствующие методы анализа» (Филиппович, Прохоров 2002: 5–6). Естественно, рядовой носитель языка, а тем более школьник, не владеет специальными методами анализа и не сможет на основе традиционных словарей составить представление о предметной области, выявить меру различия близких понятий и т. п. Эти задачи позволит ему решить тезаурус.
Некоторые полезные тезаурусы представлены в Интернете по адресу http://www.rutenia.ru/folklore/. С содержанием лингвистических понятий можно ознакомиться в «Тезаурусе по теоретической и прикладной лингвистике» С.Е. Никитиной (Никитина 1978). Опыт словарно-тезаурусного описания семантики информационных технологий обсуждается в монографии Ю.Н. Филипповича и А.В. Прохорова (Филиппович, Прохоров 2002).
Задание 1. Найдите определение термина тезаурус в сетевых энциклопедиях Википедия и Кругосвет. Сохраните скриншоты с определениями для итоговой презентации по спецкурсу.
Задание 2. Ознакомьтесь с тезаурусами, доступными по адресу http://www.rutenia.ru/folklore/.
База данных не является понятием собственно прикладной лингвистики. Это понятие общее для всех информационных технологий. База данных – это структурированная совокупность взаимосвязанных данных в рамках некоторой предметной области, предназначенная для длительного хранения во внешней (не оперативной) памяти компьютера и постоянного применения. Тем не менее создание базы данных – ключевая технология компьютерной лексикографии. Современные словари создаются на основе хранимых в памяти компьютера контекстов, для их создания используют программы, позволяющие формальным образом представить морфологические, словообразовательные, синтаксические и даже семантические характеристики слова.
Формирование базы данных начинается с табличного представления сырого материала. В стандартный пакет программного обеспечения Windows входят электронные таблицы Excel, позволяющие организовать материал и производить стандартную статистическую обработку. Однако управлять базой данных в Excel неудобно. Для управления базой данных Microsoft Office предлагает систему управления базой данных Access (СУБД Access). Это сравнительно простая система, позволяющая из исходного материала, введенного в базу данных, формировать множество таблиц по количественным и качественным параметрам, заданным самим пользователем. СУБД Аccess широко используется в лингвистических работах.
Задание 1. Ознакомьтесь с приложением Excel. Используя возможности приложения, попытайтесь составить таблицу образцов склонения русских существительных.
Задание 2. Выберите одну из доступных в Интернет лингвистическую базу данных:
http://www.speech.nw.ru/,
http://www.imli.ru/zagovor/,
www.lingsoft.fi/doc/rustwol.txt.
Подготовьте презентацию о ней.
Составить таблицу формообразования (по выбору) в Excel.
Четвертый урок
Материалы для урока
Приемы решения поставленных задач:
1. Мультимедийная презентация.
2. Рецензирование презентаций.
3. Проверка определений ключевых понятий в интернет-источниках.
Рекомендуемое домашнее задание
Найти в Интернете определение информационно-коммуникационных технологий.
Глава II.
Информационно-коммуникационные технологии в филологии
Определение новых информационных технологий. Прикладная русистика как научная сфера разработки и использования ИКТ. Основные ИКТ прикладной русистики.
Тезаурусы. Базы данных. Корпусы данных и корпусы текстов. Формирование баз знаний и экспертных систем. Системы автоматического перевода. Гипертекстовые технологии представления текста.
Национальный корпус русского языка и Национальный корпус русского литературного языка. Общая характеристика и основные приемы работы с Корпусом.
Компьютерные технологии обработки и хранения звукового сигнала. Основные характеристики звучащей речи.
Тезаурусы. Базы данных. Корпусы данных и корпусы текстов. Формирование баз знаний и экспертных систем. Системы автоматического перевода. Гипертекстовые технологии представления текста.
Национальный корпус русского языка и Национальный корпус русского литературного языка. Общая характеристика и основные приемы работы с Корпусом.
Компьютерные технологии обработки и хранения звукового сигнала. Основные характеристики звучащей речи.
Первый урок
Тема: Основные ИКТ прикладной русистики
Цель в предметной области: знакомство с терминологией, расширение кругозора.
Цель в формировании информационно-коммуникационной компетентности: определение основных технологий и их возможностей.
Задачи:
1. Проверить определения ИКТ, найденные школьниками в Интернете. Итоговое определение записать в словарик.
2. Определить различия в значениях слов «информационный» и «информативный», «коммуникационный» и «коммуникативный», «техника» и «технология».
3. Показать возможности и примеры использования технологий.
Формы: семинар.
Приемы решения задач:
1. Подготовить презентацию с определениями основных технологий.
2. Предварительное индивидуальное задание ученикам: подготовить доклад и презентацию с характеристикой технологий гипертекста, тезауруса, базы данных, корпуса данных.
3. Обсудить презентации и записать итоговое определение в словарик.
Цель в формировании информационно-коммуникационной компетентности: определение основных технологий и их возможностей.
Задачи:
1. Проверить определения ИКТ, найденные школьниками в Интернете. Итоговое определение записать в словарик.
2. Определить различия в значениях слов «информационный» и «информативный», «коммуникационный» и «коммуникативный», «техника» и «технология».
3. Показать возможности и примеры использования технологий.
Формы: семинар.
Приемы решения задач:
1. Подготовить презентацию с определениями основных технологий.
2. Предварительное индивидуальное задание ученикам: подготовить доклад и презентацию с характеристикой технологий гипертекста, тезауруса, базы данных, корпуса данных.
3. Обсудить презентации и записать итоговое определение в словарик.
Материалы для урока
Материалы для презентации можно подобрать на сайте http://www.itit.edu.nstu.ru/ (рис. 1). Стоит обратить внимание на рубрики «Компьютерный класс» и «Интернет-ресурсы».
Рис. 1. страница сайта с материалами по использованию Икт в обучении языкам http://www.itit.edu.nstu.ru/
Рис. 1. страница сайта с материалами по использованию Икт в обучении языкам http://www.itit.edu.nstu.ru/
Рекомендуемое домашнее задание
Ознакомиться с тезаурусами, доступными по адресу www.rutenia.ru/folklore/. Подготовить характеристику тезауруса (по выбору).
Второй урок
Тема: Основные ИКТ прикладной русистики: тезаурус
Цель в предметной области: систематизация лексики, определение различий в значениях слов.
Цель в формировании информационно-коммуникационной компетентности: формирование умения использовать тезаурусы.
Задачи:
1. Выбрать лексико-семантические группы для демонстрации возможностей технологии тезауруса (посуда, осветительные приборы, термины родства и т. п.).
2. Определить минимальные противопоставления в значениях выбранных слов.
3. Составить схему тезауруса.
4. Обсудить характеристики тезаурусов, подготовленные учениками.
Формы: семинар. приемы реализации задач:
1. Работа со словарями.
2. Создание схем.
3. Работа на компьютере с сетевыми тезаурусами.
Цель в формировании информационно-коммуникационной компетентности: формирование умения использовать тезаурусы.
Задачи:
1. Выбрать лексико-семантические группы для демонстрации возможностей технологии тезауруса (посуда, осветительные приборы, термины родства и т. п.).
2. Определить минимальные противопоставления в значениях выбранных слов.
3. Составить схему тезауруса.
4. Обсудить характеристики тезаурусов, подготовленные учениками.
Формы: семинар. приемы реализации задач:
1. Работа со словарями.
2. Создание схем.
3. Работа на компьютере с сетевыми тезаурусами.
Материалы для урока
В настоящее время тезаурус – это популярная форма словаря в гуманитарных науках: этнолингвистике, фольклористике, литературоведении. Общую характеристику тезаурусов как одного из обучающих средств можно найти в докладе А.Л. Воскресенского «Новые обучающие средства для новой реальности» на конференции ИТО—2003 по адресу: http://www.ito.edu.ru/main.css/. Л.А. Воскресенский определяет и описывает тезаурусы таким образом: «Тезаурус (от греч. thesauros – сокровище, сокровищница) – множество смысловыражающих единиц языка с заданной на нем системой семантических отношений. Тезаурус фактически определяет семантику языка (национального языка или языка конкретной науки)» [6]. Имеются различные подходы к построению тезауруса. Например, LingvoThesaurus [7] для слова «ниже» дает только два синонима: вниз, внизу, а также три антонима: выше, вверху, вверх. В то же время тезаурус [8], включенный в русскую версию Microsoft ® Word 97 SR—2, для слова «ниже» дает следующий перечень синонимов: гуще, приземистее, низменнее, подлее, далее, а в списке антонимов для этого слова стоят: благороднее, возвышеннее, выше, порядочнее. Этот тезаурус позволяет проходить далее по семантической сети, например, для синонима «гуще» из вышеприведенного примера дается свой ряд синонимов: басистее, басовитее, толще, жирнее. Как видно из приведенного примера, тезаурус [8] позволяет познакомить учащихся и с понятием омонима: слово «ниже» означает в одном случае положение предмета по вертикали относительно другого, в другом – сравнение людей по отрицательным качествам, в третьем – более низкий тон звука. С одной стороны, это полнее раскрывает богатства языка, с другой – для практического пользования этим тезаурусом при редактировании текста нужно знать «семантическое поле» [9] слова, чтобы не использовать синонимический ряд омонима» (там же).
Автор формулирует и основные требования к используемому в учебных целях тезаурусу:
1) раздельное представление синонимов и антонимов для каждого омонима; 2) краткое толкование значений омонимов; 3) использование пояснительных иллюстраций (в том числе анимированных для глаголов); 4) выдача по специальному запросу грамматической информации о данном слове, в том числе список его различных морфологических форм (там же).
Наконец, А.Л. Воскресенский определяет основу для разработки тезаурусов, пригодных к использованию в учебных целях: «В основу тезауруса может быть положена семантическая база данных, например «Абриаль» [10]. Анимированные иллюстрации могут быть созданы в виде VRML-объектов с помощью, например, «Конструктора виртуальных миров» (Internet Space Builder) компании ParallelGraphics. Это дает возможность иллюстрирования значений, например, глаголов «убегать» и «прибегать» с помощью одного графического файла (с поворотом сцены на 180°)» (там же).
Хотя доклад касается прежде всего использования информационных технологий при обучении неслышащих детей, он весьма полезен всем, кто рассчитывает использовать тезаурусные технологии в обучении. Приведем полностью список цитированных А.Л. Воскресенским источников:
1. Кривовяз С.Я., Воскресенский А.Л. Использование информационных технологий и личностно-ориентированного подхода в системе непрерывного образования детей с нарушением слуха // XI Международная конференция-выставка «Информационные технологии в образовании»: Материалы конференции. Ч. V. М.: МИФИ, 2001.
2. Гуленков Г.А. Электронная обучающая система «Русский жестовый язык» // Международная конференция-выставка «Информационные технологии в образовании»: Материалы конференции. Ч. V. М.: МИФИ, 2001.
3. Воскресенский А.Л. «Непризнанный язык» (язык жестов глухих и компьютерная лингвистика) // Труды Международного семинара по компьютерной лингвистике и интеллектуальным технологиям «Диалог—2002». Т. 2. Протвино, 2002.
4. Нариньяни А.С. Проект «ТезауРУС». http://www.dialog—21.ru/. (Раздел «Диалог—2003. Обсуждения и предложения»).
5. Выготский Л.С. Мышление и речь. М., 1996.
6. Большая советская энциклопедия: 30 т. на 3 CD. ЗАО «Новый Диск», 2002.
7. Abbyy Lingvo: Многоязычная версия 8.0 Abbyy Software House, 2002.
8. Тезаурус © Информатик А.О., 1992–1997.
9. Лурия А.Р. язык и сознание. М., 1979.
10. Нариньяни А.С., Пацкин А.И. «Абриаль». http://packin.narod.ru/pro/.
Некоторые полезные тезаурусы представлены в Интернете по адресу http://www.rutenia.ru/folklore/. С содержанием лингвистических понятий можно ознакомиться в «Тезаурусе по теоретической и прикладной лингвистике» С.Е. Никитиной (Никитина 1978). Опыт словарно-тезаурусного описания семантики информационных технологий обсуждается в монографии Ю.Н. Филипповича и А.В. Прохорова (2002).
Автор формулирует и основные требования к используемому в учебных целях тезаурусу:
1) раздельное представление синонимов и антонимов для каждого омонима; 2) краткое толкование значений омонимов; 3) использование пояснительных иллюстраций (в том числе анимированных для глаголов); 4) выдача по специальному запросу грамматической информации о данном слове, в том числе список его различных морфологических форм (там же).
Наконец, А.Л. Воскресенский определяет основу для разработки тезаурусов, пригодных к использованию в учебных целях: «В основу тезауруса может быть положена семантическая база данных, например «Абриаль» [10]. Анимированные иллюстрации могут быть созданы в виде VRML-объектов с помощью, например, «Конструктора виртуальных миров» (Internet Space Builder) компании ParallelGraphics. Это дает возможность иллюстрирования значений, например, глаголов «убегать» и «прибегать» с помощью одного графического файла (с поворотом сцены на 180°)» (там же).
Хотя доклад касается прежде всего использования информационных технологий при обучении неслышащих детей, он весьма полезен всем, кто рассчитывает использовать тезаурусные технологии в обучении. Приведем полностью список цитированных А.Л. Воскресенским источников:
1. Кривовяз С.Я., Воскресенский А.Л. Использование информационных технологий и личностно-ориентированного подхода в системе непрерывного образования детей с нарушением слуха // XI Международная конференция-выставка «Информационные технологии в образовании»: Материалы конференции. Ч. V. М.: МИФИ, 2001.
2. Гуленков Г.А. Электронная обучающая система «Русский жестовый язык» // Международная конференция-выставка «Информационные технологии в образовании»: Материалы конференции. Ч. V. М.: МИФИ, 2001.
3. Воскресенский А.Л. «Непризнанный язык» (язык жестов глухих и компьютерная лингвистика) // Труды Международного семинара по компьютерной лингвистике и интеллектуальным технологиям «Диалог—2002». Т. 2. Протвино, 2002.
4. Нариньяни А.С. Проект «ТезауРУС». http://www.dialog—21.ru/. (Раздел «Диалог—2003. Обсуждения и предложения»).
5. Выготский Л.С. Мышление и речь. М., 1996.
6. Большая советская энциклопедия: 30 т. на 3 CD. ЗАО «Новый Диск», 2002.
7. Abbyy Lingvo: Многоязычная версия 8.0 Abbyy Software House, 2002.
8. Тезаурус © Информатик А.О., 1992–1997.
9. Лурия А.Р. язык и сознание. М., 1979.
10. Нариньяни А.С., Пацкин А.И. «Абриаль». http://packin.narod.ru/pro/.
Некоторые полезные тезаурусы представлены в Интернете по адресу http://www.rutenia.ru/folklore/. С содержанием лингвистических понятий можно ознакомиться в «Тезаурусе по теоретической и прикладной лингвистике» С.Е. Никитиной (Никитина 1978). Опыт словарно-тезаурусного описания семантики информационных технологий обсуждается в монографии Ю.Н. Филипповича и А.В. Прохорова (2002).
Рекомендуемое домашнее задание
Создать тезаурус омонимов (по выбору).
Третий урок
Тема: Основные ИКТ прикладной русистики: база данных
Цель в предметной области: систематизация примеров на различные правила и правил формообразования (образования грамматических форм).
Цель в формировании информационно-коммуникационной компетентности: формирование умения использовать технологию базы данных и работать с программами Microsoft Office (Access и Excel).
Задачи:
1. Охарактеризовать возможности использования базы данных в русистике.
2. Показать основные возможности офисных приложений для обработки языкового материала.
3. Определить базу данных как способ представления сетевого словаря.
Формы: семинар.
Приемы решения поставленных задач:
1. Работа на компьютере (демонстрация возможностей офисных приложений). Показать возможности создания таблиц склонения имен и спряжения глаголов в Excel.
2. Работа со словариком как элементарной базой данных: определение единицы хранения, способа доступа и т. п.
3. Работа с сетевым словарем, организованным по принципу базы данных (см. примеры в пособии для школьников).
4. Демонстрация одной из баз данных, доступных в Интернете; например, база данных интерактивных диктантов на портале www.gramota.ru/. Написать один из диктантов, предлагаемых в базе.
Цель в формировании информационно-коммуникационной компетентности: формирование умения использовать технологию базы данных и работать с программами Microsoft Office (Access и Excel).
Задачи:
1. Охарактеризовать возможности использования базы данных в русистике.
2. Показать основные возможности офисных приложений для обработки языкового материала.
3. Определить базу данных как способ представления сетевого словаря.
Формы: семинар.
Приемы решения поставленных задач:
1. Работа на компьютере (демонстрация возможностей офисных приложений). Показать возможности создания таблиц склонения имен и спряжения глаголов в Excel.
2. Работа со словариком как элементарной базой данных: определение единицы хранения, способа доступа и т. п.
3. Работа с сетевым словарем, организованным по принципу базы данных (см. примеры в пособии для школьников).
4. Демонстрация одной из баз данных, доступных в Интернете; например, база данных интерактивных диктантов на портале www.gramota.ru/. Написать один из диктантов, предлагаемых в базе.
Материалы к уроку
Основные информационно-коммуникационные технологии прикладной русистики
Определим те из ИКТ, которые используются в современной прикладной русистике и в создании которых принимали участие специалисты в области прикладной лингвистики. Естественно, терминология и собственно ИКТ оказываются общими для всех сфер знания. Однако в каждой науке, особенно в науках гуманитарных, обнаруживается определенная специфика применения технологий. В русистике как разделе языкознания ИКТ используются для обработки речевого сигнала и текстов, для хранения и передачи информации, для формирования сетевых ресурсов и обучения. В русистике востребованы такие технологии, как тезаурусное описание, формирование базы данных и корпуса данных. Создание корпусов данных из текстов привело к появлению специфической отрасли науки о языке – корпусной лингвистики. Для обработки баз данных применяют базы знаний и экспертные системы. Экспертные системы, наряду с автоматическими обучающими системами, получают все большее распространение, особенно в дистанционном обучении. Гипертекстовые технологии представления текста также представляют интерес для языкознания. Наконец, технологии обработки звучащей речи и обеспечения устной коммуникации в системах связи органично входят в такую традиционную область науки о языке, как фонетика. Охарактеризуем основные информационно-коммуникационные технологии, представленные в научных публикациях по русистике и полезные для работы в сети Интернет.Тезаурус (от греч. thesaures «сокровище, сокровищница») – 1) словарь, в котором максимально полно представлены все слова языка с исчерпывающим перечнем примеров их употребления в текстах; 2) идеографический словарь, в котором показаны семантические отношения (родовидовые, синонимические и др.) между лексическими единицами. Тезаурус в первом значении в полном объеме осуществим лишь для мертвых языков. Структурной основой для тезауруса во втором значении обычно служит иерархическая система понятий, обеспечивающая поиск от смыслов к лексическим единицам, т. е. поиск слова, исходя из обозначенного им понятия. Тезаурусы обычно издаются как иллюстрированные словари: приводится изображение с пронумерованными по-чертежному деталями, в текстовой части нумерованный список сопровождается названиями (иногда на нескольких языках). Поиск в тезаурусе ведется по иерархическому дереву: от более общего наименования к более частному. Например, чтобы выяснить наименование (или внешний вид) кокошника, необходимо обратится к предметной области «одежда», далее выбрать рубрику «головные уборы».
В тезаурусах преодолевается один из весьма существенных недостатков традиционных словарей. Ведущий отечественный специалист по прикладной лингвистике А.И. Новиков полно охарактеризовал этот недостаток в предисловии к монографии «Семантика информационных технологий» Ю. Филипповича и А. Прохорова: «Традиционный словарный способ представления лексики характеризуется тем, что слова в нем организуются на основе какого-либо формального принципа (например, алфавитное расположение). Вследствие этого и значения, которые задаются в таких словарях в виде дефиниций, также оказываются разобщенными и в явном виде не обнаруживают своей системности. Ее можно установить в результате специальной деятельности, заключающейся в обнаружении некоторых общих компонентов в этих значениях, или других признаках их связности. Иногда сделать это бывает достаточно трудно. Это дает основания считать, что традиционный словарь, являясь инструментом представления лексического состава языка, как правило, не отражает достаточно полно и эксплицитно внутреннюю системность языка. Он может служить материалом для такой системности, для чего требуется специальная деятельность лингвиста и соответствующие методы анализа» (Филиппович, Прохоров 2002: 5–6). Естественно, рядовой носитель языка, а тем более школьник, не владеет специальными методами анализа и не сможет на основе традиционных словарей составить представление о предметной области, выявить меру различия близких понятий и т. п. Эти задачи позволит ему решить тезаурус.
Некоторые полезные тезаурусы представлены в Интернете по адресу http://www.rutenia.ru/folklore/. С содержанием лингвистических понятий можно ознакомиться в «Тезаурусе по теоретической и прикладной лингвистике» С.Е. Никитиной (Никитина 1978). Опыт словарно-тезаурусного описания семантики информационных технологий обсуждается в монографии Ю.Н. Филипповича и А.В. Прохорова (Филиппович, Прохоров 2002).
Задание 1. Найдите определение термина тезаурус в сетевых энциклопедиях Википедия и Кругосвет. Сохраните скриншоты с определениями для итоговой презентации по спецкурсу.
Задание 2. Ознакомьтесь с тезаурусами, доступными по адресу http://www.rutenia.ru/folklore/.
База данных не является понятием собственно прикладной лингвистики. Это понятие общее для всех информационных технологий. База данных – это структурированная совокупность взаимосвязанных данных в рамках некоторой предметной области, предназначенная для длительного хранения во внешней (не оперативной) памяти компьютера и постоянного применения. Тем не менее создание базы данных – ключевая технология компьютерной лексикографии. Современные словари создаются на основе хранимых в памяти компьютера контекстов, для их создания используют программы, позволяющие формальным образом представить морфологические, словообразовательные, синтаксические и даже семантические характеристики слова.
Формирование базы данных начинается с табличного представления сырого материала. В стандартный пакет программного обеспечения Windows входят электронные таблицы Excel, позволяющие организовать материал и производить стандартную статистическую обработку. Однако управлять базой данных в Excel неудобно. Для управления базой данных Microsoft Office предлагает систему управления базой данных Access (СУБД Access). Это сравнительно простая система, позволяющая из исходного материала, введенного в базу данных, формировать множество таблиц по количественным и качественным параметрам, заданным самим пользователем. СУБД Аccess широко используется в лингвистических работах.
Задание 1. Ознакомьтесь с приложением Excel. Используя возможности приложения, попытайтесь составить таблицу образцов склонения русских существительных.
Задание 2. Выберите одну из доступных в Интернет лингвистическую базу данных:
http://www.speech.nw.ru/,
http://www.imli.ru/zagovor/,
www.lingsoft.fi/doc/rustwol.txt.
Подготовьте презентацию о ней.
Рекомендуемое домашнее задание
(Индивидуально) Выбрать одну из доступных в Интернете лингвистическую базу данных: http://www.speech.nw.ru/, www.imli.ru/zagovor/, www.lingsoft.fi/doc/rustwol.txt. Подготовьте презентацию о ней.Составить таблицу формообразования (по выбору) в Excel.
Четвертый урок
Тема: Основные ИКТ прикладной русистики: корпус данных и корпус текстов
Цель в предметной области: знакомство с Национальным корпусом русского языка и другими корпусами, систематизация знаний о лексическом значении слова.
Цель в формировании информационно-коммуникационной компетентности: знакомство с технологией национальных корпусов.
Задачи:
1. Установить основные отличия корпуса данных от базы данных.
2. Определить цели создания национальных корпусов.
3. Определить достоинства представления национального языка в виде корпуса.
4. Определить спектр задач, решаемых на материале Национального корпуса русского языка.
Формы: лекция с обсуждением. приемы реализации задач:
1. Характеристика корпуса текстов с показом мультимедийной презентации.
2. Показать достоинства работы с корпусом текстов в презентации.
3. Продемонстрировать возможности поиска информации в корпусе на компьютере.
4. Индивидуальная работа над материалами из Национального корпуса русского языка.
Цель в формировании информационно-коммуникационной компетентности: знакомство с технологией национальных корпусов.
Задачи:
1. Установить основные отличия корпуса данных от базы данных.
2. Определить цели создания национальных корпусов.
3. Определить достоинства представления национального языка в виде корпуса.
4. Определить спектр задач, решаемых на материале Национального корпуса русского языка.
Формы: лекция с обсуждением. приемы реализации задач:
1. Характеристика корпуса текстов с показом мультимедийной презентации.
2. Показать достоинства работы с корпусом текстов в презентации.
3. Продемонстрировать возможности поиска информации в корпусе на компьютере.
4. Индивидуальная работа над материалами из Национального корпуса русского языка.
Материалы для урока
Корпус данных – особый вид базы данных. В отличие от базы данных, корпус данных претендует на отражение реальной картины, существующей в предметной области. Обычно корпус данных формируется из текстов. По запросу пользователя из корпуса извлекаются материалы. Единица извлечения материала определяется единицей хранения. Если единицей хранения является слово, то на запрос пользователя из корпуса будет извлекаться отдельное слово (как в орфографических словарях); если же единица хранения – словосочетание, то пользователь на запрос о слове получит ближайшие контексты интересующего его слова; при единице хранения предложении «ответом» пользователю будет целое предложение и т. п.
В качестве материалов предлагаем главу о корпусной лингвистике из учебного пособия И.Г. Овчинниковой и И.А. Углановой «Компьютерное моделирование речевой коммуникации» (Пермь 2006). Приведем некоторые выдержки из данного пособия.
Корпусная лингвистика – одна из наиболее востребованных отраслей прикладного языкознания. Бурное развитие корпусной лингвистики обусловлено необходимостью создания ресурсов, обеспечивающих доступ к языковому материалу, качественно обработанному и репрезентативному. Одна из основных прикладных задач, стимулирующих бурное развитие корпусной лингвистики, – обеспечение систем машинного перевода, новое поколение которых использует корпусы текстов на разных языках как базы примеров и аналогий, пригодных для повторного использования при переводе новых документов. Корпусная лингвистика использует программное обеспечение, рассчитанное на обработку естественного языка. В процессе создания корпусов текстов на различных языках совершенствуются программы, позволяющие работать с естественным языком на компьютере (так называемые NLP – natural language processing). Такого рода программы широко используются за пределами корпусной лингвистики и научных исследований.
Корпусы текстов представляют сырой материал для создания и тестирования программ по переработке естественного языка. В данном случае под текстами понимаются и высказывания устной речи как в СМИ, так и в естественной коммуникации (например, соответствующие подкорпусы Британского национального корпуса). В целом все известные корпусы реализуют четыре варианта:
– национальный корпус, в котором представлены тексты из различных сфер коммуникации (монолингвальный корпус);
– сравнительный (или контрастивный) корпус, объединяющий несколько национальных корпусов, организованных аналогично (с совпадающей репрезентативностью и общим корпус-менеджером);
– параллельный корпус, или корпус параллельных текстов, содержащих тексты на одном языке и их переводы на другой язык (или на несколько языков);
– корпус разговорной речи, который может существовать отдельно, а не только в качестве подмассива Национального корпуса. Корпусы разговорной (и шире – устной) речи могут включать только аудиозаписи (в частности, Корпус диалектов английского языка) или, напротив, только транскрипцию или орфографическую запись устной речи (как подмассив Британского национального корпуса). Оптимальным вариантом полагают параллельное размещение в корпусе аудиозаписей и их стенограммы (в транскрипции или орфографии).
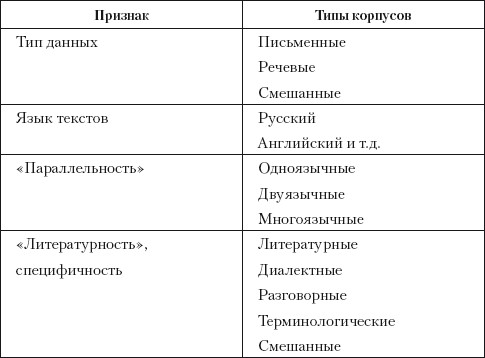
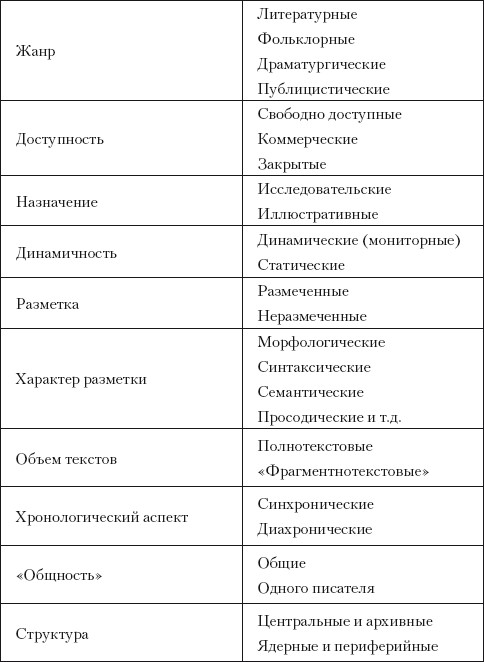
Таблица 1
Классификация корпусов В.П. Захарова
Каждый из вариантов пригоден для решения специфических задач. Например, сравнительный корпус позволяет изучать языки в контрастивном аспекте, в то время как параллельный корпус используется в качестве базы данных (базы примеров перевода) в современных системах машинного перевода. Обращение к нему в процессе контрастивного исследования нецелесообразно, поскольку в параллельных текстах на двух языках отражается неизбежная при переводе межъязыковая интерференция, что может существенным образом исказить результаты сопоставления.
Подробную классификацию корпусов предлагает В.П. Захаров в своем учебном пособии (Захаров 2005: 13). Приведем ее полностью.
Как видим, на основе корпусов можно моделировать любой из аспектов коммуникации. Основным достоинством моделей на основе корпуса является их валидность, достигаемая благодаря огромному количеству языкового материала, представленного в корпусе.
Любой корпус снабжается аннотацией. Предполагается, что аннотирование корпуса представляет собой его лингвистическую характеристику. Обычно такая характеристика включает описание текстов, составляющих корпус, определение единицы хранения, один из возможных вариантов лингвистического анализа. Аннотированный корпус приобретает такие преимущества, как простота использования и многофункциональность. Обычно при аннотировании корпусов сочетают автоматическую и ручную разметку. Автоматическая разметка и автоматическое аннотирование признаются удовлетворительными, если порог ошибки колеблется около 3 %. Некоторые программы работают довольно хорошо.
Вариант практического задания для поиска в корпусе и интерпретации результатов (рекомендуется включить в презентацию и вместе с учениками выполнять по ходу лекции). Зайдите на сайт Национального корпуса русского языка по адресу www.ruscorpora.ru и сделайте запрос о словах шоу и арт, а также о сложных и составных словах, включающих эти компоненты.
Проанализируйте контексты употребления слова шоу и составных слов с – шоу и – арт. Определите значение слова и сферу употребления соответствующих лексических единиц[2].
Результаты поиска
Запрос: арт-шоу
Область поиска: основной корпус (со снятой и неснятой омонимией)
Найдено документов: 28, контекстов: 174
1. Наталья Грушина. Новости // «Рекламный мир», 2000.02.15 [омонимия не снята] Все контексты (5)
ЦДХ, некогда считавшийся оплотом столичного арт-хауза, наконец пал под натиском шоу-бизнеса. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
На ней представлялись в основном фирмы грамзаписи (около половины экспонентов), заводы, производящие аудионосители, торговые фирмы, продюсерские центры и некоторые другие субъекты шоу-бизнеса. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
У выставки «Шоу-бизнес», бесславно прошедшей в мае 1999 года, похоже, появился более достойный и представительный преемник. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
13—16 апреля в СК «Олимпийский» намечается Межрегиональная специализированная выставка индустрии шоу-бизнеса «Professional Show-Biz'2000». [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
Помимо экспонентов, которых, по словам организаторов выставки, будет не в пример больше, чем на «Шоу-бизнесе», за четыре выставочных дня посетители смогут лицезреть ведущих специалистов отрасли – Юрия Айзеншписа, Бориса Краснова, Александра Иратова, Андрея Агапова и других. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
Show must go-go // «Рекламный мир», 2000.02.15 [омонимия не снята] Все контексты (4)
Правда, деятели шоу-бизнеса, блиц-опрошенные РМ, участвовали в рекламе не только русских но и крупных западных компаний. [Show must go-go // «Рекламный мир», 2000.02.15]
Валерия – пожалуй, первая представительница «звездной» лиги шоу-бизнеса, чье изображение появилось на столичных биллбордах («Валерия – певица, которую все ждали») [Show must go-go // «Рекламный мир», 2000.02.15]
Александр Цекало – экс – «академик», начавший вместе с Лолитой Милявской одним из первых в русском шоу-бизнесе активно заниматься рекламой. [Show must go-go // «Рекламный мир», 2000.02.15]
В качестве материалов предлагаем главу о корпусной лингвистике из учебного пособия И.Г. Овчинниковой и И.А. Углановой «Компьютерное моделирование речевой коммуникации» (Пермь 2006). Приведем некоторые выдержки из данного пособия.
Корпусная лингвистика – одна из наиболее востребованных отраслей прикладного языкознания. Бурное развитие корпусной лингвистики обусловлено необходимостью создания ресурсов, обеспечивающих доступ к языковому материалу, качественно обработанному и репрезентативному. Одна из основных прикладных задач, стимулирующих бурное развитие корпусной лингвистики, – обеспечение систем машинного перевода, новое поколение которых использует корпусы текстов на разных языках как базы примеров и аналогий, пригодных для повторного использования при переводе новых документов. Корпусная лингвистика использует программное обеспечение, рассчитанное на обработку естественного языка. В процессе создания корпусов текстов на различных языках совершенствуются программы, позволяющие работать с естественным языком на компьютере (так называемые NLP – natural language processing). Такого рода программы широко используются за пределами корпусной лингвистики и научных исследований.
Корпусы текстов представляют сырой материал для создания и тестирования программ по переработке естественного языка. В данном случае под текстами понимаются и высказывания устной речи как в СМИ, так и в естественной коммуникации (например, соответствующие подкорпусы Британского национального корпуса). В целом все известные корпусы реализуют четыре варианта:
– национальный корпус, в котором представлены тексты из различных сфер коммуникации (монолингвальный корпус);
– сравнительный (или контрастивный) корпус, объединяющий несколько национальных корпусов, организованных аналогично (с совпадающей репрезентативностью и общим корпус-менеджером);
– параллельный корпус, или корпус параллельных текстов, содержащих тексты на одном языке и их переводы на другой язык (или на несколько языков);
– корпус разговорной речи, который может существовать отдельно, а не только в качестве подмассива Национального корпуса. Корпусы разговорной (и шире – устной) речи могут включать только аудиозаписи (в частности, Корпус диалектов английского языка) или, напротив, только транскрипцию или орфографическую запись устной речи (как подмассив Британского национального корпуса). Оптимальным вариантом полагают параллельное размещение в корпусе аудиозаписей и их стенограммы (в транскрипции или орфографии).
Таблица 1
Классификация корпусов В.П. Захарова
Каждый из вариантов пригоден для решения специфических задач. Например, сравнительный корпус позволяет изучать языки в контрастивном аспекте, в то время как параллельный корпус используется в качестве базы данных (базы примеров перевода) в современных системах машинного перевода. Обращение к нему в процессе контрастивного исследования нецелесообразно, поскольку в параллельных текстах на двух языках отражается неизбежная при переводе межъязыковая интерференция, что может существенным образом исказить результаты сопоставления.
Подробную классификацию корпусов предлагает В.П. Захаров в своем учебном пособии (Захаров 2005: 13). Приведем ее полностью.
Как видим, на основе корпусов можно моделировать любой из аспектов коммуникации. Основным достоинством моделей на основе корпуса является их валидность, достигаемая благодаря огромному количеству языкового материала, представленного в корпусе.
Любой корпус снабжается аннотацией. Предполагается, что аннотирование корпуса представляет собой его лингвистическую характеристику. Обычно такая характеристика включает описание текстов, составляющих корпус, определение единицы хранения, один из возможных вариантов лингвистического анализа. Аннотированный корпус приобретает такие преимущества, как простота использования и многофункциональность. Обычно при аннотировании корпусов сочетают автоматическую и ручную разметку. Автоматическая разметка и автоматическое аннотирование признаются удовлетворительными, если порог ошибки колеблется около 3 %. Некоторые программы работают довольно хорошо.
Вариант практического задания для поиска в корпусе и интерпретации результатов (рекомендуется включить в презентацию и вместе с учениками выполнять по ходу лекции). Зайдите на сайт Национального корпуса русского языка по адресу www.ruscorpora.ru и сделайте запрос о словах шоу и арт, а также о сложных и составных словах, включающих эти компоненты.
Проанализируйте контексты употребления слова шоу и составных слов с – шоу и – арт. Определите значение слова и сферу употребления соответствующих лексических единиц[2].
Результаты поиска
Запрос: арт-шоу
Область поиска: основной корпус (со снятой и неснятой омонимией)
Найдено документов: 28, контекстов: 174
1. Наталья Грушина. Новости // «Рекламный мир», 2000.02.15 [омонимия не снята] Все контексты (5)
ЦДХ, некогда считавшийся оплотом столичного арт-хауза, наконец пал под натиском шоу-бизнеса. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
На ней представлялись в основном фирмы грамзаписи (около половины экспонентов), заводы, производящие аудионосители, торговые фирмы, продюсерские центры и некоторые другие субъекты шоу-бизнеса. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
У выставки «Шоу-бизнес», бесславно прошедшей в мае 1999 года, похоже, появился более достойный и представительный преемник. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
13—16 апреля в СК «Олимпийский» намечается Межрегиональная специализированная выставка индустрии шоу-бизнеса «Professional Show-Biz'2000». [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
Помимо экспонентов, которых, по словам организаторов выставки, будет не в пример больше, чем на «Шоу-бизнесе», за четыре выставочных дня посетители смогут лицезреть ведущих специалистов отрасли – Юрия Айзеншписа, Бориса Краснова, Александра Иратова, Андрея Агапова и других. [Наталья Грушина. Новости // «Рекламный мир», 2000.02.15]
Show must go-go // «Рекламный мир», 2000.02.15 [омонимия не снята] Все контексты (4)
Правда, деятели шоу-бизнеса, блиц-опрошенные РМ, участвовали в рекламе не только русских но и крупных западных компаний. [Show must go-go // «Рекламный мир», 2000.02.15]
Валерия – пожалуй, первая представительница «звездной» лиги шоу-бизнеса, чье изображение появилось на столичных биллбордах («Валерия – певица, которую все ждали») [Show must go-go // «Рекламный мир», 2000.02.15]
Александр Цекало – экс – «академик», начавший вместе с Лолитой Милявской одним из первых в русском шоу-бизнесе активно заниматься рекламой. [Show must go-go // «Рекламный мир», 2000.02.15]