Знание и умелое применение некоторых упражнений дают возможность извлекать «ядерное» значение из текста быстро и надежно. Упражнения основаны на использовании дифференциального алгоритма чтения.
Сделаем наше первое «открытие»: что это такое?
Открытие, обсуждаемое здесь, состоит в том, что, оказывается, хорошие читатели читают ради понимания смысла, охватывают с одного взгляда много слов сразу, в то время как плохие читатели читают маленькими кусками, охватывая всего одно, два или три слова за одну остановку (фиксацию) глаз. До тех пор, пока кто-то читает вот этим последним дробным способом, он не преуспеет в увеличении скорости чтения; более «длинные», чем, скажем, в одно предложение, мысли оказываются рассеченными на большое количество маленьких кусков, что затрудняет формирование единого, точного понимания смысла фрагмента текста.
Как мы уже знаем, интегральный алгоритм чтения облегчает поиск нужной информации в тексте в целом. Для каждого отдельного предложения и абзаца подобную программу, конечно, составить нельзя. Однако для активизации чтения нужно заранее знать, что прежде всего следует отыскивать в каждом смысловом отрезке текста. Для этого и разработан дифференциальный алгоритм чтения.
С его помощью можно разбивать каждый формально самостоятельный фрагмент текста на логические отдельные элементы (потому алгоритм и назван дифференциальным). Под отдельным логическим отрезком текста в данном случае мы понимаем каждый смысловой его абзац. Следует помнить, что печатный и смысловой абзацы могут не совпадать. Для облегчения последующей работы рассмотрим каждый из блоков алгоритма отдельно (см. рис. 13).
Ключевые слова несут основную смысловую нагрузку. Они обозначают признак предмета, состояние или действие. К ключевым словам не относятся предлоги, союзы, междометия. Очень редко выступают в этой роли и местоимения, которые лишь замещают уже употребляемое ранее в тексте предметное (ключевое) слово. Очень часто смысловой абзац текста в целом является вспомогательным и вообще не содержит ключевых слов.
Смысловые ряды. Это пары слов, они состоят из комбинаций ключевых слов и некоторых определяющих и дополняющих их вспомогательных слов, которые помогают в сжатом виде понять истинное содержание абзаца. Именно смысловые ряды являются основой «золотого ядра» содержания текста.
Таким образом, при чтении любого текста сознание соединяет ключевые слова в лаконичные, свернутые выражения смысловых рядов, несущие основной замысел автора. Текст как бы мгновенно сжимается, мысленно конспектируется. В нем остаются только зерна мысли, «золотое ядро» на уровне непрерывных цепочек пар слов.
Но это только промежуточный этап. Ключевые слова и смысловые ряды выявляются в самом тексте, который пока претерпевает как бы количественные преобразования — сжимается, прессуется. Однако, кроме количественного анализа, сообщение всегда подвергается и качественному преобразованию. Эта интеллектуальная операция соответствует третьему блоку алгоритма — выявлению доминанты.
Замечено, что содержание прочитанного при пересказе люди почти никогда не излагают слово в слово. Мозг перекодирует воспринятое сообщение в соответствии с собственным опытом, собственной программой. Такое перекодирование происходит уже в самом процессе чтения. Этим как раз и отличается активное, осмысленное восприятие текста от механической зубрежки.
На основе смысловых рядов мозг как бы формулирует сообщение самому себе, придавая ему собственную, наиболее удобную и понятную форму. Таким образом, третий блок алгоритма отражает заключительный процесс перекодирования — выявление ядерного значения содержания текста. Решить эту задачу — значит сформулировать и усвоить действительное значение того, что хотел сказать автор в конкретном отрывке. Выявление истинного значения (доминанты), таким образом, и является основной задачей чтения.
Что же такое доминанта?
Контрольный текст № 4
Во-первых, понятие может быть выражено не только отдельным словом («собака») или словосочетанием («железная дорога»), а, например, предложением или целой группой предложений…
Во-вторых, у очень и очень многих слов, обладающих значением, нельзя найти соответствующего им понятия. Например, местоимения. «Я» — говорящий сейчас человек, взятый как целое, но немыслимо представить себе совокупность «я». Такая вольность допустима только в поэзии. Например, у Андрея Вознесенского: …Во мне, как в спектре, живут семь «я»…
В-третьих, понятие — это то, что о данном предмете может сказать общество. А то, что я, отдельный человек, примысливаю к образу этого предмета, совершенно не обязательно совпадает с понятием. И даже значение слова, которое я использую, гораздо уже понятия. А главное, я, видя лопату, кошку, стол, не обязательно примысливаю к ним все те признаки, которые есть у соответствующих понятий. Значение возникает в моем сознании на основе тех признаков, которые закреплены в понятии, но это далеко не все признаки, — возможно, я знаю не все. Даже и значение слова, которое можно найти в словаре, отличается от понятия: это не то, что люди знают о предмете, а то, что им достаточно знать, чтобы правильно употреблять данное слово и правильно его понимать.
Идут столетия, понятия исчезают, появляются новые, у старых меняется содержание. Сколько всяких приключений претерпело за последние сто лет понятие «свет»! А понятие «атом»? Но все эти изменения совершенно не обязательно отражаются в значении слова. «Мысль никогда не равна прямому значению слов», — говорил Л. С. Выготский. Но она и невозможна без слова.
Понятия бывают различными. Тут и те, которыми мы пользуемся в повседневной жизни — вроде понятия «лопаты», и научные, строго определяемые, логически выдержанные — вроде понятия «галактика». Кстати, одно и то же понятие может выступать и как обыденное, житейское, и как научное. «Собака», например, и житейское понятие, определяемое простейшими способами — «домашнее животное, которое лает», и научное — вид Canis familiaris, принадлежащий семейству собак, отряду хищных, классу млекопитающих.
Научные, как и все другие, понятия невозможны без словесной оболочки, без закрепления в языке, хотя в языке и не полностью отражаются их признаки. С одной стороны, мы в прямом смысле закрепляем в языке достижения нашего познания. С другой — мы можем узнавать новое о предметах, явлениях, процессах действительности благодаря языку, через его посредство.
И вот оказывается, что язык способен выступать и как орудие познания. Мы можем при его помощи получать новые знания из уже имеющихся путем логических умозаключений.
Всякое предложение отражает определенное отношение между предметами или событиями. Это может быть простейшее отношение, которое можно представить себе, не обращаясь к языку: например, «собака лает». Но может быть и сложное отношение, которое без помощи языка представить невозможно: «собака — животное».
Говоря «собака — животное», мы совершенно не обязательно должны иметь перед глазами собаку. В том и сила (и еще одно важное отличие!) интеллектуального акта у человека, что он может быть не связан непосредственно с реальными предметами. Вы, вероятно, читали или слышали о том, как в середине века философы-схоласты пытались решить задачу — сколько чертей умещается на острие иглы? Они, несомненно, производили интеллектуальный акт, однако оперировали с такими «объектами» (чертями), которых не только не имели перед глазами, но и вообще никогда не видели и видеть не могли…
Это совершенно не значит, что наше мышление вообще может протекать в отрыве от реальности.
Время от времени мы вынуждены оглядываться и проверять, насколько наше отвлеченное, абстрактное мышление соответствует действительности. Если не проверять, могут произойти неприятные ошибки.
Что же может быть средством проверки, или, как говорят в науке, критерием истинности мышления? Марксизм считает, что единственный такой критерий — практика. Но рассказ об этом увел бы нас слишком далеко, тем более что о критерии практики нам все равно еще придется говорить. Остановимся только на том, что проверка истинности вовсе не обязательно предполагает непосредственную трудовую деятельность или научный эксперимент: опыт практики учитывается нами и в самом процессе мышления, и формой такого учета являются логические законы мышления. Именно язык и представляет мышлению средства, необходимые для того, чтобы путем логического рассуждения, логических умозаключений проверить старые и получить новые знания.
Леонтьев А. А. Мир человека и мир языка. — М., 1984. — С. 48–49.
БЕСЕДА ПЯТАЯ
Что такое артикуляция?
Речь внешняя и внутренняя
Сделаем наше первое «открытие»: что это такое?
Открытие, обсуждаемое здесь, состоит в том, что, оказывается, хорошие читатели читают ради понимания смысла, охватывают с одного взгляда много слов сразу, в то время как плохие читатели читают маленькими кусками, охватывая всего одно, два или три слова за одну остановку (фиксацию) глаз. До тех пор, пока кто-то читает вот этим последним дробным способом, он не преуспеет в увеличении скорости чтения; более «длинные», чем, скажем, в одно предложение, мысли оказываются рассеченными на большое количество маленьких кусков, что затрудняет формирование единого, точного понимания смысла фрагмента текста.
Как мы уже знаем, интегральный алгоритм чтения облегчает поиск нужной информации в тексте в целом. Для каждого отдельного предложения и абзаца подобную программу, конечно, составить нельзя. Однако для активизации чтения нужно заранее знать, что прежде всего следует отыскивать в каждом смысловом отрезке текста. Для этого и разработан дифференциальный алгоритм чтения.
С его помощью можно разбивать каждый формально самостоятельный фрагмент текста на логические отдельные элементы (потому алгоритм и назван дифференциальным). Под отдельным логическим отрезком текста в данном случае мы понимаем каждый смысловой его абзац. Следует помнить, что печатный и смысловой абзацы могут не совпадать. Для облегчения последующей работы рассмотрим каждый из блоков алгоритма отдельно (см. рис. 13).
Ключевые слова несут основную смысловую нагрузку. Они обозначают признак предмета, состояние или действие. К ключевым словам не относятся предлоги, союзы, междометия. Очень редко выступают в этой роли и местоимения, которые лишь замещают уже употребляемое ранее в тексте предметное (ключевое) слово. Очень часто смысловой абзац текста в целом является вспомогательным и вообще не содержит ключевых слов.
Смысловые ряды. Это пары слов, они состоят из комбинаций ключевых слов и некоторых определяющих и дополняющих их вспомогательных слов, которые помогают в сжатом виде понять истинное содержание абзаца. Именно смысловые ряды являются основой «золотого ядра» содержания текста.
Таким образом, при чтении любого текста сознание соединяет ключевые слова в лаконичные, свернутые выражения смысловых рядов, несущие основной замысел автора. Текст как бы мгновенно сжимается, мысленно конспектируется. В нем остаются только зерна мысли, «золотое ядро» на уровне непрерывных цепочек пар слов.
Но это только промежуточный этап. Ключевые слова и смысловые ряды выявляются в самом тексте, который пока претерпевает как бы количественные преобразования — сжимается, прессуется. Однако, кроме количественного анализа, сообщение всегда подвергается и качественному преобразованию. Эта интеллектуальная операция соответствует третьему блоку алгоритма — выявлению доминанты.
Замечено, что содержание прочитанного при пересказе люди почти никогда не излагают слово в слово. Мозг перекодирует воспринятое сообщение в соответствии с собственным опытом, собственной программой. Такое перекодирование происходит уже в самом процессе чтения. Этим как раз и отличается активное, осмысленное восприятие текста от механической зубрежки.
На основе смысловых рядов мозг как бы формулирует сообщение самому себе, придавая ему собственную, наиболее удобную и понятную форму. Таким образом, третий блок алгоритма отражает заключительный процесс перекодирования — выявление ядерного значения содержания текста. Решить эту задачу — значит сформулировать и усвоить действительное значение того, что хотел сказать автор в конкретном отрывке. Выявление истинного значения (доминанты), таким образом, и является основной задачей чтения.
Что же такое доминанта?
Доминанта — главная смысловая часть текста. Она выражается своими словами, на языке собственных мыслей, является результатом переработки текста, его осмысления в соответствии с индивидуальными особенностями читателя, выявления основного замысла автора. Таким образом, в тексте встречаются слова, которые как бы «подталкивают» вас читать дальше, дальше, предупреждают, что изменений смысла не предвидится. Бывают другие слова, которые «предупреждают» об изменении, «повороте» смысла, «говорят» вам, чтобы вы замедлили скорость чтения, что впереди «крутой поворот». Очень важно знать, как пользоваться такими словами-сигналами.
Блоки алгоритма составляют основу логико-семантического анализа текста, который наш мозг выполняет в процессе чтения в значительной степени подсознательно. Есть основания полагать, что эффективность такого анализа у большинства читателей не всегда высока. В самом деле, знание определенной программы еще не означает умение ею пользоваться. Умение пользоваться определенной программой еще не означает возможность ее применения на уровне автоматизированного, неосознаваемого действия-навыка. Задача заключается в том, чтобы образовать именно навык, т. е. доведенное до автоматизма умение грамотно и глубоко анализировать текст в режиме быстрого чтения. Поэтапное формирование навыка и предполагает детальный разбор каждого уровня мыслительных операций при чтении текста с целью выявления его основного смыслового значения — доминанты. Эту задачу и решает дифференциальный алгоритм чтения. Он предлагает в процессе чтения в соответствии с блоками алгоритма производить логико-семантический анализ текста: вначале выделить ключевые слова, затем построить смысловые ряды и, наконец, выделив цепь значений, сформировать доминанту. Цель такого упражнения — показать мозгу, как правильно надо понимать текст. Именно так, и только так можно увидеть главное, действительно важное, проникнуть в суть вещей, явлений, излагаемых автором. Многократное повторение упражнения формирует новый способ кодирования, обеспечивающий затем высококачественное понимание текста в режиме быстрого чтения.
Теперь потренируемся: проведем медленное чтение текста, размечая его в соответствии с блоками дифференциального алгоритма чтения. Посмотрим на примере, как используется дифференциальный алгоритм.
Наш век не без основания называют веком статистики. Статистика — слово многозначное. Это и набор цифр, полученных определенным образом и характеризующих некоторые явления, и специальная социально-экономическая наука, и научный метод широко применяемый как в общественных, так и в естественных науках.
В журналистской работе ко многим темам без статистики совершенно невозможно подойти. В частности, все, относящееся к вопросам народонаселения, прямо-таки основано на статистике. Относительная редкость статей на демографические темы (при громадном интересе к ним и читателей, и общественной важности этих тем) в немалой мере объясняется статистической малограмотностью многих журналистов. Очень часто смысл цифр читателям непонятен. Один пример. Кто не слышал и неупотреблял слов «средняя продолжительность жизни»? Для подавляющего большинства значение их таково: это средний возраст смерти в данное время. Однако истинный смысл их совсем иной: это средняя продолжительность жизни тех, кто родился в данном году, при условии, что на всем протяжении жизни данного поколения возрастные коэффициенты смертности будут такими же, как и в год рождения. Таким образом, эти величина расчетная и условная. .
В этом отрывке подчеркнуты ключевые слова. Порядок обработки абзацев этого текста по алгоритму показан в табл. 4.
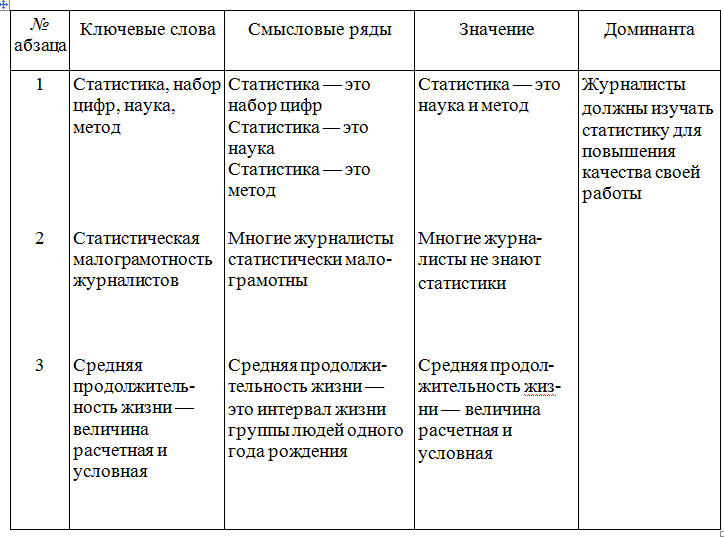 Таблица 4. Разметка текста по блокам дифференциального алгоритма чтения
Таблица 4. Разметка текста по блокам дифференциального алгоритма чтения
Нужно иметь в виду, что, выполняя упражнения в соответствии с блоками дифференциального алгоритма, мы тренируем мыслительные процессы как бы расчлененно — замедленно и по частям. При чтении они, разумеется, протекают иначе — быстро, одновременно и в значительной мере подсознательно. Но чтобы навык такого чтения стал автоматизированным и мгновенным, тренировать его нужно дифференцированно.
Размечая текст по блокам алгоритма, мы с карандашом в руках прочитываем его три раза. При первом чтении подчеркиваем только ключевые слова. Как видно из приведенного выше примера, не все слова текста являются ключевыми, а только те из них, которые будут использованы для последующих построений. Второе чтение используем для построения смысловых рядов: удобно записывать их на отдельном листочке. И наконец, читая текст, а точнее, смысловые ряды, в третий раз формируем значения, из которых складывается затем доминанта. Здесь любопытно провести некоторую аналогию с рекомендациями, которые давали просветители прошлого века для чтения. Так, русский поэт XVIII в. Я. Княжнин советовал: «Читается трояким образом: первое — читать и не понимать; второе — читать и понимать; третье — читать и понимать даже то, что не написано». Формируя доминанту, мы как раз и решаем задачу поиска именно того, что, как говорят, содержится между строк. Иногда говорят: «приценись», прежде чем читать все подряд. Да, именно так, ведь вы присматриваетесь, прицениваетесь, прежде чем купить что-то. Другими словами, предварительно знакомитесь, составляете себе предварительное представление. Тот же самый прием вы применяете к статье или книге, когда ее «покупаете», т. е. собираетесь прочитать. Выполняя упражнения, рекомендуемые ниже, вы убедитесь также, что избыточность текста — вполне реальное, осязаемое явление. Действительно, из всего многообразия слов текста после его графической произвольной разметки в соответствии с алгоритмом остается очень небольшая часть — «сухой остаток», который и составляет основное смысловое содержание.
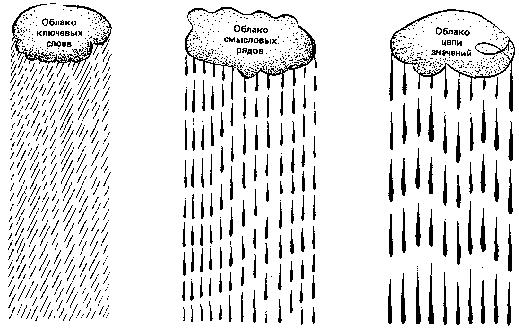 Рис. 14. Пример зрительного дифференциального алгоритма чтения в виде системы облаков
Рис. 14. Пример зрительного дифференциального алгоритма чтения в виде системы облаков
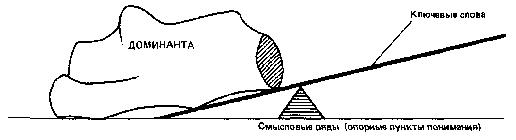 Рис. 15 Зрительный образ дифференциального алгоритма чтения
Рис. 15 Зрительный образ дифференциального алгоритма чтения
Будучи осмыслен читателем, этот «остаток» преобразуется и принимает вид лаконичного выражения — доминанты.
При разработке дифференциального алгоритма мы не предполагали, что может быть дано его зрительное описание. Однако слушатели курсов предложили оригинальное решение зрительного образа алгоритма, что, несомненно, способствует лучшему его пониманию и облегчает его практическое освоение. На рис. 14 алгоритм показан в виде системы облаков. Первые облачка — ключевые слова — разряжаются мелким дождем. Затем они сливаются и образуют облака смысловых рядов, что выражено в крупных каплях, и, наконец, третий образ — туча, которая вмещает в себя все предыдущие облака. Туча значения проливается еще более крупными каплями, а возможно, и градом. Концентрируется смысловая энергия — доминанта текста. На рис. 15 показан еще одни пример зрительного представления алгоритма, который не требует пояснения. Мы рекомендуем вам придумать и изготовить подобные рисунки самостоятельно.
Настоящее овладение дифференциальным алгоритмом наступает тогда, когда процесс автоматизирован, т. е. действие не осознается, осмысление текста происходит как бы само собой. Вот впечатление одного из слушателей курсов быстрого чтения: «Слова бегут, словно титры в кино, и понять суть удается иногда как-то вдруг, зацепившись за какое-то ключевое слово. Потом еще такое же слово, и наконец чувствую, что понимаю главное, и значит, многие пустые слова, которые вижу, можно без потерь пропустить… Когда текст бывает очень интересным, чувствую, что отключаюсь от внешнего мира и тут поразительно быстро читаю, все понимаю, запоминаю, и все это сопровождается яркими зрительными образами, картинами. Сущность содержания текста, его смысл и значение выступают тогда ярко и выпукло. Как бы говоришь себе: вот в чем тут дело, это главное, ради чего читал, трудился, тратил время».
Дифференциальный алгоритм чтения, определяющий процессы понимания текста, является важнейшим среди приемов техники быстрого чтения. Понять текст — значит не только усвоить его содержание, но и запомнить его.
В начале беседы, как вы помните, мы приводили притчу из памятника древности «Калила и Димна». Рассказ о важности понимания текста мы заканчиваем его продолжением, где еще раз с других позиций обсуждается важность этой проблемы: «…Надлежит и читателю этой книги внимательно устремлять взор в нее, чтобы не оказаться подобным одному рыбаку, который был у какого-то залива. Однажды он находился в воде за ловлей, как вдруг заметил раковину и вообразил, что это нечто. Он кинул сеть, которая захватила рыбу. бывшую недалеко, выпустил ее и сам бросился в воду, чтобы достать раковину. Когда же он ее вытащил, то увидел, что была пустой, а не такой, как он думал. И он раскаялся тогда, что оставил находившееся в руках, и горевал о том, чего лишился. На другой день он отошел от этого места и забросил сеть, он поймал маленькую рыбу и старался ее захватить. Опять он увидел дорогую раковину, но даже не повернулся к ней, плохо о ней подумал и оставил ее. По этому месту проходил другой рыбак, нашел ее и взял. Он обнаружил в ней жемчужину, которая стоила больших денег. Первый очень огорчился и до крайности раскаялся в том, что оставил такую ценную раковину.
Таковы глупцы, которые пренебрегают размышлением… не останавливаясь над тайнами ее смысла и хватаясь за внешность вместо содержания». Тренировочный комплекс этой беседы включает три упражнения: первое развивает зрительный образ алгоритма, второе — смысловую догадку, явление, которое мы уже обсуждали ранее и получившее название антиципации (предвосхищения), третье предполагает медленное чтение с одновременной графической разметкой текста в соответствии с блоками дифференциального алгоритма чтения.
Упражнение 4.1. Зрительный образ дифференциального алгоритма чтения
Изготовить рисунок алгоритма по образцам рис. 14 и 15 в двух экземплярах. Один из них укрепить на экране мысленного взора, другой постоянно носить с собой или укрепить перед рабочим столом.
Осознать смысл и содержание каждого блока алгоритма.
Хорошо представлять себе, что такое ключевое слово, смысловой ряд, доминанта.
Упражнение 4.2. Развитие смысловой догадки (антиципации)
1. В статье объемом не более 6 тыс. знаков зачернить слова в начале и в конце каждого предложения. Затем прочитать статью, пытаясь вставить пропущенные слова по смыслу.
Упражнение выполняют двое учащихся, причем каждый читает текст, подготовленный другим.
2. Читать страницу книги, закрыв последние пять букв всех строчек текста листом бумаги или линейкой. Затем закрыть начальные пять букв всех строчек и, наконец, первые и последние пять букв строчек текста, стараясь угадать закрытые части по смыслу.
Упражнение 4.3. Дифференциальный алгоритм чтения
1. В тексте объемом не более 6 тыс. знаков сделать графическую разметку каждого абзаца в соответствии с алгоритмом. Затем прочитать размеченный текст. При чтении обращать внимание только на ключевые слова.
2. Выполнить разметку еще одного текста и затем прочитать его, стараясь выделить и записать только доминанту.
3. Прочитать контрольный текст № 4. Старайтесь читать этот текст как можно быстрее, без регрессий, находя в тексте ответы на вопросы, поставленные в блоках интегрального алгоритма чтения.
Не забудьте отметить время, которое вы затратили на чтение текста, и определить свой коэффициент понимания, ответить на вопросы, указанные в приложении № 5.
Особое внимание обратите на формирование доминанты.
Подсчитайте скорость чтения по известной вам формуле и запишите ее в своем плане и на графике.
Блоки алгоритма составляют основу логико-семантического анализа текста, который наш мозг выполняет в процессе чтения в значительной степени подсознательно. Есть основания полагать, что эффективность такого анализа у большинства читателей не всегда высока. В самом деле, знание определенной программы еще не означает умение ею пользоваться. Умение пользоваться определенной программой еще не означает возможность ее применения на уровне автоматизированного, неосознаваемого действия-навыка. Задача заключается в том, чтобы образовать именно навык, т. е. доведенное до автоматизма умение грамотно и глубоко анализировать текст в режиме быстрого чтения. Поэтапное формирование навыка и предполагает детальный разбор каждого уровня мыслительных операций при чтении текста с целью выявления его основного смыслового значения — доминанты. Эту задачу и решает дифференциальный алгоритм чтения. Он предлагает в процессе чтения в соответствии с блоками алгоритма производить логико-семантический анализ текста: вначале выделить ключевые слова, затем построить смысловые ряды и, наконец, выделив цепь значений, сформировать доминанту. Цель такого упражнения — показать мозгу, как правильно надо понимать текст. Именно так, и только так можно увидеть главное, действительно важное, проникнуть в суть вещей, явлений, излагаемых автором. Многократное повторение упражнения формирует новый способ кодирования, обеспечивающий затем высококачественное понимание текста в режиме быстрого чтения.
Теперь потренируемся: проведем медленное чтение текста, размечая его в соответствии с блоками дифференциального алгоритма чтения. Посмотрим на примере, как используется дифференциальный алгоритм.
Наш век не без основания называют веком статистики. Статистика — слово многозначное. Это и набор цифр, полученных определенным образом и характеризующих некоторые явления, и специальная социально-экономическая наука, и научный метод широко применяемый как в общественных, так и в естественных науках.
В журналистской работе ко многим темам без статистики совершенно невозможно подойти. В частности, все, относящееся к вопросам народонаселения, прямо-таки основано на статистике. Относительная редкость статей на демографические темы (при громадном интересе к ним и читателей, и общественной важности этих тем) в немалой мере объясняется статистической малограмотностью многих журналистов. Очень часто смысл цифр читателям непонятен. Один пример. Кто не слышал и неупотреблял слов «средняя продолжительность жизни»? Для подавляющего большинства значение их таково: это средний возраст смерти в данное время. Однако истинный смысл их совсем иной: это средняя продолжительность жизни тех, кто родился в данном году, при условии, что на всем протяжении жизни данного поколения возрастные коэффициенты смертности будут такими же, как и в год рождения. Таким образом, эти величина расчетная и условная. .
В этом отрывке подчеркнуты ключевые слова. Порядок обработки абзацев этого текста по алгоритму показан в табл. 4.
Нужно иметь в виду, что, выполняя упражнения в соответствии с блоками дифференциального алгоритма, мы тренируем мыслительные процессы как бы расчлененно — замедленно и по частям. При чтении они, разумеется, протекают иначе — быстро, одновременно и в значительной мере подсознательно. Но чтобы навык такого чтения стал автоматизированным и мгновенным, тренировать его нужно дифференцированно.
Размечая текст по блокам алгоритма, мы с карандашом в руках прочитываем его три раза. При первом чтении подчеркиваем только ключевые слова. Как видно из приведенного выше примера, не все слова текста являются ключевыми, а только те из них, которые будут использованы для последующих построений. Второе чтение используем для построения смысловых рядов: удобно записывать их на отдельном листочке. И наконец, читая текст, а точнее, смысловые ряды, в третий раз формируем значения, из которых складывается затем доминанта. Здесь любопытно провести некоторую аналогию с рекомендациями, которые давали просветители прошлого века для чтения. Так, русский поэт XVIII в. Я. Княжнин советовал: «Читается трояким образом: первое — читать и не понимать; второе — читать и понимать; третье — читать и понимать даже то, что не написано». Формируя доминанту, мы как раз и решаем задачу поиска именно того, что, как говорят, содержится между строк. Иногда говорят: «приценись», прежде чем читать все подряд. Да, именно так, ведь вы присматриваетесь, прицениваетесь, прежде чем купить что-то. Другими словами, предварительно знакомитесь, составляете себе предварительное представление. Тот же самый прием вы применяете к статье или книге, когда ее «покупаете», т. е. собираетесь прочитать. Выполняя упражнения, рекомендуемые ниже, вы убедитесь также, что избыточность текста — вполне реальное, осязаемое явление. Действительно, из всего многообразия слов текста после его графической произвольной разметки в соответствии с алгоритмом остается очень небольшая часть — «сухой остаток», который и составляет основное смысловое содержание.
Будучи осмыслен читателем, этот «остаток» преобразуется и принимает вид лаконичного выражения — доминанты.
При разработке дифференциального алгоритма мы не предполагали, что может быть дано его зрительное описание. Однако слушатели курсов предложили оригинальное решение зрительного образа алгоритма, что, несомненно, способствует лучшему его пониманию и облегчает его практическое освоение. На рис. 14 алгоритм показан в виде системы облаков. Первые облачка — ключевые слова — разряжаются мелким дождем. Затем они сливаются и образуют облака смысловых рядов, что выражено в крупных каплях, и, наконец, третий образ — туча, которая вмещает в себя все предыдущие облака. Туча значения проливается еще более крупными каплями, а возможно, и градом. Концентрируется смысловая энергия — доминанта текста. На рис. 15 показан еще одни пример зрительного представления алгоритма, который не требует пояснения. Мы рекомендуем вам придумать и изготовить подобные рисунки самостоятельно.
Настоящее овладение дифференциальным алгоритмом наступает тогда, когда процесс автоматизирован, т. е. действие не осознается, осмысление текста происходит как бы само собой. Вот впечатление одного из слушателей курсов быстрого чтения: «Слова бегут, словно титры в кино, и понять суть удается иногда как-то вдруг, зацепившись за какое-то ключевое слово. Потом еще такое же слово, и наконец чувствую, что понимаю главное, и значит, многие пустые слова, которые вижу, можно без потерь пропустить… Когда текст бывает очень интересным, чувствую, что отключаюсь от внешнего мира и тут поразительно быстро читаю, все понимаю, запоминаю, и все это сопровождается яркими зрительными образами, картинами. Сущность содержания текста, его смысл и значение выступают тогда ярко и выпукло. Как бы говоришь себе: вот в чем тут дело, это главное, ради чего читал, трудился, тратил время».
Дифференциальный алгоритм чтения, определяющий процессы понимания текста, является важнейшим среди приемов техники быстрого чтения. Понять текст — значит не только усвоить его содержание, но и запомнить его.
В начале беседы, как вы помните, мы приводили притчу из памятника древности «Калила и Димна». Рассказ о важности понимания текста мы заканчиваем его продолжением, где еще раз с других позиций обсуждается важность этой проблемы: «…Надлежит и читателю этой книги внимательно устремлять взор в нее, чтобы не оказаться подобным одному рыбаку, который был у какого-то залива. Однажды он находился в воде за ловлей, как вдруг заметил раковину и вообразил, что это нечто. Он кинул сеть, которая захватила рыбу. бывшую недалеко, выпустил ее и сам бросился в воду, чтобы достать раковину. Когда же он ее вытащил, то увидел, что была пустой, а не такой, как он думал. И он раскаялся тогда, что оставил находившееся в руках, и горевал о том, чего лишился. На другой день он отошел от этого места и забросил сеть, он поймал маленькую рыбу и старался ее захватить. Опять он увидел дорогую раковину, но даже не повернулся к ней, плохо о ней подумал и оставил ее. По этому месту проходил другой рыбак, нашел ее и взял. Он обнаружил в ней жемчужину, которая стоила больших денег. Первый очень огорчился и до крайности раскаялся в том, что оставил такую ценную раковину.
Таковы глупцы, которые пренебрегают размышлением… не останавливаясь над тайнами ее смысла и хватаясь за внешность вместо содержания». Тренировочный комплекс этой беседы включает три упражнения: первое развивает зрительный образ алгоритма, второе — смысловую догадку, явление, которое мы уже обсуждали ранее и получившее название антиципации (предвосхищения), третье предполагает медленное чтение с одновременной графической разметкой текста в соответствии с блоками дифференциального алгоритма чтения.
Упражнение 4.1. Зрительный образ дифференциального алгоритма чтения
Изготовить рисунок алгоритма по образцам рис. 14 и 15 в двух экземплярах. Один из них укрепить на экране мысленного взора, другой постоянно носить с собой или укрепить перед рабочим столом.
Осознать смысл и содержание каждого блока алгоритма.
Хорошо представлять себе, что такое ключевое слово, смысловой ряд, доминанта.
Упражнение 4.2. Развитие смысловой догадки (антиципации)
1. В статье объемом не более 6 тыс. знаков зачернить слова в начале и в конце каждого предложения. Затем прочитать статью, пытаясь вставить пропущенные слова по смыслу.
Упражнение выполняют двое учащихся, причем каждый читает текст, подготовленный другим.
2. Читать страницу книги, закрыв последние пять букв всех строчек текста листом бумаги или линейкой. Затем закрыть начальные пять букв всех строчек и, наконец, первые и последние пять букв строчек текста, стараясь угадать закрытые части по смыслу.
Упражнение 4.3. Дифференциальный алгоритм чтения
1. В тексте объемом не более 6 тыс. знаков сделать графическую разметку каждого абзаца в соответствии с алгоритмом. Затем прочитать размеченный текст. При чтении обращать внимание только на ключевые слова.
2. Выполнить разметку еще одного текста и затем прочитать его, стараясь выделить и записать только доминанту.
3. Прочитать контрольный текст № 4. Старайтесь читать этот текст как можно быстрее, без регрессий, находя в тексте ответы на вопросы, поставленные в блоках интегрального алгоритма чтения.
Не забудьте отметить время, которое вы затратили на чтение текста, и определить свой коэффициент понимания, ответить на вопросы, указанные в приложении № 5.
Особое внимание обратите на формирование доминанты.
Подсчитайте скорость чтения по известной вам формуле и запишите ее в своем плане и на графике.
Контрольный текст № 4
Объем 4500 знаков
СЛОВО — СТУПЕНЬКА К МЫСЛИ
Понятия собаки и лопаты закреплены в определенных словах — «собака», «лопата». Но совершенно не обязательно и было бы очень серьезной ошибкой отождествлять (как это иногда делается) понятие и значение слова.Во-первых, понятие может быть выражено не только отдельным словом («собака») или словосочетанием («железная дорога»), а, например, предложением или целой группой предложений…
Во-вторых, у очень и очень многих слов, обладающих значением, нельзя найти соответствующего им понятия. Например, местоимения. «Я» — говорящий сейчас человек, взятый как целое, но немыслимо представить себе совокупность «я». Такая вольность допустима только в поэзии. Например, у Андрея Вознесенского: …Во мне, как в спектре, живут семь «я»…
В-третьих, понятие — это то, что о данном предмете может сказать общество. А то, что я, отдельный человек, примысливаю к образу этого предмета, совершенно не обязательно совпадает с понятием. И даже значение слова, которое я использую, гораздо уже понятия. А главное, я, видя лопату, кошку, стол, не обязательно примысливаю к ним все те признаки, которые есть у соответствующих понятий. Значение возникает в моем сознании на основе тех признаков, которые закреплены в понятии, но это далеко не все признаки, — возможно, я знаю не все. Даже и значение слова, которое можно найти в словаре, отличается от понятия: это не то, что люди знают о предмете, а то, что им достаточно знать, чтобы правильно употреблять данное слово и правильно его понимать.
Идут столетия, понятия исчезают, появляются новые, у старых меняется содержание. Сколько всяких приключений претерпело за последние сто лет понятие «свет»! А понятие «атом»? Но все эти изменения совершенно не обязательно отражаются в значении слова. «Мысль никогда не равна прямому значению слов», — говорил Л. С. Выготский. Но она и невозможна без слова.
Понятия бывают различными. Тут и те, которыми мы пользуемся в повседневной жизни — вроде понятия «лопаты», и научные, строго определяемые, логически выдержанные — вроде понятия «галактика». Кстати, одно и то же понятие может выступать и как обыденное, житейское, и как научное. «Собака», например, и житейское понятие, определяемое простейшими способами — «домашнее животное, которое лает», и научное — вид Canis familiaris, принадлежащий семейству собак, отряду хищных, классу млекопитающих.
Научные, как и все другие, понятия невозможны без словесной оболочки, без закрепления в языке, хотя в языке и не полностью отражаются их признаки. С одной стороны, мы в прямом смысле закрепляем в языке достижения нашего познания. С другой — мы можем узнавать новое о предметах, явлениях, процессах действительности благодаря языку, через его посредство.
И вот оказывается, что язык способен выступать и как орудие познания. Мы можем при его помощи получать новые знания из уже имеющихся путем логических умозаключений.
Всякое предложение отражает определенное отношение между предметами или событиями. Это может быть простейшее отношение, которое можно представить себе, не обращаясь к языку: например, «собака лает». Но может быть и сложное отношение, которое без помощи языка представить невозможно: «собака — животное».
Говоря «собака — животное», мы совершенно не обязательно должны иметь перед глазами собаку. В том и сила (и еще одно важное отличие!) интеллектуального акта у человека, что он может быть не связан непосредственно с реальными предметами. Вы, вероятно, читали или слышали о том, как в середине века философы-схоласты пытались решить задачу — сколько чертей умещается на острие иглы? Они, несомненно, производили интеллектуальный акт, однако оперировали с такими «объектами» (чертями), которых не только не имели перед глазами, но и вообще никогда не видели и видеть не могли…
Это совершенно не значит, что наше мышление вообще может протекать в отрыве от реальности.
Время от времени мы вынуждены оглядываться и проверять, насколько наше отвлеченное, абстрактное мышление соответствует действительности. Если не проверять, могут произойти неприятные ошибки.
Что же может быть средством проверки, или, как говорят в науке, критерием истинности мышления? Марксизм считает, что единственный такой критерий — практика. Но рассказ об этом увел бы нас слишком далеко, тем более что о критерии практики нам все равно еще придется говорить. Остановимся только на том, что проверка истинности вовсе не обязательно предполагает непосредственную трудовую деятельность или научный эксперимент: опыт практики учитывается нами и в самом процессе мышления, и формой такого учета являются логические законы мышления. Именно язык и представляет мышлению средства, необходимые для того, чтобы путем логического рассуждения, логических умозаключений проверить старые и получить новые знания.
Леонтьев А. А. Мир человека и мир языка. — М., 1984. — С. 48–49.
БЕСЕДА ПЯТАЯ
АРТИКУЛЯЦИЯ И ЧТЕНИЕ
Что такое артикуляция?
Исследования Н. И. Жинкина показали, что чтение, по существу, два одновременных процесса — приема и выдачи речи. Это означает, что при чтении письменную речь (текст) человек принимает и перерабатывает. По окончании чтения читатель формирует свое представление о прочитанном: как бы выдает результат обработки текста, в которой непременно принимают участие речевые процессы. Именно от того, как они организованы, зависит скорость чтения.
Возможны три основных способа чтения. Первый способ — артикуляция, или проговаривание вслух (или почти вслух) того, что читаешь. Скорость такого чтения невелика. Второй способ — чтение про себя, при котором речевой процесс проявлен в форме внутренней речи, т. е. без открытой артикуляции. Текст при этом усваивается более эффективно. Способ в принципе допускает быстрое чтение. И наиболее совершенный способ чтения — тоже молча, но в условиях максимального сжатия внутренней речи, при котором она проявлена в виде коротких залпов ключевых слов и смысловых рядов, адекватно отражающих смысл текста.
Итак, артикуляция замедляет процесс чтения и от нее необходимо избавиться. Однако не приведет ли сокращение артикуляции при повышении скорости чтения к снижению качества восприятия и осмысления получаемой информации?
Как показали исследования психологов, иногда при чтении слова могут быть заменены наглядными зрительными представлениями, пространственными схемами, целые группы слов — одним словом.
Быстро читающие люди обладают способностью, не проговаривая читаемый текст, сразу улавливать и фиксировать замысел автора, а затем усваивать его на уровне внутренней речи. В этом случае, несмотря на высокую скорость чтения, происходит глубокое понимание и усвоение прочитанного, так как основная идея понятна с самого начала. Задачу научиться такому чтению можно решить в два этапа. Первый предполагает сокращение артикуляции, если она ярко выражена, второй — овладение приемами чтения, при которых текст воспринимается крупными информативными блоками.
Как известно, людей по способу восприятия и переработки информации делят на два типа: зрительный и слуховой. Люди зрительного типа при чтении используют код наглядных образов, тогда как люди слухового типа применяют менее производительный код речедвижений. Наблюдения за людьми, читающими быстро, показывают, что они, как правило, относятся к зрительному типу. Вот, например, как описывает О. Бальзак процесс быстрого чтения: «Впитывание мысли в процессе чтения достигло у него способности феноменальной. Взгляд его охватывал семь-восемь строчек сразу, и разум постигал смысл со скоростью, соответствующей скорости глаз. Часто одно-единственное слово позволяло ему усвоить смысл целой фразы».
Направленным обучением можно практически любого здорового человека научить в процессе чтения использовать код наглядных зрительных образов при соответствующем сокращении артикуляции.
Возможны три основных способа чтения. Первый способ — артикуляция, или проговаривание вслух (или почти вслух) того, что читаешь. Скорость такого чтения невелика. Второй способ — чтение про себя, при котором речевой процесс проявлен в форме внутренней речи, т. е. без открытой артикуляции. Текст при этом усваивается более эффективно. Способ в принципе допускает быстрое чтение. И наиболее совершенный способ чтения — тоже молча, но в условиях максимального сжатия внутренней речи, при котором она проявлена в виде коротких залпов ключевых слов и смысловых рядов, адекватно отражающих смысл текста.
Итак, артикуляция замедляет процесс чтения и от нее необходимо избавиться. Однако не приведет ли сокращение артикуляции при повышении скорости чтения к снижению качества восприятия и осмысления получаемой информации?
Как показали исследования психологов, иногда при чтении слова могут быть заменены наглядными зрительными представлениями, пространственными схемами, целые группы слов — одним словом.
Быстро читающие люди обладают способностью, не проговаривая читаемый текст, сразу улавливать и фиксировать замысел автора, а затем усваивать его на уровне внутренней речи. В этом случае, несмотря на высокую скорость чтения, происходит глубокое понимание и усвоение прочитанного, так как основная идея понятна с самого начала. Задачу научиться такому чтению можно решить в два этапа. Первый предполагает сокращение артикуляции, если она ярко выражена, второй — овладение приемами чтения, при которых текст воспринимается крупными информативными блоками.
Как известно, людей по способу восприятия и переработки информации делят на два типа: зрительный и слуховой. Люди зрительного типа при чтении используют код наглядных образов, тогда как люди слухового типа применяют менее производительный код речедвижений. Наблюдения за людьми, читающими быстро, показывают, что они, как правило, относятся к зрительному типу. Вот, например, как описывает О. Бальзак процесс быстрого чтения: «Впитывание мысли в процессе чтения достигло у него способности феноменальной. Взгляд его охватывал семь-восемь строчек сразу, и разум постигал смысл со скоростью, соответствующей скорости глаз. Часто одно-единственное слово позволяло ему усвоить смысл целой фразы».
Направленным обучением можно практически любого здорового человека научить в процессе чтения использовать код наглядных зрительных образов при соответствующем сокращении артикуляции.
Речь внешняя и внутренняя
Из различных методов сокращения артикуляции наиболее эффективным является метод центральных речевых помех, или метод аритмического постукивания. Этот метод разработан Н. И. Жинкиным и использован им при исследовании закономерностей внутренней речи. Понятие внутренней речи для нас очень важно, поэтому давайте разберемся более подробно с тем, что же такое внутренняя речь. А. А. Леонтьев считает, что «внутренняя речь — это речь, которая обслуживает только мышление и не служит, как другие виды речи, целям общения. Классический пример внутренней речи можно встретить в. любом классе любой школы в тот момент, когда учитель открывает журнал:
чтобы начать опрос. Он говорит в раздумьи (обычно про себя, но иногда вслух): «Александрова я уже спрашивал вчера… Белова только что пришла после болезни… Васильева спрошу в следующий раз…»
«Обычно про себя, а иногда и вслух», — сказали мы. Вы, вероятно, тоже припомните случаи, когда, решая сложную мыслительную задачу, и вы начинали рассуждать вслух. Кстати (в подтверждение теории умственных действий), маленький ребенок совершенно не умеет рассуждать про себя: всякое рассуждение он старается производить во всеуслышание, чем иногда крайне смущает взрослых. Внутренняя речь всегда развивается из речи внешней. Многие психологи думают даже, что внутренняя речь — это скрытая форма внешней речи, т. е. что мозг продолжает подавать необходимые сигналы в губы, гортань и другие органы речи, но эти сигналы слишком слабы, чтобы заставить язык произносить слова. Н. И. Жинкин доказал, что чаще всего внутренняя речь вообще перестает быть речью: мы начинаем оперировать не речевыми единицами — звуками, словами, предложениями, а зрительными образами, обобщенными схемами и т. д. Доказывается это очень простым способом, с помощью ритмического постукивания. Суть в том, что внешняя речь развертывается во времени: слова произносятся последовательно, одно за другим, на каждое тратится доля секунды, различная доля, в зависимости от длины слова. Так вот, когда человек говорит вслух, ему трудно монотонно постукивать, он сбивается с ритма. Когда человек читает, он тоже мысленно произносит слова и тоже сбивается. Но в большинстве случаев постукивание не мешает и само тоже не нарушается: значит, внутренняя речь не развертывается во времени, как внешняя. Иначе говоря, речь как бы растворяется в мышлении человека, порождая в нем, правда, то, чего раньше не было, — образы и схемы. Происходит процесс формирования новой системы перекодирования. Эта система обеспечивает при чтении текста его полноценное понимание уже не за счет проговаривания и внутреннего прослушивания каждого слова, а принципиально иным способом, основанным на использовании ярких наглядных образов.
чтобы начать опрос. Он говорит в раздумьи (обычно про себя, но иногда вслух): «Александрова я уже спрашивал вчера… Белова только что пришла после болезни… Васильева спрошу в следующий раз…»
«Обычно про себя, а иногда и вслух», — сказали мы. Вы, вероятно, тоже припомните случаи, когда, решая сложную мыслительную задачу, и вы начинали рассуждать вслух. Кстати (в подтверждение теории умственных действий), маленький ребенок совершенно не умеет рассуждать про себя: всякое рассуждение он старается производить во всеуслышание, чем иногда крайне смущает взрослых. Внутренняя речь всегда развивается из речи внешней. Многие психологи думают даже, что внутренняя речь — это скрытая форма внешней речи, т. е. что мозг продолжает подавать необходимые сигналы в губы, гортань и другие органы речи, но эти сигналы слишком слабы, чтобы заставить язык произносить слова. Н. И. Жинкин доказал, что чаще всего внутренняя речь вообще перестает быть речью: мы начинаем оперировать не речевыми единицами — звуками, словами, предложениями, а зрительными образами, обобщенными схемами и т. д. Доказывается это очень простым способом, с помощью ритмического постукивания. Суть в том, что внешняя речь развертывается во времени: слова произносятся последовательно, одно за другим, на каждое тратится доля секунды, различная доля, в зависимости от длины слова. Так вот, когда человек говорит вслух, ему трудно монотонно постукивать, он сбивается с ритма. Когда человек читает, он тоже мысленно произносит слова и тоже сбивается. Но в большинстве случаев постукивание не мешает и само тоже не нарушается: значит, внутренняя речь не развертывается во времени, как внешняя. Иначе говоря, речь как бы растворяется в мышлении человека, порождая в нем, правда, то, чего раньше не было, — образы и схемы. Происходит процесс формирования новой системы перекодирования. Эта система обеспечивает при чтении текста его полноценное понимание уже не за счет проговаривания и внутреннего прослушивания каждого слова, а принципиально иным способом, основанным на использовании ярких наглядных образов.