Страница:
Разработчики программных систем тоже получили этот урок, но, похоже, до сих пор его не усвоили. В одном проекте за другим разрабатывают ряд алгоритмов и затем начинают создавать поставляемое клиенту программное обеспечение по графику, требующему поставки первой же сборки.
В большинстве проектов первой построенной системой с трудом можно пользоваться. Она может быть слишком медленной, слишком большой, неудобной в использовании, а то и все вместе. Не остается другой альтернативы, кроме как, поумнев, начать сначала и построить перепроектированную программу, в которой эти проблемы решены. Браковка и перепроектирование могут делаться для всей системы сразу или по частям. Но весь опыт разработки больших систем показывает, что будет сделано. [2] В тех случаях, когда используются новые системные концепции и новые технологии, приходится создавать систему на выброс, поскольку даже самое лучшее планирование не столь всеведуще, чтобы попасть в цель с первого раза.
Поэтому проблема не в том, создавать или нет опытную систему, которую придется выбросить. Вы все равно это сделаете. Вопрос единственно в том, планировать ли заранее разработку системы на выброс или обещать клиентам поставку системы, которую придется выбросить. Если смотреть под этим углом, ответ становится намного проще. Поставка хлама клиенту позволяет выиграть время, но происходит это ценой мучений пользователя, отвлечений разработчиков во время перепроектирования и дурной репутации продукта, которую даже самой удачно перепроектированной программе будет трудно победить.
Поэтому планируйте выбросить первую версию — вам все равно придется это сделать.
Постоянны только изменения
После уяснения того, что опытную систему нужно создавать, а потом выбросить, и что перепроектирование с новыми идеями неизбежно, полезно обратиться лицом к изменению как явлению природы. Первый шаг — признание того, что изменение — это образ жизни, а не постороннее и досадное исключение. Косгроув мудро указал, что программист поставляет удовлетворение потребности пользователя, а не какой-то осязаемый продукт. И в то время как программы создаются, тестируются и используются, меняются как фактические потребности пользователя, так и понимание им своих потребностей. [3]
Конечно, это справедливо и в отношении потребностей, удовлетворяемых физическими продуктами, будь то автомобили или компьютеры. Но само существование осязаемого продукта определяет запросы пользователя и их квантование. Податливость и неосязаемость программного продукта побуждают его создателей к бесконечному изменению требований.
Я далек от того, чтобы считать, будто все изменения целей и требований клиента можно или необходимо учитывать в проекте. Очевидно, должен быть установленный порог, который должен подниматься все выше и выше по ходу разработки, иначе ни один продукт никогда не будет создан.
Тем не менее некоторые изменения в задачах неизбежны, и лучше подготовиться к ним заранее, чем предполагать, что их не возникнет. Неизбежны не только изменения в целях, но также изменения в стратегии разработки и технологии. Концепция «работы на мусорный ящик» есть лишь признание того факта, что по мере приобретения опыта меняется проект. [4]
Планируйте внесение изменений в систему
Способы проектирования системы с учетом будущих изменений хорошо известны и широко обсуждаются в литературе — возможно, шире обсуждаются, чем применяются. Они включают в себя тщательное разбиение на модули, интенсивное использование подпрограмм, точное и полное определение межмодульных интерфейсов и полную их документацию. Менее очевидно, что при любой возможности необходимо использовать стандартные последовательности вызова и технологии табличного управления.
Очень важно использовать языки высокого уровня и технологии самодокументирования, чтобы уменьшить число ошибок, вызываемых изменений. Мощную поддержку при внесении изменений оказывают операции времени компиляции по включению стандартных объявлений.
Важным приемом является квантование изменений. Каждый продукт должен иметь нумерованные версии, и каждая версия должна иметь свой график работ и дату фиксации, после которой изменения включаются уже в следующую версию.
Планируйте организационную структуру для внесения изменений
Косгроув рекомендует ко всем планам, вехам и графикам относиться как к пробам, чтобы облегчить изменения. Здесь он заходит слишком далеко — сегодня группы программистов терпят неудачи обычно из-за слишком слабого, а не слишком сильного административного контроля.
Тем не менее он выказывает большую проницательность. Он замечает, что нежелание документировать проект происходит не только от лени или недостатка времени. Оно происходит от нежелания проектировщика связывать себя отстаиванием решений, которые, как он знает, предварительные. «Документируя проект, проектировщик становится объектом критики со всех сторон, и должен защищать все, что написал. Если организационная структура может представлять угрозу, не будет документироваться ничего, кроме того, что нельзя оспорить.»
Создавать организационную структуру с учетом внесения в будущем изменений значительно труднее, чем проектировать систему с учетом будущих изменений. Каждый получает задание, расширяющее круг его обязанностей, чтобы сделать технически более гибким все подразделение. В больших проектах менеджеру нужно иметь двух или трех высококлассных программистов в качестве резерва, который можно бросить на самый опасный участок боя.
Структуру управления также нужно изменять по мере изменения системы. Это означает, что руководитель должен уделить большое внимание тому, чтобы его менеджеры и технический персонал были настолько взаимозаменяемы, насколько позволяют их способности.
Барьеры являются социологическими, и с ними нужно бдительно и настойчиво бороться. Во-первых, менеджеры сами рассматривают руководителя как «слишком большую ценность», чтобы использовать их для реального программирования. Во-вторых, работа менеджера обладает более высоким престижем. Чтобы преодолеть эти сложности, в некоторых лабораториях, например, в Bell Labs, упраздняют все наименования должностей. Каждый профессиональный служащий является «техническим сотрудником». В других, например в IBM, вводят двойную лестницу продвижения (рис. 11.1). Соответствующие ступеньки теоретически равнозначны.
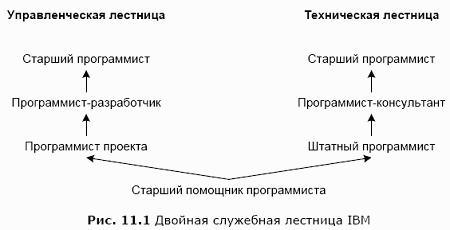 Рис. 11.1 Двойная служебная лестница IBM
Рис. 11.1 Двойная служебная лестница IBM
Легко установить соответствующие ступенькам размеры жалования. Значительно труднее дать им соответствующий престиж. Офисы должны иметь одинаковый размер и обстановку. Секретарские и прочие службы должны быть соответствующими. Перевод с технической лестницы в управленческую не должен сопровождаться повышением, и о нем всегда нужно сообщать как о «переводе», а не как о «повышении». Обратный перевод всегда должен сопровождаться прибавкой к жалованью.
Менеджеров нужно посылать на курсы технической переподготовки, а старший технический персонал — на курсы обучения управлению. Цели проекта, ход работы и административные проблемы должны доводиться до всех руководящих работников.
Если позволяет подготовка, руководящие работники должны быть технически и морально готовы возглавить группы или насладиться разработкой программ собственными руками. Конечно, осуществление всего этого требует много труда, но результат того стоит!
Идея организации групп программистов наподобие операционных бригад представляет собой коренное решение этой проблемы. Она заставляет руководящего работника почувствовать, что он не унижает себя, когда пишет программы, и пытается убрать социальные препятствия, мешающие ему испытать радость творчества.
Более того, эта структура предназначена для сокращения числа интерфейсов. Благодаря ей систему можно изменять с максимальной легкостью, и становится относительно просто перенаправить всю бригаду на другое задание в случае необходимости организационных изменений. Это действительно долгосрочное решение проблемы гибкой организации.
Два шага вперед, шаг назад
Программа не перестает изменяться после своей поставки клиенту. Изменения после поставки называются сопровождением программы, но этот процесс в корне отличается от сопровождения аппаратной части.
Сопровождение аппаратной части компьютерной системы состоит из трех видов деятельности: замены испорченных деталей, чистки и смазки и осуществления технических изменений для исправления конструктивных дефектов. (Большая часть
технических изменений, но не все, устраняет дефекты разработки или реализации, а не архитектуры, и потому незаметна пользователю.)
Сопровождение программ не предполагает чистки, смазки или замены испортившихся компонентов. Оно состоит главным образом из изменений, исправляющих конструктивные дефекты. Гораздо чаще, чем для аппаратной части, эти изменения включают в себя дополнительные функции. Обычно они видны пользователю.
Общая стоимость сопровождения широко используемой программы обычно составляет 40 и более процентов стоимости ее разработки. Удивительно, что на стоимость сопровождения сильно влияет число пользователей. Чем больше пользователей, тем больше ошибок они находят.
Бетти Кэмпбелл из Лаборатории ядерной физики МТИ отмечает интересный цикл в жизни отдельной версии программы. Он показан на рисунке 11.2. В начале существует тенденция повторного появления ошибок, найденных и устраненных в предыдущих версиях. Обнаруживаются ошибки в функциях, впервые появившихся в новой версии. Все они исправляются, и в течение нескольких месяцев все идет хорошо. Затем количество обнаруженных ошибок снова начинает расти. По мнению Кэмпбелл, это происходит потому, что пользователи выходят на новый уровень сложности, начиная полностью применять новые возможности версии. Эта интенсивная работа выявляет более скрытые ошибки в новых функциях. [5]
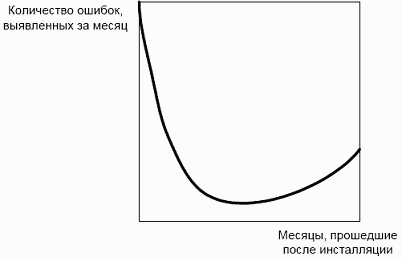 Рис. 11.2 Частота обнаружения ошибок как функция возраста версии программы
Рис. 11.2 Частота обнаружения ошибок как функция возраста версии программы
Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20-50 процентов) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, один назад».
Почему не удается устранить ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, исправляет ошибки обычно не автор программы, и часто это младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.
Очевидно, методы разработки программ, позволяющие исключить или, по крайней мере, выявить побочные эффекты, могут резко снизить стоимость сопровождения, как и методы разработки проектов меньшим числом людей и с меньшим числом интерфейсов — а значит, и с меньшим числом ошибок.
Шаг вперед, шаг назад
Леман и Белади изучили историю последовательных выпусков большой операционной системы. [6] Они считают, что общее количество модулей растет линейно с номером версии, но число модулей, затронутых изменениями, растет экспоненциально в зависимости от номера версии. Все исправления имеют тенденцию к разрушению структуры, увеличению энтропии и дезорганизации системы. Все меньше сил тратится на исправление ошибок исходного проекта и все больше — на ликвидацию последствий предыдущих исправлений. По прошествии времени система становится все менее и менее организованной. Рано или поздно исправление ошибок теряет смысл. На каждый шаг вперед приходится шаг назад. В принципе годная для вечного использования система перестает быть основой развития. Кроме того, меняются машины, конфигурации, требования пользователя, так что фактически система является вечной. Необходим совершенно новый проект, выполняемый с самого начала.
От механической статистической модели Белади и Леман приходят к общему заключению относительно программных систем, которое подкреплено всем опытом человечества. «Лучшая пора вещей — когда они только что появились», — сказал Паскаль. Ч. С. Льюис выразил это более весомо:
Вот ключ к пониманию истории. Высвобождается огромная энергия, возникают цивилизации, создаются прекрасные учреждения, но всякий раз что-то происходит не так. Какая-то роковая ошибка возносит на вершину себялюбивых и жестоких людей, и все скатывается назад, в нищету и руины. Действительно, машина глохнет. Она нормально стартует и проезжает несколько метров, а затем ломается. [7]
Системное программирование является процессом, уменьшающим энтропию, а потому ему внутренне присуща метастабильность. Сопровождение программ есть процесс, увеличивающий энтропию, и даже самое умелое его ведение лишь отдаляет впадение системы в безнадежное устаревание.
Даже в наше время многие программные проекты, с точки зрения использования инструментария, работают как механические мастерские. У каждого механика есть свой набор инструментов, собиравшийся в течение всей жизни, который он тщательно запирает и охраняет — наглядное свидетельство личного мастерства. Точно также программист собирает маленькие редакторы, сортировки, двоичные дампы, утилиты для работы с дисками и припрятывает их в своих файлах.
Однако такой подход не оправдан при работе над программным проектом. Во-первых, важной задачей является обмен информацией, а личный инструмент ему мешает, а не содействует. Во-вторых, при переходе на новую машину или новый рабочий язык технология меняется, поэтому срок жизни инструмента недолог. И наконец, очевидно, значительно эффективнее совместно разрабатывать и сопровождать программные инструменты общего назначения.
Однако недостаточно иметь инструменты общего назначения. Как специальные задачи, так и личные предпочтения обусловливают необходимость иметь также и специализированный инструмент. Поэтому при обсуждении состава команды программистов я предлагал иметь в бригаде одного инструментальщика. Этот человек владеет всеми общедоступными инструментами и может обучать их использованию. Он может также создавать специализированные инструменты, которые потребуются его начальнику.
Таким образом, менеджер проекта должен установить принципы и выделить ресурсы для разработки общих инструментов. В то же время он должен понимать необходимость в специализированных инструментах и не препятствовать разработке собственных инструментов в подчиненных рабочих группах. Есть опасный соблазн попытаться достичь большей эффективности, собрав вместе отдельных разработчиков инструмента и доработав общегрупповой инструментарий. Но это не удается.
Что это за инструменты, разработку которых менеджер должен обдумывать, планировать и организовывать? Прежде всего, вычислительные средства. Для этого требуются машины, и должна быть принята политика планирования времени. Для этого требуется операционная система, и должна быть установлена политика обслуживания. Для этого требуется язык, и должна быть заложена политика в отношении языка. Затем идут утилиты, средства отладки, генераторы контрольных примеров и текстовый процессор для работы с документацией. Рассмотрим их поочередно.[1]
Целевые машины
Машинную поддержку полезно разделить на целевые машины и рабочие машины. Целевая машина — это та, для которой пишется программное обеспечение и на которой, в конце концов, его нужно будет тестировать. Рабочие машины — это те, которые предоставляют сервисы, используемые для создания системы. Если создается новая операционная система для старой машины, последняя может служить одновременно и целевой, и рабочей.
Каковы типы целевых средств? Если бригада создает новый супервизор или другое программное средство, составляющее сердцевину системы, то ей, конечно, нужна своя машина. Для таких систем потребуются операторы и один или два системных программиста, чтобы машина была в рабочем состоянии.
Если требуется отдельная машина, то она должна быть довольно специфической: не требуется, чтобы она была быстрой, но требуется, по меньшей мере, 1 Мбайт
оперативной памяти, 100 Мбайт в активных дисках и терминалы. Достаточно символьных терминалов, но со значительно большей скоростью, чем 15 символов в секунду, характерных для пишущих машинок. Наличие большой памяти значительно способствует продуктивности, позволяя заняться разбиением на оверлеи и минимизацией размера после тестирования функций.
Машина или программные средства для отладки должны также иметь средства для автоматического подсчета и измерений любых параметров программы во время отладки. К примеру, карты использования памяти служат мощным диагностическим средством при выяснении странной логики поведения или неожиданно низкой производительности.
Планирование времени. Если целевая машина новая, — например, для нее создается первая операционная система, — то машинного времени мало, и планирование становится большой проблемой. Потребности в рабочем времени целевой машины имеет специфическую кривую роста. При разработке OS/360 у нас были хорошие эмуляторы System/360 и другие машины. По прежнему опыту мы оценили, сколько часов рабочего времени S/360 нам понадобится, и стали получать первые машины с производства. Но месяц за месяцем они оставались без нагрузки. Затем сразу все 16 систем оказались загруженными, и распределение времени стало проблемой. Использование машин выглядело примерно как на рисунке 12.1. Все одновременно начали отлаживать первые компоненты, и затем все команды постоянно что-то отлаживали.
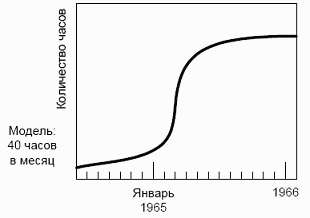 Рис. 12.1 Рост использования целевых машин
Рис. 12.1 Рост использования целевых машин
Мы централизовали все свои машины и библиотеки магнитных лент и организовали для их работы профессиональную и опытную группу машинного зала. Для максимизации бывшего в недостатке машинного времени S/360 все отладочные прогоны мы осуществляли в пакетном режиме на подходящих свободных машинах. Мы добились четырех запусков в день (оборачиваемость составила два с половиной часа), а требовалась четырехчасовая оборачиваемость. Вспомогательная машина 1401 с терминалами использовалась для планирования прогонов, отслеживания тысяч заданий и контроля времени оборачиваемости.
Но со всей этой организованностью мы перестарались. После нескольких месяцев низкой оборачиваемости, взаимных обвинений и прочих мук мы перешли к выделению машинного времени крупными блоками. К примеру, вся группа из пятнадцати человек, занимавшаяся сортировкой, получала систему на срок от четырех до шести часов. Планирование этого времени было их внутренним делом. Даже если система была на занята, посторонние не могли ею пользоваться.
Это оказалось более удачным способом планирования. Хотя коэффициент использования машины, возможно, несколько упал (а часто и этого не было), производительность поднялась. Для каждого члена команды десять запусков в течение шести часов значительно продуктивнее, чем десять запусков, осуществленных с перерывами в три часа, поскольку постоянная концентрация сокращает время обдумывания. После такой гонки команде обычно требовалось один-два дня, чтобы подогнать работу с документами, прежде чем просить о выделении нового блока. Зачастую всего три программиста могут с пользой поделить и распределить между собой выделенный им блок времени. Похоже, что это лучший способ использования целевой машины при отладке новой операционной системы.
Так было на практике, хотя это не соответствовало теории. Системная отладка всегда была занятием для ночной смены, подобно астрономии. Двадцать лет назад, работая над 701-й машиной, я впервые познал продуктивную свободу от формальностей, присущую предрассветным часам, когда все начальники из машинного зала крепко спят по домам, а операторы не расположены бороться за соблюдение правил. Сменилось три поколения машин, полностью изменились технологии, появились операционные системы, но этот лучший способ работы остался прежним. Он продолжает жить, поскольку наиболее эффективен. Пришла пора признать его продуктивность и шире применять.
Рабочие машины и службы данных
Эмуляторы. Если целевой компьютер новый, то для него необходим логический эмулятор. Это дает аппарат для отладки задолго до того, как целевая машина будет в наличии. Что столь же важно, даже тогда, когда становится доступной целевая машина, имеется доступ к надежному средству для отладки.
Надежное — не то же самое, что точное. Эмулятор неизбежно в каком-либо отношении будет отступать от верной и точной реализации архитектуры новой машины. Но это будет одна и та же реализация и сегодня, и завтра, чего не скажешь о новой аппаратной части.
В наше время мы привыкли к тому, что аппаратная часть компьютера большую часть времени работает без сбоев. Если только разработчик прикладной программы не замечает, что система неодинаково ведет себя при разных идентичных прогонах программы, ему правильнее всего поискать ошибки в своем коде, а не в технике.
Этот опыт, однако, сослужил плохую службу при программировании новой машины. Лабораторные разработки, предварительные или ранние выпуски компьютеров не работают должным образом, не работают надежно и не остаются неизменными день ото дня. По мере обнаружения ошибок технические изменения производятся во всех экземплярах машины, включая используемый группой программистов. Такая неустойчивость основания достаточно неприятна. Отказы аппаратуры, обычно скачкообразные, еще хуже. И хуже всего неопределенность, лишающая стимула старательно копаться в своем коде в поисках ошибки — ее может там вовсе не быть. Поэтому надежный эмулятор на зрелой машине остается полезным значительно дольше, чем можно было предположить.
Машины для компилятора и ассемблера. По тем же причинам требуются компиляторы и ассемблеры, работающие на надежных машинах, но компилирующие объектный код для целевой системы. Затем можно начать его отладку на эмуляторе.
При программировании на языках высокого уровня значительную часть отладки можно произвести при компиляции для вспомогательной машины и тестировании результирующей программы, прежде чем отлаживать программу для целевой машины. Этим достигается производительность непосредственного исполнения, а не эмуляции, в сочетании с надежностью стабильной машины.
Библиотеки программ и учет. Очень успешным и важным применением вспомогательной машины в программе разработки OS/360 была поддержка библиотек программ. Система, разработанная под руководством У. Р. Кроули (W. R. Crowley), состояла из двух соединенных вместе машин 7010 и общей дисковой базой данных. На 7010 поддерживался также ассемблер для S/360. В этой библиотеке хранился весь протестированный или находящийся в процессе тестирования код, как исходный, так и ассемблированные загрузочные модули. На практике библиотека была разбита на подбиблиотеки с различными правами доступа.
Прежде всего, у каждой группы или программиста была область для хранения экземпляров программ, контрольных примеров и окружения, которое требовалось для тестирования компонентов. На этой площадке для игр не было никаких ограничений на действия с собственными программами.
Когда компонент программиста был готов к включению в более крупную часть, его экземпляр передавался менеджеру этой более крупной системы, который помещал его в подбиблиотеку системной интеграции. Теперь автор не мог его изменить без разрешения менеджера интеграции. Когда система собиралась воедино, этот менеджер проводил все виды системного тестирования, выявляя ошибки и получая исправления.
Через некоторое время системная версия была готова для более широкого использования. Тогда она перемещалась в подбиблиотеку текущей версии. Этот экземпляр был священным, и доступ к нему разрешался только для исправления разрушительных ошибок. Его можно было использовать для интегрирования и тестирования всех новых версий модулей. Программный каталог на машине 7010 отслеживал все версии каждого модуля, его состояние, местонахождение и изменения.
Здесь важны два обстоятельства. Первое — это контроль, означающий, что экземпляры программ принадлежат менеджерам, и только они могут санкционировать их изменение. Второе — формальное разделение и перемещение с площадки для игр к интеграции и выпуску новой версии.
В большинстве проектов первой построенной системой с трудом можно пользоваться. Она может быть слишком медленной, слишком большой, неудобной в использовании, а то и все вместе. Не остается другой альтернативы, кроме как, поумнев, начать сначала и построить перепроектированную программу, в которой эти проблемы решены. Браковка и перепроектирование могут делаться для всей системы сразу или по частям. Но весь опыт разработки больших систем показывает, что будет сделано. [2] В тех случаях, когда используются новые системные концепции и новые технологии, приходится создавать систему на выброс, поскольку даже самое лучшее планирование не столь всеведуще, чтобы попасть в цель с первого раза.
Поэтому проблема не в том, создавать или нет опытную систему, которую придется выбросить. Вы все равно это сделаете. Вопрос единственно в том, планировать ли заранее разработку системы на выброс или обещать клиентам поставку системы, которую придется выбросить. Если смотреть под этим углом, ответ становится намного проще. Поставка хлама клиенту позволяет выиграть время, но происходит это ценой мучений пользователя, отвлечений разработчиков во время перепроектирования и дурной репутации продукта, которую даже самой удачно перепроектированной программе будет трудно победить.
Поэтому планируйте выбросить первую версию — вам все равно придется это сделать.
Постоянны только изменения
После уяснения того, что опытную систему нужно создавать, а потом выбросить, и что перепроектирование с новыми идеями неизбежно, полезно обратиться лицом к изменению как явлению природы. Первый шаг — признание того, что изменение — это образ жизни, а не постороннее и досадное исключение. Косгроув мудро указал, что программист поставляет удовлетворение потребности пользователя, а не какой-то осязаемый продукт. И в то время как программы создаются, тестируются и используются, меняются как фактические потребности пользователя, так и понимание им своих потребностей. [3]
Конечно, это справедливо и в отношении потребностей, удовлетворяемых физическими продуктами, будь то автомобили или компьютеры. Но само существование осязаемого продукта определяет запросы пользователя и их квантование. Податливость и неосязаемость программного продукта побуждают его создателей к бесконечному изменению требований.
Я далек от того, чтобы считать, будто все изменения целей и требований клиента можно или необходимо учитывать в проекте. Очевидно, должен быть установленный порог, который должен подниматься все выше и выше по ходу разработки, иначе ни один продукт никогда не будет создан.
Тем не менее некоторые изменения в задачах неизбежны, и лучше подготовиться к ним заранее, чем предполагать, что их не возникнет. Неизбежны не только изменения в целях, но также изменения в стратегии разработки и технологии. Концепция «работы на мусорный ящик» есть лишь признание того факта, что по мере приобретения опыта меняется проект. [4]
Планируйте внесение изменений в систему
Способы проектирования системы с учетом будущих изменений хорошо известны и широко обсуждаются в литературе — возможно, шире обсуждаются, чем применяются. Они включают в себя тщательное разбиение на модули, интенсивное использование подпрограмм, точное и полное определение межмодульных интерфейсов и полную их документацию. Менее очевидно, что при любой возможности необходимо использовать стандартные последовательности вызова и технологии табличного управления.
Очень важно использовать языки высокого уровня и технологии самодокументирования, чтобы уменьшить число ошибок, вызываемых изменений. Мощную поддержку при внесении изменений оказывают операции времени компиляции по включению стандартных объявлений.
Важным приемом является квантование изменений. Каждый продукт должен иметь нумерованные версии, и каждая версия должна иметь свой график работ и дату фиксации, после которой изменения включаются уже в следующую версию.
Планируйте организационную структуру для внесения изменений
Косгроув рекомендует ко всем планам, вехам и графикам относиться как к пробам, чтобы облегчить изменения. Здесь он заходит слишком далеко — сегодня группы программистов терпят неудачи обычно из-за слишком слабого, а не слишком сильного административного контроля.
Тем не менее он выказывает большую проницательность. Он замечает, что нежелание документировать проект происходит не только от лени или недостатка времени. Оно происходит от нежелания проектировщика связывать себя отстаиванием решений, которые, как он знает, предварительные. «Документируя проект, проектировщик становится объектом критики со всех сторон, и должен защищать все, что написал. Если организационная структура может представлять угрозу, не будет документироваться ничего, кроме того, что нельзя оспорить.»
Создавать организационную структуру с учетом внесения в будущем изменений значительно труднее, чем проектировать систему с учетом будущих изменений. Каждый получает задание, расширяющее круг его обязанностей, чтобы сделать технически более гибким все подразделение. В больших проектах менеджеру нужно иметь двух или трех высококлассных программистов в качестве резерва, который можно бросить на самый опасный участок боя.
Структуру управления также нужно изменять по мере изменения системы. Это означает, что руководитель должен уделить большое внимание тому, чтобы его менеджеры и технический персонал были настолько взаимозаменяемы, насколько позволяют их способности.
Барьеры являются социологическими, и с ними нужно бдительно и настойчиво бороться. Во-первых, менеджеры сами рассматривают руководителя как «слишком большую ценность», чтобы использовать их для реального программирования. Во-вторых, работа менеджера обладает более высоким престижем. Чтобы преодолеть эти сложности, в некоторых лабораториях, например, в Bell Labs, упраздняют все наименования должностей. Каждый профессиональный служащий является «техническим сотрудником». В других, например в IBM, вводят двойную лестницу продвижения (рис. 11.1). Соответствующие ступеньки теоретически равнозначны.
Легко установить соответствующие ступенькам размеры жалования. Значительно труднее дать им соответствующий престиж. Офисы должны иметь одинаковый размер и обстановку. Секретарские и прочие службы должны быть соответствующими. Перевод с технической лестницы в управленческую не должен сопровождаться повышением, и о нем всегда нужно сообщать как о «переводе», а не как о «повышении». Обратный перевод всегда должен сопровождаться прибавкой к жалованью.
Менеджеров нужно посылать на курсы технической переподготовки, а старший технический персонал — на курсы обучения управлению. Цели проекта, ход работы и административные проблемы должны доводиться до всех руководящих работников.
Если позволяет подготовка, руководящие работники должны быть технически и морально готовы возглавить группы или насладиться разработкой программ собственными руками. Конечно, осуществление всего этого требует много труда, но результат того стоит!
Идея организации групп программистов наподобие операционных бригад представляет собой коренное решение этой проблемы. Она заставляет руководящего работника почувствовать, что он не унижает себя, когда пишет программы, и пытается убрать социальные препятствия, мешающие ему испытать радость творчества.
Более того, эта структура предназначена для сокращения числа интерфейсов. Благодаря ей систему можно изменять с максимальной легкостью, и становится относительно просто перенаправить всю бригаду на другое задание в случае необходимости организационных изменений. Это действительно долгосрочное решение проблемы гибкой организации.
Два шага вперед, шаг назад
Программа не перестает изменяться после своей поставки клиенту. Изменения после поставки называются сопровождением программы, но этот процесс в корне отличается от сопровождения аппаратной части.
Сопровождение аппаратной части компьютерной системы состоит из трех видов деятельности: замены испорченных деталей, чистки и смазки и осуществления технических изменений для исправления конструктивных дефектов. (Большая часть
технических изменений, но не все, устраняет дефекты разработки или реализации, а не архитектуры, и потому незаметна пользователю.)
Сопровождение программ не предполагает чистки, смазки или замены испортившихся компонентов. Оно состоит главным образом из изменений, исправляющих конструктивные дефекты. Гораздо чаще, чем для аппаратной части, эти изменения включают в себя дополнительные функции. Обычно они видны пользователю.
Общая стоимость сопровождения широко используемой программы обычно составляет 40 и более процентов стоимости ее разработки. Удивительно, что на стоимость сопровождения сильно влияет число пользователей. Чем больше пользователей, тем больше ошибок они находят.
Бетти Кэмпбелл из Лаборатории ядерной физики МТИ отмечает интересный цикл в жизни отдельной версии программы. Он показан на рисунке 11.2. В начале существует тенденция повторного появления ошибок, найденных и устраненных в предыдущих версиях. Обнаруживаются ошибки в функциях, впервые появившихся в новой версии. Все они исправляются, и в течение нескольких месяцев все идет хорошо. Затем количество обнаруженных ошибок снова начинает расти. По мнению Кэмпбелл, это происходит потому, что пользователи выходят на новый уровень сложности, начиная полностью применять новые возможности версии. Эта интенсивная работа выявляет более скрытые ошибки в новых функциях. [5]
Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20-50 процентов) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, один назад».
Почему не удается устранить ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, исправляет ошибки обычно не автор программы, и часто это младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.
Очевидно, методы разработки программ, позволяющие исключить или, по крайней мере, выявить побочные эффекты, могут резко снизить стоимость сопровождения, как и методы разработки проектов меньшим числом людей и с меньшим числом интерфейсов — а значит, и с меньшим числом ошибок.
Шаг вперед, шаг назад
Леман и Белади изучили историю последовательных выпусков большой операционной системы. [6] Они считают, что общее количество модулей растет линейно с номером версии, но число модулей, затронутых изменениями, растет экспоненциально в зависимости от номера версии. Все исправления имеют тенденцию к разрушению структуры, увеличению энтропии и дезорганизации системы. Все меньше сил тратится на исправление ошибок исходного проекта и все больше — на ликвидацию последствий предыдущих исправлений. По прошествии времени система становится все менее и менее организованной. Рано или поздно исправление ошибок теряет смысл. На каждый шаг вперед приходится шаг назад. В принципе годная для вечного использования система перестает быть основой развития. Кроме того, меняются машины, конфигурации, требования пользователя, так что фактически система является вечной. Необходим совершенно новый проект, выполняемый с самого начала.
От механической статистической модели Белади и Леман приходят к общему заключению относительно программных систем, которое подкреплено всем опытом человечества. «Лучшая пора вещей — когда они только что появились», — сказал Паскаль. Ч. С. Льюис выразил это более весомо:
Вот ключ к пониманию истории. Высвобождается огромная энергия, возникают цивилизации, создаются прекрасные учреждения, но всякий раз что-то происходит не так. Какая-то роковая ошибка возносит на вершину себялюбивых и жестоких людей, и все скатывается назад, в нищету и руины. Действительно, машина глохнет. Она нормально стартует и проезжает несколько метров, а затем ломается. [7]
Системное программирование является процессом, уменьшающим энтропию, а потому ему внутренне присуща метастабильность. Сопровождение программ есть процесс, увеличивающий энтропию, и даже самое умелое его ведение лишь отдаляет впадение системы в безнадежное устаревание.
Хорошего работника узнают по инструменту.
ПОСЛОВИЦА
Даже в наше время многие программные проекты, с точки зрения использования инструментария, работают как механические мастерские. У каждого механика есть свой набор инструментов, собиравшийся в течение всей жизни, который он тщательно запирает и охраняет — наглядное свидетельство личного мастерства. Точно также программист собирает маленькие редакторы, сортировки, двоичные дампы, утилиты для работы с дисками и припрятывает их в своих файлах.
Однако такой подход не оправдан при работе над программным проектом. Во-первых, важной задачей является обмен информацией, а личный инструмент ему мешает, а не содействует. Во-вторых, при переходе на новую машину или новый рабочий язык технология меняется, поэтому срок жизни инструмента недолог. И наконец, очевидно, значительно эффективнее совместно разрабатывать и сопровождать программные инструменты общего назначения.
Однако недостаточно иметь инструменты общего назначения. Как специальные задачи, так и личные предпочтения обусловливают необходимость иметь также и специализированный инструмент. Поэтому при обсуждении состава команды программистов я предлагал иметь в бригаде одного инструментальщика. Этот человек владеет всеми общедоступными инструментами и может обучать их использованию. Он может также создавать специализированные инструменты, которые потребуются его начальнику.
Таким образом, менеджер проекта должен установить принципы и выделить ресурсы для разработки общих инструментов. В то же время он должен понимать необходимость в специализированных инструментах и не препятствовать разработке собственных инструментов в подчиненных рабочих группах. Есть опасный соблазн попытаться достичь большей эффективности, собрав вместе отдельных разработчиков инструмента и доработав общегрупповой инструментарий. Но это не удается.
Что это за инструменты, разработку которых менеджер должен обдумывать, планировать и организовывать? Прежде всего, вычислительные средства. Для этого требуются машины, и должна быть принята политика планирования времени. Для этого требуется операционная система, и должна быть установлена политика обслуживания. Для этого требуется язык, и должна быть заложена политика в отношении языка. Затем идут утилиты, средства отладки, генераторы контрольных примеров и текстовый процессор для работы с документацией. Рассмотрим их поочередно.[1]
Целевые машины
Машинную поддержку полезно разделить на целевые машины и рабочие машины. Целевая машина — это та, для которой пишется программное обеспечение и на которой, в конце концов, его нужно будет тестировать. Рабочие машины — это те, которые предоставляют сервисы, используемые для создания системы. Если создается новая операционная система для старой машины, последняя может служить одновременно и целевой, и рабочей.
Каковы типы целевых средств? Если бригада создает новый супервизор или другое программное средство, составляющее сердцевину системы, то ей, конечно, нужна своя машина. Для таких систем потребуются операторы и один или два системных программиста, чтобы машина была в рабочем состоянии.
Если требуется отдельная машина, то она должна быть довольно специфической: не требуется, чтобы она была быстрой, но требуется, по меньшей мере, 1 Мбайт
оперативной памяти, 100 Мбайт в активных дисках и терминалы. Достаточно символьных терминалов, но со значительно большей скоростью, чем 15 символов в секунду, характерных для пишущих машинок. Наличие большой памяти значительно способствует продуктивности, позволяя заняться разбиением на оверлеи и минимизацией размера после тестирования функций.
Машина или программные средства для отладки должны также иметь средства для автоматического подсчета и измерений любых параметров программы во время отладки. К примеру, карты использования памяти служат мощным диагностическим средством при выяснении странной логики поведения или неожиданно низкой производительности.
Планирование времени. Если целевая машина новая, — например, для нее создается первая операционная система, — то машинного времени мало, и планирование становится большой проблемой. Потребности в рабочем времени целевой машины имеет специфическую кривую роста. При разработке OS/360 у нас были хорошие эмуляторы System/360 и другие машины. По прежнему опыту мы оценили, сколько часов рабочего времени S/360 нам понадобится, и стали получать первые машины с производства. Но месяц за месяцем они оставались без нагрузки. Затем сразу все 16 систем оказались загруженными, и распределение времени стало проблемой. Использование машин выглядело примерно как на рисунке 12.1. Все одновременно начали отлаживать первые компоненты, и затем все команды постоянно что-то отлаживали.
Мы централизовали все свои машины и библиотеки магнитных лент и организовали для их работы профессиональную и опытную группу машинного зала. Для максимизации бывшего в недостатке машинного времени S/360 все отладочные прогоны мы осуществляли в пакетном режиме на подходящих свободных машинах. Мы добились четырех запусков в день (оборачиваемость составила два с половиной часа), а требовалась четырехчасовая оборачиваемость. Вспомогательная машина 1401 с терминалами использовалась для планирования прогонов, отслеживания тысяч заданий и контроля времени оборачиваемости.
Но со всей этой организованностью мы перестарались. После нескольких месяцев низкой оборачиваемости, взаимных обвинений и прочих мук мы перешли к выделению машинного времени крупными блоками. К примеру, вся группа из пятнадцати человек, занимавшаяся сортировкой, получала систему на срок от четырех до шести часов. Планирование этого времени было их внутренним делом. Даже если система была на занята, посторонние не могли ею пользоваться.
Это оказалось более удачным способом планирования. Хотя коэффициент использования машины, возможно, несколько упал (а часто и этого не было), производительность поднялась. Для каждого члена команды десять запусков в течение шести часов значительно продуктивнее, чем десять запусков, осуществленных с перерывами в три часа, поскольку постоянная концентрация сокращает время обдумывания. После такой гонки команде обычно требовалось один-два дня, чтобы подогнать работу с документами, прежде чем просить о выделении нового блока. Зачастую всего три программиста могут с пользой поделить и распределить между собой выделенный им блок времени. Похоже, что это лучший способ использования целевой машины при отладке новой операционной системы.
Так было на практике, хотя это не соответствовало теории. Системная отладка всегда была занятием для ночной смены, подобно астрономии. Двадцать лет назад, работая над 701-й машиной, я впервые познал продуктивную свободу от формальностей, присущую предрассветным часам, когда все начальники из машинного зала крепко спят по домам, а операторы не расположены бороться за соблюдение правил. Сменилось три поколения машин, полностью изменились технологии, появились операционные системы, но этот лучший способ работы остался прежним. Он продолжает жить, поскольку наиболее эффективен. Пришла пора признать его продуктивность и шире применять.
Рабочие машины и службы данных
Эмуляторы. Если целевой компьютер новый, то для него необходим логический эмулятор. Это дает аппарат для отладки задолго до того, как целевая машина будет в наличии. Что столь же важно, даже тогда, когда становится доступной целевая машина, имеется доступ к надежному средству для отладки.
Надежное — не то же самое, что точное. Эмулятор неизбежно в каком-либо отношении будет отступать от верной и точной реализации архитектуры новой машины. Но это будет одна и та же реализация и сегодня, и завтра, чего не скажешь о новой аппаратной части.
В наше время мы привыкли к тому, что аппаратная часть компьютера большую часть времени работает без сбоев. Если только разработчик прикладной программы не замечает, что система неодинаково ведет себя при разных идентичных прогонах программы, ему правильнее всего поискать ошибки в своем коде, а не в технике.
Этот опыт, однако, сослужил плохую службу при программировании новой машины. Лабораторные разработки, предварительные или ранние выпуски компьютеров не работают должным образом, не работают надежно и не остаются неизменными день ото дня. По мере обнаружения ошибок технические изменения производятся во всех экземплярах машины, включая используемый группой программистов. Такая неустойчивость основания достаточно неприятна. Отказы аппаратуры, обычно скачкообразные, еще хуже. И хуже всего неопределенность, лишающая стимула старательно копаться в своем коде в поисках ошибки — ее может там вовсе не быть. Поэтому надежный эмулятор на зрелой машине остается полезным значительно дольше, чем можно было предположить.
Машины для компилятора и ассемблера. По тем же причинам требуются компиляторы и ассемблеры, работающие на надежных машинах, но компилирующие объектный код для целевой системы. Затем можно начать его отладку на эмуляторе.
При программировании на языках высокого уровня значительную часть отладки можно произвести при компиляции для вспомогательной машины и тестировании результирующей программы, прежде чем отлаживать программу для целевой машины. Этим достигается производительность непосредственного исполнения, а не эмуляции, в сочетании с надежностью стабильной машины.
Библиотеки программ и учет. Очень успешным и важным применением вспомогательной машины в программе разработки OS/360 была поддержка библиотек программ. Система, разработанная под руководством У. Р. Кроули (W. R. Crowley), состояла из двух соединенных вместе машин 7010 и общей дисковой базой данных. На 7010 поддерживался также ассемблер для S/360. В этой библиотеке хранился весь протестированный или находящийся в процессе тестирования код, как исходный, так и ассемблированные загрузочные модули. На практике библиотека была разбита на подбиблиотеки с различными правами доступа.
Прежде всего, у каждой группы или программиста была область для хранения экземпляров программ, контрольных примеров и окружения, которое требовалось для тестирования компонентов. На этой площадке для игр не было никаких ограничений на действия с собственными программами.
Когда компонент программиста был готов к включению в более крупную часть, его экземпляр передавался менеджеру этой более крупной системы, который помещал его в подбиблиотеку системной интеграции. Теперь автор не мог его изменить без разрешения менеджера интеграции. Когда система собиралась воедино, этот менеджер проводил все виды системного тестирования, выявляя ошибки и получая исправления.
Через некоторое время системная версия была готова для более широкого использования. Тогда она перемещалась в подбиблиотеку текущей версии. Этот экземпляр был священным, и доступ к нему разрешался только для исправления разрушительных ошибок. Его можно было использовать для интегрирования и тестирования всех новых версий модулей. Программный каталог на машине 7010 отслеживал все версии каждого модуля, его состояние, местонахождение и изменения.
Здесь важны два обстоятельства. Первое — это контроль, означающий, что экземпляры программ принадлежат менеджерам, и только они могут санкционировать их изменение. Второе — формальное разделение и перемещение с площадки для игр к интеграции и выпуску новой версии.