Страница:
Семантическое ядро в таких случаях создается стихийно. Это некритично – после того как сайт попадет на продвижение к грамотному специалисту, он все равно получит нормальное семантическое ядро, в соответствии с которым будет осуществляться продвижение. Проблема лишь в том, что в этом случае сложность и стоимость продвижения вырастут. Применительно к порталу рост затрат на продвижение может быть очень значительным, а потому созданием семантического ядра имеет смысл заняться на этапе проектирования сайта.
Почему нельзя составлять семантическое ядро на основе прайс-листа или каталога?
Причин две:
□ ядро будет составляться на основе предложения, а не реального спроса, что даст заметную погрешность в оценке сложности продвижения отдельных запросов;
□ многие сущности, прямо в каталоге не упомянутые, но имеющие к нему отношение, не будут упомянуты и при составлении ядра.
При этом нельзя сказать, что прайс-лист и каталог в принципе бесполезны. Они все же дают общее представление о предмете продвижения, но не более того.
Как собирать семантическое ядро? Для сборки семантического ядра используются два главных инструмента – Excel и wordstat.yandex.ru. Если мы хотим узнать, что и как ищут в «Яндексе», логичнее всего спросить у него самого. Разумеется, данные сервиса необходимо уметь интерпретировать, однако при грамотном подходе он дает массу полезной информации. И, конечно же, не стоит забывать об автоматизации – использовать wordstat.yandex.ru для ручного сбора семантики для портала очень трудоемко. Пригодится также знание предметной области.
Сбор семантики начинают с наиболее общего запроса – пусть это будет «мебель». Компонуем в таблицу все, что дает wordstat.yandex.ru по этому запросу, и одновременно в правой колонке создаем список типов мебели: диваны, кресла и т. д. Собираем запросы по каждому из типов, одновременно вычленяя попадающиеся мебельные бренды. Затем собираем запросы, связанные с мебельными брендами.
Следующий этап – производные прилагательные сначала от слова «мебель» («мебельный», «мебельная»), затем от типов («диванный»). Это даст еще некоторое количество запросов.
Отдельный сегмент – аксессуары. Запросы, связанные с аксессуарами, есть во всех товарных тематиках, но очень часто их просто упускают из виду.
Wordstat.yandex.ru и уникальные запросы. На рис. 3.2 приведен результат довольно масштабного исследования, которое проводили сотрудники «Яндекса». Объектом исследования были пользовательские запросы. Подробнее: http://company.yandex.ru/researches/reports/ ya_regions_search_2010.xml.
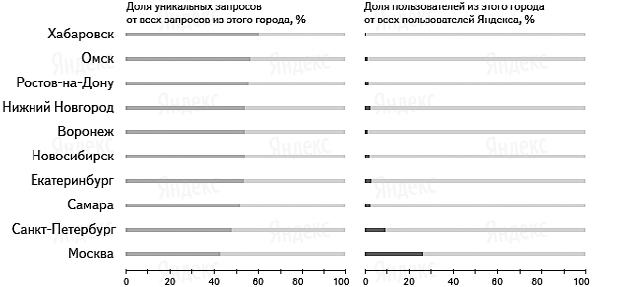 Рис. 3.2
Рис. 3.2
Мы видим, что в крупных городах доля трафика по уникальным запросам достигает 50 %. Уникальные запросы – это запросы, которые вводятся в течение суток не больше одного раза: таким образом, их частотность не превышает 30 %. Это означает, что подавляющее большинство таких запросов вообще не фигурирует в wordstat.yandex.ru. Для описанного ранее способа сбора семантики их просто нет, но они дают около 50 % трафика. С точки зрения составления семантического ядра их отсутствие в wordstat.yandex.ru является большим недостатком последнего, но не следует забывать, для чего на самом деле создавался этот сервис.
Возникает вопрос: как охватить эти уникальные запросы?
Прямых и простых решений, позволяющих получить эти запросы, нет, но есть некоторые не самые очевидные возможности:
Сервис ADVSe содержит информацию о запросах, по которым сайты ваших конкурентов продвигаются с помощью контекстной рекламы.
Анализ собственного трафика. Для сбора запросов, по которым пользователи пришли на ваш сайт, лучше использовать access.log, в котором гарантированно сохраняются все запросы. Счетчики, построенные на JavaScript, теряют около 20 % запросов, что делает их простым, но не совсем надежным источником. По поводу полноты данных, представляемых метрикой «Яндекса», также есть некоторые сомнения, а вот access.log никогда не обманет вас – необходимо лишь написать модуль, который будет анализировать его и собирать необходимые данные.
Статистика внутреннего поиска. Далеко не все сайты имеют мощный внутренний поиск, но если он есть, вы можете использовать запросы внутреннего поиска для пополнения семантического ядра.
Базы запросов. База Пастухова – это база русскоязычных запросов, состоящая из более чем 210 млн запросов с указанием частотности в основных поисковых системах (рис. 3.3). В отличие от wordstat.yandex.ru база Пастухова учитывает все словоформы, что очень полезно при подборе обширного семантического ядра. База поставляется с собственным интерфейсом (оболочкой) и в виде текстового файла. Работать с таким количеством запросов вручную крайне сложно, поэтому придется задействовать программиста, который может создать собственный интерфейс, подходящий для решения конкретных задач.
База Пастухова – лучшая, но не единственная. Не упускайте возможности купить интересную тематическую базу и пополнить ядро новыми запросами.
Подсказки поисковых систем. Подсказки часто дают свежие актуальные запросы, связанные с недавно возникшими пользовательскими интересами. Зачастую такие запросы низкоконкурентны, но дают хороший трафик.
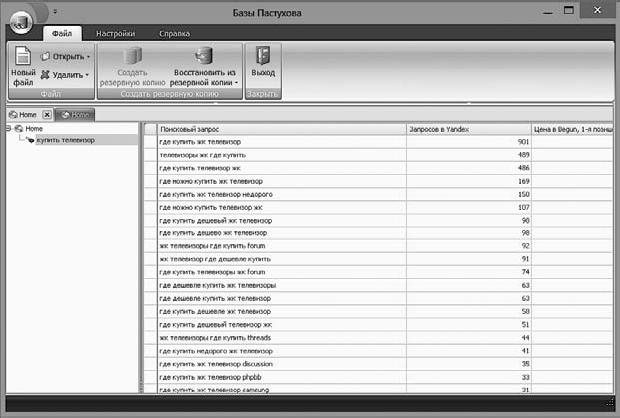 Рис. 3.3
Рис. 3.3
FastKeywords.biz – сервис, предоставляющий базы запросов, введенных в течение дня (рис. 3.4). Можно использовать как дополнительный источник данных.
Подбор запросов в «Яндекс.Директ» (не в сервисе wordstat.yandex.ru, а при создании объявления непосредственно в аккаунте). Ассоциативный подбор родственных запросов, размещенный там, предлагает такие запросы, которые никогда не найдет wordstat.yandex.ru.
Предсказание запросов. Если вы получили запрос «как работает экспозамер в Nikon D7000», есть некоторые шансы, что в природе существуют также запросы «как работает экспозамер в…». Поскольку моделей фотоаппаратов много, запросов тоже получается много. К слову, закрыть их можно автоматическим созданием контента – необходимо лишь, чтобы формулу для генерирования создавал кто-то, знакомый с предметной областью.
В результате такого массированного сбора семантики мы получаем обширный список, который может содержать несколько десятков тысяч (в отдельных случаях несколько миллионов) запросов. Разумеется, в этом списке велика доля пустых запросов, которые никогда не принесут трафика. Поэтому следующий этап – чистка семантического ядра.
Чистка семантического ядра
Оценка конкурентоспособности запросов
Создание групп запросов
Почему так важно охватить все ядро
Пополнение и обновление ядра после запуска портала
Альтернативный способ создания ядра
Почему нельзя составлять семантическое ядро на основе прайс-листа или каталога?
Причин две:
□ ядро будет составляться на основе предложения, а не реального спроса, что даст заметную погрешность в оценке сложности продвижения отдельных запросов;
□ многие сущности, прямо в каталоге не упомянутые, но имеющие к нему отношение, не будут упомянуты и при составлении ядра.
При этом нельзя сказать, что прайс-лист и каталог в принципе бесполезны. Они все же дают общее представление о предмете продвижения, но не более того.
Как собирать семантическое ядро? Для сборки семантического ядра используются два главных инструмента – Excel и wordstat.yandex.ru. Если мы хотим узнать, что и как ищут в «Яндексе», логичнее всего спросить у него самого. Разумеется, данные сервиса необходимо уметь интерпретировать, однако при грамотном подходе он дает массу полезной информации. И, конечно же, не стоит забывать об автоматизации – использовать wordstat.yandex.ru для ручного сбора семантики для портала очень трудоемко. Пригодится также знание предметной области.
Сбор семантики начинают с наиболее общего запроса – пусть это будет «мебель». Компонуем в таблицу все, что дает wordstat.yandex.ru по этому запросу, и одновременно в правой колонке создаем список типов мебели: диваны, кресла и т. д. Собираем запросы по каждому из типов, одновременно вычленяя попадающиеся мебельные бренды. Затем собираем запросы, связанные с мебельными брендами.
Следующий этап – производные прилагательные сначала от слова «мебель» («мебельный», «мебельная»), затем от типов («диванный»). Это даст еще некоторое количество запросов.
Отдельный сегмент – аксессуары. Запросы, связанные с аксессуарами, есть во всех товарных тематиках, но очень часто их просто упускают из виду.
Wordstat.yandex.ru и уникальные запросы. На рис. 3.2 приведен результат довольно масштабного исследования, которое проводили сотрудники «Яндекса». Объектом исследования были пользовательские запросы. Подробнее: http://company.yandex.ru/researches/reports/ ya_regions_search_2010.xml.
Мы видим, что в крупных городах доля трафика по уникальным запросам достигает 50 %. Уникальные запросы – это запросы, которые вводятся в течение суток не больше одного раза: таким образом, их частотность не превышает 30 %. Это означает, что подавляющее большинство таких запросов вообще не фигурирует в wordstat.yandex.ru. Для описанного ранее способа сбора семантики их просто нет, но они дают около 50 % трафика. С точки зрения составления семантического ядра их отсутствие в wordstat.yandex.ru является большим недостатком последнего, но не следует забывать, для чего на самом деле создавался этот сервис.
Возникает вопрос: как охватить эти уникальные запросы?
Прямых и простых решений, позволяющих получить эти запросы, нет, но есть некоторые не самые очевидные возможности:
Сервис ADVSe содержит информацию о запросах, по которым сайты ваших конкурентов продвигаются с помощью контекстной рекламы.
Анализ собственного трафика. Для сбора запросов, по которым пользователи пришли на ваш сайт, лучше использовать access.log, в котором гарантированно сохраняются все запросы. Счетчики, построенные на JavaScript, теряют около 20 % запросов, что делает их простым, но не совсем надежным источником. По поводу полноты данных, представляемых метрикой «Яндекса», также есть некоторые сомнения, а вот access.log никогда не обманет вас – необходимо лишь написать модуль, который будет анализировать его и собирать необходимые данные.
Статистика внутреннего поиска. Далеко не все сайты имеют мощный внутренний поиск, но если он есть, вы можете использовать запросы внутреннего поиска для пополнения семантического ядра.
Базы запросов. База Пастухова – это база русскоязычных запросов, состоящая из более чем 210 млн запросов с указанием частотности в основных поисковых системах (рис. 3.3). В отличие от wordstat.yandex.ru база Пастухова учитывает все словоформы, что очень полезно при подборе обширного семантического ядра. База поставляется с собственным интерфейсом (оболочкой) и в виде текстового файла. Работать с таким количеством запросов вручную крайне сложно, поэтому придется задействовать программиста, который может создать собственный интерфейс, подходящий для решения конкретных задач.
База Пастухова – лучшая, но не единственная. Не упускайте возможности купить интересную тематическую базу и пополнить ядро новыми запросами.
Подсказки поисковых систем. Подсказки часто дают свежие актуальные запросы, связанные с недавно возникшими пользовательскими интересами. Зачастую такие запросы низкоконкурентны, но дают хороший трафик.
FastKeywords.biz – сервис, предоставляющий базы запросов, введенных в течение дня (рис. 3.4). Можно использовать как дополнительный источник данных.
Подбор запросов в «Яндекс.Директ» (не в сервисе wordstat.yandex.ru, а при создании объявления непосредственно в аккаунте). Ассоциативный подбор родственных запросов, размещенный там, предлагает такие запросы, которые никогда не найдет wordstat.yandex.ru.
Предсказание запросов. Если вы получили запрос «как работает экспозамер в Nikon D7000», есть некоторые шансы, что в природе существуют также запросы «как работает экспозамер в…». Поскольку моделей фотоаппаратов много, запросов тоже получается много. К слову, закрыть их можно автоматическим созданием контента – необходимо лишь, чтобы формулу для генерирования создавал кто-то, знакомый с предметной областью.
В результате такого массированного сбора семантики мы получаем обширный список, который может содержать несколько десятков тысяч (в отдельных случаях несколько миллионов) запросов. Разумеется, в этом списке велика доля пустых запросов, которые никогда не принесут трафика. Поэтому следующий этап – чистка семантического ядра.
Чистка семантического ядра
Необходимость чистки семантического ядра связана с наличием в статистике wordstat.yandex.ru пустых, накрученных и неконверсионных запросов.
 Рис. 3.4
Рис. 3.4
Пустые запросы – это запросы, которые не приносят трафика, но при этом имеют неплохие показатели в статистике wordstat.yandex.ru.
Большое количество пустых запросов в этом сервисе связано с его назначением и механизмом работы. Ведь предназначен wordstat.yandex.ru не для формирования семантического ядра, а для работы с контекстной рекламой. Специфика же контекстной рекламы заключается в том, что система пытается обеспечить максимальный охват по ключевому слову. Таким образом, покупая клики по ключевому слову «мебель», мы получим показы по всем запросам с вхождением этого слова вплоть до «какую мебель любил Петр Великий». Это составляет определенную проблему для специалистов по контексту, однако с точки зрения сбора семантики для нас важно другое – то, что wordstat.yandex.ru работает аналогичным образом. Говоря иными словами, показатель просмотров по результату запроса «мебель» представляет собой сумму всех просмотров с вхождением этого слова. При этом собственно запрос может приносить очень мало трафика или не приносить вообще. В случае если трафик очень мал, а статистика показывает большие цифры, мы можем говорить о пустом запросе.
Пример из жизни: руководитель компании заказал создание контекстной рекламной кампании по запросу «квартиры под ключ». На предложение подключить еще и SEO категорически и довольно резко отказался. В ходе обсуждения проблемы выяснилось, что он уже находился на ведущих позициях в «Яндекс.Директ» и выдаче по запросу «квартиры под ключ» одновременно, причем посетителей с контекстных объявлений было много, а из органической выдачи практически не было. Объяснить ему, что в контексте он закупал трафик со всех запросов с вхождением «квартиры под ключ», а продвигался только по одному этому практически пустому запросу, было сложно.
Самый простой способ обнаружить пустые запросы – ввести их в wordstat.yandex.ru в кавычках. В этом случае он отсекает производные и дает довольно точное число показов – правда, без учета словоформ. Далее необходимо высчитать соотношение реального числа показов к общему и отсортировать запросы по этому показателю. Запросы с наибольшим соотношением являются наиболее продуктивными. Запрос «квартиры под ключ» в этом смысле совершенно непродуктивен (на момент написания этого раздела соотношение было 206:15 956). С учетом того, какая конкурентная борьба разворачивается за 206 показов, его можно считать пустым и дать ему самый низкий приоритет либо вообще исключить из ядра.
Для того чтобы эффективно очистить семантическое ядро от таких запросов, надо иметь представление о проблемной области и интересах пользователей. Впрочем, некоторые типы ненужных запросов бросаются в глаза сразу, например:
□ запросы с вхождением года («мебель 2010», «диваны 2009»);
□ геозапросы, частотность которых значительно отличается от частотности геозапросов по другим регионам с аналогичной и даже большей численностью населения. Если «диваны станица Голубицкая» имеют частотность на порядки большую, чем «диваны Темрюк», это однозначно говорит о том, что какой-то голубицкий оптимизатор решил продать бесполезный запрос подороже. При этом все же необходимо иметь представление о предмете, поскольку «мебель Шатура» означает совсем не то, что «мебель Сергиев Посад»;
□ запросы, частотность которых резко отличается от частотности аналогичных. Условный пример: «купить голубой диван» – 2, «купить синий диван» – 2500 – так не бывает;
□ запросы с непонятным синтаксисом, например «диван 30 километрах»;
□ применительно к магазинам следует удалить запросы, связанные с продажей бывших в употреблении, самодельных вещей, с их ремонтом, историей и т. д. Например, «дивану бу», «диван из раскладушки своими руками», «починить диван без пружин», «кто придумал диваны» вряд ли дадут посетителей, заинтересованных в покупке дивана. Вместе с тем многие такие запросы могут постоянно собирать полезный для информационного портала трафик, а потому решением об их исключении следует принимать, исходя из итоговых целей и задач продвижения.
Изучение потребностей пользователей иллюстрирует следующая таблица.
 Стоп-слова. Если при продвижении порталов нам необходим практически любой трафик, то интернет-магазинам нужны продажи. Продвигать интернет-магазин по тематическим некоммерческим запросам – почти пустая трата ресурсов (почти – потому что полнота охвата тематики все же будет бонусом при продвижении высокочастотных запросов), а потому лучше сразу исключить такие запросы из семантического ядра.
Стоп-слова. Если при продвижении порталов нам необходим практически любой трафик, то интернет-магазинам нужны продажи. Продвигать интернет-магазин по тематическим некоммерческим запросам – почти пустая трата ресурсов (почти – потому что полнота охвата тематики все же будет бонусом при продвижении высокочастотных запросов), а потому лучше сразу исключить такие запросы из семантического ядра.
Одним из способов быстро исключить большое количество некоммерческих запросов является использование стоп-слов. Пользователи, приходящие по запросам, содержащим «скачать бесплатно», «сделать самому», «своими руками», «как отремонтировать», «скачать инструкцию», «история производства», однозначно ничего не купят, а потому вы можете убрать эти запросы автоматически и сэкономить немало времени. Сформируйте собственный список стоп-слов, исходя из своей тематики, причем он может быть уникальным для каждого тематического кластера.
Пустые запросы – это запросы, которые не приносят трафика, но при этом имеют неплохие показатели в статистике wordstat.yandex.ru.
Большое количество пустых запросов в этом сервисе связано с его назначением и механизмом работы. Ведь предназначен wordstat.yandex.ru не для формирования семантического ядра, а для работы с контекстной рекламой. Специфика же контекстной рекламы заключается в том, что система пытается обеспечить максимальный охват по ключевому слову. Таким образом, покупая клики по ключевому слову «мебель», мы получим показы по всем запросам с вхождением этого слова вплоть до «какую мебель любил Петр Великий». Это составляет определенную проблему для специалистов по контексту, однако с точки зрения сбора семантики для нас важно другое – то, что wordstat.yandex.ru работает аналогичным образом. Говоря иными словами, показатель просмотров по результату запроса «мебель» представляет собой сумму всех просмотров с вхождением этого слова. При этом собственно запрос может приносить очень мало трафика или не приносить вообще. В случае если трафик очень мал, а статистика показывает большие цифры, мы можем говорить о пустом запросе.
Пример из жизни: руководитель компании заказал создание контекстной рекламной кампании по запросу «квартиры под ключ». На предложение подключить еще и SEO категорически и довольно резко отказался. В ходе обсуждения проблемы выяснилось, что он уже находился на ведущих позициях в «Яндекс.Директ» и выдаче по запросу «квартиры под ключ» одновременно, причем посетителей с контекстных объявлений было много, а из органической выдачи практически не было. Объяснить ему, что в контексте он закупал трафик со всех запросов с вхождением «квартиры под ключ», а продвигался только по одному этому практически пустому запросу, было сложно.
Самый простой способ обнаружить пустые запросы – ввести их в wordstat.yandex.ru в кавычках. В этом случае он отсекает производные и дает довольно точное число показов – правда, без учета словоформ. Далее необходимо высчитать соотношение реального числа показов к общему и отсортировать запросы по этому показателю. Запросы с наибольшим соотношением являются наиболее продуктивными. Запрос «квартиры под ключ» в этом смысле совершенно непродуктивен (на момент написания этого раздела соотношение было 206:15 956). С учетом того, какая конкурентная борьба разворачивается за 206 показов, его можно считать пустым и дать ему самый низкий приоритет либо вообще исключить из ядра.
ДМИТРИЙ ИВАНОВ:Итак, на выходе у нас есть перечень запросов, худо-бедно отсортированных по эффективности. Теперь наша задача – убрать из него накрученные запросы и запросы, которые не несут целевого трафика.
«Ключевики с нулевой полнотой не несут в себе трафика и являются пустышками, появившимися в ядре по разным причинам. Так, например, к их появлению может привести использование автоматизированных сервисов по сбору семантики, которые пытаются подобрать максимальное количество словоформ под шаблонные запросы и дополняют их, комбинируя все возможные варианты. Такие сервисы, как правило, могут собрать действительно полное семантическое ядро, но также они дают ключи с нулевой полнотой, от которых необходимо избавиться. Очень важно пользоваться автоматизацией, но любую семантику, полученную машинным сбором, нужно проверять вручную, дополнять и группировать.
Нулевая полнота может появиться также как результат сезонности запроса. Например, кондиционеры практически не продаются зимой, а обогреватели – летом. При составлении ядра следует учитывать и эти факторы. Не забывайте также о географии запроса. Прежде чем продвигать запрос в регионе, убедитесь, что его действительно там задают. Так, например, "купить лексус" – не самый популярный запрос за пределами больших городов».
Для того чтобы эффективно очистить семантическое ядро от таких запросов, надо иметь представление о проблемной области и интересах пользователей. Впрочем, некоторые типы ненужных запросов бросаются в глаза сразу, например:
□ запросы с вхождением года («мебель 2010», «диваны 2009»);
□ геозапросы, частотность которых значительно отличается от частотности геозапросов по другим регионам с аналогичной и даже большей численностью населения. Если «диваны станица Голубицкая» имеют частотность на порядки большую, чем «диваны Темрюк», это однозначно говорит о том, что какой-то голубицкий оптимизатор решил продать бесполезный запрос подороже. При этом все же необходимо иметь представление о предмете, поскольку «мебель Шатура» означает совсем не то, что «мебель Сергиев Посад»;
□ запросы, частотность которых резко отличается от частотности аналогичных. Условный пример: «купить голубой диван» – 2, «купить синий диван» – 2500 – так не бывает;
□ запросы с непонятным синтаксисом, например «диван 30 километрах»;
□ применительно к магазинам следует удалить запросы, связанные с продажей бывших в употреблении, самодельных вещей, с их ремонтом, историей и т. д. Например, «дивану бу», «диван из раскладушки своими руками», «починить диван без пружин», «кто придумал диваны» вряд ли дадут посетителей, заинтересованных в покупке дивана. Вместе с тем многие такие запросы могут постоянно собирать полезный для информационного портала трафик, а потому решением об их исключении следует принимать, исходя из итоговых целей и задач продвижения.
Изучение потребностей пользователей иллюстрирует следующая таблица.
Одним из способов быстро исключить большое количество некоммерческих запросов является использование стоп-слов. Пользователи, приходящие по запросам, содержащим «скачать бесплатно», «сделать самому», «своими руками», «как отремонтировать», «скачать инструкцию», «история производства», однозначно ничего не купят, а потому вы можете убрать эти запросы автоматически и сэкономить немало времени. Сформируйте собственный список стоп-слов, исходя из своей тематики, причем он может быть уникальным для каждого тематического кластера.
Оценка конкурентоспособности запросов
Очевидно, что даже среди запросов с примерно одинаковой частотностью есть запросы с разным уровнем конкурентоспособности. Перед нами стоит задача в итоге лидировать в выдаче по всем запросам, однако разумнее начать с тех, продвинуться по которым будет проще. Для этого необходимо сначала определить их.
Для оценки конкурентоспособности не нужны сложные аналитические инструменты, хотя они могут серьезно ускорить работу. Вам понадобятся:
□ сервис Solomono.ru;
□ выдача «Яндекса»;
□ любой сервис, который будет определять основные SEO-параметры доменов.
Примерный алгоритм действий такой.
1. Вводим поисковый запрос в «Яндекс».
2. Анализируем внешние ссылки, ведущие на страницы, которые находятся в первой пятерке выдачи «Яндекса» по запросу. Если ссылок на страницы нет, запрос можно считать довольно низкоконкурентоспособным.
3. Анализируем содержимое тега Title. То, что прямого вхождения ключевой фразы нет, еще один показатель низкого уровня конкуренции за запрос.
4. Оцениваем основные SEO-параметры сайтов первой пятерки. Если в нее входят сайты с низким ТИЦ, не описанные в каталоге «Яндекса», с небольшим возрастом домена, это означает, что занять место одного их них будет несложно.
Для формализации процесса вы можете разработать собственную балльную систему оценки конкурентоспособности и на ее основе планировать этапы продвижения. Например, запросы, по которым в топ-5 выдаются страницы без вхождения в Title на доменах с возрастом менее года, – 1 балл, с возрастом от года до двух – 2 балла, с вхождением – 3 балла и т. д. Опытный оптимизатор легко сможет составить довольно точную шкалу с учетом тематики портала.
Как и любой другой рутинный процесс, оценка конкурентоспособности может быть в значительной степени автоматизирована. При этом не обязательно, чтобы система сразу могла определять конкурентоспособность на полном автомате, – даже если на начальном этапе она сможет только разбирать страницу выдачи и анализировать вхождение ключевого слова в Title, это уже позволит значительно повысить производительность труда. Добавляя такой программе новые функции, со временем вы можете получить убийственно эффективный аналитический инструмент.
Для оценки конкурентоспособности не нужны сложные аналитические инструменты, хотя они могут серьезно ускорить работу. Вам понадобятся:
□ сервис Solomono.ru;
□ выдача «Яндекса»;
□ любой сервис, который будет определять основные SEO-параметры доменов.
Примерный алгоритм действий такой.
1. Вводим поисковый запрос в «Яндекс».
2. Анализируем внешние ссылки, ведущие на страницы, которые находятся в первой пятерке выдачи «Яндекса» по запросу. Если ссылок на страницы нет, запрос можно считать довольно низкоконкурентоспособным.
3. Анализируем содержимое тега Title. То, что прямого вхождения ключевой фразы нет, еще один показатель низкого уровня конкуренции за запрос.
4. Оцениваем основные SEO-параметры сайтов первой пятерки. Если в нее входят сайты с низким ТИЦ, не описанные в каталоге «Яндекса», с небольшим возрастом домена, это означает, что занять место одного их них будет несложно.
Для формализации процесса вы можете разработать собственную балльную систему оценки конкурентоспособности и на ее основе планировать этапы продвижения. Например, запросы, по которым в топ-5 выдаются страницы без вхождения в Title на доменах с возрастом менее года, – 1 балл, с возрастом от года до двух – 2 балла, с вхождением – 3 балла и т. д. Опытный оптимизатор легко сможет составить довольно точную шкалу с учетом тематики портала.
Как и любой другой рутинный процесс, оценка конкурентоспособности может быть в значительной степени автоматизирована. При этом не обязательно, чтобы система сразу могла определять конкурентоспособность на полном автомате, – даже если на начальном этапе она сможет только разбирать страницу выдачи и анализировать вхождение ключевого слова в Title, это уже позволит значительно повысить производительность труда. Добавляя такой программе новые функции, со временем вы можете получить убийственно эффективный аналитический инструмент.
Создание групп запросов
После чистки мы получим очень длинный список, состоящий из важных для нашего портала либо интернет-магазина запросов, однако работать с этим списком будет крайне сложно, поскольку он неструктурирован. Следующая задача – выстроить структуру, разбив список на группы.
Создавая группы, следует исходить из особенностей предметной области и специфики бизнеса. Применительно к мебели будет логичным разделить ее, например, следующим образом:
□ мебель для офиса;
□ письменные столы;
□ шкафы для документов;
□ выкатные тумбы;
□ приставные тумбы;
□ приставки;
□ кабинеты;
□ офисные кресла;
□ мебель для руководителя;
□ мебель для переговорной;
□ мебель для дома;
□ мебель для кухни;
□ мебель для прихожей;
□ мебель для спальни;
□ мебель для гостиной;
□ торговая мебель;
□ мебель для кафе и ресторанов;
□ садовая мебель.
Очевидно, что категории второго уровня вложенности будут делиться и далее. Так, категория «письменные столы», входящая в «офисную мебель», может включать в себя категории четвертого уровня вложенности «экономкласс», «бизнес-класс», «элитные», «садовая мебель» может включать «садовую мебель из пластмассы», «садовую мебель из ротанга» и т. п.
После того как структура будет полностью выстроена, необходимо распределить все запросы по группам. И возникает проблема – необходимость внести один запрос сразу в несколько групп. К примеру, «письменные столы» могут быть отнесены к категориям «письменные столы», «кабинеты», «мебель для переговорной» и «детская мебель».
Следует ли внести этот запрос во все группы, к которым он может иметь отношение?
Ответ на этот вопрос однозначно отрицательный. Каждый запрос должен находиться только в одной группе и продвигаться только на одной странице. В том случае, если запрос может иметь отношение к разным категориям, следует выбрать только одну, исходя из приоритетов бизнеса или трафика (например, если на портале планируется создать мощный раздел по детской мебели, лучше будет увеличить именно его).
Что делать с синонимами? Запросы-синонимы должны быть представлены на одной странице, которая оптимизируется под каждый из них. В подавляющем большинстве случаев сделать это несложно.
Создавая группы, следует исходить из особенностей предметной области и специфики бизнеса. Применительно к мебели будет логичным разделить ее, например, следующим образом:
□ мебель для офиса;
□ письменные столы;
□ шкафы для документов;
□ выкатные тумбы;
□ приставные тумбы;
□ приставки;
□ кабинеты;
□ офисные кресла;
□ мебель для руководителя;
□ мебель для переговорной;
□ мебель для дома;
□ мебель для кухни;
□ мебель для прихожей;
□ мебель для спальни;
□ мебель для гостиной;
□ торговая мебель;
□ мебель для кафе и ресторанов;
□ садовая мебель.
Очевидно, что категории второго уровня вложенности будут делиться и далее. Так, категория «письменные столы», входящая в «офисную мебель», может включать в себя категории четвертого уровня вложенности «экономкласс», «бизнес-класс», «элитные», «садовая мебель» может включать «садовую мебель из пластмассы», «садовую мебель из ротанга» и т. п.
После того как структура будет полностью выстроена, необходимо распределить все запросы по группам. И возникает проблема – необходимость внести один запрос сразу в несколько групп. К примеру, «письменные столы» могут быть отнесены к категориям «письменные столы», «кабинеты», «мебель для переговорной» и «детская мебель».
Следует ли внести этот запрос во все группы, к которым он может иметь отношение?
Ответ на этот вопрос однозначно отрицательный. Каждый запрос должен находиться только в одной группе и продвигаться только на одной странице. В том случае, если запрос может иметь отношение к разным категориям, следует выбрать только одну, исходя из приоритетов бизнеса или трафика (например, если на портале планируется создать мощный раздел по детской мебели, лучше будет увеличить именно его).
Что делать с синонимами? Запросы-синонимы должны быть представлены на одной странице, которая оптимизируется под каждый из них. В подавляющем большинстве случаев сделать это несложно.
Почему так важно охватить все ядро
Первая причина, по которой нам необходимо составить как можно более полное семантическое ядро и затем отработать его при создании контента, очевидна. Больше запросов – больше трафика, а именно большой трафик является нашей целью. Вторая причина менее очевидна, однако она тоже имеет отношение к трафику.
Суть проста: чем больше у вас контента, релевантного разным низкочастотным запросам, тем больше шансов, что алгоритмы сочтут его достойным высоких позиций и по высокочастотным. Проще говоря, для того, чтобы уверенно занимать лидирующие позиции по запросу «мебель» и т. д., придется создать довольно большой объем контента по самым низкочастотным запросам. В противном случае лидером окажется другой портал. Разумеется, это не строгое правило, но тенденция очевидна и лишь усиливается. Кроме того, большое количество контента позволяет получить больше естественных ссылок на разные страницы с разными анкорами, что делает продвижение как минимум более стабильным. Именно по этой причине не стоит пренебрегать низкочастотными запросами, даже если они на первый взгляд не очень нужны.
Суть проста: чем больше у вас контента, релевантного разным низкочастотным запросам, тем больше шансов, что алгоритмы сочтут его достойным высоких позиций и по высокочастотным. Проще говоря, для того, чтобы уверенно занимать лидирующие позиции по запросу «мебель» и т. д., придется создать довольно большой объем контента по самым низкочастотным запросам. В противном случае лидером окажется другой портал. Разумеется, это не строгое правило, но тенденция очевидна и лишь усиливается. Кроме того, большое количество контента позволяет получить больше естественных ссылок на разные страницы с разными анкорами, что делает продвижение как минимум более стабильным. Именно по этой причине не стоит пренебрегать низкочастотными запросами, даже если они на первый взгляд не очень нужны.
Пополнение и обновление ядра после запуска портала
Пользовательские интересы не остаются неизменными. Любое явление реального мира сразу же отражается на интересах, а те, в свою очередь, – на запросах, которые вводят пользователи. Именно поэтому нельзя составить семантическое ядро раз и навсегда. Его необходимо регулярно дополнять и обновлять.
Какие факторы могут стать причиной изменения структуры запросов?
□ Появление новых моделей техники, выход новых фильмов, альбомов и т. п. Тут все понятно – первые запросы появляются сразу после анонса или появления слухов о выходе, затем всплеск интереса сразу после выхода, затем довольно долго количество запросов близко к пику и только после выхода новой модели, фильма, книги и т. п. начинает угасать. Продолжительность пикового интереса может колебаться от пары недель (фильм) до нескольких лет (новая марка автомобиля).
□ Появление новых, ранее неизвестных аспектов явления. Например, сразу после выхода автомобиля список запросов невелик и включает в себя традиционные «автомобиль дата выхода», «автомобиль цена», «купить автомобиль», «автомобиль краш-тест». По мере роста спроса и появления опыта эксплуатации к запросу добавляются «автомобиль запчасти», «купить фару для автомобиль», «заедает клаксон автомобиль» и т. п. Таким образом, со временем ядро прирастает большим количеством низкочастотных (а иногда и не слишком низкочастотных) запросов, и было бы просто неразумно не использовать эту возможность.
□ Сезонность. К примеру, если вы начали работу над ядром для туристического сайта во время мертвого сезона, многие низкочастотные запросы просто выпадут из поля зрения. На пике сезона, когда интерес к отдыху и турам вырастет многократно, они возникнут практически ниоткуда. Отчасти эта проблема решается правильной работой со статистикой по месяцам, но лишь отчасти.
□ События, которые изменяют отношение к явлению, новые факты, интернет-мемы и т. п. Работа с такими запросами – часть работы с событийным трафиком, которая сама по себе является темой для небольшого учебного пособия. Отметим лишь, что систематическая и вдумчивая работа с таким трафиком позволяет периодически получать взрывной рост посещаемости и значительный приток естественных ссылок.
Как часто обновлять ядро? Если ваш портал посвящен технике, кино, музыке и т. п. – практически ежедневно. Сигналом к работе над ядром становятся информационные поводы. Анонс новой модели автомобиля – однозначный повод запускать в работу весь хорошо известный спектр запросов, связанных с авто (благо они практически универсальны для всех моделей). Одновременно с пополнением ядра запросами по новому объекту имеет смысл проверить структуру запросов по тому, что было выпущено/издано в течение последних месяцев, – статистические сервисы вполне могут выдать нечто неожиданное. Таким образом, затрачивая сравнительно немного времени на поддержание семантического ядра, вы всегда будете двигаться в ногу со временем и давать пользователям актуальный и интересный контент.
В тематиках, где анонсы и релизы не являются значимым явлением, ядро можно просматривать раз в три месяца и даже реже. Так, к примеру, магазин мебели едва ли может получить какие-то принципиально новые ключевые слова в большом количестве. В лучшем случае это будут трудноконвертируемые низкочастотные запросы, связанные с выходом новых коллекций.
Какие факторы могут стать причиной изменения структуры запросов?
□ Появление новых моделей техники, выход новых фильмов, альбомов и т. п. Тут все понятно – первые запросы появляются сразу после анонса или появления слухов о выходе, затем всплеск интереса сразу после выхода, затем довольно долго количество запросов близко к пику и только после выхода новой модели, фильма, книги и т. п. начинает угасать. Продолжительность пикового интереса может колебаться от пары недель (фильм) до нескольких лет (новая марка автомобиля).
□ Появление новых, ранее неизвестных аспектов явления. Например, сразу после выхода автомобиля список запросов невелик и включает в себя традиционные «автомобиль дата выхода», «автомобиль цена», «купить автомобиль», «автомобиль краш-тест». По мере роста спроса и появления опыта эксплуатации к запросу добавляются «автомобиль запчасти», «купить фару для автомобиль», «заедает клаксон автомобиль» и т. п. Таким образом, со временем ядро прирастает большим количеством низкочастотных (а иногда и не слишком низкочастотных) запросов, и было бы просто неразумно не использовать эту возможность.
□ Сезонность. К примеру, если вы начали работу над ядром для туристического сайта во время мертвого сезона, многие низкочастотные запросы просто выпадут из поля зрения. На пике сезона, когда интерес к отдыху и турам вырастет многократно, они возникнут практически ниоткуда. Отчасти эта проблема решается правильной работой со статистикой по месяцам, но лишь отчасти.
□ События, которые изменяют отношение к явлению, новые факты, интернет-мемы и т. п. Работа с такими запросами – часть работы с событийным трафиком, которая сама по себе является темой для небольшого учебного пособия. Отметим лишь, что систематическая и вдумчивая работа с таким трафиком позволяет периодически получать взрывной рост посещаемости и значительный приток естественных ссылок.
Как часто обновлять ядро? Если ваш портал посвящен технике, кино, музыке и т. п. – практически ежедневно. Сигналом к работе над ядром становятся информационные поводы. Анонс новой модели автомобиля – однозначный повод запускать в работу весь хорошо известный спектр запросов, связанных с авто (благо они практически универсальны для всех моделей). Одновременно с пополнением ядра запросами по новому объекту имеет смысл проверить структуру запросов по тому, что было выпущено/издано в течение последних месяцев, – статистические сервисы вполне могут выдать нечто неожиданное. Таким образом, затрачивая сравнительно немного времени на поддержание семантического ядра, вы всегда будете двигаться в ногу со временем и давать пользователям актуальный и интересный контент.
В тематиках, где анонсы и релизы не являются значимым явлением, ядро можно просматривать раз в три месяца и даже реже. Так, к примеру, магазин мебели едва ли может получить какие-то принципиально новые ключевые слова в большом количестве. В лучшем случае это будут трудноконвертируемые низкочастотные запросы, связанные с выходом новых коллекций.
Альтернативный способ создания ядра
Как уже отмечалось, семантическое ядро портала имеет одну важную особенность – оно большое. Очень большое. Некоторые туристические порталы используют для продвижения ядро, включающее порядка 100 000 запросов, а если они планируют собирать трафик по запросам с частотностью 1-5 в месяц, оно может вырасти примерно в два раза.
Средний оптимизатор может составить за один день семантическое ядро объемом 1000 запросов. На 100 000 запросов уйдет 100 дней. Три месяца.
Очевидно, что это слишком долго, а потому необходимо автоматизировать процесс. Автоматический парсер справится с задачей быстро, но качество продукта получится низким. Вместе с тем начинать следует именно с автоматического сбора ядра, которое затем очищать и улучшать вручную.
В качестве примера, иллюстрирующего правильную организацию, рассмотрим создание семантического ядра для последующего генерирования контента туристического портала.
Создание масок запросов. Для этой цели оптимизатор может использовать wordstat.yandex.ru, базу Пастухова, статистику собственного портала или все вместе. Его задача – собрать все распространенные формулы типа «туры страна», «тура страна месяц», «туры страна курорт», «отель курорт месяц» и т. д.
Создание базы слов. Для этой цели отлично подходит Excel. Мы просто собираем в колонку «Страны» все страны, в колонку «Курорты» – все курорты и т. д. При наличии баз курортов и отелей (такие базы можно найти, составить или собрать парсером) задача решается очень быстро.
Генерирование запросов. Имея формулу с переменными и массив значений для этих переменных, мы можем легко сгенерировать огромный массив запросов.
Для проведения работ, описанных в этих трех пунктах, оптимизатор просто не нужен – набить базу значений может его помощник или любой другой просто неглупый и грамотный человек, а программу для генерирования должен написать программист. От оптимизатора требуется лишь проконтролировать полноту сбора возможных значений.
Первая действительно более или менее интеллектуальная работа – сортировка получившегося ядра. Необходимо отбросить заведомо абсурдные варианты, такие как «купить детский тур в Сомали». Впрочем, можно и оставить – для поисковых алгоритмов портал, содержащий страницы, оптимизированный под такие запросы, – не дорвей, а сайт, представляющий более полную информацию по теме «туризм».
Сбор запросов, не укладывающихся в стандартные формулы, – действительно тонкая интеллектуальная работа. Примером такого запроса может быть «поморье бей» – это отнюдь не призыв к борьбе с российским регионом, а своеобразный транслит названия гостиницы Pomorie Bay Apartments and Spa.
Остальное – оценка сложности продвижения и распределение по страницам – уже описывалось.
Средний оптимизатор может составить за один день семантическое ядро объемом 1000 запросов. На 100 000 запросов уйдет 100 дней. Три месяца.
Очевидно, что это слишком долго, а потому необходимо автоматизировать процесс. Автоматический парсер справится с задачей быстро, но качество продукта получится низким. Вместе с тем начинать следует именно с автоматического сбора ядра, которое затем очищать и улучшать вручную.
В качестве примера, иллюстрирующего правильную организацию, рассмотрим создание семантического ядра для последующего генерирования контента туристического портала.
Создание масок запросов. Для этой цели оптимизатор может использовать wordstat.yandex.ru, базу Пастухова, статистику собственного портала или все вместе. Его задача – собрать все распространенные формулы типа «туры страна», «тура страна месяц», «туры страна курорт», «отель курорт месяц» и т. д.
Создание базы слов. Для этой цели отлично подходит Excel. Мы просто собираем в колонку «Страны» все страны, в колонку «Курорты» – все курорты и т. д. При наличии баз курортов и отелей (такие базы можно найти, составить или собрать парсером) задача решается очень быстро.
Генерирование запросов. Имея формулу с переменными и массив значений для этих переменных, мы можем легко сгенерировать огромный массив запросов.
Для проведения работ, описанных в этих трех пунктах, оптимизатор просто не нужен – набить базу значений может его помощник или любой другой просто неглупый и грамотный человек, а программу для генерирования должен написать программист. От оптимизатора требуется лишь проконтролировать полноту сбора возможных значений.
Первая действительно более или менее интеллектуальная работа – сортировка получившегося ядра. Необходимо отбросить заведомо абсурдные варианты, такие как «купить детский тур в Сомали». Впрочем, можно и оставить – для поисковых алгоритмов портал, содержащий страницы, оптимизированный под такие запросы, – не дорвей, а сайт, представляющий более полную информацию по теме «туризм».
Сбор запросов, не укладывающихся в стандартные формулы, – действительно тонкая интеллектуальная работа. Примером такого запроса может быть «поморье бей» – это отнюдь не призыв к борьбе с российским регионом, а своеобразный транслит названия гостиницы Pomorie Bay Apartments and Spa.
Остальное – оценка сложности продвижения и распределение по страницам – уже описывалось.
ДМИТРИЙ ИВАНОВ:
«Создание максимально полного семантического ядра является одним из важнейших этапов при продвижении крупных порталов, в особенности интернет-магазинов. Необходимо не просто подбирать слова, по которым люди могут прийти на сайт, – нужно изучать спрос, сопоставлять его с возможностями заказчика, определять приоритетные категории и находить пустоты в списке предложений. Полноту семантики сложно переоценить – от того, кто и как составлял ядро, зависит конвертация трафика и в итоге будущая прибыль.