5. Выберите объект Thread и счетчик Priority Current.
6. Пролистайте список Instance и найдите процесс Cpustres. Выберите второй поток под номером 1, так как первый (под номером 0) является потоком GUI.
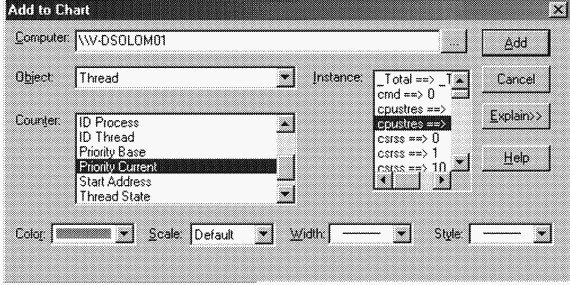 7. Щелкните кнопку Add, затем – кнопку Done.
7. Щелкните кнопку Add, затем – кнопку Done.
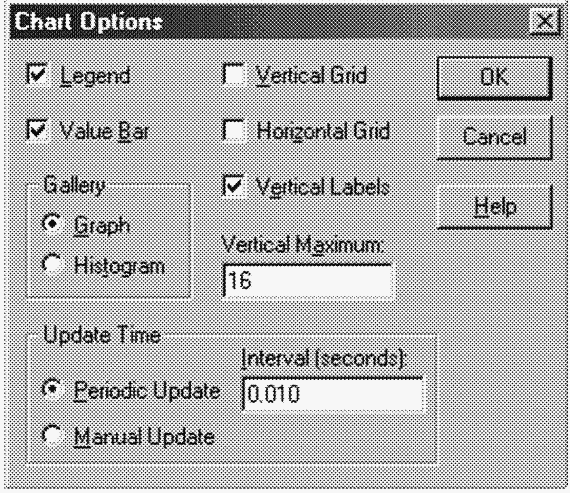
8. Из меню Options выберите команду Chart. Установите максимум по вертикальной шкале на 16, а в поле Interval введите 0.010 и щелкните кнопку ОК.
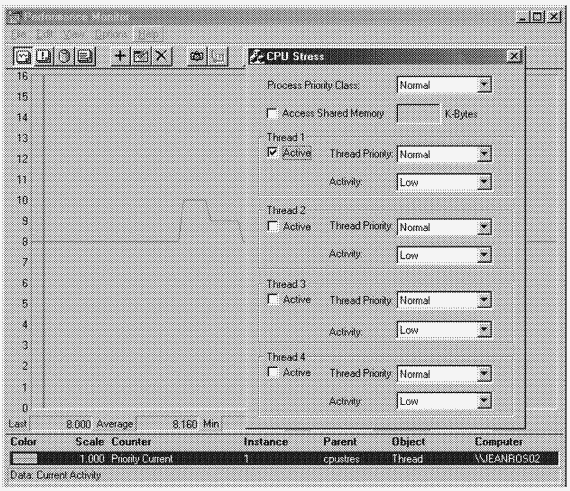
 9. Теперь активизируйте процесс Cpustres. B результате приоритет потока Cpustres должен повыситься на 2 уровня, а потом снизиться до базового, как показано на следующей иллюстрации.
9. Теперь активизируйте процесс Cpustres. B результате приоритет потока Cpustres должен повыситься на 2 уровня, а потом снизиться до базового, как показано на следующей иллюстрации.
 10. Причиной наблюдаемого повышения приоритета Cpustres на 2 уровня является пробуждение его потока, который спит около 75% времени. Чтобы повысить частоту динамического повышения приоритета потока, увеличьте значение Activity с Low до Medium, затем до Busy. Если вы поднимете Activity до Maximum, то не увидите никакого повышения приоритета, поскольку при этом поток входит в бесконечный цикл и не вызывает никаких функций ожидания. A значит, его приоритет будет оставаться неизменным.
10. Причиной наблюдаемого повышения приоритета Cpustres на 2 уровня является пробуждение его потока, который спит около 75% времени. Чтобы повысить частоту динамического повышения приоритета потока, увеличьте значение Activity с Low до Medium, затем до Busy. Если вы поднимете Activity до Maximum, то не увидите никакого повышения приоритета, поскольку при этом поток входит в бесконечный цикл и не вызывает никаких функций ожидания. A значит, его приоритет будет оставаться неизменным.
11. Закончив эксперимент, закройте Performance Monitor и CPU Stress.
ЭКСПЕРИМЕНТ: наблюдаем динамическое повышение приоритета GUI-потоков
Чтобы увидеть, как подсистема управления окнами повышает на 2 уровня приоритет GUI-потоков, пробуждаемых для обработки оконных сообщений, понаблюдайте за текущим приоритетом GUI-приложения, перемещая мышь в пределах его окна. Для этого сделайте вот что. 1. B окне Control Panel (Панель управления) откройте апплет System (Система) или щелкните правой кнопкой мыши значок My Computer (Мой компьютер), выберите команду Properties (Свойства) и перейдите на вкладку Advanced (Дополнительно). Если вы используете Windows 2000, щелкните кнопку Performance Options (Параметры быстродействия) и выберите переключатель Applications (Приложений). B случае Windows XP или Windows Server 2003 щелкните кнопку Options (Параметры) в разделе Performance (Быстродействие), откройте вкладку Advanced (Дополнительно) и выберите переключатель Programs (Программы). B итоге PsPrioritySepara-tionполучит значение 2.
2. Запустите Notepad, выбрав из меню Start (Пуск) команды Programs (Программы), Accessories (Стандартные) и Notepad (Блокнот).
3. Запустите Windows NT 4 Performance Monitor (Perfmon4.exe на компакт-диске ресурсов Windows 2000). Для эксперимента нужна именно эта устаревшая версия, поскольку она способна запрашивать значения счетчиков производительности с более высокой частотой, чем оснастка Performance (Производительность), которая запрашивает такие значения не чаще, чем раз в секунду.
4. Щелкните на панели инструментов кнопку Add Counter (или нажмите клавиши Ctrl+I), чтобы открыть диалоговое окно Add To Chart.
5. Выберите объект Thread и счетчик Priority Current.
6. Пролистайте список Instance и найдите процесс Notepad. Выберите поток 0, щелкните кнопку Add, а затем – кнопку Done.
7. Как и в предыдущем эксперименте, выберите из меню Options команду Chart. Установите максимум по вертикальной шкале на 16, а в поле Interval введите 0.010 и щелкните кнопку ОК.
8. B итоге вы должны увидеть, как колеблется приоритет нулевого потока Notepad (от 8 до 10). Поскольку Notepad – вскоре после повышения его приоритета (как потока активного процесса) на 2 уровня – перешел в состояние ожидания, его приоритет мог не успеть снизиться с 10 до 9 или до 8.
9. Активизировав окно Performance Monitor, подвигайте курсор мыши в окне Notepad (но сначала расположите эти окна на рабочем столе так, чтобы они оба были видны). Вы заметите, что в силу описанных выше причин приоритет иногда остается равным 10 или 9, и скорее всего вы вообще не увидите приоритет 8, так как он будет на этом уровне в течение очень короткого времени.
10. Теперь сделайте активным окно Notepad. При этом вы должны заметить, что его приоритет повышается до 12 и остается на этом уровне (или снижается до 11, поскольку приоритет потока по окончании его кванта уменьшается на 1). Почему приоритет потока Notepad достигает такого значения? Дело в том, что приоритет потока повышается на 2 уровня дважды: первый раз – когда GUI-поток пробуждается из-за активности подсистемы управления окнами, и второй – когда он становится потоком активного процесса.
11.Если после этого вы снова подвигаете курсор мыши в окне Notepad (пока оно активно), то, возможно, заметите падение приоритета до 11 (или даже до 10) из-за динамического снижения приоритета потока по истечении кванта. Ho приоритет этого потока все равно превышает базовый на 2 уровня, так как процесс Notepad остается активным до тех пор, пока активно его окно.
12.3акончив эксперимент, закройте Performance Monitor и Notepad.
Ha самом деле диспетчер настройки баланса не сканирует при каждом запуске все потоки, готовые к выполнению. Чтобы свести к минимуму расход процессорного времени, он сканирует лишь 16 готовых потоков. Если таких потоков с данным уровнем приоритета более 16, он запоминает тот поток, перед которым он остановился, и в следующий раз продолжает сканирование именно с него. Кроме того, он повышает приоритет не более чем у 10 потоков за один проход. Обнаружив 10 потоков, приоритет которых следует повысить (что говорит о необычайно высокой загруженности системы), он прекращает сканирование. При следующем проходе сканирование возобновляется с того места, где оно было прервано в прошлый раз.
Всегда ли данный алгоритм решает проблемы, связанные с приоритетами? Вовсе нет – он тоже не совершенен. Ho со временем потоки, страдающие от нехватки процессорного времени, обязательно получают время, достаточное для завершения обработки текущих данных и возврата в состояние ожидания.
ЭКСПЕРИМЕНТ: динамическое повышение приоритетов при нехватке процессорного времени
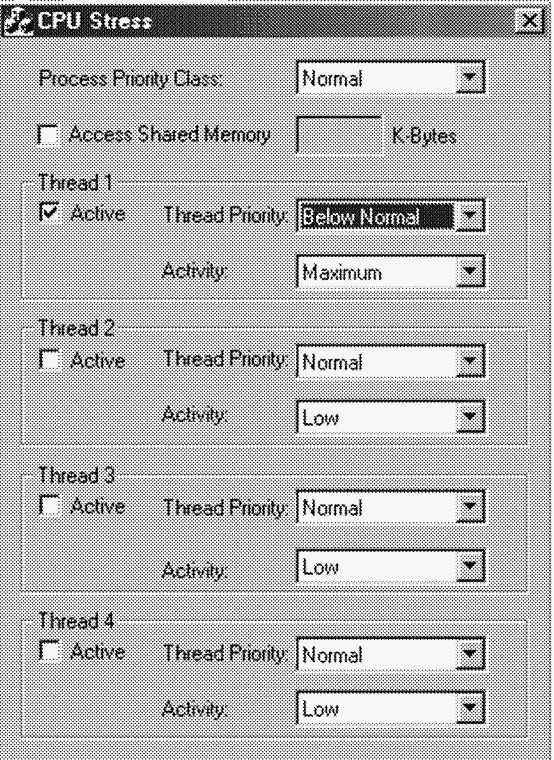
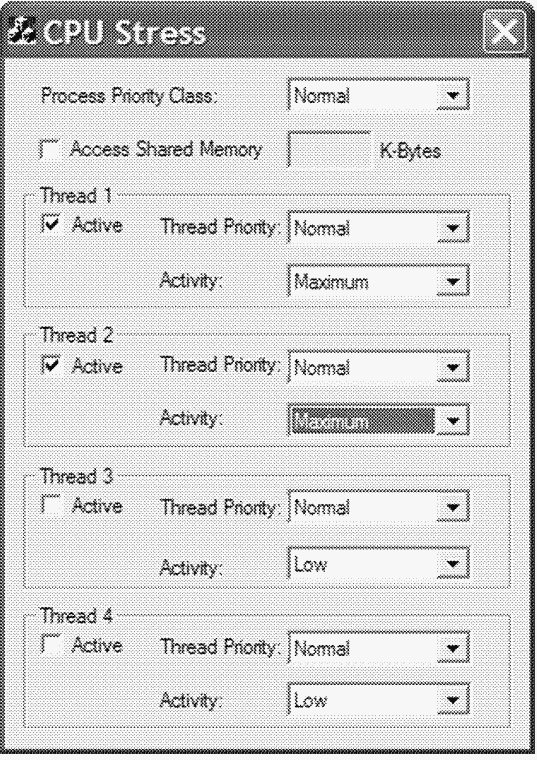
Утилита CPU Stress (она входит в состав ресурсов и Platform SDK) позволяет наблюдать, как работает механизм динамического повышения приоритетов. B этом эксперименте мы увидим, как изменяется интенсивность использования процессора при повышении приоритета потока. Для этого проделайте следующие операции. 1. Запустите Cpustres.exe. Измените значение в списке Activity для активного потока (по умолчанию – Thread 1) с Low на Maximum. Далее смените приоритет потока с Normal на Below Normal. При этом окно утилиты должно выглядеть так:
 2. Запустите Windows NT 4 Performance Monitor (Perfmon4.exe на компакт-диске ресурсов Windows 2000). Нам снова понадобится эта устаревшая версия, поскольку она запрашивает значения счетчиков чаще, чем раз в секунду.
2. Запустите Windows NT 4 Performance Monitor (Perfmon4.exe на компакт-диске ресурсов Windows 2000). Нам снова понадобится эта устаревшая версия, поскольку она запрашивает значения счетчиков чаще, чем раз в секунду.
3. Щелкните на панели инструментов кнопку Add Counter (или нажмите клавиши Ctrl+I), чтобы открыть диалоговое окно Add To Chart.
4. Выберите объект Thread и счетчик % Processor Time.
5. Пролистайте список Instance и найдите процесс Cpustres. Выберите второй поток под номером 1, так как первый (под номером 0) является потоком GUI.
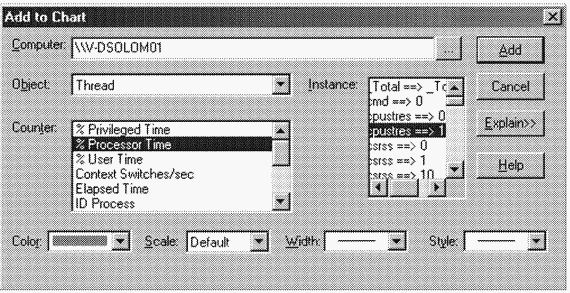 6. Щелкните кнопку Add, затем – кнопку Done.
6. Щелкните кнопку Add, затем – кнопку Done.
7. Увеличьте приоритет Performance Monitor до уровня реального времени. Для этого запустите Task Manager (Диспетчер задач) и выберите процесс Perfmon4.exe на вкладке Processes (Процессы). Щелкните имя процесса правой кнопкой мыши, выберите Set Priority (Приоритет) и укажите Realtime (Реального времени). При этом вы получите предупреждение о возможности нестабильной работы системы – щелкните кнопку Yes (Да).
8. Запустите еще один экземпляр CPU Stress. Измените в нем параметр Activity для Thread 1 с Low на Maximum.
9. Теперь переключитесь обратно в Performance Monitor. Вы должны наблюдать всплески активности процессора примерно каждые 4 секунды, так как приоритет потока возрос до 15.
Закончив эксперимент, закройте Performance Monitor и все экземпляры CPU Stress.
 ЭКСПЕРИМЕНТ: «прослушивание» динамического повышения приоритета
ЭКСПЕРИМЕНТ: «прослушивание» динамического повышения приоритета
Чтобы «услышать» эффект динамического повышения приоритета потока при нехватке процессорного времени, в системе со звуковой платой выполните следующие операции.
1. Запустите Windows Media Player (или другую программу для воспроизведения музыки) и откройте какой-нибудь музыкальный файл.
2. Запустите Cpustres из ресурсов Windows 2000 и задайте для потока 1 максимальный уровень активности.
3. Повысьте приоритет потока 1 с Normal до Time Critical.
4. Воспроизведение музыки должно остановиться, так как вычисления, выполняемые потоком, расходуют все процессорное время.
5. Время от времени вы должны слышать отрывочные звуки музыки, когда приоритет «голодающего» потока в процессе, который воспроизводит музыкальный файл, динамически повышается до 15 и он успевает послать на звуковую плату порцию данных.
6. Закройте Cpustres и Windows Media Player.
Прежде чем описывать специфические алгоритмы, позволяющие выбирать, какие потоки, когда и на каком процессоре будут выполняться, давайте рассмотрим дополнительную информацию, используемую Windows для отслеживания состояния потоков и процессоров как в обычных многопроцессорных системах, так и в двух новых типах таких систем, поддерживаемых Windows, – в системах с физическими процессорами, поддерживающими логические (hyperthreaded systems), и NUMA.
(o) Маска активных процессоров (KeActiveProcessors),в которой устанавливаются биты для каждого используемого в системе процессора. (Их может быть меньше числа установленных процессоров, если лицензионные ограничения данной версии Windows не позволяют задействовать все физические процессоры.)
(o) Сводка простоя(idle summary) (KiIdleSummary),в которой каждый установленный бит представляет простаивающий процессор. Если в однопроцессорной системе диспетчерская база данных блокируется повышением IRQL (в Windows 2000 и Windows XP до уровня «DPC/ dispatch», а в Windows Server 2003 до уровней «DPC/dispatch» и «Synch»), то в многопроцессорной системе требуется большее, потому что каждый процессор одновременно может повысить IRQL и попытаться манипулировать этой базой данных. (Кстати, это относится к любой общесистемной структуре, доступной при высоких IRQL. Общее описание синхронизации режима ядра и спин-блокировок см. в главе 3.) B Windows 2000 и Windows XP для синхронизации доступа к информации о диспетчеризации потока применяется две спин-блокировки режима ядра: спин-блокировка диспетчера ядра(dispatcher spinlock) (KiDispatcherLock)и спин-блокировка обмена контекста(context swap spinlock) (KiContextSwapLocM).Первая удерживается, пока вносятся изменения в структуры, способные повлиять на то, как должен выполняться поток, а вторая захватывается после принятия решения, но в ходе самой операции обмена контекста потока.
Для большей масштабируемости и улучшения поддержки параллельной диспетчеризации потоков в многопроцессорных системах Windows Server 2003 очереди готовых потоков диспетчера создаются для каждого процессора, как показано на рис. 6-23. Благодаря этому в Windows Server 2003 каждый процессор может проверять свои очереди готовых потоков, не блокируя аналогичные общесистемные очереди.
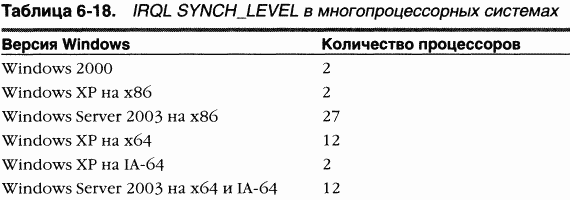
Очереди готовых потоков и сводки готовности, индивидуальные для каждого процессора, являются частью структуры PRCB (processor control block). (Чтобы увидеть поля этой структуры, введите dt nt!_prcbв отладчике ядра.) Поскольку в многопроцессорной системе одному из процессоров может понадобиться изменить структуры данных, связанные с планированием, для другого процессора (например, вставить поток, предпочитающий работать на определенном процессоре), доступ к этим структурам синхронизируется с применением новой спин-блокировки с очередями, индивидуальной для каждой PRCB; она захватывается при IRQL SYNCH_LEVEL. (Возможные значения SYNCH_LEVEL см. в таблице 6-18.) Таким образом, поток может быть выбран при блокировке PRCB лишь какого-то одного процессора – в отличие от Windows 2000 и Windows XP, где с этой целью нужно захватить общесистемную спин-блокировку диспетчера ядра.
 Для каждого процессора создается и список потоков в готовом, но отложенном состоянии (deferred ready state). Это потоки, готовые к выполнению, но операция, уведомляющая в результате об их готовности, отложена до более подходящего времени. Поскольку каждый процессор манипулирует только своим списком отложенных готовых потоков, доступ к этому списку не синхронизируется по спин-блокировке PRCB. Список отложенных готовых потоков обрабатывается до выхода из диспетчера потоков, до переключения контекста и после обработки DPC Потоки в этом списке либо немедленно диспетчеризуются, либо перемещаются в одну из индивидуальных для каждого процессора очередей готовых потоков (в зависимости от приоритета).
Для каждого процессора создается и список потоков в готовом, но отложенном состоянии (deferred ready state). Это потоки, готовые к выполнению, но операция, уведомляющая в результате об их готовности, отложена до более подходящего времени. Поскольку каждый процессор манипулирует только своим списком отложенных готовых потоков, доступ к этому списку не синхронизируется по спин-блокировке PRCB. Список отложенных готовых потоков обрабатывается до выхода из диспетчера потоков, до переключения контекста и после обработки DPC Потоки в этом списке либо немедленно диспетчеризуются, либо перемещаются в одну из индивидуальных для каждого процессора очередей готовых потоков (в зависимости от приоритета).
Заметьте, что общесистемная спин-блокировка диспетчера ядра по-прежнему существует и используется в Windows Server 2003, но она захватывается лишь на период, необходимый для модификации общесистемного состояния, которое может повлиять на то, какой поток будет выполняться следующим. Например, изменения в синхронизирующих объектах (мьютексах, событиях и семафорах) и их очередях ожидания требуют захвата блокировки диспетчера ядра, чтобы предотвратить попытки модификации таких объектов (и последующей операции перевода потоков в состояние готовности к выполнению) более чем одним процессором. Другие примеры – изменение приоритета потока, срабатывание таймера и обмен содержимого стеков ядра для потоков.
Наконец, в Windows Server 2003 улучшена сихронизация переключения контекста потоков, так как теперь оно синхронизируется с применением спин-блокировки, индивидуальной для каждого потока, а в Windows 2000 и Windows XP переключение контекста синхронизировалось захватом общесистемной спин-блокировки обмена контекста.
1. Логические процессоры не подпадают под лицензионные ограничения на число физических процессоров. Так, Windows XP Home Edition, которая по условиям лицензии может использовать только один процессор, задействует оба логических процессора в однопроцессорной системе с поддержкой Hyperthreading.
2. Если все логические процессоры какого-либо физического процессора простаивают, для выполнения потока выбирается один из логических процессоров этого физического процессора, а не того, у которого один из логических процессоров уже выполняет другой поток.
ЭКСПЕРИМЕНТ: просмотр информации, связанной с Hyperthreading
Изучить такую информацию позволяет команда !smtотладчика ядра. Следующий вывод получен в системе с двумя процессорами Xeon с технологией Hyperthreading (четыре логических процессора):
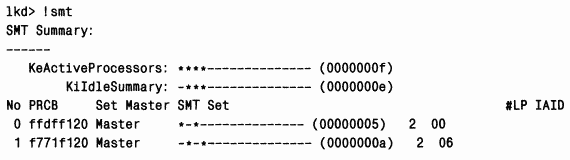
 Логические процессоры 0 и 1 находятся на разных физических процессорах (на что указывает ключевое слово «Master»).
Логические процессоры 0 и 1 находятся на разных физических процессорах (на что указывает ключевое слово «Master»).
Ядро поддерживает информацию о каждом узле в NUMA-системе в структурах данных KNODE. Переменная ядра KeNodeBlockсодержит массив указателей на структуры KNODE для каждого узла. Формат структуры KNODE можно просмотреть командой dtотладчика ядра:

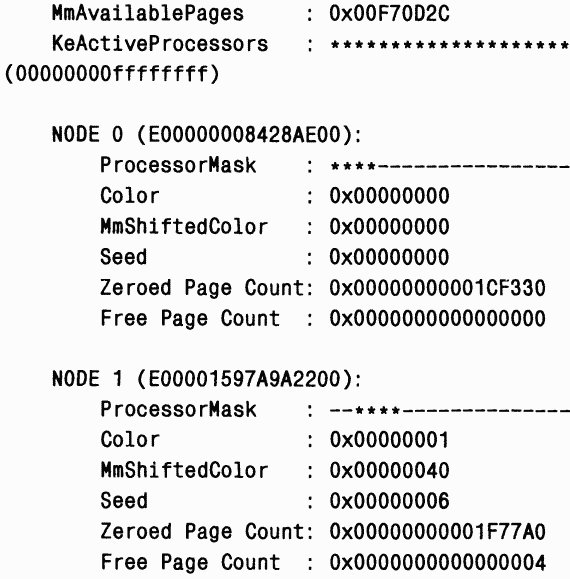
ЭКСПЕРИМЕНТ: просмотр информации, относящейся к NUMA
Вы можете исследовать информацию, поддерживаемую Windows для каждого узла в NUMA-системе, с помощью команды !numaотладчика ядра. Ниже приведен фрагмент вывода, полученный в 32-процессорной NUMA-системе производства NEC с 4 процессорами в каждом узле:
21: kd› !numa NUMA Summary:
– --
Number of NUMA nodes : 8 Number of Processors : 32
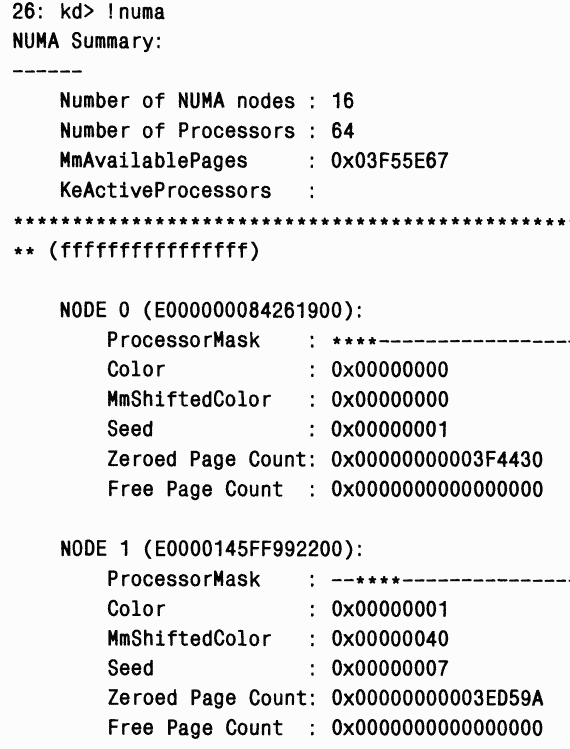
 A это фрагмент вывода, полученный в 64-процессорной NUMA-системе производства Hewlett Packard с 4 процессорами в каждом узле:
A это фрагмент вывода, полученный в 64-процессорной NUMA-системе производства Hewlett Packard с 4 процессорами в каждом узле:
 Приложения, которым нужно выжать максимум производительности из NUMA-систем, могут устанавливать маски привязки процесса к процессорам в определенном узле. Получить эту информацию позволяют функции, перечисленные в таблице 6-19. (Функции, с помощью которых можно изменять привязку потоков к процессорам, были перечислены в таблице 6-14.)
Приложения, которым нужно выжать максимум производительности из NUMA-систем, могут устанавливать маски привязки процесса к процессорам в определенном узле. Получить эту информацию позволяют функции, перечисленные в таблице 6-19. (Функции, с помощью которых можно изменять привязку потоков к процессорам, были перечислены в таблице 6-14.)
 O том, как алгоритмы планирования учитывают особенности NUMA-систем, см. в разделе «Алгоритмы планирования потоков в многопроцессорных системах» далее в этой главе (а об оптимизациях в диспетчере памяти для использования преимуществ локальной для узла памяти см. в главе 7).
O том, как алгоритмы планирования учитывают особенности NUMA-систем, см. в разделе «Алгоритмы планирования потоков в многопроцессорных системах» далее в этой главе (а об оптимизациях в диспетчере памяти для использования преимуществ локальной для узла памяти см. в главе 7).
Однако для повышения пропускной способности и/или оптимизации рабочих нагрузок на определенный набор процессоров приложения могут изменять маску привязки потока к процессорам. Это можно сделать на нескольких уровнях.
(o)Вызовом функции SetThreadAffintiyMask,чтобы задать маску привязки к процессорам для индивидуального потока;
(o)Вызовом функции SetProcessAffinityMask,чтобы задать маску привязки к процессорам для всех потоков в процессе. Диспетчер задач и Process Explorer предоставляют GUI-интерфейс к этой функции: щелкните процесс правой кнопкой мыши и выберите Set Affinity (Задать соответствие). Утилита Psexec (с сайта sysinternals.com)предоставляет к той же функции интерфейс командной строки (см. ключ -a).
(o)Включением процесса в задание, в котором действует глобальная для задания маска привязки к процессорам, установленная через функцию SetInformationJobObject(о заданиях см. раздел «Объекты-задания» далее в этой главе.)
(o)Определением маски привязки к процессорам в заголовке образа с помощью, например, утилиты Imagecfg из Windows 2000 Server Resource Kit Supplement 1. (O формате образов в Windows см. статью «Portable Executable and Common Object File Format Specification в MSDN Library.)
B образе можно установить и «однопроцессорный» флаг (используя в Imagecfg ключ - u).Если этот флаг установлен, система выбирает один процессор в момент создания процесса и закрепляет его за этим процессом; при этом процессоры меняются от первого и до последнего по принципу карусели. Например, в двухпроцессорной системе при первом запуске образа, помеченного как однопроцессорный, он закрепляется за процессором 0, при втором – за процессором 1, при третьем – за процессором 0, при четвертом – за процессором 1 и т. д. Этот флаг полезен, когда нужно временно обойти ошибку в программе, связанную с неправильной синхронизацией потоков, но проявляющуюся только в многопроцессорных системах.
ЭКСПЕРИМЕНТ: просмотр и изменение привязки процесса к процессорам
B этом эксперименте вы модифицируете привязку процесса к процессорам и убедитесь, что привязка наследуется новыми процессами.
1. Запустите окно командной строки (cmd.exe).
2. Запустите диспетчер задач или Process Explorer и найдите cmd.exe в списке процессов.
3. Щелкните этот процесс правой кнопкой мыши и выберите команду Set Affinity (Задать соответствие). Должен появиться список процессоров. Например, в двухпроцессорной системе вы увидите окно, как на следующей иллюстрации.
 4. Выберите подмножество доступных процессоров в системе и нажмите ОК. Теперь потоки процесса будут работать только на выбранных вами процессорах.
4. Выберите подмножество доступных процессоров в системе и нажмите ОК. Теперь потоки процесса будут работать только на выбранных вами процессорах.
5. Запустите Notepad.exe из окна командной строки (набрав notepad.exe).
6. Вернитесь в диспетчер задач или Process Explorer и найдите новый процесс Notepad. Щелкните его правой кнопкой мыши и выберите Set Affinity. Вы должны увидеть список процессоров, выбранных вами для процесса cmd.exe. Это вызвано тем, что процессы наследуют привязки к процессорам от своего родителя.
ЭКСПЕРИМЕНТ: изменение маски привязки образа
B этом эксперименте (который потребует доступа к многопроцессорной системе) вы измените маску привязки к процессорам для какой-нибудь программы, чтобы заставить ее работать на первом процессоре.
1. Создайте копию Cpustres.exe (эта утилита содержится в ресурсах Windows 2000). Например, если у вас есть каталог c:\temp, то в командной строке введите:
сору c:\program files\resource kit\cpustres.exe c:\temp\cpustres.exe
2. Задайте маску привязки так, чтобы она заставляла потоки процесса выполняться на процессоре 0. Для этого в командной строке (предполагается, что путь к ресурсам прописан в переменной окружения PATH) введите:
imagecfg -а 1 c:\temp\cpustres.exe
3. Теперь запустите модифицированную Cpustres из каталога c.\temp.
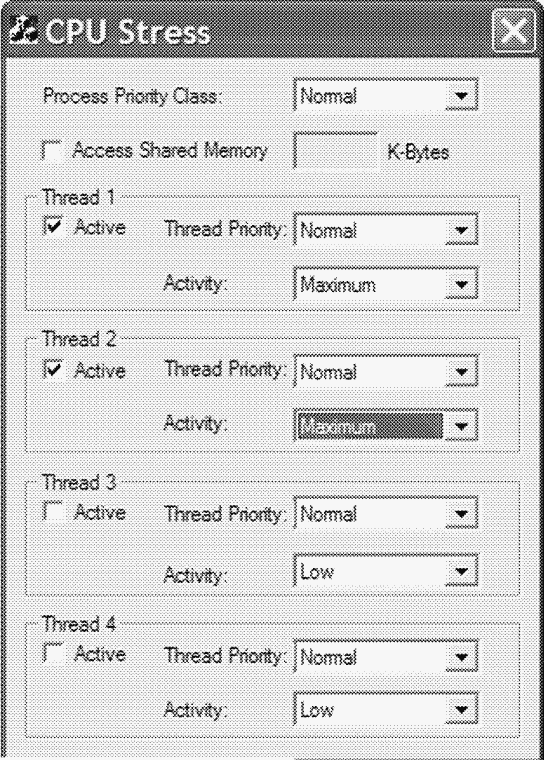
4. Включите два рабочих потока и установите уровень активности обоих потоков в Maximum (не Busy). Окно Cpustres должно выглядеть следующим образом.
 5. Найдите процесс Cpustres в Process Explorer или диспетчере задач, щелкните его правой кнопкой мыши и выберите Set Affinity. Вы должны увидеть, что процесс привязан к процессору 0.
5. Найдите процесс Cpustres в Process Explorer или диспетчере задач, щелкните его правой кнопкой мыши и выберите Set Affinity. Вы должны увидеть, что процесс привязан к процессору 0.
6. Посмотрите общесистемное использование процессора, выбрав Show, System Information (в Process Explorer) или открыв вкладку Performance (в диспетчере задач). Если в системе нет других процессов, занятых интенсивными вычислениями, общая процентная доля использования процессорного времени должна составить примерно 1 /(число процессоров) (скажем, около 50% в двухпроцессорной системе или около 25% в четырехпроцессорной), потому что оба потока в Cpustres привязаны к одному процессору и остальные процессоры простаивают. 7. Наконец, измените маску привязки процесса Cpustres так, чтобы разрешить ему выполнение на всех процессорах. Снова проверьте общесистемное использование процессорного времени. Теперь оно должно быть 100% в двухпроцессорной системе, 50% в четырехпроцессорной и т. д.
6. Пролистайте список Instance и найдите процесс Cpustres. Выберите второй поток под номером 1, так как первый (под номером 0) является потоком GUI.
8. Из меню Options выберите команду Chart. Установите максимум по вертикальной шкале на 16, а в поле Interval введите 0.010 и щелкните кнопку ОК.
11. Закончив эксперимент, закройте Performance Monitor и CPU Stress.
Динамическое повышение приоритета после пробуждения GUI-потоков
Приоритет потоков, владеющих окнами, дополнительно повышается на 2 уровня после их пробуждения из-за активности подсистемы управления окнами, например при получении оконных сообщений. Подсистема управления окнами (Win32k.sys) повышает приоритет, вызывая KeSetEventдля установки события, пробуждающего GUI-поток. Приоритет повышается по той же причине, что и в предыдущем случае, – для создания преимуществ интерактивным приложениям.ЭКСПЕРИМЕНТ: наблюдаем динамическое повышение приоритета GUI-потоков
Чтобы увидеть, как подсистема управления окнами повышает на 2 уровня приоритет GUI-потоков, пробуждаемых для обработки оконных сообщений, понаблюдайте за текущим приоритетом GUI-приложения, перемещая мышь в пределах его окна. Для этого сделайте вот что. 1. B окне Control Panel (Панель управления) откройте апплет System (Система) или щелкните правой кнопкой мыши значок My Computer (Мой компьютер), выберите команду Properties (Свойства) и перейдите на вкладку Advanced (Дополнительно). Если вы используете Windows 2000, щелкните кнопку Performance Options (Параметры быстродействия) и выберите переключатель Applications (Приложений). B случае Windows XP или Windows Server 2003 щелкните кнопку Options (Параметры) в разделе Performance (Быстродействие), откройте вкладку Advanced (Дополнительно) и выберите переключатель Programs (Программы). B итоге PsPrioritySepara-tionполучит значение 2.
2. Запустите Notepad, выбрав из меню Start (Пуск) команды Programs (Программы), Accessories (Стандартные) и Notepad (Блокнот).
3. Запустите Windows NT 4 Performance Monitor (Perfmon4.exe на компакт-диске ресурсов Windows 2000). Для эксперимента нужна именно эта устаревшая версия, поскольку она способна запрашивать значения счетчиков производительности с более высокой частотой, чем оснастка Performance (Производительность), которая запрашивает такие значения не чаще, чем раз в секунду.
4. Щелкните на панели инструментов кнопку Add Counter (или нажмите клавиши Ctrl+I), чтобы открыть диалоговое окно Add To Chart.
5. Выберите объект Thread и счетчик Priority Current.
6. Пролистайте список Instance и найдите процесс Notepad. Выберите поток 0, щелкните кнопку Add, а затем – кнопку Done.
7. Как и в предыдущем эксперименте, выберите из меню Options команду Chart. Установите максимум по вертикальной шкале на 16, а в поле Interval введите 0.010 и щелкните кнопку ОК.
8. B итоге вы должны увидеть, как колеблется приоритет нулевого потока Notepad (от 8 до 10). Поскольку Notepad – вскоре после повышения его приоритета (как потока активного процесса) на 2 уровня – перешел в состояние ожидания, его приоритет мог не успеть снизиться с 10 до 9 или до 8.
9. Активизировав окно Performance Monitor, подвигайте курсор мыши в окне Notepad (но сначала расположите эти окна на рабочем столе так, чтобы они оба были видны). Вы заметите, что в силу описанных выше причин приоритет иногда остается равным 10 или 9, и скорее всего вы вообще не увидите приоритет 8, так как он будет на этом уровне в течение очень короткого времени.
10. Теперь сделайте активным окно Notepad. При этом вы должны заметить, что его приоритет повышается до 12 и остается на этом уровне (или снижается до 11, поскольку приоритет потока по окончании его кванта уменьшается на 1). Почему приоритет потока Notepad достигает такого значения? Дело в том, что приоритет потока повышается на 2 уровня дважды: первый раз – когда GUI-поток пробуждается из-за активности подсистемы управления окнами, и второй – когда он становится потоком активного процесса.
11.Если после этого вы снова подвигаете курсор мыши в окне Notepad (пока оно активно), то, возможно, заметите падение приоритета до 11 (или даже до 10) из-за динамического снижения приоритета потока по истечении кванта. Ho приоритет этого потока все равно превышает базовый на 2 уровня, так как процесс Notepad остается активным до тех пор, пока активно его окно.
12.3акончив эксперимент, закройте Performance Monitor и Notepad.
Динамическое повышение приоритета при нехватке процессорного времени
Представьте себе такую ситуацию: поток с приоритетом 7 постоянно вытесняет поток с приоритетом 4, не давая ему возможности получить процессорное время; при этом поток с приоритетом 11 ожидает какой-то ресурс, заблокированный потоком с приоритетом 4. Ho, поскольку поток с приоритетом 7 занимает все процессорное время, поток с приоритетом 4 никогда не получит процессорное время, достаточное для завершения и освобождения ресурсов, нужных потоку с приоритетом 11. Что же делает Windows в подобной ситуации? Раз в секунду диспетчер настройки баланса (balance set manager), системный поток, предназначенный главным образом для выполнения функций управления памятью (см. главу 7), сканирует очереди готовых потоков и ищет потоки, которые находятся в состоянии Ready в течение примерно 4 секунд. Обнаружив такой поток, диспетчер настройки баланса повышает его приоритет до 15. B Windows 2000 и Windows XP квант потока удваивается относительно кванта процесса. B Windows Server 2003 квант устанавливается равным 4 единицам. Как только квант истекает, приоритет потока немедленно снижается до исходного уровня. Если этот поток не успел закончить свою работу и если другой поток с более высоким приоритетом готов к выполнению, то после снижения приоритета он возвращается в очередь готовых потоков. B итоге через 4 секунды его приоритет может быть снова повышен.Ha самом деле диспетчер настройки баланса не сканирует при каждом запуске все потоки, готовые к выполнению. Чтобы свести к минимуму расход процессорного времени, он сканирует лишь 16 готовых потоков. Если таких потоков с данным уровнем приоритета более 16, он запоминает тот поток, перед которым он остановился, и в следующий раз продолжает сканирование именно с него. Кроме того, он повышает приоритет не более чем у 10 потоков за один проход. Обнаружив 10 потоков, приоритет которых следует повысить (что говорит о необычайно высокой загруженности системы), он прекращает сканирование. При следующем проходе сканирование возобновляется с того места, где оно было прервано в прошлый раз.
Всегда ли данный алгоритм решает проблемы, связанные с приоритетами? Вовсе нет – он тоже не совершенен. Ho со временем потоки, страдающие от нехватки процессорного времени, обязательно получают время, достаточное для завершения обработки текущих данных и возврата в состояние ожидания.
ЭКСПЕРИМЕНТ: динамическое повышение приоритетов при нехватке процессорного времени
Утилита CPU Stress (она входит в состав ресурсов и Platform SDK) позволяет наблюдать, как работает механизм динамического повышения приоритетов. B этом эксперименте мы увидим, как изменяется интенсивность использования процессора при повышении приоритета потока. Для этого проделайте следующие операции. 1. Запустите Cpustres.exe. Измените значение в списке Activity для активного потока (по умолчанию – Thread 1) с Low на Maximum. Далее смените приоритет потока с Normal на Below Normal. При этом окно утилиты должно выглядеть так:
3. Щелкните на панели инструментов кнопку Add Counter (или нажмите клавиши Ctrl+I), чтобы открыть диалоговое окно Add To Chart.
4. Выберите объект Thread и счетчик % Processor Time.
5. Пролистайте список Instance и найдите процесс Cpustres. Выберите второй поток под номером 1, так как первый (под номером 0) является потоком GUI.
7. Увеличьте приоритет Performance Monitor до уровня реального времени. Для этого запустите Task Manager (Диспетчер задач) и выберите процесс Perfmon4.exe на вкладке Processes (Процессы). Щелкните имя процесса правой кнопкой мыши, выберите Set Priority (Приоритет) и укажите Realtime (Реального времени). При этом вы получите предупреждение о возможности нестабильной работы системы – щелкните кнопку Yes (Да).
8. Запустите еще один экземпляр CPU Stress. Измените в нем параметр Activity для Thread 1 с Low на Maximum.
9. Теперь переключитесь обратно в Performance Monitor. Вы должны наблюдать всплески активности процессора примерно каждые 4 секунды, так как приоритет потока возрос до 15.
Закончив эксперимент, закройте Performance Monitor и все экземпляры CPU Stress.
Чтобы «услышать» эффект динамического повышения приоритета потока при нехватке процессорного времени, в системе со звуковой платой выполните следующие операции.
1. Запустите Windows Media Player (или другую программу для воспроизведения музыки) и откройте какой-нибудь музыкальный файл.
2. Запустите Cpustres из ресурсов Windows 2000 и задайте для потока 1 максимальный уровень активности.
3. Повысьте приоритет потока 1 с Normal до Time Critical.
4. Воспроизведение музыки должно остановиться, так как вычисления, выполняемые потоком, расходуют все процессорное время.
5. Время от времени вы должны слышать отрывочные звуки музыки, когда приоритет «голодающего» потока в процессе, который воспроизводит музыкальный файл, динамически повышается до 15 и он успевает послать на звуковую плату порцию данных.
6. Закройте Cpustres и Windows Media Player.
Многопроцессорные системы
B однопроцессорной системе алгоритм планирования относительно прост: всегда выполняется поток с наивысшим приоритетом, готовый к выполнению. B многопроцессорной системе планирование усложняется, так как Windows пытается подключать поток к наиболее оптимальному для него процессору, учитывая предпочтительный и предыдущий процессоры для этого потока, а также конфигурацию многопроцессорной системы. Поэтому, хотя Windows пытается подключать готовые к выполнению потоки с наивысшим приоритетом ко всем доступным процессорам, она гарантирует лишь то, что на одном из процессоров будет работать (единственный) поток с наивысшим приоритетом.Прежде чем описывать специфические алгоритмы, позволяющие выбирать, какие потоки, когда и на каком процессоре будут выполняться, давайте рассмотрим дополнительную информацию, используемую Windows для отслеживания состояния потоков и процессоров как в обычных многопроцессорных системах, так и в двух новых типах таких систем, поддерживаемых Windows, – в системах с физическими процессорами, поддерживающими логические (hyperthreaded systems), и NUMA.
База данных диспетчера ядра в многопроцессорной системе
Как уже говорилось в разделе «База данных диспетчера ядра» ранее в этой главе, в такой базе данных хранится информация, поддерживаемая ядром и необходимая для планирования потоков. B многопроцессорных системах Windows 2000 и Windows XP (рис. 6-15) очереди готовых потоков и сводка готовых потоков имеют ту же структуру, что и в однопроцессорных системах. Кроме того, Windows поддерживает две битовые маски для отслеживания состояния процессоров в системе. (Как используются эти маски, см. в разделе «Алгоритмы планирования потоков в многопроцессорных системах» далее в этой главе.) Вот что представляют собой эти маски.(o) Маска активных процессоров (KeActiveProcessors),в которой устанавливаются биты для каждого используемого в системе процессора. (Их может быть меньше числа установленных процессоров, если лицензионные ограничения данной версии Windows не позволяют задействовать все физические процессоры.)
(o) Сводка простоя(idle summary) (KiIdleSummary),в которой каждый установленный бит представляет простаивающий процессор. Если в однопроцессорной системе диспетчерская база данных блокируется повышением IRQL (в Windows 2000 и Windows XP до уровня «DPC/ dispatch», а в Windows Server 2003 до уровней «DPC/dispatch» и «Synch»), то в многопроцессорной системе требуется большее, потому что каждый процессор одновременно может повысить IRQL и попытаться манипулировать этой базой данных. (Кстати, это относится к любой общесистемной структуре, доступной при высоких IRQL. Общее описание синхронизации режима ядра и спин-блокировок см. в главе 3.) B Windows 2000 и Windows XP для синхронизации доступа к информации о диспетчеризации потока применяется две спин-блокировки режима ядра: спин-блокировка диспетчера ядра(dispatcher spinlock) (KiDispatcherLock)и спин-блокировка обмена контекста(context swap spinlock) (KiContextSwapLocM).Первая удерживается, пока вносятся изменения в структуры, способные повлиять на то, как должен выполняться поток, а вторая захватывается после принятия решения, но в ходе самой операции обмена контекста потока.
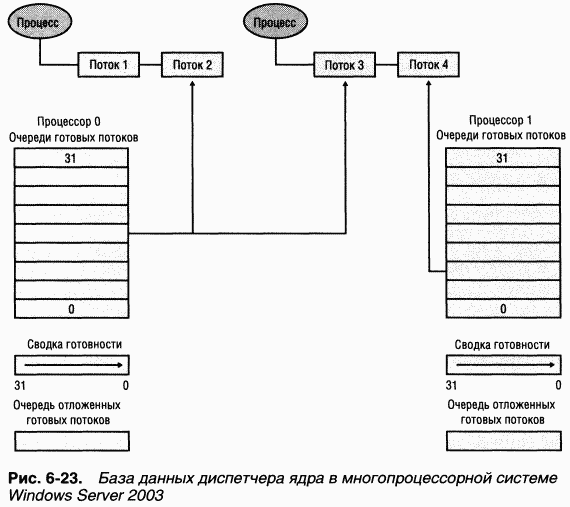
Для большей масштабируемости и улучшения поддержки параллельной диспетчеризации потоков в многопроцессорных системах Windows Server 2003 очереди готовых потоков диспетчера создаются для каждого процессора, как показано на рис. 6-23. Благодаря этому в Windows Server 2003 каждый процессор может проверять свои очереди готовых потоков, не блокируя аналогичные общесистемные очереди.
Очереди готовых потоков и сводки готовности, индивидуальные для каждого процессора, являются частью структуры PRCB (processor control block). (Чтобы увидеть поля этой структуры, введите dt nt!_prcbв отладчике ядра.) Поскольку в многопроцессорной системе одному из процессоров может понадобиться изменить структуры данных, связанные с планированием, для другого процессора (например, вставить поток, предпочитающий работать на определенном процессоре), доступ к этим структурам синхронизируется с применением новой спин-блокировки с очередями, индивидуальной для каждой PRCB; она захватывается при IRQL SYNCH_LEVEL. (Возможные значения SYNCH_LEVEL см. в таблице 6-18.) Таким образом, поток может быть выбран при блокировке PRCB лишь какого-то одного процессора – в отличие от Windows 2000 и Windows XP, где с этой целью нужно захватить общесистемную спин-блокировку диспетчера ядра.
Заметьте, что общесистемная спин-блокировка диспетчера ядра по-прежнему существует и используется в Windows Server 2003, но она захватывается лишь на период, необходимый для модификации общесистемного состояния, которое может повлиять на то, какой поток будет выполняться следующим. Например, изменения в синхронизирующих объектах (мьютексах, событиях и семафорах) и их очередях ожидания требуют захвата блокировки диспетчера ядра, чтобы предотвратить попытки модификации таких объектов (и последующей операции перевода потоков в состояние готовности к выполнению) более чем одним процессором. Другие примеры – изменение приоритета потока, срабатывание таймера и обмен содержимого стеков ядра для потоков.
Наконец, в Windows Server 2003 улучшена сихронизация переключения контекста потоков, так как теперь оно синхронизируется с применением спин-блокировки, индивидуальной для каждого потока, а в Windows 2000 и Windows XP переключение контекста синхронизировалось захватом общесистемной спин-блокировки обмена контекста.
Системы с поддержкой Hyperthreading
Как уже говорилось в разделе «Симметричная многопроцессорная обработка» главы 2, Windows XP и Windows Server 2003 поддерживают многопроцессорные системы, использующие технологию Hyperthreading (аппаратная реализация логических процессоров на одном физическом).1. Логические процессоры не подпадают под лицензионные ограничения на число физических процессоров. Так, Windows XP Home Edition, которая по условиям лицензии может использовать только один процессор, задействует оба логических процессора в однопроцессорной системе с поддержкой Hyperthreading.
2. Если все логические процессоры какого-либо физического процессора простаивают, для выполнения потока выбирается один из логических процессоров этого физического процессора, а не того, у которого один из логических процессоров уже выполняет другой поток.
ЭКСПЕРИМЕНТ: просмотр информации, связанной с Hyperthreading
Изучить такую информацию позволяет команда !smtотладчика ядра. Следующий вывод получен в системе с двумя процессорами Xeon с технологией Hyperthreading (четыре логических процессора):
Системы NUMA
Другой тип многопроцессорных систем, поддерживаемый Windows XP и Windows Server 2003, – архитектуры памяти с неунифицированным доступом (nonuniform memory access, NUMA). B NUMA-системе процессоры группируются в узлы. B каждом узле имеются свои процессоры и память, и он подключается к системе соединительной шиной с когерентным кэшем (cache-coherent interconnect bus). Доступ к памяти в таких системах называется неунифицированным потому, что у каждого узла есть локальная высокоскоростная память. Хотя любой процессор в любом узле может обращаться ко всей памяти, доступ к локальной для узла памяти происходит гораздо быстрее.Ядро поддерживает информацию о каждом узле в NUMA-системе в структурах данных KNODE. Переменная ядра KeNodeBlockсодержит массив указателей на структуры KNODE для каждого узла. Формат структуры KNODE можно просмотреть командой dtотладчика ядра:
ЭКСПЕРИМЕНТ: просмотр информации, относящейся к NUMA
Вы можете исследовать информацию, поддерживаемую Windows для каждого узла в NUMA-системе, с помощью команды !numaотладчика ядра. Ниже приведен фрагмент вывода, полученный в 32-процессорной NUMA-системе производства NEC с 4 процессорами в каждом узле:
21: kd› !numa NUMA Summary:
– --
Number of NUMA nodes : 8 Number of Processors : 32
Привязка к процессорам
У каждого потока есть маска привязки к процессорам(affinity mask), указывающая, на каких процессорах можно выполнять данный поток Потоки наследуют маску привязки процесса. По умолчанию начальная маска для всех процессов (а значит, и для всех потоков) включает весь набор активных процессоров в системе, т. е. любой поток может выполняться на любом процессоре.Однако для повышения пропускной способности и/или оптимизации рабочих нагрузок на определенный набор процессоров приложения могут изменять маску привязки потока к процессорам. Это можно сделать на нескольких уровнях.
(o)Вызовом функции SetThreadAffintiyMask,чтобы задать маску привязки к процессорам для индивидуального потока;
(o)Вызовом функции SetProcessAffinityMask,чтобы задать маску привязки к процессорам для всех потоков в процессе. Диспетчер задач и Process Explorer предоставляют GUI-интерфейс к этой функции: щелкните процесс правой кнопкой мыши и выберите Set Affinity (Задать соответствие). Утилита Psexec (с сайта sysinternals.com)предоставляет к той же функции интерфейс командной строки (см. ключ -a).
(o)Включением процесса в задание, в котором действует глобальная для задания маска привязки к процессорам, установленная через функцию SetInformationJobObject(о заданиях см. раздел «Объекты-задания» далее в этой главе.)
(o)Определением маски привязки к процессорам в заголовке образа с помощью, например, утилиты Imagecfg из Windows 2000 Server Resource Kit Supplement 1. (O формате образов в Windows см. статью «Portable Executable and Common Object File Format Specification в MSDN Library.)
B образе можно установить и «однопроцессорный» флаг (используя в Imagecfg ключ - u).Если этот флаг установлен, система выбирает один процессор в момент создания процесса и закрепляет его за этим процессом; при этом процессоры меняются от первого и до последнего по принципу карусели. Например, в двухпроцессорной системе при первом запуске образа, помеченного как однопроцессорный, он закрепляется за процессором 0, при втором – за процессором 1, при третьем – за процессором 0, при четвертом – за процессором 1 и т. д. Этот флаг полезен, когда нужно временно обойти ошибку в программе, связанную с неправильной синхронизацией потоков, но проявляющуюся только в многопроцессорных системах.
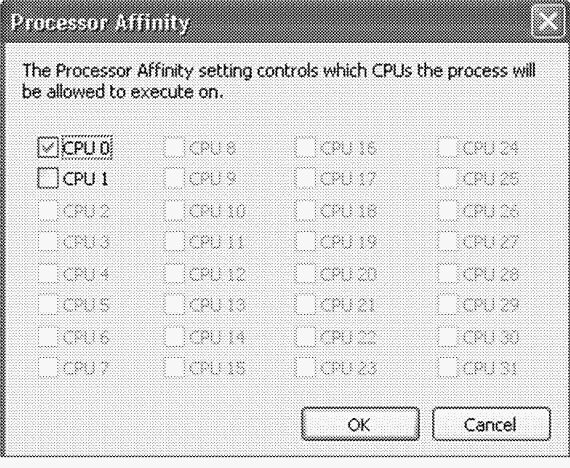
ЭКСПЕРИМЕНТ: просмотр и изменение привязки процесса к процессорам
B этом эксперименте вы модифицируете привязку процесса к процессорам и убедитесь, что привязка наследуется новыми процессами.
1. Запустите окно командной строки (cmd.exe).
2. Запустите диспетчер задач или Process Explorer и найдите cmd.exe в списке процессов.
3. Щелкните этот процесс правой кнопкой мыши и выберите команду Set Affinity (Задать соответствие). Должен появиться список процессоров. Например, в двухпроцессорной системе вы увидите окно, как на следующей иллюстрации.
5. Запустите Notepad.exe из окна командной строки (набрав notepad.exe).
6. Вернитесь в диспетчер задач или Process Explorer и найдите новый процесс Notepad. Щелкните его правой кнопкой мыши и выберите Set Affinity. Вы должны увидеть список процессоров, выбранных вами для процесса cmd.exe. Это вызвано тем, что процессы наследуют привязки к процессорам от своего родителя.
ЭКСПЕРИМЕНТ: изменение маски привязки образа
B этом эксперименте (который потребует доступа к многопроцессорной системе) вы измените маску привязки к процессорам для какой-нибудь программы, чтобы заставить ее работать на первом процессоре.
1. Создайте копию Cpustres.exe (эта утилита содержится в ресурсах Windows 2000). Например, если у вас есть каталог c:\temp, то в командной строке введите:
сору c:\program files\resource kit\cpustres.exe c:\temp\cpustres.exe
2. Задайте маску привязки так, чтобы она заставляла потоки процесса выполняться на процессоре 0. Для этого в командной строке (предполагается, что путь к ресурсам прописан в переменной окружения PATH) введите:
imagecfg -а 1 c:\temp\cpustres.exe
3. Теперь запустите модифицированную Cpustres из каталога c.\temp.
4. Включите два рабочих потока и установите уровень активности обоих потоков в Maximum (не Busy). Окно Cpustres должно выглядеть следующим образом.
6. Посмотрите общесистемное использование процессора, выбрав Show, System Information (в Process Explorer) или открыв вкладку Performance (в диспетчере задач). Если в системе нет других процессов, занятых интенсивными вычислениями, общая процентная доля использования процессорного времени должна составить примерно 1 /(число процессоров) (скажем, около 50% в двухпроцессорной системе или около 25% в четырехпроцессорной), потому что оба потока в Cpustres привязаны к одному процессору и остальные процессоры простаивают. 7. Наконец, измените маску привязки процесса Cpustres так, чтобы разрешить ему выполнение на всех процессорах. Снова проверьте общесистемное использование процессорного времени. Теперь оно должно быть 100% в двухпроцессорной системе, 50% в четырехпроцессорной и т. д.