Страница:

Прошу взглянуть на рисунок. В воронку насыпаются шарики. По очереди они мчатся вниз, отскакивают то вправо то влево от препятствий и наконец достигают какой-то ячейки. В качестве препятствий можно брать шестиугольные бляшки или вбить в доску гвоздики. Для доски Гальтона разработана детальная теория. Мы попытаемся обойтись без неё и предположить, что от каждого гвоздика шарик с равной вероятностью может отскочить влево или вправо. Отклонение вправо и влево будет происходить совершенно по тем же законам, что и появление в рулетке красного и чёрного. На одну комбинацию лллллл… или пппппп… приходится множество комбинаций, состоящих из примерно равного числа отклонений влево и вправо. Поэтому чаще всего шарик будет попадать в среднюю пробирку и реже всего в самые крайние.
Можно провести большое число опытов, и каждый раз шарики будут распределяться примерно одинаково. Если усреднить результаты, то получим гладкую симметричную колоколообразную кривую, которая называется кривой Гаусса или кривой нормального распределения. Не кажется ли вам, читатель, странным, что какой-то кривой мы уделяем так много внимания. На небольшом клочке бумаги можно начертить сколько угодно самых разнообразных кривых, и никому не придёт в голову присваивать им имена или названия. А наша этой чести удостаивается. Почему? Не имеет ли она какой-то математический признак, раз она заслужила специальное название.
Несомненно. Сейчас мы поясним, в чём состоит её математическая общность, только разрешите от реального опыта перейти к абстрактной схеме. И пожалуйста, имейте в виду, что так поступают всегда физики-теоретики, поэтому абстрагированием мы не нарушаем канонов науки.
Упрощение, которое мы введём, состоит в следующем: будем считать, что каждый столбик отличается от соседнего на единицу отклонений. Положим для конкретности, что доска состоит из 10 рядов препятствий. Будем считать, что шарик обязательно встречается с одним из препятствий каждого ряда и с равной вероятностью отскакивает вправо или влево, при этом отклонения происходят всегда на один интервал.
Тогда шарик, который попал в среднюю пробирку, отклонился 5 раз влево, 5 раз вправо. Следующая ячейка заполнена шариками, путь которых состоял из шести отклонений в одну сторону и четырех в другую. Далее идут пробирки, заполняющиеся шариками в соответствии с вариантами 7—3, 8—2, 9—1 и 10—0.
Вариант 5—5 осуществляется максимальным числом способов, 6—4 – уже несколько меньшим, 7—3 – ещё меньшим… 10—0 – самая редкая комбинация. Отсюда и характерный вид кривой, проходящей через вершины столбиков.
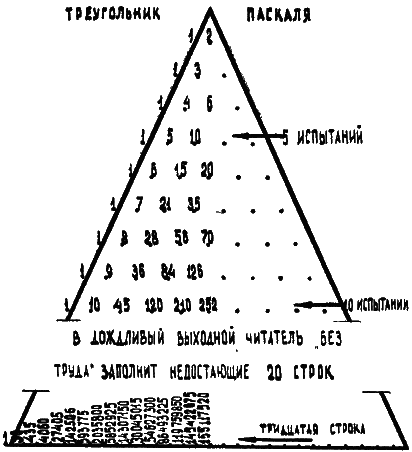
Надо было бы для ясности выписать все комбинации для серии из 10 опытов. Пожалуй, мы пойдём на большее. На этой странице изображён так называемый треугольник Паскаля, с помощью которого можно определять числа комбинаций для любых рядов испытаний. Для того чтобы продолжить этот треугольник хоть до бесконечности, нужно лишь время и умение складывать. Даже таблицу умножения знать не обязательно, поскольку каждое число треугольника равно сумме двух чисел, а именно соседних левого и правого верхней строки.
В результате этих наипростейших арифметических операций мы получаем числа комбинаций левого и правого, красного и чёрного и вообще любых статистических «да» и «нет».
Как же пользоваться треугольником? Любая из его строк даёт числа комбинаций для определённого числа элементов. На рисунке выделена пятая строка. Она отвечает на все вопросы, касающиеся рядов из пяти испытаний. Числам 1, 5, 10, 10, 5, 1 (мы помним их) пропорциональны вероятности появления красного цвета в пяти последовательных поворотах колеса рулетки 0 раз, 1 раз, 2 раза, 3 раза, 4 раза и 5 раз. Значение вероятностей мы получим, поделив каждое число треугольника Паскаля на общее число испытаний, которое равно сумме чисел строки.
Возвращаясь к доске Гальтона мы можем сказать, что при десяти случайных встречах с препятствиями число шариков, которые попадут в крайние пробирки (все встречи привели к одним лишь левым или к одним лишь правым отклонениям), будет в среднем в 252 раза меньше числа шариков, попавших в средний приёмник.
С гауссовой кривой приходится сталкиваться во всех областях знания. Универсальность её объясняется очень просто: на неё укладываются вероятности отклонений от среднего во всех случаях, если только отклонения «вправо» и «влево» равновероятны. Если же отклонения от среднего невелики, как это бывает очень часто, то подобное требование осуществляется всегда. Сейчас мы продолжим знакомство с этой замечательной кривой, лежащей в основе любой статистики.
Случайные отклонения
Вкусы у людей, как известно, чрезвычайно разные. Одни сникают при взгляде на длинные колонки цифр, на графики с ниспадающими и вздымающимися вверх ломаными и плавными кривыми, на масштабные столбики, высота которых описывает все, что угодно, – урожаи, рост, потребление водки или посещаемость театров. У других же, и их немало, глаза загораются при взгляде на это богатство информации. Жадно рыщут они взглядом вдоль цифровых столбцов, просматривают графики и приходят к интересным и важным выводам в области экономики страны, понимания человеческого характера или ещё в чем-нибудь. Люди эти – статистики, – нужное и важное племя работников, значительный отряд министерств и ведомств.
Задачи статистики (так называются не только люди, но и область деятельности) разнообразны и обширны. На десятках тысяч библиографических карточек приведены данные о промышленном производстве, о народном образовании, о смертности населения, о функционировании поликлиник и больниц, об автомобильных катастрофах, о посещаемости кинофильмов и бог весть ещё о чём. Статистиков интересуют самые разные вещи: динамика роста тех или иных показателей, сопоставление данных по значению какого-либо параметра в разные времена года, или в разные часы дня, или среди мужчин и женщин, или среди лиц разного возраста.
Особое место занимают в статистике измерения средних значений и отклонений от средних. Весьма распространены измерения роста и веса. Вес цыплят, которыми торгует птицеферма, интересен потому, что характеризует её работу; рост людей интересен для швейной промышленности, выпускающей одежду ог 46-го до 56-го размеров, и т.д. Так как все это известно читателю из газет и радиопередач, приводящих всевозможные числа, то перейдём к нашей теме, а именно, к проявлению во всей этой массе чисел законов случая.
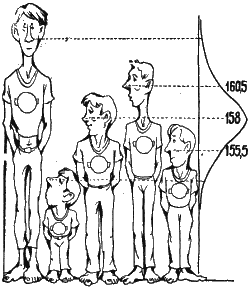
Один из скучных рисунков, фигурирующих в сочинениях по статистике, нам придётся привести. Мы с художником долго ломали голову над тем, как сделать это масштабное построение более приемлемым в книге серии «Эврика». Результат творчества изображён на странице 71 [ссылка]. Рисунок показывает диаграмму и кривую, которая носит название кривой статистического распределения.
Чтобы рисунок лучше рассмотреть, поверните, пожалуйста, книжку на 90 градусов. Правда, новобранцы очутились в лежачем положении. Но, ей-богу, ничего более толкового не придумаешь. Теперь (в повёрнутом положении) высота кривой показывает число будущих солдат определённого роста. Величины роста нанесены на уровне носа. Выбран конкретный пример измерения роста 1375 ребят. Столбики – это результат измерения, а плавная линия – наиболее близкая к опыту – гауссова кривая.
 Статистикам известна следующая замечательная вещь: чем больше привлечённый для построения графика материал (в данном случае чем больше ребят), тем плавнее и ближе к теории кривая, соединяющая вершины масштабных столбиков.
Статистикам известна следующая замечательная вещь: чем больше привлечённый для построения графика материал (в данном случае чем больше ребят), тем плавнее и ближе к теории кривая, соединяющая вершины масштабных столбиков.
Самым замечательным обстоятельством является то, что кривая, получающаяся при измерении любых объектов, имеет форму той же самой кривой Гаусса, на которую, как мы видели, ложатся числа комбинаций «красного» и «чёрного»!
Теперь рассмотрим вид кривой нормального распределения в деталях. Нормальная кривая примерно похожа на колокол; она спадает одинаково в обе стороны сначала медленно, а потом быстро. Чтобы построить её, математику достаточно знать три параметра: высоту её максимума, среднее значение изучаемой величины (то есть то место на горизонтальной оси, которое соответствует среднему значению) и ширину кривой. Вершине колокола как раз и соответствует то, что мы называем средней величиной. (Как получить среднее, известно даже тем, кто враждует с арифметикой: надо сложить все измерения и разделить на число измерений.) Откуда же видно, что максимум кривой Гаусса придётся на среднюю величину? Доказательство лёгкое: нужно проинтегрировать гауссову кривую. Но так как это занятие здесь неуместно, то просим поверить на слово, что теорема доказывается совсем просто.
Итак, остаётся пояснить, что такое ширина нормальной кривой. Условно меряют ширину на полувысоте колокола. Очевидно, что ширина показывает, насколько часто или редко мы встречаемся с отклонениями от среднего. Чем уже колокол, тем реже значительные отклонения от среднего.
Нормальная кривая распределения роста, которая была нарисована на предыдущей странице, описывается такими словами: «Высота кривой 200 человек», то есть двести человек имеют средний рост (первый параметр кривой).
Заметим тут же, что иметь строго средний рост невозможно, можно иметь средний рост с точностью 1, 2, 5 сантиметров и т.д. На нашем графике каждая точка представляет группу ребят, рост которых лежит в пределах 2,5 сантиметра. Средняя высота новобранцев, как мы видим по диаграмме, равна 158 сантиметрам – это второй параметр.
Третьим параметром является ширина колокола, равная в этом случае 15 сантиметрам. Знание ширины кривой позволяет сразу же оценить, с какими отклонениями от среднего мы можем встретиться.
Нормальная кривая универсальна и относится к любым событиям, поэтому, смотря все на тот же рисунок, мы можем делать общие заключения, справедливые для любых нормальных кривых. Скажем, отклонения больше трех полуширин практически не встречаются. Так обстоит дело всегда, вне зависимости от того, о чём идёт речь.
Для характеристики вероятности отклонения от среднего значения в технике и статистике существуют ещё среднее отклонение по абсолютной величине, среднее квадратичное отклонение, вероятное отклонение, мера точности. Все эти величины связаны между собой и с полушириной гауссовой кривой числовыми множителями, близкими к единице.
Вообще говоря, каких-либо доводов в пользу того, чтобы те или иные статистические сведения ложились на гауссову кривую, нет. Правда, кое-что мы чуть позже увидим. Сейчас же надо подчеркнуть, что точные представления о нормальном распределении случайных событий показывает кривая числа комбинаций «красного» и «чёрного». И к идеалу, с точки зрения математической, эта кривая приближается тем лучше, чем большее число испытаний проводится. Если число событий, которые мы обрабатываем статистически, исчисляется десятками, то ординаты кривой будут отличаться от идеальных на десятые доли процента; при сотнях испытаний разница уменьшится до сотых долей процента. Во всяком случае, на рисунке размером в страницу мы не отличим кривую распределения, построенную для тридцати событий, от гауссовой кривой идеальной.
Без преувеличения можно сказать, что закон Гаусса является важнейшим оружием в технике, в физике, в медицине – в любой науке.
Знание среднего значения случайной величины и ширины кривой нормального распределения позволяет уверенно судить о возможном и невозможном.
В технике беспорядочные колебания случайной величины около её среднего значения называют шумом. Такой шум вы слышите, когда снимаете телефонную трубку. Шумом называют обыкновенный белый свет. Шумит молния, излучая весь спектр электромагнитных колебаний. Если шум изображать на телевизионном экране (осциллографе), то будет видна беспорядочная зигзагообразная кривая.
Шум нетрудно ограничить двумя горизонтальными линиями; так сказать, вписать его между нулём и некоторым максимумом. Что можно сказать об этом максимуме, о верхнем пределе шума?
В зависимости от природы, источника, от излучателя, шум может быть как угодно большим. По-одному шумит громкоговоритель в квартире, по-другому – на маленьком полустанке и совсем иной шум громкоговорителей, работающих на улицах Москвы во время парада на Красной площади. Разница основательная. Но если построить графики этих трех шумов, то одну общую черту, продиктованную законом Гаусса, мы обнаружили бы без труда: верхний предел шума превышает средний шум примерно в четыре раза. То есть колокол гауссовой кривой весьма крутой и обрывается исключительно резко, несмотря на то, что с точки зрения формальной математики крылья кривой продолжаются в бесконечность. Из этого графика мы бы увидели, какое маловероятное событие становится практически невозможным. Ещё одно замечание: всякое заметное превышение шума над граничной горизонталью, дающее более чем пятикратное отклонение от среднего шума, называется уже не шумом, а сигналом.
Кривая гауссова распределения показывает, на что надо, а на что не надо обращать внимания, когда речь идёт о случайной величине. Физические измерения, как и математический анализ, показывают, что отклонения, не превышающие четырехкратного значения среднего отклонения, являются нормой и поэтому не заслуживают ни особого внимания, ни объяснения. Скажем, известно, что физики могут измерять расстояния между атомами с точностью до 0,01 ангстрема. Некто Иванов публично заявил, что его измерения на 0,03 ангстрема отличаются от ранее полученных результатов, и пытается доказать, что его результат лучше имеющегося. Не стоило ему так поступать: не спорить ему надо, а сообщить учёному миру, что он лишь подтвердил ранее достигнутый физиками результат. Вот если бы его измерения отличались на 0,06 ангстрема, тогда другое дело; тогда можно было бы говорить, что какая-то из двух величин неверна и некто Петров был бы прав с точки зрения научной этики, приступив к измерению того же межатомного расстояния третий раз.
Зная гауссовы кривые для разных случайных событий, статистики отвергнут газетное сообщение о новорождённом весом в 6 килограммов, о том, что в городе Киеве 12-го числа рождались только мальчики, а 13-го только девочки, о том, что в Москве в мае месяце не было ни одного дня с температурой ниже 30 градусов, о том, что число автомобильных катастроф в декабре было в десять раз больше, чем в январе, что во вторник по всему городу не было продано ни одного куска мыла, а в среду никто не приобрёл в аптеке таблеток пирамидона и т.д.
И право же, такой скептицизм, базирующийся на хорошей статистике и знании закона вероятности, обоснован не хуже, чем расчёты траектории космического корабля. Словом, невероятно – не факт.
Задачи статистики (так называются не только люди, но и область деятельности) разнообразны и обширны. На десятках тысяч библиографических карточек приведены данные о промышленном производстве, о народном образовании, о смертности населения, о функционировании поликлиник и больниц, об автомобильных катастрофах, о посещаемости кинофильмов и бог весть ещё о чём. Статистиков интересуют самые разные вещи: динамика роста тех или иных показателей, сопоставление данных по значению какого-либо параметра в разные времена года, или в разные часы дня, или среди мужчин и женщин, или среди лиц разного возраста.
Особое место занимают в статистике измерения средних значений и отклонений от средних. Весьма распространены измерения роста и веса. Вес цыплят, которыми торгует птицеферма, интересен потому, что характеризует её работу; рост людей интересен для швейной промышленности, выпускающей одежду ог 46-го до 56-го размеров, и т.д. Так как все это известно читателю из газет и радиопередач, приводящих всевозможные числа, то перейдём к нашей теме, а именно, к проявлению во всей этой массе чисел законов случая.
Один из скучных рисунков, фигурирующих в сочинениях по статистике, нам придётся привести. Мы с художником долго ломали голову над тем, как сделать это масштабное построение более приемлемым в книге серии «Эврика». Результат творчества изображён на странице 71 [ссылка]. Рисунок показывает диаграмму и кривую, которая носит название кривой статистического распределения.
Чтобы рисунок лучше рассмотреть, поверните, пожалуйста, книжку на 90 градусов. Правда, новобранцы очутились в лежачем положении. Но, ей-богу, ничего более толкового не придумаешь. Теперь (в повёрнутом положении) высота кривой показывает число будущих солдат определённого роста. Величины роста нанесены на уровне носа. Выбран конкретный пример измерения роста 1375 ребят. Столбики – это результат измерения, а плавная линия – наиболее близкая к опыту – гауссова кривая.
Самым замечательным обстоятельством является то, что кривая, получающаяся при измерении любых объектов, имеет форму той же самой кривой Гаусса, на которую, как мы видели, ложатся числа комбинаций «красного» и «чёрного»!
Теперь рассмотрим вид кривой нормального распределения в деталях. Нормальная кривая примерно похожа на колокол; она спадает одинаково в обе стороны сначала медленно, а потом быстро. Чтобы построить её, математику достаточно знать три параметра: высоту её максимума, среднее значение изучаемой величины (то есть то место на горизонтальной оси, которое соответствует среднему значению) и ширину кривой. Вершине колокола как раз и соответствует то, что мы называем средней величиной. (Как получить среднее, известно даже тем, кто враждует с арифметикой: надо сложить все измерения и разделить на число измерений.) Откуда же видно, что максимум кривой Гаусса придётся на среднюю величину? Доказательство лёгкое: нужно проинтегрировать гауссову кривую. Но так как это занятие здесь неуместно, то просим поверить на слово, что теорема доказывается совсем просто.
Итак, остаётся пояснить, что такое ширина нормальной кривой. Условно меряют ширину на полувысоте колокола. Очевидно, что ширина показывает, насколько часто или редко мы встречаемся с отклонениями от среднего. Чем уже колокол, тем реже значительные отклонения от среднего.
Нормальная кривая распределения роста, которая была нарисована на предыдущей странице, описывается такими словами: «Высота кривой 200 человек», то есть двести человек имеют средний рост (первый параметр кривой).
Заметим тут же, что иметь строго средний рост невозможно, можно иметь средний рост с точностью 1, 2, 5 сантиметров и т.д. На нашем графике каждая точка представляет группу ребят, рост которых лежит в пределах 2,5 сантиметра. Средняя высота новобранцев, как мы видим по диаграмме, равна 158 сантиметрам – это второй параметр.
Третьим параметром является ширина колокола, равная в этом случае 15 сантиметрам. Знание ширины кривой позволяет сразу же оценить, с какими отклонениями от среднего мы можем встретиться.
Нормальная кривая универсальна и относится к любым событиям, поэтому, смотря все на тот же рисунок, мы можем делать общие заключения, справедливые для любых нормальных кривых. Скажем, отклонения больше трех полуширин практически не встречаются. Так обстоит дело всегда, вне зависимости от того, о чём идёт речь.
Для характеристики вероятности отклонения от среднего значения в технике и статистике существуют ещё среднее отклонение по абсолютной величине, среднее квадратичное отклонение, вероятное отклонение, мера точности. Все эти величины связаны между собой и с полушириной гауссовой кривой числовыми множителями, близкими к единице.
Вообще говоря, каких-либо доводов в пользу того, чтобы те или иные статистические сведения ложились на гауссову кривую, нет. Правда, кое-что мы чуть позже увидим. Сейчас же надо подчеркнуть, что точные представления о нормальном распределении случайных событий показывает кривая числа комбинаций «красного» и «чёрного». И к идеалу, с точки зрения математической, эта кривая приближается тем лучше, чем большее число испытаний проводится. Если число событий, которые мы обрабатываем статистически, исчисляется десятками, то ординаты кривой будут отличаться от идеальных на десятые доли процента; при сотнях испытаний разница уменьшится до сотых долей процента. Во всяком случае, на рисунке размером в страницу мы не отличим кривую распределения, построенную для тридцати событий, от гауссовой кривой идеальной.
Без преувеличения можно сказать, что закон Гаусса является важнейшим оружием в технике, в физике, в медицине – в любой науке.
Знание среднего значения случайной величины и ширины кривой нормального распределения позволяет уверенно судить о возможном и невозможном.
В технике беспорядочные колебания случайной величины около её среднего значения называют шумом. Такой шум вы слышите, когда снимаете телефонную трубку. Шумом называют обыкновенный белый свет. Шумит молния, излучая весь спектр электромагнитных колебаний. Если шум изображать на телевизионном экране (осциллографе), то будет видна беспорядочная зигзагообразная кривая.
Шум нетрудно ограничить двумя горизонтальными линиями; так сказать, вписать его между нулём и некоторым максимумом. Что можно сказать об этом максимуме, о верхнем пределе шума?
В зависимости от природы, источника, от излучателя, шум может быть как угодно большим. По-одному шумит громкоговоритель в квартире, по-другому – на маленьком полустанке и совсем иной шум громкоговорителей, работающих на улицах Москвы во время парада на Красной площади. Разница основательная. Но если построить графики этих трех шумов, то одну общую черту, продиктованную законом Гаусса, мы обнаружили бы без труда: верхний предел шума превышает средний шум примерно в четыре раза. То есть колокол гауссовой кривой весьма крутой и обрывается исключительно резко, несмотря на то, что с точки зрения формальной математики крылья кривой продолжаются в бесконечность. Из этого графика мы бы увидели, какое маловероятное событие становится практически невозможным. Ещё одно замечание: всякое заметное превышение шума над граничной горизонталью, дающее более чем пятикратное отклонение от среднего шума, называется уже не шумом, а сигналом.
Кривая гауссова распределения показывает, на что надо, а на что не надо обращать внимания, когда речь идёт о случайной величине. Физические измерения, как и математический анализ, показывают, что отклонения, не превышающие четырехкратного значения среднего отклонения, являются нормой и поэтому не заслуживают ни особого внимания, ни объяснения. Скажем, известно, что физики могут измерять расстояния между атомами с точностью до 0,01 ангстрема. Некто Иванов публично заявил, что его измерения на 0,03 ангстрема отличаются от ранее полученных результатов, и пытается доказать, что его результат лучше имеющегося. Не стоило ему так поступать: не спорить ему надо, а сообщить учёному миру, что он лишь подтвердил ранее достигнутый физиками результат. Вот если бы его измерения отличались на 0,06 ангстрема, тогда другое дело; тогда можно было бы говорить, что какая-то из двух величин неверна и некто Петров был бы прав с точки зрения научной этики, приступив к измерению того же межатомного расстояния третий раз.
Зная гауссовы кривые для разных случайных событий, статистики отвергнут газетное сообщение о новорождённом весом в 6 килограммов, о том, что в городе Киеве 12-го числа рождались только мальчики, а 13-го только девочки, о том, что в Москве в мае месяце не было ни одного дня с температурой ниже 30 градусов, о том, что число автомобильных катастроф в декабре было в десять раз больше, чем в январе, что во вторник по всему городу не было продано ни одного куска мыла, а в среду никто не приобрёл в аптеке таблеток пирамидона и т.д.
И право же, такой скептицизм, базирующийся на хорошей статистике и знании закона вероятности, обоснован не хуже, чем расчёты траектории космического корабля. Словом, невероятно – не факт.
Если вероятности невелики…
Во время войны довольно часто стреляли из винтовок по вражеским самолётам. Может показаться, что это безнадёжное дело; о прицельной стрельбе здесь и речи быть не может, поскольку лишь пули, пробивающие бензобак или поражающие лётчика, приносят результат. Было установлено, что вероятность удачного выстрела равнялась 0,001. Действительно мало. Но если стреляет одновременно много бойцов, то картина меняется.
Примеров, в которых нас интересует вероятность многократно осуществлённого события, обладающего малой вероятностью, множество. Например, с задачей попадания в самолёт из винтовки полностью совпадает задача о выигрыше в лотерею по нескольким билетам.
Каждая серия «выстрелов» может быть как неудачной, так и закончиться одной удачей, а то и несколькими. Соответствующее распределение вероятностей было найдено французским математиком Пуассоном.
В любом математическом справочнике вы найдёте формулу Пуассона, а также таблицы, позволяющие найти интересующую вас вероятность без расчёта.
Средняя частота – это результат, идеально совпавший с предсказанием теории вероятностей. Если вероятность выигрыша равняется 0,01, то из ста билетов выиграет 1, а из тысячи – 10. Единица и десять это и есть средние частоты выигрыша для серий в сто и тысячу билетов. Конечно, средняя частота может быть и дробным числом. Так, для серий в десять билетов при том же значении вероятности средняя частота выигрыша равняется 0,1. Это значит, что в среднем одна из десяти серий по десяти билетов будет содержать один выигрыш.
 В таблицах Пуассона приводятся цифровые данные для всевозможных значений средних частот. Чтобы было ясно, в каком виде нам сообщаются эти сведения и для общей ориентировки приведём несколько чисел характеризующих распределение вероятности при средней частоте, равной единице. Вот эти числа.
В таблицах Пуассона приводятся цифровые данные для всевозможных значений средних частот. Чтобы было ясно, в каком виде нам сообщаются эти сведения и для общей ориентировки приведём несколько чисел характеризующих распределение вероятности при средней частоте, равной единице. Вот эти числа.
Ста выстрелами при вероятности попадания в 0,01 или тысячью выстрелами при вероятности попадания в 0,001, или миллионом при вероятности в 0,000001, мы поразим цель один раз в 37 процентах случая, 2 раза в 18 процентах, 3 раза в 6 процентах… 8 раз лишь в 0,001 процента. А промахнёмся сколько раз? Промахов точно столько же, сколько одноразовых попаданий, то есть 37 процентов.
Приведённые проценты, как и любые числа вероятностей, работают точно лишь для очень большого числа серий. Если миллион людей приобрёл лотерейные билеты, выигрывающие с вероятностью в 0,01, то 37 процентов из них не выиграют ни разу, а 37 процентов других лиц обязательно выиграют по одному билету и т.д. Если же мы заинтересуемся выигрышами только 100 человек, то должны считаться с вероятными отклонениями от среднего. В «среднем» 37 из них не выиграют ни разу. Отклонения здесь от «среднего» не превысят 6?sqrt(37). А с такими отклонениями, как мы уже знаем, следует считаться и помнить, что число неудачников будет находиться между 31 и 43. Конечно, не исключены и бо?льшие отклонения в обе стороны, но их вероятность совсем уж невелика.
Узнав из условий розыгрыша, что в среднем на сотню лотерейных билетов один выигрывает, владелец билетов будет считать себя несчастливым, если на его 100 билетов выигрыш не упадёт ни разу. Если же ему не повезёт несколько раз, то он, возможно, заподозрит устроителей лотереи в несправедливости. Однако сделаем простой расчёт. Если вероятность одного «промаха» равна 0,37 (37%), то вероятность двух «непопаданий» равна квадрату этого числа (0,14), а трех – кубу (0,05). А это не такие уж малые доли, чтобы делать столь решительные выводы.
Примеров, в которых нас интересует вероятность многократно осуществлённого события, обладающего малой вероятностью, множество. Например, с задачей попадания в самолёт из винтовки полностью совпадает задача о выигрыше в лотерею по нескольким билетам.
Каждая серия «выстрелов» может быть как неудачной, так и закончиться одной удачей, а то и несколькими. Соответствующее распределение вероятностей было найдено французским математиком Пуассоном.
В любом математическом справочнике вы найдёте формулу Пуассона, а также таблицы, позволяющие найти интересующую вас вероятность без расчёта.
Средняя частота – это результат, идеально совпавший с предсказанием теории вероятностей. Если вероятность выигрыша равняется 0,01, то из ста билетов выиграет 1, а из тысячи – 10. Единица и десять это и есть средние частоты выигрыша для серий в сто и тысячу билетов. Конечно, средняя частота может быть и дробным числом. Так, для серий в десять билетов при том же значении вероятности средняя частота выигрыша равняется 0,1. Это значит, что в среднем одна из десяти серий по десяти билетов будет содержать один выигрыш.
Ста выстрелами при вероятности попадания в 0,01 или тысячью выстрелами при вероятности попадания в 0,001, или миллионом при вероятности в 0,000001, мы поразим цель один раз в 37 процентах случая, 2 раза в 18 процентах, 3 раза в 6 процентах… 8 раз лишь в 0,001 процента. А промахнёмся сколько раз? Промахов точно столько же, сколько одноразовых попаданий, то есть 37 процентов.
Приведённые проценты, как и любые числа вероятностей, работают точно лишь для очень большого числа серий. Если миллион людей приобрёл лотерейные билеты, выигрывающие с вероятностью в 0,01, то 37 процентов из них не выиграют ни разу, а 37 процентов других лиц обязательно выиграют по одному билету и т.д. Если же мы заинтересуемся выигрышами только 100 человек, то должны считаться с вероятными отклонениями от среднего. В «среднем» 37 из них не выиграют ни разу. Отклонения здесь от «среднего» не превысят 6?sqrt(37). А с такими отклонениями, как мы уже знаем, следует считаться и помнить, что число неудачников будет находиться между 31 и 43. Конечно, не исключены и бо?льшие отклонения в обе стороны, но их вероятность совсем уж невелика.
Узнав из условий розыгрыша, что в среднем на сотню лотерейных билетов один выигрывает, владелец билетов будет считать себя несчастливым, если на его 100 билетов выигрыш не упадёт ни разу. Если же ему не повезёт несколько раз, то он, возможно, заподозрит устроителей лотереи в несправедливости. Однако сделаем простой расчёт. Если вероятность одного «промаха» равна 0,37 (37%), то вероятность двух «непопаданий» равна квадрату этого числа (0,14), а трех – кубу (0,05). А это не такие уж малые доли, чтобы делать столь решительные выводы.
Теория рекламы
Мой знакомый – американский математик мистер В., ранее занимавшийся достаточно успешно приложениями теории вероятностей к вопросам структуры жидкостей, переменил область своей деятельности.
– Я занимаюсь теорией рекламы, – сообщил он мне при последней нашей встрече.
– И это интересно?
– Бесспорно. Здесь много занятных тонкостей.
– А, собственно говоря, что же является конечной целью теории?
– Хотя бы получение ответа на вопрос, который интересует любого нашего промышленника: сколько денег имеет смысл потратить на рекламу?
– Но каковы же математические методы, которые вы используете?
– Да все те же, с которыми я имел дело до сих пор. Теория рекламы, теория популярности актёра, теория известности писателя, прогноз бестселлеров литературы – все это классический предмет теории вероятностей. Не я один, а много моих коллег заняты этим приложением теории вероятностей к проблемам нашей капиталистической действительности.
– Может быть, вы расскажете мне о наиболее интересных теоретических находках в этой области?
– С удовольствием. Надеюсь, мне не надо доказывать вам, что, прежде чем добиться того, чтобы вещь, или событие, или некая персона понравились, надо, чтобы они стали известными потребителю?
– Без сомнения.
– Поэтому не будем пока касаться проблемы «нравится», а остановимся на вероятности получения неким гражданином сведений о существовании сигарет Честерфилд, лезвий для бритья фирмы Вильсон, романа Агаты Кристи «Убийство по азбуке» или киноактрисы Бетти Симпсон. Мы оставим в стороне систематические знания, приобретаемые в результате обучения в школе или университете, и будем интересоваться лишь теми сведениями, которые люди приобретают «на ходу», не преследуя образовательных целей. На каждого из нас через разные каналы: радио, газеты, телевидение, болтовню с друзьями – обрушивается мощный поток информации, получаемой «по случаю». Фамилии актёров, названия книжных новинок, новых сортов сигарет, лезвий для бритья и многое другое мы узнаем большей частью случайно. В зависимости от размаха рекламы, от интереса, который общество проявляет к тому или иному «модному» предмету, имеется некоторая определённая вероятность о нём услышать. Эта вероятность более или менее одинакова для однородной группы населения – скажем, для жителей города, имеющих телевизоры и радиоприёмники и выписывающих две-три наиболее распространённые газеты.
Разумеется, равная вероятность получить информацию вовсе не означает, что по истечении какого-либо срока все люди окажутся одинаково сведущими. Случайное получение информации очень похоже на лотерейный выигрыш. Действительно, среди тысячи обладателей по десяти лотерейных билетов окажутся лица, которые не выиграют ни разу, которые выиграют один раз, найдутся обладатели двух счастливых билетов, будут и такие везучие игроки, у которых выигрыши выпадут на три, четыре и более билетов. Так что…
– Вы хотите сказать, что вероятность «столкновения» с рекламой, вернее, не с рекламой, а с упоминанием о предмете или лице, известность которого обсуждается, подчиняется распределению Пуассона?
– Совершенно верно. Если, скажем, вероятность натолкнуться на соответствующую информацию в течение одного дня равна одной сотой, то через сто дней 37 процентов населения, так сказать, омываемого этим потоком информации, так и не столкнётся с этой рекламой, другие 37 процентов встретятся с упоминанием о рекламируемом предмете 1 раз, 18 процентов – два раза, 6 процентов – три раза и т.д. Эти числа, как вы, конечно, помните, даёт закон Пуассона.
– Значит, при вероятности узнавания, равной одной сотой в день, через сто дней обеспечивается известность среди 63 процентов населения?
– Не совсем так. У людей, к сожалению торговцев, память коротка, да и жизнь суматошная. С одного взгляда на рекламу мало кто запоминает рекламируемую вещь.
– Так что у вероятности узнавания имеется ещё и второй множитель?
– Вот именно!
– А какова величина этой поправки на невнимательность?
– Разумеется, она различна в зависимости от того, о чём идёт речь. Я могу вам сообщить, к примеру, данные, полученные из анализа анкет, распространявшихся среди телезрителей. Из этих данных была вычислена вероятность запоминания с одной встречи. Оказалось, что она колеблется между 0,01 и 0,1.
– Существенная поправка к распределению Пуассона!..
– Конечно. Судите сами: если подсчитать процент населения, который получит информацию через сто дней, то из 37 процентов «столкнувшихся» с рекламой один раз, информированными окажутся лишь 3,7 процента (если мы примем вероятность запоминания с одной встречи равной 0,1). Из 18 процентов «сталкивавшихся» с информацией два раза доля лиц, усвоивших рекламу, будет больше. Действительно, вероятность не запомнить с одного раза равна 0,9, а не запомнить после двух встреч равна квадрату этой величины, то есть 0,81. Запомнивших будет 0,19. Таким образом, процент информированного населения в нашем примере будет подсчитываться так:
37·0,1 + 18·0,19 + 6·0,27 + …
– Да, до 63 процентов далеко!..
– Вот этот коэффициент невнимательности и приводит к необходимости назойливой, торчащей на всех углах рекламы. Чтобы каждый потребитель узнал о товаре, он должен сталкиваться с соответствующей информацией очень часто.
– Мы всё время говорим с вами об известности. Но ведь знать – это ещё не значит предпочитать!
– Так-то оно так, – улыбнулся мой собеседник. – Но роль рекламы оказывается решающей. Недостаточная реклама означает малую известность, а малая известность влечёт двойной проигрыш в конкурсе на высшую оценку. Первая причина ясна. Те, кто не знает, естественно, не могут подать голос за то, что им неизвестно. Вторая причина состоит вот в чём. Менее популярные вещи, книги, актёры, писатели… известны наиболее образованным людям. Но поскольку они образованны, они делают свой выбор среди значительно большего числа конкурентов. По этой причине вероятность высшей оценки предмета или объекта, который выбирается знатоками, становится меньше вероятности высшей оценки, которую выносит менее осведомлённый судья.
– Я начинаю теперь понимать, почему в вашей стране тратят столько денег на рекламу!
– Ещё бы!.. Вот вам простая числовая иллюстрация. Имеется 10 лучших ресторанов в городе. Из них два, скажем, «Империал» и «Континенталь», разрекламированы много более других. Гурманы знают о существовании всех десяти ресторанов, которые примерно одинаково хороши. Случайные же посетители ресторанов, как правило ужинающие у себя дома, знают лишь о существовании «Империала» и «Континенталя». Положим, что тысяча человек собирается сегодня вечером поужинать вне дома. Из них 500 знатоков и 500 профанов. На первый взгляд может показаться, что менее разрекламированные рестораны не будут в проигрыше. Однако, будут – и в очень большом! 500 профанов с вероятностью 1/2 выберут один из двух наиболее известных ресторанов. Из них 250 очутится в «Империале» и 250 в «Континентале». А 500 знатоков с вероятностью 1/10 выберут один из десяти ресторанов. Таким образом, в «Империале» и «Континентале» окажется по 300 человек, а в остальных 8 ресторанах – по 50. Как видите, наименее компетентные потребители играют решающую роль.
– Я занимаюсь теорией рекламы, – сообщил он мне при последней нашей встрече.
– И это интересно?
– Бесспорно. Здесь много занятных тонкостей.
– А, собственно говоря, что же является конечной целью теории?
– Хотя бы получение ответа на вопрос, который интересует любого нашего промышленника: сколько денег имеет смысл потратить на рекламу?
– Но каковы же математические методы, которые вы используете?
– Да все те же, с которыми я имел дело до сих пор. Теория рекламы, теория популярности актёра, теория известности писателя, прогноз бестселлеров литературы – все это классический предмет теории вероятностей. Не я один, а много моих коллег заняты этим приложением теории вероятностей к проблемам нашей капиталистической действительности.
– Может быть, вы расскажете мне о наиболее интересных теоретических находках в этой области?
– С удовольствием. Надеюсь, мне не надо доказывать вам, что, прежде чем добиться того, чтобы вещь, или событие, или некая персона понравились, надо, чтобы они стали известными потребителю?
– Без сомнения.
– Поэтому не будем пока касаться проблемы «нравится», а остановимся на вероятности получения неким гражданином сведений о существовании сигарет Честерфилд, лезвий для бритья фирмы Вильсон, романа Агаты Кристи «Убийство по азбуке» или киноактрисы Бетти Симпсон. Мы оставим в стороне систематические знания, приобретаемые в результате обучения в школе или университете, и будем интересоваться лишь теми сведениями, которые люди приобретают «на ходу», не преследуя образовательных целей. На каждого из нас через разные каналы: радио, газеты, телевидение, болтовню с друзьями – обрушивается мощный поток информации, получаемой «по случаю». Фамилии актёров, названия книжных новинок, новых сортов сигарет, лезвий для бритья и многое другое мы узнаем большей частью случайно. В зависимости от размаха рекламы, от интереса, который общество проявляет к тому или иному «модному» предмету, имеется некоторая определённая вероятность о нём услышать. Эта вероятность более или менее одинакова для однородной группы населения – скажем, для жителей города, имеющих телевизоры и радиоприёмники и выписывающих две-три наиболее распространённые газеты.
Разумеется, равная вероятность получить информацию вовсе не означает, что по истечении какого-либо срока все люди окажутся одинаково сведущими. Случайное получение информации очень похоже на лотерейный выигрыш. Действительно, среди тысячи обладателей по десяти лотерейных билетов окажутся лица, которые не выиграют ни разу, которые выиграют один раз, найдутся обладатели двух счастливых билетов, будут и такие везучие игроки, у которых выигрыши выпадут на три, четыре и более билетов. Так что…
– Вы хотите сказать, что вероятность «столкновения» с рекламой, вернее, не с рекламой, а с упоминанием о предмете или лице, известность которого обсуждается, подчиняется распределению Пуассона?
– Совершенно верно. Если, скажем, вероятность натолкнуться на соответствующую информацию в течение одного дня равна одной сотой, то через сто дней 37 процентов населения, так сказать, омываемого этим потоком информации, так и не столкнётся с этой рекламой, другие 37 процентов встретятся с упоминанием о рекламируемом предмете 1 раз, 18 процентов – два раза, 6 процентов – три раза и т.д. Эти числа, как вы, конечно, помните, даёт закон Пуассона.
– Значит, при вероятности узнавания, равной одной сотой в день, через сто дней обеспечивается известность среди 63 процентов населения?
– Не совсем так. У людей, к сожалению торговцев, память коротка, да и жизнь суматошная. С одного взгляда на рекламу мало кто запоминает рекламируемую вещь.
– Так что у вероятности узнавания имеется ещё и второй множитель?
– Вот именно!
– А какова величина этой поправки на невнимательность?
– Разумеется, она различна в зависимости от того, о чём идёт речь. Я могу вам сообщить, к примеру, данные, полученные из анализа анкет, распространявшихся среди телезрителей. Из этих данных была вычислена вероятность запоминания с одной встречи. Оказалось, что она колеблется между 0,01 и 0,1.
– Существенная поправка к распределению Пуассона!..
– Конечно. Судите сами: если подсчитать процент населения, который получит информацию через сто дней, то из 37 процентов «столкнувшихся» с рекламой один раз, информированными окажутся лишь 3,7 процента (если мы примем вероятность запоминания с одной встречи равной 0,1). Из 18 процентов «сталкивавшихся» с информацией два раза доля лиц, усвоивших рекламу, будет больше. Действительно, вероятность не запомнить с одного раза равна 0,9, а не запомнить после двух встреч равна квадрату этой величины, то есть 0,81. Запомнивших будет 0,19. Таким образом, процент информированного населения в нашем примере будет подсчитываться так:
37·0,1 + 18·0,19 + 6·0,27 + …
– Да, до 63 процентов далеко!..
– Вот этот коэффициент невнимательности и приводит к необходимости назойливой, торчащей на всех углах рекламы. Чтобы каждый потребитель узнал о товаре, он должен сталкиваться с соответствующей информацией очень часто.
– Мы всё время говорим с вами об известности. Но ведь знать – это ещё не значит предпочитать!
– Так-то оно так, – улыбнулся мой собеседник. – Но роль рекламы оказывается решающей. Недостаточная реклама означает малую известность, а малая известность влечёт двойной проигрыш в конкурсе на высшую оценку. Первая причина ясна. Те, кто не знает, естественно, не могут подать голос за то, что им неизвестно. Вторая причина состоит вот в чём. Менее популярные вещи, книги, актёры, писатели… известны наиболее образованным людям. Но поскольку они образованны, они делают свой выбор среди значительно большего числа конкурентов. По этой причине вероятность высшей оценки предмета или объекта, который выбирается знатоками, становится меньше вероятности высшей оценки, которую выносит менее осведомлённый судья.
– Я начинаю теперь понимать, почему в вашей стране тратят столько денег на рекламу!
– Ещё бы!.. Вот вам простая числовая иллюстрация. Имеется 10 лучших ресторанов в городе. Из них два, скажем, «Империал» и «Континенталь», разрекламированы много более других. Гурманы знают о существовании всех десяти ресторанов, которые примерно одинаково хороши. Случайные же посетители ресторанов, как правило ужинающие у себя дома, знают лишь о существовании «Империала» и «Континенталя». Положим, что тысяча человек собирается сегодня вечером поужинать вне дома. Из них 500 знатоков и 500 профанов. На первый взгляд может показаться, что менее разрекламированные рестораны не будут в проигрыше. Однако, будут – и в очень большом! 500 профанов с вероятностью 1/2 выберут один из двух наиболее известных ресторанов. Из них 250 очутится в «Империале» и 250 в «Континентале». А 500 знатоков с вероятностью 1/10 выберут один из десяти ресторанов. Таким образом, в «Империале» и «Континентале» окажется по 300 человек, а в остальных 8 ресторанах – по 50. Как видите, наименее компетентные потребители играют решающую роль.