Страница:
Эти две системы, панель мониторинга юнит-тестов и система непрерывной сборки Криса и Джея, использовались в Google несколько лет. Они принесли огромную пользу командам, были несложны в настройке и неприхотливы в сопровождении. И вот встал вопрос о реализации этих систем в виде общей инфраструктуры для всех команд. Так появилась система Test Automation Program (TAP). Когда мы писали эту книгу, TAP уже заменила собой обе первоначальные системы. Ее используют почти все проекты Google, кроме Chromium и Android. Только проекты с открытым кодом используют отдельные деревья исходного кода и серверные среды сборки.
Плюсы того, что большинство сотрудников используют один набор инструментов и единую инфраструктуру, трудно переоценить. Одной простой командой инженер может собрать и исполнить все бинарники и тесты, которые связаны с его списком изменений, получить данные о покрытии кода, сохранить и проанализировать результаты в облаке, а потом посмотреть их в виде отчета на постоянной веб-странице. Результат выводится в терминал в виде сообщения «PASS» или «FAIL» со ссылками на подробную информацию. Когда разработчик выполняет тесты, их результаты и данные о покрытии кода сохраняются в облаке, и любой рецензент может посмотреть их через внутренний инструмент для код-ревью.
Пример работы разработчика в тестировании
Выполнение тестов
Определения размеров тестов
Как мы используем размеры тестов в общей инфраструктуре
Преимущества разных размеров тестов
Плюсы того, что большинство сотрудников используют один набор инструментов и единую инфраструктуру, трудно переоценить. Одной простой командой инженер может собрать и исполнить все бинарники и тесты, которые связаны с его списком изменений, получить данные о покрытии кода, сохранить и проанализировать результаты в облаке, а потом посмотреть их в виде отчета на постоянной веб-странице. Результат выводится в терминал в виде сообщения «PASS» или «FAIL» со ссылками на подробную информацию. Когда разработчик выполняет тесты, их результаты и данные о покрытии кода сохраняются в облаке, и любой рецензент может посмотреть их через внутренний инструмент для код-ревью.
Пример работы разработчика в тестировании
Следующий пример объединяет все, о чем мы говорили выше. Предупреждаем, в этом разделе много технической информации с уймой низкоуровневых деталей. Если вам интересна только общая картина, смело переходите к следующему разделу.
Представьте простое веб-приложение, с помощью которого пользователи отправляют URL-адреса в Google для добавления в Google-индекс. Форма HTML содержит два поля – ULR-адрес и комментарий – и генерирует запрос HTTP GET к серверу Google в следующем формате:
Разработчик начинает работу с создания каталога для проекта:
Посмотрев на определения сообщения AddUrlRequest, мы видим, что поле url должно быть задано вызывающей стороной, а поле comment не является обязательным.
Точно так же из определения сообщения AddUrlReply следует, что оба поля – error_code и error_details опционально могут быть переданы в ответах сервиса. Мы предполагаем, что в типичном случае, когда URL-адрес успешно принят, эти поля останутся пустыми, чтобы минимизировать объем передаваемых данных. Это одно из правил Google: типичный случай должен работать быстро.
Из определения AddUrlService видно, что сервис содержит единственный метод AddUrl, который принимает AddUrlRequest и возвращает AddUrlReply. По умолчанию вызов метода AddUrl прерывается по тайм-ауту через 10 секунд, если клиент не получил ответа за это время. Реализации интерфейса AddUrlService могут включать в себя сколько угодно систем хранения данных, но для клиентов интерфейса это несущественно, поэтому эти подробности не отражены в файле addurl.proto.
Обозначение '= 1' в полях сообщений не имеет никакого отношения к значениям этих полей. Оно существует для того, чтобы протокол можно было дорабатывать. Например, кто-то захочет добавить поле uri в сообщение AddUrlRequest к уже имеющимся полям. Для этого вносится следующее изменение:
Пора писать AddUrlFrontend. Для этого мы объявляем класс AddUrlFrontend в новом файле addurl_frontend.h. Этот код в основном шаблонный.
В этом месте разработчик изменяет существующую спецификацию сборки проекта addurl, включая в нее запись для библиотеки addurl_frontend. При сборке создается статическая библиотека C++ для AddUrlFrontend.
Знатоки гибкой методологии тестирования укажут, что все функции FakeAddUrlService достаточно просты и вместо имитации (fake) можно было бы использовать подставной объект (mock). И они будут правы. Мы реализовали эти функции в виде имитации исключительно для ознакомления с процессом.
Теперь разработчик хочет выполнить написанные тесты. Для этого он должен обновить свои определения сборки и включить новое тестовое правило, определяющее бинарник теста addurl_frontend_test.
Представьте простое веб-приложение, с помощью которого пользователи отправляют URL-адреса в Google для добавления в Google-индекс. Форма HTML содержит два поля – ULR-адрес и комментарий – и генерирует запрос HTTP GET к серверу Google в следующем формате:
GET /addurl?url=http://www.foo.com&comment=Foo+comment HTTP/1.1На стороне сервера это веб-приложение делится на две части: AddUrlFrontend, который получает запрос HTTP, распознает и проверяет его, и бэкенд AddUrlService. Сервис бэкенда получает запросы от AddUrlFrontend, проверяет, нет ли в них ошибок, и дальше взаимодействует с такими хранилищами данных, как, например, Google Bigtable[22] или Google File System[23].
Разработчик начинает работу с создания каталога для проекта:
$ mkdir depot/addurl/Затем он определяет протокол AddUrlService с использованием языка Protocol Buffers[24]:
File: depot/addurl/addurl.protoВ файле addurl.proto определены три важных элемента: сообщения AddUrlRequest и AddUrlReply и сервис удаленного вызова процедур (RPC, Remote Procedure) AddUrlService.
message AddUrlRequest {
required string url = 1; // The URL address entered by user.
optional string comment = 2; // Comments made by user.
}
message AddUrlReply {
// Error code if an error occured.
optional int32 error_code = 1;
// Error mtssage if an error occured.
optional string error_details = 2;
}
service AddUrlService {
// Accepts a URL for submission to the index.
rpc AddUrl(AddUrlRequest) returns (AddUrlReply) {
option deadline = 10.0;
}
}
Посмотрев на определения сообщения AddUrlRequest, мы видим, что поле url должно быть задано вызывающей стороной, а поле comment не является обязательным.
Точно так же из определения сообщения AddUrlReply следует, что оба поля – error_code и error_details опционально могут быть переданы в ответах сервиса. Мы предполагаем, что в типичном случае, когда URL-адрес успешно принят, эти поля останутся пустыми, чтобы минимизировать объем передаваемых данных. Это одно из правил Google: типичный случай должен работать быстро.
Из определения AddUrlService видно, что сервис содержит единственный метод AddUrl, который принимает AddUrlRequest и возвращает AddUrlReply. По умолчанию вызов метода AddUrl прерывается по тайм-ауту через 10 секунд, если клиент не получил ответа за это время. Реализации интерфейса AddUrlService могут включать в себя сколько угодно систем хранения данных, но для клиентов интерфейса это несущественно, поэтому эти подробности не отражены в файле addurl.proto.
Обозначение '= 1' в полях сообщений не имеет никакого отношения к значениям этих полей. Оно существует для того, чтобы протокол можно было дорабатывать. Например, кто-то захочет добавить поле uri в сообщение AddUrlRequest к уже имеющимся полям. Для этого вносится следующее изменение:
message AddUrlRequest {Но это выглядит довольно глупо – скорее всего, потребуется просто переименовать поле url в uri. Если это число и тип останутся неизменными, сохранится совместимость между старой и новой версией:
required string url = 1; // The URL entered by the user.
optional string comment = 2; // Comments made by the user.
optional string uri = 3; // The URI entered by the user.
}
message AddUrlRequest {Написав файл addurl.proto, разработчик переходит к созданию правила сборки proto_library, которое генерирует исходные файлы C++, определяющие сущности из addurl.proto, и компилирует их в статическую библиотеку addurl C++. С дополнительными параметрами можно сгенерировать исходный код для языков Java и Python.
required string uri = 1; // The URI entered by user.
optional string comment = 2; // Comments made by the user.
}
File: depot/addurl/BUILDРазработчик запускает систему сборки и исправляет все проблемы, обнаруженные ею в addurl.proto и в файле BUILD. Система сборки вызывает компилятор Protocol Buffers, генерирует исходные файлы addurl.pb.h и addurl.pb.cc и статическую библиотеку addurl, которую теперь можно подключить.
proto_library(name="addurl",
srcs=["addurl.proto"])
Пора писать AddUrlFrontend. Для этого мы объявляем класс AddUrlFrontend в новом файле addurl_frontend.h. Этот код в основном шаблонный.
File: depot/addurl/addurl_frontend.hПродолжая определять классы AddUrlFrontend, разработчик создает файл addurl_frontend.cc, в котором описывает класс AddUrlFrontend. Для экономии места мы опустили часть файла.
#ifndef ADDURL_ADDURL_FRONTEND_H_
#define ADDURL_ADDURL_FRONTEND_H_
// Forward-declaration of dependencies.
class AddUrlService;
class HTTPRequest;
class HTTPReply;
// Frontend for the AddUrl system.
// Accepts HTTP requests from web clients,
// and forwards well-formed requests to the backend.
class AddUrlFrontend {
public:
// Constructor which enables injection of an
// AddUrlService dependency.
explicit AddUrlFrontend(AddUrlService* add_url_service);
~AddUrlFrontend();
// Method invoked by our HTTP server when a request arrives
// for the /addurl resource.
void HandleAddUrlFrontendRequest(const HTTPRequest* http_request,
HTTPReply* http_reply);
private:
AddUrlService* add_url_service_;
// Declare copy constructor and operator= private to prohibit
// unintentional copying of instances of this class.
AddUrlFrontend(const AddUrlFrontend&);
AddUrlFrontend& operator=(const AddUrlFrontend& rhs);
};
#endif // ADDURL_ADDURL_FRONTEND_H_
File: depot/addurl/addurl_frontend.ccНа функцию HandleAddUrlFrontendRequest ложится большая нагрузка – так устроены многие веб-обработчики. Разработчик может разгрузить эту функцию, выделив часть ее функциональности вспомогательным функциям. Но такой рефакторинг обычно не проводят, пока сборка не станет стабильной, а написанные юнит-тесты не будут успешно проходить.
#include "addurl/addurl_frontend.h"
#include "addurl/addurl.pb.h"
#include "path/to/httpqueryparams.h"
// Functions used by HandleAddUrlFrontendRequest() below, but
// whose definitions are omitted for brevity.
void ExtractHttpQueryParams(const HTTPRequest* http_request,
HTTPQueryParams* query_params);
void WriteHttp200Reply(HTTPReply* reply);
void WriteHttpReplyWithErrorDetails(
HTTPReply* http_reply, const AddUrlReply& add_url_reply);
// AddUrlFrontend constructor that injects the AddUrlService
// dependency.
AddUrlFrontend::AddUrlFrontend(AddUrlService* add_url_service)
: add_url_service_(add_url_service) {
}
// AddUrlFrontend destructor – there's nothing to do here.
AddUrlFrontend::~AddUrlFrontend() {
}
// HandleAddUrlFrontendRequest:
// Handles requests to /addurl by parsing the request,
// dispatching a backend request to an AddUrlService backend,
// and transforming the backend reply into an appropriate
// HTTP reply.
//
// Args:
// http_request – The raw HTTP request received by the server.
// http_reply – The raw HTTP reply to send in response.
void AddUrlFrontend::HandleAddUrlFrontendRequest(
const HTTPRequest* http_request, HTTPReply* http_reply) {
// Extract the query parameters from the raw HTTP request.
HTTPQueryParams query_params;
ExtractHttpQueryParams(http_request, &query_params);
// Get the 'url' and 'comment' query components.
// Default each to an empty string if they were not present
// in http_request.
string url =
query_params.GetQueryComponentDefault("url", "");
string comment =
query_params.GetQueryComponentDefault("comment", "");
// Prepare the request to the AddUrlService backend.
AddUrlRequest add_url_request;
AddUrlReply add_url_reply;
add_url_request.set_url(url);
if (!comment.empty()) {
add_url_request.set_comment(comment);
}
// Issue the request to the AddUrlService backend.
RPC rpc;
add_url_service_->AddUrl(
&rpc, &add_url_request, &add_url_reply);
// Block until the reply is received from the
// AddUrlService backend.
rpc.Wait();
// Handle errors, if any:
if (add_url_reply.has_error_code()) {
WriteHttpReplyWithErrorDetails(http_reply, add_url_reply);
} else {
// No errors. Send HTTP 200 OK response to client.
WriteHttp200Reply(http_reply);
}
}
В этом месте разработчик изменяет существующую спецификацию сборки проекта addurl, включая в нее запись для библиотеки addurl_frontend. При сборке создается статическая библиотека C++ для AddUrlFrontend.
File: /depot/addurl/BUILDРазработчик снова запускает средства сборки, исправляет ошибки компиляции и компоновщика в addurl_frontend.h и addurl_frontend.cc, пока все не будет собираться и компоноваться без предупреждений или ошибок. На этой стадии пора писать юнит-тесты для AddUrlFrontend. Они пишутся в новом файле addurl_frontend_test.cc. Тест определяет имитацию для бэкенд-системы AddUrlService и использует конструктор AddUrlFrontend для внедрения этой имитации во время тестирования. При таком подходе разработчик может внедрять ожидания и ошибки в поток операций AddUrlFrontend без изменения кода AddUrlFrontend.
# From before:
proto_library(name="addurl",
srcs=["addurl.proto"])
# New:
cc_library(name="addurl_frontend",
srcs=["addurl_frontend.cc"],
deps=[
"path/to/httpqueryparams",
"other_http_server_stuff",
":addurl", # Link against the addurl library above.
])
File: depot/addurl/addurl_frontend_test.ccРазработчик напишет еще много похожих тестов, но этот пример хорошо демонстрирует общую схему определения имитации, ее внедрения в тестируемую систему. Он объясняет, как использовать имитацию в тестах для внедрения ошибок и логики проверки в потоке операций тестируемой системы. Один из отсутствующих здесь важных тестов имитирует сетевой тайм-аут между AddUrlFrontend и бэкенд-системой FakeAddUrlService. Такой тест поможет, если наш разработчик забыл проверить и обработать ситуацию с возникновением тайм-аута.
#include "addurl/addurl.pb.h"
#include "addurl/addurl_frontend.h"
// See http://code.google.com/p/googletest/
#include "path/to/googletest.h"
// Defines a fake AddUrlService, which will be injected by
// the AddUrlFrontendTest test fixture into AddUrlFrontend
// instances under test.
class FakeAddUrlService : public AddUrlService {
public:
FakeAddUrlService()
: has_request_expectations_(false),
error_code_(0) {
}
// Allows tests to set expectations on requests.
void set_expected_url(const string& url) {
expected_url_ = url;
has_request_expectations_ = true;
}
void set_expected_comment(const string& comment) {
expected_comment_ = comment;
has_request_expectations_ = true;
}
// Allows for injection of errors by tests.
void set_error_code(int error_code) {
error_code_ = error_code;
}
void set_error_details(const string& error_details) {
error_details_ = error_details;
}
// Overrides of the AddUrlService::AddUrl method generated from
// service definition in addurl.proto by the Protocol Buffer
// compiler.
virtual void AddUrl(RPC* rpc,
const AddUrlRequest* request,
AddUrlReply* reply) {
// Enforce expectations on request (if present).
if (has_request_expectations_) {
EXPECT_EQ(expected_url_, request->url());
EXPECT_EQ(expected_comment_, request->comment());
}
// Inject errors specified in the set_* methods above if present.
if (error_code_ != 0 || !error_details_.empty()) {
reply->set_error_code(error_code_);
reply->set_error_details(error_details_);
}
}
private:
// Expected request information.
// Clients set using set_expected_* methods.
string expected_url_;
string expected_comment_;
bool has_request_expectations_;
// Injected error information.
// Clients set using set_* methods above.
int error_code_;
string error_details_;
};
// The test fixture for AddUrlFrontend. It is code shared by the
// TEST_F test definitions below. For every test using this
// fixture, the fixture will create a FakeAddUrlService, an
// AddUrlFrontend, and inject the FakeAddUrlService into that
// AddUrlFrontend. Tests will have access to both of these
// objects at runtime.
class AddurlFrontendTest : public ::testing::Test {
// Runs before every test method is executed.
virtual void SetUp() {
// Create a FakeAddUrlService for injection.
fake_add_url_service_.reset(new FakeAddUrlService);
// Create an AddUrlFrontend and inject our FakeAddUrlService
// into it.
add_url_frontend_.reset(
new AddUrlFrontend(fake_add_url_service_.get()));
}
scoped_ptr<FakeAddUrlService> fake_add_url_service_;
scoped_ptr<AddUrlFrontend> add_url_frontend_;
};
// Test that AddurlFrontendTest::SetUp works.
TEST_F(AddurlFrontendTest, FixtureTest) {
// AddurlFrontendTest::SetUp was invoked by this point.
}
// Test that AddUrlFrontend parses URLs correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesUrlCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a 'url' query parameter.
http_request.set_text(
"GET /addurl?url=http://www.foo.com HTTP/1.1");
// Tell the FakeAddUrlService to expect to receive a URL
// of 'http://www.foo.com'.
fake_add_url_service_->set_expected_url("http://www.foo.com");
// Send the request to AddUrlFrontend, which should dispatch
// a request to the FakeAddUrlService.
add_url_frontend_->HandleAddUrlFrontendRequest(
&http_request, &http_reply);
// Validate the response.
EXPECT_STREQ("200 OK", http_reply.text());
}
// Test that AddUrlFrontend parses comments correctly from its
// query parameters.
TEST_F(AddurlFrontendTest, ParsesCommentCorrectly) {
HTTPRequest http_request;
HTTPReply http_reply;
// Configure the request to go to the /addurl resource and
// to contain a 'url' query parameter and to also contain
// a 'comment' query parameter that contains the
// url-encoded query string 'Test comment'.
http_request.set_text("GET /addurl?url=http://www.foo.com"
"&comment=Test+comment HTTP/1.1");
// Tell the FakeAddUrlService to expect to receive a URL
// of 'http://www.foo.com' again.
fake_add_url_service_->set_expected_url("http://www.foo.com");
// Tell the FakeAddUrlService to also expect to receive a
// comment of 'Test comment' this time.
fake_add_url_service_->set_expected_comment("Test comment");
Знатоки гибкой методологии тестирования укажут, что все функции FakeAddUrlService достаточно просты и вместо имитации (fake) можно было бы использовать подставной объект (mock). И они будут правы. Мы реализовали эти функции в виде имитации исключительно для ознакомления с процессом.
Теперь разработчик хочет выполнить написанные тесты. Для этого он должен обновить свои определения сборки и включить новое тестовое правило, определяющее бинарник теста addurl_frontend_test.
File: depot/addurl/BUILDИ снова разработчик использует свои инструменты сборки для компилирования и запуска бинарного файла addurl_frontend_test, исправляет все обнаруженные ошибки компилятора и компоновщика. Кроме того, он исправляет тесты, тестовые фикстуры, имитации и саму AddUrlFrontend по всем падениям тестов. Этот процесс начинается сразу же после определения FixtureTest и повторяется при следующих добавлениях тестовых сценариев. Когда все тесты готовы и успешно проходят, разработчик создает список изменений, содержащий все файлы, а заодно исправляет все мелкие проблемы, выявленные в ходе предварительных проверок. После этого он отправляет список изменений на рецензирование и переходит к следующей задаче (скорее всего, начинает писать реальный бэкенд AddUrlService), одновременно ожидая обратной связи от рецензента.
# From before:
proto_library(name="addurl",
srcs=["addurl.proto"])
# Also from before:
cc_library(name="addurl_frontend",
srcs=["addurl_frontend.cc"],
deps=[
"path/to/httpqueryparams",
"other_http_server_stuff",
":addurl", # Depends on the proto_library above.
])
# New:
cc_test(name="addurl_frontend_test",
size="small", # See section on Test Sizes.
srcs=["addurl_frontend_test.cc"],
deps=[
":addurl_frontend", # Depends on library above.
"path/to/googletest_main"])
$ create_cl BUILD \par addurl.proto \par addurl_frontend.h \par addurl_frontend.cc \par addurl_frontend_test.ccПолучив обратную связь, разработчик вносит соответствующие изменения или вместе с рецензентом находит альтернативные решения, возможно – проходит дополнительное рецензирование, после чего отправляет список изменений в систему контроля версий. Системы автоматизации тестирования Google знают, что начиная с этого момента при внесении изменений в код, содержащийся в этих файлах, следует выполнить addurl_frontend_test и убедиться, что новые изменения не ломают существующие тесты. Каждый разработчик, который собирается изменять addurl_frontend.cc, может использовать addurl_frontend_test как страховку для внесения изменений.
$ mail_cl -m reviewer@google.com
Выполнение тестов
Автоматизация тестирования – это больше, чем просто написание отдельных тестов. Если подумать, что еще нужно для хорошего результата, мы увидим, что в автоматизации не обойтись без компиляции тестов и их выполнения, анализа, сортировки и формирования отчетов о результатах каждого прогона. Автоматизация тестирования – это полноценная разработка ПО со всеми вытекающими.
Вся эта работа мешает инженерам сосредоточиться на сути – написании правильных автотестов, приносящих пользу проекту. Код тестов полезен настолько, насколько он ускоряет процесс разработки. Чтобы этого достичь, его нужно встраивать в процесс разработки основного продукта так, чтобы он стал его естественной частью, а не побочной деятельностью. Код продукта никогда не существует в вакууме, сам по себе. Так же должно быть и с кодом тестов.
Вот почему мы построили общую инфраструктуру, которая отвечает за компиляцию, прогон, анализ, хранение и отчетность о тестах. Внимание инженеров Google вернулось к написанию отдельных тестов. Они просто отправляют их в эту общую инфраструктуру, которая заботится о выполнении тестов и следит, чтобы тестовый код обслуживался так же, как и функциональный.
Написав новый набор тестов, разработчик в тестировании создает спецификацию на сборку этого теста для нашей инфраструктуры сборки. Спецификация на сборку теста содержит название теста, исходные файлы для сборки, зависимости файлов от прочих библиотек и данных и, наконец, размер теста. Размер задается обязательно для каждого теста: малый, средний, большой или громадный. Человек только заливает код тестов и спецификацию сборки в систему, средства сборки и инфраструктура прогона тестов Google берут на себя все остальное. Всего лишь по одной команде запустится сборка, выполнится автотест и покажутся результаты этого прогона.
Инфраструктура выполнения тестов накладывает на тесты некоторые ограничения. Что это за ограничения и как с ними работать, мы расскажем в следующем разделе.
Вся эта работа мешает инженерам сосредоточиться на сути – написании правильных автотестов, приносящих пользу проекту. Код тестов полезен настолько, насколько он ускоряет процесс разработки. Чтобы этого достичь, его нужно встраивать в процесс разработки основного продукта так, чтобы он стал его естественной частью, а не побочной деятельностью. Код продукта никогда не существует в вакууме, сам по себе. Так же должно быть и с кодом тестов.
Вот почему мы построили общую инфраструктуру, которая отвечает за компиляцию, прогон, анализ, хранение и отчетность о тестах. Внимание инженеров Google вернулось к написанию отдельных тестов. Они просто отправляют их в эту общую инфраструктуру, которая заботится о выполнении тестов и следит, чтобы тестовый код обслуживался так же, как и функциональный.
Написав новый набор тестов, разработчик в тестировании создает спецификацию на сборку этого теста для нашей инфраструктуры сборки. Спецификация на сборку теста содержит название теста, исходные файлы для сборки, зависимости файлов от прочих библиотек и данных и, наконец, размер теста. Размер задается обязательно для каждого теста: малый, средний, большой или громадный. Человек только заливает код тестов и спецификацию сборки в систему, средства сборки и инфраструктура прогона тестов Google берут на себя все остальное. Всего лишь по одной команде запустится сборка, выполнится автотест и покажутся результаты этого прогона.
Инфраструктура выполнения тестов накладывает на тесты некоторые ограничения. Что это за ограничения и как с ними работать, мы расскажем в следующем разделе.
Определения размеров тестов
По мере роста Google и прихода новых сотрудников в компании началась путаница с названиями тестов: юнит-тесты, тесты на основе кода, тесты белого ящика, интеграционные тесты, системные тесты и сквозные тесты – все они выделяли разные уровни детализации, как рассказывает Пэм на рис. 2.1. Однажды мы решили, что так дальше продолжаться не может, и создали стандартный набор типов тестов.
Малые тесты проверяют работу каждой единицы кода независимо от ее окружения. Примеры таких единиц кода: отдельные классы или небольшие группы связанных функций. У малых тестов не должно быть внешних зависимостей. Вне Google такие малые тесты обычно называют юнит-тестами.
У малых тестов самый узкий охват, и они фокусируются на одной, отделенной от всего, функции, как показано на рис. 2.2 на следующей странице. Такой узкий охват малых тестов позволяет им обеспечивать исчерпывающее покрытие низкоуровневого кода, недоступное для более крупных тестов.
 Рис. 2.1. В Google используется много разных видов тестов
Рис. 2.1. В Google используется много разных видов тестов
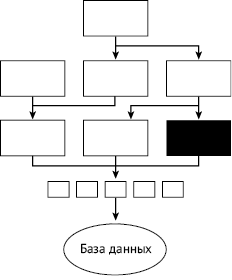 Рис. 2.2. В малом тесте обычно проверяется всего одна функция
Рис. 2.2. В малом тесте обычно проверяется всего одна функция
 Рис. 2.3. Средние тесты охватывают несколько модулей и могут задействовать внешние источники данных
Рис. 2.3. Средние тесты охватывают несколько модулей и могут задействовать внешние источники данных
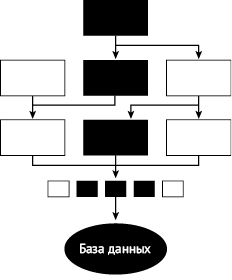 Рис. 2.4. Большие и громадные тесты включают модули, необходимые для сквозного выполнения задач
Рис. 2.4. Большие и громадные тесты включают модули, необходимые для сквозного выполнения задач
Для малых тестов необходимо имитировать внешние сервисы вроде файловой системы, сетей и баз данных через подставные объекты и имитации. Лучше имитировать даже внутренние сервисы, которые находятся внутри того же модуля, что и тестируемый класс. Чем меньше внешних зависимостей – тем лучше для малых тестов.
Ограниченный охват и отсутствие внешних зависимостей означают, что малые тесты могут работать очень быстро. Следовательно, их можно часто запускать и быстро находить ошибки. Задумка в том, чтобы разработчик, по мере запуска тестов и правки основного кода, заодно отвечал за поддержку этого тестового кода. Изоляция малых тестов также позволяет сократить время их сборки и исполнения.
Средние тесты проверяют взаимодействие между двумя или более модулями приложения, как это показано на рис. 2.3. Средние тесты отличаются от малых большим охватом и временем прогона. Если малые тесты пытаются задействовать весь код одной функции, средние тесты направлены на взаимодействие между определенным набором модулей. За пределами Google такие тесты обычно называют интеграционными.
Средними тестами нужно управлять через тестовую инфраструктуру. Из-за большего времени прогона они запускаются реже. В основном эти тесты создаются и выполняются силами разработчиков в тестировании.
Большие и громадные тесты за пределами Google называют системными тестами, или сквозными тестами. Большие тесты оперируют на высоком уровне и проверяют, что система работает как единое целое. Эти тесты задействуют все подсистемы, начиная с пользовательского интерфейса и заканчивая хранилищами данных, как это показано на рис. 2.4. Они могут обращаться к внешним ресурсам, таким как базы данных, файловые системы и сетевые службы.
Малые тесты проверяют работу каждой единицы кода независимо от ее окружения. Примеры таких единиц кода: отдельные классы или небольшие группы связанных функций. У малых тестов не должно быть внешних зависимостей. Вне Google такие малые тесты обычно называют юнит-тестами.
У малых тестов самый узкий охват, и они фокусируются на одной, отделенной от всего, функции, как показано на рис. 2.2 на следующей странице. Такой узкий охват малых тестов позволяет им обеспечивать исчерпывающее покрытие низкоуровневого кода, недоступное для более крупных тестов.
Для малых тестов необходимо имитировать внешние сервисы вроде файловой системы, сетей и баз данных через подставные объекты и имитации. Лучше имитировать даже внутренние сервисы, которые находятся внутри того же модуля, что и тестируемый класс. Чем меньше внешних зависимостей – тем лучше для малых тестов.
Ограниченный охват и отсутствие внешних зависимостей означают, что малые тесты могут работать очень быстро. Следовательно, их можно часто запускать и быстро находить ошибки. Задумка в том, чтобы разработчик, по мере запуска тестов и правки основного кода, заодно отвечал за поддержку этого тестового кода. Изоляция малых тестов также позволяет сократить время их сборки и исполнения.
Средние тесты проверяют взаимодействие между двумя или более модулями приложения, как это показано на рис. 2.3. Средние тесты отличаются от малых большим охватом и временем прогона. Если малые тесты пытаются задействовать весь код одной функции, средние тесты направлены на взаимодействие между определенным набором модулей. За пределами Google такие тесты обычно называют интеграционными.
Средними тестами нужно управлять через тестовую инфраструктуру. Из-за большего времени прогона они запускаются реже. В основном эти тесты создаются и выполняются силами разработчиков в тестировании.
На заметкуИмитация внешних сервисов для средних тестов приветствуется, но не обязательна. Это может быть полезно, если нужно увеличить быстродействие. Там, где полноценная имитация сервисов неоправданна, для повышения производительности можно использовать облегченные вариации, например встроенные в память базы данных.
Малые тесты проверяют поведение отдельной единицы кода. Средние тесты проверяют взаимодействие одного или нескольких модулей кода. Большие тесты проверяют работоспособность системы в целом.
Большие и громадные тесты за пределами Google называют системными тестами, или сквозными тестами. Большие тесты оперируют на высоком уровне и проверяют, что система работает как единое целое. Эти тесты задействуют все подсистемы, начиная с пользовательского интерфейса и заканчивая хранилищами данных, как это показано на рис. 2.4. Они могут обращаться к внешним ресурсам, таким как базы данных, файловые системы и сетевые службы.
Как мы используем размеры тестов в общей инфраструктуре
Автоматизацию тестирования трудно сделать универсальной. Чтобы все проекты в большой IT-компании могли работать с общей тестовой инфраструктурой, она должна поддерживать множество разных сценариев запуска тестов.
Например, вот некоторые типичные сценарии запуска тестов, которые поддерживает общая инфраструктура тестирования Google.
– Разработчик хочет скомпилировать и запустить малый тест и тут же получить результаты.
– Разработчик хочет запустить все малые тесты для проекта и тут же получить результаты.
– Разработчик хочет скомпилировать и запустить только те тесты, которые связаны с последним изменением кода, и тут же получить результаты.
– Разработчик или тестировщик хочет собрать данные о покрытии кода в конкретном проекте и посмотреть результаты.
– Команда хочет прогонять все малые тесты для своего проекта каждый раз при создании списка изменений и рассылать результаты всем участникам команды.
– Команда хочет прогонять все тесты для своего проекта после отправки списка изменений в систему управления версиями.
– Команда хочет еженедельно собирать статистику о покрытии кода и отслеживать его прогресс со временем.
Может быть и так, что все вышеперечисленные задания отправляются в систему выполнения тестов Google одновременно. Некоторые из тестов могут захватывать ресурсы, занимая общие машины на целые часы. Другим будет достаточно миллисекунд для выполнения, и они могут благополучно исполняться на одной машине с сотнями других тестов. Когда тесты помечены как малые, средние и большие, гораздо проще планировать расписание выполнения запусков, так как планировщик понимает, сколько времени может занять запуск, и оптимизирует очередь.
Система выполнения тестов Google отличает быстрые задания от медленных по информации о размере тестов. У каждого размера есть верхняя граница времени выполнения теста (табл. 2.1). Размер определяет и потенциальную потребность в ресурсах (табл. 2.2). Система прерывает выполнение и сообщает об ошибке, если тест превышает выделенное для его категории время или доступный объем ресурса. Это мотивирует разработчиков в тестировании назначать правильные метки размеров тестов. Точное определение размеров тестов позволяет системе строить эффективное расписание.
 Таблица 2.1. Цели и ограничения времени отработки тестов по их размеру
Таблица 2.1. Цели и ограничения времени отработки тестов по их размеру
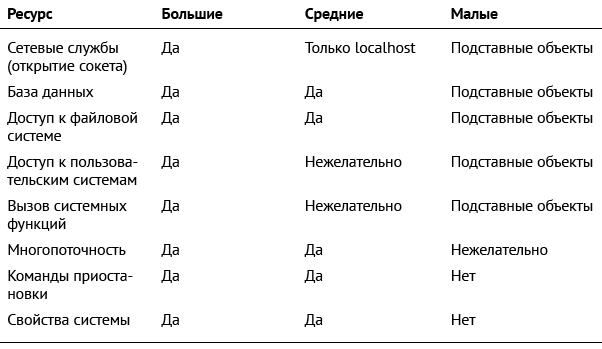 Таблица 2.2. Использование ресурсов в зависимости от размеров теста
Таблица 2.2. Использование ресурсов в зависимости от размеров теста
Например, вот некоторые типичные сценарии запуска тестов, которые поддерживает общая инфраструктура тестирования Google.
– Разработчик хочет скомпилировать и запустить малый тест и тут же получить результаты.
– Разработчик хочет запустить все малые тесты для проекта и тут же получить результаты.
– Разработчик хочет скомпилировать и запустить только те тесты, которые связаны с последним изменением кода, и тут же получить результаты.
– Разработчик или тестировщик хочет собрать данные о покрытии кода в конкретном проекте и посмотреть результаты.
– Команда хочет прогонять все малые тесты для своего проекта каждый раз при создании списка изменений и рассылать результаты всем участникам команды.
– Команда хочет прогонять все тесты для своего проекта после отправки списка изменений в систему управления версиями.
– Команда хочет еженедельно собирать статистику о покрытии кода и отслеживать его прогресс со временем.
Может быть и так, что все вышеперечисленные задания отправляются в систему выполнения тестов Google одновременно. Некоторые из тестов могут захватывать ресурсы, занимая общие машины на целые часы. Другим будет достаточно миллисекунд для выполнения, и они могут благополучно исполняться на одной машине с сотнями других тестов. Когда тесты помечены как малые, средние и большие, гораздо проще планировать расписание выполнения запусков, так как планировщик понимает, сколько времени может занять запуск, и оптимизирует очередь.
Система выполнения тестов Google отличает быстрые задания от медленных по информации о размере тестов. У каждого размера есть верхняя граница времени выполнения теста (табл. 2.1). Размер определяет и потенциальную потребность в ресурсах (табл. 2.2). Система прерывает выполнение и сообщает об ошибке, если тест превышает выделенное для его категории время или доступный объем ресурса. Это мотивирует разработчиков в тестировании назначать правильные метки размеров тестов. Точное определение размеров тестов позволяет системе строить эффективное расписание.
