– Большие тесты проверяют самое важное – работу приложения. Они учитывают поведение внешних подсистем.
– Большие тесты могут быть недетерминированными (результат может быть получен разными путями), потому что зависят от внешних подсистем.
– Большой охват усложняет поиск причин при неудачном прохождении теста.
– Подготовка данных для тестовых сценариев может занимать много времени.
– Из-за высокоуровневости больших тестов в них трудно прорабатывать граничные значения. Для этого нужны малые тесты.
Средние тесты
Малые тесты
Требования к выполнению тестов
– Большие тесты могут быть недетерминированными (результат может быть получен разными путями), потому что зависят от внешних подсистем.
– Большой охват усложняет поиск причин при неудачном прохождении теста.
– Подготовка данных для тестовых сценариев может занимать много времени.
– Из-за высокоуровневости больших тестов в них трудно прорабатывать граничные значения. Для этого нужны малые тесты.
Средние тесты
Достоинства и недостатки средних тестов:
– Требования к подставным объектам мягче, а временные ограничения свободнее, чем у малых тестов. Разработчики используют их как промежуточную ступень для перехода от больших тестов к малым.
– Средние тесты выполняются относительно быстро, поэтому разработчики могут запускать их часто.
– Средние тесты выполняются в стандартной среде разработки, поэтому их очень легко запускать.
– Средние тесты учитывают поведение внешних подсистем.
– Средние тесты могут быть недетерминированными, потому что зависят от внешних подсистем.
– Средние тесты выполняются не так быстро, как малые.
– Требования к подставным объектам мягче, а временные ограничения свободнее, чем у малых тестов. Разработчики используют их как промежуточную ступень для перехода от больших тестов к малым.
– Средние тесты выполняются относительно быстро, поэтому разработчики могут запускать их часто.
– Средние тесты выполняются в стандартной среде разработки, поэтому их очень легко запускать.
– Средние тесты учитывают поведение внешних подсистем.
– Средние тесты могут быть недетерминированными, потому что зависят от внешних подсистем.
– Средние тесты выполняются не так быстро, как малые.
Малые тесты
Достоинства и недостатки малых тестов:
– Малые тесты помогают повысить чистоту кода, потому что работают узконаправленно с небольшими методами. Соблюдение требований подставных объектов приводит к хорошо структурированным интерфейсам между подсистемами.
– Из-за скорости выполнения малые тесты выявляют баги очень рано и дают немедленную обратную связь при внесении изменений в код.
– Малые тесты надежно выполняются во всех средах.
– Малые тесты обладают большей детализацией, а это упрощает тестирование граничных случаев и поиск состояний, приводящих к ошибкам, например null-указатели.
– Узкая направленность малых тестов сильно упрощает локализацию ошибок.
– Малые тесты не проверяют интеграцию между модулями – для этого используются другие тесты.
– Иногда сложно применить подставные объекты для подсистем.
– Подставные объекты и псевдосреды могут отличаться от реальности.
Малые тесты способствуют созданию качественного кода, хорошей проработке исключений и получению информации об ошибках. Более масштабные тесты ориентированы на общее качество продукта и проверку данных. Ни один тип тестов не покрывает все потребности продукта в тестировании. Поэтому в проектах Google мы стараемся использовать разумное сочетание всех типов тестов в каждом тестовом наборе. Автоматизация, основанная только на больших комплексных тестах, так же вредна, как и создание только малых юнит-тестов.
Google разрабатывает самые разные проекты, их потребности в тестировании сильно отличаются. В начале работы мы обычно используем правило 70/20/10: 70 % малых тестов, 20 % – средних и 10 % – больших. В пользовательских проектах со сложными интерфейсами или высокой степенью интеграции доля средних и крупных тестов должна быть выше. В инфраструктурных проектах или проектах, где много обработки данных (например, индексирование или обход веб-контента), малых тестов нужно намного больше, чем больших и средних.
Для наблюдения за покрытием кода в Google используется внутренний инструмент – Harvester. Это инструмент визуализации, который отслеживает все списки изменений проекта и графически отображает важные показатели: отношение объема кода тестов к объему нового кода в конкретных списках изменений; размер изменений; зависимость частоты изменений от времени и даты; распределение изменений по разработчикам и т. д. Цель Harvester – дать общую сводку об изменениях в процессе тестирования проекта со временем.
– Малые тесты помогают повысить чистоту кода, потому что работают узконаправленно с небольшими методами. Соблюдение требований подставных объектов приводит к хорошо структурированным интерфейсам между подсистемами.
– Из-за скорости выполнения малые тесты выявляют баги очень рано и дают немедленную обратную связь при внесении изменений в код.
– Малые тесты надежно выполняются во всех средах.
– Малые тесты обладают большей детализацией, а это упрощает тестирование граничных случаев и поиск состояний, приводящих к ошибкам, например null-указатели.
– Узкая направленность малых тестов сильно упрощает локализацию ошибок.
– Малые тесты не проверяют интеграцию между модулями – для этого используются другие тесты.
– Иногда сложно применить подставные объекты для подсистем.
– Подставные объекты и псевдосреды могут отличаться от реальности.
Малые тесты способствуют созданию качественного кода, хорошей проработке исключений и получению информации об ошибках. Более масштабные тесты ориентированы на общее качество продукта и проверку данных. Ни один тип тестов не покрывает все потребности продукта в тестировании. Поэтому в проектах Google мы стараемся использовать разумное сочетание всех типов тестов в каждом тестовом наборе. Автоматизация, основанная только на больших комплексных тестах, так же вредна, как и создание только малых юнит-тестов.
На заметкуПокрытие кода — отличный инструмент, чтобы оценить, насколько разумно используется сочетание разных размеров тестов в проекте. Проект генерирует один отчет с данными покрытия только для малых тестов, а потом другой отчет с данными только для средних и больших тестов. Каждый отчет в отдельности должен показывать приемлемую величину покрытия для проекта. Если средние и большие тесты в отдельности обеспечивают только 20-процентное покрытие, а покрытие малыми тестами приближается к 100, то у проекта не будет доказательств работоспособности всей системы. А если поменять эти числа местами, скорее всего, расширение или сопровождение проекта потребует серьезных затрат на отладку. Чтобы генерировать и просматривать данные о покрытии кода на ходу, мы используем те же инструменты, которые собирают и выполняют тесты. Достаточно поставить дополнительный флаг в командной строке. Данные о покрытии кода хранятся в облаке, и любой инженер может просмотреть их через веб в любой момент.
Малые тесты направлены на проверку качества кода, а средние и большие – на проверку качества всего продукта.
Google разрабатывает самые разные проекты, их потребности в тестировании сильно отличаются. В начале работы мы обычно используем правило 70/20/10: 70 % малых тестов, 20 % – средних и 10 % – больших. В пользовательских проектах со сложными интерфейсами или высокой степенью интеграции доля средних и крупных тестов должна быть выше. В инфраструктурных проектах или проектах, где много обработки данных (например, индексирование или обход веб-контента), малых тестов нужно намного больше, чем больших и средних.
Для наблюдения за покрытием кода в Google используется внутренний инструмент – Harvester. Это инструмент визуализации, который отслеживает все списки изменений проекта и графически отображает важные показатели: отношение объема кода тестов к объему нового кода в конкретных списках изменений; размер изменений; зависимость частоты изменений от времени и даты; распределение изменений по разработчикам и т. д. Цель Harvester – дать общую сводку об изменениях в процессе тестирования проекта со временем.
Требования к выполнению тестов
У системы выполнения тестов в Google одинаковые требования ко всем тестам.
– Каждый тест должен быть независим от других, чтобы тесты могли выполняться в любом порядке.
– Тесты не должны иметь долгосрочных последствий. После их завершения среда должна возвращаться в то же состояние, в котором она находилась при запуске.
Требования простые и понятные, но выполнить их оказывается не так просто. Даже если сам тест отвечает требованиям, тестируемая программа может их нарушать, сохраняя файлы данных или изменяя конфигурацию. К счастью, сама среда выполнения тестов Google упрощает соблюдение этих требований.
Что касается требования независимости, инженер во время прогона может установить флаг выполнения тестов в случайном порядке. Эта фича помогает выявить зависимости, связанные с порядком выполнения. Впрочем, случайный порядок может означать, что тесты запускаются параллельно. Система может отправить выполнять два теста на одной машине. Если каждый тест требует единоличного доступа к ресурсам системы, один из них упадет. Например:
– оба теста пытаются подключиться к одному порту для единоличного получения сетевого трафика;
– оба теста пытаются создать каталог, используя один путь;
– один тест создает и заполняет таблицу базы данных, а другой пытается удалить ту же таблицу.
Такие конфликты могут вызывать сбои не только в самих тестах, но и в соседних тестах, которые выполняются в той же системе, даже если эти другие тесты соблюдают правила. Наша система умеет выявлять такие ситуации и оповещать владельцев тестов-бунтарей.
Если установить специальный флаг, тест будет выполняться единолично на выделенной машине. Но это лишь временное решение. Все равно придется переписать тесты и удалить зависимости от критических ресурсов. Например, эти проблемы можно решить так:
– каждый тест запрашивает свободный порт у системы выполнения тестов, а тестируемая программа динамически к нему подключается;
– каждый тест создает все папки и файлы во временной директории, созданной и выделенной системой специально для него перед выполнением тестов;
– каждый тест работает со своим экземпляром базы данных в изолированной среде с выделенными системой выполнения тестов директориями и портами.
Ребята, ответственные за сопровождение системы выполнения тестов Google, довольно подробно описали свою среду выполнения тестов. Их документ называется «Энциклопедией тестирования Google», и он отвечает на все вопросы о том, какие ресурсы доступны тестам во время выполнения. «Энциклопедия тестирования» составлена как стандартизированный документ, где у терминов «должен» и «будет» однозначное значение. В энциклопедии подробно объясняются роли и обязанности тестов, исполнителей тестов, систем хостинга, рантайм-библиотек, файловых систем и т. д.
Вряд ли все инженеры Google читали «Энциклопедию тестирования». Скорее всего, большинство предпочитает учиться у других, или испытывать метод проб и ошибок, или постоянно натыкаться на комментарии рецензентов их кода. Они и не подозревают, что общая среда выполнения тестов может обслужить все проекты по тестированию Google. Чтобы это узнать, достаточно заглянуть в энциклопедию. Им неизвестно, что этот документ – главная причина того, что тесты ведут себя в общей среде ровно так же, как и на личной машине написавшего тест инженера. Технические детали даже самых сложных систем остаются незамеченными теми, кто их использует. Все же работает, зачем читать.
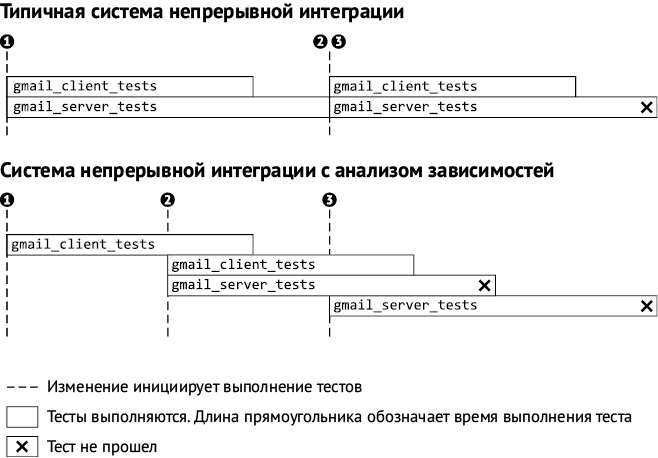 Рис. 2.6. Сравнение систем непрерывной интеграции
Рис. 2.6. Сравнение систем непрерывной интеграции
– Каждый тест должен быть независим от других, чтобы тесты могли выполняться в любом порядке.
– Тесты не должны иметь долгосрочных последствий. После их завершения среда должна возвращаться в то же состояние, в котором она находилась при запуске.
Требования простые и понятные, но выполнить их оказывается не так просто. Даже если сам тест отвечает требованиям, тестируемая программа может их нарушать, сохраняя файлы данных или изменяя конфигурацию. К счастью, сама среда выполнения тестов Google упрощает соблюдение этих требований.
Что касается требования независимости, инженер во время прогона может установить флаг выполнения тестов в случайном порядке. Эта фича помогает выявить зависимости, связанные с порядком выполнения. Впрочем, случайный порядок может означать, что тесты запускаются параллельно. Система может отправить выполнять два теста на одной машине. Если каждый тест требует единоличного доступа к ресурсам системы, один из них упадет. Например:
– оба теста пытаются подключиться к одному порту для единоличного получения сетевого трафика;
– оба теста пытаются создать каталог, используя один путь;
– один тест создает и заполняет таблицу базы данных, а другой пытается удалить ту же таблицу.
Такие конфликты могут вызывать сбои не только в самих тестах, но и в соседних тестах, которые выполняются в той же системе, даже если эти другие тесты соблюдают правила. Наша система умеет выявлять такие ситуации и оповещать владельцев тестов-бунтарей.
Если установить специальный флаг, тест будет выполняться единолично на выделенной машине. Но это лишь временное решение. Все равно придется переписать тесты и удалить зависимости от критических ресурсов. Например, эти проблемы можно решить так:
– каждый тест запрашивает свободный порт у системы выполнения тестов, а тестируемая программа динамически к нему подключается;
– каждый тест создает все папки и файлы во временной директории, созданной и выделенной системой специально для него перед выполнением тестов;
– каждый тест работает со своим экземпляром базы данных в изолированной среде с выделенными системой выполнения тестов директориями и портами.
Ребята, ответственные за сопровождение системы выполнения тестов Google, довольно подробно описали свою среду выполнения тестов. Их документ называется «Энциклопедией тестирования Google», и он отвечает на все вопросы о том, какие ресурсы доступны тестам во время выполнения. «Энциклопедия тестирования» составлена как стандартизированный документ, где у терминов «должен» и «будет» однозначное значение. В энциклопедии подробно объясняются роли и обязанности тестов, исполнителей тестов, систем хостинга, рантайм-библиотек, файловых систем и т. д.
Вряд ли все инженеры Google читали «Энциклопедию тестирования». Скорее всего, большинство предпочитает учиться у других, или испытывать метод проб и ошибок, или постоянно натыкаться на комментарии рецензентов их кода. Они и не подозревают, что общая среда выполнения тестов может обслужить все проекты по тестированию Google. Чтобы это узнать, достаточно заглянуть в энциклопедию. Им неизвестно, что этот документ – главная причина того, что тесты ведут себя в общей среде ровно так же, как и на личной машине написавшего тест инженера. Технические детали даже самых сложных систем остаются незамеченными теми, кто их использует. Все же работает, зачем читать.
Тестирование на скоростях и в масштабах Google
Пуджа Гупта, Марк Айви и Джон Пеникс
Системы непрерывной интеграции – главные герои обеспечения работоспособности программного продукта во время разработки. Типичная схема работы большинства систем непрерывной интеграции такая.
1. Получить последнюю копию кода.
2. Выполнить все тесты.
3. Сообщить о результатах.
4. Перейти к пункту 1.
Решение отлично справляется с небольшой кодовой базой, пока динамичность изменений кода не выходит за рамки, а тесты прогоняются быстро. Чем больше становится кода, тем сильнее падает эффективность подобных систем. Добавление нового кода увеличивает время «чистого» запуска, и в один прогон включается все больше изменений. Если что-то сломается, найти и исправить изменение становится все сложнее.
Разработка программных продуктов в Google происходит быстро и с размахом. Мы добавляем в базу кода всего Google больше 20 изменений в минуту, и 50 % файлов в ней меняются каждый месяц. Разработка и выпуск всех продуктов опираются на автотесты, проверяющие поведение продукта. Есть продукты, которые выпускаются несколько раз в день, другие – раз в несколько недель.
По идее, при такой огромной и динамичной базе кода команды должны тратить кучу времени только на поддержание сборки в состоянии «зеленого света». Система непрерывной интеграции должна помогать с этим. Она должна сразу выделять изменение, приводящее к сбою теста, а не просто указывать на набор подозрительных изменений или, что еще хуже, перебирать их все в поисках нарушителя.
Чтобы решить эту проблему, мы построили систему непрерывной сборки (рис. 2.6), которая анализирует зависимости и выделяет только те тесты, которые связаны с конкретным изменением, а потом выполняет только их. И так для каждого изменения. Система построена на инфраструктуре облачных вычислений Google, которая позволяет одновременно выполнять большое количество сборок и запускать затронутые тесты сразу же после отправки изменений.
Примером ниже мы показываем, как наша система дает более быструю и точную обратную связь, чем типичная непрерывная сборка. В нашем сценарии используются два теста и три изменения, затрагивающие эти тесты. Тест gmail_server_tests падает из-за изменения 2. Типичная система непрерывной сборки сообщила бы, что к сбой случился из-за изменения 2 или 3, не уточняя. Мы же используем механизм параллельного выполнения, поэтому запускаем тесты независимо, не дожидаясь завершения текущего цикла «сборка – тестирование». Анализ зависимостей сузит набор тестов для каждого изменения, поэтому в нашем примере общее количество выполнений теста то же самое.
Конец бесплатного ознакомительного фрагмента