Страница:
Метод имеет два очевидных недостатка. Первый из них – неэффективное использование объема памяти под таблицу идентификаторов: размер массива для ее хранения должен соответствовать всей области значений хэш-функции, в то время как реально хранимых в таблице идентификаторов может быть существенно меньше. Второй недостаток – необходимость соответствующего разумного выбора хэш-функции. Этот недостаток является настолько существенным, что не позволяет непосредственно использовать хэш-адресацию для организации таблиц идентификаторов.
Проблема выбора хэш-функции не имеет универсального решения. Хэширование обычно происходит за счет выполнения над цепочкой символов некоторых простых арифметических и логических операций. Самой простой хэш-функцией для символа является код внутреннего представления в компьютере литеры символа. Эту хэш-функцию можно использовать и для цепочки символов, выбирая первый символ в цепочке.
Очевидно, что такая примитивная хэш-функция будет неудовлетворительной: при ее использовании возникнет проблема – двум различным идентификаторам, начинающимся с одной и той же буквы, будет соответствовать одно и то же значение хэш-функции. Тогда при хэш-адресации в одну и ту же ячейку таблицы идентификаторов должны быть помещены два различных идентификатора, что явно невозможно. Такая ситуация, когда двум или более идентификаторам соответствует одно и то же значение хэш-функции, называется коллизией.
Естественно, что хэш-функция, допускающая коллизии, не может быть использована для хэш-адресации в таблице идентификаторов. Причем достаточно получить хотя бы один случай коллизии на всем множестве идентификаторов, чтобы такой хэш-функцией нельзя было пользоваться. Но возможно ли построить хэш-функцию, которая бы полностью исключала возникновение коллизий?
Для полного исключения коллизий хэш-функция должна быть взаимно однозначной: каждому элементу из области определения хэш-функции должно соответствовать одно значение из ее множества значений, и наоборот – каждому значению из множества значений этой функции должен соответствовать только один элемент из ее области определения. Тогда любым двум произвольным элементам из области определения хэш-функции будут всегда соответствовать два различных ее значения. Теоретически для идентификаторов такую хэш-функцию построить можно, так как и область определения хэш-функции (все возможные имена идентификаторов), и область ее значений (целые неотрицательные числа) являются бесконечными счетными множествами, поэтому можно организовать взаимно однозначное отображение одного множества на другое.
Но на практике существует ограничение, делающее создание взаимно однозначной хэш-функции для идентификаторов невозможным. Дело в том, что в реальности область значений любой хэш-функции ограничена размером доступного адресного пространства компьютера. Множество адресов любого компьютера с традиционной архитектурой может быть велико, но всегда конечно, то есть ограничено. Организовать взаимно однозначное отображение бесконечного множества на конечное даже теоретически невозможно. Можно, конечно, учесть, что длина принимаемой во внимание части имени идентификатора в реальных компиляторах на практике также ограничена – обычно она лежит в пределах от 32 до 128 символов (то есть и область определения хэш-функции конечна). Но и тогда количество элементов в конечном множестве, составляющем область определения хэш-функции, будет превышать их количество в конечном множестве области ее значений (количество всех возможных идентификаторов больше количества допустимых адресов в современных компьютерах). Таким образом, создать взаимно однозначную хэш-функцию на практике невозможно. Следовательно, невозможно избежать возникновения коллизий.
Поэтому нельзя организовать таблицу идентификаторов непосредственно на основе одной только хэш-адресации. Но существуют методы, позволяющие использовать хэш-функции для организации таблиц идентификаторов даже при наличии коллизий.
Хэш-адресация с рехэшированием
Хэш-адресация с использованием метода цепочек
Комбинированные способы построения таблиц идентификаторов
Требования к выполнению работы
Порядок выполнения работы
Требования к оформлению отчета
Основные контрольные вопросы
Варианты заданий
Пример выполнения работы
Задание для примера
Выбор и описание хэш-функции
Проблема выбора хэш-функции не имеет универсального решения. Хэширование обычно происходит за счет выполнения над цепочкой символов некоторых простых арифметических и логических операций. Самой простой хэш-функцией для символа является код внутреннего представления в компьютере литеры символа. Эту хэш-функцию можно использовать и для цепочки символов, выбирая первый символ в цепочке.
Очевидно, что такая примитивная хэш-функция будет неудовлетворительной: при ее использовании возникнет проблема – двум различным идентификаторам, начинающимся с одной и той же буквы, будет соответствовать одно и то же значение хэш-функции. Тогда при хэш-адресации в одну и ту же ячейку таблицы идентификаторов должны быть помещены два различных идентификатора, что явно невозможно. Такая ситуация, когда двум или более идентификаторам соответствует одно и то же значение хэш-функции, называется коллизией.
Естественно, что хэш-функция, допускающая коллизии, не может быть использована для хэш-адресации в таблице идентификаторов. Причем достаточно получить хотя бы один случай коллизии на всем множестве идентификаторов, чтобы такой хэш-функцией нельзя было пользоваться. Но возможно ли построить хэш-функцию, которая бы полностью исключала возникновение коллизий?
Для полного исключения коллизий хэш-функция должна быть взаимно однозначной: каждому элементу из области определения хэш-функции должно соответствовать одно значение из ее множества значений, и наоборот – каждому значению из множества значений этой функции должен соответствовать только один элемент из ее области определения. Тогда любым двум произвольным элементам из области определения хэш-функции будут всегда соответствовать два различных ее значения. Теоретически для идентификаторов такую хэш-функцию построить можно, так как и область определения хэш-функции (все возможные имена идентификаторов), и область ее значений (целые неотрицательные числа) являются бесконечными счетными множествами, поэтому можно организовать взаимно однозначное отображение одного множества на другое.
Но на практике существует ограничение, делающее создание взаимно однозначной хэш-функции для идентификаторов невозможным. Дело в том, что в реальности область значений любой хэш-функции ограничена размером доступного адресного пространства компьютера. Множество адресов любого компьютера с традиционной архитектурой может быть велико, но всегда конечно, то есть ограничено. Организовать взаимно однозначное отображение бесконечного множества на конечное даже теоретически невозможно. Можно, конечно, учесть, что длина принимаемой во внимание части имени идентификатора в реальных компиляторах на практике также ограничена – обычно она лежит в пределах от 32 до 128 символов (то есть и область определения хэш-функции конечна). Но и тогда количество элементов в конечном множестве, составляющем область определения хэш-функции, будет превышать их количество в конечном множестве области ее значений (количество всех возможных идентификаторов больше количества допустимых адресов в современных компьютерах). Таким образом, создать взаимно однозначную хэш-функцию на практике невозможно. Следовательно, невозможно избежать возникновения коллизий.
Поэтому нельзя организовать таблицу идентификаторов непосредственно на основе одной только хэш-адресации. Но существуют методы, позволяющие использовать хэш-функции для организации таблиц идентификаторов даже при наличии коллизий.
Хэш-адресация с рехэшированием
Для решения проблемы коллизии можно использовать много способов. Одним из них является метод рехэширования (или расстановки). Согласно этому методу, если для элемента А адрес n0 = h(A), вычисленный с помощью хэш-функции h, указывает на уже занятую ячейку, то необходимо вычислить значение функции n1 = h1(A) и проверить занятость ячейки по адресу п1. Если и она занята, то вычисляется значение h2(A), и так до тех пор, пока либо не будет найдена свободная ячейка, либо очередное значение hi(А) не совпадет с h(A). В последнем случае считается, что таблица идентификаторов заполнена и места в ней больше нет – выдается информация об ошибке размещения идентификатора в таблице.
Тогда поиск элемента А в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму:
1. Вычислить значение хэш-функции n = h(A) для искомого элемента А.
2. Если ячейка по адресу п пустая, то элемент не найден, алгоритм завершен, иначе необходимо сравнить имя элемента в ячейке n с именем искомого элемента A. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= 1 и перейти к шагу 3.
3. Вычислить ni = hi(A). Если ячейка по адресу ni пустая или n = ni, то элемент не найден и алгоритм завершен, иначе – сравнить имя элемента в ячейке ni с именем искомого элемента A. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= i + 1 и повторить шаг 3.
Алгоритмы размещения и поиска элемента схожи по выполняемым операциям. Поэтому они будут иметь одинаковые оценки времени, необходимого для их выполнения.
При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм помещает элементы в пустые ячейки таблицы, выбирая их определенным образом. При этом элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хэш-функции, что приведет к возникновению новых, дополнительных коллизий. Таким образом, количество операций, необходимых для поиска или размещения в таблице элемента, зависит от заполненности таблицы.
Для организации таблицы идентификаторов по методу рехэширования необходимо определить все хэш-функции hi для всех i. Чаще всего функции hi определяют как некоторые модификации хэш-функции h. Например, самым простым методом вычисления функции hi(A) является ее организация в виде hi(A) = (h(A) + pi) mod Nm, где pi – некоторое вычисляемое целое число, а Nm – максимальное значение из области значений хэш-функции h. В свою очередь, самым простым подходом здесь будет положить pi = i. Тогда получаем формулу hi(A) = (h(A) + i) mod Nm. В этом случае при совпадении значений хэш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хэш-функцией h(A).
Этот способ нельзя признать особенно удачным: при совпадении хэш-адресов элементы в таблице начинают группироваться вокруг них, что увеличивает число необходимых сравнений при поиске и размещении. Но даже такой примитивный метод рехэширования является достаточно эффективным средством организации таблиц идентификаторов при неполном заполнении таблицы.
Среднее время на помещение одного элемента в таблицу и на поиск элемента в таблице можно снизить, если применить более совершенный метод рехэширования. Одним из таких методов является использование в качестве pi для функции hi(A) = (h(A) + pi) mod Nm последовательности псевдослучайных целых чисел p1, p2, …, pk. При хорошем выборе генератора псевдослучайных чисел длина последовательности k = Nm.
Существуют и другие методы организации функций рехэширования hi(A), основанные на квадратичных вычислениях или, например, на вычислении произведения по формуле: hi(A) = (h(A)N·i) mod N'm, где N'm – ближайшее простое число, меньшее Nm. В целом рехэширование позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем бинарный поиск и бинарное дерево), но эффективность метода сильно зависит от заполненности таблицы идентификаторов и качества используемой хэш-функции – чем реже возникают коллизии, тем выше эффективность метода. Требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Оценки времени размещения и поиска элемента в таблицах идентификаторов при использовании различных методов рехэширования можно найти в [1, 3, 7].
Тогда поиск элемента А в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму:
1. Вычислить значение хэш-функции n = h(A) для искомого элемента А.
2. Если ячейка по адресу п пустая, то элемент не найден, алгоритм завершен, иначе необходимо сравнить имя элемента в ячейке n с именем искомого элемента A. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= 1 и перейти к шагу 3.
3. Вычислить ni = hi(A). Если ячейка по адресу ni пустая или n = ni, то элемент не найден и алгоритм завершен, иначе – сравнить имя элемента в ячейке ni с именем искомого элемента A. Если они совпадают, то элемент найден и алгоритм завершен, иначе i:= i + 1 и повторить шаг 3.
Алгоритмы размещения и поиска элемента схожи по выполняемым операциям. Поэтому они будут иметь одинаковые оценки времени, необходимого для их выполнения.
При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм помещает элементы в пустые ячейки таблицы, выбирая их определенным образом. При этом элементы могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хэш-функции, что приведет к возникновению новых, дополнительных коллизий. Таким образом, количество операций, необходимых для поиска или размещения в таблице элемента, зависит от заполненности таблицы.
Для организации таблицы идентификаторов по методу рехэширования необходимо определить все хэш-функции hi для всех i. Чаще всего функции hi определяют как некоторые модификации хэш-функции h. Например, самым простым методом вычисления функции hi(A) является ее организация в виде hi(A) = (h(A) + pi) mod Nm, где pi – некоторое вычисляемое целое число, а Nm – максимальное значение из области значений хэш-функции h. В свою очередь, самым простым подходом здесь будет положить pi = i. Тогда получаем формулу hi(A) = (h(A) + i) mod Nm. В этом случае при совпадении значений хэш-функции для каких-либо элементов поиск свободной ячейки в таблице начинается последовательно от текущей позиции, заданной хэш-функцией h(A).
Этот способ нельзя признать особенно удачным: при совпадении хэш-адресов элементы в таблице начинают группироваться вокруг них, что увеличивает число необходимых сравнений при поиске и размещении. Но даже такой примитивный метод рехэширования является достаточно эффективным средством организации таблиц идентификаторов при неполном заполнении таблицы.
Среднее время на помещение одного элемента в таблицу и на поиск элемента в таблице можно снизить, если применить более совершенный метод рехэширования. Одним из таких методов является использование в качестве pi для функции hi(A) = (h(A) + pi) mod Nm последовательности псевдослучайных целых чисел p1, p2, …, pk. При хорошем выборе генератора псевдослучайных чисел длина последовательности k = Nm.
Существуют и другие методы организации функций рехэширования hi(A), основанные на квадратичных вычислениях или, например, на вычислении произведения по формуле: hi(A) = (h(A)N·i) mod N'm, где N'm – ближайшее простое число, меньшее Nm. В целом рехэширование позволяет добиться неплохих результатов для эффективного поиска элемента в таблице (лучших, чем бинарный поиск и бинарное дерево), но эффективность метода сильно зависит от заполненности таблицы идентификаторов и качества используемой хэш-функции – чем реже возникают коллизии, тем выше эффективность метода. Требование неполного заполнения таблицы ведет к неэффективному использованию объема доступной памяти.
Оценки времени размещения и поиска элемента в таблицах идентификаторов при использовании различных методов рехэширования можно найти в [1, 3, 7].
Хэш-адресация с использованием метода цепочек
Неполное заполнение таблицы идентификаторов при применении рехэширования ведет к неэффективному использованию всего объема памяти, доступного компилятору. Причем объем неиспользуемой памяти будет тем выше, чем больше информации хранится для каждого идентификатора. Этого недостатка можно избежать, если дополнить таблицу идентификаторов некоторой промежуточной хэш-таблицей.
В ячейках хэш-таблицы может храниться либо пустое значение, либо значение указателя на некоторую область памяти из основной таблицы идентификаторов. Тогда хэш-функция вычисляет адрес, по которому происходит обращение сначала к хэш-таблице, а потом уже через нее по найденному адресу – к самой таблице идентификаторов. Если соответствующая ячейка таблицы идентификаторов пуста, то ячейка хэш-таблицы будет содержать пустое значение. Тогда вовсе не обязательно иметь в самой таблице идентификаторов ячейку для каждого возможного значения хэш-функции – таблицу можно сделать динамической, так чтобы ее объем рос по мере заполнения (первоначально таблица идентификаторов не содержит ни одной ячейки, а все ячейки хэш-таблицы имеют пустое значение).
Такой подход позволяет добиться двух положительных результатов: во-первых, нет необходимости заполнять пустыми значениями таблицу идентификаторов – это можно сделать только для хэш-таблицы; во-вторых, каждому идентификатору будет соответствовать строго одна ячейка в таблице идентификаторов. Пустые ячейки в таком случае будут только в хэш-таблице, и объем неиспользуемой памяти не будет зависеть от объема информации, хранимой для каждого идентификатора, – для каждого значения хэш-функции будет расходоваться только память, необходимая для хранения одного указателя на основную таблицу идентификаторов.
На основе этой схемы можно реализовать еще один способ организации таблиц идентификаторов с помощью хэш-функции, называемый методом цепочек. В этом случае в таблицу идентификаторов для каждого элемента добавляется еще одно поле, в котором может содержаться ссылка на любой элемент таблицы. Первоначально это поле всегда пустое (никуда не указывает). Также необходимо иметь одну специальную переменную, которая всегда указывает на первую свободную ячейку основной таблицы идентификаторов (первоначально она указывает на начало таблицы).
Метод цепочек работает по следующему алгоритму:
1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов пуста, переменная FreePtr (указатель первой свободной ячейки) указывает на начало таблицы идентификаторов.
2. Вычислить значение хэш-функции n для нового элемента A. Если ячейка хэш-таблицы по адресу n пустая, то поместить в нее значение переменной FreePtr и перейти к шагу 5; иначе перейти к шагу 3.
3. Выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов m и перейти к шагу 4.
4. Для ячейки таблицы идентификаторов по адресу m проверить значение поля ссылки. Если оно пустое, то записать в него адрес из переменной FreePtr и перейти к шагу 5; иначе выбрать из поля ссылки новый адрес m и повторить шаг 4.
5. Добавить в таблицу идентификаторов новую ячейку, записать в нее информацию для элемента A (поле ссылки должно быть пустым), в переменную FreePtr поместить адрес за концом добавленной ячейки. Если больше нет идентификаторов, которые надо поместить в таблицу, то выполнение алгоритма закончено, иначе перейти к шагу 2.
Поиск элемента в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму:
1. Вычислить значение хэш-функции n для искомого элемента A. Если ячейка хэш-таблицы по адресу n пустая, то элемент не найден и алгоритм завершен, иначе выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов m.
2. Сравнить имя элемента в ячейке таблицы идентификаторов по адресу m с именем искомого элемента A. Если они совпадают, то искомый элемент найден и алгоритм завершен, иначе перейти к шагу 3.
3. Проверить значение поля ссылки в ячейке таблицы идентификаторов по адресу m. Если оно пустое, то искомый элемент не найден и алгоритм завершен; иначе выбрать из поля ссылки адрес m и перейти к шагу 2.
При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм помещает элементы в ячейки таблицы, связывая их друг с другом последовательно через поле ссылки. При этом элементы не могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хэш-функции. Таким образом, дополнительные коллизии не возникают. В итоге в таблице возникают своеобразные цепочки связанных элементов, откуда и происходит название данного метода – «метод цепочек».
На рис. 1.2 проиллюстрировано заполнение хэш-таблицы и таблицы идентификаторов для ряда идентификаторов: A1, A2, A3, A4, A5 при условии, что h(A1) = h(A2) = h(A5) = n1; h(A3) = n2; h(A4) = n4. После размещения в таблице для поиска идентификатора A1 потребуется одно сравнение, для A2 – два сравнения, для A3 – одно сравнение, для A4 – одно сравнение и для A5 – три сравнения (попробуйте сравнить эти данные с результатами, полученными с использованием простого рехэширования для тех же идентификаторов).
Метод цепочек является очень эффективным средством организации таблиц идентификаторов. Среднее время на размещение одного элемента и на поиск элемента в таблице для него зависит только от среднего числа коллизий, возникающих при вычислении хэш-функции. Накладные расходы памяти, связанные с необходимостью иметь одно дополнительное поле указателя в таблице идентификаторов на каждый ее элемент, можно признать вполне оправданными, так как возникает экономия используемой памяти за счет промежуточной хэш-таблицы. Этот метод позволяет более экономно использовать память, но требует организации работы с динамическими массивами данных.
 Рис. 1.2. Заполнение таблицы идентификаторов при использовании метода цепочек.
Рис. 1.2. Заполнение таблицы идентификаторов при использовании метода цепочек.
В ячейках хэш-таблицы может храниться либо пустое значение, либо значение указателя на некоторую область памяти из основной таблицы идентификаторов. Тогда хэш-функция вычисляет адрес, по которому происходит обращение сначала к хэш-таблице, а потом уже через нее по найденному адресу – к самой таблице идентификаторов. Если соответствующая ячейка таблицы идентификаторов пуста, то ячейка хэш-таблицы будет содержать пустое значение. Тогда вовсе не обязательно иметь в самой таблице идентификаторов ячейку для каждого возможного значения хэш-функции – таблицу можно сделать динамической, так чтобы ее объем рос по мере заполнения (первоначально таблица идентификаторов не содержит ни одной ячейки, а все ячейки хэш-таблицы имеют пустое значение).
Такой подход позволяет добиться двух положительных результатов: во-первых, нет необходимости заполнять пустыми значениями таблицу идентификаторов – это можно сделать только для хэш-таблицы; во-вторых, каждому идентификатору будет соответствовать строго одна ячейка в таблице идентификаторов. Пустые ячейки в таком случае будут только в хэш-таблице, и объем неиспользуемой памяти не будет зависеть от объема информации, хранимой для каждого идентификатора, – для каждого значения хэш-функции будет расходоваться только память, необходимая для хранения одного указателя на основную таблицу идентификаторов.
На основе этой схемы можно реализовать еще один способ организации таблиц идентификаторов с помощью хэш-функции, называемый методом цепочек. В этом случае в таблицу идентификаторов для каждого элемента добавляется еще одно поле, в котором может содержаться ссылка на любой элемент таблицы. Первоначально это поле всегда пустое (никуда не указывает). Также необходимо иметь одну специальную переменную, которая всегда указывает на первую свободную ячейку основной таблицы идентификаторов (первоначально она указывает на начало таблицы).
Метод цепочек работает по следующему алгоритму:
1. Во все ячейки хэш-таблицы поместить пустое значение, таблица идентификаторов пуста, переменная FreePtr (указатель первой свободной ячейки) указывает на начало таблицы идентификаторов.
2. Вычислить значение хэш-функции n для нового элемента A. Если ячейка хэш-таблицы по адресу n пустая, то поместить в нее значение переменной FreePtr и перейти к шагу 5; иначе перейти к шагу 3.
3. Выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов m и перейти к шагу 4.
4. Для ячейки таблицы идентификаторов по адресу m проверить значение поля ссылки. Если оно пустое, то записать в него адрес из переменной FreePtr и перейти к шагу 5; иначе выбрать из поля ссылки новый адрес m и повторить шаг 4.
5. Добавить в таблицу идентификаторов новую ячейку, записать в нее информацию для элемента A (поле ссылки должно быть пустым), в переменную FreePtr поместить адрес за концом добавленной ячейки. Если больше нет идентификаторов, которые надо поместить в таблицу, то выполнение алгоритма закончено, иначе перейти к шагу 2.
Поиск элемента в таблице идентификаторов, организованной таким образом, будет выполняться по следующему алгоритму:
1. Вычислить значение хэш-функции n для искомого элемента A. Если ячейка хэш-таблицы по адресу n пустая, то элемент не найден и алгоритм завершен, иначе выбрать из хэш-таблицы адрес ячейки таблицы идентификаторов m.
2. Сравнить имя элемента в ячейке таблицы идентификаторов по адресу m с именем искомого элемента A. Если они совпадают, то искомый элемент найден и алгоритм завершен, иначе перейти к шагу 3.
3. Проверить значение поля ссылки в ячейке таблицы идентификаторов по адресу m. Если оно пустое, то искомый элемент не найден и алгоритм завершен; иначе выбрать из поля ссылки адрес m и перейти к шагу 2.
При такой организации таблиц идентификаторов в случае возникновения коллизии алгоритм помещает элементы в ячейки таблицы, связывая их друг с другом последовательно через поле ссылки. При этом элементы не могут попадать в ячейки с адресами, которые потом будут совпадать со значениями хэш-функции. Таким образом, дополнительные коллизии не возникают. В итоге в таблице возникают своеобразные цепочки связанных элементов, откуда и происходит название данного метода – «метод цепочек».
На рис. 1.2 проиллюстрировано заполнение хэш-таблицы и таблицы идентификаторов для ряда идентификаторов: A1, A2, A3, A4, A5 при условии, что h(A1) = h(A2) = h(A5) = n1; h(A3) = n2; h(A4) = n4. После размещения в таблице для поиска идентификатора A1 потребуется одно сравнение, для A2 – два сравнения, для A3 – одно сравнение, для A4 – одно сравнение и для A5 – три сравнения (попробуйте сравнить эти данные с результатами, полученными с использованием простого рехэширования для тех же идентификаторов).
Метод цепочек является очень эффективным средством организации таблиц идентификаторов. Среднее время на размещение одного элемента и на поиск элемента в таблице для него зависит только от среднего числа коллизий, возникающих при вычислении хэш-функции. Накладные расходы памяти, связанные с необходимостью иметь одно дополнительное поле указателя в таблице идентификаторов на каждый ее элемент, можно признать вполне оправданными, так как возникает экономия используемой памяти за счет промежуточной хэш-таблицы. Этот метод позволяет более экономно использовать память, но требует организации работы с динамическими массивами данных.
Комбинированные способы построения таблиц идентификаторов
Кроме рехэширования и метода цепочек можно использовать комбинированные методы для организации таблиц идентификаторов с помощью хэш-адресации. В этом случае для исключения коллизий хэш-адресация сочетается с одним из ранее рассмотренных методов – простым списком, упорядоченным списком или бинарным деревом, который используется как дополнительный метод упорядочивания идентификаторов, для которых возникают коллизии. Причем, поскольку при качественном выборе хэш-функции количество коллизий обычно невелико (единицы или десятки случаев), даже простой список может быть вполне удовлетворительным решением при использовании комбинированного метода.
При таком подходе возможны два варианта: в первом случае, как и для метода цепочек, в таблице идентификаторов организуется специальное дополнительное поле ссылки. Но в отличие от метода цепочек оно имеет несколько иное значение: при отсутствии коллизий для выборки информации из таблицы используется хэш-функция, поле ссылки остается пустым. Если же возникает коллизия, то через поле ссылки организуется поиск идентификаторов, для которых значения хэш-функции совпадают – это поле должно указывать на структуру данных для дополнительного метода: начало списка, первый элемент динамического массива или корневой элемент дерева.
Во втором случае используется хэш-таблица, аналогичная хэш-таблице для метода цепочек. Если по данному адресу хэш-функции идентификатор отсутствует, то ячейка хэш-таблицы пустая. Когда появляется идентификатор с данным значением хэш-функции, то создается соответствующая структура для дополнительного метода, в хэш-таблицу записывается ссылка на эту структуру, а идентификатор помещается в созданную структуру по правилам выбранного дополнительного метода.
В первом варианте при отсутствии коллизий поиск выполняется быстрее, но второй вариант предпочтительнее, так как за счет использования промежуточной хэш-таблицы обеспечивается более эффективное использование памяти.
Как и для метода цепочек, для комбинированных методов время размещения и время поиска элемента в таблице идентификаторов зависит только от среднего числа коллизий, возникающих при вычислении хэш-функции. Накладные расходы памяти при использовании промежуточной хэш-таблицы минимальны.
Очевидно, что если в качестве дополнительного метода использовать простой список, то получится алгоритм, полностью аналогичный методу цепочек. Если же использовать упорядоченный список или бинарное дерево, то метод цепочек и комбинированные методы будут иметь примерно равную эффективность при незначительном числе коллизий (единичные случаи), но с ростом количества коллизий эффективность комбинированных методов по сравнению с методом цепочек будет возрастать.
Недостатком комбинированных методов является более сложная организация алгоритмов поиска и размещения идентификаторов, необходимость работы с динамически распределяемыми областями памяти, а также бóльшие затраты времени на размещение нового элемента в таблице идентификаторов по сравнению с методом цепочек.
То, какой конкретно метод применяется в компиляторе для организации таблиц идентификаторов, зависит от реализации компилятора. Один и тот же компилятор может иметь даже несколько разных таблиц идентификаторов, организованных на основе различных методов. Как правило, применяются комбинированные методы.
Создание эффективной хэш-функции – это отдельная задача разработчиков компиляторов, и полученные результаты, как правило, держатся в секрете. Хорошая хэш-функция распределяет поступающие на ее вход идентификаторы равномерно на все имеющиеся в распоряжении адреса, чтобы свести к минимуму количество коллизий. В настоящее время существует множество хэш-функций, но, как было показано выше, идеального хэширования достичь невозможно.
Хэш-адресация – это метод, который применяется не только для организации таблиц идентификаторов в компиляторах. Данный метод нашел свое применение и в операционных системах, и в системах управления базами данных [5, 6, 11].
При таком подходе возможны два варианта: в первом случае, как и для метода цепочек, в таблице идентификаторов организуется специальное дополнительное поле ссылки. Но в отличие от метода цепочек оно имеет несколько иное значение: при отсутствии коллизий для выборки информации из таблицы используется хэш-функция, поле ссылки остается пустым. Если же возникает коллизия, то через поле ссылки организуется поиск идентификаторов, для которых значения хэш-функции совпадают – это поле должно указывать на структуру данных для дополнительного метода: начало списка, первый элемент динамического массива или корневой элемент дерева.
Во втором случае используется хэш-таблица, аналогичная хэш-таблице для метода цепочек. Если по данному адресу хэш-функции идентификатор отсутствует, то ячейка хэш-таблицы пустая. Когда появляется идентификатор с данным значением хэш-функции, то создается соответствующая структура для дополнительного метода, в хэш-таблицу записывается ссылка на эту структуру, а идентификатор помещается в созданную структуру по правилам выбранного дополнительного метода.
В первом варианте при отсутствии коллизий поиск выполняется быстрее, но второй вариант предпочтительнее, так как за счет использования промежуточной хэш-таблицы обеспечивается более эффективное использование памяти.
Как и для метода цепочек, для комбинированных методов время размещения и время поиска элемента в таблице идентификаторов зависит только от среднего числа коллизий, возникающих при вычислении хэш-функции. Накладные расходы памяти при использовании промежуточной хэш-таблицы минимальны.
Очевидно, что если в качестве дополнительного метода использовать простой список, то получится алгоритм, полностью аналогичный методу цепочек. Если же использовать упорядоченный список или бинарное дерево, то метод цепочек и комбинированные методы будут иметь примерно равную эффективность при незначительном числе коллизий (единичные случаи), но с ростом количества коллизий эффективность комбинированных методов по сравнению с методом цепочек будет возрастать.
Недостатком комбинированных методов является более сложная организация алгоритмов поиска и размещения идентификаторов, необходимость работы с динамически распределяемыми областями памяти, а также бóльшие затраты времени на размещение нового элемента в таблице идентификаторов по сравнению с методом цепочек.
То, какой конкретно метод применяется в компиляторе для организации таблиц идентификаторов, зависит от реализации компилятора. Один и тот же компилятор может иметь даже несколько разных таблиц идентификаторов, организованных на основе различных методов. Как правило, применяются комбинированные методы.
Создание эффективной хэш-функции – это отдельная задача разработчиков компиляторов, и полученные результаты, как правило, держатся в секрете. Хорошая хэш-функция распределяет поступающие на ее вход идентификаторы равномерно на все имеющиеся в распоряжении адреса, чтобы свести к минимуму количество коллизий. В настоящее время существует множество хэш-функций, но, как было показано выше, идеального хэширования достичь невозможно.
Хэш-адресация – это метод, который применяется не только для организации таблиц идентификаторов в компиляторах. Данный метод нашел свое применение и в операционных системах, и в системах управления базами данных [5, 6, 11].
Требования к выполнению работы
Порядок выполнения работы
Во всех вариантах задания требуется разработать программу, которая может обеспечить сравнение двух способов организации таблицы идентификаторов с помощью хэш-адресации. Для сравнения предлагаются способы, основанные на использовании рехэширования или комбинированных методов. Программа должна считывать идентификаторы из входного файла, размещать их в таблицах с помощью заданных методов и выполнять поиск указанных идентификаторов по требованию пользователя. В процессе размещения и поиска идентификаторов в таблицах программа должна подсчитывать среднее число выполненных операций сравнения для сопоставления эффективности используемых методов.
Для организации таблиц предлагается использовать простейшую хэш-функцию, которую разработчик программы должен выбрать самостоятельно. Хэш-функция должна обеспечивать работу не менее чем с 200 идентификаторами, допустимая длина идентификатора должна быть не менее 32 символов. Запрещается использовать в работе хэш-функции, взятые из примера выполнения работы.
Лабораторная работа должна выполняться в следующем порядке:
1. Получить вариант задания у преподавателя.
2. Выбрать и описать хэш-функцию.
3. Описать структуры данных, используемые для заданных методов организации таблиц идентификаторов.
4. Подготовить и защитить отчет.
5. Написать и отладить программу на ЭВМ.
6. Сдать работающую программу преподавателю.
Для организации таблиц предлагается использовать простейшую хэш-функцию, которую разработчик программы должен выбрать самостоятельно. Хэш-функция должна обеспечивать работу не менее чем с 200 идентификаторами, допустимая длина идентификатора должна быть не менее 32 символов. Запрещается использовать в работе хэш-функции, взятые из примера выполнения работы.
Лабораторная работа должна выполняться в следующем порядке:
1. Получить вариант задания у преподавателя.
2. Выбрать и описать хэш-функцию.
3. Описать структуры данных, используемые для заданных методов организации таблиц идентификаторов.
4. Подготовить и защитить отчет.
5. Написать и отладить программу на ЭВМ.
6. Сдать работающую программу преподавателю.
Требования к оформлению отчета
Отчет по лабораторной работе должен содержать следующие разделы:
• задание по лабораторной работе;
• описание выбранной хэш-функции;
• схемы организации таблиц идентификаторов (в соответствии с вариантом задания);
• описание алгоритмов поиска в таблицах идентификаторов (в соответствии с вариантом задания);
• текст программы (оформляется после выполнения программы на ЭВМ);
• результаты обработки заданного набора идентификаторов (входного файла) с помощью методов организации таблиц идентификаторов, указанных в варианте задания;
• анализ эффективности используемых методов организации таблиц идентификаторов и выводы по проделанной работе.
• задание по лабораторной работе;
• описание выбранной хэш-функции;
• схемы организации таблиц идентификаторов (в соответствии с вариантом задания);
• описание алгоритмов поиска в таблицах идентификаторов (в соответствии с вариантом задания);
• текст программы (оформляется после выполнения программы на ЭВМ);
• результаты обработки заданного набора идентификаторов (входного файла) с помощью методов организации таблиц идентификаторов, указанных в варианте задания;
• анализ эффективности используемых методов организации таблиц идентификаторов и выводы по проделанной работе.
Основные контрольные вопросы
• Что такое таблица символов и для чего она предназначена? Какая информация может храниться в таблице символов?
• Какие цели преследуются при организации таблицы символов?
• Какими характеристиками могут обладать лексические элементы исходной программы? Какие характеристики являются обязательными?
• Какие существуют способы организации таблиц символов?
• В чем заключается алгоритм логарифмического поиска? Какие преимущества он дает по сравнению с простым перебором и какие он имеет недостатки?
• Расскажите о древовидной организации таблиц идентификаторов. В чем ее преимущества и недостатки?
• Что такое хэш-функции и для чего они используются? В чем суть хэш-адресации?
• Что такое коллизия? Почему она происходит? Можно ли полностью избежать коллизий?
• Что такое рехэширование? Какие методы рехэширования существуют?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью хэш-адресации и рехэширования.
• В чем заключается метод цепочек?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью хэш-адресации и метода цепочек.
• Как могут быть скомбинированы различные методы организации хеш-таблиц?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью комбинированных методов.
• Какие цели преследуются при организации таблицы символов?
• Какими характеристиками могут обладать лексические элементы исходной программы? Какие характеристики являются обязательными?
• Какие существуют способы организации таблиц символов?
• В чем заключается алгоритм логарифмического поиска? Какие преимущества он дает по сравнению с простым перебором и какие он имеет недостатки?
• Расскажите о древовидной организации таблиц идентификаторов. В чем ее преимущества и недостатки?
• Что такое хэш-функции и для чего они используются? В чем суть хэш-адресации?
• Что такое коллизия? Почему она происходит? Можно ли полностью избежать коллизий?
• Что такое рехэширование? Какие методы рехэширования существуют?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью хэш-адресации и рехэширования.
• В чем заключается метод цепочек?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью хэш-адресации и метода цепочек.
• Как могут быть скомбинированы различные методы организации хеш-таблиц?
• Расскажите о преимуществах и недостатках организации таблиц идентификаторов с помощью комбинированных методов.
Варианты заданий
В табл. 1.1 перечислены методы организации таблиц идентификаторов, используемые в заданиях.

 В табл. 1.2 даны варианты заданий на основе методов организации таблиц идентификаторов, перечисленных в табл. 1.1.
В табл. 1.2 даны варианты заданий на основе методов организации таблиц идентификаторов, перечисленных в табл. 1.1.
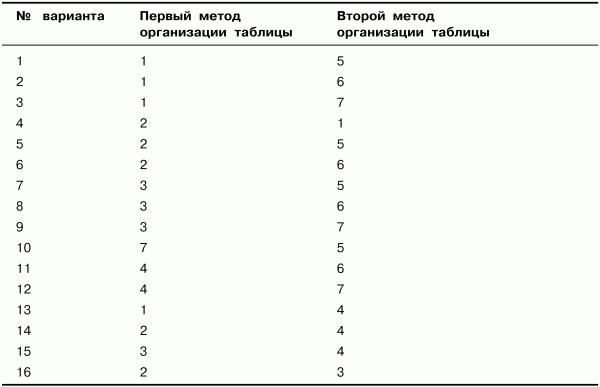
Таблица 1.1. Методы организации таблиц идентификаторов
Таблица 1.2. Варианты заданий
Пример выполнения работы
Задание для примера
В качестве примера выполнения лабораторной работы возьмем сопоставление двух методов: хэш-адресации с рехэшированием на основе псевдослучайных чисел и комбинации хэш-адресации с бинарным деревом. Если обратиться к приведенной выше табл. 1.1, то такой вариант задания будет соответствовать комбинации методов 2 и 7 (в табл. 1.2 среди вариантов заданий такая комбинация отсутствует).
Выбор и описание хэш-функции
Для хэш-адресации с рехэшированием в качестве хэш-функции возьмем функцию, которая будет получать на входе строку, а в результате выдавать сумму кодов первого, среднего и последнего элементов строки. Причем если строка содержит менее трех символов, то один и тот же символ будет взят и в качестве первого, и в качестве среднего, и в качестве последнего.
Будем считать, что прописные и строчные буквы в идентификаторах различны.[2] В качестве кодов символов возьмем коды таблицы ASCII, которая используется в вычислительных системах на базе ОС типа Microsoft Windows. Тогда, если положить, что строка из области определения хэш-функции содержит только цифры и буквы английского алфавита, то минимальным значением хэш-функции будет сумма трех кодов цифры «0», а максимальным значением – сумма трех кодов литеры «z».
Таким образом, область значений выбранной хэш-функции в терминах языка Object Pascal может быть описана как:
(Ord(0 )+Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z')+Ord('z'))
Диапазон области значений составляет 223 элемента, что удовлетворяет требованиям задания (не менее 200 элементов). Длина входных идентификаторов в данном случае ничем не ограничена. Для удобства пользования опишем две константы, задающие границы области значений хэш-функции:
Будем считать, что прописные и строчные буквы в идентификаторах различны.[2] В качестве кодов символов возьмем коды таблицы ASCII, которая используется в вычислительных системах на базе ОС типа Microsoft Windows. Тогда, если положить, что строка из области определения хэш-функции содержит только цифры и буквы английского алфавита, то минимальным значением хэш-функции будет сумма трех кодов цифры «0», а максимальным значением – сумма трех кодов литеры «z».
Таким образом, область значений выбранной хэш-функции в терминах языка Object Pascal может быть описана как:
(Ord(0 )+Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z')+Ord('z'))
Диапазон области значений составляет 223 элемента, что удовлетворяет требованиям задания (не менее 200 элементов). Длина входных идентификаторов в данном случае ничем не ограничена. Для удобства пользования опишем две константы, задающие границы области значений хэш-функции: