Страница:
Кроме того, информация о некоторых типах лексем, найденных в исходной программе, должна помещаться в таблицу идентификаторов (или в одну из таблиц идентификаторов, если компилятор предусматривает различные таблицы идентификаторов для различных типов лексем).
В качестве примера можно рассмотреть некоторый фрагмент исходного кода на языке Object Pascal и соответствующую ему таблицу лексем, представленную в табл. 2.1:
…
begin
for i:=1 to N do
fg:= fg * 0.5
…
 Поле «значение» в табл. 2.1 подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем в результате работы лексического анализатора. Конечно, значения, которые записаны в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Важно отметить также, что устанавливается связь таблицы лексем с таблицей идентификаторов (в примере это отражено некоторым индексом, следующим после идентификатора за знаком «:», а в реальном компиляторе определяется его реализацией).
Поле «значение» в табл. 2.1 подразумевает некое кодовое значение, которое будет помещено в итоговую таблицу лексем в результате работы лексического анализатора. Конечно, значения, которые записаны в примере, являются условными. Конкретные коды выбираются разработчиками при реализации компилятора. Важно отметить также, что устанавливается связь таблицы лексем с таблицей идентификаторов (в примере это отражено некоторым индексом, следующим после идентификатора за знаком «:», а в реальном компиляторе определяется его реализацией).
Построение лексических анализаторов (сканеров)
Требования к выполнению работы
Порядок выполнения работы
Требования к оформлению отчета
Основные контрольные вопросы
Варианты заданий
Пример выполнения работы
Задание для примера
Грамматика входного языка
Описание конечного автомата для распознавания лексем входного языка
Внимание!Таблица лексем фактически содержит весь текст исходной программы, обработанный лексическим анализатором. В нее входят все возможные типы лексем, кроме того, любая лексема может встречаться в ней любое количество раз. Таблица идентификаторов содержит только определенные типы лексем – идентификаторы и константы. В нее не попадают такие лексемы, как ключевые (служебные) слова входного языка, знаки операций и разделители. Кроме того, каждая лексема (идентификатор или константа) может встречаться в таблице идентификаторов только один раз. Также можно отметить, что лексемы в таблице лексем обязательно располагаются в том же порядке, что и в исходной программе (порядок лексем в ней не меняется), а в таблице идентификаторов лексемы располагаются в любом порядке так, чтобы обеспечить удобство поиска.
Не следует путать таблицу лексем и таблицу идентификаторов – это две принципиально разные таблицы, обрабатываемые лексическим анализатором.
В качестве примера можно рассмотреть некоторый фрагмент исходного кода на языке Object Pascal и соответствующую ему таблицу лексем, представленную в табл. 2.1:
…
begin
for i:=1 to N do
fg:= fg * 0.5
…
Таблица 2.1. Лексемы фрагмента программы на языке Pascal
Построение лексических анализаторов (сканеров)
Лексический анализатор имеет дело с такими объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык описания констант и идентификаторов в большинстве случаев является регулярным, то есть может быть описан с помощью регулярных грамматик [1–4, 7]. Распознавателями для регулярных языков являются конечные автоматы (КА). Существуют правила, с помощью которых для любой регулярной грамматики может быть построен КА, распознающий цепочки языка, заданного этой грамматикой.
Более подробно о построении КА на основе грамматик для регулярных языков можно узнать в [3, 7, 26].
Любой КА может быть задан с помощью пяти параметров: M(Q,Σ,δ,q0,F),
где:
Q – конечное множество состояний автомата;
Σ – конечное множество допустимых входных символов (входной алфавит КА);
δ – заданное отображение множества Q·Σ во множество подмножеств P(Q)δ: Q·Σ → P(Q) (иногда δ называют функцией переходов автомата);
 – начальное состояние автомата;
– начальное состояние автомата;
 – множество заключительных состояний автомата.
– множество заключительных состояний автомата.
Другим способом описания КА является граф переходов – графическое представление множества состояний и функции переходов КА. Граф переходов КА – это нагруженный однонаправленный граф, в котором вершины представляют состояния КА, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода КА. Если функция перехода КА предусматривает переход из состояния q в q' по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q'.
Недетерминированный КА неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, то есть такие, из которых выходит две или более дуги, помеченные одним и тем же символом. Очевидно, что программирование работы такого КА – нетривиальная задача. Для простого программирования функционирования КА M(Q,Σ,δ,q0,F) он должен быть детерминированным – в каждом из возможных состояний этого КА для любого входного символа функция перехода должна содержать не более одного состояния:
 Доказано, что любой недетерминированный КА может быть преобразован в детерминированный КА так, чтобы их языки совпадали [3, 7, 26] (говорят, что эти КА эквивалентны).
Доказано, что любой недетерминированный КА может быть преобразован в детерминированный КА так, чтобы их языки совпадали [3, 7, 26] (говорят, что эти КА эквивалентны).
Кроме преобразования в детерминированный КА любой КА может быть минимизирован – для него может быть построен эквивалентный ему детерминированный КА с минимально возможным количеством состояний. Алгоритмы преобразования КА в детерминированный КА и минимизации КА подробно описаны в [3, 7, 26].
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.
Однако в общем случае задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Он должен правильно определить конец лексемы (об этом было сказано выше) и выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор выполняемых действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
Во входном тексте лексемы не ограничены специальными символами. Определение границ лексем – это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. Если границы лексем всегда определяются (а выше было принято именно такое соглашение), то их можно определить по заданным терминальным символам и по символам начала следующей лексемы. Терминальные символы – это пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Таким образом, алгоритм работы простейшего сканера можно описать так:
• просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
• для выбранной части входного потока выполняется функция распознавания лексемы;
• при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу;
• при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера: либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Более подробно о построении КА на основе грамматик для регулярных языков можно узнать в [3, 7, 26].
Любой КА может быть задан с помощью пяти параметров: M(Q,Σ,δ,q0,F),
где:
Q – конечное множество состояний автомата;
Σ – конечное множество допустимых входных символов (входной алфавит КА);
δ – заданное отображение множества Q·Σ во множество подмножеств P(Q)δ: Q·Σ → P(Q) (иногда δ называют функцией переходов автомата);
Другим способом описания КА является граф переходов – графическое представление множества состояний и функции переходов КА. Граф переходов КА – это нагруженный однонаправленный граф, в котором вершины представляют состояния КА, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода КА. Если функция перехода КА предусматривает переход из состояния q в q' по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q'.
Недетерминированный КА неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, то есть такие, из которых выходит две или более дуги, помеченные одним и тем же символом. Очевидно, что программирование работы такого КА – нетривиальная задача. Для простого программирования функционирования КА M(Q,Σ,δ,q0,F) он должен быть детерминированным – в каждом из возможных состояний этого КА для любого входного символа функция перехода должна содержать не более одного состояния:
Кроме преобразования в детерминированный КА любой КА может быть минимизирован – для него может быть построен эквивалентный ему детерминированный КА с минимально возможным количеством состояний. Алгоритмы преобразования КА в детерминированный КА и минимизации КА подробно описаны в [3, 7, 26].
Можно написать функцию, отражающую функционирование любого детерминированного КА. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние КА, а переходы из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершении проанализировать состояние КА. Если это одно из конечных состояний, то функция выполнена успешно и входная цепочка принимается, если нет, то входная цепочка не принадлежит заданному языку.
Однако в общем случае задача лексического анализатора шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Он должен правильно определить конец лексемы (об этом было сказано выше) и выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор выполняемых действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же при обнаружении конца распознаваемой лексемы.
Во входном тексте лексемы не ограничены специальными символами. Определение границ лексем – это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. Если границы лексем всегда определяются (а выше было принято именно такое соглашение), то их можно определить по заданным терминальным символам и по символам начала следующей лексемы. Терминальные символы – это пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами и необходимо не пропустить их при распознавании текста.
Таким образом, алгоритм работы простейшего сканера можно описать так:
• просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему;
• для выбранной части входного потока выполняется функция распознавания лексемы;
• при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу;
• при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера: либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма).
Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Требования к выполнению работы
Порядок выполнения работы
Для выполнения лабораторной работы требуется написать программу, которая выполняет лексический анализ входного текста в соответствии с заданием и порождает таблицу лексем с указанием их типов и значений. Текст на входном языке задается в виде символьного (текстового) файла. Программа должна выдавать сообщения о наличии во входном тексте ошибок, которые могут быть обнаружены на этапе лексического анализа.
Длину идентификаторов и строковых констант можно считать ограниченной 32 символами. Программа должна допускать наличие комментариев неограниченной длины во входном файле. Форму организации комментариев предлагается выбрать самостоятельно.
Лабораторная работа должна выполняться в следующем порядке:
1. Получить вариант задания у преподавателя.
2. Построить описание КА, лежащего в основе лексического анализатора (в виде набора множеств и функции переходов или в виде графа переходов).
3. Подготовить и защитить отчет.
4. Написать и отладить программу на ЭВМ.
5. Сдать работающую программу преподавателю.
Длину идентификаторов и строковых констант можно считать ограниченной 32 символами. Программа должна допускать наличие комментариев неограниченной длины во входном файле. Форму организации комментариев предлагается выбрать самостоятельно.
Лабораторная работа должна выполняться в следующем порядке:
1. Получить вариант задания у преподавателя.
2. Построить описание КА, лежащего в основе лексического анализатора (в виде набора множеств и функции переходов или в виде графа переходов).
3. Подготовить и защитить отчет.
4. Написать и отладить программу на ЭВМ.
5. Сдать работающую программу преподавателю.
Требования к оформлению отчета
Отчет должен содержать следующие разделы:
• Задание по лабораторной работе.
• Описание КС-грамматики входного языка в форме Бэкуса—Наура.
• Описание алгоритма работы сканера или граф переходов КА для распознавания цепочек (в соответствии с вариантом задания).
• Текст программы (оформляется после выполнения программы на ЭВМ).
• Выводы по проделанной работе.
• Задание по лабораторной работе.
• Описание КС-грамматики входного языка в форме Бэкуса—Наура.
• Описание алгоритма работы сканера или граф переходов КА для распознавания цепочек (в соответствии с вариантом задания).
• Текст программы (оформляется после выполнения программы на ЭВМ).
• Выводы по проделанной работе.
Основные контрольные вопросы
• Что такое трансляция, компиляция, транслятор, компилятор?
• Из каких процессов состоит компиляция? Расскажите об общей структуре компилятора.
• Какую роль выполняет лексический анализ в процессе компиляции?
• Что такое лексема? Расскажите, какие типы лексем существуют в языках программирования.
• Как могут быть связаны между собой лексический и синтаксический анализ?
• Какие проблемы могут возникать при определении границ лексем в процессе лексического анализа? Как решаются эти проблемы?
• Что такое таблица лексем? Какая информация хранится в таблице лексем?
• В чем разница между таблицей лексем и таблицей идентификаторов?
• Что такое грамматика? Дайте определения грамматики. Как выглядит описание грамматики в форме Бэкуса—Наура.
• Какие классы грамматик существуют? Что такое регулярные грамматики?
• Что такое конечный автомат? Дайте определение детерминированного и недетерминированного конечных автоматов.
• Опишите алгоритм преобразования недетерминированного конечного автомата в детерминированный.
• Какие проблемы необходимо решить при построении сканера на основе конечного автомата?
• Объясните общий алгоритм функционирования лексического анализатора.
• Из каких процессов состоит компиляция? Расскажите об общей структуре компилятора.
• Какую роль выполняет лексический анализ в процессе компиляции?
• Что такое лексема? Расскажите, какие типы лексем существуют в языках программирования.
• Как могут быть связаны между собой лексический и синтаксический анализ?
• Какие проблемы могут возникать при определении границ лексем в процессе лексического анализа? Как решаются эти проблемы?
• Что такое таблица лексем? Какая информация хранится в таблице лексем?
• В чем разница между таблицей лексем и таблицей идентификаторов?
• Что такое грамматика? Дайте определения грамматики. Как выглядит описание грамматики в форме Бэкуса—Наура.
• Какие классы грамматик существуют? Что такое регулярные грамматики?
• Что такое конечный автомат? Дайте определение детерминированного и недетерминированного конечных автоматов.
• Опишите алгоритм преобразования недетерминированного конечного автомата в детерминированный.
• Какие проблемы необходимо решить при построении сканера на основе конечного автомата?
• Объясните общий алгоритм функционирования лексического анализатора.
Варианты заданий
1. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, десятичных чисел с плавающей точкой (в обычной и логарифмической форме), знака присваивания (:=), знаков операций +, —, *, / и круглых скобок.
2. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, констант true и false, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
3. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, десятичные числа с плавающей точкой (в обычной и логарифмической форме), знак присваивания (:=).
4. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, десятичные числа с плавающей точкой (в обычной и логарифмической форме), знак присваивания (:=).
5. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, римских чисел, знака присваивания (:=), знаков операций +, —, *, / и круглых скобок.
6. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, констант 0 и 1, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
7. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, римские числа, знак присваивания (:=).
8. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, римские числа, знак присваивания (:=).
9. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, шестнадцатеричных чисел, знака присваивания (:=), знаков операций +, —, *, / и круглых скобок.
10. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, шестнадцатеричных чисел, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
11. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, шестнадцатеричные числа, знак присваивания (:=).
12. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, шестнадцатеричные числа, знак присваивания (:=).
13. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, символьных констант (один символ в одинарных кавычках), знака присваивания (:=), знаков операций +, -, *, / и круглых скобок.
14. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, символьных констант Т и 'F', знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
15. Входной язык содержит операторы условия типа if… then… else и if… then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, строковые константы (последовательность символов в двойных кавычках), знак присваивания (:=).
16. Входной язык содержит операторы цикла типа for (…;…;…) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, строковые константы (последовательность символов в двойных кавычках), знак присваивания (:=).
2. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, констант true и false, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
3. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, десятичные числа с плавающей точкой (в обычной и логарифмической форме), знак присваивания (:=).
4. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, десятичные числа с плавающей точкой (в обычной и логарифмической форме), знак присваивания (:=).
5. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, римских чисел, знака присваивания (:=), знаков операций +, —, *, / и круглых скобок.
6. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, констант 0 и 1, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
7. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, римские числа, знак присваивания (:=).
8. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, римские числа, знак присваивания (:=).
9. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, шестнадцатеричных чисел, знака присваивания (:=), знаков операций +, —, *, / и круглых скобок.
10. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, шестнадцатеричных чисел, знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
11. Входной язык содержит операторы условия типа if … then … else и if … then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, шестнадцатеричные числа, знак присваивания (:=).
12. Входной язык содержит операторы цикла типа for (…; …; …) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, шестнадцатеричные числа, знак присваивания (:=).
13. Входной язык содержит арифметические выражения, разделенные символом; (точка с запятой). Арифметические выражения состоят из идентификаторов, символьных констант (один символ в одинарных кавычках), знака присваивания (:=), знаков операций +, -, *, / и круглых скобок.
14. Входной язык содержит логические выражения, разделенные символом; (точка с запятой). Логические выражения состоят из идентификаторов, символьных констант Т и 'F', знака присваивания (:=), знаков операций or, xor, and, not и круглых скобок.
15. Входной язык содержит операторы условия типа if… then… else и if… then, разделенные символом; (точка с запятой). Операторы условия содержат идентификаторы, знаки сравнения <, >, =, строковые константы (последовательность символов в двойных кавычках), знак присваивания (:=).
16. Входной язык содержит операторы цикла типа for (…;…;…) do, разделенные символом; (точка с запятой). Операторы цикла содержат идентификаторы, знаки сравнения <, >, =, строковые константы (последовательность символов в двойных кавычках), знак присваивания (:=).
Примечание.
• Римскими числами считать последовательности заглавных латинских букв X, V и I;
• шестнадцатеричными числами считать последовательность цифр и символов «а», «Ь», «с», «d, „е“ и „f“, начинающуюся с цифры (например: 89, 45ас9, 0abc4);
• задание по лабораторной работе № 2 взаимосвязано с заданием по лабораторной работе № 3, для уточнения состава входного языка можно посмотреть грамматику, заданную в работе № 3 по соответствующему варианту.
Пример выполнения работы
Задание для примера
В качестве задания для примера возьмем входной язык, который содержит набор условных операторов условия типа if… then… else и if… then, разделенных символом; (точка с запятой). Эти операторы в качестве условия содержат логические выражения, построенные с помощью операций or, xor и and, операндами которых являются идентификаторы и целые десятичные константы без знака. В исполнительной части эти операторы содержат или оператор присваивания переменной логического выражения (:=), или другой условный оператор.
Комментарий будет организован в виде последовательности символов, начинающейся с открывающей фигурной скобки ({) и заканчивающейся закрывающей фигурной скобкой (}). Комментарий может содержать любые алфавитно-цифровые символы, в том числе и символы национальных алфавитов.
Комментарий будет организован в виде последовательности символов, начинающейся с открывающей фигурной скобки ({) и заканчивающейся закрывающей фигурной скобкой (}). Комментарий может содержать любые алфавитно-цифровые символы, в том числе и символы национальных алфавитов.
Грамматика входного языка
Описанный выше входной язык может быть построен с помощью КС-грамматики G({if,then,else,a,=,or,xor,and,(,),},{S,F,E,D,C},P,S) с правилами Р:
S → F;
F → if E then T else F | if E then F | a:= E
T → if E then T else T | a:= E
E → E or D | E xor D | D
D → D and С | С
С → a | (E)
Описание грамматики построено в форме Бэкуса—Наура. Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
Выбранный в качестве примера язык и задающая его грамматика не совпадают ни с одним из предложенных выше вариантов. С другой стороны, на этом примере можно проиллюстрировать многие особенности построения лексического, а впоследствии – и синтаксического распознавателя, присущие различным вариантам. Он содержит как условные операторы, связанные с передачей управления в то или иное место исходной программы, так и линейные операции в форме вычисления логических выражений. Поэтому данный пример выбран в качестве иллюстрации для лабораторной работы № 2, а позже будет использоваться также в лабораторных работах № 3 и 4.
S → F;
F → if E then T else F | if E then F | a:= E
T → if E then T else T | a:= E
E → E or D | E xor D | D
D → D and С | С
С → a | (E)
Описание грамматики построено в форме Бэкуса—Наура. Жирным шрифтом в грамматике и в правилах выделены терминальные символы.
Выбранный в качестве примера язык и задающая его грамматика не совпадают ни с одним из предложенных выше вариантов. С другой стороны, на этом примере можно проиллюстрировать многие особенности построения лексического, а впоследствии – и синтаксического распознавателя, присущие различным вариантам. Он содержит как условные операторы, связанные с передачей управления в то или иное место исходной программы, так и линейные операции в форме вычисления логических выражений. Поэтому данный пример выбран в качестве иллюстрации для лабораторной работы № 2, а позже будет использоваться также в лабораторных работах № 3 и 4.
Описание конечного автомата для распознавания лексем входного языка
Задача лексического анализатора для описанного выше языка заключается в том, чтобы распознавать и выделять в исходном тексте программы все лексемы этого языка. Лексемами данного языка являются:
• шесть ключевых слов языка (if, then, else, or, xor и and);
• разделители: открывающая и закрывающая круглые скобки, точка с запятой;
• знак операции присваивания;
• идентификаторы;
• целые десятичные константы без знака.
Кроме перечисленных лексем распознаватель должен уметь определять и исключать из входного текста комментарии, принцип построения которых описан выше. Для выделения комментариев ключевыми символами должны быть открывающая и закрывающая фигурные скобки.
Для перечисленных типов лексем и комментария можно построить регулярную грамматику, а затем на ее основе создать КА. Однако построенная таким образом грамматика, с одной стороны, будет элементарно простой, с другой стороны – громоздкой и малоинформативной. Поэтому можно пойти путем построения КА непосредственно по описанию лексем. Для этого не хватает только описания идентификаторов и целых десятичных констант без знака:
• идентификатор – это произвольная последовательность малых и прописных букв латинского алфавита (от А до Z и от а до z), цифр (от 0 до 9) и знака подчеркивания (_), начинающаяся с буквы или со знака подчеркивания;
• целое десятичное число без знака – это произвольная последовательность цифр (от 0 до 9), начинающаяся с любой цифры.
Границами лексем для данного распознавателя будут служить пробел, знак табуляции, знаки перевода строки и возврата каретки, а также круглые скобки, открывающая фигурная скобка, точка с запятой и знак двоеточия. При этом следует помнить, что круглые скобки и точка с запятой сами по себе являются лексемами, открывающая фигурная скобка начинает комментарий, а знак двоеточия, являясь границей лексемы, в то же время является и началом другой лексемы – операции присваивания.
В данном языке лексический анализатор всегда может однозначно определить границы лексемы, поэтому нет необходимости в его взаимодействии с синтаксическим анализатором и другими элементами компилятора.
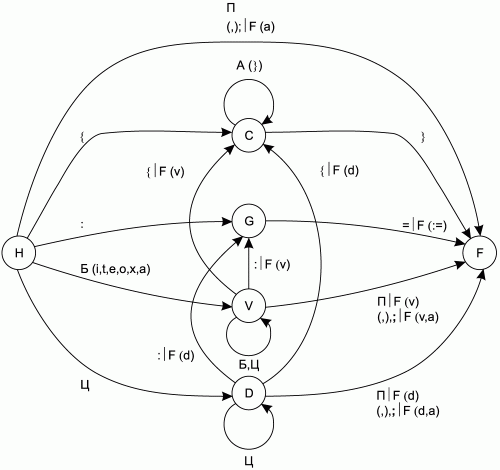 Рис. 2.1. Фрагмент графа переходов КА для распознавания всех лексем, кроме ключевых слов.
Рис. 2.1. Фрагмент графа переходов КА для распознавания всех лексем, кроме ключевых слов.
Полный граф переходов КА будет очень громоздким и неудобным для просмотра, поэтому проиллюстрируем его несколькими фрагментами. На рис. 2.1 изображен фрагмент графа переходов КА, отвечающий за распознавание разделителей, комментариев, знака присваивания, переменных и констант (всех лексем входного языка, кроме ключевых слов).
На рис. 2.2 изображен фрагмент графа переходов КА, отвечающий за распознавание ключевых слов if и then (этот фрагмент имеет ссылки на состояния, изображенные на рис. 2.1). Аналогичные фрагменты можно построить и для других ключевых слов.
 Рис. 2.2. Фрагмент графа переходов КА для ключевых слов if и then.
Рис. 2.2. Фрагмент графа переходов КА для ключевых слов if и then.
На фрагментах графа переходов КА, изображенных на рис. 2.1 и 2.2, приняты следующие обозначения:
• А– любой алфавитно-цифровой символ;
• А(*) – любой алфавитно-цифровой символ, кроме перечисленных в скобках;
• П– любой незначащий символ (пробел, знак табуляции, перевод строки, возврат каретки);
• Б– любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_);
• Б(*) – любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_), кроме перечисленных в скобках;
• Ц– любая цифра от 0 до 9;
• F – функция обработки таблицы лексем, вызываемая при переходе КА из одного состояния в другое. Обозначения ее аргументов:
– v – переменная, запомненная при работе КА;
– d – константа, запомненная при работе КА;
– a – текущий входной символ КА.
С учетом этих обозначений, полностью КА можно описать следующим образом:
M(Q,Σ,δ,q0,F):
Q = {H, C, G, V, D, I1, I2, T1, T2, T3, T4, E1, E2, E3, E4, O1, O2, X1, X2, X3, A1, A2, A3, F}
Σ = А (все допустимые алфавитно-цифровые символы);
q 0 = H;
F = {F}.
Функция переходов (δ) для этого КА приведена в приложении 2.
Из начального состояния КА литеры «i», «t», «e», «o», «x» и «a» ведут в начало цепочек состояний, каждая из которых соответствует ключевому слову:
• состояния I1, I2 – ключевому слову if;
• состояния T1, T2, T3, T4 – ключевому слову then;
• состояния E1, E2, E3, E4 – ключевому слову else;
• состояния O1, O2 – ключевому слову or;
• состояния X1, X2, X3 – ключевому слову xor;
• состояния A1, A2, A3 – ключевому слову and.
Остальные литеры ведут к состоянию, соответствующему переменной (идентификатору), – V. Если в какой-то из цепочек встречается литера, не соответствующая ключевому слову, или цифра, то КА также переходит в состояние V, а если встречается граница лексемы – запоминает уже прочитанную часть ключевого слова как переменную (чтобы правильно выделять такие идентификаторы, как «i» или «els», которые совпадают с началом ключевых слов).
Цифры ведут в состояние, соответствующее входной константе, – D. Открывающая фигурная скобка ведет в состояние C, которое соответствует обнаружению комментария – из этого состояния КА выходит, только если получит на вход закрывающую фигурную скобку. Еще одно состояние – G – соответствует лексеме «знак присваивания». В него КА переходит, получив на вход двоеточие, и ожидает в этом состоянии символа «равенство».
Состояние H – начальное состояние КА, а состояние F – его конечное состояние. Поскольку КА работает с непрерывным потоком лексем, перейдя в конечное состояние, он тут же должен возвращаться в начальное, чтобы распознавать очередную лексему. Поэтому в моделирующей программе эти два состояния можно объединить.
На графе и при описании функции переходов не обозначено состояние «ошибка», чтобы не загромождать и без того сложный граф и функцию. В это состояние КА переходит всегда, когда получает на вход символ, по которому нет переходов из текущего состояния.
Функция F, которой помечены дуги КА на графе и переходы в функции переходов, соответствует выполнению записи данных в таблицу лексем. Аргументы функции зависят от текущего состояния КА. В реализации программы, моделирующей функционирование КА, этой функции должны соответствовать несколько функций, вызываемые в зависимости от текущего состояния и входного символа.
Надо отметить, что для корректной записи переменных и констант в таблицу лексем КА должен запоминать соответствующие им цепочки символов. Проще всего это делать, запоминая позицию считывающей головки КА всякий раз, когда он находится в состоянии H.
Можно заметить, что функция переходов КА получилась довольно громоздкой, хотя и простой по своей сути (для всех ключевых слов она работает однотипно). В реализации функционирования КА проще было бы не выделять отдельные состояния для ключевых слов, а переходить всегда по обнаружению буквы на входе КА в состояние V. Тогда проверку того, является ли считанная строка ключевым словом или же идентификатором, можно было бы выполнять на момент ее записи в таблицу лексем с помощью стандартных операций сравнения строк. Граф переходов КА в таком варианте был бы намного компактнее – он выглядел бы точно так же, как фрагмент, представленный на рис. 2.1. Его можно назвать «сокращенным» графом переходов КА (или «сокращенным КА»).
Но следует отметить, что, несмотря на большую наглядность и простоту реализации, сокращенный КА будет менее эффективным, поскольку в момент записи лексемы в таблицу он должен будет выполнять ее сравнение со всеми известными ключевыми словами (в данном случае надо определять шесть ключевых слов – следовательно, будет выполняться шесть сравнений строк). То есть такой КА будет повторно просматривать уже прочитанную часть входной цепочки, да еще и несколько раз! И хотя в явном виде в реализации сокращенного КА эта операция не присутствует, она все равно будет выполняться в вызове библиотечной функции сравнения строк.
• шесть ключевых слов языка (if, then, else, or, xor и and);
• разделители: открывающая и закрывающая круглые скобки, точка с запятой;
• знак операции присваивания;
• идентификаторы;
• целые десятичные константы без знака.
Кроме перечисленных лексем распознаватель должен уметь определять и исключать из входного текста комментарии, принцип построения которых описан выше. Для выделения комментариев ключевыми символами должны быть открывающая и закрывающая фигурные скобки.
Для перечисленных типов лексем и комментария можно построить регулярную грамматику, а затем на ее основе создать КА. Однако построенная таким образом грамматика, с одной стороны, будет элементарно простой, с другой стороны – громоздкой и малоинформативной. Поэтому можно пойти путем построения КА непосредственно по описанию лексем. Для этого не хватает только описания идентификаторов и целых десятичных констант без знака:
• идентификатор – это произвольная последовательность малых и прописных букв латинского алфавита (от А до Z и от а до z), цифр (от 0 до 9) и знака подчеркивания (_), начинающаяся с буквы или со знака подчеркивания;
• целое десятичное число без знака – это произвольная последовательность цифр (от 0 до 9), начинающаяся с любой цифры.
Границами лексем для данного распознавателя будут служить пробел, знак табуляции, знаки перевода строки и возврата каретки, а также круглые скобки, открывающая фигурная скобка, точка с запятой и знак двоеточия. При этом следует помнить, что круглые скобки и точка с запятой сами по себе являются лексемами, открывающая фигурная скобка начинает комментарий, а знак двоеточия, являясь границей лексемы, в то же время является и началом другой лексемы – операции присваивания.
В данном языке лексический анализатор всегда может однозначно определить границы лексемы, поэтому нет необходимости в его взаимодействии с синтаксическим анализатором и другими элементами компилятора.
Полный граф переходов КА будет очень громоздким и неудобным для просмотра, поэтому проиллюстрируем его несколькими фрагментами. На рис. 2.1 изображен фрагмент графа переходов КА, отвечающий за распознавание разделителей, комментариев, знака присваивания, переменных и констант (всех лексем входного языка, кроме ключевых слов).
На рис. 2.2 изображен фрагмент графа переходов КА, отвечающий за распознавание ключевых слов if и then (этот фрагмент имеет ссылки на состояния, изображенные на рис. 2.1). Аналогичные фрагменты можно построить и для других ключевых слов.
На фрагментах графа переходов КА, изображенных на рис. 2.1 и 2.2, приняты следующие обозначения:
• А– любой алфавитно-цифровой символ;
• А(*) – любой алфавитно-цифровой символ, кроме перечисленных в скобках;
• П– любой незначащий символ (пробел, знак табуляции, перевод строки, возврат каретки);
• Б– любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_);
• Б(*) – любая буква английского алфавита (прописная или строчная) или символ подчеркивания (_), кроме перечисленных в скобках;
• Ц– любая цифра от 0 до 9;
• F – функция обработки таблицы лексем, вызываемая при переходе КА из одного состояния в другое. Обозначения ее аргументов:
– v – переменная, запомненная при работе КА;
– d – константа, запомненная при работе КА;
– a – текущий входной символ КА.
С учетом этих обозначений, полностью КА можно описать следующим образом:
M(Q,Σ,δ,q0,F):
Q = {H, C, G, V, D, I1, I2, T1, T2, T3, T4, E1, E2, E3, E4, O1, O2, X1, X2, X3, A1, A2, A3, F}
Σ = А (все допустимые алфавитно-цифровые символы);
q 0 = H;
F = {F}.
Функция переходов (δ) для этого КА приведена в приложении 2.
Из начального состояния КА литеры «i», «t», «e», «o», «x» и «a» ведут в начало цепочек состояний, каждая из которых соответствует ключевому слову:
• состояния I1, I2 – ключевому слову if;
• состояния T1, T2, T3, T4 – ключевому слову then;
• состояния E1, E2, E3, E4 – ключевому слову else;
• состояния O1, O2 – ключевому слову or;
• состояния X1, X2, X3 – ключевому слову xor;
• состояния A1, A2, A3 – ключевому слову and.
Остальные литеры ведут к состоянию, соответствующему переменной (идентификатору), – V. Если в какой-то из цепочек встречается литера, не соответствующая ключевому слову, или цифра, то КА также переходит в состояние V, а если встречается граница лексемы – запоминает уже прочитанную часть ключевого слова как переменную (чтобы правильно выделять такие идентификаторы, как «i» или «els», которые совпадают с началом ключевых слов).
Цифры ведут в состояние, соответствующее входной константе, – D. Открывающая фигурная скобка ведет в состояние C, которое соответствует обнаружению комментария – из этого состояния КА выходит, только если получит на вход закрывающую фигурную скобку. Еще одно состояние – G – соответствует лексеме «знак присваивания». В него КА переходит, получив на вход двоеточие, и ожидает в этом состоянии символа «равенство».
Состояние H – начальное состояние КА, а состояние F – его конечное состояние. Поскольку КА работает с непрерывным потоком лексем, перейдя в конечное состояние, он тут же должен возвращаться в начальное, чтобы распознавать очередную лексему. Поэтому в моделирующей программе эти два состояния можно объединить.
На графе и при описании функции переходов не обозначено состояние «ошибка», чтобы не загромождать и без того сложный граф и функцию. В это состояние КА переходит всегда, когда получает на вход символ, по которому нет переходов из текущего состояния.
Функция F, которой помечены дуги КА на графе и переходы в функции переходов, соответствует выполнению записи данных в таблицу лексем. Аргументы функции зависят от текущего состояния КА. В реализации программы, моделирующей функционирование КА, этой функции должны соответствовать несколько функций, вызываемые в зависимости от текущего состояния и входного символа.
Надо отметить, что для корректной записи переменных и констант в таблицу лексем КА должен запоминать соответствующие им цепочки символов. Проще всего это делать, запоминая позицию считывающей головки КА всякий раз, когда он находится в состоянии H.
Можно заметить, что функция переходов КА получилась довольно громоздкой, хотя и простой по своей сути (для всех ключевых слов она работает однотипно). В реализации функционирования КА проще было бы не выделять отдельные состояния для ключевых слов, а переходить всегда по обнаружению буквы на входе КА в состояние V. Тогда проверку того, является ли считанная строка ключевым словом или же идентификатором, можно было бы выполнять на момент ее записи в таблицу лексем с помощью стандартных операций сравнения строк. Граф переходов КА в таком варианте был бы намного компактнее – он выглядел бы точно так же, как фрагмент, представленный на рис. 2.1. Его можно назвать «сокращенным» графом переходов КА (или «сокращенным КА»).
Но следует отметить, что, несмотря на большую наглядность и простоту реализации, сокращенный КА будет менее эффективным, поскольку в момент записи лексемы в таблицу он должен будет выполнять ее сравнение со всеми известными ключевыми словами (в данном случае надо определять шесть ключевых слов – следовательно, будет выполняться шесть сравнений строк). То есть такой КА будет повторно просматривать уже прочитанную часть входной цепочки, да еще и несколько раз! И хотя в явном виде в реализации сокращенного КА эта операция не присутствует, она все равно будет выполняться в вызове библиотечной функции сравнения строк.