Страница:
HASH_MIN = Ord(0 )+Ord(0 )+Ord(0 );
HASH_MAX = Ord('z')+Ord('z')+Ord('z').
Сама хэш-функция без учета рехэширования будет вычислять следующее выражение:
Ord(sName[1]) + Ord(sName[(Length(sName)+1) div 2]) + Ord(sName[Length(sName);
здесь sName – это входная строка (аргумент хэш-функции).
Для рехэширования возьмем простейший генератор последовательности псевдослучайных чисел, построенный на основе формулы F = i-H1 mod Н2, где Н1 и Н2 – простые числа, выбранные таким образом, чтобы H1 было в диапазоне от Н2/2 до Н2. Причем, чтобы этот генератор выдавал максимально длинную последовательность во всем диапазоне от HASH_MIN до HASH_MAX, Н2 должно быть максимально близко к величине HASH_MAX – HASН_МIN + 1. В данном случае диапазон содержит 223 элемента, и поскольку 223 – простое число, то возьмем Н2 = 223 (если бы размер диапазона не был простым числом, то в качестве Н2 нужно было бы взять ближайшее к нему меньшее простое число). В качестве H1 возьмем 127: H1 = 127.
Опишем соответствующие константы:
REHASH1 = 127;
REHASH2 = 223;
Тогда хэш-функция с учетом рехэширования будет иметь следующий вид:
function VarHash(const sName: string; iNum: integer):longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
+ Ord(sName[Length(sName)]) – HASH_MIN
+ iNum*REHASH1 mod REHASH2)
mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end;
Входные параметры этой функции: sName – имя хэшируемого идентификатора, iNum – индекс рехэшированиея (если iNum = 0, то рехэширование отсутствует). Строка проверки величины результата (Result < HASH_MIN) добавлена, чтобы исключить ошибки в тех случаях, когда на вход функции подается строка, содержащая символы вне диапазона 0 ..'z' (поскольку контроль входных идентификаторов отсутствует, это имеет смысл).
Для комбинации хэш-адресации и бинарного дерева можно использовать более простую хэш-функцию – сумму кодов первого и среднего символов входной строки. Диапазон значений такой хэш-функции в терминах языка Object Pascal будет выглядеть так:
(Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z'))
Этот диапазон содержит менее 200 элементов, однако функция будет удовлетворять требованиям задания, так как в комбинации с бинарным деревом она будет обеспечивать обработку неограниченного количества идентификаторов (максимальное количество идентификаторов будет ограничено только объемом доступной оперативной памяти компьютера).
Без применения рехэширования эта хэш-функция будет выглядеть значительно проще, чем описанная выше хэш-функция с учетом рехэширования:
function VarHash(const sName: string): longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
– HASH_MIN) mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end.
Описание структур данных таблиц идентификаторов
Организация таблиц идентификаторов
Текст программы
Выводы по проделанной работе
Лабораторная работа № 2
Цель работы
Краткие теоретические сведения
Назначение лексического анализатора
Проблема определения границ лексем
Таблица лексем и содержащаяся в ней информация
HASH_MAX = Ord('z')+Ord('z')+Ord('z').
Сама хэш-функция без учета рехэширования будет вычислять следующее выражение:
Ord(sName[1]) + Ord(sName[(Length(sName)+1) div 2]) + Ord(sName[Length(sName);
здесь sName – это входная строка (аргумент хэш-функции).
Для рехэширования возьмем простейший генератор последовательности псевдослучайных чисел, построенный на основе формулы F = i-H1 mod Н2, где Н1 и Н2 – простые числа, выбранные таким образом, чтобы H1 было в диапазоне от Н2/2 до Н2. Причем, чтобы этот генератор выдавал максимально длинную последовательность во всем диапазоне от HASH_MIN до HASH_MAX, Н2 должно быть максимально близко к величине HASH_MAX – HASН_МIN + 1. В данном случае диапазон содержит 223 элемента, и поскольку 223 – простое число, то возьмем Н2 = 223 (если бы размер диапазона не был простым числом, то в качестве Н2 нужно было бы взять ближайшее к нему меньшее простое число). В качестве H1 возьмем 127: H1 = 127.
Опишем соответствующие константы:
REHASH1 = 127;
REHASH2 = 223;
Тогда хэш-функция с учетом рехэширования будет иметь следующий вид:
function VarHash(const sName: string; iNum: integer):longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
+ Ord(sName[Length(sName)]) – HASH_MIN
+ iNum*REHASH1 mod REHASH2)
mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end;
Входные параметры этой функции: sName – имя хэшируемого идентификатора, iNum – индекс рехэшированиея (если iNum = 0, то рехэширование отсутствует). Строка проверки величины результата (Result < HASH_MIN) добавлена, чтобы исключить ошибки в тех случаях, когда на вход функции подается строка, содержащая символы вне диапазона 0 ..'z' (поскольку контроль входных идентификаторов отсутствует, это имеет смысл).
Для комбинации хэш-адресации и бинарного дерева можно использовать более простую хэш-функцию – сумму кодов первого и среднего символов входной строки. Диапазон значений такой хэш-функции в терминах языка Object Pascal будет выглядеть так:
(Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z'))
Этот диапазон содержит менее 200 элементов, однако функция будет удовлетворять требованиям задания, так как в комбинации с бинарным деревом она будет обеспечивать обработку неограниченного количества идентификаторов (максимальное количество идентификаторов будет ограничено только объемом доступной оперативной памяти компьютера).
Без применения рехэширования эта хэш-функция будет выглядеть значительно проще, чем описанная выше хэш-функция с учетом рехэширования:
function VarHash(const sName: string): longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
– HASH_MIN) mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end.
Описание структур данных таблиц идентификаторов
В первую очередь необходимо описать структуру данных, которая будет использована для хранения информации об идентификаторах в таблицах идентификаторов. Для обеих таблиц (с рехэшированием на основе генератора псевдослучайных чисел и в комбинации с бинарным деревом) будем использовать одну и ту же структуру. В этом случае в таблицах будут храниться неиспользуемые данные, но программный код будет проще. В качестве учебного примера такой подход оправдан.
Структура данных таблицы идентификаторов (назовем ее TVarInfo) должна содержать в обязательном порядке поле имени идентификатора (поле sName: string), а также поля дополнительной информации об идентификаторе по усмотрению разработчиков компилятора. В лабораторной работе не предусмотрено хранение какой-либо дополнительной информации об идентификаторах, поэтому в качестве иллюстрации информационного поля включим в структуру TVarInfo дополнительную информационную структуру TAddVarInfo (поле pInfo: TAddVarInfo).
Поскольку в языке Object Pascal для полей и переменных, описанных как class, хранятся только ссылки на соответствующую структуру, такой подход не приведет к значительным расходам памяти, но позволит в будущем хранить любую информацию, связанную с идентификатором, в отдельной структуре данных (поскольку предполагается использовать создаваемые программные модули в последующих лабораторных работах). В данном случае другой подход невозможен, так как заранее не известно, какие данные необходимо будет хранить в таблицах идентификаторов. Но разработчик реального компилятора, как правило, знает, какую информацию требуется хранить, и может использовать другой подход – непосредственно включить все необходимые поля в структуру данных таблицы идентификаторов (в данном случае – в структуру TVarInfo) без использования промежуточных структур данных и ссылок.
Первый подход, реализованный в данном примере, обеспечивает более экономное использование оперативной памяти, но является более сложным и требует работы с динамическими структурами, второй подход более прост в реализации, но менее экономно использует память. Какой из двух подходов выбрать, решает разработчик компилятора в каждом конкретном случае (второй подход будет проиллюстрирован позже в примере к лабораторной работе № 4).
Для работы со структурой данных TVarInfo потребуются следующие функции:
• функции создания структуры данных и освобождения занимаемой памяти – реализованы как constructor Create и destructor Destroy;
• функции доступа к дополнительной информации – в данной реализации это procedure SetInfo и procedure ClearInfo.
Эти функции будут общими для таблицы идентификаторов с рехэшированием и для комбинированной таблицы идентификаторов.
Однако для комбинированной таблицы идентификаторов в структуру данных TVarInfo потребуется также включить дополнительные поля данных и функции, обеспечивающие организацию бинарного дерева:
• ссылки на левую («меньшую») и правую («большую») ветвь дерева – реализованы как поля данных minEl, maxEl: TVarInfo;
• функции добавления элемента в дерево – function AddElCnt и function AddElem;
• функции поиска элемента в дереве – function FindElCnt и function FindElem;
• функция очистки информационных полей во всем дереве – procedure ClearAllInfo;
• функция вывода содержимого бинарного дерева в одну строку (для получения списка всех идентификаторов) – function GetElList.
Функции поиска и размещения элемента в дереве реализованы в двух экземплярах, так как одна из них выполняет подсчет количества сравнений, а другая – нет.
Поскольку на функции и процедуры не расходуется оперативная память, в результате получилось, что при использовании одной и той же структуры данных для разных таблиц идентификаторов в таблице с рехэшированием будет расходоваться неиспользуемая память только на хранение двух лишних ссылок (minEl и maxEl).
Полностью вся структура данных TVarInfo и связанные с ней процедуры и функции описаны в программном модуле TblElem. Полный текст этого программного модуля приведен в листинге П3.1 в приложении 3.
Надо обратить внимание на один важный момент в реализации функции поиска идентификатора в дереве (function TVarInfo.FindElCnt). Если выполнять сравнение двух строк (в данном случае – имени искомого идентификатора sN и имени идентификатора в текущем узле дерева sName) с помощью стандартных методов сравнения строк языка Object Pascal, то фрагмент программного кода выглядел бы примерно так:
if sN < sName then
begin
…
end
else
if sN > sName then
begin
…
end
else…
В этом фрагменте сравнение строк выполняется дважды: сначала проверяется отношение «меньше» (sN < sName), а потом – «больше» (sN > sName). И хотя в программном коде явно это не указано, для каждого из этих операторов будет вызвана библиотечная функция сравнения строк (то есть операция сравнения может выполниться дважды!). Чтобы этого избежать, в реализации предложенной в примере выполняется явный вызов функции сравнения строк, а потом обрабатывается полученный результат:
i:= StrComp(PChar(sN), PChar(sName));
if i < 0 then
begin
…
end
else
if i > 0 then
begin
…
end
else…
В таком варианте дважды может быть выполнено только сравнение целого числа с нулем, а сравнение строк всегда выполняется только один раз, что существенно увеличивает эффективность процедуры поиска.
Структура данных таблицы идентификаторов (назовем ее TVarInfo) должна содержать в обязательном порядке поле имени идентификатора (поле sName: string), а также поля дополнительной информации об идентификаторе по усмотрению разработчиков компилятора. В лабораторной работе не предусмотрено хранение какой-либо дополнительной информации об идентификаторах, поэтому в качестве иллюстрации информационного поля включим в структуру TVarInfo дополнительную информационную структуру TAddVarInfo (поле pInfo: TAddVarInfo).
Поскольку в языке Object Pascal для полей и переменных, описанных как class, хранятся только ссылки на соответствующую структуру, такой подход не приведет к значительным расходам памяти, но позволит в будущем хранить любую информацию, связанную с идентификатором, в отдельной структуре данных (поскольку предполагается использовать создаваемые программные модули в последующих лабораторных работах). В данном случае другой подход невозможен, так как заранее не известно, какие данные необходимо будет хранить в таблицах идентификаторов. Но разработчик реального компилятора, как правило, знает, какую информацию требуется хранить, и может использовать другой подход – непосредственно включить все необходимые поля в структуру данных таблицы идентификаторов (в данном случае – в структуру TVarInfo) без использования промежуточных структур данных и ссылок.
Первый подход, реализованный в данном примере, обеспечивает более экономное использование оперативной памяти, но является более сложным и требует работы с динамическими структурами, второй подход более прост в реализации, но менее экономно использует память. Какой из двух подходов выбрать, решает разработчик компилятора в каждом конкретном случае (второй подход будет проиллюстрирован позже в примере к лабораторной работе № 4).
Для работы со структурой данных TVarInfo потребуются следующие функции:
• функции создания структуры данных и освобождения занимаемой памяти – реализованы как constructor Create и destructor Destroy;
• функции доступа к дополнительной информации – в данной реализации это procedure SetInfo и procedure ClearInfo.
Эти функции будут общими для таблицы идентификаторов с рехэшированием и для комбинированной таблицы идентификаторов.
Однако для комбинированной таблицы идентификаторов в структуру данных TVarInfo потребуется также включить дополнительные поля данных и функции, обеспечивающие организацию бинарного дерева:
• ссылки на левую («меньшую») и правую («большую») ветвь дерева – реализованы как поля данных minEl, maxEl: TVarInfo;
• функции добавления элемента в дерево – function AddElCnt и function AddElem;
• функции поиска элемента в дереве – function FindElCnt и function FindElem;
• функция очистки информационных полей во всем дереве – procedure ClearAllInfo;
• функция вывода содержимого бинарного дерева в одну строку (для получения списка всех идентификаторов) – function GetElList.
Функции поиска и размещения элемента в дереве реализованы в двух экземплярах, так как одна из них выполняет подсчет количества сравнений, а другая – нет.
Поскольку на функции и процедуры не расходуется оперативная память, в результате получилось, что при использовании одной и той же структуры данных для разных таблиц идентификаторов в таблице с рехэшированием будет расходоваться неиспользуемая память только на хранение двух лишних ссылок (minEl и maxEl).
Полностью вся структура данных TVarInfo и связанные с ней процедуры и функции описаны в программном модуле TblElem. Полный текст этого программного модуля приведен в листинге П3.1 в приложении 3.
Надо обратить внимание на один важный момент в реализации функции поиска идентификатора в дереве (function TVarInfo.FindElCnt). Если выполнять сравнение двух строк (в данном случае – имени искомого идентификатора sN и имени идентификатора в текущем узле дерева sName) с помощью стандартных методов сравнения строк языка Object Pascal, то фрагмент программного кода выглядел бы примерно так:
if sN < sName then
begin
…
end
else
if sN > sName then
begin
…
end
else…
В этом фрагменте сравнение строк выполняется дважды: сначала проверяется отношение «меньше» (sN < sName), а потом – «больше» (sN > sName). И хотя в программном коде явно это не указано, для каждого из этих операторов будет вызвана библиотечная функция сравнения строк (то есть операция сравнения может выполниться дважды!). Чтобы этого избежать, в реализации предложенной в примере выполняется явный вызов функции сравнения строк, а потом обрабатывается полученный результат:
i:= StrComp(PChar(sN), PChar(sName));
if i < 0 then
begin
…
end
else
if i > 0 then
begin
…
end
else…
В таком варианте дважды может быть выполнено только сравнение целого числа с нулем, а сравнение строк всегда выполняется только один раз, что существенно увеличивает эффективность процедуры поиска.
Организация таблиц идентификаторов
Таблицы идентификаторов реализованы в виде статических массивов размером HASH_MIN..HASH_MAX, элементами которых являются структуры данных типа TVarInfo. В языке Object Pascal, как было сказано выше, для структур таких типов хранятся ссылки. Поэтому для обозначения пустых ячеек в таблицах идентификаторов будет использоваться пустая ссылка – nil.
Поскольку в памяти хранятся ссылки, описанные массивы будут играть роль хэш-таблиц, ссылки из которых указывают непосредственно на информацию в таблицах идентификаторов.
На рис. 1.3 показаны условные схемы, наглядно иллюстрирующие организацию таблиц идентификаторов. Схема 1 иллюстрирует таблицу идентификаторов с рехэшированием на основе генератора псевдослучайных чисел, схема 2 – таблицу идентификаторов на основе комбинации хэш-адресации с бинарным деревом. Ячейки с надписью «nil» соответствуют незаполненным ячейкам хэш-таблицы.
 Рис. 1.3. Схемы организации таблиц идентификаторов.
Рис. 1.3. Схемы организации таблиц идентификаторов.
Для каждой таблицы идентификаторов реализованы следующие функции:
• функции начальной инициализации хэш-таблицы – InitTreeVar и InitHashVar;
• функции освобождения памяти хэш-таблицы – ClearTreeVar и ClearHashVar;
• функции удаления дополнительной информации в таблице – ClearTreeInfo и ClearHashInfo;
• функции добавления элемента в таблицу идентификаторов – AddTreeVar и AddHashVar;
• функции поиска элемента в таблице идентификаторов – GetTreeVar и GetHashVar;
• функции, возвращающие количество выполненных операций сравнения при размещении или поиске элемента в таблице – GetTreeCount и GetHashCount.
Алгоритмы поиска и размещения идентификаторов для двух данных методов организации таблиц были описаны выше в разделе «Краткие теоретические сведения», поэтому приводить их здесь повторно нет смысла. Они реализованы в виде четырех перечисленных выше функций (AddTreeVar и AddHashVar – для размещения элемента; GetTreeVar и GetHashVar – для поиска элемента). Функции поиска и размещения элементов в таблице в качестве результата возвращают ссылку на элемент таблицы (структура которого описана в модуле TblElem) в случае успешного выполнения и нулевую ссылку – в противном случае.
Надо отметить, что функции размещения идентификатора в таблице организованы таким образом, что если на момент помещения нового идентификатора в таблице уже есть идентификатор с таким же именем, то функция не добавляет новый идентификатор в таблицу, а возвращает в качестве результата ссылку на ранее помещенный в таблицу идентификатор. Таким образом, в таблице не может быть двух и более идентификаторов с одинаковым именем. При этом наличие одинаковых идентификаторов во входном файле не воспринимается как ошибка – это допустимо, так как в задании не предусмотрено ограничение на наличие совпадающих имен идентификаторов.
Все перечисленные функции описаны в двух программных модулях: FncHash – для таблицы идентификаторов, построенной на основе рехэширования с использованием генератора псевдослучайных чисел, и FncTree – для таблицы идентификаторов, построенной на основе комбинации хэш-адресации и бинарного дерева. Кроме массивов данных для организации таблиц идентификаторов и функций работы с ними эти модули содержат также описание переменных, используемых для подсчета количества выполненных операций сравнения при размещении и поиске идентификатора в таблицах.
Полные тексты обоих модулей (FncHash и FncTree) можно найти на веб-сайте издательства, в файлах FncHash.pas и FncTree.pas. Кроме того, текст модуля FncTree приведен в листинге П3.2 в приложении 3.
Хочется обратить внимание на то, что в разделах инициализации (initialization) обоих модулей вызывается функция начального заполнения таблицы идентификаторов, а в разделах завершения (finalization) обоих модулей – функция освобождения памяти. Это гарантирует корректную работу модулей при любом порядке вызова остальных функций, поскольку Object Pascal сам обеспечивает своевременный вызов программного кода в разделах инициализации и завершения модулей.
Поскольку в памяти хранятся ссылки, описанные массивы будут играть роль хэш-таблиц, ссылки из которых указывают непосредственно на информацию в таблицах идентификаторов.
На рис. 1.3 показаны условные схемы, наглядно иллюстрирующие организацию таблиц идентификаторов. Схема 1 иллюстрирует таблицу идентификаторов с рехэшированием на основе генератора псевдослучайных чисел, схема 2 – таблицу идентификаторов на основе комбинации хэш-адресации с бинарным деревом. Ячейки с надписью «nil» соответствуют незаполненным ячейкам хэш-таблицы.
Для каждой таблицы идентификаторов реализованы следующие функции:
• функции начальной инициализации хэш-таблицы – InitTreeVar и InitHashVar;
• функции освобождения памяти хэш-таблицы – ClearTreeVar и ClearHashVar;
• функции удаления дополнительной информации в таблице – ClearTreeInfo и ClearHashInfo;
• функции добавления элемента в таблицу идентификаторов – AddTreeVar и AddHashVar;
• функции поиска элемента в таблице идентификаторов – GetTreeVar и GetHashVar;
• функции, возвращающие количество выполненных операций сравнения при размещении или поиске элемента в таблице – GetTreeCount и GetHashCount.
Алгоритмы поиска и размещения идентификаторов для двух данных методов организации таблиц были описаны выше в разделе «Краткие теоретические сведения», поэтому приводить их здесь повторно нет смысла. Они реализованы в виде четырех перечисленных выше функций (AddTreeVar и AddHashVar – для размещения элемента; GetTreeVar и GetHashVar – для поиска элемента). Функции поиска и размещения элементов в таблице в качестве результата возвращают ссылку на элемент таблицы (структура которого описана в модуле TblElem) в случае успешного выполнения и нулевую ссылку – в противном случае.
Надо отметить, что функции размещения идентификатора в таблице организованы таким образом, что если на момент помещения нового идентификатора в таблице уже есть идентификатор с таким же именем, то функция не добавляет новый идентификатор в таблицу, а возвращает в качестве результата ссылку на ранее помещенный в таблицу идентификатор. Таким образом, в таблице не может быть двух и более идентификаторов с одинаковым именем. При этом наличие одинаковых идентификаторов во входном файле не воспринимается как ошибка – это допустимо, так как в задании не предусмотрено ограничение на наличие совпадающих имен идентификаторов.
Все перечисленные функции описаны в двух программных модулях: FncHash – для таблицы идентификаторов, построенной на основе рехэширования с использованием генератора псевдослучайных чисел, и FncTree – для таблицы идентификаторов, построенной на основе комбинации хэш-адресации и бинарного дерева. Кроме массивов данных для организации таблиц идентификаторов и функций работы с ними эти модули содержат также описание переменных, используемых для подсчета количества выполненных операций сравнения при размещении и поиске идентификатора в таблицах.
Полные тексты обоих модулей (FncHash и FncTree) можно найти на веб-сайте издательства, в файлах FncHash.pas и FncTree.pas. Кроме того, текст модуля FncTree приведен в листинге П3.2 в приложении 3.
Хочется обратить внимание на то, что в разделах инициализации (initialization) обоих модулей вызывается функция начального заполнения таблицы идентификаторов, а в разделах завершения (finalization) обоих модулей – функция освобождения памяти. Это гарантирует корректную работу модулей при любом порядке вызова остальных функций, поскольку Object Pascal сам обеспечивает своевременный вызов программного кода в разделах инициализации и завершения модулей.
Текст программы
Кроме перечисленных выше модулей необходим еще модуль, обеспечивающий интерфейс с пользователем. Этот модуль (FormLab1) реализует графическое окно TLab1Form на основе класса TForm библиотеки VCL. Он обеспечивает интерфейс средствами Graphical User Interface (GUI) в ОС типа Windows на основе стандартных органов управления из системных библиотек данной ОС. Кроме программного кода (файл FormLab1.pas) модуль включает в себя описание ресурсов пользовательского интерфейса (файл FormLab1.dfm). Более подробно принципы организации пользовательского интерфейса на основе GUI и работа систем программирования с ресурсами интерфейса описаны в [3, 5, 6, 7].
Кроме описания интерфейсной формы и ее органов управления модуль FormLab1 содержит три переменные (iCountNum, iCountHash, iCountTree), служащие для накопления статистических результатов по мере выполнения размещения и поиска идентификаторов в таблицах, а также функцию (procedure ViewStatistic) для отображения накопленной статистической информации на экране.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
• многострочное поле для отображения прочитанного файла (Listldents);
• поле ввода имени искомого идентификатора (EditSearch);
• кнопка для поиска введенного идентификатора (BtnSearch) – этой кнопкой однократно вызывается процедура поиска (procedure SearchStr);
• кнопка автоматического поиска всех идентификаторов (BtnAllSearch) – этой кнопкой процедура поиска идентификатора (procedure SearchStr) вызывается циклически для всех считанных из файла идентификаторов (для всех, перечисленных в поле Listldents);
• кнопка сброса накопленной статистической информации (BtnReset);
• поля для отображения статистической информации;
• кнопка завершения работы с программой (BtnExit).
Внешний вид этой формы приведен на рис. 1.4.
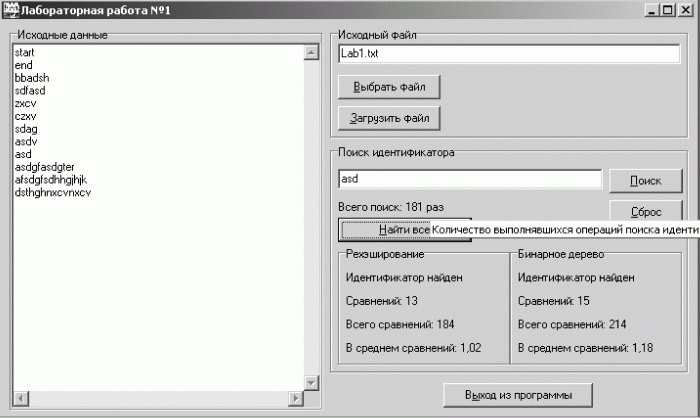 Рис. 1.4. Внешний вид интерфейсной формы для лабораторной работы № 1.
Рис. 1.4. Внешний вид интерфейсной формы для лабораторной работы № 1.
Функция чтения содержимого файла с идентификаторами (procedure TLab1Form. BtnLoadClick) вызывается щелчком по кнопке BtnLoad. Она организована таким образом, что сначала содержимое файла читается в многострочное поле Listldents, а затем все прочитанные идентификаторы записываются в две таблицы идентификаторов. Каждая строка файла считается отдельным идентификатором, пробелы в начале и в конце строки игнорируются. При ошибке размещения идентификатора в одной из таблиц выдается предупреждающее сообщение (например, если будет считано более 223 различных идентификаторов, то рехэширование станет невозможным и будет выдано сообщение об ошибке).
Функция поиска идентификатора (procedure TLab1Form.SearchStr) вызывается однократно щелчком по кнопке BtnSearch (процедура procedure TLab1Form.BtnSearchClick) или многократно щелчком по кнопке BtnAllSearch (процедура procedure TLab1Form. BtnAllSearchClick). Поиск идет сразу в двух таблицах, результаты поиска и накопленная статистическая информация отображаются в соответствующих полях.
Полный текст программного кода модуля интерфейса с пользователем и описание ресурсов пользовательского интерфейса находятся в архиве, располагающемся на веб-сайте издательства, в файлах FormLab1.pas и FormLab1.dfm соответственно.
Полный текст всех программных модулей, реализующих рассмотренный пример для лабораторной работы № 1, можно найти в архиве, располагающемся на вебсайте, в подкаталогах LABS и COMMON (в подкаталог COMMON вынесены те программные модули, исходный текст которых не зависит от входного языка и задания по лабораторной работе). Главным файлом проекта является файл LAB1.DPR в подкаталоге LABS. Кроме того, текст модуля FncTree приведен в листинге П3.1 в приложении 3.
Кроме описания интерфейсной формы и ее органов управления модуль FormLab1 содержит три переменные (iCountNum, iCountHash, iCountTree), служащие для накопления статистических результатов по мере выполнения размещения и поиска идентификаторов в таблицах, а также функцию (procedure ViewStatistic) для отображения накопленной статистической информации на экране.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
• многострочное поле для отображения прочитанного файла (Listldents);
• поле ввода имени искомого идентификатора (EditSearch);
• кнопка для поиска введенного идентификатора (BtnSearch) – этой кнопкой однократно вызывается процедура поиска (procedure SearchStr);
• кнопка автоматического поиска всех идентификаторов (BtnAllSearch) – этой кнопкой процедура поиска идентификатора (procedure SearchStr) вызывается циклически для всех считанных из файла идентификаторов (для всех, перечисленных в поле Listldents);
• кнопка сброса накопленной статистической информации (BtnReset);
• поля для отображения статистической информации;
• кнопка завершения работы с программой (BtnExit).
Внешний вид этой формы приведен на рис. 1.4.
Функция чтения содержимого файла с идентификаторами (procedure TLab1Form. BtnLoadClick) вызывается щелчком по кнопке BtnLoad. Она организована таким образом, что сначала содержимое файла читается в многострочное поле Listldents, а затем все прочитанные идентификаторы записываются в две таблицы идентификаторов. Каждая строка файла считается отдельным идентификатором, пробелы в начале и в конце строки игнорируются. При ошибке размещения идентификатора в одной из таблиц выдается предупреждающее сообщение (например, если будет считано более 223 различных идентификаторов, то рехэширование станет невозможным и будет выдано сообщение об ошибке).
Функция поиска идентификатора (procedure TLab1Form.SearchStr) вызывается однократно щелчком по кнопке BtnSearch (процедура procedure TLab1Form.BtnSearchClick) или многократно щелчком по кнопке BtnAllSearch (процедура procedure TLab1Form. BtnAllSearchClick). Поиск идет сразу в двух таблицах, результаты поиска и накопленная статистическая информация отображаются в соответствующих полях.
Полный текст программного кода модуля интерфейса с пользователем и описание ресурсов пользовательского интерфейса находятся в архиве, располагающемся на веб-сайте издательства, в файлах FormLab1.pas и FormLab1.dfm соответственно.
Полный текст всех программных модулей, реализующих рассмотренный пример для лабораторной работы № 1, можно найти в архиве, располагающемся на вебсайте, в подкаталогах LABS и COMMON (в подкаталог COMMON вынесены те программные модули, исходный текст которых не зависит от входного языка и задания по лабораторной работе). Главным файлом проекта является файл LAB1.DPR в подкаталоге LABS. Кроме того, текст модуля FncTree приведен в листинге П3.1 в приложении 3.
Выводы по проделанной работе
В результате выполнения написанного программного кода для ряда тестовых файлов было установлено, что при заполнении таблицы идентификаторов до 20 % (до 45 идентификаторов) для поиска и размещения идентификатора с использованием рехэширования на основе генератора псевдослучайных чисел в среднем требуется меньшее число сравнений, чем при использовании хэш-адресации в комбинации с бинарным деревом. При заполнении таблицы от 20 % до 40 % (примерно 45–90 идентификаторов) оба метода имеют примерно равные показатели, но при заполнении таблицы более, чем на 40 % (90-223 идентификаторов), эффективность комбинированного метода по сравнению с методом рехэширования резко возрастает. Если на входе имеется более 223 идентификаторов, рехэширование полностью перестает работать.
Таким образом, установлено, что комбинированный метод работоспособен даже при наличии простейшей хэш-функции и дает неплохие результаты (в среднем 3–5 сравнений на входных файлах, содержащих 500–700 идентификаторов), в то время как метод на основе рехэширования для реальной работы требует более сложной хэш-функции с диапазоном значений в несколько тысяч или десятков тысяч.
Таким образом, установлено, что комбинированный метод работоспособен даже при наличии простейшей хэш-функции и дает неплохие результаты (в среднем 3–5 сравнений на входных файлах, содержащих 500–700 идентификаторов), в то время как метод на основе рехэширования для реальной работы требует более сложной хэш-функции с диапазоном значений в несколько тысяч или десятков тысяч.
Лабораторная работа № 2
Проектирование лексического анализатора
Цель работы
Цель работы: изучение основных понятий теории регулярных грамматик, ознакомление с назначением и принципами работы лексических анализаторов (сканеров), получение практических навыков построения сканера на примере заданного простейшего входного языка.
Краткие теоретические сведения
Назначение лексического анализатора
Лексический анализатор (или сканер) – это часть компилятора, которая читает литеры программы на исходном языке и строит из них слова (лексемы) исходного языка. На вход лексического анализатора поступает текст исходной программы, а выходная информация передается для дальнейшей обработки компилятором на этапе синтаксического анализа и разбора.
Лексема (лексическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка.
С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического анализа. Однако существует несколько причин, исходя из которых в состав практически всех компиляторов включают лексический анализ. Это следующие причины:
• упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и удаляет всю незначащую информацию;
• для выделения в тексте и разбора лексем возможно применять простую, эффективную и хорошо проработанную теоретически технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
• лексический анализатор отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходной программы, структура которого может варьироваться в зависимости от версии входного языка – при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой лексический анализатор.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, знаков операций, разделителей и ключевых (служебных) слов входного языка.
В большинстве компиляторов лексический и синтаксический анализаторы – это взаимосвязанные части. Где провести границу между лексическим и синтаксическим анализом, какие конструкции анализировать сканером, а какие – синтаксическим распознавателем, решает разработчик компилятора. Как правило, любой анализ стремятся выполнить на этапе лексического разбора входной программы, если он может быть там выполнен. Возможности лексического анализатора ограничены по сравнению с синтаксическим анализатором, так как в его основе лежат более простые механизмы. Более подробно о роли лексического анализатора в компиляторе и о его взаимодействии с синтаксическим анализатором можно узнать в [1–4, 7].
Лексема (лексическая единица языка) – это структурная единица языка, которая состоит из элементарных символов языка и не содержит в своем составе других структурных единиц языка. Лексемами языков программирования являются идентификаторы, константы, ключевые слова языка, знаки операций и т. п. Состав возможных лексем каждого конкретного языка программирования определяется синтаксисом этого языка.
С теоретической точки зрения лексический анализатор не является обязательной, необходимой частью компилятора. Его функции могут выполняться на этапе синтаксического анализа. Однако существует несколько причин, исходя из которых в состав практически всех компиляторов включают лексический анализ. Это следующие причины:
• упрощается работа с текстом исходной программы на этапе синтаксического разбора и сокращается объем обрабатываемой информации, так как лексический анализатор структурирует поступающий на вход исходный текст программы и удаляет всю незначащую информацию;
• для выделения в тексте и разбора лексем возможно применять простую, эффективную и хорошо проработанную теоретически технику анализа, в то время как на этапе синтаксического анализа конструкций исходного языка используются достаточно сложные алгоритмы разбора;
• лексический анализатор отделяет сложный по конструкции синтаксический анализатор от работы непосредственно с текстом исходной программы, структура которого может варьироваться в зависимости от версии входного языка – при такой конструкции компилятора при переходе от одной версии языка к другой достаточно только перестроить относительно простой лексический анализатор.
Функции, выполняемые лексическим анализатором, и состав лексем, которые он выделяет в тексте исходной программы, могут меняться в зависимости от версии компилятора. В основном лексические анализаторы выполняют исключение из текста исходной программы комментариев и незначащих пробелов, а также выделение лексем следующих типов: идентификаторов, строковых, символьных и числовых констант, знаков операций, разделителей и ключевых (служебных) слов входного языка.
В большинстве компиляторов лексический и синтаксический анализаторы – это взаимосвязанные части. Где провести границу между лексическим и синтаксическим анализом, какие конструкции анализировать сканером, а какие – синтаксическим распознавателем, решает разработчик компилятора. Как правило, любой анализ стремятся выполнить на этапе лексического разбора входной программы, если он может быть там выполнен. Возможности лексического анализатора ограничены по сравнению с синтаксическим анализатором, так как в его основе лежат более простые механизмы. Более подробно о роли лексического анализатора в компиляторе и о его взаимодействии с синтаксическим анализатором можно узнать в [1–4, 7].
Проблема определения границ лексем
В простейшем случае фазы лексического и синтаксического анализа могут выполняться компилятором последовательно. Но для многих языков программирования информации на этапе лексического анализа может быть недостаточно для однозначного определения типа и границ очередной лексемы.
Иллюстрацией такого случая может служить пример оператора программы на языке Фортран, когда по части текста DO 10 I=1… невозможно определить тип оператора (а соответственно, и границы лексем). В случае DO 10 I=1.15 это будет присвоение вещественной переменной DO10I значения константы 1.15 (пробелы в Фортране игнорируются), а в случае DO 10 I=1,15 это цикл с перечислением от 1 до 15 по целочисленной переменной I до метки 10.
Другая иллюстрация из более современного языка программирования C++ – оператор присваивания k=i+++++j;, который имеет только одну верную интерпретацию (если операции разделить пробелами): k = i++ + ++j;.
Если невозможно определить границы лексем, то лексический анализ исходного текста должен выполняться поэтапно. Тогда лексический и синтаксический анализаторы должны функционировать параллельно, поочередно обращаясь друг к другу. Лексический анализатор, найдя очередную лексему, передает ее синтаксическому анализатору, тот пытается выполнить анализ считанной части исходной программы и может либо запросить у лексического анализатора следующую лексему, либо потребовать от него вернуться на несколько шагов назад и попробовать выделить лексемы с другими границами. При этом он может сообщить информацию о том, какую лексему следует ожидать. Более подробно такая схема взаимодействия лексического и синтаксического анализаторов описана в [3, 7].
Параллельная работа лексического и синтаксического анализаторов, очевидно, более сложна в реализации, чем их последовательное выполнение. Кроме того, такой подход требует больше вычислительных ресурсов и в общем случае большего времени на анализ исходной программы, так как допускает возврат назад и повторный анализ уже прочитанной части исходного кода. Тем не менее сложность синтаксиса некоторых языков программирования требует именно такого подхода – рассмотренный ранее пример программы на языке Фортран не может быть проанализирован иначе.
Чтобы избежать параллельной работы лексического и синтаксического анализаторов, разработчики компиляторов и языков программирования часто идут на разумные ограничения синтаксиса входного языка. Например, для языка C++ принято соглашение, что при возникновении проблем с определением границ лексемы всегда выбирается лексема максимально возможной длины.
В рассмотренном выше примере для оператора k=i+++++j; это приведет к тому, что при чтении четвертого знака + из двух вариантов лексем (+ – знак сложения в C++, а ++ – оператор инкремента) лексический анализатор выберет самую длинную – ++ (оператор инкремента) – и в целом весь оператор будет разобран как k = i++ ++ +j; (знаки операций разделены пробелами), что неверно, так как семантика языка C++ запрещает два оператора инкремента подряд. Конечно, неверный анализ операторов, аналогичных приведенному в примере (желающие могут убедиться в этом на любом доступном компиляторе языка C++), – незначительная плата за увеличение эффективности работы компилятора и не ограничивает возможности языка (тот же самый оператор может быть записан в виде k=i++ + ++j;, что исключит любые неоднозначности в его анализе). Однако таким же путем для языка Фортран пойти нельзя – разница между оператором присваивания и оператором цикла слишком велика, чтобы ею можно было пренебречь.
В дальнейшем будем исходить из предположения, что все лексемы могут быть однозначно выделены сканером на этапе лексического анализа. Для всех современных языков программирования это действительно так, поскольку их синтаксис разрабатывался с учетом возможностей компиляторов.
Иллюстрацией такого случая может служить пример оператора программы на языке Фортран, когда по части текста DO 10 I=1… невозможно определить тип оператора (а соответственно, и границы лексем). В случае DO 10 I=1.15 это будет присвоение вещественной переменной DO10I значения константы 1.15 (пробелы в Фортране игнорируются), а в случае DO 10 I=1,15 это цикл с перечислением от 1 до 15 по целочисленной переменной I до метки 10.
Другая иллюстрация из более современного языка программирования C++ – оператор присваивания k=i+++++j;, который имеет только одну верную интерпретацию (если операции разделить пробелами): k = i++ + ++j;.
Если невозможно определить границы лексем, то лексический анализ исходного текста должен выполняться поэтапно. Тогда лексический и синтаксический анализаторы должны функционировать параллельно, поочередно обращаясь друг к другу. Лексический анализатор, найдя очередную лексему, передает ее синтаксическому анализатору, тот пытается выполнить анализ считанной части исходной программы и может либо запросить у лексического анализатора следующую лексему, либо потребовать от него вернуться на несколько шагов назад и попробовать выделить лексемы с другими границами. При этом он может сообщить информацию о том, какую лексему следует ожидать. Более подробно такая схема взаимодействия лексического и синтаксического анализаторов описана в [3, 7].
Параллельная работа лексического и синтаксического анализаторов, очевидно, более сложна в реализации, чем их последовательное выполнение. Кроме того, такой подход требует больше вычислительных ресурсов и в общем случае большего времени на анализ исходной программы, так как допускает возврат назад и повторный анализ уже прочитанной части исходного кода. Тем не менее сложность синтаксиса некоторых языков программирования требует именно такого подхода – рассмотренный ранее пример программы на языке Фортран не может быть проанализирован иначе.
Чтобы избежать параллельной работы лексического и синтаксического анализаторов, разработчики компиляторов и языков программирования часто идут на разумные ограничения синтаксиса входного языка. Например, для языка C++ принято соглашение, что при возникновении проблем с определением границ лексемы всегда выбирается лексема максимально возможной длины.
В рассмотренном выше примере для оператора k=i+++++j; это приведет к тому, что при чтении четвертого знака + из двух вариантов лексем (+ – знак сложения в C++, а ++ – оператор инкремента) лексический анализатор выберет самую длинную – ++ (оператор инкремента) – и в целом весь оператор будет разобран как k = i++ ++ +j; (знаки операций разделены пробелами), что неверно, так как семантика языка C++ запрещает два оператора инкремента подряд. Конечно, неверный анализ операторов, аналогичных приведенному в примере (желающие могут убедиться в этом на любом доступном компиляторе языка C++), – незначительная плата за увеличение эффективности работы компилятора и не ограничивает возможности языка (тот же самый оператор может быть записан в виде k=i++ + ++j;, что исключит любые неоднозначности в его анализе). Однако таким же путем для языка Фортран пойти нельзя – разница между оператором присваивания и оператором цикла слишком велика, чтобы ею можно было пренебречь.
В дальнейшем будем исходить из предположения, что все лексемы могут быть однозначно выделены сканером на этапе лексического анализа. Для всех современных языков программирования это действительно так, поскольку их синтаксис разрабатывался с учетом возможностей компиляторов.
Таблица лексем и содержащаяся в ней информация
Результатом работы лексического анализатора является перечень всех найденных в тексте исходной программы лексем с учетом характеристик каждой лексемы. Этот перечень лексем можно представить в виде таблицы, называемой таблицей лексем. Каждой лексеме в таблице лексем соответствует некий уникальный условный код, зависящий от типа лексемы, и дополнительная служебная информация. Таблица лексем в каждой строке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно структуры данных, служащие для организации такой таблицы, имеют два поля: первое – тип лексемы, второе – указатель на информацию о лексеме.