Итак, хотя сокращенный КА меньше по количеству состояний и проще в реализации, он является менее эффективным, чем полный КА, построенный на анализе всех входных лексем. Тем не менее оба варианта реализации КА обеспечивают построение требуемого лексического анализатора. Какой из них выбрать, решает разработчик компилятора.
Реализация лексического анализатора
• модули, программный код которых не зависит от входного языка;
• модули, программный код которых зависит от входного языка.
В первую группу входят модули:
• LexElem – описывает структуру данных элемента таблицы лексем;
• FormLab2 – описывает интерфейс с пользователем.
Во вторую группу входят модули:
• LexType – описывает типы входных лексем, связанные с ними наименования и текстовую информацию;
• LexAuto – реализует функционирование КА.
Такое разбиение на модули позволяет использовать те же самые структуры данных для организации лексического распознавателя при изменении входного языка.
Кроме этих модулей для реализации лабораторной работы № 2 используются также программные модули (TblElem и FncTree), позволяющие работать с комбинированной таблицей идентификаторов, которые были созданы при выполнении лабораторной работы № 1. Эти два модуля, очевидно, также не зависят от входного языка.
Кратко опишем содержание программных модулей, используемых для организации лексического анализатора.
Модуль LexElem описывает структуры данных элемента таблицы лексем (TLexem) и самой таблицы лексем (TLexList), а также все, что с ними связано.
• VarInfo – ссылку на элемент таблицы идентификаторов для лексем типа «переменная»;
• ConstVal – целочисленное значение для лексем типа «константа»;
• szInfo – произвольная строка для информационной лексемы.
Для лексем других типов не требуется никакой дополнительной информации.
Следует отметить, что для лексем типа «переменная» хранится именно ссылка на таблицу идентификаторов, а не имя переменной. Именно для этого в данной лабораторной работе используются модули из лабораторной работы № 1. Для самого лексического анализатора не имеет значения, что хранить в таблице лексем – ссылку на таблицу идентификаторов со всей информацией о переменной или же только имя переменной. Но реализация лексического анализатора, при которой хранится именно ссылка на таблицу идентификаторов, чрезвычайно удобна для дальнейшей обработки данных, что будет очевидно в последующих работах (лабораторных работах № 3 и № 4). Поскольку лексический анализатор интересен не сам по себе, а в составе компилятора, такой подход принципиально важен.
Кроме этого в структуре данных элемента таблицы лексем хранится информация о позиции лексемы в тексте входной программы:
• iStr – номер строки, где встретилась лексема;
• iPos – позиция лексемы в строке;
• iAllP – позиция лексемы относительно начала входного файла.
Эта информация будет полезна, в частности, при информировании пользователя об ошибках.
Кроме этих данных структура содержит также:
• четыре конструктора для создания лексем четырех разных типов:
– CreateVar – для создания лексем типа «переменная»;
– CreateConst – для создания лексем типа «константа»;
– CreateInfo – для создания информационных лексем;
– CreateKey – для создания лексем других типов;
• деструктор Destroy для освобождения памяти, занятой лексемой (важен для информационных лексем);
• свойства и функции для доступа к информации о лексеме.
Хранить в структуре строку самой лексемы нет никакой необходимости (для переменных строка хранится в таблице идентификаторов, для других типов лексем она просто не нужна).
Сама таблица лексем (тип данных TLexList) построена на основе динамического массива TList из библиотеки VCL (модуль Classes) системы программирования Delphi 5.
Динамический массив типа TList обеспечивает все функции и данные, необходимые для хранения в памяти произвольного количества лексем (максимальное количество лексем ограничено только объемом доступной оперативной памяти). Для таблицы лексем TLexList дополнительно реализованы функции очистки таблицы, которые освобождают память, занятую лексемами, при их удалении из таблицы (функция Clear и деструктор Destroy), а также функция GetLexem и свойство Lexem, обеспечивающие удобный доступ к любой лексеме в таблице по ее индексу (порядковому номеру).
Главной составляющей этого программного модуля является функция МакеLexList, которая непосредственно моделирует работу КА. На вход функции подается входная программа в виде списка строк (формальный параметр listFile) и таблица лексем, куда должны помещаться найденные лексемы (формальный параметр listLex). Результатом работы функции является 0, если лексический анализ выполнен без ошибок, а если ошибка обнаружена – номер строки в исходном файле, в которой она присутствует. Для более подробной информации об обнаруженной ошибке функция создает информационную лексему и помещает ее в конец таблицы лексем. Сама информационная лексема кроме текстовой информации об ошибке содержит еще дополнительную информацию о ее местонахождении в исходной программе (смещение от начала файла и длина ошибочной лексемы).
В типе данных TAutoPos перечислены все возможные состояния КА. Перечень состояний полностью соответствует функции переходов КА.
Реализация функции MakeLexList, несмотря на большой объем программного кода, предельно проста. Она построена на основе двух вложенных циклов (первый – по строкам входного списка, второй – по символам в текущей строке), внутри которых находятся два уровня вложенных оператора выбора типа case – типичный подход к моделированию функционирования КА. Внешний оператор case выполняется по всем возможным состояниям автомата, а case второго уровня – по допустимым входным символам в каждом состоянии.
Можно обратить внимание на шесть вспомогательных функций:
• AddVarToList – добавление лексемы типа «переменная» в таблицу лексем;
• AddVarKeyToList – добавление лексем типа «переменная» и типа «разделитель» в таблицу лексем;
• AddConstToList – добавление лексемы типа «константа» в таблицу лексем;
• AddConstKeyToList – добавление лексем типа «константа» и типа «разделитель» в таблицу лексем;
• AddKeyToList – добавление лексемы типа «ключевое слово» или «разделитель» в таблицу лексем;
• Add2KeysToList – добавление лексем типа «ключевое слово» и «разделитель» в таблицу лексем подряд.
Эти функции, по сути, являются реализацией функции, которая на графе переходов КА была обозначена F.
Еще две вспомогательные функции служат для упрощения кода. Они выполняют часто повторяющиеся действия в состояниях автомата, которые связаны со средними символами ключевых слов (в функции переходов эти состояния обозначены T2, T3, E2, E3, X2 и A2) и завершающими символами ключевых слов (в функции переходов эти состояния обозначены I2, T4, E4, O2, X3 и A3).
Построенный лексический анализатор обнаруживает три типа ошибок:
• неверный символ в лексеме (например, сочетания «2a» или «:6» будут признаны неверными символами в лексемах);
• незакрытый комментарий (присутствует открывающая фигурная скобка, но отсутствует соответствующая ей закрывающая);
• незавершенная лексема (в данном входном языке это может быть только символ «:» в конце входной программы, который будет воспринят как начало незавершенной лексемы «:=»).
Остальные ошибки входного языка должен обнаруживать синтаксический анализатор.
В качестве еще одной особенности реализации можно отметить, что переход с одной строки входного списка на другую должен восприниматься как граница текущей лексемы, так как одна лексема не может быть разбита на две строки – именно это и реализовано в конце цикла по символам текущей строки.
Текст программы распознавателя
Выводы по проделанной работе
Лабораторная работа № 3
Цель работы
Краткие теоретические сведения
Назначение синтаксического анализатора
Проблема распознавания цепочек КС-языков
Виды распознавателей для КС-языков
Реализация лексического анализатора
Разбиение на модули
Модули, реализующие лексический анализатор, разделены на две группы:• модули, программный код которых не зависит от входного языка;
• модули, программный код которых зависит от входного языка.
В первую группу входят модули:
• LexElem – описывает структуру данных элемента таблицы лексем;
• FormLab2 – описывает интерфейс с пользователем.
Во вторую группу входят модули:
• LexType – описывает типы входных лексем, связанные с ними наименования и текстовую информацию;
• LexAuto – реализует функционирование КА.
Такое разбиение на модули позволяет использовать те же самые структуры данных для организации лексического распознавателя при изменении входного языка.
Кроме этих модулей для реализации лабораторной работы № 2 используются также программные модули (TblElem и FncTree), позволяющие работать с комбинированной таблицей идентификаторов, которые были созданы при выполнении лабораторной работы № 1. Эти два модуля, очевидно, также не зависят от входного языка.
Кратко опишем содержание программных модулей, используемых для организации лексического анализатора.
Модуль типов лексем
Модуль LexType в детальных комментариях не нуждается. В нем перечислены все допустимые типы лексем (тип данных TLexType), каждой из которых соответствует наименование и обозначение лексемы. Вывод наименований лексем обеспечивает функция LexTypeName, а вывод обозначений – функция LexTypeInfo. Следует отметить, что кроме перечисленных в задании лексем используется еще одна дополнительная информационная лексема (LEXSTART), обозначающая конец строки.Модуль LexElem описывает структуры данных элемента таблицы лексем (TLexem) и самой таблицы лексем (TLexList), а также все, что с ними связано.
Модуль структур данных таблицы идентификаторов
Структура данных таблицы лексем содержит информацию о лексеме (поле LexInfo). В этом поле содержится тип лексемы (LexType), а также следующие данные:• VarInfo – ссылку на элемент таблицы идентификаторов для лексем типа «переменная»;
• ConstVal – целочисленное значение для лексем типа «константа»;
• szInfo – произвольная строка для информационной лексемы.
Для лексем других типов не требуется никакой дополнительной информации.
Следует отметить, что для лексем типа «переменная» хранится именно ссылка на таблицу идентификаторов, а не имя переменной. Именно для этого в данной лабораторной работе используются модули из лабораторной работы № 1. Для самого лексического анализатора не имеет значения, что хранить в таблице лексем – ссылку на таблицу идентификаторов со всей информацией о переменной или же только имя переменной. Но реализация лексического анализатора, при которой хранится именно ссылка на таблицу идентификаторов, чрезвычайно удобна для дальнейшей обработки данных, что будет очевидно в последующих работах (лабораторных работах № 3 и № 4). Поскольку лексический анализатор интересен не сам по себе, а в составе компилятора, такой подход принципиально важен.
Кроме этого в структуре данных элемента таблицы лексем хранится информация о позиции лексемы в тексте входной программы:
• iStr – номер строки, где встретилась лексема;
• iPos – позиция лексемы в строке;
• iAllP – позиция лексемы относительно начала входного файла.
Эта информация будет полезна, в частности, при информировании пользователя об ошибках.
Кроме этих данных структура содержит также:
• четыре конструктора для создания лексем четырех разных типов:
– CreateVar – для создания лексем типа «переменная»;
– CreateConst – для создания лексем типа «константа»;
– CreateInfo – для создания информационных лексем;
– CreateKey – для создания лексем других типов;
• деструктор Destroy для освобождения памяти, занятой лексемой (важен для информационных лексем);
• свойства и функции для доступа к информации о лексеме.
Хранить в структуре строку самой лексемы нет никакой необходимости (для переменных строка хранится в таблице идентификаторов, для других типов лексем она просто не нужна).
Сама таблица лексем (тип данных TLexList) построена на основе динамического массива TList из библиотеки VCL (модуль Classes) системы программирования Delphi 5.
Динамический массив типа TList обеспечивает все функции и данные, необходимые для хранения в памяти произвольного количества лексем (максимальное количество лексем ограничено только объемом доступной оперативной памяти). Для таблицы лексем TLexList дополнительно реализованы функции очистки таблицы, которые освобождают память, занятую лексемами, при их удалении из таблицы (функция Clear и деструктор Destroy), а также функция GetLexem и свойство Lexem, обеспечивающие удобный доступ к любой лексеме в таблице по ее индексу (порядковому номеру).
Модуль моделирования работы КА
Модуль LexAuto, моделирующий работу КА, на основе которого построен лексический распознаватель, – самый значительный по объему программного кода. Однако по содержанию программного кода он предельно прост. Этот модуль обеспечивает функционирование полного КА, фрагменты графа переходов которого были изображены на рис. 2.1 и 2.2, а функция переходов была построена выше.Главной составляющей этого программного модуля является функция МакеLexList, которая непосредственно моделирует работу КА. На вход функции подается входная программа в виде списка строк (формальный параметр listFile) и таблица лексем, куда должны помещаться найденные лексемы (формальный параметр listLex). Результатом работы функции является 0, если лексический анализ выполнен без ошибок, а если ошибка обнаружена – номер строки в исходном файле, в которой она присутствует. Для более подробной информации об обнаруженной ошибке функция создает информационную лексему и помещает ее в конец таблицы лексем. Сама информационная лексема кроме текстовой информации об ошибке содержит еще дополнительную информацию о ее местонахождении в исходной программе (смещение от начала файла и длина ошибочной лексемы).
В типе данных TAutoPos перечислены все возможные состояния КА. Перечень состояний полностью соответствует функции переходов КА.
Реализация функции MakeLexList, несмотря на большой объем программного кода, предельно проста. Она построена на основе двух вложенных циклов (первый – по строкам входного списка, второй – по символам в текущей строке), внутри которых находятся два уровня вложенных оператора выбора типа case – типичный подход к моделированию функционирования КА. Внешний оператор case выполняется по всем возможным состояниям автомата, а case второго уровня – по допустимым входным символам в каждом состоянии.
Можно обратить внимание на шесть вспомогательных функций:
• AddVarToList – добавление лексемы типа «переменная» в таблицу лексем;
• AddVarKeyToList – добавление лексем типа «переменная» и типа «разделитель» в таблицу лексем;
• AddConstToList – добавление лексемы типа «константа» в таблицу лексем;
• AddConstKeyToList – добавление лексем типа «константа» и типа «разделитель» в таблицу лексем;
• AddKeyToList – добавление лексемы типа «ключевое слово» или «разделитель» в таблицу лексем;
• Add2KeysToList – добавление лексем типа «ключевое слово» и «разделитель» в таблицу лексем подряд.
Эти функции, по сути, являются реализацией функции, которая на графе переходов КА была обозначена F.
Еще две вспомогательные функции служат для упрощения кода. Они выполняют часто повторяющиеся действия в состояниях автомата, которые связаны со средними символами ключевых слов (в функции переходов эти состояния обозначены T2, T3, E2, E3, X2 и A2) и завершающими символами ключевых слов (в функции переходов эти состояния обозначены I2, T4, E4, O2, X3 и A3).
Построенный лексический анализатор обнаруживает три типа ошибок:
• неверный символ в лексеме (например, сочетания «2a» или «:6» будут признаны неверными символами в лексемах);
• незакрытый комментарий (присутствует открывающая фигурная скобка, но отсутствует соответствующая ей закрывающая);
• незавершенная лексема (в данном входном языке это может быть только символ «:» в конце входной программы, который будет воспринят как начало незавершенной лексемы «:=»).
Остальные ошибки входного языка должен обнаруживать синтаксический анализатор.
В качестве еще одной особенности реализации можно отметить, что переход с одной строки входного списка на другую должен восприниматься как граница текущей лексемы, так как одна лексема не может быть разбита на две строки – именно это и реализовано в конце цикла по символам текущей строки.
Текст программы распознавателя
Кроме перечисленных выше модулей необходим еще модуль, обеспечивающий интерфейс с пользователем. Как и в лабораторной работе № 1, этот модуль (FormLab2) реализует графическое окно TLab2Form на основе класса TForm библиотеки VCL и включает в себя две составляющие:
• файл программного кода (файл FormLab2.pas);
• файл описания ресурсов пользовательского интерфейса (файл FormLab2.dfm).
Кроме описания интерфейсной формы и ее органов управления модуль FormLab2 содержит переменную (listLex), в которую записывается ссылка на таблицу лексем.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• многостраничную вкладку (PageControll) с двумя закладками (SheetFile и SheetLexems) под названиями «Исходный файл» и «Таблица лексем» соответственно;
• на закладке SheetFilе:
– поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
– многострочное поле для отображения прочитанного файла (Listldents);
• на закладке SheetLexems:
– сетка (GridLex) с тремя колонками для отображения данных о прочитанных лексемах;
• кнопка завершения работы с программой (BtnExit).
Внешний вид двух закладок этой формы приведен на рис. 2.3 и 2.4.
 Рис. 2.3. Внешний вид первой закладки интерфейсной формы для лабораторной работы № 2.
Рис. 2.3. Внешний вид первой закладки интерфейсной формы для лабораторной работы № 2.
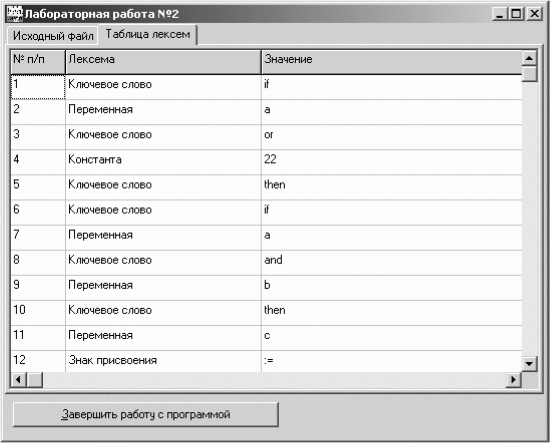 Рис. 2.4. Внешний вид второй закладки интерфейсной формы для лабораторной работы № 2.
Рис. 2.4. Внешний вид второй закладки интерфейсной формы для лабораторной работы № 2.
Чтение содержимого входного файла организовано точно так же, как в лабораторной работе № 1.
После чтения файла создается таблица лексем (ссылка на нее запоминается в переменной listLex) и вызывается функция MakeLexList, результат работы которой помещается во временную переменную iErr.
Если обнаружена ошибка, пользователю выдается сообщение об этом и указатель в списке строк позиционируется на место, где обнаружена ошибка.
Если ошибок не обнаружено, то на основании считанной таблицы лексем listLex заполняется сетка GridLex, которая очень удобна для наглядного представления таблицы лексем:
• первая колонка – порядковый номер лексемы;
• вторая колонка – тип лексемы (ее внешний вид);
• третья колонка – информация о лексеме.
Полный текст программного кода модуля интерфейса с пользователем приведен в листинге П2.4 в приложении 2, а описание ресурсов пользовательского интерфейса – в листинге П2.5 в приложении 2.
Полный текст всех программных модулей, реализующих рассмотренный пример для лабораторной работы № 2, приведен в приложении 2.
• файл программного кода (файл FormLab2.pas);
• файл описания ресурсов пользовательского интерфейса (файл FormLab2.dfm).
Кроме описания интерфейсной формы и ее органов управления модуль FormLab2 содержит переменную (listLex), в которую записывается ссылка на таблицу лексем.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• многостраничную вкладку (PageControll) с двумя закладками (SheetFile и SheetLexems) под названиями «Исходный файл» и «Таблица лексем» соответственно;
• на закладке SheetFilе:
– поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
– многострочное поле для отображения прочитанного файла (Listldents);
• на закладке SheetLexems:
– сетка (GridLex) с тремя колонками для отображения данных о прочитанных лексемах;
• кнопка завершения работы с программой (BtnExit).
Внешний вид двух закладок этой формы приведен на рис. 2.3 и 2.4.
Чтение содержимого входного файла организовано точно так же, как в лабораторной работе № 1.
После чтения файла создается таблица лексем (ссылка на нее запоминается в переменной listLex) и вызывается функция MakeLexList, результат работы которой помещается во временную переменную iErr.
Если обнаружена ошибка, пользователю выдается сообщение об этом и указатель в списке строк позиционируется на место, где обнаружена ошибка.
Если ошибок не обнаружено, то на основании считанной таблицы лексем listLex заполняется сетка GridLex, которая очень удобна для наглядного представления таблицы лексем:
• первая колонка – порядковый номер лексемы;
• вторая колонка – тип лексемы (ее внешний вид);
• третья колонка – информация о лексеме.
Полный текст программного кода модуля интерфейса с пользователем приведен в листинге П2.4 в приложении 2, а описание ресурсов пользовательского интерфейса – в листинге П2.5 в приложении 2.
Полный текст всех программных модулей, реализующих рассмотренный пример для лабораторной работы № 2, приведен в приложении 2.
Выводы по проделанной работе
В результате лабораторной работы № 2 построен лексический анализатор на основе конечного автомата. Построенный лексический анализатор позволяет выделять в тексте исходной программы лексемы следующих типов:
• ключевые слова (if, then, else, or, xor и and);
• идентификаторы (при этом в именах идентификаторов различаются строчные и прописные английские буквы);
• знак операции присваивания;
• целые десятичные константы без знака;
• разделители (круглые скобки и точка с запятой).
Лексический анализатор игнорирует в тексте входной программы пробелы, знаки табуляции и переводы строки, а также комментарии, выделенные фигурными скобками.
В случае обнаружения неверной лексемы (например числа, содержащего букву), незакрытого комментария или незавершенной лексемы (такой лексемой может быть только символ «:») лексический анализатор выдает сообщение об ошибке и прекращает дальнейший анализ. При наличии нескольких неверных лексем анализатор обнаруживает только первую из них.
Результатом выполнения лексического анализа является структура данных, которая представляет таблицу лексем. Построенный лексический анализатор предназначен для подготовки данных, необходимых для выполнения следующих лабораторных работ, связанных с синтаксическим анализом и генерацией кода.
• ключевые слова (if, then, else, or, xor и and);
• идентификаторы (при этом в именах идентификаторов различаются строчные и прописные английские буквы);
• знак операции присваивания;
• целые десятичные константы без знака;
• разделители (круглые скобки и точка с запятой).
Лексический анализатор игнорирует в тексте входной программы пробелы, знаки табуляции и переводы строки, а также комментарии, выделенные фигурными скобками.
В случае обнаружения неверной лексемы (например числа, содержащего букву), незакрытого комментария или незавершенной лексемы (такой лексемой может быть только символ «:») лексический анализатор выдает сообщение об ошибке и прекращает дальнейший анализ. При наличии нескольких неверных лексем анализатор обнаруживает только первую из них.
Результатом выполнения лексического анализа является структура данных, которая представляет таблицу лексем. Построенный лексический анализатор предназначен для подготовки данных, необходимых для выполнения следующих лабораторных работ, связанных с синтаксическим анализом и генерацией кода.
Лабораторная работа № 3
Построение простейшего дерева вывода
Цель работы
Цель работы: изучение основных понятий теории грамматик простого и операторного предшествования, ознакомление с алгоритмами синтаксического анализа (разбора) для некоторых классов КС-грамматик, получение практических навыков создания простейшего синтаксического анализатора для заданной грамматики операторного предшествования.
Краткие теоретические сведения
Назначение синтаксического анализатора
По иерархии грамматик Хомского выделяют четыре основные группы языков (и описывающих их грамматик) [1, 3, 4, 7]. При этом наибольший интерес представляют регулярные и контекстно-свободные (КС) грамматики и языки. Они используются при описании синтаксиса языков программирования. С помощью регулярных грамматик можно описать лексемы языка – идентификаторы, константы, служебные слова и прочие. На основе КС-грамматик строятся более крупные синтаксические конструкции: описания типов и переменных, арифметические и логические выражения, управляющие операторы и, наконец, полностью вся программа на входном языке.
Входные цепочки регулярных языков распознаются с помощью конечных автоматов (КА). Они лежат в основе сканеров, выполняющих лексический анализ и выделение слов в тексте программы на входном языке. Результатом работы сканера является преобразование исходной программы в список или таблицу лексем. Дальнейшую ее обработку выполняет другая часть компилятора – синтаксический анализатор. Его работа основана на использовании правил КС-грамматики, описывающих конструкции исходного языка.
Синтаксический анализатор (синтаксический разборщик) – это часть компилятора, которая отвечает за выявление и проверку синтаксических конструкций входного языка. В задачу синтаксического анализатора входит:
• найти и выделить синтаксические конструкции в тексте исходной программы;
• установить тип и проверить правильность каждой синтаксической конструкции;
• представить синтаксические конструкции в виде, удобном для дальнейшей генерации текста результирующей программы.
Синтаксический анализатор – это основная часть компилятора на этапе анализа. Без выполнения синтаксического разбора работа компилятора бессмысленна, в то время как лексический разбор, в принципе, не является обязательной фазой компиляции. Все задачи по проверке синтаксиса входного языка могут быть решены на этапе синтаксического разбора. Лексический анализатор только позволяет избавить сложный по структуре синтаксический анализатор от решения примитивных задач по выявлению и запоминанию лексем исходной программы.
Выходом лексического анализатора является таблица лексем. Эта таблица образует вход синтаксического анализатора, который исследует только один компонент каждой лексемы – ее тип. Остальная информация о лексемах используется на более поздних фазах компиляции при семантическом анализе, подготовке к генерации и генерации кода результирующей программы.
Синтаксический анализатор воспринимает выход лексического анализатора и разбирает его в соответствии с грамматикой входного языка. Однако в грамматике входного языка программирования обычно не уточняется, какие конструкции следует считать лексемами. Примерами конструкций, которые обычно распознаются во время лексического анализа, служат ключевые слова, константы и идентификаторы. Но эти же конструкции могут распознаваться и синтаксическим анализатором. На практике не существует жесткого правила, определяющего, какие конструкции должны распознаваться на лексическом уровне, а какие надо оставлять синтаксическому анализатору. Обычно это определяет разработчик компилятора исходя из технологических аспектов программирования, а также синтаксиса и семантики входного языка. Принципы взаимодействия лексического и синтаксического анализаторов были рассмотрены в лабораторной работе № 2.
В основе синтаксического анализатора лежит распознаватель текста исходной программы, построенный на основе грамматики входного языка. Как правило, синтаксические конструкции языков программирования могут быть описаны с помощью КС-грамматик; реже встречаются языки, которые могут быть описаны с помощью регулярных грамматик.
Главную роль в том, как функционирует синтаксический анализатор и какой алгоритм лежит в его основе, играют принципы построения распознавателей для КС-языков. Без применения этих принципов невозможно выполнить эффективный синтаксический разбор предложений входного языка.
Входные цепочки регулярных языков распознаются с помощью конечных автоматов (КА). Они лежат в основе сканеров, выполняющих лексический анализ и выделение слов в тексте программы на входном языке. Результатом работы сканера является преобразование исходной программы в список или таблицу лексем. Дальнейшую ее обработку выполняет другая часть компилятора – синтаксический анализатор. Его работа основана на использовании правил КС-грамматики, описывающих конструкции исходного языка.
Синтаксический анализатор (синтаксический разборщик) – это часть компилятора, которая отвечает за выявление и проверку синтаксических конструкций входного языка. В задачу синтаксического анализатора входит:
• найти и выделить синтаксические конструкции в тексте исходной программы;
• установить тип и проверить правильность каждой синтаксической конструкции;
• представить синтаксические конструкции в виде, удобном для дальнейшей генерации текста результирующей программы.
Синтаксический анализатор – это основная часть компилятора на этапе анализа. Без выполнения синтаксического разбора работа компилятора бессмысленна, в то время как лексический разбор, в принципе, не является обязательной фазой компиляции. Все задачи по проверке синтаксиса входного языка могут быть решены на этапе синтаксического разбора. Лексический анализатор только позволяет избавить сложный по структуре синтаксический анализатор от решения примитивных задач по выявлению и запоминанию лексем исходной программы.
Выходом лексического анализатора является таблица лексем. Эта таблица образует вход синтаксического анализатора, который исследует только один компонент каждой лексемы – ее тип. Остальная информация о лексемах используется на более поздних фазах компиляции при семантическом анализе, подготовке к генерации и генерации кода результирующей программы.
Синтаксический анализатор воспринимает выход лексического анализатора и разбирает его в соответствии с грамматикой входного языка. Однако в грамматике входного языка программирования обычно не уточняется, какие конструкции следует считать лексемами. Примерами конструкций, которые обычно распознаются во время лексического анализа, служат ключевые слова, константы и идентификаторы. Но эти же конструкции могут распознаваться и синтаксическим анализатором. На практике не существует жесткого правила, определяющего, какие конструкции должны распознаваться на лексическом уровне, а какие надо оставлять синтаксическому анализатору. Обычно это определяет разработчик компилятора исходя из технологических аспектов программирования, а также синтаксиса и семантики входного языка. Принципы взаимодействия лексического и синтаксического анализаторов были рассмотрены в лабораторной работе № 2.
В основе синтаксического анализатора лежит распознаватель текста исходной программы, построенный на основе грамматики входного языка. Как правило, синтаксические конструкции языков программирования могут быть описаны с помощью КС-грамматик; реже встречаются языки, которые могут быть описаны с помощью регулярных грамматик.
Главную роль в том, как функционирует синтаксический анализатор и какой алгоритм лежит в его основе, играют принципы построения распознавателей для КС-языков. Без применения этих принципов невозможно выполнить эффективный синтаксический разбор предложений входного языка.
Проблема распознавания цепочек КС-языков
Взаимодействие лексического и синтаксического анализаторов рассматривалось в предыдущей лабораторной работе, здесь же будут рассмотрены алгоритмы, лежащие в основе синтаксического анализа. Перед синтаксическим анализатором стоят две основные задачи: проверить правильность конструкций программы, которая представляется в виде уже выделенных слов входного языка, и преобразовать ее в вид, удобный для дальнейшей семантической (смысловой) обработки и генерации кода. Одним из способов такого представления является дерево синтаксического разбора.
Основой для построения распознавателей КС-языков являются автоматы с магазинной памятью – МП-автоматы – односторонние недетерминированные распознаватели с линейно-ограниченной магазинной памятью (полная классификация распознавателей приведена в [1, 4, 3, 7]). Поэтому важно рассмотреть, как функционирует МП-автомат и как для КС-языков решается задача разбора – построение распознавателя языка на основе заданной грамматики. Далее рассмотрены технические аспекты, связанные с реализацией синтаксических анализаторов.
МП-автомат в отличие от обычного КА имеет стек (магазин), в который можно помещать специальные «магазинные» символы (обычно это терминальные и нетерминальные символы грамматики языка). Переход МП-автомата из одного состояния в другое зависит не только от входного символа, но и от одного или нескольких верхних символов стека. Таким образом, конфигурация автомата определяется тремя параметрами: состоянием автомата, текущим символом входной цепочки (положением указателя в цепочке) и содержимым стека.
При выполнении перехода МП-автомата из одной конфигурации в другую из стека удаляются верхние символы, соответствующие условию перехода, и добавляется цепочка, соответствующая правилу перехода. Первый символ цепочки становится верхушкой стека. Допускаются переходы, при которых входной символ игнорируется (и тем самым он будет входным символом при следующем переходе). Эти переходы называются ^-переходами. Если при окончании цепочки автомат находится в одном из заданных конечных состояний, а стек пуст, цепочка считается принятой (после окончания цепочки могут быть сделаны Х-переходы). Иначе цепочка символов не принимается.
МП-автомат называется недетерминированным, если при одной и той же его конфигурации возможен более чем один переход. В противном случае (если из любой конфигурации МП-автомата по любому входному символу возможно не более одного перехода в следующую конфигурацию) МП-автомат считается детерминированным (ДМП-автоматом). ДМП-автоматы задают класс детерминированных КС-языков, для которых существуют однозначные КС-грамматики. Именно этот класс языков лежит в основе синтаксических конструкций всех языков программирования, так как любая синтаксическая конструкция языка программирования должна допускать только однозначную трактовку [1–4, 7].
По произвольной КС-грамматике
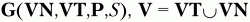 всегда можно построить недетерминированный МП-автомат, который допускает цепочки языка, заданного этой грамматикой [1–3, 7]. А на основе этого МП-автомата можно создать распознаватель для заданного языка.
всегда можно построить недетерминированный МП-автомат, который допускает цепочки языка, заданного этой грамматикой [1–3, 7]. А на основе этого МП-автомата можно создать распознаватель для заданного языка.
Однако при алгоритмической реализации функционирования такого распознавателя могут возникнуть проблемы. Дело в том, что построенный МП-автомат будет, как правило, недетерминированным, а для МП-автоматов, в отличие от обычных КА, не существует алгоритма, который позволял бы преобразовать произвольный МП-автомат в ДМП-автомат. Поэтому программирование функционирования МП-автомата – нетривиальная задача. Если моделировать его функционирование по шагам с перебором всех возможных состояний, то может оказаться, что построенный для тривиального МП-автомата алгоритм никогда не завершится на конечной входной цепочке символов при определенных условиях. Примеры таких МП-автоматов можно найти в [1, 3, 7].
Поэтому для построения распознавателя для языка, заданного КС-грамматикой, рекомендуется воспользоваться соответствующим математическим аппаратом и одним из существующих алгоритмов.
Основой для построения распознавателей КС-языков являются автоматы с магазинной памятью – МП-автоматы – односторонние недетерминированные распознаватели с линейно-ограниченной магазинной памятью (полная классификация распознавателей приведена в [1, 4, 3, 7]). Поэтому важно рассмотреть, как функционирует МП-автомат и как для КС-языков решается задача разбора – построение распознавателя языка на основе заданной грамматики. Далее рассмотрены технические аспекты, связанные с реализацией синтаксических анализаторов.
МП-автомат в отличие от обычного КА имеет стек (магазин), в который можно помещать специальные «магазинные» символы (обычно это терминальные и нетерминальные символы грамматики языка). Переход МП-автомата из одного состояния в другое зависит не только от входного символа, но и от одного или нескольких верхних символов стека. Таким образом, конфигурация автомата определяется тремя параметрами: состоянием автомата, текущим символом входной цепочки (положением указателя в цепочке) и содержимым стека.
При выполнении перехода МП-автомата из одной конфигурации в другую из стека удаляются верхние символы, соответствующие условию перехода, и добавляется цепочка, соответствующая правилу перехода. Первый символ цепочки становится верхушкой стека. Допускаются переходы, при которых входной символ игнорируется (и тем самым он будет входным символом при следующем переходе). Эти переходы называются ^-переходами. Если при окончании цепочки автомат находится в одном из заданных конечных состояний, а стек пуст, цепочка считается принятой (после окончания цепочки могут быть сделаны Х-переходы). Иначе цепочка символов не принимается.
МП-автомат называется недетерминированным, если при одной и той же его конфигурации возможен более чем один переход. В противном случае (если из любой конфигурации МП-автомата по любому входному символу возможно не более одного перехода в следующую конфигурацию) МП-автомат считается детерминированным (ДМП-автоматом). ДМП-автоматы задают класс детерминированных КС-языков, для которых существуют однозначные КС-грамматики. Именно этот класс языков лежит в основе синтаксических конструкций всех языков программирования, так как любая синтаксическая конструкция языка программирования должна допускать только однозначную трактовку [1–4, 7].
По произвольной КС-грамматике
Однако при алгоритмической реализации функционирования такого распознавателя могут возникнуть проблемы. Дело в том, что построенный МП-автомат будет, как правило, недетерминированным, а для МП-автоматов, в отличие от обычных КА, не существует алгоритма, который позволял бы преобразовать произвольный МП-автомат в ДМП-автомат. Поэтому программирование функционирования МП-автомата – нетривиальная задача. Если моделировать его функционирование по шагам с перебором всех возможных состояний, то может оказаться, что построенный для тривиального МП-автомата алгоритм никогда не завершится на конечной входной цепочке символов при определенных условиях. Примеры таких МП-автоматов можно найти в [1, 3, 7].
Поэтому для построения распознавателя для языка, заданного КС-грамматикой, рекомендуется воспользоваться соответствующим математическим аппаратом и одним из существующих алгоритмов.
Виды распознавателей для КС-языков
Существуют несложные преобразования КС-грамматик, выполнение которых гарантирует, что построенный на основе преобразованной грамматики МП-автомат можно будет промоделировать за конечное время на основе конечных вычислительных ресурсов. Описание сути и алгоритмов этих преобразований можно найти в [1, 3, 7].
Эти преобразования позволяют строить два основных типа простейших распознавателей:
• распознаватель с подбором альтернатив;
• распознаватель на основе алгоритма «сдвиг-свертка».
Работу распознавателя с подбором альтернатив можно неформально описать следующим образом: если на верхушке стека МП-автомата находится нетерминальный символ A, то его можно заменить на цепочку символов а при условии, что в грамматике языка есть правило A → а, не сдвигая при этом считывающую головку автомата (этот шаг работы называется «подбор альтернативы»); если же на верхушке стека находится терминальный символ a, который совпадает с текущим символом входной цепочки, то этот символ можно выбросить из стека и передвинуть считывающую головку на одну позицию вправо (этот шаг работы называется «выброс»). Данный МП-автомат может быть недетерминированным, поскольку при подборе альтернативы в грамматике языка может оказаться более одного правила вида A → а, тогда функция δ(q,λ,A) будет содержать более одного следующего состояния – у МП-автомата будет несколько альтернатив.
Решение о том, выполнять ли на каждом шаге работы МП-автомата выброс или подбор альтернативы, принимается однозначно. Моделирующий алгоритм должен обеспечивать выбор одной из возможных альтернатив и хранение информации о том, какие альтернативы на каком шаге уже были выбраны, чтобы иметь возможность вернуться к этому шагу и подобрать другие альтернативы.
Распознаватель с подбором альтернатив является нисходящим распознавателем: он читает входную цепочку символов слева направо и строит левосторонний вывод. Название «нисходящий» дано ему потому, что дерево вывода в этом случае следует строить сверху вниз, от корня к концевым вершинам («листьям»).[3]
Эти преобразования позволяют строить два основных типа простейших распознавателей:
• распознаватель с подбором альтернатив;
• распознаватель на основе алгоритма «сдвиг-свертка».
Работу распознавателя с подбором альтернатив можно неформально описать следующим образом: если на верхушке стека МП-автомата находится нетерминальный символ A, то его можно заменить на цепочку символов а при условии, что в грамматике языка есть правило A → а, не сдвигая при этом считывающую головку автомата (этот шаг работы называется «подбор альтернативы»); если же на верхушке стека находится терминальный символ a, который совпадает с текущим символом входной цепочки, то этот символ можно выбросить из стека и передвинуть считывающую головку на одну позицию вправо (этот шаг работы называется «выброс»). Данный МП-автомат может быть недетерминированным, поскольку при подборе альтернативы в грамматике языка может оказаться более одного правила вида A → а, тогда функция δ(q,λ,A) будет содержать более одного следующего состояния – у МП-автомата будет несколько альтернатив.
Решение о том, выполнять ли на каждом шаге работы МП-автомата выброс или подбор альтернативы, принимается однозначно. Моделирующий алгоритм должен обеспечивать выбор одной из возможных альтернатив и хранение информации о том, какие альтернативы на каком шаге уже были выбраны, чтобы иметь возможность вернуться к этому шагу и подобрать другие альтернативы.
Распознаватель с подбором альтернатив является нисходящим распознавателем: он читает входную цепочку символов слева направо и строит левосторонний вывод. Название «нисходящий» дано ему потому, что дерево вывода в этом случае следует строить сверху вниз, от корня к концевым вершинам («листьям»).[3]
Конец бесплатного ознакомительного фрагмента