Второй по важности индикатор состояния очереди в ЦОВ – максимальные задержки при ответе на вызовы. Их надо тщательно исследовать – как по значениям, так и по частоте. Ведь именно эти «пики» и есть самая неприятная вещь в колл-центре и для клиентов (долгое ожидание), и для операторов (работа на уровне перегрузки), и для менеджеров (потеря управляемости ЦОВ).
Во время аудита операторских центров мне иногда приходилось сталкиваться на первый взгляд с парадоксом: среднее время ожидания – вполне пристойное (меньше минуты), но число потерянных вызовов неоправданно велико. Проверяю максимальные задержки при ответе – и точно, их значения зашкаливают.
Но и этого мало. При изучении времени ожидания в очереди необходимо исследовать и так называемый «профиль вызовов», который показывает распределение обслуженных и потерянных вызовов по временным интервалам. Если толково задать эти самые временные интервалы, то из отчета о профиле вызовов можно извлечь очень важную информацию.
Давайте посмотрим на следующем примере, как можно использовать профиль вызовов. Предположим, в течение дня он выглядит таким образом (табл. 3.1).
Средняя скорость ответа – меньше 30 секунд. Казалось бы, неплохо. Однако мы видим, что, хотя большинство вызовов (330 из 532) получили ответ в течение 15 секунд, 202 вызова, т. е. почти 38 %, ждали обслуживания гораздо дольше. Причем 15 % провели в очереди более 1,5 минуты! А самые стойкие 4 % прождали более 5 минут.
Таблица 3.1. Пример профиля вызовов

Почему же возникают такие «провалы» в обслуживании? Конечно, из-за перегрузок в операторском центре. Поэтому так важно их не допускать. Именно не допускать, предупреждать само появление перегрузок, а не бороться с ними по мере их возникновения.
Предвижу ваш резонный вопрос: почему в профессионально работающем, хорошо отлаженном операторском центре (а ведь к этому все и стремятся, не так ли?) могут вообще возникать перегрузки? По двум причинам. Я бы условно назвала их объективной (внешней) и субъективной (внутренней).
Объективная (внешняя) причина заключается в том, что, как мы уже говорили, в операторский центр вызовы никогда не поступают равномерно, поэтому в течение дня, недели или сезона обязательно будут возникать пиковые нагрузки. Иногда их можно предсказать (объявление маркетинговой кампании, сезон гриппа) – и тогда они в какой-то мере перестают быть пиковыми, а иногда нельзя (сбой в системе, экстренная ситуация, даже непредсказуемое поведение и предпочтения абонентов) – и тогда они носят классический пиковый характер.
Субъективная (внутренняя) причина возникновения перегрузок обусловлена человеческим фактором в самом Центре обслуживания вызовов (как говаривали в позабытые нынче времена Никиты Сергеевича Хрущева – «волюнтаризмом»). Вдруг возникает момент, когда по какой-либо причине начинает ощущаться острая нехватка операторов: кто-то ушел на обед (хотя в большинстве ЦОВ это время регламентировано), у кого-то заболел зуб, у кого-то прихватило желудок, кому-то именно в это время позвонили по личному вопросу и т. д.
Особенно часто такую картину можно наблюдать в небольших операторских центрах.
Со всеми перегрузками, вызванными как объективными, так и, тем более, субъективными причинами, можно и нужно бороться. Конечно, мы не можем влиять на все семь факторов, определяющих поведение вызывающих абонентов, но тем не менее многое в наших руках. Оставив в стороне вопросы планирования ресурсов и поддержания дисциплины (об этом мы подробно поговорим в главе 11), рассмотрим способы управления ЦОВ на основе метода, предсказывающего расчетное время ожидания в очереди.
Расчетное время ожидания в очереди
Расчет времени ожидания на основе хронологических данных
Расчет времени ожидания на основе оперативной ситуации
Расчет времени ожидания на основе одновременного анализа хронологических и оперативных данных
Целесообразность использования расчетного времени ожидания
Расчетное время ожидания на уровне группы и на уровне вызова
Факторы, влияющие на расчетное время ожидания
Глава 4
Базовые алгоритмы маршрутизации
«Первый свободный», или «Горячее место»
«Наиболее свободный»
Маршрутизация на основе квалификации операторов
Во время аудита операторских центров мне иногда приходилось сталкиваться на первый взгляд с парадоксом: среднее время ожидания – вполне пристойное (меньше минуты), но число потерянных вызовов неоправданно велико. Проверяю максимальные задержки при ответе – и точно, их значения зашкаливают.
Но и этого мало. При изучении времени ожидания в очереди необходимо исследовать и так называемый «профиль вызовов», который показывает распределение обслуженных и потерянных вызовов по временным интервалам. Если толково задать эти самые временные интервалы, то из отчета о профиле вызовов можно извлечь очень важную информацию.
Давайте посмотрим на следующем примере, как можно использовать профиль вызовов. Предположим, в течение дня он выглядит таким образом (табл. 3.1).
Средняя скорость ответа – меньше 30 секунд. Казалось бы, неплохо. Однако мы видим, что, хотя большинство вызовов (330 из 532) получили ответ в течение 15 секунд, 202 вызова, т. е. почти 38 %, ждали обслуживания гораздо дольше. Причем 15 % провели в очереди более 1,5 минуты! А самые стойкие 4 % прождали более 5 минут.
Таблица 3.1. Пример профиля вызовов
Почему же возникают такие «провалы» в обслуживании? Конечно, из-за перегрузок в операторском центре. Поэтому так важно их не допускать. Именно не допускать, предупреждать само появление перегрузок, а не бороться с ними по мере их возникновения.
Предвижу ваш резонный вопрос: почему в профессионально работающем, хорошо отлаженном операторском центре (а ведь к этому все и стремятся, не так ли?) могут вообще возникать перегрузки? По двум причинам. Я бы условно назвала их объективной (внешней) и субъективной (внутренней).
Объективная (внешняя) причина заключается в том, что, как мы уже говорили, в операторский центр вызовы никогда не поступают равномерно, поэтому в течение дня, недели или сезона обязательно будут возникать пиковые нагрузки. Иногда их можно предсказать (объявление маркетинговой кампании, сезон гриппа) – и тогда они в какой-то мере перестают быть пиковыми, а иногда нельзя (сбой в системе, экстренная ситуация, даже непредсказуемое поведение и предпочтения абонентов) – и тогда они носят классический пиковый характер.
Субъективная (внутренняя) причина возникновения перегрузок обусловлена человеческим фактором в самом Центре обслуживания вызовов (как говаривали в позабытые нынче времена Никиты Сергеевича Хрущева – «волюнтаризмом»). Вдруг возникает момент, когда по какой-либо причине начинает ощущаться острая нехватка операторов: кто-то ушел на обед (хотя в большинстве ЦОВ это время регламентировано), у кого-то заболел зуб, у кого-то прихватило желудок, кому-то именно в это время позвонили по личному вопросу и т. д.
Особенно часто такую картину можно наблюдать в небольших операторских центрах.
Со всеми перегрузками, вызванными как объективными, так и, тем более, субъективными причинами, можно и нужно бороться. Конечно, мы не можем влиять на все семь факторов, определяющих поведение вызывающих абонентов, но тем не менее многое в наших руках. Оставив в стороне вопросы планирования ресурсов и поддержания дисциплины (об этом мы подробно поговорим в главе 11), рассмотрим способы управления ЦОВ на основе метода, предсказывающего расчетное время ожидания в очереди.
Расчетное время ожидания в очереди
Имея в своем распоряжении такой важный параметр, как расчетное время ожидания в очереди, можно в значительной мере повысить эффективность обслуживания вызовов за счет:
• объявления клиенту о том, сколько он может прождать в очереди (подробнее об этом мы говорили выше). Гораздо предпочтительнее, чтобы в случае резко возросшего расчетного времени ожидания в момент пиковой нагрузки (например, 3 минуты и более) клиенты вешали трубку и перезванивали позже, а не бесконечно «висели» на линии;
• прямого вмешательства супервизора,
• автоматической перенастройки системы.
Вручную супервизор может предупредить пиковые нагрузки следующим простым способом: увидев, что в одной из операторских групп расчетное время ожидания приближается к опасной черте, а в другой равно нулю или чрезвычайно мало, он может просто перебросить операторов из второй группы в первую и таким образом сократить время ожидания в проблемной группе. В небольшом Сall Center супервизор может также проверить, по какой причине его подчиненные ушли на перерыв, и, если это возможно, попросить их вернуться на рабочее место.
Конечно, приведенная картина весьма схематична, в жизни все гораздо сложнее (например, см. главу 5), но все же подход описан верно.
Гораздо эффективнее, если система сама сможет перенастраиваться, т. е. выбирать оптимальный алгоритм обслуживания в зависимости от расчетного времени ожидания. Например, она может сравнить несколько операторских групп по этому параметру и направить вызов в ту, у которой такое время минимально.
Причем заметьте: и супервизор, и система анализируют не реальное, текущее, а расчетное, предполагаемое время ожидания. Таким образом, возникает очень ценная возможность проактивных, а не реактивных действий. Иными словами, можно не ждать возникновения проблем, а попытаться их предотвратить.
Но именно в том, что приходится оперировать не реальным, а только предполагаемым временем ожидания, и заключается вся сложность. Ведь длительность ожидания в очереди в каждый момент зависит от множества труднопредсказуемых составляющих: поведения вызывающих абонентов, длительности разговоров, даже, наконец, поведения и производительности операторов (хотя как раз в последнем случае прогноз сделать легче).
Как наиболее точно рассчитать предполагаемое время ожидания? Ведь чем точнее оно будет рассчитано, тем эффективнее будет управление операторским центром и, следовательно, тем эффективнее будут выбраны алгоритмы обслуживания.
Существуют три основных подхода к определению расчетного времени ожидания:
• на основе анализа хронологических данных;
• на основе анализа текущей производительности;
• на основе комбинирования оперативных и хронологических данных.
• объявления клиенту о том, сколько он может прождать в очереди (подробнее об этом мы говорили выше). Гораздо предпочтительнее, чтобы в случае резко возросшего расчетного времени ожидания в момент пиковой нагрузки (например, 3 минуты и более) клиенты вешали трубку и перезванивали позже, а не бесконечно «висели» на линии;
• прямого вмешательства супервизора,
• автоматической перенастройки системы.
Вручную супервизор может предупредить пиковые нагрузки следующим простым способом: увидев, что в одной из операторских групп расчетное время ожидания приближается к опасной черте, а в другой равно нулю или чрезвычайно мало, он может просто перебросить операторов из второй группы в первую и таким образом сократить время ожидания в проблемной группе. В небольшом Сall Center супервизор может также проверить, по какой причине его подчиненные ушли на перерыв, и, если это возможно, попросить их вернуться на рабочее место.
Конечно, приведенная картина весьма схематична, в жизни все гораздо сложнее (например, см. главу 5), но все же подход описан верно.
Гораздо эффективнее, если система сама сможет перенастраиваться, т. е. выбирать оптимальный алгоритм обслуживания в зависимости от расчетного времени ожидания. Например, она может сравнить несколько операторских групп по этому параметру и направить вызов в ту, у которой такое время минимально.
Причем заметьте: и супервизор, и система анализируют не реальное, текущее, а расчетное, предполагаемое время ожидания. Таким образом, возникает очень ценная возможность проактивных, а не реактивных действий. Иными словами, можно не ждать возникновения проблем, а попытаться их предотвратить.
Но именно в том, что приходится оперировать не реальным, а только предполагаемым временем ожидания, и заключается вся сложность. Ведь длительность ожидания в очереди в каждый момент зависит от множества труднопредсказуемых составляющих: поведения вызывающих абонентов, длительности разговоров, даже, наконец, поведения и производительности операторов (хотя как раз в последнем случае прогноз сделать легче).
Как наиболее точно рассчитать предполагаемое время ожидания? Ведь чем точнее оно будет рассчитано, тем эффективнее будет управление операторским центром и, следовательно, тем эффективнее будут выбраны алгоритмы обслуживания.
Существуют три основных подхода к определению расчетного времени ожидания:
• на основе анализа хронологических данных;
• на основе анализа текущей производительности;
• на основе комбинирования оперативных и хронологических данных.
Расчет времени ожидания на основе хронологических данных
Методы, основанные на анализе хронологических данных за какой-то интервал времени, например за последние полчаса, оперируют такими показателями, как средняя скорость ответа, заданный уровень обслуживания и т. п. Давайте рассмотрим подробнее распространенный метод Average Speed of Answer (ASA), основанный на определении средней скорости ответа за какой-либо отрезок времени, чаще всего – за последние полчаса. Схематично это выглядит так.
Предположим, в операторский центр поступил вызов определенного типа. Система определяет, что среднее время ожидания для вызовов данного типа за последние полчаса составило 2 минуты, поэтому она экстраполирует этот показатель и на вновь поступивший вызов и прогнозирует, что он тоже прождет 2 минуты. Через каждые полчаса показатель ASA снова пересчитывается.
Такая схема вполне работоспособна, но лишь в случае постоянной равномерной нагрузки. Однако, как мы уже не раз говорили, для операторского центра такое положение вещей – идеальное и потому недостижимое. А как только происходит скачкообразное нарастание потока вызовов, любой метод, основанный на анализе не текущей, а уже прошедшей ситуации, начинает буксовать. Ведь оперативная ситуация резко изменилась и оказалась достаточно далека от той, что была 10, а тем более 20 минут назад. И чем дальше, тем больше расчетное время ожидания расходится с реальным.
Схематично данный процесс показан на рисунке 3.4.
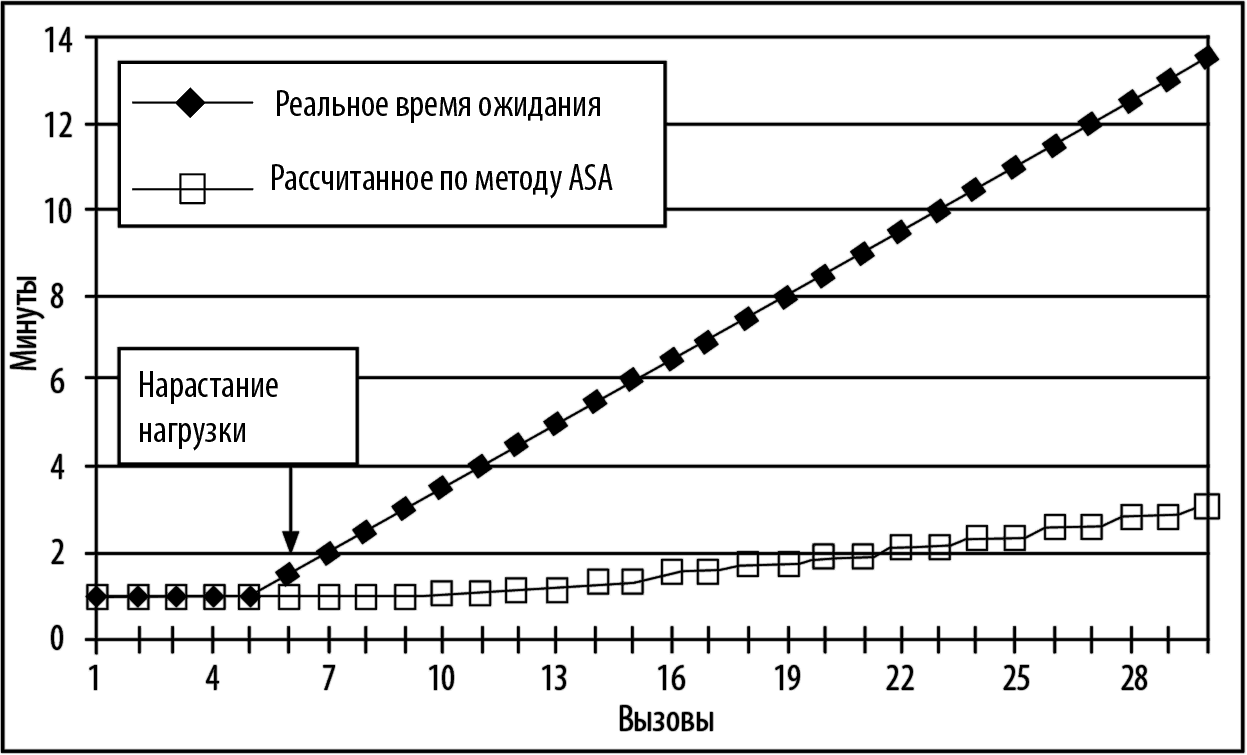 Рис. 3.4. Графики реального и расчетного времени ожидания, определенные по методу ASA
Рис. 3.4. Графики реального и расчетного времени ожидания, определенные по методу ASA
Из приведенного графика видно, сколь неточно работает данная методика. Например, уже для 30-го звонка предполагаемое время ожидания, рассчитанное по методу ASA, может составить 3 минуты, в то время как в действительности оно будет равно 13 минутам. Разве можно принимать адекватные решения, базируясь на такой недостоверной информации?
Предположим, в операторский центр поступил вызов определенного типа. Система определяет, что среднее время ожидания для вызовов данного типа за последние полчаса составило 2 минуты, поэтому она экстраполирует этот показатель и на вновь поступивший вызов и прогнозирует, что он тоже прождет 2 минуты. Через каждые полчаса показатель ASA снова пересчитывается.
Такая схема вполне работоспособна, но лишь в случае постоянной равномерной нагрузки. Однако, как мы уже не раз говорили, для операторского центра такое положение вещей – идеальное и потому недостижимое. А как только происходит скачкообразное нарастание потока вызовов, любой метод, основанный на анализе не текущей, а уже прошедшей ситуации, начинает буксовать. Ведь оперативная ситуация резко изменилась и оказалась достаточно далека от той, что была 10, а тем более 20 минут назад. И чем дальше, тем больше расчетное время ожидания расходится с реальным.
Схематично данный процесс показан на рисунке 3.4.
Из приведенного графика видно, сколь неточно работает данная методика. Например, уже для 30-го звонка предполагаемое время ожидания, рассчитанное по методу ASA, может составить 3 минуты, в то время как в действительности оно будет равно 13 минутам. Разве можно принимать адекватные решения, базируясь на такой недостоверной информации?
Расчет времени ожидания на основе оперативной ситуации
При использовании методов, основанных на анализе производительности в данный момент времени, оперируют такими показателями, как число вызовов в очереди, время, которое провел в очереди самый ранний вызов, и т. п. Метод, построенный на анализе времени ожидания самого раннего вызова (Oldest Call Waiting, OCW), является наиболее популярным. Давайте рассмотрим его подробнее.
Предположим, в операторский центр поступил вызов определенного типа. Система определяет, что к данному моменту самый ранний вызов этого типа уже ожидает в очереди 2 минуты, поэтому она экстраполирует данный показатель и на вновь прибывший вызов, прогнозируя, что он тоже прождет 2 минуты.
На первый взгляд неплохая схема, но тоже лишь в случае равномерной нагрузки. Если она становится пиковой, использование этого метода дает неточные результаты.
Дело в том, что он основан на следующем предположении: вызов, стоящий в очереди самым последним, будет ждать обслуживания столько же, сколько и самый первый. Но за то время, пока этот последний вызов доберется до начала очереди, может произойти множество изменений, например в числе работающих операторов, количестве вызовов в очереди, времени обслуживания вызова и т. д. Поэтому чем длиннее очередь, тем хуже работает метод OCW.
Схематично данный процесс показан на рисунке 3.5.
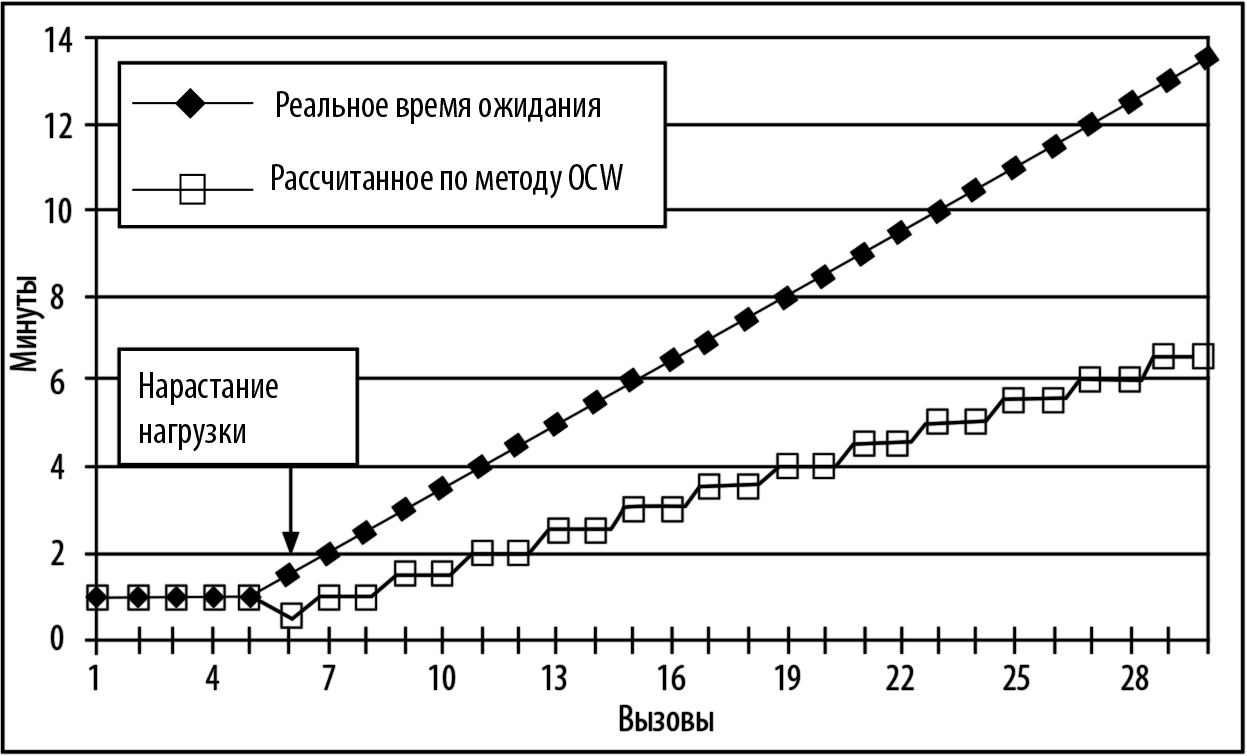 Рис. 3.5. Графики реального и расчетного времени ожидания, определенные по методу OCW
Рис. 3.5. Графики реального и расчетного времени ожидания, определенные по методу OCW
Из приведенного графика видно, что хотя метод, основанный на анализе оперативной ситуации, работает немного лучше, чем построенный на анализе хронологических данных (например, для 30-го вызова соотношение между предполагаемым и реальным временем ожидания составит 6,5 против 13 минут вместо 3 против 13 минут по методу ASA), все равно его точности не хватает для эффективного управления операторским центром.
Предположим, в операторский центр поступил вызов определенного типа. Система определяет, что к данному моменту самый ранний вызов этого типа уже ожидает в очереди 2 минуты, поэтому она экстраполирует данный показатель и на вновь прибывший вызов, прогнозируя, что он тоже прождет 2 минуты.
На первый взгляд неплохая схема, но тоже лишь в случае равномерной нагрузки. Если она становится пиковой, использование этого метода дает неточные результаты.
Дело в том, что он основан на следующем предположении: вызов, стоящий в очереди самым последним, будет ждать обслуживания столько же, сколько и самый первый. Но за то время, пока этот последний вызов доберется до начала очереди, может произойти множество изменений, например в числе работающих операторов, количестве вызовов в очереди, времени обслуживания вызова и т. д. Поэтому чем длиннее очередь, тем хуже работает метод OCW.
Схематично данный процесс показан на рисунке 3.5.
Из приведенного графика видно, что хотя метод, основанный на анализе оперативной ситуации, работает немного лучше, чем построенный на анализе хронологических данных (например, для 30-го вызова соотношение между предполагаемым и реальным временем ожидания составит 6,5 против 13 минут вместо 3 против 13 минут по методу ASA), все равно его точности не хватает для эффективного управления операторским центром.
Расчет времени ожидания на основе одновременного анализа хронологических и оперативных данных
Как следует из двух предыдущих разделов, анализ оперативных и хронологических данных по отдельности не дает сколько-нибудь пригодного результата для расчета предполагаемого времени ожидания в очереди, а следовательно, и оснований для того, чтобы предпринять адекватные действия по перенастройке операторского центра и его адаптации к изменению нагрузки. Возникает естественный вопрос: а что, если эти два подхода скомбинировать? Сделать это очень непросто, потому что надо принять во внимание как минимум следующие факторы:
• число работающих операторов;
• время обработки вызовов;
• частоту поступления вызовов с учетом их приоритетности;
• параметры потерянных вызовов (их количество и время, после которого абоненты вешают трубку, не дождавшись ответа);
• возможность постановки вызовов в очередь в несколько групп одновременно;
• возможность работы операторов в нескольких группах одновременно и др.
Давайте посмотрим теперь, что получится. Назовем такой комбинированный метод просто Expected Wait Time (EWT). На рисунке 3.6 показаны графики реального и предполагаемого времени ожидания, рассчитанного по методам ASA, OCW и EWT. Эти графики свидетельствуют о том, что метод, основанный на комбинированном анализе хронологических и оперативных данных, работает точнее всего.
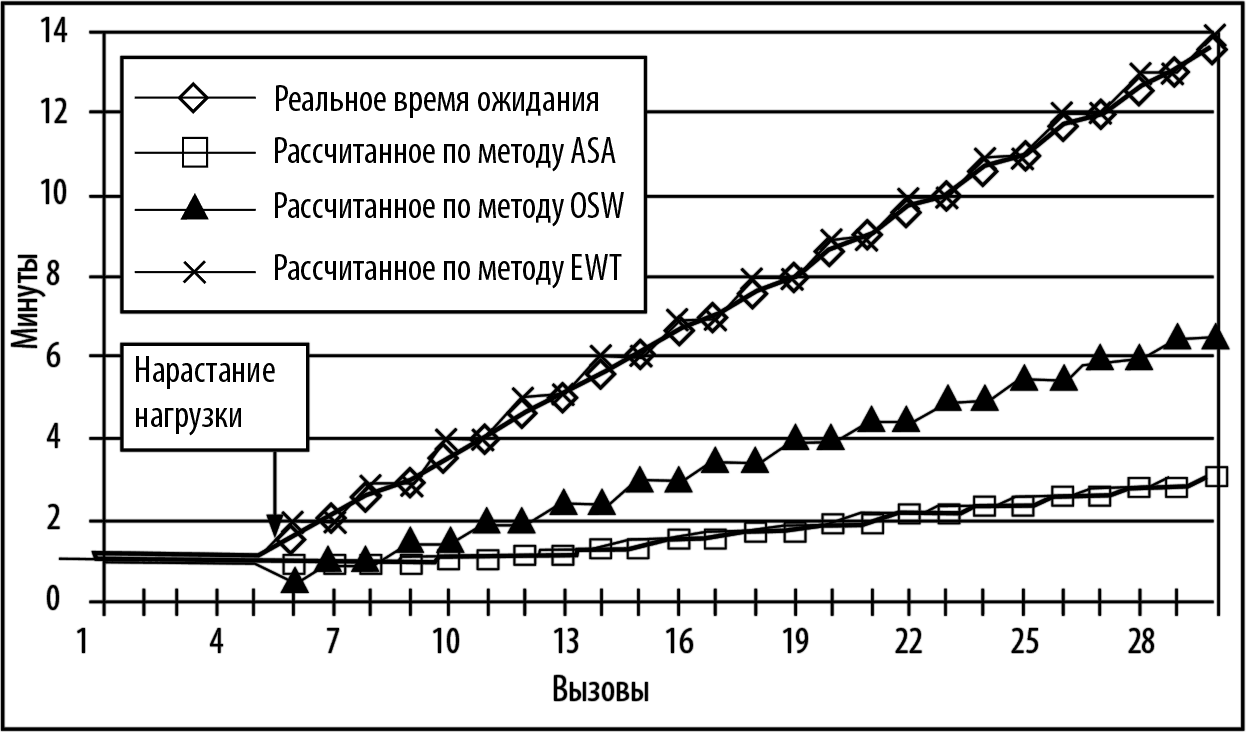 Рис. 3.6. Графики реального и расчетного времени ожидания, определенные по методам ASA, OCW, EWT
Рис. 3.6. Графики реального и расчетного времени ожидания, определенные по методам ASA, OCW, EWT
И это вполне объяснимо. Пользуясь хронологическими методами расчета (типа ASA), вы можете понять, что у вас только что были проблемы. Пользуясь методами расчета на основе оперативных данных (типа OCW), вы можете понять, что у вас сейчас есть проблемы. Пользуясь комбинированным методом, вы можете понять, что у вас могут возникнуть проблемы. Ну а кто предупрежден, тот вооружен!
• число работающих операторов;
• время обработки вызовов;
• частоту поступления вызовов с учетом их приоритетности;
• параметры потерянных вызовов (их количество и время, после которого абоненты вешают трубку, не дождавшись ответа);
• возможность постановки вызовов в очередь в несколько групп одновременно;
• возможность работы операторов в нескольких группах одновременно и др.
Давайте посмотрим теперь, что получится. Назовем такой комбинированный метод просто Expected Wait Time (EWT). На рисунке 3.6 показаны графики реального и предполагаемого времени ожидания, рассчитанного по методам ASA, OCW и EWT. Эти графики свидетельствуют о том, что метод, основанный на комбинированном анализе хронологических и оперативных данных, работает точнее всего.
И это вполне объяснимо. Пользуясь хронологическими методами расчета (типа ASA), вы можете понять, что у вас только что были проблемы. Пользуясь методами расчета на основе оперативных данных (типа OCW), вы можете понять, что у вас сейчас есть проблемы. Пользуясь комбинированным методом, вы можете понять, что у вас могут возникнуть проблемы. Ну а кто предупрежден, тот вооружен!
Целесообразность использования расчетного времени ожидания
К сожалению, несмотря на высокую точность определения расчетного времени ожидания, а также на важность его использования для маршрутизации вызовов и оповещения абонентов, метод EWT имеет некоторые ограничения.
Так, его нецелесообразно использовать при малом числе вызовов (так как при этом время ожидания чаще всего просто равно нулю, ибо нет никакой очереди) и при малом числе операторов. EWT следует применять, когда одновременно работают не меньше 15, а еще лучше – 20 операторов. В противном случае пострадает точность расчета EWT. Во-первых, будет не хватать чисто статистической «пищи». Во-вторых, очень большое значение приобретут различные субъективные характеристики поведения как вызывающих абонентов, так и операторов.
Вообще, как и в любом статистическом методе, чем больше число работающих операторов, тем точнее рассчитывается предполагаемое время ожидания в очереди.
Кроме того, поскольку EWT определяется на основе как оперативной, так и хронологической информации, могут возникнуть трудности при первоначальном вводе системы в эксплуатацию или при добавлении новой операторской группы. Дело в том, что в этих случаях будет некоторое время «хромать» хронологическая составляющая, поскольку ей просто еще неоткуда взяться. Точно так же негативное влияние на точность показателя EWT будут оказывать крупные реорганизации операторских групп. Кстати, на эти обстоятельства следует обратить особое внимание, если для расчета предполагаемого времени ожидания вы пользуетесь хронологическими методами типа рассмотренного выше способа расчета на основе средней скорости ответа ASA.
Так, его нецелесообразно использовать при малом числе вызовов (так как при этом время ожидания чаще всего просто равно нулю, ибо нет никакой очереди) и при малом числе операторов. EWT следует применять, когда одновременно работают не меньше 15, а еще лучше – 20 операторов. В противном случае пострадает точность расчета EWT. Во-первых, будет не хватать чисто статистической «пищи». Во-вторых, очень большое значение приобретут различные субъективные характеристики поведения как вызывающих абонентов, так и операторов.
Вообще, как и в любом статистическом методе, чем больше число работающих операторов, тем точнее рассчитывается предполагаемое время ожидания в очереди.
Кроме того, поскольку EWT определяется на основе как оперативной, так и хронологической информации, могут возникнуть трудности при первоначальном вводе системы в эксплуатацию или при добавлении новой операторской группы. Дело в том, что в этих случаях будет некоторое время «хромать» хронологическая составляющая, поскольку ей просто еще неоткуда взяться. Точно так же негативное влияние на точность показателя EWT будут оказывать крупные реорганизации операторских групп. Кстати, на эти обстоятельства следует обратить особое внимание, если для расчета предполагаемого времени ожидания вы пользуетесь хронологическими методами типа рассмотренного выше способа расчета на основе средней скорости ответа ASA.
Расчетное время ожидания на уровне группы и на уровне вызова
Расчетное время ожидания может быть определено:
• на уровне каждого отдельного вызова;
• на уровне отдельной операторской группы.
Это могут быть два совершенно разных значения, хотя иногда они могут и совпадать. EWT на уровне операторской группы означает время, в течение которого новый вызов будет ожидать в очереди, чтобы получить ответ оператора, входящего в эту конкретную группу. EWT на уровне вызова означает время, в течение которого данный конкретный вызов будет ожидать в очереди.
Поясним нашу мысль. Предположим, есть две операторские группы: № 1 и № 2. Расчетное время ожидания для первой группы (EWT1) составляет 2 минуты, для второй (EWT2) – 1,5 минуты. Это означает, что если бы сейчас в группу № 1 поступил новый вызов, то он прождал бы ответа ее оператора 2 минуты. Соответственно, если бы вызов поступил в группу № 2, то он прождал бы 1,5 минуты.
Теперь предположим, что вызов, о котором мы столько говорили, наконец поступил. Какое у него будет расчетное время ожидания? Здесь возможны три варианта:
• если этот вызов может быть обслужен только операторами из группы № 1, то его расчетное время будет равно расчетному времени ожидания именно для этой группы, т. е. 2 минутам;
• если этот вызов может быть обслужен только операторами из группы № 2, то его расчетное время будет равно расчетному времени ожидания именно для этой группы, т. е. 1,5 минутам;
• если же этот вызов может быть обслужен операторами из обеих групп, то его расчетное время будет равно минимальному EWT для каждой группы. Таким образом, поскольку EWT2 < EWT1, то в качестве EWT вызова будет выбрано значение EWT2, т. е. 1,5 минуты.
Влиять на EWT вызова супервизор, естественно, не может, в то время как на EWT группы – вполне.
• на уровне каждого отдельного вызова;
• на уровне отдельной операторской группы.
Это могут быть два совершенно разных значения, хотя иногда они могут и совпадать. EWT на уровне операторской группы означает время, в течение которого новый вызов будет ожидать в очереди, чтобы получить ответ оператора, входящего в эту конкретную группу. EWT на уровне вызова означает время, в течение которого данный конкретный вызов будет ожидать в очереди.
Поясним нашу мысль. Предположим, есть две операторские группы: № 1 и № 2. Расчетное время ожидания для первой группы (EWT1) составляет 2 минуты, для второй (EWT2) – 1,5 минуты. Это означает, что если бы сейчас в группу № 1 поступил новый вызов, то он прождал бы ответа ее оператора 2 минуты. Соответственно, если бы вызов поступил в группу № 2, то он прождал бы 1,5 минуты.
Теперь предположим, что вызов, о котором мы столько говорили, наконец поступил. Какое у него будет расчетное время ожидания? Здесь возможны три варианта:
• если этот вызов может быть обслужен только операторами из группы № 1, то его расчетное время будет равно расчетному времени ожидания именно для этой группы, т. е. 2 минутам;
• если этот вызов может быть обслужен только операторами из группы № 2, то его расчетное время будет равно расчетному времени ожидания именно для этой группы, т. е. 1,5 минутам;
• если же этот вызов может быть обслужен операторами из обеих групп, то его расчетное время будет равно минимальному EWT для каждой группы. Таким образом, поскольку EWT2 < EWT1, то в качестве EWT вызова будет выбрано значение EWT2, т. е. 1,5 минуты.
Влиять на EWT вызова супервизор, естественно, не может, в то время как на EWT группы – вполне.
Факторы, влияющие на расчетное время ожидания
Начнем, как водится, с хорошего – с уменьшения EWT. На уменьшение расчетного времени ожидания могут влиять следующие факторы (некоторые из них вполне очевидны, а некоторые не очень):
• уменьшение числа вызовов в очереди;
• увеличение числа операторов;
• сокращение времени разговора;
• увеличение числа потерянных вызовов (на первый взгляд выглядит странно, но если немного подумать, то понятно);
• уменьшение доли вызовов с самым высоким уровнем приоритета;
• уменьшение числа вызовов, пропущенных операторами.
Теперь перейдем к факторам, негативно влияющим на EWT, т. е. вызывающим его увеличение. В принципе, тут существует обратная зависимость:
• увеличение числа вызовов в очереди;
• уменьшение числа операторов (по любой причине: кто-то вышел из системы, кто-то ушел на перерыв и т. п.);
• увеличение времени разговора;
• сокращение числа потерянных вызовов;
• увеличение доли вызовов с самым высоким уровнем приоритета;
• увеличение числа вызовов, пропущенных операторами.
Коротко о главном
• Основной принцип организации очереди – обрабатывать как можно большее число вызовов как можно меньшим числом операторов без ухудшения качества обслуживания и перегрузки сотрудников ЦОВ.
• Очередь – нормальное явление в колл-центре. Однако необходимо эффективно управлять ее длиной за счет правильного планирования ресурсов, соблюдения дисциплины и реализации эффективных алгоритмов обслуживания вызовов.
• В случае возникновения перегрузки лучше воспользоваться сигналом «занято», чем речевой почтой.
• При оценке эффективности обслуживания не следует полагаться на усредненные показатели типа средней скорости ответа ASA. Важно исследовать уровень обслуживания, максимальные задержки с ответом и профиль вызовов.
• Расчетное время ожидания – важнейший параметр, благодаря которому можно в значительной мере повысить эффективность обслуживания вызовов.
• Существуют три основных метода определения расчетного времени ожидания: на основе анализа хронологических данных, на основе анализа текущей производительности и на основе комбинирования оперативных и хронологических данных.
• Наиболее точно расчетное время ожидания определяется по методу, основанному на анализе одновременно хронологических и оперативных данных.
• уменьшение числа вызовов в очереди;
• увеличение числа операторов;
• сокращение времени разговора;
• увеличение числа потерянных вызовов (на первый взгляд выглядит странно, но если немного подумать, то понятно);
• уменьшение доли вызовов с самым высоким уровнем приоритета;
• уменьшение числа вызовов, пропущенных операторами.
Теперь перейдем к факторам, негативно влияющим на EWT, т. е. вызывающим его увеличение. В принципе, тут существует обратная зависимость:
• увеличение числа вызовов в очереди;
• уменьшение числа операторов (по любой причине: кто-то вышел из системы, кто-то ушел на перерыв и т. п.);
• увеличение времени разговора;
• сокращение числа потерянных вызовов;
• увеличение доли вызовов с самым высоким уровнем приоритета;
• увеличение числа вызовов, пропущенных операторами.
Коротко о главном
• Основной принцип организации очереди – обрабатывать как можно большее число вызовов как можно меньшим числом операторов без ухудшения качества обслуживания и перегрузки сотрудников ЦОВ.
• Очередь – нормальное явление в колл-центре. Однако необходимо эффективно управлять ее длиной за счет правильного планирования ресурсов, соблюдения дисциплины и реализации эффективных алгоритмов обслуживания вызовов.
• В случае возникновения перегрузки лучше воспользоваться сигналом «занято», чем речевой почтой.
• При оценке эффективности обслуживания не следует полагаться на усредненные показатели типа средней скорости ответа ASA. Важно исследовать уровень обслуживания, максимальные задержки с ответом и профиль вызовов.
• Расчетное время ожидания – важнейший параметр, благодаря которому можно в значительной мере повысить эффективность обслуживания вызовов.
• Существуют три основных метода определения расчетного времени ожидания: на основе анализа хронологических данных, на основе анализа текущей производительности и на основе комбинирования оперативных и хронологических данных.
• Наиболее точно расчетное время ожидания определяется по методу, основанному на анализе одновременно хронологических и оперативных данных.
Глава 4
Эволюция методов распределения вызовов
Как мы уже говорили в главе 1, одним из трех основных условий существования Сall Center является необходимость маршрутизации вызовов, их интеллектуального распределения по операторам. Процесс этот достаточно сложен, и в настоящей главе мы попытаемся проследить, как он эволюционировал с течением времени, начиная c наиболее ранних способов маршрутизации по принципу «горячее место» и заканчивая самыми современными сложными прогностическими методами.
Базовые алгоритмы маршрутизации
«Первый свободный», или «Горячее место»
Как известно, первые операторские центры в современном понимании этого термина появились в Америке в самом начале 70-х годов прошлого века. Но понятно, что и до этой исторической вехи существовали специальные службы, отвечавшие на звонки абонентов. В основе распределения вызовов по «телефонным барышням» лежал принцип выбора первого свободного оператора (First Available Agent), или, как его прозвали, принцип «горячего места».
Схематично процесс маршрутизации выглядел так: поступивший вызов направлялся к первому оператору. Если он (а в те времена, скорее, она) оказывался занят, то выбирался второй оператор. Если же и тот был несвободен, вызов направлялся к третьему и т. д.
Таким образом, на первых двух-трех (или пяти, или десяти – в зависимости от величины операторского центра) сотрудников приходилась гораздо бóльшая нагрузка, чем на других. Появлялось так называемое «горячее место».
Работать на таком «горячем месте», в условиях неимоверной нагрузки, было очень тяжело, поэтому периодически происходила ротация операторов. Люди, работавшие на последних местах, менялись с теми, кто работал на первых, по кругу. Только так можно было защитить операторов от перегрузки и, более того, от нервного истощения.
Схематично процесс маршрутизации выглядел так: поступивший вызов направлялся к первому оператору. Если он (а в те времена, скорее, она) оказывался занят, то выбирался второй оператор. Если же и тот был несвободен, вызов направлялся к третьему и т. д.
Таким образом, на первых двух-трех (или пяти, или десяти – в зависимости от величины операторского центра) сотрудников приходилась гораздо бóльшая нагрузка, чем на других. Появлялось так называемое «горячее место».
Работать на таком «горячем месте», в условиях неимоверной нагрузки, было очень тяжело, поэтому периодически происходила ротация операторов. Люди, работавшие на последних местах, менялись с теми, кто работал на первых, по кругу. Только так можно было защитить операторов от перегрузки и, более того, от нервного истощения.
«Наиболее свободный»
Так продолжалось довольно долго, но человеческая мысль развивается, и в середине 70-х годов прошлого века появились первые профессиональные ЦОВ, в основе которых лежала функция автоматического распределения вызовов, или ACD. В этом случае вызов направлялся уже не к первому свободному оператору, а к наиболее свободному (Most Idle Agent, MIA), т. е. к тому, который дольше всех оставался свободным от обслуживания вызовов.
Разница между этими двумя алгоритмами огромная. Правда, чисто математически основное их отличие заключается всего лишь в следующем.
В соответствии с принципом «горячего места» система по порядку перебирает операторов: первый, второй, третий и т. д., до тех пор пока не обнаружит свободного. Как только система находит незанятого оператора, она сразу же направляет к нему звонок абонента. Более совершенный алгоритм MIA подразумевает, что система сначала проверяет всех операторов, находит среди них наиболее свободного и только тогда, после, повторяю, просмотра каждого оператора, направляет вызов к выбранному сотруднику (рис. 4.1).
 Рис. 4.1. Принцип выбора наиболее свободного оператора
Рис. 4.1. Принцип выбора наиболее свободного оператора
Как видите, с математической точки зрения – ничего необычного. Гораздо важнее, что алгоритм MIA изменил саму идеологию распределения вызовов, позволил достичь равномерной нагрузки на операторов и дал толчок развитию современных операторских центров.
Алгоритм MIA был значительным шагом вперед и долгое время, более 20 лет, оставался единственным методом распределения вызовов.
Разница между этими двумя алгоритмами огромная. Правда, чисто математически основное их отличие заключается всего лишь в следующем.
В соответствии с принципом «горячего места» система по порядку перебирает операторов: первый, второй, третий и т. д., до тех пор пока не обнаружит свободного. Как только система находит незанятого оператора, она сразу же направляет к нему звонок абонента. Более совершенный алгоритм MIA подразумевает, что система сначала проверяет всех операторов, находит среди них наиболее свободного и только тогда, после, повторяю, просмотра каждого оператора, направляет вызов к выбранному сотруднику (рис. 4.1).
Как видите, с математической точки зрения – ничего необычного. Гораздо важнее, что алгоритм MIA изменил саму идеологию распределения вызовов, позволил достичь равномерной нагрузки на операторов и дал толчок развитию современных операторских центров.
Алгоритм MIA был значительным шагом вперед и долгое время, более 20 лет, оставался единственным методом распределения вызовов.
Маршрутизация на основе квалификации операторов
Однако жизнь не стояла на месте, бизнес развивался, запросы абонентов становились все сложнее, и операторам требовалось все больше знаний, чтобы их обслуживать. Появились потребности:
1) в сегментации клиентов;
2) в учете квалификации операторов.
В простейшем виде обе эти потребности сначала удовлетворялись следующим образом. Операторы обладали одним квалификационным признаком и, соответственно, могли входить только в одну группу приема вызовов. Предположим теперь, что у компании имелись две категории клиентов. Обозначим их условно как «красные» и «синие». Соответственно, образовывались две группы операторов: первая, «красная», обслуживала вызовы «красных» абонентов, вторая, «синяя», – «синих». Также имелись два телефонных номера: один для «красных», другой для «синих». «Синие» набирали свой «синий» номер и сразу попадали на группу «синих» операторов. То же самое – для «красных». Все четко, ясно, прозрачно. Никакой путаницы.
До определенного момента такая схема отлично работала. Потом начинались сложности. В течение дня возникали моменты, когда в «синей» группе обозначалась явная перегрузка, операторы не успевали отвечать на звонки, время ожидания в очереди резко увеличивалось. А в «красной» группе царили тишь да покой. Вызовов было мало, операторы маялись от избытка свободного времени.
В такой ситуации, с одной стороны, росло недовольство «синих» клиентов, вынужденных подолгу ждать ответа операторов, а с другой стороны, крайне неэффективно использовался штат операторов: «синие» были перегружены, а «красные» – недогружены.
Стали заставлять «красных» операторов выходить из своей группы и подключаться к обслуживанию «синих» абонентов. На какое-то время проблему удавалось решить, но такой системе явно не хватало гибкости и способности к самонастройке.
Конечно, весь этот процесс описан крайне схематично, но тем не менее он дает общее представление о проблеме.
В начале 1990-х годов появились первые системы, которые стали распределять поступающие вызовы с учетом квалификации операторов (их общее название – Skill Based Routing). Стало возможным вхождение каждого оператора одновременно в две группы приема вызовов и, соответственно, обладание двумя квалификационными навыками (пользуясь нашим предыдущим примером, – «синим» и «красным»).
Поскольку с точки зрения эффективности использования человеческих ресурсов следовало по возможности сохранить специализацию операторов, но в то же время дать системе возможность адаптироваться к изменениям оперативной обстановки, профессиональные навыки стали делить на первичные и вторичные. Таким образом, хотя по-прежнему оставались две группы приема вызовов – «красная» и «синяя», – операторы приобрели, скажем так, несколько другой «окрас»: вместо «красных» и «синих» они стали «красно-синими» и «сине-красными». У «красно-синих» операторов первичными квалификационными навыками были «красные», а вторичными – «синие». Соответственно, у «сине-красных» операторов – наоборот (рис. 4.2).
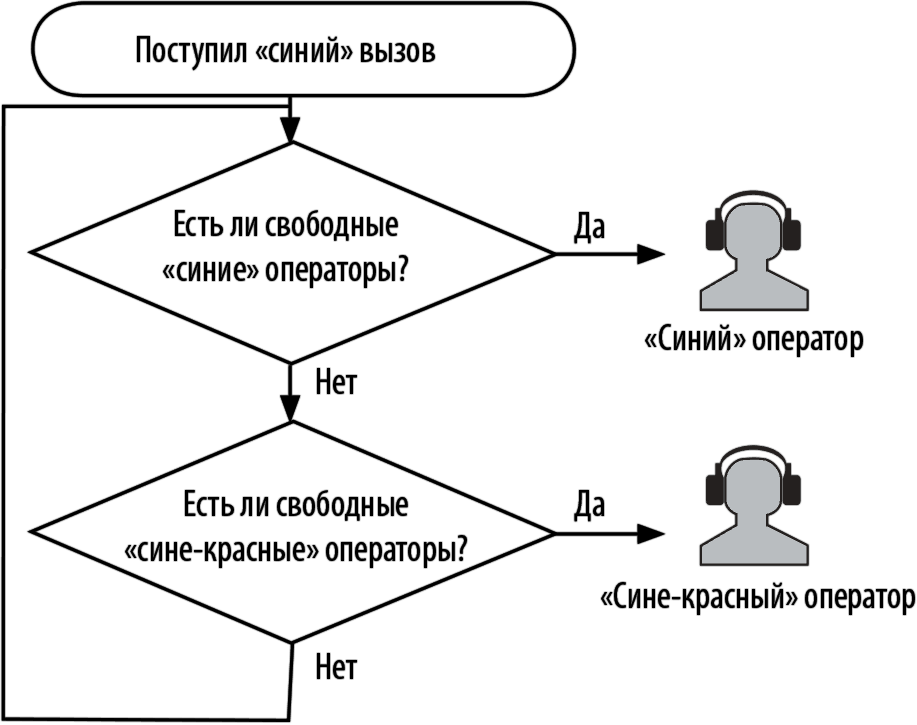 Рис. 4.2. Простейшая схема Skill Based Routing
Рис. 4.2. Простейшая схема Skill Based Routing
Схематично процесс обслуживания вызовов теперь выглядел так: при поступлении звонка от «красного» клиента система сначала проверяла «красно-синих» операторов, а затем, если среди них не оказывалось ни одного свободного, – «сине-красных». Благодаря такой схеме, во-первых, наилучшим образом обслуживались все виды вызовов, во-вторых, эффективно использовались знания операторов, и в-третьих, сокращались непроизводительные затраты рабочего времени сотрудников.
Через несколько лет схема маршрутизации вызовов усложнилась еще больше. Теперь стала возможной ситуация, когда операторы одновременно входили не в две, а в несколько групп приема вызовов, т. е. операторы стали многосплитовыми (от слова split – группа). Причем степень владения тем или иным квалификационным навыком тоже стала значительно варьироваться. Раньше было всего два уровня владения профессиональными навыками (первичный и вторичный), теперь их стало много.
Давайте рассмотрим подробнее принцип Skill Based Routing на следующем примере. Предположим, что каждый оператор может одновременно входить в 20 групп, а следовательно, обладать 20 видами профессиональных навыков. Владение оператора тем или иным профессиональным навыком оценивается по шкале от 1 до 15 в зависимости от опыта, обучения или собственных предпочтений. Уровень 1 считается наивысшим. Таким образом, при маршрутизации вызовов получается матрица из 20 × 15 = 300 различных комбинаций.
На мой взгляд, в этом даже есть некоторая избыточность. Я лично при внедрении Skill Based Routing у различных клиентов ни разу не сталкивалась с необходимостью существования у оператора более трех-четырех квалификационных навыков; при этом градуировка владения каждым из них колебалась от 1 до 4.
Следует упомянуть, что к разбивке операторов на группы следует относиться очень внимательно. Это как раз тот случай, когда «размер имеет значение». Что лучше: много мелких групп, учитывающих малейшие нюансы специализации, или одна большая группа, организованная вовсе без ее учета? Иными словами, какими должны быть операторы – узкоспециализированными или универсальными? Подробнее об этом мы поговорим в разделе «Преимущества и недостатки маршрутизации на основе квалификации операторов».
1) в сегментации клиентов;
2) в учете квалификации операторов.
В простейшем виде обе эти потребности сначала удовлетворялись следующим образом. Операторы обладали одним квалификационным признаком и, соответственно, могли входить только в одну группу приема вызовов. Предположим теперь, что у компании имелись две категории клиентов. Обозначим их условно как «красные» и «синие». Соответственно, образовывались две группы операторов: первая, «красная», обслуживала вызовы «красных» абонентов, вторая, «синяя», – «синих». Также имелись два телефонных номера: один для «красных», другой для «синих». «Синие» набирали свой «синий» номер и сразу попадали на группу «синих» операторов. То же самое – для «красных». Все четко, ясно, прозрачно. Никакой путаницы.
До определенного момента такая схема отлично работала. Потом начинались сложности. В течение дня возникали моменты, когда в «синей» группе обозначалась явная перегрузка, операторы не успевали отвечать на звонки, время ожидания в очереди резко увеличивалось. А в «красной» группе царили тишь да покой. Вызовов было мало, операторы маялись от избытка свободного времени.
В такой ситуации, с одной стороны, росло недовольство «синих» клиентов, вынужденных подолгу ждать ответа операторов, а с другой стороны, крайне неэффективно использовался штат операторов: «синие» были перегружены, а «красные» – недогружены.
Стали заставлять «красных» операторов выходить из своей группы и подключаться к обслуживанию «синих» абонентов. На какое-то время проблему удавалось решить, но такой системе явно не хватало гибкости и способности к самонастройке.
Конечно, весь этот процесс описан крайне схематично, но тем не менее он дает общее представление о проблеме.
В начале 1990-х годов появились первые системы, которые стали распределять поступающие вызовы с учетом квалификации операторов (их общее название – Skill Based Routing). Стало возможным вхождение каждого оператора одновременно в две группы приема вызовов и, соответственно, обладание двумя квалификационными навыками (пользуясь нашим предыдущим примером, – «синим» и «красным»).
Поскольку с точки зрения эффективности использования человеческих ресурсов следовало по возможности сохранить специализацию операторов, но в то же время дать системе возможность адаптироваться к изменениям оперативной обстановки, профессиональные навыки стали делить на первичные и вторичные. Таким образом, хотя по-прежнему оставались две группы приема вызовов – «красная» и «синяя», – операторы приобрели, скажем так, несколько другой «окрас»: вместо «красных» и «синих» они стали «красно-синими» и «сине-красными». У «красно-синих» операторов первичными квалификационными навыками были «красные», а вторичными – «синие». Соответственно, у «сине-красных» операторов – наоборот (рис. 4.2).
Схематично процесс обслуживания вызовов теперь выглядел так: при поступлении звонка от «красного» клиента система сначала проверяла «красно-синих» операторов, а затем, если среди них не оказывалось ни одного свободного, – «сине-красных». Благодаря такой схеме, во-первых, наилучшим образом обслуживались все виды вызовов, во-вторых, эффективно использовались знания операторов, и в-третьих, сокращались непроизводительные затраты рабочего времени сотрудников.
Через несколько лет схема маршрутизации вызовов усложнилась еще больше. Теперь стала возможной ситуация, когда операторы одновременно входили не в две, а в несколько групп приема вызовов, т. е. операторы стали многосплитовыми (от слова split – группа). Причем степень владения тем или иным квалификационным навыком тоже стала значительно варьироваться. Раньше было всего два уровня владения профессиональными навыками (первичный и вторичный), теперь их стало много.
Давайте рассмотрим подробнее принцип Skill Based Routing на следующем примере. Предположим, что каждый оператор может одновременно входить в 20 групп, а следовательно, обладать 20 видами профессиональных навыков. Владение оператора тем или иным профессиональным навыком оценивается по шкале от 1 до 15 в зависимости от опыта, обучения или собственных предпочтений. Уровень 1 считается наивысшим. Таким образом, при маршрутизации вызовов получается матрица из 20 × 15 = 300 различных комбинаций.
На мой взгляд, в этом даже есть некоторая избыточность. Я лично при внедрении Skill Based Routing у различных клиентов ни разу не сталкивалась с необходимостью существования у оператора более трех-четырех квалификационных навыков; при этом градуировка владения каждым из них колебалась от 1 до 4.
Следует упомянуть, что к разбивке операторов на группы следует относиться очень внимательно. Это как раз тот случай, когда «размер имеет значение». Что лучше: много мелких групп, учитывающих малейшие нюансы специализации, или одна большая группа, организованная вовсе без ее учета? Иными словами, какими должны быть операторы – узкоспециализированными или универсальными? Подробнее об этом мы поговорим в разделе «Преимущества и недостатки маршрутизации на основе квалификации операторов».
Конец бесплатного ознакомительного фрагмента