Итак, мы видим, что использование пиратского ПО выгодно начальству, но практически невыгодно админу.
Выходя на новую работу, я всегда провожу инвентаризацию имеющегося аппаратного и программного обеспечения. О результатах информирую начальство и рекомендую купить лицензии ПО, если их нет. Желательно все это делать в письменном виде и отдавать под расписку, и при проверке начальство уже не сможет кивать на админа: мол, это он вводил нас в заблуждение.
Под этой позицией я бы и сам мог подписаться. Но согласитесь, результаты поражают. Получается, что бизнесмены действительно врут сами себе, стараясь создать иллюзорную картину мира? То, что они врут специально, я мало допускаю. Ведь для себя они покупают, и среди наших покупателей около 40% — руководители различного уровня. Это позиция страуса, спрятавшего голову в песок, и отодвигание проблемы легализации софта на потом или желание руководителей сэкономить деньги? Или все-таки частично это своего рода негласный договор между руководителем и сисадмином (один не дает денег на покупку софта, другой уже и не просит — все равно не дадут, и вынужден ставить пиратский софт, и оба хорошо понимают, что они совершают противозаконные поступки)?
Я считаю, что бизнесмены врут. Цели этого для меня не важны. Я как-то читал результаты анонимного исследования про супружеские измены. Так вот: процент женщин, которые признались в адюльтере, был существенно ниже фактического результата, полученного с помощью анализа ДНК их детей. То же самое мы имеем при оценке коррупции. Те, кто берут взятки, всегда будут занижать их количество, в отличие от тех, кому их приходится давать.
ТЕМА НОМЕРА: 64 бита для всех
Выходя на новую работу, я всегда провожу инвентаризацию имеющегося аппаратного и программного обеспечения. О результатах информирую начальство и рекомендую купить лицензии ПО, если их нет. Желательно все это делать в письменном виде и отдавать под расписку, и при проверке начальство уже не сможет кивать на админа: мол, это он вводил нас в заблуждение.
Под этой позицией я бы и сам мог подписаться. Но согласитесь, результаты поражают. Получается, что бизнесмены действительно врут сами себе, стараясь создать иллюзорную картину мира? То, что они врут специально, я мало допускаю. Ведь для себя они покупают, и среди наших покупателей около 40% — руководители различного уровня. Это позиция страуса, спрятавшего голову в песок, и отодвигание проблемы легализации софта на потом или желание руководителей сэкономить деньги? Или все-таки частично это своего рода негласный договор между руководителем и сисадмином (один не дает денег на покупку софта, другой уже и не просит — все равно не дадут, и вынужден ставить пиратский софт, и оба хорошо понимают, что они совершают противозаконные поступки)?
Я считаю, что бизнесмены врут. Цели этого для меня не важны. Я как-то читал результаты анонимного исследования про супружеские измены. Так вот: процент женщин, которые признались в адюльтере, был существенно ниже фактического результата, полученного с помощью анализа ДНК их детей. То же самое мы имеем при оценке коррупции. Те, кто берут взятки, всегда будут занижать их количество, в отличие от тех, кому их приходится давать.
***
Относительно негласного договора: во многих случаях это так. То есть вина как минимум обоюдная. Специально ставить пиратский софт, если есть возможность поставить легально купленный, не будет ни один админ — по причинам, изложенным выше.
ТЕМА НОМЕРА: 64 бита для всех
История знает много разных компьютеров и много разных технологических решений, применявшихся в них. Лампы, транзисторы, ИС, БИС и СБИС; CISC, RISC и VLIW; компьютеры большие и маленькие; процессоры удачные и неудачные. Компьютеры на троичной логике, аналоговые машины, стохастические вычислители и компьютеры с «байтом» из девяти битов — бывало всякое. Однако конечный результат эволюции известен всем — это «тьюринговые» компьютеры с процессором, линейной оперативной памятью и средствами ввода-вывода и накопления информации, основанные на детерминированных вычислениях, двоичной логике и восьмибитных «неделимых» атомах информации — байтах. Но поскольку в один байт много не запишешь, то собственно байтами процессоры оперируют редко (разве что совсем уж простые 8-битные микропроцессоры), используя гораздо более крупные объекты — машинные слова[По традиции, идущей от первого процессора семейства x86 — CPU Intel 8086, который оперировал 16-разрядными числами, словом (word) обычно называют два байта. Потом, когда x86-процессоры получили возможность работать и с 32-разрядными данными, для совместимости со старым программным обеспечением эти 32 бита стали представлять в виде двух 16-битных слов — вот и получилось четырехбайтное двойное слово (double word). Таким образом, четверное слово (quad word) соответствует 64-битным данным (8 байтам) и т. д.]. При этом самые популярные сегодня x86-процессоры прошли почти весь путь усложнения объектов, с которыми они работали, начав с 8 битов (Intel 8008, 8080, 8085), «выбившись в люди» на 16 битах (8086 и 80286), надолго застряв на 32 битах и вот наконец, два года назад, обретя 64-битность. Но что это такое, как оно устроено, как его использовать и что это дает обычному пользователю? Об этом — наш сегодняшний рассказ.
Чтобы было понятнее, о чем идет речь, поясняю: стандартная модель записи целочисленных чисел позволяет записать в 32-разрядный GPR-регистр процессора архитектуры IA-32 любое целое число от 0 до 232—1. Оперативная память с точки зрения прикладных приложений представляется здесь в виде эдакой длинной ленты из ячеек определенного размера (1 байт в x86), причем все они «пронумерованы» — ячейка 0, ячейка 1 и так далее, вплоть до ячейки 4.294.967.295. Какие-то ячейки могут «отсутствовать» — в этом случае обращение к ним будет вызывать ошибку, однако потенциальная возможность обратиться к этой ячейке существует всегда. А вот у 32-разрядного процессора возможности обратиться к ячейке 4.294.967.295 нет в принципе — просто потому, что он не сможет «дать ей название».
Что это означает на практике? Только то, что ни одна «классическая» 32-битная программа не может использовать больше 4 Гбайт (232/210*210*210) памяти. Поэтому если вы спросите продавца о преимуществах 64-разрядного процессора, то именно эту сакральную фразу о «поддержке большого объема оперативной памяти» (вместе с вопросом «а оно вам надо?») и услышите. Но все-таки не спешите сводить эту возможность к установке в систему четырех двухгигабайтных планок SDRAM. Все далеко не так просто.
Впрочем, перенумерацией дело не ограничивается, поскольку вместе с номерами указываются всяческие атрибуты — «только для чтения», «только для операционной системы» и пр. Вдобавок для некоторых ячеек можно указать, что они в оперативную память «пока не загружены». Встретив такую пометку, CPU генерирует специальную системную ошибку (Page Fault) и обращается за помощью к операционной системе, которая может, к примеру, загрузить данные для этой ячейки с жесткого диска (техника своппинга). Поэтому всегда следует помнить, что «ограничение 4 Гбайт» в первую очередь относится не к физической, а к виртуальной оперативной памяти, доступной процессу. А вот что стоит за этими четырьмя гигабайтами адресного пространства — скромные ли 128 Мбайт памяти SDRAM или кусочек от пары терабайтов дискового массива — неважно: собственно процессор этот «реальный мир» почти ничем не ограничивает.
Но все же — что дает разрядность? Если процессор поддерживает длинные физические адреса (в архитектуре x86 соответствующий режим называется Physical Address Extension, PAE[Если подробнее, то в PAE используется 52-битная адресация, позволяющая адресовать до четырех петабайт данных]), то мы можем поставить на сервер хоть 64 Гбайт оперативной памяти и выделять ее разным приложениям. Условия вроде «не более двух гигов для чипсета такого-то» — это ограничения именно чипсета, не умеющего обслуживать большой объем памяти, а не 32-разрядной системы. Поэтому в серверных приложениях, когда на одном сервере, как правило, запущено несколько десятков одновременно работающих приложений, пресловутый «барьер в 4 Гбайт» практически не ощущается. Но означает ли это, что сегодня 64-разрядный x86 никому не нужен?
Конечно, нет! 64-разрядность виртуальной памяти в приложениях востребована уже сейчас, просто эти «добавочные биты» используются другими способами.
Во-первых, какую-то часть виртуального адресного пространства может забирать операционная система. К примеру, MS Windows обычно использует для своих нужд старший бит виртуального адреса, ограничивая адресное пространство запущенного в ней приложения 31 битом и 2 Гбайт адресного пространства. А два гигабайта оперативной памяти, согласитесь, куда ближе к реальной жизни, нежели гипотетические четыре; и ситуацию, когда их начнет не хватать, представить гораздо проще. Можно, правда, попытаться использовать специальный режим, когда Windows будет предоставлять процессам не два, а три гига адресного пространства, но работает он, к сожалению, далеко не всегда, зачастую роняя при неправильной настройке операционную систему.
Во-вторых, линейное адресное пространство подвержено «засорению» — процессу, в ходе которого в нем образуются дырки, которые невозможно использовать. Программы часто оперируют не байтами и словами, а гораздо более крупными структурами, занимающими десятки, сотни и даже миллионы байт информации. Если мы использовали эту структуру, а затем необходимость в ней отпала, то в памяти остается дыра, совпадающая по размерам и расположению с местом, где лежали данные этой структуры. И удастся ли сию дыру использовать — еще бабушка надвое сказала. Иногда почти вся оперативная память состоит из дырок, не несущих никакой практической пользы, и места для записи даже небольшого объема данных не находится[Подобным особенно грешат операционные системы и среды разработки компании Microsoft: менеджер памяти, используемый в Windows, не столь эффективен, как его UNIX-собратья, и «мусора» в памяти оставляет гораздо больше. Иногда это приводит к тому, что нормально работающие на UNIX программы, использующие вдобавок сравнительно небольшой объем оперативной памяти, в MS Windows через некоторое время вылетают с ошибкой Out of memory].
В-третьих, существует такая интересная техника, как маппинг файлов на оперативную память. «Маппить» можно что угодно, причем это не только самый быстрый, но и один из самых удобных способов обработки файлов. Не нужно ничего читать из файла или записывать в него, не нужно думать об эффективном кэшировании данных — все происходит автоматически. Просто «мапнул» файл на память — и находившиеся в нем данные волшебным образом мгновенно оказались доступными приложению. В «настоящую» оперативную память они будут подгружаться только при обращении к ним, а в случае длительной «невостребованности» — вновь возвращаться на жесткий диск, освобождая место для чего-нибудь более актуального. Реализовать что-либо подобное «вручную» — практически невозможно. Но, к сожалению, на двух гигабайтах адресного пространства Windows особенно не развернешься[И на 4 Гбайт своп-файла, которыми нас обычно ограничивает Windows (ругать так ругать!), — зачастую тоже], поэтому техника маппинга задействуется только тогда, когда высокая скорость обработки файлов для приложения становится критичной.
Поэтому даже если бы в технологиях EM64T/AMD64 не было бы ничего сверх возможности оперировать с 64-битными указателями[Указатель на оперативную память (обычно просто говорят: указатель) — это ячейка памяти, в которой записывается номер другой ячейки. То есть, к примеру, мы можем как-то использовать в программе это число (номер ячейки) — присваивать его, изменять, увеличивать или уменьшать, а потом вызвать специальную операцию «разыменования» — взятия данных, расположенных по этому адресу в оперативной памяти. В C/C++ и подобных языках программирования указатели выделены в самостоятельный тип данных, и программист работает с ними «вручную»; в других языках «арифметику» указателей от программиста прячут, предлагая работать с более высокоуровневыми абстракциями, однако в машинном коде и оперативной памяти указатели встречаются почти всегда] на оперативную память, они по-прежнему оставались бы востребованными и своего покупателя все равно бы нашли. Но стоила бы в этом случае овчинка выделки?
 Увы, нет. По крайней мере в ближайшие года три. Изменения регистров общего назначения и системы адресации памяти — совсем не то, что добавление новых регистров и новых инструкций для работы с ними. Расширения никак не влияют на работу старых программ, которые об их существовании и не догадываются; а вот пройти мимо изменений использующихся на каждом шагу регистров общего назначения — даже в уже существующих приложениях — невозможно. Очень часто приложения явным или неявным образом апеллируют к тому, что данные, которые они используют, имеют ту или иную длину и неожиданный сюрприз в виде занимающего не 4, а 8 байт указателя на оперативную память для них почти всегда фатален. Даже если программа не занимается «явным приведением типов», превращая их в 32-битные целые числа и обратно (это из сугубо программистских заморочек), то почти наверняка хоть где-нибудь она работает со структурой данных, в которую одним из компонентов входит тот самый указатель, и где для него отведено строго четыре байта, зажатых слева и справа данными той же или других структур. Так что подавляющее большинство существующих 32-битных программ в 64-битном режиме выполняться не будут.
Увы, нет. По крайней мере в ближайшие года три. Изменения регистров общего назначения и системы адресации памяти — совсем не то, что добавление новых регистров и новых инструкций для работы с ними. Расширения никак не влияют на работу старых программ, которые об их существовании и не догадываются; а вот пройти мимо изменений использующихся на каждом шагу регистров общего назначения — даже в уже существующих приложениях — невозможно. Очень часто приложения явным или неявным образом апеллируют к тому, что данные, которые они используют, имеют ту или иную длину и неожиданный сюрприз в виде занимающего не 4, а 8 байт указателя на оперативную память для них почти всегда фатален. Даже если программа не занимается «явным приведением типов», превращая их в 32-битные целые числа и обратно (это из сугубо программистских заморочек), то почти наверняка хоть где-нибудь она работает со структурой данных, в которую одним из компонентов входит тот самый указатель, и где для него отведено строго четыре байта, зажатых слева и справа данными той же или других структур. Так что подавляющее большинство существующих 32-битных программ в 64-битном режиме выполняться не будут.
Это не такая уж катастрофа, как может показаться: современные процессоры умеют быстро переключаться между 32— и 64-битным режимами, однако как минимум одно приложение, работающее на 64-битном компьютере, эти «нововведения» все-таки должно поддерживать. Ибо если даже операционная система, заведующая менеджментом виртуального адресного пространства, будет работать в 32-битном режиме, то ради чего мы боролись? Поэтому сформулируем «принцип номер один» для 64-битных систем: для поддержки 64-битности операционная система тоже должна быть 64-битной. Правда, объем переделок, которые для этого требуются, велик, но не бесконечен — релизы UNIX-систем с поддержкой AMD64 появились всего лишь несколькими месяцами позже представления новых систем, так что если бы этим дело и ограничилось, то особых поводов для беспокойства не возникло. Но, к сожалению, драйверы для операционных систем — это часть ОС, и, волей-неволей, они тоже должны быть 64-битными. А поскольку драйверы пишут тысячи и десятки тысяч «сторонних разработчиков», которым отнюдь не улыбается одновременно поддерживать 32— и 64-битные версии, не говоря о том, чтобы создавать драйвер для «железки», выпуск которой уже два года как прекращен, то это уже очень серьезная проблема, не решенная до сих пор[Сообществу OpenSource проще: там почти ко всем драйверам идут исходники, и зачастую достаточно простой перекомпиляции исходников, чтобы получить из 32-битной версии 64-битную или наоборот. Юниксоиды вообще стараются по возможности создавать переносимый код, который можно использовать с минимумом изменений на разных платформах; но даже если перекомпиляции недостаточно, то «модификация» этих исходников с исправлением тонких мест, вызывающих проблемы с 64-битностью, в принципе доступна любому мало-мальски грамотному программисту. Поэтому с «опенсорсными» 64-битными драйверами особых проблем сейчас нет. А вот с «фирменными» (вроде поддерживающего в Linux аппаратное ускорение OpenGL-драйвера для видеокарт nVidia) есть, хотя вендоры и стараются оперативно их решать].
Второе «слабое место» 64-битных процессоров в том, что обработка 64-битных данных заведомо требует больше времени, чем обработка 32-битных, и, что еще важнее, 64-битные программы и данные к ним занимают в оперативной памяти гораздо больше места. А поскольку оперативная память — ресурс медленный и дефицитный (кэш-память, особенно кэши первого уровня, имеет конечные размеры), то вместе с возросшей вычислительной сложностью это приводит к сильному падению «чистой» производительности процессора в 64-битных режимах. А что вы хотели, за все нужно платить, и в классическом варианте за поддержку большого объема памяти, устранение «проблемы мусора» и упрощение процедуры маппинга файлов на память приходится расплачиваться сравнительно невысоким быстродействием процессора, подсистемы оперативной памяти и несовместимостью с ранее написанными драйверами. Разумеется, в перспективе мы никуда от этого не уйдем, но сегодня потенциальные недостатки 64-битности для обычного пользователя перевешивают ее потенциальные достоинства.
Но кто сказал, что x86-64 — это только 64-битные указатели, команды и регистры GPR?..
 Первое и, пожалуй, главное преимущество, которое получила архитектура x86-64, — долгожданная поддержка шестнадцати регистров общего назначения и шестнадцати регистров XMM. На первый взгляд это чисто количественное изменение, но на самом деле — принципиальная во всех отношениях доработка архитектуры IA-32. Судите сами: у современного IA-32 восемь регистров общего назначения (EAX, EBX, ECX, EDX, EDI, ESI, EBP и ESP), восемь 64-битных регистров MMX (MMX0—MMX7) и восемь же регистров SSE (XMM0—XMM7). Не замечаете ничего странного? Откуда вообще взялась цифра восемь? Для ответа на этот вопрос нам потребуется обратиться к «основам основ» — к формату x86-инструкций.
Первое и, пожалуй, главное преимущество, которое получила архитектура x86-64, — долгожданная поддержка шестнадцати регистров общего назначения и шестнадцати регистров XMM. На первый взгляд это чисто количественное изменение, но на самом деле — принципиальная во всех отношениях доработка архитектуры IA-32. Судите сами: у современного IA-32 восемь регистров общего назначения (EAX, EBX, ECX, EDX, EDI, ESI, EBP и ESP), восемь 64-битных регистров MMX (MMX0—MMX7) и восемь же регистров SSE (XMM0—XMM7). Не замечаете ничего странного? Откуда вообще взялась цифра восемь? Для ответа на этот вопрос нам потребуется обратиться к «основам основ» — к формату x86-инструкций.
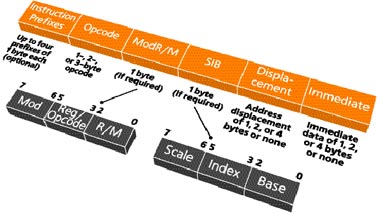
Каждая инструкция представляет собой длинную комбинацию из пяти составляющих: а) опкода (operation code, opcode), описывающего, что нужно сделать с данными, б) поля ModR/M, в котором записывается «подвид» инструкции, режим адресации памяти (как и у всякого CISC-процессорa, этих подвидов у x86 много) и один или два регистра, используемых инструкцией, в) поля SIB (Scale-Index-Base), в котором при некоторых режимах адресации памяти записываются еще два регистра (база и индекс) и масштаб, г) полей Displacement и Immediate, в них записываются используемые инструкцией константы, д) набора «приставок» (prefixes), позволяющих задать «нестандартные» режимы использования инструкции. Обязательным является только поле опкода, все остальные опциональны и могут отсутствовать[Теперь понимаете, что имелось в виду под «непомерной сложностью декодирования CISC-инструкций»?].
Оставим в стороне вопрос о том, для чего нужна столь сложная конструкция и как она работает, и сосредоточимся на одном-единственном интересующем нас аспекте: как в x86 кодируются используемые инструкциями операнды. Смотрите: поля Reg/Opcode[В принципе здесь может быть записан не регистр, а (для некоторых инструкций) дополнительный опкод, указывающий на ту или иную разновидность одной и той же инструкции] и R/M[Здесь тоже не всегда записывается регистр — иногда это поле используют для кодирования одной из 24 разновидностей режимов адресации памяти. В x86 много подобных «тонкостей»] занимают по три бита, поля Index и Base в SIB — тоже трехбитные. А трехбитных комбинаций, как легко посчитать, всего восемь, именно столько регистров может быть одновременно доступно любой программе. Так было задумано еще три десятка лет назад, при проектировании Intel 8086, и с тех пор ничего не изменилось, хотя Pentium 4 отличается от 8086, как небо от земли. Восемь регистров современных Athlon и Pentium не блажь разработчиков и не техническая необходимость, а фундаментальное ограничение самого набора инструкций x86.
 Что же делать, если нам хочется как-то обойти это ограничение, не теряя совместимости со старыми приложениями? К счастью, инженеры, проектировавшие x86 ISA, были очень талантливыми и прозорливыми, а потому заложили в архитектуру возможность вводить перед инструкциями приставки — специальные указатели, так или иначе изменяющие значения инструкций. Скажем, приставка LOCK говорит, что инструкция должна быть выполнена в «атомном» режиме["Атомный" режим — это когда выполнение инструкции гарантированно не будет прервано каким-нибудь внешним событием. К примеру, если мы что-нибудь записываем в оперативную память, то начиная с момента исполнения и до завершения атомной инструкции никто «посторонний» не сможет ни записать в то же место оперативной памяти, ни прочитать оттуда. Используется в многопроцессорных системах для организации межпроцессорного взаимодействия], приставки 2E и 2F подсказывают процессору, произойдет условный переход или нет, а приставка 66 приказывает переключаться между 16-битным и 32-битным представлением данных в регистрах. Поэтому когда разработчикам x86-64 понадобилось добавить в архитектуру IA-32 поддержку 64-битности, они сделали очень простую и в то же время гениальную вещь, введя набор 64-битных приставок REX, которые не столько расширяют возможности инструкций, сколько служат для кодирования дополнительной информации в четырех своих полях. Поле REX.W задает «размер» обрабатываемых данных: если здесь записан нолик, то обрабатываемые регистры интерпретируются как 32-битные, если единичка — то как 64-битные; а поля REX.R, REX.X и REX.B — старшие биты, дополняющие трехбитные поля ModR/M.Reg, SIB.Index и, в зависимости от ситуации, ModR/M.R/M или SIB.Base соответственно. Знаю, что это звучит не слишком понятно, поэтому тут же поясню, что это означает. На самом деле в 64-битном режиме мы используем 4-битную кодировку регистров процессора, но три младших регистровых бита записываем на их «традиционные» места в инструкции, а старший бит — переносим в приставку REX, обходя тем самым архитектурное ограничение. А заодно, помимо поддержки восьми новых GPR-регистров R8—R15 и SSE-регистров XMM8—XMM15, получаем возможность отключить 64-битные вычисления, когда они нам не требуются, — и пропорционально сэкономить на времени исполнения и занимаемом данными месте! И все это — одним-единственным байтом!
Что же делать, если нам хочется как-то обойти это ограничение, не теряя совместимости со старыми приложениями? К счастью, инженеры, проектировавшие x86 ISA, были очень талантливыми и прозорливыми, а потому заложили в архитектуру возможность вводить перед инструкциями приставки — специальные указатели, так или иначе изменяющие значения инструкций. Скажем, приставка LOCK говорит, что инструкция должна быть выполнена в «атомном» режиме["Атомный" режим — это когда выполнение инструкции гарантированно не будет прервано каким-нибудь внешним событием. К примеру, если мы что-нибудь записываем в оперативную память, то начиная с момента исполнения и до завершения атомной инструкции никто «посторонний» не сможет ни записать в то же место оперативной памяти, ни прочитать оттуда. Используется в многопроцессорных системах для организации межпроцессорного взаимодействия], приставки 2E и 2F подсказывают процессору, произойдет условный переход или нет, а приставка 66 приказывает переключаться между 16-битным и 32-битным представлением данных в регистрах. Поэтому когда разработчикам x86-64 понадобилось добавить в архитектуру IA-32 поддержку 64-битности, они сделали очень простую и в то же время гениальную вещь, введя набор 64-битных приставок REX, которые не столько расширяют возможности инструкций, сколько служат для кодирования дополнительной информации в четырех своих полях. Поле REX.W задает «размер» обрабатываемых данных: если здесь записан нолик, то обрабатываемые регистры интерпретируются как 32-битные, если единичка — то как 64-битные; а поля REX.R, REX.X и REX.B — старшие биты, дополняющие трехбитные поля ModR/M.Reg, SIB.Index и, в зависимости от ситуации, ModR/M.R/M или SIB.Base соответственно. Знаю, что это звучит не слишком понятно, поэтому тут же поясню, что это означает. На самом деле в 64-битном режиме мы используем 4-битную кодировку регистров процессора, но три младших регистровых бита записываем на их «традиционные» места в инструкции, а старший бит — переносим в приставку REX, обходя тем самым архитектурное ограничение. А заодно, помимо поддержки восьми новых GPR-регистров R8—R15 и SSE-регистров XMM8—XMM15, получаем возможность отключить 64-битные вычисления, когда они нам не требуются, — и пропорционально сэкономить на времени исполнения и занимаемом данными месте! И все это — одним-единственным байтом!
Вторая группа усовершенствований — отказ от поддержки безнадежно устаревших и давно не использующихся возможностей IA-32. В расширенном режиме не поддерживаются Real Mode и Virtual 8086-mode[Да-да, Virtual 8086 — это именно то, о чем вы сейчас подумали, — полная имитация процессора Intel 8086. Много ли найдется людей, которые пожалеют о его отсутствии?], и почти полностью отключена сегментация[Поскольку читатель уже заскучал от обилия технических фактов, не буду утомлять его описанием сегментированной модели памяти 80286, скажу только, что сегментация — это очень упрощенный аналог виртуальной памяти] (хотя некоторые настройки сегмента CS и сегменты FS/GS все же можно использовать); не поддерживаются инструкции, работавшие с этими сегментами, и инструкции, оперировавшие BCD-числами[BCD (Binary Coded Decimal) — это когда десятичное число записывается шестнадцатеричными цифрами. Например, 54d — в виде 54h = 01010100b вместо традиционных 36h = 00110110b]. Все это позволяет заметно облегчить процессору жизнь и в перспективе — повысить его производительность. К примеру, отказ от сегментации позволяет при обращении к оперативной памяти не вычислять линейный адрес и не проверять его допустимость в рамках сегмента, а значит, эффективность этой подсистемы при переходе к x86-64 существенно возрастет.
«А как обстоят дела с совместимостью со старыми программами?» — спросит читатель. Посмотрим: если обойтись без приставки REX, то процессор будет считать, что все записанные там данные — нули, то есть новые регистры не используются, а размер операндов инструкции равен 32 битам, то есть старшие 32 бита каждого 64-разрядного регистра при подобных вычислениях явным образом забиваются нулями. Как легко догадаться, инструкция без префикса REX даже в 64-битном режиме будет работать точно так же, как она работала и в 32-битном; и если соблюдать меры предосторожности (в частности, не выходить при адресации за границу «нижних 4 Гбайт» виртуальной памяти, то даже в 64-битном режиме все программы будут работать как и в 32-битном! Красивое решение? Мне кажется, да. Если программе не требуется поддержка всяческих «64-битностей», то она может запросто продолжать работать на «физически» 64-битном процессоре в 32-битном режиме, не используя ни 64-битные указатели, ни 64-битные вычисления, зато «радуясь» удвоенному количеству регистров и другим улучшениям x86.
8, 16, 32, 64…
Что вообще такое «разрядность процессора»? Как ни странно, это отнюдь не максимальный размер обрабатываемых данных. Складывать и вычитать 64-битные числа x86-процессоры умеют еще со времен Intel Pentium MMX; более того — даже i486 мог работать не только с 64-битными, но и с 80-битными числами, записанными в формате длинной двойной точности с плавающей запятой (long double). И если уж проводить аналогию дальше, то обрабатываемые инструкциями SSE-наборов операнды (регистры XMM) вообще имеют длину 128 бит. Но поддержка инструкций MMX, x87 и SSE 1/2/3 отнюдь не делает процессор 64-, 80— или 128-битным. Грубо говоря, по возможностям вычислений 64-битный процессор теоретически почти ничем не отличается от 32-битного, но достаточно продвинутого собрата[На самом деле, 32-разрядные процессоры, например, не умеют перемножать целочисленные 64-битные числа и делить 128-битные целые числа на 64-битное число, но это уже детали]. Да, работать с ним не так удобно, но при желании можно. В любом случае, соответствующие данные (long long integer или __int64, в общепринятой терминологии языка C) в программах встречаются нечасто.Так в чем же дело?
А в том, что и x87, и SSE — расширенные наборы инструкций, работающие со специализированными регистрами процессора. Они никак не затрагивают сердце процессора — его базовый набор инструкций (Instruction Set Architecture, ISA) и базовые регистры общего назначения (General Purpose Registers, GPR), равно как и некоторые «представления» процессора об окружающем его мире. Лирик, наверное, не упустил бы здесь возможности немного пофилософствовать на тему подобных «неощутимых» с первого взгляда, но очень глубоких по своей сути различий, но я не философ, а математик, и потому просто скажу, что на практике главное отличие GPR-регистров от всех остальных в том, что их можно использовать для адресации оперативной памяти. То есть 64-битный процессор — это не тот, который в принципе может работать с 64-битными числами (хотя это он тоже должен уметь делать, выполняя с 64-битными целыми числами все базовые арифметические операции), а тот, который способен этими числами «нумеровать» ячейки памяти.Чтобы было понятнее, о чем идет речь, поясняю: стандартная модель записи целочисленных чисел позволяет записать в 32-разрядный GPR-регистр процессора архитектуры IA-32 любое целое число от 0 до 232—1. Оперативная память с точки зрения прикладных приложений представляется здесь в виде эдакой длинной ленты из ячеек определенного размера (1 байт в x86), причем все они «пронумерованы» — ячейка 0, ячейка 1 и так далее, вплоть до ячейки 4.294.967.295. Какие-то ячейки могут «отсутствовать» — в этом случае обращение к ним будет вызывать ошибку, однако потенциальная возможность обратиться к этой ячейке существует всегда. А вот у 32-разрядного процессора возможности обратиться к ячейке 4.294.967.295 нет в принципе — просто потому, что он не сможет «дать ей название».
Что это означает на практике? Только то, что ни одна «классическая» 32-битная программа не может использовать больше 4 Гбайт (232/210*210*210) памяти. Поэтому если вы спросите продавца о преимуществах 64-разрядного процессора, то именно эту сакральную фразу о «поддержке большого объема оперативной памяти» (вместе с вопросом «а оно вам надо?») и услышите. Но все-таки не спешите сводить эту возможность к установке в систему четырех двухгигабайтных планок SDRAM. Все далеко не так просто.
64-разрядность и оперативная память
Первая «особенность», о которой часто забывают, рассматривая 64-разрядные процессоры, — это то, что во всех современных компьютерах программы работают не с физической, а с виртуальной оперативной памятью, то есть программная адресация памяти может не совпадать с действительным расположением этой памяти в компьютере. В нашей модели длинной ленты ячеек мы можем нумеровать их в произвольном порядке (0, 6533, 21, 554, 54223563, 2, …). Это очень удобно в многозадачных операционных системах: по-разному пронумеровав ячейки и раздав их разным приложениям (после чего в памяти образуется каша, когда данные разных программ лежат вперемешку), на логическом уровне мы сохраняем линейность и стройность, поскольку каждая программа работает не с этой кашей, а с виртуальным пространством адресов, в которое попадают данные только этой программы, и расположенные именно так, как программе привычно.Впрочем, перенумерацией дело не ограничивается, поскольку вместе с номерами указываются всяческие атрибуты — «только для чтения», «только для операционной системы» и пр. Вдобавок для некоторых ячеек можно указать, что они в оперативную память «пока не загружены». Встретив такую пометку, CPU генерирует специальную системную ошибку (Page Fault) и обращается за помощью к операционной системе, которая может, к примеру, загрузить данные для этой ячейки с жесткого диска (техника своппинга). Поэтому всегда следует помнить, что «ограничение 4 Гбайт» в первую очередь относится не к физической, а к виртуальной оперативной памяти, доступной процессу. А вот что стоит за этими четырьмя гигабайтами адресного пространства — скромные ли 128 Мбайт памяти SDRAM или кусочек от пары терабайтов дискового массива — неважно: собственно процессор этот «реальный мир» почти ничем не ограничивает.
Но все же — что дает разрядность? Если процессор поддерживает длинные физические адреса (в архитектуре x86 соответствующий режим называется Physical Address Extension, PAE[Если подробнее, то в PAE используется 52-битная адресация, позволяющая адресовать до четырех петабайт данных]), то мы можем поставить на сервер хоть 64 Гбайт оперативной памяти и выделять ее разным приложениям. Условия вроде «не более двух гигов для чипсета такого-то» — это ограничения именно чипсета, не умеющего обслуживать большой объем памяти, а не 32-разрядной системы. Поэтому в серверных приложениях, когда на одном сервере, как правило, запущено несколько десятков одновременно работающих приложений, пресловутый «барьер в 4 Гбайт» практически не ощущается. Но означает ли это, что сегодня 64-разрядный x86 никому не нужен?
Конечно, нет! 64-разрядность виртуальной памяти в приложениях востребована уже сейчас, просто эти «добавочные биты» используются другими способами.
Во-первых, какую-то часть виртуального адресного пространства может забирать операционная система. К примеру, MS Windows обычно использует для своих нужд старший бит виртуального адреса, ограничивая адресное пространство запущенного в ней приложения 31 битом и 2 Гбайт адресного пространства. А два гигабайта оперативной памяти, согласитесь, куда ближе к реальной жизни, нежели гипотетические четыре; и ситуацию, когда их начнет не хватать, представить гораздо проще. Можно, правда, попытаться использовать специальный режим, когда Windows будет предоставлять процессам не два, а три гига адресного пространства, но работает он, к сожалению, далеко не всегда, зачастую роняя при неправильной настройке операционную систему.
Во-вторых, линейное адресное пространство подвержено «засорению» — процессу, в ходе которого в нем образуются дырки, которые невозможно использовать. Программы часто оперируют не байтами и словами, а гораздо более крупными структурами, занимающими десятки, сотни и даже миллионы байт информации. Если мы использовали эту структуру, а затем необходимость в ней отпала, то в памяти остается дыра, совпадающая по размерам и расположению с местом, где лежали данные этой структуры. И удастся ли сию дыру использовать — еще бабушка надвое сказала. Иногда почти вся оперативная память состоит из дырок, не несущих никакой практической пользы, и места для записи даже небольшого объема данных не находится[Подобным особенно грешат операционные системы и среды разработки компании Microsoft: менеджер памяти, используемый в Windows, не столь эффективен, как его UNIX-собратья, и «мусора» в памяти оставляет гораздо больше. Иногда это приводит к тому, что нормально работающие на UNIX программы, использующие вдобавок сравнительно небольшой объем оперативной памяти, в MS Windows через некоторое время вылетают с ошибкой Out of memory].
В-третьих, существует такая интересная техника, как маппинг файлов на оперативную память. «Маппить» можно что угодно, причем это не только самый быстрый, но и один из самых удобных способов обработки файлов. Не нужно ничего читать из файла или записывать в него, не нужно думать об эффективном кэшировании данных — все происходит автоматически. Просто «мапнул» файл на память — и находившиеся в нем данные волшебным образом мгновенно оказались доступными приложению. В «настоящую» оперативную память они будут подгружаться только при обращении к ним, а в случае длительной «невостребованности» — вновь возвращаться на жесткий диск, освобождая место для чего-нибудь более актуального. Реализовать что-либо подобное «вручную» — практически невозможно. Но, к сожалению, на двух гигабайтах адресного пространства Windows особенно не развернешься[И на 4 Гбайт своп-файла, которыми нас обычно ограничивает Windows (ругать так ругать!), — зачастую тоже], поэтому техника маппинга задействуется только тогда, когда высокая скорость обработки файлов для приложения становится критичной.
Поэтому даже если бы в технологиях EM64T/AMD64 не было бы ничего сверх возможности оперировать с 64-битными указателями[Указатель на оперативную память (обычно просто говорят: указатель) — это ячейка памяти, в которой записывается номер другой ячейки. То есть, к примеру, мы можем как-то использовать в программе это число (номер ячейки) — присваивать его, изменять, увеличивать или уменьшать, а потом вызвать специальную операцию «разыменования» — взятия данных, расположенных по этому адресу в оперативной памяти. В C/C++ и подобных языках программирования указатели выделены в самостоятельный тип данных, и программист работает с ними «вручную»; в других языках «арифметику» указателей от программиста прячут, предлагая работать с более высокоуровневыми абстракциями, однако в машинном коде и оперативной памяти указатели встречаются почти всегда] на оперативную память, они по-прежнему оставались бы востребованными и своего покупателя все равно бы нашли. Но стоила бы в этом случае овчинка выделки?
Явные недостатки x86-64
Это не такая уж катастрофа, как может показаться: современные процессоры умеют быстро переключаться между 32— и 64-битным режимами, однако как минимум одно приложение, работающее на 64-битном компьютере, эти «нововведения» все-таки должно поддерживать. Ибо если даже операционная система, заведующая менеджментом виртуального адресного пространства, будет работать в 32-битном режиме, то ради чего мы боролись? Поэтому сформулируем «принцип номер один» для 64-битных систем: для поддержки 64-битности операционная система тоже должна быть 64-битной. Правда, объем переделок, которые для этого требуются, велик, но не бесконечен — релизы UNIX-систем с поддержкой AMD64 появились всего лишь несколькими месяцами позже представления новых систем, так что если бы этим дело и ограничилось, то особых поводов для беспокойства не возникло. Но, к сожалению, драйверы для операционных систем — это часть ОС, и, волей-неволей, они тоже должны быть 64-битными. А поскольку драйверы пишут тысячи и десятки тысяч «сторонних разработчиков», которым отнюдь не улыбается одновременно поддерживать 32— и 64-битные версии, не говоря о том, чтобы создавать драйвер для «железки», выпуск которой уже два года как прекращен, то это уже очень серьезная проблема, не решенная до сих пор[Сообществу OpenSource проще: там почти ко всем драйверам идут исходники, и зачастую достаточно простой перекомпиляции исходников, чтобы получить из 32-битной версии 64-битную или наоборот. Юниксоиды вообще стараются по возможности создавать переносимый код, который можно использовать с минимумом изменений на разных платформах; но даже если перекомпиляции недостаточно, то «модификация» этих исходников с исправлением тонких мест, вызывающих проблемы с 64-битностью, в принципе доступна любому мало-мальски грамотному программисту. Поэтому с «опенсорсными» 64-битными драйверами особых проблем сейчас нет. А вот с «фирменными» (вроде поддерживающего в Linux аппаратное ускорение OpenGL-драйвера для видеокарт nVidia) есть, хотя вендоры и стараются оперативно их решать].
Второе «слабое место» 64-битных процессоров в том, что обработка 64-битных данных заведомо требует больше времени, чем обработка 32-битных, и, что еще важнее, 64-битные программы и данные к ним занимают в оперативной памяти гораздо больше места. А поскольку оперативная память — ресурс медленный и дефицитный (кэш-память, особенно кэши первого уровня, имеет конечные размеры), то вместе с возросшей вычислительной сложностью это приводит к сильному падению «чистой» производительности процессора в 64-битных режимах. А что вы хотели, за все нужно платить, и в классическом варианте за поддержку большого объема памяти, устранение «проблемы мусора» и упрощение процедуры маппинга файлов на память приходится расплачиваться сравнительно невысоким быстродействием процессора, подсистемы оперативной памяти и несовместимостью с ранее написанными драйверами. Разумеется, в перспективе мы никуда от этого не уйдем, но сегодня потенциальные недостатки 64-битности для обычного пользователя перевешивают ее потенциальные достоинства.
Но кто сказал, что x86-64 — это только 64-битные указатели, команды и регистры GPR?..
IA-32 versus x86-64
Переделывая почти весь процессор и весь набор поддерживаемых им инструкций, мы все равно получаем несовместимость в 64-битном режиме со старыми программами. Так почему бы заодно не исправить ошибки предшественников и не убрать из x86 устаревшие ограничения? 64-битный режим не просто улучшенная версия IA-32 ISA, фактически это следующая версия архитектуры x86, во многом лишенная «родовых травм» этого семейства, начинавшегося с микроконтроллеров и долгое время не претендовавшего на «серьезное» использование.Каждая инструкция представляет собой длинную комбинацию из пяти составляющих: а) опкода (operation code, opcode), описывающего, что нужно сделать с данными, б) поля ModR/M, в котором записывается «подвид» инструкции, режим адресации памяти (как и у всякого CISC-процессорa, этих подвидов у x86 много) и один или два регистра, используемых инструкцией, в) поля SIB (Scale-Index-Base), в котором при некоторых режимах адресации памяти записываются еще два регистра (база и индекс) и масштаб, г) полей Displacement и Immediate, в них записываются используемые инструкцией константы, д) набора «приставок» (prefixes), позволяющих задать «нестандартные» режимы использования инструкции. Обязательным является только поле опкода, все остальные опциональны и могут отсутствовать[Теперь понимаете, что имелось в виду под «непомерной сложностью декодирования CISC-инструкций»?].
Оставим в стороне вопрос о том, для чего нужна столь сложная конструкция и как она работает, и сосредоточимся на одном-единственном интересующем нас аспекте: как в x86 кодируются используемые инструкциями операнды. Смотрите: поля Reg/Opcode[В принципе здесь может быть записан не регистр, а (для некоторых инструкций) дополнительный опкод, указывающий на ту или иную разновидность одной и той же инструкции] и R/M[Здесь тоже не всегда записывается регистр — иногда это поле используют для кодирования одной из 24 разновидностей режимов адресации памяти. В x86 много подобных «тонкостей»] занимают по три бита, поля Index и Base в SIB — тоже трехбитные. А трехбитных комбинаций, как легко посчитать, всего восемь, именно столько регистров может быть одновременно доступно любой программе. Так было задумано еще три десятка лет назад, при проектировании Intel 8086, и с тех пор ничего не изменилось, хотя Pentium 4 отличается от 8086, как небо от земли. Восемь регистров современных Athlon и Pentium не блажь разработчиков и не техническая необходимость, а фундаментальное ограничение самого набора инструкций x86.
Вторая группа усовершенствований — отказ от поддержки безнадежно устаревших и давно не использующихся возможностей IA-32. В расширенном режиме не поддерживаются Real Mode и Virtual 8086-mode[Да-да, Virtual 8086 — это именно то, о чем вы сейчас подумали, — полная имитация процессора Intel 8086. Много ли найдется людей, которые пожалеют о его отсутствии?], и почти полностью отключена сегментация[Поскольку читатель уже заскучал от обилия технических фактов, не буду утомлять его описанием сегментированной модели памяти 80286, скажу только, что сегментация — это очень упрощенный аналог виртуальной памяти] (хотя некоторые настройки сегмента CS и сегменты FS/GS все же можно использовать); не поддерживаются инструкции, работавшие с этими сегментами, и инструкции, оперировавшие BCD-числами[BCD (Binary Coded Decimal) — это когда десятичное число записывается шестнадцатеричными цифрами. Например, 54d — в виде 54h = 01010100b вместо традиционных 36h = 00110110b]. Все это позволяет заметно облегчить процессору жизнь и в перспективе — повысить его производительность. К примеру, отказ от сегментации позволяет при обращении к оперативной памяти не вычислять линейный адрес и не проверять его допустимость в рамках сегмента, а значит, эффективность этой подсистемы при переходе к x86-64 существенно возрастет.
«А как обстоят дела с совместимостью со старыми программами?» — спросит читатель. Посмотрим: если обойтись без приставки REX, то процессор будет считать, что все записанные там данные — нули, то есть новые регистры не используются, а размер операндов инструкции равен 32 битам, то есть старшие 32 бита каждого 64-разрядного регистра при подобных вычислениях явным образом забиваются нулями. Как легко догадаться, инструкция без префикса REX даже в 64-битном режиме будет работать точно так же, как она работала и в 32-битном; и если соблюдать меры предосторожности (в частности, не выходить при адресации за границу «нижних 4 Гбайт» виртуальной памяти, то даже в 64-битном режиме все программы будут работать как и в 32-битном! Красивое решение? Мне кажется, да. Если программе не требуется поддержка всяческих «64-битностей», то она может запросто продолжать работать на «физически» 64-битном процессоре в 32-битном режиме, не используя ни 64-битные указатели, ни 64-битные вычисления, зато «радуясь» удвоенному количеству регистров и другим улучшениям x86.