Фактически развитие собственно «архитектуры» x86-процессоров долгое время стояло на месте: что древний Pentium Pro, что новейший Pentium M - все они основаны на одной и той же старой-престарой архитектуре P6. Вылизанной, оптимизированной, но старой - ибо повода для ее смены до сих пор просто не было; «внутреннее представление» x86-кода, несмотря на все внесенные в x86 новации, с тех самых древних времен «чистой IA-32» вплоть до появления технологии AMD64 практически не изменялось.
К сожалению, нет места для рассказа об архитектурах VLIW и Cell - потенциальных претендентов на замену суперскалярных OoO-процессоров, так что о них мы поговорим в следующий раз. А пока рассмотрим самые популярные примеры «классических» подходов - в их видении Intel и AMD.
Блок предсказания переходов
Да-да, именно так называется этот странный блок! Но «гадание на кофейной гуще» здесь ни при чем - переходы предсказываются на основе вполне научных соображений. Обычно используется очень простой способ: в процессоре ведется табличка ранее совершенных переходов - для каждого условного перехода подсчитывается, сколько раз он «сработал», а сколько - «был проигнорирован». Поэтому, скажем, когда процессор встречает переход, замыкающий какой-нибудь цикл, то он быстренько начинает считать: раз переход сработал, два сработал, три сработал - ну, значит, наверное, он всегда будет срабатывать, вот так и будем предсказывать, что переход всегда происходит. То, что мы один раз в конце цикла ошибемся, - не беда, зато ценой максимум двух ошибок мы добьемся точного предсказания во всех остальных случаях. Кстати, на простых циклах процессор, как правило, ошибается еще реже - не более одного раза: по умолчанию, когда не из чего выбирать, считается, что условный переход всегда происходит.
При неправильном предсказании конвейер обычно приходится «сбрасывать», каким-то образом восстанавливая состояние процессора, предшествующее моменту неправильного перехода. А ведь пока исполнялась неправильная ветка, там ого-го сколько всего могло случиться! Неправильный опкод (нераспознаваемая машинная инструкция), обращение к виртуальной памяти (провоцирующее исключение в процессоре), некстати распознанное деление на ноль (тоже ошибка). Все это приходится тщательно отслеживать и проверять, причем это не шутки: одно время из-за ошибки в реализации конвейера процессора AMD K5, программист, написавший конструкцию если x A 0, то y = 1/x, иначе y = 0, запросто мог получить при x @ 0 на, казалось бы, ровном месте ошибку «деление на ноль», вызванную неправильным предсказанием перехода. А в OoO-процессорах ситуация еще сложнее - пока «тормозит» не вовремя отправившаяся за операндами в оперативную память инструкция, процессор успевает пропустить вперед, выполнить и едва ли не сохранить результат вычисления десятков инструкций неправильной ветки: попробуй за всем этим уследить!
Но бороться здесь есть за что: для современных процессоров каждая ошибка предсказания - это десятки вхолостую израсходованных тактов. Сущая катастрофа, если учитывать, что за каждый такт можно было бы исполнить до трех x86-инструкций и совершить кучу вычислений. Если бы блока предсказания не было, то так «тормозил» бы каждый условный переход.
Точность предсказания современных блоков составляет на тестах SPEC порядка 98-99%. Может показаться, что совершенствовать блок не имеет смысла, но это не совсем так. Дело в том, что на производительности гораздо больше сказывается процент ошибок, а не верных предсказаний. А переход от 98-процентной точности к 99-процентной означает двукратное снижение ошибок - с 2% до 1%! Поэтому если вы внимательно почитаете пресс-релизы о новых CPU, то заметите, что «усовершенствованный блок предсказания переходов» упоминается в них почти всегда.
В архитектуре IA-64 техника предсказания переходов сделала значительный шаг вперед - эти процессоры умеют одновременно вычислять несколько веток программного кода. То есть, встретив инструкцию условного перехода, процессор начинает «охотиться за двумя зайцами» - просчитывать оба варианта развития событий вплоть до того момента, пока не станет ясно, какой из них правильный. Поскольку инструкции «разных вариантов» практически не зависят друг от друга, а исполнительные устройства Itanium обычно загружены далеко не полностью, то исполнять побочную ветку нередко удается практически с той же скоростью, что и основную, так что даже при неправильном предсказании условного перехода происходит не остановка процессора на пару десятков тактов, а всего лишь снижение производительности на небольшом участке кода.
Архитектура PowerPC
Последняя из ныне здравствующих процессорных RISC-архитектур - это, конечно же, знаменитая PowerPC, детище альянса Apple, IBM и Motorola (AIM). Сегодня на PowerPC есть четкие спецификации, следуя которым любой желающий может разработать совместимый с ним процессор. Ничего особо интересного в нем нет - это самый что ни на есть классический RISC-процессор без специальных «примочек». Существуют 32- и 64-разрядные версии PowerPC (причем 64-разрядные совместимы с 32-разрядным кодом), а равно и ряд стандартизованных расширений (типа эппловского набора инструкций AltiVec). В то время как MIPS и ARM «специализировались» на тех или иных применениях, PowerPC, подобно x86, позиционировалась в основном для обычных персоналок и серверов. Вплоть до 2001 года x86 и PowerPC развивались более или менее синхронно, однако из-за технологических проблем и неспособности угнаться за процессорами AMD и Intel в «гонке мегагерц» PPC шаг за шагом сдавала позиции. А исчерпав «запас прочности» и застряв на частотах 1,0-1,4 ГГц, она стала стремительно проигрывать архитектуре x86, по-прежнему сохранявшей высокие темпы развития из-за ожесточенной схватки Intel и AMD. Поскольку «отступать» PowerPC было в общем-то некуда (нишу интегрированных процессоров оккупировали ARM и MIPS), то многие посчитали ее верным кандидатом на вымирание. Даже Apple недавно «отреклась» от своей архитектуры, переметнувшись в стан приверженцев x86. Только крайне дорогие серверные процессоры POWER, выпускавшиеся на пределе технологических возможностей Голубого гиганта (Power4, в частности, стали первыми в мире двухъядерниками), еще довольно уверенно чувствуют себя в линейке продуктов IBM.
Однако ситуация, похоже, начала меняться: именно архитектура PowerPC положена в основу будущих многоядерных процессоров всех игровых приставок шестого поколения (от Sony, Microsoft и Nintendo), поскольку ни MIPS, ни тем более ARM на эту роль не годятся; процессоры Intel в их текущем варианте плохо подходят для создания игровых приставок нового поколения; о процессорах AMD и говорить не приходится - компания просто не в состоянии обеспечить достаточный объем их производства. Вот и остается единственным кандидатом на роль нового «суперпроцессора» только всем доступная, технологически более простая, нежели x86, и достаточно производительная архитектура PowerPC. Что еще важнее для PPC, именно она положена в качестве аппаратной основы концепции Cell, которая, возможно, станет следующим шагом в развитии компьютинга. Так что пожелаем РРС удачи - от наличия на рынке множества альтернатив пользователи только выигрывают, и видеть в обозримом будущем абсолютную монополию x86, даже в варианте AMD64, лично мне не хотелось бы.
Устройство процессоров AMD архитектуры K8
Архитектура K8 используется во всех современных серверных, десктопных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера[Время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память] варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до трех; тактовые частоты серийно выпускаемых процессоров - от 1,6 до 2,8 ГГц.
Об особенностях организации архитектуры K8, связанных с интегрированным контроллером памяти, линками HyperTransport и неоднородной моделью памяти SUMa мы подробно писали в статье про двухъядерные процессоры; в остальном же - перед нами вполне классический процессор Гарвардской архитектуры. Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) - фиксирован и составляет по 64 Кбайт; имеется общий эксклюзивный[Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш - когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти нижележащих] кэш второго уровня объемом от 128 до 1024 Кбайт; кэш третьего и более низких уровней не предусмотрен, но в рамках протокола MOESI процессоры в многопроцессорных системах могут обращаться к кэш-памяти других процессоров.
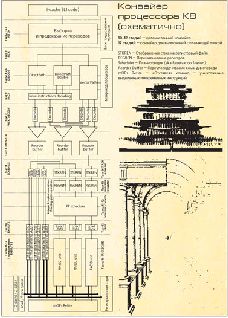 Исполнение инструкций на конвейере K8, как и положено, начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 - сколько в выбранных данных поместилось[Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт]. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы - в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86. Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I-cache; при вытеснении данных из L1 в L2 теги сохраняются.
Исполнение инструкций на конвейере K8, как и положено, начинается с блока выборки инструкций. За один такт блок выбирает из кэша 16 байт данных и выделяет из них от одной до трех инструкций x86 - сколько в выбранных данных поместилось[Поскольку средняя длина инструкции x86 составляет 5-6 байт, то, как правило, блоку удается выбрать три инструкции за такт]. Чтобы облегчить процесс декодирования, инструкции, хранящиеся в кэшах L1, тегированы - в линейках кэша сохраняется информация о том, как внутри этой линейки распределены инструкции x86. Попутно с помощью блока предсказания переходов в этом же такте определяется адрес блока, с которого начнется выборка в следующем такте. Тегирование производится при выборке данных из кэша L2 в кэш L1 I-cache; при вытеснении данных из L1 в L2 теги сохраняются.
На втором такте работы конвейера свежевыбранные одна-три инструкции x86 распределяются по трем блокам декодирования инструкций. Самые сложные инструкции, требующие декодирования с использованием микрокода процессора, отправляются в декодер VectorPath. Более простые - в декодеры DirectPath: те, что попроще, - в обычный, те, что посложнее, - в сдвоенный DirectPath Double. Начиная с этого момента процессор «забывает» о существовании x86 и переключается на работу с внутренними микроинструкциями (mOP).
Весь дальнейший конвейер строится на том, что работа с mOP’ами происходит тройками инструкций (AMD называет их линиями, line). С логической точки зрения конвейер K8 строится таким образом, что обрабатывает именно линии, а не x86-инструкции или отдельные микрооперации. При этом в одной линии может быть меньше трех микроопераций - тогда «недосдачу» в тройке заполняют специальные пустые операции (null-mOP). При этом со «сложными» vector-инструкциями все элементарно - VectorPath-декодер подставляет на их место прошитые в микрокоде процессора линии; а вот декодирование «простых» инструкций выливается в сложный процесс превращения x86-инструкции в один (DirectPath) или два (DirectPath Double) mOP’а, которые потом перетасовываются и упаковываются в одну линию специальным упаковщиком[В этом упаковщике, который, в частности, научился эффективно управляться с разбивающимися на два mOP’а инструкциями SSE, и скрыто важнейшее усовершенствование конвейера K8 по сравнению с конвейером K7 (процессоры Athlon/Athlon XP). Изменение декодера (и значительное увеличение времени на декодирование), усовершенствование планировщика инструкций - казалось бы, мелочи, но эффект огромный. Кстати, отсюда следует, что конвейер K8 практически не оптимизировался для достижения высоких тактовых частот - неудивительно, что на старом 130-нм технологическом процессе он и не показал существенно более высоких тактовых частот, нежели старичок K7]. На весь процесс в нормальных условиях уходит пять тактов конвейера.
Сгенерированные линии от VectorPath- и DirectPath-декодеров по одной за такт поступают в специальное устройство - Instructions Control Unit (ICU), где подготовленные к исполнению линии накапливаются в специальной очереди (24 линии). О том, что происходит дальше, поясним с помощью аналогии.
Предположим, что наша программа - это книжка, в которой записано, как процессору нужно обрабатывать данные. Что делает процессор? Упоминавшийся блок выборки вырывает из книжки страничку с текстом (будем считать, что странички достаточно маленькие) и выбирает из нее от одной до трех содержательных частей, которые передает декодеру. Декодер читает выделенные фрагменты текста и конвертирует их в четкие инструкции, указывающие, что и в какой последовательности нужно сделать. Инструкции (по одной) он записывает на бумажках (mOP’ах) и упаковывает в конверты - до трех бумажек в один конверт (линию). Конверты поступают в специальную картотеку - ICU, где их вскрывает и прочитывает специальный человек.
Что дальше? Претендентов на декодированные инструкции два - блок целочисленных вычислений (ALU) и блок вычислений с плавающей точкой (FPU). Когда блоки готовы принять очередную инструкцию, они сообщают об этом человеку в картотеке; человек копается в своих конвертах и выбирает из них в произвольном порядке, как ему удобнее, до трех бумажек-инструкций, которые и раздает ALU и FPU. Единственное ограничение, которое при этом накладывается, - человек никогда не передает ALU и FPU те инструкции, выполнение которых зависит от еще не переданных. Блоки ALU/FPU каким-то хитрым образом выполняют полученные инструкции, но результаты отсылают не во «внешний мир», а в нашу картотеку-ICU, где их кладут в тот же самый конверт, в котором лежали инструкции. Даже если происходит ошибка выполнения, процессор не сообщает о ней сразу, а сперва записывает информацию об ошибке на конверте; когда настанет пора вскрыть конверт - вот тогда он про нее и сообщит. Чтобы потом эти данные использовать - применяется довольно хитрая техника (та самая, из сноски 4), позволяющая вновь выполняемым инструкциям обращаться к еще «официально несуществующим» данным. Когда для конверта все инструкции оказываются выполненными, а конверт стоит первым в очереди и больше не содержит инструкций, но лишь результаты их исполнения - то полученные результаты «объявляются официальными», а конверт выбрасывается (отставка линий). Иногда, если при вскрытии очередного конверта выясняется, что ранее была допущена ошибка при предсказании условного перехода или при выполнении содержащейся в конверте инструкции, дело до этого и не доходит - конвейер приходится «сбрасывать», то есть смотреть на последнем конверте адрес того самого неудачного перехода, выкидывать всю накопленную к текущему моменту картотеку со всеми ее результатами и начинать выполнение с того самого места, где произошло неверное предсказание перехода. Благодаря тому, что результаты выброшенных конвертов еще не были «объявлены официальными», а «рвем» мы конверты строго в той же очередности, в которой они к нам в очередь поступали - допущенная ошибка «никому не станет известна» - результаты выполнившихся «вперед батьки» инструкций автоматически будут аннулированы.
Если теперь вернуться к технологическому описанию конвейера, то изложенный выше процесс с конвертами происходит следующим образом. Из очереди в 24 линии по три mOP’а в каждой ICU выбирает в наиболее удобной для исполнения последовательности один-три mOP’а и пересылает их либо на ALU, либо на FPU - в зависимости от типа микрооперации. В случае ALU микрооперации сразу же попадают в очередь планировщика (шесть элементов по три mOP’а), который подготавливает необходимые для исполнения микрооперации ресурсы, дожидается их готовности и только потом отправляет mOP вместе со всеми необходимыми данными на исполнение. Причем при исполнении одного mOP’а на самом деле может происходить исполнение сразу двух действий - несложных арифметических вычислений, которые часто возникают при обращении к оперативной памяти (ими занимается блок Address Generation Unit, AGU), и «сложных», требующих вмешательства «полновесного» ALU, - соответствующая «двойка» микроинструкций (ROP) закладывается в mOP еще на стадии декодирования. Подготовка данных в планировщике занимает (в идеальном случае) один такт, исполнение - от одного (подавляющее большинство инструкций) до трех (при обращении к оперативной памяти) и даже пяти (64-битное умножение) тактов.
С блоком FPU все чуточку сложнее. Для начала вышедшие из ICU mOP’ы проходят две стадии по подготовке их операндов. Затем - накапливаются в планировщике FPU (двенадцать элементов по три mOP’а), который, по аналогии со своим целочисленным собратом, дожидается, пока данные для этих mOP’ов будут готовы, а исполнительные устройства освободятся, и разбрасывает накопленные mOP’ы по трем исполнительным устройствам. Но в отличие от целочисленной части конвейера (где содержатся по три одинаковых блока ALU и AGU), исполнительные устройства FPU «специализированы» - каждое производит только свой специфический набор действий над числами с плавающей запятой. Время выполнения: два такта на переименование и отображение регистров, один такт (в идеале) на планирование и ожидание операндов, четыре такта на собственно исполнение.
Финал же у всех закончившихся микроопераций один - они «возвращаются» в ICU с полученными результатами, и ICU, по мере готовности линий, потихоньку производит их отставку. На все про все в идеальных условиях у нас ушло 10-17 тактов, причем за каждый такт мы исполняли по три mOP’а (это обычно 1,5-3 инструкции x86).
Устройство процессоров Intel архитектуры NetBurst
Архитектура NetBurst сегодня лежит в основе всех процессоров Pentium 4, Xeon и Celeron. Эффективная длина конвейера в зависимости от варианта составляет 20 или 31 стадию. Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до четырех; тактовые частоты серийно выпускаемых процессоров - от 2,53 до 3,8 ГГц - это по всем показателям лучше данных по K8. Лучше, но, к сожалению, только сугубо теоретически и на специально подготовленном коде.
 NetBurst тщательно оптимизировалась для работы на высоких частотах, и назвать эту архитектуру классической можно только с большой натяжкой. Для начала упомянем хотя бы тот же Trace Cache (TC), заменяющий в NetBurst классический Гарвардский I-cache (L1 code). Идея состоит в том, что в NetBurst декодер вынесен за пределы собственно конвейера - процессор конвертирует x86-инструкции в свое внутреннее представление не на лету, как AMD K8, а заблаговременно, еще на стадии копирования кода в кэш-память первого уровня. Устроено это все так своеобразно (например, в процессе декодирования декодер убирает безусловные переходы, занимается предсказанием условных переходов и может едва ли не «разворачивать» циклы!), что внутреннему устройству Trace Cache и декодеру инструкций для него вообще можно посвятить отдельную статью (чего мы делать сейчас не будем; скажем только, что декодер для TC работает очень медленно). Точная длина соответствующего участка конвейера неизвестна, но составляет, по разным оценкам, от 10-15 до 30 тактов - то есть этот «скрытый» участок конвейера имеет длину едва ли не большую, чем «видимый». Таким образом, введение TC позволяет практически вдвое уменьшить эффективную длину конвейера (страшно даже представить NetBurst без Trace Cache)[С K8, кстати, та же самая история - декодированием и подготовкой инструкций занята примерно половина конвейера. Есть предположения, что в следующем поколении процессоров AMD - архитектуре K9 - появится и Trace Cache. Скажем, в K8 подобное нововведение уменьшило бы видимую длину конвейера до 6-7 стадий в целочисленных вычислениях и до 12 стадий в вычислениях с плавающей точкой!]! Емкость TC для всех NetBurst составляет 12 тысяч микроопераций; в терминах классического x86 это соответствует примерно 8-16 Кбайт кэша L1-data; причем работает TC и обслуживающая его логика на половинной частоте ядра и наполняется декодером с темпом не более одной новой инструкции за такт. Поэтому если процессор некстати вылетит на незакэшированный участок кода (а кэш маленький, и подобная ситуация вполне возможна), то от теоретически возможных четырех инструкций за такт в лучшем случае останется лишь одна. Подобные «резкие потери темпа» вообще свойственны архитектуре NetBurst; к счастью, такие ситуации возникают редко.
NetBurst тщательно оптимизировалась для работы на высоких частотах, и назвать эту архитектуру классической можно только с большой натяжкой. Для начала упомянем хотя бы тот же Trace Cache (TC), заменяющий в NetBurst классический Гарвардский I-cache (L1 code). Идея состоит в том, что в NetBurst декодер вынесен за пределы собственно конвейера - процессор конвертирует x86-инструкции в свое внутреннее представление не на лету, как AMD K8, а заблаговременно, еще на стадии копирования кода в кэш-память первого уровня. Устроено это все так своеобразно (например, в процессе декодирования декодер убирает безусловные переходы, занимается предсказанием условных переходов и может едва ли не «разворачивать» циклы!), что внутреннему устройству Trace Cache и декодеру инструкций для него вообще можно посвятить отдельную статью (чего мы делать сейчас не будем; скажем только, что декодер для TC работает очень медленно). Точная длина соответствующего участка конвейера неизвестна, но составляет, по разным оценкам, от 10-15 до 30 тактов - то есть этот «скрытый» участок конвейера имеет длину едва ли не большую, чем «видимый». Таким образом, введение TC позволяет практически вдвое уменьшить эффективную длину конвейера (страшно даже представить NetBurst без Trace Cache)[С K8, кстати, та же самая история - декодированием и подготовкой инструкций занята примерно половина конвейера. Есть предположения, что в следующем поколении процессоров AMD - архитектуре K9 - появится и Trace Cache. Скажем, в K8 подобное нововведение уменьшило бы видимую длину конвейера до 6-7 стадий в целочисленных вычислениях и до 12 стадий в вычислениях с плавающей точкой!]! Емкость TC для всех NetBurst составляет 12 тысяч микроопераций; в терминах классического x86 это соответствует примерно 8-16 Кбайт кэша L1-data; причем работает TC и обслуживающая его логика на половинной частоте ядра и наполняется декодером с темпом не более одной новой инструкции за такт. Поэтому если процессор некстати вылетит на незакэшированный участок кода (а кэш маленький, и подобная ситуация вполне возможна), то от теоретически возможных четырех инструкций за такт в лучшем случае останется лишь одна. Подобные «резкие потери темпа» вообще свойственны архитектуре NetBurst; к счастью, такие ситуации возникают редко.
Дальнейшее повествование я буду вести, указывая время исполнения инструкции для ядра Northwood (20-стадийный конвейер). Для более нового Prescott в целом справедливо все то же самое, просто время исполнения отдельных стадий слегка возросло.
Первые четыре такта работы конвейера - извлечение специальным блоком выборки инструкций из TC и второй этап предсказания условных переходов. В первый раз декодер TC уже пытался предсказать переход, так что второй этап предсказания фактически сводится к «угадыванию» того, правильно ли декодер угадал переход еще «в тот раз» или нет. Заодно для некоторых записей TC («закладок»["Закладки" позволяют увеличить эффективный объем Trace Cache, поскольку вместо нескольких mОР’ов мы храним в нем одну «закладку»]) происходит их «развертывание» в несколько микроопераций. В силу того что TC работает на половинной частоте ядра, происходит выборка довольно медленно и каждый ее этап занимает по два такта конвейера. Затем полученные микрооперации (до шести штук за такт) складываются в традиционную очередь выборки (Fetch Queue), где буферизуются, сглаживая неравномерность декодирования и обеспечивая «на выходе» устоявшийся темп декодирования в три микроинструкции за такт. Задержка, вносимая буферизацией, - 1 такт; еще 1 такт расходуется на то, чтобы подготовить внутренние ресурсы процессора для выбранной из Fetch Queue тройки mOP’ов. Затем еще два такта уходит на то, чтобы подготовить для каждого mOP’а персональные физические регистры для вычислений (в рамках техники переименования регистров). И, наконец, на последнем, девятом по счету такте полностью готовые к исполнению mOP’ы начинают «распихиваться» по очередям инструкций, стоящих на выполнение.
Зачем понадобилась вся эта каша с многократными очередями? Разработчики NetBurst пытались добиться того, чтобы все стадии конвейера были независимы друг от друга и работали асинхронно, без точной привязки к некой «единой тактовой частоте» процессора. Именно асинхронность (а не только длинный конвейер!) позволяет резко повысить тактовые частоты, на которых способно работать ядро процессора.
Вернемся к конвейеру NetBurst. Итак, подготовленные к исполнению инструкции на девятом такте распределяются по двум очередям - очереди для AGU-инструкций, обращающихся к оперативной памяти (длина - 16 mOР’ов), и очереди для всего остального (32 mOP’а). На следующем такте инструкции из этих очередей разбираются аж пятью независимо работающими планировщиками - планировщиком AGU, двумя «быстрыми» и двумя «медленным» планировщиками. «Быстрые» имеют дело лишь с некоторыми самыми простыми арифметико-логическими операциями и работают на удвоенной тактовой частоте процессора, успевая забирать из очередей по две простые инструкции за такт. Нужны они для того, чтобы загружать работой «быстрые» же исполнительные блоки, построенные на специальной быстродействующей логике и тоже работающие на удвоенной тактовой частоте (до 8 ГГц!), обрабатывая по две инструкции за такт. «Медленные» планировщики «специализируются» каждый на своем типе инструкций и работают на номинальной частоте ядра. Планировщики могут переупорядочивать микрооперации по своему усмотрению (OoO-исполнение); они же отслеживают ход выполнения микроопераций, при необходимости перезапускают их и в конце выполнения инструкции записывает полученные результаты в оперативную память; на все про все у них уходит еще три такта процессора. Наконец, планировщики через четыре порта запуска (порты частично общие, а это значит, что «быстрые» и «медленные» планировщики конкурируют друг с другом за то, кто из них получит право запускать в текущем такте подготовленные mOP’ы дальше) переправляют упорядоченные микрооперации в очереди диспетчеров, где они дожидаются «разрешения на запуск». И тут начинается самое интересное.
К сожалению, нет места для рассказа об архитектурах VLIW и Cell - потенциальных претендентов на замену суперскалярных OoO-процессоров, так что о них мы поговорим в следующий раз. А пока рассмотрим самые популярные примеры «классических» подходов - в их видении Intel и AMD.
Блок предсказания переходов
Да-да, именно так называется этот странный блок! Но «гадание на кофейной гуще» здесь ни при чем - переходы предсказываются на основе вполне научных соображений. Обычно используется очень простой способ: в процессоре ведется табличка ранее совершенных переходов - для каждого условного перехода подсчитывается, сколько раз он «сработал», а сколько - «был проигнорирован». Поэтому, скажем, когда процессор встречает переход, замыкающий какой-нибудь цикл, то он быстренько начинает считать: раз переход сработал, два сработал, три сработал - ну, значит, наверное, он всегда будет срабатывать, вот так и будем предсказывать, что переход всегда происходит. То, что мы один раз в конце цикла ошибемся, - не беда, зато ценой максимум двух ошибок мы добьемся точного предсказания во всех остальных случаях. Кстати, на простых циклах процессор, как правило, ошибается еще реже - не более одного раза: по умолчанию, когда не из чего выбирать, считается, что условный переход всегда происходит.
При неправильном предсказании конвейер обычно приходится «сбрасывать», каким-то образом восстанавливая состояние процессора, предшествующее моменту неправильного перехода. А ведь пока исполнялась неправильная ветка, там ого-го сколько всего могло случиться! Неправильный опкод (нераспознаваемая машинная инструкция), обращение к виртуальной памяти (провоцирующее исключение в процессоре), некстати распознанное деление на ноль (тоже ошибка). Все это приходится тщательно отслеживать и проверять, причем это не шутки: одно время из-за ошибки в реализации конвейера процессора AMD K5, программист, написавший конструкцию если x A 0, то y = 1/x, иначе y = 0, запросто мог получить при x @ 0 на, казалось бы, ровном месте ошибку «деление на ноль», вызванную неправильным предсказанием перехода. А в OoO-процессорах ситуация еще сложнее - пока «тормозит» не вовремя отправившаяся за операндами в оперативную память инструкция, процессор успевает пропустить вперед, выполнить и едва ли не сохранить результат вычисления десятков инструкций неправильной ветки: попробуй за всем этим уследить!
Но бороться здесь есть за что: для современных процессоров каждая ошибка предсказания - это десятки вхолостую израсходованных тактов. Сущая катастрофа, если учитывать, что за каждый такт можно было бы исполнить до трех x86-инструкций и совершить кучу вычислений. Если бы блока предсказания не было, то так «тормозил» бы каждый условный переход.
Точность предсказания современных блоков составляет на тестах SPEC порядка 98-99%. Может показаться, что совершенствовать блок не имеет смысла, но это не совсем так. Дело в том, что на производительности гораздо больше сказывается процент ошибок, а не верных предсказаний. А переход от 98-процентной точности к 99-процентной означает двукратное снижение ошибок - с 2% до 1%! Поэтому если вы внимательно почитаете пресс-релизы о новых CPU, то заметите, что «усовершенствованный блок предсказания переходов» упоминается в них почти всегда.
В архитектуре IA-64 техника предсказания переходов сделала значительный шаг вперед - эти процессоры умеют одновременно вычислять несколько веток программного кода. То есть, встретив инструкцию условного перехода, процессор начинает «охотиться за двумя зайцами» - просчитывать оба варианта развития событий вплоть до того момента, пока не станет ясно, какой из них правильный. Поскольку инструкции «разных вариантов» практически не зависят друг от друга, а исполнительные устройства Itanium обычно загружены далеко не полностью, то исполнять побочную ветку нередко удается практически с той же скоростью, что и основную, так что даже при неправильном предсказании условного перехода происходит не остановка процессора на пару десятков тактов, а всего лишь снижение производительности на небольшом участке кода.
Архитектура PowerPC
Последняя из ныне здравствующих процессорных RISC-архитектур - это, конечно же, знаменитая PowerPC, детище альянса Apple, IBM и Motorola (AIM). Сегодня на PowerPC есть четкие спецификации, следуя которым любой желающий может разработать совместимый с ним процессор. Ничего особо интересного в нем нет - это самый что ни на есть классический RISC-процессор без специальных «примочек». Существуют 32- и 64-разрядные версии PowerPC (причем 64-разрядные совместимы с 32-разрядным кодом), а равно и ряд стандартизованных расширений (типа эппловского набора инструкций AltiVec). В то время как MIPS и ARM «специализировались» на тех или иных применениях, PowerPC, подобно x86, позиционировалась в основном для обычных персоналок и серверов. Вплоть до 2001 года x86 и PowerPC развивались более или менее синхронно, однако из-за технологических проблем и неспособности угнаться за процессорами AMD и Intel в «гонке мегагерц» PPC шаг за шагом сдавала позиции. А исчерпав «запас прочности» и застряв на частотах 1,0-1,4 ГГц, она стала стремительно проигрывать архитектуре x86, по-прежнему сохранявшей высокие темпы развития из-за ожесточенной схватки Intel и AMD. Поскольку «отступать» PowerPC было в общем-то некуда (нишу интегрированных процессоров оккупировали ARM и MIPS), то многие посчитали ее верным кандидатом на вымирание. Даже Apple недавно «отреклась» от своей архитектуры, переметнувшись в стан приверженцев x86. Только крайне дорогие серверные процессоры POWER, выпускавшиеся на пределе технологических возможностей Голубого гиганта (Power4, в частности, стали первыми в мире двухъядерниками), еще довольно уверенно чувствуют себя в линейке продуктов IBM.
Однако ситуация, похоже, начала меняться: именно архитектура PowerPC положена в основу будущих многоядерных процессоров всех игровых приставок шестого поколения (от Sony, Microsoft и Nintendo), поскольку ни MIPS, ни тем более ARM на эту роль не годятся; процессоры Intel в их текущем варианте плохо подходят для создания игровых приставок нового поколения; о процессорах AMD и говорить не приходится - компания просто не в состоянии обеспечить достаточный объем их производства. Вот и остается единственным кандидатом на роль нового «суперпроцессора» только всем доступная, технологически более простая, нежели x86, и достаточно производительная архитектура PowerPC. Что еще важнее для PPC, именно она положена в качестве аппаратной основы концепции Cell, которая, возможно, станет следующим шагом в развитии компьютинга. Так что пожелаем РРС удачи - от наличия на рынке множества альтернатив пользователи только выигрывают, и видеть в обозримом будущем абсолютную монополию x86, даже в варианте AMD64, лично мне не хотелось бы.
Устройство процессоров AMD архитектуры K8
Архитектура K8 используется во всех современных серверных, десктопных и мобильных процессорах AMD (Opteron, Sempron, Athlon 64 и Athlon 64 X2). Эффективная длина конвейера[Время в тактах от начала исполнения инструкции до момента, когда результаты выполнения будут записаны в оперативную память] варьируется от 10-12 стадий (для целочисленных, логических вычислений и обращений к оперативной памяти) до 17 стадий (вычисления с плавающей точкой). Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до трех; тактовые частоты серийно выпускаемых процессоров - от 1,6 до 2,8 ГГц.
Об особенностях организации архитектуры K8, связанных с интегрированным контроллером памяти, линками HyperTransport и неоднородной моделью памяти SUMa мы подробно писали в статье про двухъядерные процессоры; в остальном же - перед нами вполне классический процессор Гарвардской архитектуры. Объем кэшей L1 D-cache (для данных) и L1 I-cache (для кода) - фиксирован и составляет по 64 Кбайт; имеется общий эксклюзивный[Эксклюзивным называется кэш, в котором данные, хранящиеся в кэш-памяти первого уровня, не обязательно должны быть продублированы в кэшах нижележащих уровней. Инклюзивный кэш - когда любая информация, хранящаяся в кэшах высших уровней, дублируется в кэш-памяти нижележащих] кэш второго уровня объемом от 128 до 1024 Кбайт; кэш третьего и более низких уровней не предусмотрен, но в рамках протокола MOESI процессоры в многопроцессорных системах могут обращаться к кэш-памяти других процессоров.
***
На втором такте работы конвейера свежевыбранные одна-три инструкции x86 распределяются по трем блокам декодирования инструкций. Самые сложные инструкции, требующие декодирования с использованием микрокода процессора, отправляются в декодер VectorPath. Более простые - в декодеры DirectPath: те, что попроще, - в обычный, те, что посложнее, - в сдвоенный DirectPath Double. Начиная с этого момента процессор «забывает» о существовании x86 и переключается на работу с внутренними микроинструкциями (mOP).
Весь дальнейший конвейер строится на том, что работа с mOP’ами происходит тройками инструкций (AMD называет их линиями, line). С логической точки зрения конвейер K8 строится таким образом, что обрабатывает именно линии, а не x86-инструкции или отдельные микрооперации. При этом в одной линии может быть меньше трех микроопераций - тогда «недосдачу» в тройке заполняют специальные пустые операции (null-mOP). При этом со «сложными» vector-инструкциями все элементарно - VectorPath-декодер подставляет на их место прошитые в микрокоде процессора линии; а вот декодирование «простых» инструкций выливается в сложный процесс превращения x86-инструкции в один (DirectPath) или два (DirectPath Double) mOP’а, которые потом перетасовываются и упаковываются в одну линию специальным упаковщиком[В этом упаковщике, который, в частности, научился эффективно управляться с разбивающимися на два mOP’а инструкциями SSE, и скрыто важнейшее усовершенствование конвейера K8 по сравнению с конвейером K7 (процессоры Athlon/Athlon XP). Изменение декодера (и значительное увеличение времени на декодирование), усовершенствование планировщика инструкций - казалось бы, мелочи, но эффект огромный. Кстати, отсюда следует, что конвейер K8 практически не оптимизировался для достижения высоких тактовых частот - неудивительно, что на старом 130-нм технологическом процессе он и не показал существенно более высоких тактовых частот, нежели старичок K7]. На весь процесс в нормальных условиях уходит пять тактов конвейера.
Сгенерированные линии от VectorPath- и DirectPath-декодеров по одной за такт поступают в специальное устройство - Instructions Control Unit (ICU), где подготовленные к исполнению линии накапливаются в специальной очереди (24 линии). О том, что происходит дальше, поясним с помощью аналогии.
Предположим, что наша программа - это книжка, в которой записано, как процессору нужно обрабатывать данные. Что делает процессор? Упоминавшийся блок выборки вырывает из книжки страничку с текстом (будем считать, что странички достаточно маленькие) и выбирает из нее от одной до трех содержательных частей, которые передает декодеру. Декодер читает выделенные фрагменты текста и конвертирует их в четкие инструкции, указывающие, что и в какой последовательности нужно сделать. Инструкции (по одной) он записывает на бумажках (mOP’ах) и упаковывает в конверты - до трех бумажек в один конверт (линию). Конверты поступают в специальную картотеку - ICU, где их вскрывает и прочитывает специальный человек.
Что дальше? Претендентов на декодированные инструкции два - блок целочисленных вычислений (ALU) и блок вычислений с плавающей точкой (FPU). Когда блоки готовы принять очередную инструкцию, они сообщают об этом человеку в картотеке; человек копается в своих конвертах и выбирает из них в произвольном порядке, как ему удобнее, до трех бумажек-инструкций, которые и раздает ALU и FPU. Единственное ограничение, которое при этом накладывается, - человек никогда не передает ALU и FPU те инструкции, выполнение которых зависит от еще не переданных. Блоки ALU/FPU каким-то хитрым образом выполняют полученные инструкции, но результаты отсылают не во «внешний мир», а в нашу картотеку-ICU, где их кладут в тот же самый конверт, в котором лежали инструкции. Даже если происходит ошибка выполнения, процессор не сообщает о ней сразу, а сперва записывает информацию об ошибке на конверте; когда настанет пора вскрыть конверт - вот тогда он про нее и сообщит. Чтобы потом эти данные использовать - применяется довольно хитрая техника (та самая, из сноски 4), позволяющая вновь выполняемым инструкциям обращаться к еще «официально несуществующим» данным. Когда для конверта все инструкции оказываются выполненными, а конверт стоит первым в очереди и больше не содержит инструкций, но лишь результаты их исполнения - то полученные результаты «объявляются официальными», а конверт выбрасывается (отставка линий). Иногда, если при вскрытии очередного конверта выясняется, что ранее была допущена ошибка при предсказании условного перехода или при выполнении содержащейся в конверте инструкции, дело до этого и не доходит - конвейер приходится «сбрасывать», то есть смотреть на последнем конверте адрес того самого неудачного перехода, выкидывать всю накопленную к текущему моменту картотеку со всеми ее результатами и начинать выполнение с того самого места, где произошло неверное предсказание перехода. Благодаря тому, что результаты выброшенных конвертов еще не были «объявлены официальными», а «рвем» мы конверты строго в той же очередности, в которой они к нам в очередь поступали - допущенная ошибка «никому не станет известна» - результаты выполнившихся «вперед батьки» инструкций автоматически будут аннулированы.
Если теперь вернуться к технологическому описанию конвейера, то изложенный выше процесс с конвертами происходит следующим образом. Из очереди в 24 линии по три mOP’а в каждой ICU выбирает в наиболее удобной для исполнения последовательности один-три mOP’а и пересылает их либо на ALU, либо на FPU - в зависимости от типа микрооперации. В случае ALU микрооперации сразу же попадают в очередь планировщика (шесть элементов по три mOP’а), который подготавливает необходимые для исполнения микрооперации ресурсы, дожидается их готовности и только потом отправляет mOP вместе со всеми необходимыми данными на исполнение. Причем при исполнении одного mOP’а на самом деле может происходить исполнение сразу двух действий - несложных арифметических вычислений, которые часто возникают при обращении к оперативной памяти (ими занимается блок Address Generation Unit, AGU), и «сложных», требующих вмешательства «полновесного» ALU, - соответствующая «двойка» микроинструкций (ROP) закладывается в mOP еще на стадии декодирования. Подготовка данных в планировщике занимает (в идеальном случае) один такт, исполнение - от одного (подавляющее большинство инструкций) до трех (при обращении к оперативной памяти) и даже пяти (64-битное умножение) тактов.
С блоком FPU все чуточку сложнее. Для начала вышедшие из ICU mOP’ы проходят две стадии по подготовке их операндов. Затем - накапливаются в планировщике FPU (двенадцать элементов по три mOP’а), который, по аналогии со своим целочисленным собратом, дожидается, пока данные для этих mOP’ов будут готовы, а исполнительные устройства освободятся, и разбрасывает накопленные mOP’ы по трем исполнительным устройствам. Но в отличие от целочисленной части конвейера (где содержатся по три одинаковых блока ALU и AGU), исполнительные устройства FPU «специализированы» - каждое производит только свой специфический набор действий над числами с плавающей запятой. Время выполнения: два такта на переименование и отображение регистров, один такт (в идеале) на планирование и ожидание операндов, четыре такта на собственно исполнение.
Финал же у всех закончившихся микроопераций один - они «возвращаются» в ICU с полученными результатами, и ICU, по мере готовности линий, потихоньку производит их отставку. На все про все в идеальных условиях у нас ушло 10-17 тактов, причем за каждый такт мы исполняли по три mOP’а (это обычно 1,5-3 инструкции x86).
Устройство процессоров Intel архитектуры NetBurst
Архитектура NetBurst сегодня лежит в основе всех процессоров Pentium 4, Xeon и Celeron. Эффективная длина конвейера в зависимости от варианта составляет 20 или 31 стадию. Количество одновременно исполняемых инструкций за такт в устоявшемся режиме - до четырех; тактовые частоты серийно выпускаемых процессоров - от 2,53 до 3,8 ГГц - это по всем показателям лучше данных по K8. Лучше, но, к сожалению, только сугубо теоретически и на специально подготовленном коде.
***
Дальнейшее повествование я буду вести, указывая время исполнения инструкции для ядра Northwood (20-стадийный конвейер). Для более нового Prescott в целом справедливо все то же самое, просто время исполнения отдельных стадий слегка возросло.
Первые четыре такта работы конвейера - извлечение специальным блоком выборки инструкций из TC и второй этап предсказания условных переходов. В первый раз декодер TC уже пытался предсказать переход, так что второй этап предсказания фактически сводится к «угадыванию» того, правильно ли декодер угадал переход еще «в тот раз» или нет. Заодно для некоторых записей TC («закладок»["Закладки" позволяют увеличить эффективный объем Trace Cache, поскольку вместо нескольких mОР’ов мы храним в нем одну «закладку»]) происходит их «развертывание» в несколько микроопераций. В силу того что TC работает на половинной частоте ядра, происходит выборка довольно медленно и каждый ее этап занимает по два такта конвейера. Затем полученные микрооперации (до шести штук за такт) складываются в традиционную очередь выборки (Fetch Queue), где буферизуются, сглаживая неравномерность декодирования и обеспечивая «на выходе» устоявшийся темп декодирования в три микроинструкции за такт. Задержка, вносимая буферизацией, - 1 такт; еще 1 такт расходуется на то, чтобы подготовить внутренние ресурсы процессора для выбранной из Fetch Queue тройки mOP’ов. Затем еще два такта уходит на то, чтобы подготовить для каждого mOP’а персональные физические регистры для вычислений (в рамках техники переименования регистров). И, наконец, на последнем, девятом по счету такте полностью готовые к исполнению mOP’ы начинают «распихиваться» по очередям инструкций, стоящих на выполнение.
Зачем понадобилась вся эта каша с многократными очередями? Разработчики NetBurst пытались добиться того, чтобы все стадии конвейера были независимы друг от друга и работали асинхронно, без точной привязки к некой «единой тактовой частоте» процессора. Именно асинхронность (а не только длинный конвейер!) позволяет резко повысить тактовые частоты, на которых способно работать ядро процессора.
Вернемся к конвейеру NetBurst. Итак, подготовленные к исполнению инструкции на девятом такте распределяются по двум очередям - очереди для AGU-инструкций, обращающихся к оперативной памяти (длина - 16 mOР’ов), и очереди для всего остального (32 mOP’а). На следующем такте инструкции из этих очередей разбираются аж пятью независимо работающими планировщиками - планировщиком AGU, двумя «быстрыми» и двумя «медленным» планировщиками. «Быстрые» имеют дело лишь с некоторыми самыми простыми арифметико-логическими операциями и работают на удвоенной тактовой частоте процессора, успевая забирать из очередей по две простые инструкции за такт. Нужны они для того, чтобы загружать работой «быстрые» же исполнительные блоки, построенные на специальной быстродействующей логике и тоже работающие на удвоенной тактовой частоте (до 8 ГГц!), обрабатывая по две инструкции за такт. «Медленные» планировщики «специализируются» каждый на своем типе инструкций и работают на номинальной частоте ядра. Планировщики могут переупорядочивать микрооперации по своему усмотрению (OoO-исполнение); они же отслеживают ход выполнения микроопераций, при необходимости перезапускают их и в конце выполнения инструкции записывает полученные результаты в оперативную память; на все про все у них уходит еще три такта процессора. Наконец, планировщики через четыре порта запуска (порты частично общие, а это значит, что «быстрые» и «медленные» планировщики конкурируют друг с другом за то, кто из них получит право запускать в текущем такте подготовленные mOP’ы дальше) переправляют упорядоченные микрооперации в очереди диспетчеров, где они дожидаются «разрешения на запуск». И тут начинается самое интересное.