Страница:
Метод позиционного анализа текста
Метод, созданный для изучения пространственно-временной организации текста, получил название метода позиционного анализа [Белоусов 2008а; Корбут 2004; Москальчук 2003]. Рассмотрение текста как становящегося объекта актуализирует представления о неоднородности его пространственной протяженной структуры, что сближает позиционный анализ с теорией сильных позиций [Арнольд 1978; Кухаренко 1980; Черемисина 1981 и др.].
Основное различие между позиционным анализом и теорией сильных позиций состоит в том, что предмет позиционного анализа – позиционная структура текста как неоднородное целое. С помощью позиционного анализа исследователь стремится не просто обнаружить и описать сильные позиции в тексте (например, начало и конец, заглавие, эпиграф и др.), но представить весь текст как последовательно разворачивающуюся структуру, пронизанную многочисленными связями между предшествующей и последующей позициями.
Метод позиционного анализа, с нашей точки зрения, имеет трехуровневое строение[6].
1. Первый уровень отражает существо самого метода, которое состоит в позиционировании интересующих исследователя языковых единиц в линейном ряду всех единиц текста. Поскольку текст имеет границы (начало и конец), постольку начало принимается за «0», а конец за «1» независимо от размера текста. Это позволяет сопоставлять тексты разных объемов. В ряду (от 0 до 1) линейно расположены все языковые элементы данного текста. За единицу счета принимается словоформа. Чтобы локализовать какой-либо элемент на заданном отрезке (0; 1), нужно разделить порядковый номер искомой словоформы на общее количество словоформ в тексте. Этот уровень (вариант) позиционного анализа направлен только на то, чтобы позиционировать, привязать искомые языковые единицы к текстовой оси (от 0 до 1).
Эта интерпретация метода позиционного анализа позволяет (с опорой на универсальную шкалу):
1) выявлять универсальные параметры распределения каких-либо языковых явлений в тексте (что впервые было сделано Г.Г. Москальчук [Москальчук 2003];
2) сопоставлять (синхронизировать) сценарии развертывания языкового субстрата разной природы одного и того же текста, например, синхронизировать ритм размеров предложений и ритм размеров синтаксических звеньев; интенсивность развертки эмотивного и просодического пространств и др., что было впервые осуществлено в работе [Белоусов 2002].
Данное понимание метода позиционного анализа наиболее приближено к природе текста. В качестве теоретической базы выступают положения о пространственно-временном как конститутивном факторе существования текста. Подход к тексту как симультанному образованию определяется посредством анализа сукцессивной его реализации. Основные понятия, используемые на данном уровне анализа: координата, вероятность, интенсивность. Позиционная же локализация компонентов текста – один из основных независимых параметров, описывающих динамику становления текста как целостности.
2. Второй уровень связан с дополнительно вводимыми теоретическими конструктами, в качестве которых выступают: а) постулат о единых принципах формообразования текста и формообразования объектов природы и искусства; б) признание пропорции золотого сечения в качестве базиса формообразования (о золотом сечении см.: [Белоусов 2005; Деев 2001; Ковалев 1989; Корбут 1994, 2004; Коробко 1998, 2000; Москальчук 2003; Розенов 1982; Черемисина 1981; Шафрановский 1985; Шевелев 1990]).
Одной из первых проблема золотого сечения как конститутивного принципа строения текста была поставлена Н.В. Черемисиной. Исследователь определял гармонический центр текста (ГЦ) как синтагму, «которая стоит в «точке» «золотого сечения» и делит предложение на две неравные части в соответствии с гармонической пропорцией, так называемой, винтовой симметрией» [Черемисина 1981, с. 118]. В целом, автор связывал гармонический центр с функцией выделения наиболее важного для восприятия экспрессивно-эмоционального содержания текста, с появлением интонационного пика, который заставляет читателя ожидать выхода из напряжения, то есть, разрешения. Важным является также вывод Н.В. Черемисиной о том, что в пределах абзаца или небольшого стихотворения между гармоническими центрами каждой синтагмы устанавливаются эксплицитные смысловые связи. Гармонический центр может совпадать с мелодической вершиной предложения (с тональным максимумом) или (реже) с самой низкой «точкой» внутри предложения (мелодический минимум). Автор приходит к выводу, что «мелодическое выделение ГЦ – общая особенность художественной речи <…> ГЦ оказывается… конструктивным и эмоциональным «стержнем», вокруг которого объединяются тяготеющие к нему эмоционально менее значимые синтагматическое и… фразовое ударения» [Черемисина-Ениколопова 1999, с. 220]. Автором подчеркивалось также интуитивное выделение гармонического центра пишущим и читающим.
Текст имеет следующую позиционную структуру (в том виде, в котором она изучена на сегодняшний день) [Москальчук 1998, 2003]:
– абсолютное начало (Абс. Н., первая словоформа);
– зачин (Зачин, на расстоянии 0,136 от начала текста);
– гармонический центр зоны начала (ГЦн, на расстоянии 0,236 от начала текста);
– гармонический центр текста (ГЦ, на расстоянии 0,618 от начала текста);
– абсолютно слабые позиции (АСП1, АСП2, на расстоянии 0,236 вправо и влево от ГЦ текста);
– абсолютный конец (Абс. К., последняя словоформа).
Абс. Н., Абс. К., ГЦн, ГЦ – называются позициями и в пространстве текста имеют протяженность равную словоформе. Например,
Абс. Н – занимает место первой словоформы текста. Зачин, АСП1, АСП2 являются срезами и в текстовом пространстве приходятся на «разъем» между словоформами. АСП1, АСП2 являются границами позиционных зон текста: зоны начала (Абс. Н. – АСП1), зоны гармонического центра (АСП1 – АСП2) и зоны конца (АСП2 – Абс. К.).
В позиционной структуре текста выделяется два гармонических центра: ГЦ – гармонический центр всего текста и ГЦн – гармонический центр зоны начала. А.Ю. Корбут полагает наличие гармонического центра в зоне конца текста (расстояние 0,944), что имеет под собой основания [Корбут 2004]. Между позициями (и срезами), маркирующими возраст системы-текста, расположены интервалы, в которых полагается качественная однородность происходящих процессов. Между Абс. Н. и Зачином располагается интервал Зачин; между Зачином и ГЦн – пред-ГЦн; между ГЦн и АСП1 – пост-ГЦн; между АСП1 и ГЦ – пред-ГЦ; между ГЦ и АСП2 – Пост-ГЦ; между АСП2 и Абс. К – конец (см. рисунок 1).
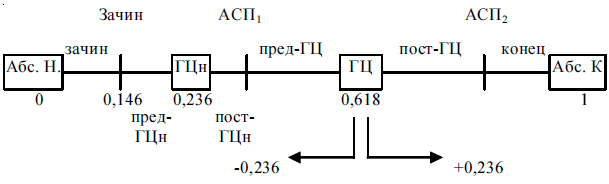
Рисунок 1. Позиционная структура текста
На этом уровне позиционного анализа «время входит в состав структуры целого текста в виде позиционной последовательности, а также межпозиционных интервалов. Прослеживая репрезентанты течения тех или иных процессов в аналогичных позициях текста и интервалах между ними, можно изучать изменения состояний структуры целого с течением внутреннего пространства-времени текста как системы. Анализ возможен как в отдельном тексте, так и в совокупности текстов» [Москальчук 1998, с. 192]. Весь конструкт, который представлен на рисунке 1 и включает в себя: 1) набор позиций и срезов, 2) позиционных интервалов и 3) позиционных зон, – получил название метроритмической матрицы. В качестве операциональных понятий на данном уровне используются: позиционный срез, координата, инвариант, метроритмическая матрица и ее составляющие, интенсивность, вероятность.
Метроритмическая матрица получена в ходе исследований большого количества текстов и отражает распределение элементов симметрии в определенных позициях – собственно, как сильные, так и слабые позиции были выделены Г.Г. Москальчук на основе изучения концентрации в тексте лексико-грамматических повторов [Москальчук 1990, 2003]. Однако использование метроритмической матрицы при анализе конкретного текста часто не приносит никаких результатов – в конкретных текстах языковой субстрат может распределяться совершенно иначе, нежели предполагает метроритмическая матрица. На наш взгляд, вся ситуация с выделением четко зафиксированных позиций, интервалов и др., рассмотренная не со стороны инварианта, а в аспекте его конкретных проявлений, значительно сложнее, чем инвариантная модель. Если обратиться к формообразованию природных объектов и объектов искусства, то можно увидеть, что золотое сечение в его чистом виде редко является основным и единственным принципом организации формы. Гораздо чаще при формообразовании единичных объектов присутствуют разные модификации золотого сечения и других пропорций, образуя очень пеструю систему. Полагаем, что эти же явления должны присутствовать и в процессах формообразования конкретных текстов.
Еще одним фактором, значительно ослабляющим применение предлагаемой модели, является возможность совершенно иной закономерности распределения языкового субстрата в тексте (об этом см. в разделе, посвященном изучению структуры темпорального пространства текста).
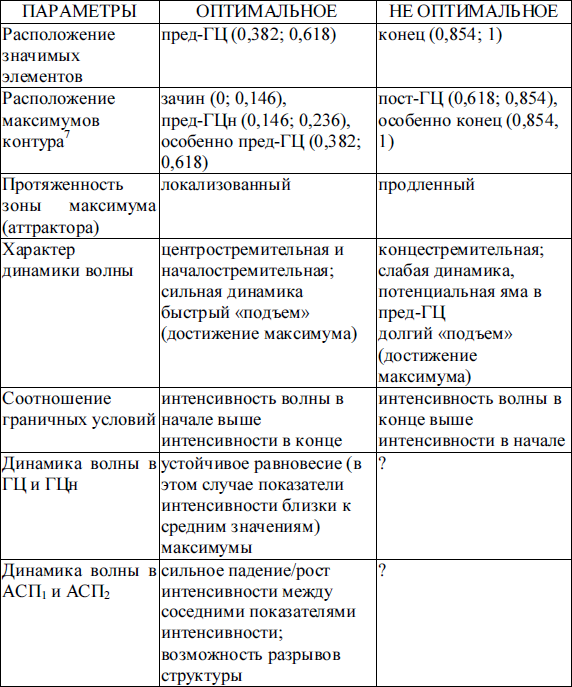
Очерченные проблемы приводят к необходимости в процессе анализа текста как пространственно-временного объекта опираться на метод позиционного анализа в его первой интерпретации, которая нацелена только на позиционирование искомых языковых единиц на текстовой оси (от 0 до 1). Между тем, в процессе интерпретации полученных результатов (пространственных распределений тех или иных аспектов бытия текста), уместно опираться на позиционную шкалу, поскольку в отношении спецификации позиционных срезов накоплены некоторые данные (основные результаты проведенных исследований представлены в табличной форме (см. таблица 1)).
3. Третий уровень метода позиционного анализа подразумевает более сложное «примеривание» теоретической схемы к конкретному материалу. Данный уровень анализа дополняется введением ряда понятий и допущений.
Формы движения материи (пространство и время) создают и форму объекта, в частности, текста. Единицей (измерения) пространства-времени текста служит словоформа (элемент его процессуальности). Всякая форма состоит из повторяющихся и неповторимых (в рамках целого) комплексов. Единство и последовательность этих симметро-асимметричных комплексов в рамках целого задает ритм его формы.
Таблица 1.
Характеристики расположения языковых единиц в тексте в аспекте его позиционной организации[7]
По отношению к тексту выдвигается следующее утверждение: всякий текст независимо от его объема, функционально-стилистической принадлежности имеет в своей основе некоторые универсальные сценарии становления его глубинной структуры (формы), которые и выражают взаимодействие ее симметричных и асимметричных комплексов. Движение языковой материи текста относительно позиций-констант и определяет ритм становления его формы. Поскольку каждая из позиций находится в тексте внутри предложения, то последнее членится на равные и неравные отрезки, что и создает ритм внутри целого текста. Членя предложения на равные доли, позиция задает монотонный ритм формообразования. Разделяя же предложения на неравные доли, пропорция создает ритмический рисунок с помощью акцентов на правую (устремленную к концу) и левую (устремленную к началу) долю предложения. Право-и левосторонняя асимметрия создает акцентность формы, в которую встраивается монотон равных долей. Взаимодействие противоположных акцентных тенденций и создает все богатство разнообразия (в определенных границах) форм текста.
Последним штрихом к созданию теоретической схемы будет введение понятий циклической связи (связи между лево-и правосторонней асимметрией) и плотности циклических связей (суммы циклических связей между теми или иными позициями текста в том или ином интервале текста, который определяется как длительность между двумя соседними позициями). Третий уровень позиционного анализа текста использует в качестве необходимых следующие понятия: координата, инвариант, метроритмическая матрица и ее составляющие, интенсивность, вероятность, симметрия / асимметрия, цикл (циклическая связь), формула текста (подробнее см.: [Москальчук 2003]).
Центральным понятием данного уровня позиционного анализа становится формула текста, которая отражает плотность циклических связей между позиционными срезами, членящими предложения текста. Возникает вопрос: какие стороны структуры и / или функционирования текста отражает его формула и плотность циклических связей. В работах, выполняемых в данной области, предполагалось, что плотность циклических связей соотносится с концентрацией элементов симметрии, а максимум плотности циклических связей является креативным аттрактором текста (далее. – КА), передающим наиболее важную информацию [Москальчук 1998; Солодянкина 2004; Болдырева 2007].
Однако, как показали результаты исследования В.А. Дорофеевой, – статистика распределения элементов симметрии по 6 интервалам (зачин, пред-ГЦн, пост-ГЦн, пред-ГЦ, пост-ГЦ и конец) для 906 русских поэтических текстов [Дорофеева 2004] – формула текста никаким образом не связана с распределением элементов симметрии в нем. Доказано это было следующим образом: 1) для каждого из исследуемых текстов была определена модель формы и выявлено распределение плотности циклических связей в интервалах и 2) в каждом интервале анализируемых текстов были подсчитаны лексические (тематические) повторы (элементы симметрии). С помощью метода корреляционного анализа полученные данные были соотнесены друг с другом. В результате было установлено, что формула текста не коррелирует с динамикой элементов симметрии на уровне тематического повтора.
То же самое можно сказать и о корреляции креативного аттрактора, вычисляемого с помощью формулы текста (предполагаем возможность совершенно иного метода обнаружения КА в тексте), и наиболее важной текстовой информации. Статистически значимых отличий в распределении разного рода языковых единиц и категорий между КА и другими областями текста нет (это показывают результаты исследований Э.Т. Болдыревой [Болдырева 2007]). Поэтому в практике филологического анализа текста применение метода позиционного анализа на его втором и, особенно, на третьем уровнях оказывается проблематичным. Как отмечает Н.С. Болотнова: «Вместе с тем далеко не всегда попытки использовать этот метод (метод позиционного анализа. – К.Б.) на практике венчаются успехом: представляется, что в смысловой интерпретации опора на формальные критерии может служить лишь вспомогательным средством» [Болотнова 2003, с. 42]. Строго говоря, так и остается непроясненным, что же отражает формула текста на языковом и текстовом уровнях.
Таким образом, из всех вариантов (уровней) позиционного анализа текста его первый (базовый) уровень является наиболее жизнеспособным. В то же время, где это оказывается возможным, мотивировано и обращение ко второму его уровню. Третий же уровень метода позиционного анализа представляется нам не имеющим отношения к организации физического и семантического пространств текста.
Основное различие между позиционным анализом и теорией сильных позиций состоит в том, что предмет позиционного анализа – позиционная структура текста как неоднородное целое. С помощью позиционного анализа исследователь стремится не просто обнаружить и описать сильные позиции в тексте (например, начало и конец, заглавие, эпиграф и др.), но представить весь текст как последовательно разворачивающуюся структуру, пронизанную многочисленными связями между предшествующей и последующей позициями.
Метод позиционного анализа, с нашей точки зрения, имеет трехуровневое строение[6].
1. Первый уровень отражает существо самого метода, которое состоит в позиционировании интересующих исследователя языковых единиц в линейном ряду всех единиц текста. Поскольку текст имеет границы (начало и конец), постольку начало принимается за «0», а конец за «1» независимо от размера текста. Это позволяет сопоставлять тексты разных объемов. В ряду (от 0 до 1) линейно расположены все языковые элементы данного текста. За единицу счета принимается словоформа. Чтобы локализовать какой-либо элемент на заданном отрезке (0; 1), нужно разделить порядковый номер искомой словоформы на общее количество словоформ в тексте. Этот уровень (вариант) позиционного анализа направлен только на то, чтобы позиционировать, привязать искомые языковые единицы к текстовой оси (от 0 до 1).
Эта интерпретация метода позиционного анализа позволяет (с опорой на универсальную шкалу):
1) выявлять универсальные параметры распределения каких-либо языковых явлений в тексте (что впервые было сделано Г.Г. Москальчук [Москальчук 2003];
2) сопоставлять (синхронизировать) сценарии развертывания языкового субстрата разной природы одного и того же текста, например, синхронизировать ритм размеров предложений и ритм размеров синтаксических звеньев; интенсивность развертки эмотивного и просодического пространств и др., что было впервые осуществлено в работе [Белоусов 2002].
Данное понимание метода позиционного анализа наиболее приближено к природе текста. В качестве теоретической базы выступают положения о пространственно-временном как конститутивном факторе существования текста. Подход к тексту как симультанному образованию определяется посредством анализа сукцессивной его реализации. Основные понятия, используемые на данном уровне анализа: координата, вероятность, интенсивность. Позиционная же локализация компонентов текста – один из основных независимых параметров, описывающих динамику становления текста как целостности.
2. Второй уровень связан с дополнительно вводимыми теоретическими конструктами, в качестве которых выступают: а) постулат о единых принципах формообразования текста и формообразования объектов природы и искусства; б) признание пропорции золотого сечения в качестве базиса формообразования (о золотом сечении см.: [Белоусов 2005; Деев 2001; Ковалев 1989; Корбут 1994, 2004; Коробко 1998, 2000; Москальчук 2003; Розенов 1982; Черемисина 1981; Шафрановский 1985; Шевелев 1990]).
Одной из первых проблема золотого сечения как конститутивного принципа строения текста была поставлена Н.В. Черемисиной. Исследователь определял гармонический центр текста (ГЦ) как синтагму, «которая стоит в «точке» «золотого сечения» и делит предложение на две неравные части в соответствии с гармонической пропорцией, так называемой, винтовой симметрией» [Черемисина 1981, с. 118]. В целом, автор связывал гармонический центр с функцией выделения наиболее важного для восприятия экспрессивно-эмоционального содержания текста, с появлением интонационного пика, который заставляет читателя ожидать выхода из напряжения, то есть, разрешения. Важным является также вывод Н.В. Черемисиной о том, что в пределах абзаца или небольшого стихотворения между гармоническими центрами каждой синтагмы устанавливаются эксплицитные смысловые связи. Гармонический центр может совпадать с мелодической вершиной предложения (с тональным максимумом) или (реже) с самой низкой «точкой» внутри предложения (мелодический минимум). Автор приходит к выводу, что «мелодическое выделение ГЦ – общая особенность художественной речи <…> ГЦ оказывается… конструктивным и эмоциональным «стержнем», вокруг которого объединяются тяготеющие к нему эмоционально менее значимые синтагматическое и… фразовое ударения» [Черемисина-Ениколопова 1999, с. 220]. Автором подчеркивалось также интуитивное выделение гармонического центра пишущим и читающим.
Текст имеет следующую позиционную структуру (в том виде, в котором она изучена на сегодняшний день) [Москальчук 1998, 2003]:
– абсолютное начало (Абс. Н., первая словоформа);
– зачин (Зачин, на расстоянии 0,136 от начала текста);
– гармонический центр зоны начала (ГЦн, на расстоянии 0,236 от начала текста);
– гармонический центр текста (ГЦ, на расстоянии 0,618 от начала текста);
– абсолютно слабые позиции (АСП1, АСП2, на расстоянии 0,236 вправо и влево от ГЦ текста);
– абсолютный конец (Абс. К., последняя словоформа).
Абс. Н., Абс. К., ГЦн, ГЦ – называются позициями и в пространстве текста имеют протяженность равную словоформе. Например,
Абс. Н – занимает место первой словоформы текста. Зачин, АСП1, АСП2 являются срезами и в текстовом пространстве приходятся на «разъем» между словоформами. АСП1, АСП2 являются границами позиционных зон текста: зоны начала (Абс. Н. – АСП1), зоны гармонического центра (АСП1 – АСП2) и зоны конца (АСП2 – Абс. К.).
В позиционной структуре текста выделяется два гармонических центра: ГЦ – гармонический центр всего текста и ГЦн – гармонический центр зоны начала. А.Ю. Корбут полагает наличие гармонического центра в зоне конца текста (расстояние 0,944), что имеет под собой основания [Корбут 2004]. Между позициями (и срезами), маркирующими возраст системы-текста, расположены интервалы, в которых полагается качественная однородность происходящих процессов. Между Абс. Н. и Зачином располагается интервал Зачин; между Зачином и ГЦн – пред-ГЦн; между ГЦн и АСП1 – пост-ГЦн; между АСП1 и ГЦ – пред-ГЦ; между ГЦ и АСП2 – Пост-ГЦ; между АСП2 и Абс. К – конец (см. рисунок 1).
Рисунок 1. Позиционная структура текста
На этом уровне позиционного анализа «время входит в состав структуры целого текста в виде позиционной последовательности, а также межпозиционных интервалов. Прослеживая репрезентанты течения тех или иных процессов в аналогичных позициях текста и интервалах между ними, можно изучать изменения состояний структуры целого с течением внутреннего пространства-времени текста как системы. Анализ возможен как в отдельном тексте, так и в совокупности текстов» [Москальчук 1998, с. 192]. Весь конструкт, который представлен на рисунке 1 и включает в себя: 1) набор позиций и срезов, 2) позиционных интервалов и 3) позиционных зон, – получил название метроритмической матрицы. В качестве операциональных понятий на данном уровне используются: позиционный срез, координата, инвариант, метроритмическая матрица и ее составляющие, интенсивность, вероятность.
Метроритмическая матрица получена в ходе исследований большого количества текстов и отражает распределение элементов симметрии в определенных позициях – собственно, как сильные, так и слабые позиции были выделены Г.Г. Москальчук на основе изучения концентрации в тексте лексико-грамматических повторов [Москальчук 1990, 2003]. Однако использование метроритмической матрицы при анализе конкретного текста часто не приносит никаких результатов – в конкретных текстах языковой субстрат может распределяться совершенно иначе, нежели предполагает метроритмическая матрица. На наш взгляд, вся ситуация с выделением четко зафиксированных позиций, интервалов и др., рассмотренная не со стороны инварианта, а в аспекте его конкретных проявлений, значительно сложнее, чем инвариантная модель. Если обратиться к формообразованию природных объектов и объектов искусства, то можно увидеть, что золотое сечение в его чистом виде редко является основным и единственным принципом организации формы. Гораздо чаще при формообразовании единичных объектов присутствуют разные модификации золотого сечения и других пропорций, образуя очень пеструю систему. Полагаем, что эти же явления должны присутствовать и в процессах формообразования конкретных текстов.
Еще одним фактором, значительно ослабляющим применение предлагаемой модели, является возможность совершенно иной закономерности распределения языкового субстрата в тексте (об этом см. в разделе, посвященном изучению структуры темпорального пространства текста).
Очерченные проблемы приводят к необходимости в процессе анализа текста как пространственно-временного объекта опираться на метод позиционного анализа в его первой интерпретации, которая нацелена только на позиционирование искомых языковых единиц на текстовой оси (от 0 до 1). Между тем, в процессе интерпретации полученных результатов (пространственных распределений тех или иных аспектов бытия текста), уместно опираться на позиционную шкалу, поскольку в отношении спецификации позиционных срезов накоплены некоторые данные (основные результаты проведенных исследований представлены в табличной форме (см. таблица 1)).
3. Третий уровень метода позиционного анализа подразумевает более сложное «примеривание» теоретической схемы к конкретному материалу. Данный уровень анализа дополняется введением ряда понятий и допущений.
Формы движения материи (пространство и время) создают и форму объекта, в частности, текста. Единицей (измерения) пространства-времени текста служит словоформа (элемент его процессуальности). Всякая форма состоит из повторяющихся и неповторимых (в рамках целого) комплексов. Единство и последовательность этих симметро-асимметричных комплексов в рамках целого задает ритм его формы.
Таблица 1.
Характеристики расположения языковых единиц в тексте в аспекте его позиционной организации[7]
По отношению к тексту выдвигается следующее утверждение: всякий текст независимо от его объема, функционально-стилистической принадлежности имеет в своей основе некоторые универсальные сценарии становления его глубинной структуры (формы), которые и выражают взаимодействие ее симметричных и асимметричных комплексов. Движение языковой материи текста относительно позиций-констант и определяет ритм становления его формы. Поскольку каждая из позиций находится в тексте внутри предложения, то последнее членится на равные и неравные отрезки, что и создает ритм внутри целого текста. Членя предложения на равные доли, позиция задает монотонный ритм формообразования. Разделяя же предложения на неравные доли, пропорция создает ритмический рисунок с помощью акцентов на правую (устремленную к концу) и левую (устремленную к началу) долю предложения. Право-и левосторонняя асимметрия создает акцентность формы, в которую встраивается монотон равных долей. Взаимодействие противоположных акцентных тенденций и создает все богатство разнообразия (в определенных границах) форм текста.
Последним штрихом к созданию теоретической схемы будет введение понятий циклической связи (связи между лево-и правосторонней асимметрией) и плотности циклических связей (суммы циклических связей между теми или иными позициями текста в том или ином интервале текста, который определяется как длительность между двумя соседними позициями). Третий уровень позиционного анализа текста использует в качестве необходимых следующие понятия: координата, инвариант, метроритмическая матрица и ее составляющие, интенсивность, вероятность, симметрия / асимметрия, цикл (циклическая связь), формула текста (подробнее см.: [Москальчук 2003]).
Центральным понятием данного уровня позиционного анализа становится формула текста, которая отражает плотность циклических связей между позиционными срезами, членящими предложения текста. Возникает вопрос: какие стороны структуры и / или функционирования текста отражает его формула и плотность циклических связей. В работах, выполняемых в данной области, предполагалось, что плотность циклических связей соотносится с концентрацией элементов симметрии, а максимум плотности циклических связей является креативным аттрактором текста (далее. – КА), передающим наиболее важную информацию [Москальчук 1998; Солодянкина 2004; Болдырева 2007].
Однако, как показали результаты исследования В.А. Дорофеевой, – статистика распределения элементов симметрии по 6 интервалам (зачин, пред-ГЦн, пост-ГЦн, пред-ГЦ, пост-ГЦ и конец) для 906 русских поэтических текстов [Дорофеева 2004] – формула текста никаким образом не связана с распределением элементов симметрии в нем. Доказано это было следующим образом: 1) для каждого из исследуемых текстов была определена модель формы и выявлено распределение плотности циклических связей в интервалах и 2) в каждом интервале анализируемых текстов были подсчитаны лексические (тематические) повторы (элементы симметрии). С помощью метода корреляционного анализа полученные данные были соотнесены друг с другом. В результате было установлено, что формула текста не коррелирует с динамикой элементов симметрии на уровне тематического повтора.
То же самое можно сказать и о корреляции креативного аттрактора, вычисляемого с помощью формулы текста (предполагаем возможность совершенно иного метода обнаружения КА в тексте), и наиболее важной текстовой информации. Статистически значимых отличий в распределении разного рода языковых единиц и категорий между КА и другими областями текста нет (это показывают результаты исследований Э.Т. Болдыревой [Болдырева 2007]). Поэтому в практике филологического анализа текста применение метода позиционного анализа на его втором и, особенно, на третьем уровнях оказывается проблематичным. Как отмечает Н.С. Болотнова: «Вместе с тем далеко не всегда попытки использовать этот метод (метод позиционного анализа. – К.Б.) на практике венчаются успехом: представляется, что в смысловой интерпретации опора на формальные критерии может служить лишь вспомогательным средством» [Болотнова 2003, с. 42]. Строго говоря, так и остается непроясненным, что же отражает формула текста на языковом и текстовом уровнях.
Таким образом, из всех вариантов (уровней) позиционного анализа текста его первый (базовый) уровень является наиболее жизнеспособным. В то же время, где это оказывается возможным, мотивировано и обращение ко второму его уровню. Третий же уровень метода позиционного анализа представляется нам не имеющим отношения к организации физического и семантического пространств текста.
Метод графосемантического моделирования
Если метод позиционного анализа связан с исследованием текста как сукцессивного лингвистического объекта (чем исчерпывается сфера применения данного метода), то метод графосемантического моделирования используется для представления структуры текста (и других объектов) как симультанного образования.
Метод графосемантического моделирования является методом, разработанным К.И. Белоусовым и Н.Л. Зелянской для анализа языковых, литературных и культурных объектов. Сфера его применения многообразна: концептуальная организация семантического пространства текста [Белоусов 2008а]; исследование функционирования системы литературоведческих категорий в рецептивных пространствах учительского и филологического микросоциумов [Зелянская 2005]; моделирование эпохального семиозиса русской литературы 18401850-х гг. [Зелянская 2009]; моделирование понятийного потенциала термина [Белоусов 2008 г, Стренева 2009]; и др. Метод применяется в прикладных филологических работах – в лингвомаркетологии и нейминге (создание марочного имени) [Белоусов 2007а]; в лингвополитологии и филологической имиджелогии (в работах по реконструкции имиджевых портретов политиков и политических организаций [Белоусов 2008б]; и мн. др.
Графосемантическое моделирование представляет собой метод графической экспликации структурных связей между семантическими компонентами одного множества. В качестве такого множества, как правило, выступает либо принципиально незамкнутая совокупность данных, либо некоторая целостность, состоящая из конечного набора компонентов. Основное условие, позволяющее использовать описываемый метод, – наличие связей между компонентами множества. Характер связей, конечно, может заметно различаться: они либо обусловливаются специфическими особенностями целого, либо реконструируются с помощью статистической обработки и интерпретации результатов. Метод графосемантического моделирования позволяет представить набор данных в виде системы, в которой каждый из компонентов имеет иерархическую и топологическую определенность по отношению к другим компонентам и всей системе в целом. Эта структурная контекстуальность, в свою очередь, позволяет интерпретировать каждый компонент системы в отношении к возможным причинам его появления и вариантам его дальнейшего развития.
Надо заметить, что в филологии накоплен некоторый опыт графического представления исследовательских данных. Такая форма модельного рассмотрения объекта является не только наглядной репрезентацией материала, но и самостоятельным средством научного анализа. Отражение особенностей структурной организации объекта в графической модели стремится к максимальной релевантности, т. к. все элементы структуры даны в ней одновременно и иерархические зависимости, связи между элементами, а также сила и актуальность этих связей приобретают дополнительный прогностический потенциал. Структурная модель, передающая особенности взаимодействия между элементами в рамках целого, содержит «в свернутом виде» альтернативные сценарии собственного развития, т. е. преодолевает статичность, свойственную синхронии, и становится хроноструктурной.
Алгоритм проведения графосемантического моделирования включает пять шагов:
1) проведение компонентного анализа отобранного материала (слова, фразы и др.);
2) проведение полевого анализа (на основании выделенных компонентов);
3) обнаружение основных связей между полями в пределах всей выборки контекстов;
4) графическая экспликация результатов анализа;
5) интерпретация полученной модели.
Охарактеризуем более подробно этапы проведения графосемантического моделирования.
1. Компонентный анализ.
Компонентный анализ является одним из основных инструментов лингвистического анализа (см. например, [Кузнецов 1986, Болотнова 1999]). Однако, на наш взгляд, можно выделить два варианта компонентного анализа: анализ по единицам и анализ по элементам. Вариант компонентного анализа по элементам предполагает разложение анализируемых языковых единиц до предельных, первичных сем. При анализе по единицам (аналог термину, введенному Л.С. Выготским [Выготский 1998, с. 13]) последний компонент членения еще сохраняет качества целого, т. е. может служить объектом анализа, репрезентирующим индивидуальные черты целого объекта. Дальнейшее же членение приводит к выделению элементов, синтез которых уже не позволяет получить исходный объект. В нашем случае мы используем метод компонентного анализа «по единицам».
2. Полевый анализ.
Проведение полевого анализа в рамках метода графосемантического моделирования также имеет свою специфику. Формируемые нами семантические поля состоят из выделенных в процессе анализа материала компонентов, имеющих смысловую общность. Эти компоненты не дифференцируются по значимости, но они могут группироваться в рамках пространства понятийного поля по более дробным основаниям, нежели основание, по которому сформировано вобравшее их поле. Более того, если в процессе развития исследуемого предмета (например, при изучении диахронической динамики понятия) будет наблюдаться усиление значимости какой-либо из семантических групп, ранее входивших в самостоятельное поле (оно преодолевает порог статистической значимости), то мы начинаем рассматривать эту группу в качестве актуализировавшегося в новых условиях поля. Таким образом, основным критерием выделения самостоятельных полей является для нас статистический показатель. Подобный подход, на наш взгляд, более органичен для изучения способного изменяться во времени понятийного феномена, т. к. структурированность этого феномена обнаруживается не исходя из имманентных свойств входящих в него единиц (они принципиально понимаются как подвижные), а опираясь на особенности его функционирования (проявляющиеся во вновь привлекаемом материале). Заметим, что понятия ядро и периферия, традиционно используемые для описания поля, в графосемантическом моделировании оказываются востребованными при описании системы связей между полями.
3. Обнаружение основным связей между полями.
Следующий этап моделирования предполагает определение количества связей между выявленными полями и силы этих связей. Для достижения данной цели необходимо высчитать общее количество взаимодействий, которое образует каждое поле с другими полями в рамках смыслового пространства каждого контекста. Полагается, что, если два компонента выделяются при анализе одного и того же контекста, то они становятся связанными между собой через отнесение их к одному высказыванию (контексту), соответствующим образом мы делаем вывод о связи между полями, в которые входят указанные компоненты.
Подобным образом анализируется весь материал и выявляется исчерпывающее количество взаимосвязей между полями в рамках каждого контекста. Затем производится подсчет количества одинаковых связей, образованных каждым полем. Одинаковые связи одного поля истолковываются как одна и та же связь, но имеющая повышенную интенсивность. Поэтому суммированное значение одинаковых связей становится показателем силы каждой связи каждого поля.
4. Графическая экспликация результатов анализа.
После выявления количества связей каждого поля с другими полями в рамках всей выборки контекстов, производится графическая экспликация данных результатов, т. е. строится семантический граф. Само построение семантического графа из уже имеющихся (предварительно выявленных) семантических связей состоит из ряда простых операций:
1) необходимо расположить компоненты на графической плоскости;
2) определить из всего набора обнаруженных связей значимые (главным образом, учитывая статистические закономерности);
3) с помощью соединительных стрелок отметить наличие установленных связей между компонентами.
5. Интерпретация полученной графосемантической модели.
После построения семантического графа производится интерпретация полученной модели.
Для этого сначала определяются роли компонентов и структур в рамках всей системы. Система может представлять собой единое гомогенное целое, но нередко возникает ситуация, когда она распадается на ряд автономных структур. Каждую из них можно считать самостоятельным графом. В таких случаях, как правило, в рамках всей системы один из графов (с наибольшим числом компонентов) становится доминирующим. Таким образом, анализ построенной модели предполагает определение наличия автономных структур, выявление образующих их подструктур, установление их статуса (доминантная, периферийная). Затем исследуются компоненты, входящие в каждую из структур. В целом, все компоненты можно разделить:
1. По степени принадлежности к той или иной подструктуре:
а) принадлежащие одной подструктуре; б) принадлежащие нескольким подструктурам одновременно.
2. По роли в подструктуре:
а) ядерные компоненты (группирующие вокруг себя некоторое количество зависимых от них компонентов, но не имеющие непосредственной связи с другими ядерными компонентами); б) второстепенные компоненты (образующие какое-то количество связей помимо связи с ядерным компонентом подструктуры, но не имеющие связи с другими ядерными компонентами); в) компоненты-посредники (связывающие две автономные подструктуры); г) тупиковые компоненты (связанные только с одним компонентом (ядерным, второстепенным, посредником)).
Метод графосемантического моделирования является методом, разработанным К.И. Белоусовым и Н.Л. Зелянской для анализа языковых, литературных и культурных объектов. Сфера его применения многообразна: концептуальная организация семантического пространства текста [Белоусов 2008а]; исследование функционирования системы литературоведческих категорий в рецептивных пространствах учительского и филологического микросоциумов [Зелянская 2005]; моделирование эпохального семиозиса русской литературы 18401850-х гг. [Зелянская 2009]; моделирование понятийного потенциала термина [Белоусов 2008 г, Стренева 2009]; и др. Метод применяется в прикладных филологических работах – в лингвомаркетологии и нейминге (создание марочного имени) [Белоусов 2007а]; в лингвополитологии и филологической имиджелогии (в работах по реконструкции имиджевых портретов политиков и политических организаций [Белоусов 2008б]; и мн. др.
Графосемантическое моделирование представляет собой метод графической экспликации структурных связей между семантическими компонентами одного множества. В качестве такого множества, как правило, выступает либо принципиально незамкнутая совокупность данных, либо некоторая целостность, состоящая из конечного набора компонентов. Основное условие, позволяющее использовать описываемый метод, – наличие связей между компонентами множества. Характер связей, конечно, может заметно различаться: они либо обусловливаются специфическими особенностями целого, либо реконструируются с помощью статистической обработки и интерпретации результатов. Метод графосемантического моделирования позволяет представить набор данных в виде системы, в которой каждый из компонентов имеет иерархическую и топологическую определенность по отношению к другим компонентам и всей системе в целом. Эта структурная контекстуальность, в свою очередь, позволяет интерпретировать каждый компонент системы в отношении к возможным причинам его появления и вариантам его дальнейшего развития.
Надо заметить, что в филологии накоплен некоторый опыт графического представления исследовательских данных. Такая форма модельного рассмотрения объекта является не только наглядной репрезентацией материала, но и самостоятельным средством научного анализа. Отражение особенностей структурной организации объекта в графической модели стремится к максимальной релевантности, т. к. все элементы структуры даны в ней одновременно и иерархические зависимости, связи между элементами, а также сила и актуальность этих связей приобретают дополнительный прогностический потенциал. Структурная модель, передающая особенности взаимодействия между элементами в рамках целого, содержит «в свернутом виде» альтернативные сценарии собственного развития, т. е. преодолевает статичность, свойственную синхронии, и становится хроноструктурной.
Алгоритм проведения графосемантического моделирования включает пять шагов:
1) проведение компонентного анализа отобранного материала (слова, фразы и др.);
2) проведение полевого анализа (на основании выделенных компонентов);
3) обнаружение основных связей между полями в пределах всей выборки контекстов;
4) графическая экспликация результатов анализа;
5) интерпретация полученной модели.
Охарактеризуем более подробно этапы проведения графосемантического моделирования.
1. Компонентный анализ.
Компонентный анализ является одним из основных инструментов лингвистического анализа (см. например, [Кузнецов 1986, Болотнова 1999]). Однако, на наш взгляд, можно выделить два варианта компонентного анализа: анализ по единицам и анализ по элементам. Вариант компонентного анализа по элементам предполагает разложение анализируемых языковых единиц до предельных, первичных сем. При анализе по единицам (аналог термину, введенному Л.С. Выготским [Выготский 1998, с. 13]) последний компонент членения еще сохраняет качества целого, т. е. может служить объектом анализа, репрезентирующим индивидуальные черты целого объекта. Дальнейшее же членение приводит к выделению элементов, синтез которых уже не позволяет получить исходный объект. В нашем случае мы используем метод компонентного анализа «по единицам».
2. Полевый анализ.
Проведение полевого анализа в рамках метода графосемантического моделирования также имеет свою специфику. Формируемые нами семантические поля состоят из выделенных в процессе анализа материала компонентов, имеющих смысловую общность. Эти компоненты не дифференцируются по значимости, но они могут группироваться в рамках пространства понятийного поля по более дробным основаниям, нежели основание, по которому сформировано вобравшее их поле. Более того, если в процессе развития исследуемого предмета (например, при изучении диахронической динамики понятия) будет наблюдаться усиление значимости какой-либо из семантических групп, ранее входивших в самостоятельное поле (оно преодолевает порог статистической значимости), то мы начинаем рассматривать эту группу в качестве актуализировавшегося в новых условиях поля. Таким образом, основным критерием выделения самостоятельных полей является для нас статистический показатель. Подобный подход, на наш взгляд, более органичен для изучения способного изменяться во времени понятийного феномена, т. к. структурированность этого феномена обнаруживается не исходя из имманентных свойств входящих в него единиц (они принципиально понимаются как подвижные), а опираясь на особенности его функционирования (проявляющиеся во вновь привлекаемом материале). Заметим, что понятия ядро и периферия, традиционно используемые для описания поля, в графосемантическом моделировании оказываются востребованными при описании системы связей между полями.
3. Обнаружение основным связей между полями.
Следующий этап моделирования предполагает определение количества связей между выявленными полями и силы этих связей. Для достижения данной цели необходимо высчитать общее количество взаимодействий, которое образует каждое поле с другими полями в рамках смыслового пространства каждого контекста. Полагается, что, если два компонента выделяются при анализе одного и того же контекста, то они становятся связанными между собой через отнесение их к одному высказыванию (контексту), соответствующим образом мы делаем вывод о связи между полями, в которые входят указанные компоненты.
Подобным образом анализируется весь материал и выявляется исчерпывающее количество взаимосвязей между полями в рамках каждого контекста. Затем производится подсчет количества одинаковых связей, образованных каждым полем. Одинаковые связи одного поля истолковываются как одна и та же связь, но имеющая повышенную интенсивность. Поэтому суммированное значение одинаковых связей становится показателем силы каждой связи каждого поля.
4. Графическая экспликация результатов анализа.
После выявления количества связей каждого поля с другими полями в рамках всей выборки контекстов, производится графическая экспликация данных результатов, т. е. строится семантический граф. Само построение семантического графа из уже имеющихся (предварительно выявленных) семантических связей состоит из ряда простых операций:
1) необходимо расположить компоненты на графической плоскости;
2) определить из всего набора обнаруженных связей значимые (главным образом, учитывая статистические закономерности);
3) с помощью соединительных стрелок отметить наличие установленных связей между компонентами.
5. Интерпретация полученной графосемантической модели.
После построения семантического графа производится интерпретация полученной модели.
Для этого сначала определяются роли компонентов и структур в рамках всей системы. Система может представлять собой единое гомогенное целое, но нередко возникает ситуация, когда она распадается на ряд автономных структур. Каждую из них можно считать самостоятельным графом. В таких случаях, как правило, в рамках всей системы один из графов (с наибольшим числом компонентов) становится доминирующим. Таким образом, анализ построенной модели предполагает определение наличия автономных структур, выявление образующих их подструктур, установление их статуса (доминантная, периферийная). Затем исследуются компоненты, входящие в каждую из структур. В целом, все компоненты можно разделить:
1. По степени принадлежности к той или иной подструктуре:
а) принадлежащие одной подструктуре; б) принадлежащие нескольким подструктурам одновременно.
2. По роли в подструктуре:
а) ядерные компоненты (группирующие вокруг себя некоторое количество зависимых от них компонентов, но не имеющие непосредственной связи с другими ядерными компонентами); б) второстепенные компоненты (образующие какое-то количество связей помимо связи с ядерным компонентом подструктуры, но не имеющие связи с другими ядерными компонентами); в) компоненты-посредники (связывающие две автономные подструктуры); г) тупиковые компоненты (связанные только с одним компонентом (ядерным, второстепенным, посредником)).