Страница:
Обзор почты DCOM неизменно был для этой книги источником вдохновения и идей. Отдельное спасибо тем, кто прочесывает DCOM для меня: печально известному Марку Райланду (Mark Ryland), СОМ-вундеркииду Майку Нелсону (Mike Nelson), Кэйт Браун (Keith Brown), Тиму Эвалду (Tim Ewald), Крису Селлсу (Chris Sells), Сайджи Эйбрахам (Saji Abraham), Хэнку де Кёнингу (Henk De Koning), Стиву Робинсону (Steve Robinson), Антону фон Штраттену (Anton von Stratten) и Рэнди Путтику (Randy Puttick).
На сюжет этой книги сильно повлияло мое преподавание СОМ в DevelopMentor в течение нескольких последних лет. Этот сюжет формировался студентами в той же мере, как и моими коллегами-преподавателями. Я мог бы поблагодарить персонально каждого студента. Эддисон Уэсли (Addison Wesley) ограничил авторское предисловие всего лишь двадцатью страницами, я благодарю нынешний состав DevelopMentor, который помог мне отточить мое понимание Essential СОМ посредством преподавания соответствующего курса и обеспечением бесценной обратной связи: Рона Сумиду (Ron Sumida), Фрица Ониона (Fritz Onion), Скотта Батлера (Scott Butler), Оуэна Толмана (Owen Tallman), Джорджа Шеферда (George Shepherd), Тэда Пэттисона (Ted Pattison), Кейт Браун (Keith Brown), Тима Эвалда (Tim Ewald) и Криса Селлса (Chris Sells). Спасибо вам, ребята! Мои благодарности также Майку Эберкромби (Mike Abercrombie) из DevelopMentor за создание такого окружения, где научный рост участника не сдерживался коммерцией.
Книга могла бы выйти значительно раньше, если бы не Терри Кеннеди (Terry Kennedy) и его друзья из Software AG. Терри был весьма любезен, пригласив меня в Германию помочь им с работой по DCOM/UNIX как раз во время годичного отпуска, который я вырвал специально для написания этой книги. Хотя книга и вышла годом позже из-за того, что я не мог сказать Терри «нет» (это моя вина, а не Терри), но я думаю, что книга получилась несравненно лучше благодаря тому времени, которое я провел за их проектом. В частности, я значительно усилил свою интуицию, работая с Харалдом Стилом (Harald Stiehl), Винни Фролих (Winnie Froehlich), Фолкером Денкхаузом (Volker Denkhaus), Дитмаром Гётнером (Deitmar Gaeitner), Джеффом Ли (Jeff Lee), Дейтером Кеслером (Deiter Kesler), Мартином Кохом (Martin Koch), Блауэром Ауфом (Blauer Aff), Ули Кессом (Uli Kaess), Стивом Уайлдом (Steve Wild) и прославленным Томасом Воглером (Thomas Vogler).
Особые благодарности внимательным читателям, нашедшим ошибки в прежних изданиях этой книги: Тэду Неффу (Ted Neff), Дэну Мойеру (Dan Moyer), Пурушу Рудрекшале (Purush Rudrakshala), Хенгу де Коненгу (Heng de Koneng), Дэйву Хэйлу (Dave Hale), Джорджу Рейли (George Reilly), Стиву Де-Лассусу (Steve DeLassus), Уоррену Янгу (Warren Young), Джеффу Просайзу (Jeff Prosise), Ричарду Граймсу (Richard Grimes), Бэрри Клэвенсу (Barry Klawans), Джеймсу Баумеру (James Bowmer), Стефану Сасу (Stephan Sas), Петеру Заборски (Peter Zaborski), Кристоферу Л. Экерли (Christopher L. Akerley), Роберту Бруксу (Robert Brooks), Джонатану Прайеру (Jonathan Prior), Аллену Чамберсу (Alien Chambers), Тимо Кеттунену (Timo Kettunen), Атулсу Моидекару (Atulx Mohidekar), Крису Хиамсу (Chris Hyams), Максу Рубинштейну (Мах Rubinstein), Брэди Хойзингеру (Bradey Honsinger), Санни Томасу (Sunny Thomas), Гарднеру фон Холту (Gardner von Holt) и Тони Вервилосу (Tony Vervilos).
И, наконец, спасибо Шаху Джехану (Shah Jehan) и корпорации «Coca-Cola» за заправку этой затеи горючим в виде производства соответственно превосходной индийской пищи и доступных безалкогольных напитков.
Дон Бокс
Redondo Beach, CA
Август 1997 года
http://www.develop.com/dbox
http://delphi.vitpc.com ), и Артему Артемьеву, ведущему программисту фирмы Data Art, за консультации и помощь при выборе книг для издания.
На сюжет этой книги сильно повлияло мое преподавание СОМ в DevelopMentor в течение нескольких последних лет. Этот сюжет формировался студентами в той же мере, как и моими коллегами-преподавателями. Я мог бы поблагодарить персонально каждого студента. Эддисон Уэсли (Addison Wesley) ограничил авторское предисловие всего лишь двадцатью страницами, я благодарю нынешний состав DevelopMentor, который помог мне отточить мое понимание Essential СОМ посредством преподавания соответствующего курса и обеспечением бесценной обратной связи: Рона Сумиду (Ron Sumida), Фрица Ониона (Fritz Onion), Скотта Батлера (Scott Butler), Оуэна Толмана (Owen Tallman), Джорджа Шеферда (George Shepherd), Тэда Пэттисона (Ted Pattison), Кейт Браун (Keith Brown), Тима Эвалда (Tim Ewald) и Криса Селлса (Chris Sells). Спасибо вам, ребята! Мои благодарности также Майку Эберкромби (Mike Abercrombie) из DevelopMentor за создание такого окружения, где научный рост участника не сдерживался коммерцией.
Книга могла бы выйти значительно раньше, если бы не Терри Кеннеди (Terry Kennedy) и его друзья из Software AG. Терри был весьма любезен, пригласив меня в Германию помочь им с работой по DCOM/UNIX как раз во время годичного отпуска, который я вырвал специально для написания этой книги. Хотя книга и вышла годом позже из-за того, что я не мог сказать Терри «нет» (это моя вина, а не Терри), но я думаю, что книга получилась несравненно лучше благодаря тому времени, которое я провел за их проектом. В частности, я значительно усилил свою интуицию, работая с Харалдом Стилом (Harald Stiehl), Винни Фролих (Winnie Froehlich), Фолкером Денкхаузом (Volker Denkhaus), Дитмаром Гётнером (Deitmar Gaeitner), Джеффом Ли (Jeff Lee), Дейтером Кеслером (Deiter Kesler), Мартином Кохом (Martin Koch), Блауэром Ауфом (Blauer Aff), Ули Кессом (Uli Kaess), Стивом Уайлдом (Steve Wild) и прославленным Томасом Воглером (Thomas Vogler).
Особые благодарности внимательным читателям, нашедшим ошибки в прежних изданиях этой книги: Тэду Неффу (Ted Neff), Дэну Мойеру (Dan Moyer), Пурушу Рудрекшале (Purush Rudrakshala), Хенгу де Коненгу (Heng de Koneng), Дэйву Хэйлу (Dave Hale), Джорджу Рейли (George Reilly), Стиву Де-Лассусу (Steve DeLassus), Уоррену Янгу (Warren Young), Джеффу Просайзу (Jeff Prosise), Ричарду Граймсу (Richard Grimes), Бэрри Клэвенсу (Barry Klawans), Джеймсу Баумеру (James Bowmer), Стефану Сасу (Stephan Sas), Петеру Заборски (Peter Zaborski), Кристоферу Л. Экерли (Christopher L. Akerley), Роберту Бруксу (Robert Brooks), Джонатану Прайеру (Jonathan Prior), Аллену Чамберсу (Alien Chambers), Тимо Кеттунену (Timo Kettunen), Атулсу Моидекару (Atulx Mohidekar), Крису Хиамсу (Chris Hyams), Максу Рубинштейну (Мах Rubinstein), Брэди Хойзингеру (Bradey Honsinger), Санни Томасу (Sunny Thomas), Гарднеру фон Холту (Gardner von Holt) и Тони Вервилосу (Tony Vervilos).
И, наконец, спасибо Шаху Джехану (Shah Jehan) и корпорации «Coca-Cola» за заправку этой затеи горючим в виде производства соответственно превосходной индийской пищи и доступных безалкогольных напитков.
Дон Бокс
Redondo Beach, CA
Август 1997 года
http://www.develop.com/dbox
http://delphi.vitpc.com ), и Артему Артемьеву, ведущему программисту фирмы Data Art, за консультации и помощь при выборе книг для издания.
Ваши замечания, предложения, вопросы отправляйте по адресу электронной почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на Web-сайте издательства http://www.piter.com .
Все исходные тексты, приведенные в книге, вы найдете по адресу http://www.piter.com/download
Глава 1. СОМ как улучшенный C++
template <class Т, class Ex>
class listt: virtual protected CPrivateAlloc {
list<T**> mlist;
mutable TWnd mwnd;
virtual ~listt(void);
protected:
explicit listt(int nElems, …);
inline operator unsigned int *(void) const
{ return reinterpretcast <int*>(this) ; }
template <class X> void clear(X& rx) const throw(Ex);
};
Аноним, 1996
C++ уже давно с нами. Сообщество программистов на C++ весьма обширно, и большинство из них хорошо знают о западнях и подводных камнях языка. Язык C++ был создан высоко квалифицированной командой разработчиков, которые, работая в Bell Laboratories, выпустили не только первый программный продукт C++ (CFRONT), но и опубликовали много конструктивных работ о C++. Большинство правил языка C++ было опубликовано в конце 1980-х и начале 1990-х годов. В этот период многие разработчики C++ (включая авторов практически каждой значительной книги по C++) работали на рабочих станциях UNIX и создавали довольно монолитные приложения, использующие технологию компиляции и компоновки того времени. Ясно, что среда, в которой работало это поколение программистов, была в основном создана умами всего сообщества C++.
Одной из главных целей языка C++ являлось позволить программистам строить типы, определенные пользователем (user-defined types – UDTs), которые затем можно было бы использовать вне их исходного контекста. Этот принцип лег в основу идеи создания библиотек классов, или структур, какими мы знаем их сегодня. С момента появления C++ рынок библиотек классов C++ расширялся, хотя и довольно медленно. Одной из причин того. что этот рынок рос не так быстро, как можно было ожидать, был NIH-фактор (not invented here – «изобретен не здесь») среди разработчиков C++. Использовать код других разработчиков часто представляется более трудным, чем воспроизведение собственных наработок. Иногда это представление базируется исключительно на высокомерии разработчика. В других случаях сопротивление использованию чужого кода проистекает из неизбежности дополнительного умственного усилия, необходимого для понимания чужой идеологии и стиля программирования. Это особенно верно для библиотек-оберток (wrappers), когда необходимо понять не только технологию того, что упаковано, но и дополнительные абстракции, добавленные самой библиотекой.
Другая проблема: многие библиотеки составлены с расчетом на то, что пользователь будет обращаться к исходному коду данной библиотеки как к эталону. Такое повторное использование «белого ящика» часто приводит к огромному количеству связей между программой клиента и библиотекой классов, что с течением времени усиливает неустойчивость всей программы. Эффект чрезмерной связи ослабляет модульный принцип библиотеки классов и усложняет адаптацию к изменениям в реализации основной библиотеки. Это побуждает пользователей относиться к библиотеке как всего лишь к одной из частей исходного кода проекта, а не как к модулю повторного использования. Действительно, разработчики фактически подгоняют коммерческие библиотеки классов под собственные нужды, выпуская «собственную версию», которая лучше приспособлена к данному программному продукту, но уже не является оригинальной библиотекой.
Повторное использование (reuse) кода всегда было одной из классических мотиваций объектного ориентирования. Несмотря на это обстоятельство, написание классов C++, простых для повторного использования, довольно затруднительно. Помимо таких препятствий для повторного использования, как этап проектирования (design-time) и этап разработки (development-time), которые уже можно считать частью культуры C++, существует и довольно большое число препятствий на этапе выполнения (runtime), что делает объектную модель C++ далекой от идеала для создания программных продуктов повторного использования. Многие из этих препятствий обусловлены моделями компиляции и компоновки, принятой в C++. Данная глава будет посвящена техническим проблемам приведения классов C++ к виду компонентов повторного использования. Все задачи будут решаться методами программирования, которые базируются на готовых общедоступных (off-the-shelf) технологиях. В этой главе будет показано, как, применяя эти технологии, можно создать архитектуру для повторного использования модулей, которая позволяла бы динамично и эффективно строить системы из независимо сконструированных двоичных компонентов.
Распространение программного обеспечения и язык С++
Для понимания проблем, связанных с использованием C++ как набора компонентов, полезно проследить, как распространялись библиотеки C++ в конце 1980-х годов. Представим себе разработчика библиотек, который создал алгоритм поиска подстрок за время O(1) (то есть время поиска постоянно, а не пропорционально длине строки). Это, как известно, нетривиальная задача. Для того чтобы сделать алгоритм возможно более простым для пользователя, разработчик должен создать класс строк, основанный на алгоритме, который будет быстро передавать текстовые строки (fast text strings) в любую программу клиента. Чтобы сделать это, разработчику необходимо подготовить заголовочный файл, содержащий определение класса:
// faststring.h
class FastString
{
char *mpsz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset
//возвращает смещение
};
После того как класс определен, разработчик должен реализовать его функции-члены в отдельном файле:
// FastString.cpp
#include «faststring.h»
#include <string.h>
FastString::FastString(const char *psz) : mpsz(new char [strlen(psz) + 1])
{ strcpy(mpsz, psz); }
FastString::~FastString(void)
{ delete[] mpsz; }
int FastString::Length(void) const
{ return strlen(mpsz); }
int FastString::Find(const char *psz) const
{
//O(1) lookup code deleted for> clarity
1
// код поиска 0(1) удален для ясности
}
Библиотеки C++ традиционно распространялись в форме исходного кода. Ожидалось, что пользователи библиотеки будут добавлять реализации исходных файлов и создаваемую ими систему и перекомпилировать библиотечные исходные файлы на месте, с использованием своего компилятора C++. Если предположить, что библиотека написана на наиболее употребительной версии языка C++, то такой подход был бы вполне работоспособным. Подводным камнем этой схемы было то, что исполняемый код этой библиотеки должен был включаться во все клиентские приложения.
Предположим, что для показанного выше класса FastString сгенерированный машинный код для четырех методов занял 16 Мбайт пространства в результирующем исполняемом файле. Напомним, что при выполнении O(1)-поиска может потребоваться много пространства для кода, чтобы обеспечить заданное время исполнения, – дилемма, которая ограничивает большинство алгоритмов. Как показано на рис. 1.1, если три приложения используют библиотеку FastString, то каждая из трех исполняемых программ будет включать в себя по 16 Мбайт кода. Это означает, что если конечный пользователь инсталлирует все три клиентских приложения, то реализация FastString займет 48 Мбайт дискового пространства. Хуже того – если конечный пользователь запустит все три клиентских приложения одновременно, то код FastString займет 48 Мбайт виртуальной памяти, так как операционная система не может обнаружить дублирующий код, имеющийся в каждой исполняемой программе.
 Есть еще одна проблема в таком сценарии: когда разработчик библиотеки находит дефект в классе FastString, нет способа всюду заменить его реализацию. После того как код FastString скомпонован с клиентским приложением, невозможно исправить машинный код FastString непосредственно в компьютере конечного пользователя. Вместо этого разработчик библиотеки должен известить разработчиков каждого клиентского приложения об изменениях в исходном коде и надеяться, что они переделают свои приложения, чтобы получить эффект от этих исправлений. Ясно, что модульность компонента FastString утрачивается, как только клиент запускает компоновщик и заново формирует исполняемый файл.
Есть еще одна проблема в таком сценарии: когда разработчик библиотеки находит дефект в классе FastString, нет способа всюду заменить его реализацию. После того как код FastString скомпонован с клиентским приложением, невозможно исправить машинный код FastString непосредственно в компьютере конечного пользователя. Вместо этого разработчик библиотеки должен известить разработчиков каждого клиентского приложения об изменениях в исходном коде и надеяться, что они переделают свои приложения, чтобы получить эффект от этих исправлений. Ясно, что модульность компонента FastString утрачивается, как только клиент запускает компоновщик и заново формирует исполняемый файл.
// faststring.h
class FastString
{
char *mpsz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset
//возвращает смещение
};
После того как класс определен, разработчик должен реализовать его функции-члены в отдельном файле:
// FastString.cpp
#include «faststring.h»
#include <string.h>
FastString::FastString(const char *psz) : mpsz(new char [strlen(psz) + 1])
{ strcpy(mpsz, psz); }
FastString::~FastString(void)
{ delete[] mpsz; }
int FastString::Length(void) const
{ return strlen(mpsz); }
int FastString::Find(const char *psz) const
{
//O(1) lookup code deleted for> clarity
1
// код поиска 0(1) удален для ясности
}
Библиотеки C++ традиционно распространялись в форме исходного кода. Ожидалось, что пользователи библиотеки будут добавлять реализации исходных файлов и создаваемую ими систему и перекомпилировать библиотечные исходные файлы на месте, с использованием своего компилятора C++. Если предположить, что библиотека написана на наиболее употребительной версии языка C++, то такой подход был бы вполне работоспособным. Подводным камнем этой схемы было то, что исполняемый код этой библиотеки должен был включаться во все клиентские приложения.
Предположим, что для показанного выше класса FastString сгенерированный машинный код для четырех методов занял 16 Мбайт пространства в результирующем исполняемом файле. Напомним, что при выполнении O(1)-поиска может потребоваться много пространства для кода, чтобы обеспечить заданное время исполнения, – дилемма, которая ограничивает большинство алгоритмов. Как показано на рис. 1.1, если три приложения используют библиотеку FastString, то каждая из трех исполняемых программ будет включать в себя по 16 Мбайт кода. Это означает, что если конечный пользователь инсталлирует все три клиентских приложения, то реализация FastString займет 48 Мбайт дискового пространства. Хуже того – если конечный пользователь запустит все три клиентских приложения одновременно, то код FastString займет 48 Мбайт виртуальной памяти, так как операционная система не может обнаружить дублирующий код, имеющийся в каждой исполняемой программе.
Динамическая компоновка и С++
Один из путей решения этих проблем – упаковка класса FastString в динамически подключаемую библиотеку (Dynamic Link Library – DLL). Это может быть сделано несколькими способами. Простейший из них – использовать директиву компилятора, действующую на уровне классов, чтобы заставить все методы FastString экспортироваться из DLL. Компилятор Microsoft C++ предусматривает для этого ключевое слово _declspec(dllexport):
class _declspec(dllexport) FastString
{
char *m_psz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset
// возвращает смещение
};
В этом случае все методы FastString будут добавлены в список экспорта соответствующей библиотеки DLL, что позволит записать время выполнения каждого метода в его адрес в памяти. Кроме того, компоновщик создаст библиотеку импорта (import library), которая объявляет символы для методов FastString. Вместо того чтобы содержать сам код, библиотека импорта включает в себя ссылки на имя файла DLL и имена экспортируемых символов. Когда клиент обращается к библиотеке импорта, эти ссылки добавляются к исполняемой программе. Это побуждает загрузчик динамически загружать DLL FastString во время выполнения и размещать импортируемые символы в соответствующие ячейки памяти. Это размещение автоматически происходит в момент запуска клиентской программы операционной системой.
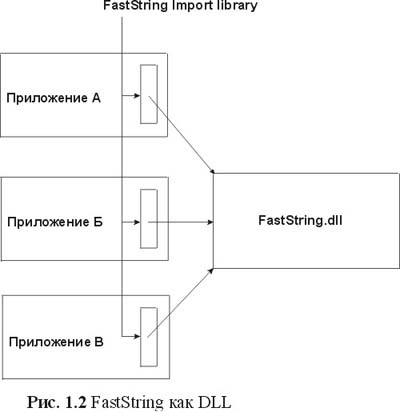
Рисунок 1.2 иллюстрирует модель FastString на этапе выполнения (runtime model), объявляемую из DLL. Заметим, что библиотека импорта достаточно мала (примерно вдвое больше, чем суммарный размер экспортируемого символьного текста). Когда класс экспортируется из DLL, код FastString должен присутствовать на жестком диске пользователя только один раз. Если даже несколько клиентов применяют этот код для своей библиотеки, загрузчик операционной системы обладает достаточным интеллектом, чтобы разделить физические страницы памяти, содержащие исполняемый код FastString (только для чтения), между всеми клиентскими программами. Кроме того, если разработчик библиотеки найдет дефект в исходном коде, теоретически возможно послать новую DLL конечному пользователю, исправляя дефектную реализацию для всех клиентских приложений сразу. Ясно, что перемещение библиотеки FastString в DLL является важным шагом на пути превращения класса C++ в заменяемый и эффективный компонент повторного использования.
class _declspec(dllexport) FastString
{
char *m_psz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset
// возвращает смещение
};
В этом случае все методы FastString будут добавлены в список экспорта соответствующей библиотеки DLL, что позволит записать время выполнения каждого метода в его адрес в памяти. Кроме того, компоновщик создаст библиотеку импорта (import library), которая объявляет символы для методов FastString. Вместо того чтобы содержать сам код, библиотека импорта включает в себя ссылки на имя файла DLL и имена экспортируемых символов. Когда клиент обращается к библиотеке импорта, эти ссылки добавляются к исполняемой программе. Это побуждает загрузчик динамически загружать DLL FastString во время выполнения и размещать импортируемые символы в соответствующие ячейки памяти. Это размещение автоматически происходит в момент запуска клиентской программы операционной системой.
Рисунок 1.2 иллюстрирует модель FastString на этапе выполнения (runtime model), объявляемую из DLL. Заметим, что библиотека импорта достаточно мала (примерно вдвое больше, чем суммарный размер экспортируемого символьного текста). Когда класс экспортируется из DLL, код FastString должен присутствовать на жестком диске пользователя только один раз. Если даже несколько клиентов применяют этот код для своей библиотеки, загрузчик операционной системы обладает достаточным интеллектом, чтобы разделить физические страницы памяти, содержащие исполняемый код FastString (только для чтения), между всеми клиентскими программами. Кроме того, если разработчик библиотеки найдет дефект в исходном коде, теоретически возможно послать новую DLL конечному пользователю, исправляя дефектную реализацию для всех клиентских приложений сразу. Ясно, что перемещение библиотеки FastString в DLL является важным шагом на пути превращения класса C++ в заменяемый и эффективный компонент повторного использования.
C++ и мобильность
Поскольку вы решили распространять классы C++ как DLL, вы непременно столкнетесь с одним из фундаментальных недостатков C++ – недостаточной стандартизацией на двоичном уровне. Хотя рабочий документ ISO/ANSI C++ Draft Working Paper (DWP) предпринимает попытку определить, какие программы будут транслироваться и каковы будут семантические эффекты при их запуске, двоичная динамическая модель C++ ею не стандартизируется. Впервые клиент сталкивается с этой проблемой при попытке скомпоновать библиотеку импорта DLL FastString из среды развития C++, отличной от той, в которой он привык строить эту DLL.
Для обеспечения перегрузки операторов и функций компиляторы C++ обычно видоизменяют символическое имя каждой точки входа, чтобы разрешить многократное использование одного и того же имени (или с различными типами аргументов, или в различных областях действия) без нарушения работы существующих компоновщиков для языка С. Этот прием часто называют коррекцией имени. Несмотря на то что ARM (C++ Annotated Reference Manual) документировала схему кодирования, использующуюся в CFRONT, многие разработчики трансляторов предпочли создать свою собственную схему коррекции. Поскольку библиотека импорта FastString и DLL экспортирует символы, используя корректирующую схему того транслятора, который создал DLL (то есть GNU C++), клиенты, скомпилированные другим транслятором (например, Borland C++), не могут быть корректно скомпонованы с библиотекой импорта. Классическая методика использования extern "С" для отключения коррекции символов не поможет в данном случае, так как DLL экспортирует функции-члены (методы), а не глобальные функции.
Для решения этой проблемы можно проделать фокусы с клиентским компоновщиком, применяя файл описания модуля (Module Definition File), известный как DEF-файл. Одно из свойств DEF-файлов заключается в том, что они позволяют экспортируемым символам совмещаться с различными импортируемыми символами. Имея достаточно времени и информации относительно каждой схемы коррекции, разработчик библиотек может создать особую библиотеку импорта для каждого компилятора. Это утомительно, но зато позволяет любому компилятору обеспечить совместимость с DLL на уровне компоновки, при условии, что разработчик библиотеки заранее ожидал ее использование и создал нужный DEF-файл.
Если вы разрешили проблемы, возникшие при компоновке, вам еще придется столкнуться с более сложными проблемами несовместимости, которые связаны со сгенерированным кодом. За исключением простейших языковых конструкций, разработчики трансляторов часто предпочитают реализовывать особенности языка своими собственными путями. Это формирует объекты, недоступные для кода, созданного любым другим компилятором. Классическим примером таких языковых особенностей являются исключительные ситуации (исключения). Исключительная ситуация в среде C++, исходящая от функции, которая была транслирована компилятором Microsoft, не может быть надежно перехвачена клиентской программой, оттранслированной компилятором Watcom. Это происходит потому, что DWP не может определить, как должна выглядеть та или иная особенность языка на этапе выполнения, поэтому для каждого разработчика компилятора вполне естественно реализовать такую языковую особенность в своей собственной, новаторской манере. Это несущественно при построении независимой однобинарной (single-binary) исполняемой программы, так как весь код будет транслироваться и компоноваться в одной и той же среде. При построении мультибинарных (multibinary) исполняемых программ, основанных на компонентах (component-based), это представляет серьезную проблему, так как каждый компонент может, очевидно, быть построен с использованием другого компилятора и компоновщика. Отсутствие двоичного стандарта в C++ ограничивает возможности того, какие особенности языка могут быть использованы вне границ DLL. Это означает, что простой экспорт функций-членов C++ из DLL недостаточен для создания независимого от разработчика набора компонентов.
Для обеспечения перегрузки операторов и функций компиляторы C++ обычно видоизменяют символическое имя каждой точки входа, чтобы разрешить многократное использование одного и того же имени (или с различными типами аргументов, или в различных областях действия) без нарушения работы существующих компоновщиков для языка С. Этот прием часто называют коррекцией имени. Несмотря на то что ARM (C++ Annotated Reference Manual) документировала схему кодирования, использующуюся в CFRONT, многие разработчики трансляторов предпочли создать свою собственную схему коррекции. Поскольку библиотека импорта FastString и DLL экспортирует символы, используя корректирующую схему того транслятора, который создал DLL (то есть GNU C++), клиенты, скомпилированные другим транслятором (например, Borland C++), не могут быть корректно скомпонованы с библиотекой импорта. Классическая методика использования extern "С" для отключения коррекции символов не поможет в данном случае, так как DLL экспортирует функции-члены (методы), а не глобальные функции.
Для решения этой проблемы можно проделать фокусы с клиентским компоновщиком, применяя файл описания модуля (Module Definition File), известный как DEF-файл. Одно из свойств DEF-файлов заключается в том, что они позволяют экспортируемым символам совмещаться с различными импортируемыми символами. Имея достаточно времени и информации относительно каждой схемы коррекции, разработчик библиотек может создать особую библиотеку импорта для каждого компилятора. Это утомительно, но зато позволяет любому компилятору обеспечить совместимость с DLL на уровне компоновки, при условии, что разработчик библиотеки заранее ожидал ее использование и создал нужный DEF-файл.
Если вы разрешили проблемы, возникшие при компоновке, вам еще придется столкнуться с более сложными проблемами несовместимости, которые связаны со сгенерированным кодом. За исключением простейших языковых конструкций, разработчики трансляторов часто предпочитают реализовывать особенности языка своими собственными путями. Это формирует объекты, недоступные для кода, созданного любым другим компилятором. Классическим примером таких языковых особенностей являются исключительные ситуации (исключения). Исключительная ситуация в среде C++, исходящая от функции, которая была транслирована компилятором Microsoft, не может быть надежно перехвачена клиентской программой, оттранслированной компилятором Watcom. Это происходит потому, что DWP не может определить, как должна выглядеть та или иная особенность языка на этапе выполнения, поэтому для каждого разработчика компилятора вполне естественно реализовать такую языковую особенность в своей собственной, новаторской манере. Это несущественно при построении независимой однобинарной (single-binary) исполняемой программы, так как весь код будет транслироваться и компоноваться в одной и той же среде. При построении мультибинарных (multibinary) исполняемых программ, основанных на компонентах (component-based), это представляет серьезную проблему, так как каждый компонент может, очевидно, быть построен с использованием другого компилятора и компоновщика. Отсутствие двоичного стандарта в C++ ограничивает возможности того, какие особенности языка могут быть использованы вне границ DLL. Это означает, что простой экспорт функций-членов C++ из DLL недостаточен для создания независимого от разработчика набора компонентов.
Инкапсуляция и С++
Предположим, что вам удалось преодолеть проблемы с транслятором и компоновщиком, описанные в предыдущем разделе. Очередное препятствие при построении двоичных компонентов на C++ появится, когда вы будете проводить инкапсуляцию (encapsulation), то есть формирование пакета. Посмотрим, что получится, если организация, использующая FastString в приложении, возьмется выполнить невыполнимое: закончит разработку и тестирование за два месяца до срока рассылки продукта. Пусть также в течение этих двух месяцев некоторые из наиболее скептически настроенных разработчиков решили протестировать O(1) -поисковый алгоритм FastString , запустив профайлер своего приложения. К их большому удивлению, FastString::Find стала бы на самом деле работать очень быстро, независимо от заданной длины строки. Однако с оператором Length дело обстоит не столь хорошо, так как FastString::Length использует подпрограмму strlen из динамической библиотеки С. Эта подпрограмма – алгоритм O(n)– осуществляет линейный поиск по строкам с использованием символа конца строки (null terminator); скорость его работы пропорциональна длине строки. Столкнувшись с тем, что клиентское приложение может многократно вызывать оператор Length, один из таких скептиков, скорее всего, свяжется с разработчиком библиотеки и попросит его убыстрить Length, чтобы его работа также не зависела от длины строки. Но здесь есть одно препятствие. Разработчик библиотеки уже закончил свою разработку и, скорее всего, не расположен менять одну строку исходного кода, чтобы воспользоваться преимуществами улучшенного метода Length. Кроме того, некоторые другие разработчики, возможно, уже выпустили свои продукты, основанные на текущей версии FastString, и теперь разработчик библиотеки не имеет морального права изменять эти приложення.
С этой точки зрения нужно просто вернуться к определению класса FastString и решить, что можно изменить и что необходимо сохранить, чтобы уже установленная база успешно функционировала. К счастью, класс FastString был разработан с учетом возможности инкапсуляции, и все его элементы данных (data members ) являются закрытыми (private ). Это придает классу значительную гибкость, так как ни одна клиентская программа не может непосредственно получить доступ к элементам данных FastString. В силу того, что по отношению к четырем открытым (public ) членам класса не было сделано никаких изменений, то и в любом клиентском приложении никаких изменений также не потребуется. Вооружившись этой верой, разработчик библиотеки переходит к реализации FastString версии 2.0.
Очевидным улучшением является следующее решение: в тексте конструктора (constructor ) занести длину строки в кэш и возвращать кэшированную длину в новой версии метода Length . Так как строка не может быть изменена после создания, нет необходимости беспокоиться, что ее длина будет вычисляться многократно. В действительности длина уже однажды вычислена в конструкторе при назначении буфера, так что понадобится только горстка дополнительных машинных инструкций. Вот каким будет модифицированное определение класса:
// faststring.h version 2.0
class declspec(dllexport) FastString {
const int mcch;
// count of characters
// число символов
char mpsz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset – возвращает смещение
};
Отметим, что единственной модификацией является добавление закрытого элемента данных. Чтобы правильно инициализировать такой элемент, конструктор должен быть изменен следующим образом:
FastString::FastString(const char *psz) : mcch(strlen(psz)), mpsz(new char[mcch + 1])
{
strcpy(mpsz, psz);
}
С введением кэшированной длины метод Length становится тривиальным:
int FastString::Length(void) const
{
return mcch;
// return cached length
// возвращает скрытую длину
}
Сделав эти три модификации, разработчик библиотеки может теперь перестроить DLL FastString и сопутствующий ей набор тестов, которые полностью проверяют каждый аспект класса FastString . Разработчик будет приятно удивлен, узнав, что принцип инкапсуляции обошелся ему дешево, и в исходных текстах тестов не понадобилось делать никаких изменений. После проверки того. что новая DLL работает правильно, разработчик библиотек отсылает FastString версии 2.0 клиенту, будучи уверенным, что вся работа завершена.
Когда клиенты, заказавшие изменения, получают модернизированный FastString , они включают новое определение класса и DLL в систему контроля своего исходного кода и запускают тестирование нового и улучшенного FastString . Подобно разработчику библиотеки, они тоже приятно удивлены: для того, чтобы воспользоваться преимуществами новой версии Length , не требуется никаких модификаций исходного кода. Вдохновленная этим опытом, команда разработчиков убеждает начальство включить новую DLL в окончательный «золотой» CD, уже готовый для выпуска. Это тот редкий случай, когда руководство идет навстречу энтузиастам-разработчикам и включает в окончательный продукт новую DLL. Подобно большинству программ инсталляции, описание установки клиентской программы настроено на молчаливое (без предупреждения) замещение всех старых версий FastString DLL, какие есть на машине конечного пользователя. Это выглядит вполне безобидно, поскольку эти изменения не затронули открытый интерфейс класса, так что тотальная молчаливая модернизация под версию 2.0 FastString только улучшит любые имеющиеся клиентские приложения, которые были установлены раньше.
С этой точки зрения нужно просто вернуться к определению класса FastString и решить, что можно изменить и что необходимо сохранить, чтобы уже установленная база успешно функционировала. К счастью, класс FastString был разработан с учетом возможности инкапсуляции, и все его элементы данных (data members ) являются закрытыми (private ). Это придает классу значительную гибкость, так как ни одна клиентская программа не может непосредственно получить доступ к элементам данных FastString. В силу того, что по отношению к четырем открытым (public ) членам класса не было сделано никаких изменений, то и в любом клиентском приложении никаких изменений также не потребуется. Вооружившись этой верой, разработчик библиотеки переходит к реализации FastString версии 2.0.
Очевидным улучшением является следующее решение: в тексте конструктора (constructor ) занести длину строки в кэш и возвращать кэшированную длину в новой версии метода Length . Так как строка не может быть изменена после создания, нет необходимости беспокоиться, что ее длина будет вычисляться многократно. В действительности длина уже однажды вычислена в конструкторе при назначении буфера, так что понадобится только горстка дополнительных машинных инструкций. Вот каким будет модифицированное определение класса:
// faststring.h version 2.0
class declspec(dllexport) FastString {
const int mcch;
// count of characters
// число символов
char mpsz;
public:
FastString(const char *psz);
~FastString(void);
int Length(void) const;
// returns # of characters
// возвращает число символов
int Find(const char *psz) const;
// returns offset – возвращает смещение
};
Отметим, что единственной модификацией является добавление закрытого элемента данных. Чтобы правильно инициализировать такой элемент, конструктор должен быть изменен следующим образом:
FastString::FastString(const char *psz) : mcch(strlen(psz)), mpsz(new char[mcch + 1])
{
strcpy(mpsz, psz);
}
С введением кэшированной длины метод Length становится тривиальным:
int FastString::Length(void) const
{
return mcch;
// return cached length
// возвращает скрытую длину
}
Сделав эти три модификации, разработчик библиотеки может теперь перестроить DLL FastString и сопутствующий ей набор тестов, которые полностью проверяют каждый аспект класса FastString . Разработчик будет приятно удивлен, узнав, что принцип инкапсуляции обошелся ему дешево, и в исходных текстах тестов не понадобилось делать никаких изменений. После проверки того. что новая DLL работает правильно, разработчик библиотек отсылает FastString версии 2.0 клиенту, будучи уверенным, что вся работа завершена.
Когда клиенты, заказавшие изменения, получают модернизированный FastString , они включают новое определение класса и DLL в систему контроля своего исходного кода и запускают тестирование нового и улучшенного FastString . Подобно разработчику библиотеки, они тоже приятно удивлены: для того, чтобы воспользоваться преимуществами новой версии Length , не требуется никаких модификаций исходного кода. Вдохновленная этим опытом, команда разработчиков убеждает начальство включить новую DLL в окончательный «золотой» CD, уже готовый для выпуска. Это тот редкий случай, когда руководство идет навстречу энтузиастам-разработчикам и включает в окончательный продукт новую DLL. Подобно большинству программ инсталляции, описание установки клиентской программы настроено на молчаливое (без предупреждения) замещение всех старых версий FastString DLL, какие есть на машине конечного пользователя. Это выглядит вполне безобидно, поскольку эти изменения не затронули открытый интерфейс класса, так что тотальная молчаливая модернизация под версию 2.0 FastString только улучшит любые имеющиеся клиентские приложения, которые были установлены раньше.