Страница:
Хотя C++ – чрезвычайно полезный язык программирования, существует множество областей программирования, где больше подходят другие языки. Но точно так же, как проблемы совместимости при компоновке можно решить путем обеспечения всех существующих компиляторов файлами определения модуля, возможно и перевести определение интерфейса с C++ на любые другие языки программирования. А так как двоичная сигнатура интерфейса есть просто сочетание vptr/vtbl, этот перевод может быть сделан для большой группы языков.
Проделывание этих языковых преобразований данных для всех известных интерфейсов потребовало бы огромного количества работы, а главное – невозможно успевать делать это для бурного потока языков программирования, которые индустрия программного обеспечения не устает изобретать чуть ли не каждую декаду. Идеально было бы написать сервисную программу, которая переводила бы определения класса C++ в некую абстрактную промежуточную форму. Из этой промежуточной формы такая программа могла бы преобразовывать данные для любого языка программирования, имеющего соответствующий выходной генератор (back-end generator). По мере того как новые языки приобретают значимость, могли бы добавляться новые выходные генераторы, и все ранее определенные интерфейсы смогли бы тотчас использоваться в совершенно новом контексте.
К сожалению, язык программирования C++ полон неоднозначностей, что делает его малопригодным для преобразования данных на все мыслимые языки. Многие из этих неоднозначностей приводят к неопределенным соотношениям между указателями, памятью и массивами. Это не является проблемой, когда оба объекта: вызывающий (caller) и вызываемый (callee) – скомпилированы на С или на C++, но они не могут быть точно переведены на другие языки без дополнительной квалификации. Поэтому, чтобы устранить зависимость определения интерфейса от языка, используемого в какой-либо конкретной реализации, необходимо для определений интерфейсов использовать один язык, а для определений реализации – другой. Если все участники договорятся о едином языке для определений интерфейсов, то станет возможным определить интерфейс однажды и получать по мере необходимости новые представления реализации на специфических языках. СОМ предусматривает язык, который основан на хорошо известном синтаксисе С, но добавляет возможность при переводе на другие языки корректно устранить неоднозначность любых особенностей языка С. Этот язык называется языком описаний интерфейса (Interface Definition Language – IDL).
IDL
Методы и их результаты
Интерфейсы и IDL
Интерфейс IUnknown
Проделывание этих языковых преобразований данных для всех известных интерфейсов потребовало бы огромного количества работы, а главное – невозможно успевать делать это для бурного потока языков программирования, которые индустрия программного обеспечения не устает изобретать чуть ли не каждую декаду. Идеально было бы написать сервисную программу, которая переводила бы определения класса C++ в некую абстрактную промежуточную форму. Из этой промежуточной формы такая программа могла бы преобразовывать данные для любого языка программирования, имеющего соответствующий выходной генератор (back-end generator). По мере того как новые языки приобретают значимость, могли бы добавляться новые выходные генераторы, и все ранее определенные интерфейсы смогли бы тотчас использоваться в совершенно новом контексте.
К сожалению, язык программирования C++ полон неоднозначностей, что делает его малопригодным для преобразования данных на все мыслимые языки. Многие из этих неоднозначностей приводят к неопределенным соотношениям между указателями, памятью и массивами. Это не является проблемой, когда оба объекта: вызывающий (caller) и вызываемый (callee) – скомпилированы на С или на C++, но они не могут быть точно переведены на другие языки без дополнительной квалификации. Поэтому, чтобы устранить зависимость определения интерфейса от языка, используемого в какой-либо конкретной реализации, необходимо для определений интерфейсов использовать один язык, а для определений реализации – другой. Если все участники договорятся о едином языке для определений интерфейсов, то станет возможным определить интерфейс однажды и получать по мере необходимости новые представления реализации на специфических языках. СОМ предусматривает язык, который основан на хорошо известном синтаксисе С, но добавляет возможность при переводе на другие языки корректно устранить неоднозначность любых особенностей языка С. Этот язык называется языком описаний интерфейса (Interface Definition Language – IDL).
IDL
СОМ IDL базируется на языке определения интерфейсов основного открытого математического обеспечения удаленного вызова процедур в распределенной вычислительной среде – Open Software Foundation Distributed Computing Environment Remote Procedure Call (OSF DCE RPC). DCE IDL позволяет описывать удаленные вызовы процедур не зависящим от языка способом. Это дает возможность компилятору IDL генерировать код для работы в сети, который прозрачным образом (transparently), то есть незаметно для пользователя, переносит описанные операции на всевозможные сетевые средства сообщения. СОМ IDL просто добавляет некоторые расширения, специфические для СОМ, в DCE IDL для поддержки объектно-ориентированных понятий СОМ (например, наследование, полиморфизм). Не случайно, что когда обращение к объектам СОМ осуществляется через границу контекста выполнения[1] или через границы между машинами, все связи клиент-объект используют MS-RPC (реализация DCE RPC, являющаяся частью Windows NT и Windows 95) как основное средство сообщения.
Win32 SDK включает в себя компилятор МIDL.ЕХЕ , который анализирует файлы СОМ IDL и генерирует несколько искусственных объектов – артефактов (artifacts). Как показано на рис. 2.1, MIDL генерирует совместимые с C/C++ заголовочные файлы, которые содержат определения абстрактного базового класса, соответствующие интерфейсам, описанным в исходном IDL-файле.
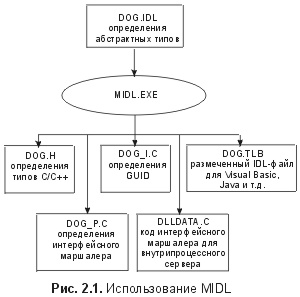
Эти заголовочные файлы также содержат совместимые с С, основанные на структурах определения (structure-based definitions), которые позволяют С-программам обращаться к интерфейсам, описанным на IDL, или обеспечивать их выполнение. То, что MIDL автоматически генерирует С/С++-заголовочный файл, означает, что ни один из СОМ-интерфейсов не нужно определять на C++ вручную. Исход определений из одной точки исключает возникновение множества несовместимых версий определений интерфейсов, которые со временем могут вызвать асинхронность. MIDL также генерирует исходный код, который позволяет использовать интерфейсы в различных потоках, процессах и машинах. Этот код будет обсуждаться в главе 5. И наконец, MIDL может генерировать двоичный файл, который позволяет другим средам, принимающим СОМ, отображать интерфейсы, определенные в исходном IDL-файле, на другие языки. Этот двоичный файл называется библиотекой типа (type library) и содержит разобранный файл IDL в наиболее эффективной для анализа форме. Библиотеки типа обычно распространяются как часть исполняемого файла реализации и позволяют таким языкам, как Visual Basic, Java, Object Pascal использовать интерфейсы, которые выставляются этой реализацией.
Чтобы понять IDL, необходимо рассмотреть логический и физический аспекты интерфейса. Обсуждение методов интерфейса и выполняемых ими операций относятся к логическому аспекту интерфейса. Обсуждение памяти, стекового фрейма, сетевых пакетов и других динамических явлений обычно относятся к физическому аспекту интерфейса. Некоторые физические аспекты интерфейса могут непосредственно наследовать логическому описанию (например, расположение таблицы vtbl , порядок параметров в стеке). Другие физические аспекты (например, границы массивов, сетевые представления сложных типов данных) требуют дополнительной квалификации.
IDL позволяет разработчикам интерфейса работать непосредственно в сфере логики, используя синтаксис С. Но в то же время IDL требует от разработчиков точно определять все те аспекты интерфейса, которые не могут быть воспроизведены непосредственно по их логическому описанию на С, с помощью использования аннотаций, формально называемых атрибутами. Атрибуты IDL легко распознать в основном тексте IDL: разделенные запятыми, они заключены в скобки. Атрибуты всегда предшествуют описанию объекта, к которому они относятся. Например, в следующем IDL– фрагменте
[
v1enum, helpstring(«This is a color!»)
]
enum COLOR { RED, GREEN, BLUE };
атрибут v1_enum относится к описанию перечисления (enumeration) COLOR. Этот атрибут информирует компилятор IDL о том, что представление COLOR при передаче значения через сеть должно иметь 32 бита, а не 16, как принято по умолчанию. Атрибут helpstring также относится к СОLОR и добавляет строку «This is a color!» («Это – цвет!») в создаваемую библиотеку типа как описание этого перечисления. Если игнорировать атрибуты в IDL-файле, то его синтаксис такой же, как в С. IDL поддерживает структуры, объединения, массивы, перечисления, а также определения типа (typedef) – с синтаксисом, идентичным их аналогам в С.
Определяя методы СОМ в IDL, необходимо четко указать, кто – вызывающий или вызываемый объект – будет записывать или читать каждый параметр метода. Это выполняется с помощью атрибутов параметра [in] и [out]:
void Method1([in] long arg1, [out] long *parg2, [in, out] long *parg3);
Для этого фрагмента IDL предполагается, что вызывающий объект передаст значение в объект arg1 и по адресу, содержащемуся в указателе parg3. По завершении возвращаемые значения будут получены вызывающим объектом по адресам, указанным в parg2 и parg3. Это означает, что для последовательности вызовов:
long arg2 = 20, arg3 = 30;
p->Method1(10, &arg2, &arg3);
объект не может полагаться на получение передаваемого значения 20 через parg2. Если объект запускается в том же контексте выполнения, что и вызывающий объект, и оба участника вызова реализованы на C++, то *parg2 действительно будет иметь на входе метода значение 20. Однако если объект вызывается из другого контекста выполнения или один из участников вызова реализован на языке, который сводит на нет оптимизацию начальных значений чисто выходных (out-only) параметров, то инициализация параметра вызывающим объектом будет утеряна.
Win32 SDK включает в себя компилятор МIDL.ЕХЕ , который анализирует файлы СОМ IDL и генерирует несколько искусственных объектов – артефактов (artifacts). Как показано на рис. 2.1, MIDL генерирует совместимые с C/C++ заголовочные файлы, которые содержат определения абстрактного базового класса, соответствующие интерфейсам, описанным в исходном IDL-файле.
Эти заголовочные файлы также содержат совместимые с С, основанные на структурах определения (structure-based definitions), которые позволяют С-программам обращаться к интерфейсам, описанным на IDL, или обеспечивать их выполнение. То, что MIDL автоматически генерирует С/С++-заголовочный файл, означает, что ни один из СОМ-интерфейсов не нужно определять на C++ вручную. Исход определений из одной точки исключает возникновение множества несовместимых версий определений интерфейсов, которые со временем могут вызвать асинхронность. MIDL также генерирует исходный код, который позволяет использовать интерфейсы в различных потоках, процессах и машинах. Этот код будет обсуждаться в главе 5. И наконец, MIDL может генерировать двоичный файл, который позволяет другим средам, принимающим СОМ, отображать интерфейсы, определенные в исходном IDL-файле, на другие языки. Этот двоичный файл называется библиотекой типа (type library) и содержит разобранный файл IDL в наиболее эффективной для анализа форме. Библиотеки типа обычно распространяются как часть исполняемого файла реализации и позволяют таким языкам, как Visual Basic, Java, Object Pascal использовать интерфейсы, которые выставляются этой реализацией.
Чтобы понять IDL, необходимо рассмотреть логический и физический аспекты интерфейса. Обсуждение методов интерфейса и выполняемых ими операций относятся к логическому аспекту интерфейса. Обсуждение памяти, стекового фрейма, сетевых пакетов и других динамических явлений обычно относятся к физическому аспекту интерфейса. Некоторые физические аспекты интерфейса могут непосредственно наследовать логическому описанию (например, расположение таблицы vtbl , порядок параметров в стеке). Другие физические аспекты (например, границы массивов, сетевые представления сложных типов данных) требуют дополнительной квалификации.
IDL позволяет разработчикам интерфейса работать непосредственно в сфере логики, используя синтаксис С. Но в то же время IDL требует от разработчиков точно определять все те аспекты интерфейса, которые не могут быть воспроизведены непосредственно по их логическому описанию на С, с помощью использования аннотаций, формально называемых атрибутами. Атрибуты IDL легко распознать в основном тексте IDL: разделенные запятыми, они заключены в скобки. Атрибуты всегда предшествуют описанию объекта, к которому они относятся. Например, в следующем IDL– фрагменте
[
v1enum, helpstring(«This is a color!»)
]
enum COLOR { RED, GREEN, BLUE };
атрибут v1_enum относится к описанию перечисления (enumeration) COLOR. Этот атрибут информирует компилятор IDL о том, что представление COLOR при передаче значения через сеть должно иметь 32 бита, а не 16, как принято по умолчанию. Атрибут helpstring также относится к СОLОR и добавляет строку «This is a color!» («Это – цвет!») в создаваемую библиотеку типа как описание этого перечисления. Если игнорировать атрибуты в IDL-файле, то его синтаксис такой же, как в С. IDL поддерживает структуры, объединения, массивы, перечисления, а также определения типа (typedef) – с синтаксисом, идентичным их аналогам в С.
Определяя методы СОМ в IDL, необходимо четко указать, кто – вызывающий или вызываемый объект – будет записывать или читать каждый параметр метода. Это выполняется с помощью атрибутов параметра [in] и [out]:
void Method1([in] long arg1, [out] long *parg2, [in, out] long *parg3);
Для этого фрагмента IDL предполагается, что вызывающий объект передаст значение в объект arg1 и по адресу, содержащемуся в указателе parg3. По завершении возвращаемые значения будут получены вызывающим объектом по адресам, указанным в parg2 и parg3. Это означает, что для последовательности вызовов:
long arg2 = 20, arg3 = 30;
p->Method1(10, &arg2, &arg3);
объект не может полагаться на получение передаваемого значения 20 через parg2. Если объект запускается в том же контексте выполнения, что и вызывающий объект, и оба участника вызова реализованы на C++, то *parg2 действительно будет иметь на входе метода значение 20. Однако если объект вызывается из другого контекста выполнения или один из участников вызова реализован на языке, который сводит на нет оптимизацию начальных значений чисто выходных (out-only) параметров, то инициализация параметра вызывающим объектом будет утеряна.
Методы и их результаты
Результаты методов – это одна из сторон СОМ, где логический и физический миры расходятся. В сущности, все методы СОМ физически возвращают номер ошибки с типом НRESULT. Использование одного типа возвращаемого результата позволяет удаленной COM-архитектуре перегружать результат выполнения метода, а также сообщать об ошибках соединения, просто зарезервировав ряд величин для RPC-ошибок. Величины НRESULT представляют собой 32-битные целые числа, которые передают в вызывающий контекст выполнения информацию о типе ошибок, которые могут произойти (например, ошибки сети, сбои сервера). Во многих языках, поддерживающих СОМ (например, Visual Basic, Java), HRESULT–значения перехватываются контекстом выполнения или виртуальной машиной и преобразуются в программные исключения (programmatic exceptions).
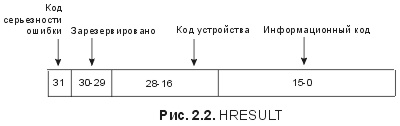 Как показано на рис. 2.2, HRESULT-значения состоят из трех битовых полей: бита серьезности ошибки (severity bit), кода устройства и информационного кода. Бит серьезности ошибки показывает, успешно выполнена операция или нет, код устройства индицирует, к какой технологии относится HRESULT , а информационный код представляет собой точный результат в рамках заданной технологии и серьезности. Заголовки SDK (software development kit – набор инструментальных средств разработки программного обеспечения) определяют два макроса, облегчающие работу с HRESULT:
Как показано на рис. 2.2, HRESULT-значения состоят из трех битовых полей: бита серьезности ошибки (severity bit), кода устройства и информационного кода. Бит серьезности ошибки показывает, успешно выполнена операция или нет, код устройства индицирует, к какой технологии относится HRESULT , а информационный код представляет собой точный результат в рамках заданной технологии и серьезности. Заголовки SDK (software development kit – набор инструментальных средств разработки программного обеспечения) определяют два макроса, облегчающие работу с HRESULT:
#define SUCCEEDED(hr) (long(hr) >= 0) #def1ne FAILED(hr) (long(hr) < 0)
Эти два макроса используют тот факт, что при трактовке НRESULT как целого числа со знаком бит серьезности ошибки он является также знаковым битом.
Заголовки SDK содержат определения всех стандартных HRESULT. Эти HRESULT имеют символические имена, соответствующие трем компонентам HRESULT, и используются в следующем формате:
<facility>_<severity>_<information>
Например, HRESULT с именем STG_S_CONVERTED показывает, что кодом устройства является FACILITY_STORAGE. Это означает, что результат относится к структурированному хранилищу (Structured Storage) или к персистентности (Persistence). Код серьезности ошибки – SEVERITY_SUCCESS. Это означает, что вызов смог успешно выполнить операцию. Третья составляющая – CONVERTED – означает, что в данном случае было произведено преобразование базового файла для поддержки структурированного хранилища. HRESULT-значения, являющиеся универсальными и не привязанными к определенной технологии, используют FACILITY_NULL, и их символическое имя не содержит префикса кода устройства. Вот некоторые стандартные имена HRESULT-значений с кодом FACILITY_NULL:
S_OK – успешная нормальная операция
S_FALSE – используется для возвращения логического false в случае успеха
E_FAIL – общий сбой E_NOTIMPL – метод не реализован
E_UNEXPECTED – метод вызван в неподходящее время
FACILITY_ITF используется в специфически интерфейсных HRESULT-значениях и является в то же время единственным допустимым кодом устройства для HRESULT, определяемых пользователем. При этом значения FACILITY_ITF должны быть уникальными в контексте каждого отдельного интерфейса. Стандартные заголовки определяют макрос MAKE_HRESULT для определения пользовательского HRESULT из трех необходимых полей:
const HRESULT CALC_E_IAMHOSED = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0х200 + 15);
Для пользовательских HRESULT принято соглашение, что значения информационного кода должны превышать 0х200 , чтобы избежать повторного использования значений, уже задействованных в системных HRESULT -значениях. Хотя это не опасно, таким образом предотвращается повторное использование значений, уже имеющих смысл для стандартных интерфейсов. Например, большинство HRESULT имеют текстовые описания для пользователя, которые можно получить на этапе выполнения с помощью функции API FormatMessage. Выбор HRESULT, не пересекающихся со значениями, определенными в системе, служит гарантией того, что неверные сообщения об ошибках не будут получены.
Чтобы позволить методам возвращать логический результат, не имеющий отношения к их физическому HRESULT -значению, язык СОМ IDL поддерживает атрибут параметров retval . Атрибут retval показывает, что соответствующий параметр физического метода в действительности является логическим результатом операции и, если контекст это позволяет, должен быть представлен как результат операции. Рассмотрим IDL-описание следующего метода:
HRESULT Method2([in] short arg1, [out, retval] short *parg2);
на языке Java это соответствует:
public short Method2(short arg1);
в то время как Visual Basic дает такое описание метода:
Function Method2(arg1 as Integer) As Integer
Поскольку C++ не использует поддержку контекста выполнения для обращения к СОМ-интерфейсам, представление этого метода в Microsoft C++ имеет вид:
virtual HRESULT stdcall Method2(short arg1, short *parg2) = 0;
Это значит, что следующий клиентский код на языке C++:
short sum = 10;
short s;
HRESULT hr = pItf->Method2(20, &s);
if (FAILED(hr)) throw hr;
sum += s;
примерно эквивалентен такому Java-коду:
short sum == 10; short s = Itf.Method2(20); sum += s;
Если HRESULT, возвращенный методом, сообщает об аварийном результате, то Java Virtual Machine преобразует HRESULT в исключение Java. Во фрагменте кода на языке C++ необходимо проверить вручную HRESULT, возвращенный этим методом, и соответствующим образом обработать этот аварийный результат.
#define SUCCEEDED(hr) (long(hr) >= 0) #def1ne FAILED(hr) (long(hr) < 0)
Эти два макроса используют тот факт, что при трактовке НRESULT как целого числа со знаком бит серьезности ошибки он является также знаковым битом.
Заголовки SDK содержат определения всех стандартных HRESULT. Эти HRESULT имеют символические имена, соответствующие трем компонентам HRESULT, и используются в следующем формате:
<facility>_<severity>_<information>
Например, HRESULT с именем STG_S_CONVERTED показывает, что кодом устройства является FACILITY_STORAGE. Это означает, что результат относится к структурированному хранилищу (Structured Storage) или к персистентности (Persistence). Код серьезности ошибки – SEVERITY_SUCCESS. Это означает, что вызов смог успешно выполнить операцию. Третья составляющая – CONVERTED – означает, что в данном случае было произведено преобразование базового файла для поддержки структурированного хранилища. HRESULT-значения, являющиеся универсальными и не привязанными к определенной технологии, используют FACILITY_NULL, и их символическое имя не содержит префикса кода устройства. Вот некоторые стандартные имена HRESULT-значений с кодом FACILITY_NULL:
S_OK – успешная нормальная операция
S_FALSE – используется для возвращения логического false в случае успеха
E_FAIL – общий сбой E_NOTIMPL – метод не реализован
E_UNEXPECTED – метод вызван в неподходящее время
FACILITY_ITF используется в специфически интерфейсных HRESULT-значениях и является в то же время единственным допустимым кодом устройства для HRESULT, определяемых пользователем. При этом значения FACILITY_ITF должны быть уникальными в контексте каждого отдельного интерфейса. Стандартные заголовки определяют макрос MAKE_HRESULT для определения пользовательского HRESULT из трех необходимых полей:
const HRESULT CALC_E_IAMHOSED = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0х200 + 15);
Для пользовательских HRESULT принято соглашение, что значения информационного кода должны превышать 0х200 , чтобы избежать повторного использования значений, уже задействованных в системных HRESULT -значениях. Хотя это не опасно, таким образом предотвращается повторное использование значений, уже имеющих смысл для стандартных интерфейсов. Например, большинство HRESULT имеют текстовые описания для пользователя, которые можно получить на этапе выполнения с помощью функции API FormatMessage. Выбор HRESULT, не пересекающихся со значениями, определенными в системе, служит гарантией того, что неверные сообщения об ошибках не будут получены.
Чтобы позволить методам возвращать логический результат, не имеющий отношения к их физическому HRESULT -значению, язык СОМ IDL поддерживает атрибут параметров retval . Атрибут retval показывает, что соответствующий параметр физического метода в действительности является логическим результатом операции и, если контекст это позволяет, должен быть представлен как результат операции. Рассмотрим IDL-описание следующего метода:
HRESULT Method2([in] short arg1, [out, retval] short *parg2);
на языке Java это соответствует:
public short Method2(short arg1);
в то время как Visual Basic дает такое описание метода:
Function Method2(arg1 as Integer) As Integer
Поскольку C++ не использует поддержку контекста выполнения для обращения к СОМ-интерфейсам, представление этого метода в Microsoft C++ имеет вид:
virtual HRESULT stdcall Method2(short arg1, short *parg2) = 0;
Это значит, что следующий клиентский код на языке C++:
short sum = 10;
short s;
HRESULT hr = pItf->Method2(20, &s);
if (FAILED(hr)) throw hr;
sum += s;
примерно эквивалентен такому Java-коду:
short sum == 10; short s = Itf.Method2(20); sum += s;
Если HRESULT, возвращенный методом, сообщает об аварийном результате, то Java Virtual Machine преобразует HRESULT в исключение Java. Во фрагменте кода на языке C++ необходимо проверить вручную HRESULT, возвращенный этим методом, и соответствующим образом обработать этот аварийный результат.
Интерфейсы и IDL
Определения методов в IDL являются просто аннотированными аналогами С-функций. Определения интерфейсов в IDL требуют расширения по сравнению с С, так как С не имеет встроенной поддержки этого понятия. Определение интерфейса в IDL начинается с ключевого слова interface. Это определение состоит их четырех частей: имя интерфейса, базовое имя интерфейса, тело интерфейса и атрибуты интерфейса. Тело интерфейса представляет собой просто набор определений методов и операторов определения типов:
[ attribute1, attribute2, …]
interface IThisInterface : IBaseInterface
{
typedef1;
typedef2;
:
:
method1;
method2;
}
Каждый интерфейс СОМ должен иметь как минимум два атрибута IDL. Атрибут [object] служит признаком того, что данный интерфейс является СОМ-, а не DCE-интерфейсом. Второй обязательный атрибут указывает на физическое имя интерфейса (в предшествующем IDL-фрагменте IThisInterface является логическим именем интерфейса).
Чтобы понять, почему СОМ-интерфейсы требуют физическое имя, отличное от логического имени интерфейса, рассмотрим следующую ситуацию. Два разработчика независимо друг от друга решили создать интерфейс, моделирующий ручной калькулятор. Два их определения интерфейса будут, вероятно, похожими, будучи заданными в общей проблемной области, но скорее всего фактический порядок определений методов и, возможно, сигнатур методов могут в чем-то различаться. Несмотря на это, оба разработчика, вероятно, выберут одно и то же логическое имя: ICalculator.
Клиентская программа на машине какого-нибудь конечного пользователя может реализовать определение интерфейса от первого разработчика, а запустить объект, созданный вторым. Поскольку оба интерфейса имеют одно и то же логическое имя, то если клиент запросит объект для поддержки ICalculator, просто использовав строку «ICalculator», объект ответит на запрос возвратом ненулевого указателя интерфейса. Однако представление клиента о том, на что похож ICalculator, вступит в конфликт с тем, какое представление о нем имеет этот объект, и результирующий указатель будет не тем, которого ожидает клиент. Ведь эти два интерфейса могут быть совершенно разными, несмотря на то, что оба используют одно и то же логическое имя.
Чтобы исключить коллизию имен, всем СОМ-интерфейсам на этапе проектирования назначается уникальное двоичное имя, которое является физическим именем интерфейса. Эти физические имена называются глобально уникальными идентификаторами (Globally Unique Identifiers – GUIDs), что рифмуется со словом squids [1]. GUID используются в СОМ повсюду для именования статических сущностей, таких как интерфейсы или реализации. GUID являются чрезвычайно большими 128-битными числами, что гарантирует их уникальность как во времени, так и в пространстве. GUID в СОМ основаны на универсальных уникальных идентификаторах (Universally Unique Identifiers – UUIDs), используемых в DCE RPC. При использовании GUID для именования СОМ-интерфейсов их часто называют идентификаторами интерфейса (Interface IDs – IIDs). Реализации в СОМ также именуются с помощью GUID, и в этом случае GUID называются идентификаторами класса (Class IDs – CLSIDs ). Будучи представленными в текстовой форме, GUID всегда имеют следующий канонический вид: BDA4A270-A1BA-11d0-8C2C-0080C73925BA
Эти 32 шестнадцатеричные цифры представляют 128-битное значение GUID. Именование интерфейсов и реализации с помощью GUID важно для предотвращения коллизий между разными компонентами.
Для создания нового GUID в СОМ имеется API-функция, которая использует децентрализованный алгоритм уникальности для генерирования нового 128-битного числа, которое никогда больше не встретится в природе:
HRESULT CoCreateGuid(GUID *pguid);
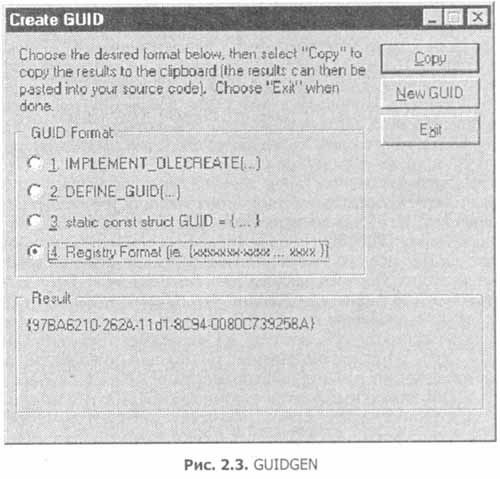
Алгоритм, задействованный в функции CoCreateGuid, использует локальный сетевой интерфейсный адрес машины, текущее машинное время и два постоянных счетчика для компенсации точности часов и нестандартных изменении в них (таких, как переход на летнее время или ручная коррекция системных часов). Если данная машина не имеет сетевого интерфейса, то синтезируется статистически уникальная величина и CoCreateGuid возвращает особого вида HRESULT, показывающий, что данная величина является глобально уникальной только статистически и может считаться таковой только при использовании на локальной машине. Хотя прямой вызов функции CoCreateGuid иногда полезен, большинство разработчиков вызывают ее в неявной форме, применяя из SDK программу GUIDGEN.EXE. На рис. 2.3 показана работа GUIDGEN. GUIDGEN вызывает CoCreateGuid и преобразует полученный GUID в один из четырех форматов, удобных для включения в исходный код на C++ или IDL. При работе в IDL используется четвертый формат (каноническая текстовая форма).
Чтобы связать физическое имя интерфейса с его определением на IDL, используется второй обязательный атрибут интерфейса – [uuid] . Атрибут [uuid] содержит один параметр – каноническую текстовую форму
GUID: [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)]
interface ICalculator : IBaseInterface
{
HRESULT Clear(void);
HRESULT Add([in] long n);
HRESULT Sum([out, retval] long *pn);
}
При использовании при программировании на С или C++ физического имени интерфейса IID данного интерфейса представляет собой просто логическое имя интерфейса, предшествуемое префиксом IID_. Например, интерфейс ICalculator будет иметь IID, которым можно программно манипулировать, используя сгенерированную IDL константу IID_ICalculator. Для предотвращения коллизий между символическими именами интерфейсов можно использовать пространство имен C++.
Поскольку лишь немногие из компиляторов C++ могут поддерживать 128-битные числа, СОМ определяет С-структуру для представления 128-битовой величины GUID и предлагает псевдонимы для типов IID и CLSID с использованием следующего определения типов:
typedef struct GUID
{
DWORD Data1;
WORD Data2;
WORD Data3;
BYTE Data4[8];
} GUID;
typedef GUID IID;
typedef GUID CLSID;
Внутренняя структура GUID для большинства программистов несущественна, так как единственная значимая операция, которую можно выполнить с GUID, – это проверка их эквивалентности. Для обеспечения эффективной передачи величин GUID как аргументов функций СОМ предусматривает также постоянные псевдонимы для ссылок (constant reference aliases) для каждого типа GUID:
#define REFGUID const GUID&
#define REFIID const IID&
#define REFCLSID const CLSID&
Чтобы иметь возможность сравнивать величины GUID, СОМ обеспечивает функции эквивалентности и перегружает операторы == и != для постоянных ссылок GUID:
inline BOOL IsEqualGUID(REFGUID r1, REFGUID r2)
{
return !memcmp(&r1, &r2, sizeof(GUID));
}
#def1ne IsEqualIID(r1, r2) IsEqualGUID((r1) , (r2))
#define IsEqualCLSID(r1, r2) IsEqualGUID((r1), (r2))
inline BOOL operator == (REFGUID r1, REFGUID r2)
{
return !memcmp(&r1, &r2, sizeof(GUID));
}
inline BOOL operator != (REFGUID r1, REFGUID r2)
{
return !(r1 == r2);
}
Фактические заголовки SDK содержат условно компилируемые совместимые с С версии определений типа, макросов и встраиваемых функций, как показано выше.
Поскольку показано, что представления имен интерфейсов на этапе выполнения являются GUID, а не строками; это означает, что метод Dynamic_Cast, описанный в предыдущей главе, следует пересмотреть. Действительно, весь интерфейс IЕхtensibleObject должен быть изменен и преобразован в свой аналог IUnknown, совместимый с СОМ.
[ attribute1, attribute2, …]
interface IThisInterface : IBaseInterface
{
typedef1;
typedef2;
:
:
method1;
method2;
}
Каждый интерфейс СОМ должен иметь как минимум два атрибута IDL. Атрибут [object] служит признаком того, что данный интерфейс является СОМ-, а не DCE-интерфейсом. Второй обязательный атрибут указывает на физическое имя интерфейса (в предшествующем IDL-фрагменте IThisInterface является логическим именем интерфейса).
Чтобы понять, почему СОМ-интерфейсы требуют физическое имя, отличное от логического имени интерфейса, рассмотрим следующую ситуацию. Два разработчика независимо друг от друга решили создать интерфейс, моделирующий ручной калькулятор. Два их определения интерфейса будут, вероятно, похожими, будучи заданными в общей проблемной области, но скорее всего фактический порядок определений методов и, возможно, сигнатур методов могут в чем-то различаться. Несмотря на это, оба разработчика, вероятно, выберут одно и то же логическое имя: ICalculator.
Клиентская программа на машине какого-нибудь конечного пользователя может реализовать определение интерфейса от первого разработчика, а запустить объект, созданный вторым. Поскольку оба интерфейса имеют одно и то же логическое имя, то если клиент запросит объект для поддержки ICalculator, просто использовав строку «ICalculator», объект ответит на запрос возвратом ненулевого указателя интерфейса. Однако представление клиента о том, на что похож ICalculator, вступит в конфликт с тем, какое представление о нем имеет этот объект, и результирующий указатель будет не тем, которого ожидает клиент. Ведь эти два интерфейса могут быть совершенно разными, несмотря на то, что оба используют одно и то же логическое имя.
Чтобы исключить коллизию имен, всем СОМ-интерфейсам на этапе проектирования назначается уникальное двоичное имя, которое является физическим именем интерфейса. Эти физические имена называются глобально уникальными идентификаторами (Globally Unique Identifiers – GUIDs), что рифмуется со словом squids [1]. GUID используются в СОМ повсюду для именования статических сущностей, таких как интерфейсы или реализации. GUID являются чрезвычайно большими 128-битными числами, что гарантирует их уникальность как во времени, так и в пространстве. GUID в СОМ основаны на универсальных уникальных идентификаторах (Universally Unique Identifiers – UUIDs), используемых в DCE RPC. При использовании GUID для именования СОМ-интерфейсов их часто называют идентификаторами интерфейса (Interface IDs – IIDs). Реализации в СОМ также именуются с помощью GUID, и в этом случае GUID называются идентификаторами класса (Class IDs – CLSIDs ). Будучи представленными в текстовой форме, GUID всегда имеют следующий канонический вид: BDA4A270-A1BA-11d0-8C2C-0080C73925BA
Эти 32 шестнадцатеричные цифры представляют 128-битное значение GUID. Именование интерфейсов и реализации с помощью GUID важно для предотвращения коллизий между разными компонентами.
Для создания нового GUID в СОМ имеется API-функция, которая использует децентрализованный алгоритм уникальности для генерирования нового 128-битного числа, которое никогда больше не встретится в природе:
HRESULT CoCreateGuid(GUID *pguid);
Алгоритм, задействованный в функции CoCreateGuid, использует локальный сетевой интерфейсный адрес машины, текущее машинное время и два постоянных счетчика для компенсации точности часов и нестандартных изменении в них (таких, как переход на летнее время или ручная коррекция системных часов). Если данная машина не имеет сетевого интерфейса, то синтезируется статистически уникальная величина и CoCreateGuid возвращает особого вида HRESULT, показывающий, что данная величина является глобально уникальной только статистически и может считаться таковой только при использовании на локальной машине. Хотя прямой вызов функции CoCreateGuid иногда полезен, большинство разработчиков вызывают ее в неявной форме, применяя из SDK программу GUIDGEN.EXE. На рис. 2.3 показана работа GUIDGEN. GUIDGEN вызывает CoCreateGuid и преобразует полученный GUID в один из четырех форматов, удобных для включения в исходный код на C++ или IDL. При работе в IDL используется четвертый формат (каноническая текстовая форма).
Чтобы связать физическое имя интерфейса с его определением на IDL, используется второй обязательный атрибут интерфейса – [uuid] . Атрибут [uuid] содержит один параметр – каноническую текстовую форму
GUID: [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)]
interface ICalculator : IBaseInterface
{
HRESULT Clear(void);
HRESULT Add([in] long n);
HRESULT Sum([out, retval] long *pn);
}
При использовании при программировании на С или C++ физического имени интерфейса IID данного интерфейса представляет собой просто логическое имя интерфейса, предшествуемое префиксом IID_. Например, интерфейс ICalculator будет иметь IID, которым можно программно манипулировать, используя сгенерированную IDL константу IID_ICalculator. Для предотвращения коллизий между символическими именами интерфейсов можно использовать пространство имен C++.
Поскольку лишь немногие из компиляторов C++ могут поддерживать 128-битные числа, СОМ определяет С-структуру для представления 128-битовой величины GUID и предлагает псевдонимы для типов IID и CLSID с использованием следующего определения типов:
typedef struct GUID
{
DWORD Data1;
WORD Data2;
WORD Data3;
BYTE Data4[8];
} GUID;
typedef GUID IID;
typedef GUID CLSID;
Внутренняя структура GUID для большинства программистов несущественна, так как единственная значимая операция, которую можно выполнить с GUID, – это проверка их эквивалентности. Для обеспечения эффективной передачи величин GUID как аргументов функций СОМ предусматривает также постоянные псевдонимы для ссылок (constant reference aliases) для каждого типа GUID:
#define REFGUID const GUID&
#define REFIID const IID&
#define REFCLSID const CLSID&
Чтобы иметь возможность сравнивать величины GUID, СОМ обеспечивает функции эквивалентности и перегружает операторы == и != для постоянных ссылок GUID:
inline BOOL IsEqualGUID(REFGUID r1, REFGUID r2)
{
return !memcmp(&r1, &r2, sizeof(GUID));
}
#def1ne IsEqualIID(r1, r2) IsEqualGUID((r1) , (r2))
#define IsEqualCLSID(r1, r2) IsEqualGUID((r1), (r2))
inline BOOL operator == (REFGUID r1, REFGUID r2)
{
return !memcmp(&r1, &r2, sizeof(GUID));
}
inline BOOL operator != (REFGUID r1, REFGUID r2)
{
return !(r1 == r2);
}
Фактические заголовки SDK содержат условно компилируемые совместимые с С версии определений типа, макросов и встраиваемых функций, как показано выше.
Поскольку показано, что представления имен интерфейсов на этапе выполнения являются GUID, а не строками; это означает, что метод Dynamic_Cast, описанный в предыдущей главе, следует пересмотреть. Действительно, весь интерфейс IЕхtensibleObject должен быть изменен и преобразован в свой аналог IUnknown, совместимый с СОМ.
Интерфейс IUnknown
СОМ-интерфейс IUnknown имеет то же назначение, что и интерфейс IExtensibleObject, определенный в предыдущей главе. Последняя версия IExtensibleObject, появившаяся в конце предыдущей главы, имеет вид:
class IExtensibleObject
{
public:
virtual void *Dynamic_Cast(const char* pszType) = 0;
virtual void DuplicatePointer(void) = 0;
virtual void DestroyPointer(void) = 0;
}
Для определения типа на этапе выполнения был применен метод Dynamic_Cast, аналогичный оператору C++ dynamic_cast. Для извещения объекта о том, что указатель интерфейса дублировался, использовался метод DuplicatePointer. Для сообщения объекту, что указатель интерфейса уничтожен и все используемые им ресурсы могут быть освобождены, был применен метод DestroyPointer. Вот как выглядит определение IUnknown на C++:
extern "С" const IID IID_IUnknown: interface IUnknown
{
virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, void **ppv) = 0;
virtual ULONG STDMETHODCALLTYPE AddRef(void) = 0;
virtual ULONG STDMETHODCALLTYPE Release(void) = 0;
};
Заголовочные файлы SDK дают псевдоним interface ключевому слову C++ struct, используя препроцессор С. Поскольку интерфейсы в СОМ определены не как классы, а как структуры, то для того, чтобы сделать методы интерфейса общедоступными, ключевое слово public не требуется. Чтобы создать для целевой платформы СОМ-совместимые стековые фреймы, необходим макрос STDMETHODCALLTYPE. Если целевыми являются платформы Win32, то при использовании компилятора Microsoft C++ этот макрос раскрывается в _stdcall.
IUnknown функционально эквивалентен IExtensibleObject. Метод QueryInterface используется для динамического определения типа и аналогичен С++-оператору dynamic_cast. Метод AddRef используется для сообщения объекту, что указатель интерфейса дублирован. Метод Release используется для сообщения объекту, что указатель интерфейса уничтожен и все ресурсы, которые объект поддерживал от имени клиента, могут быть отключены. Главное различие между IUnknown и интерфейсом, определенным в предыдущей главе, заключается в том, что IUnknown использует идентификаторы GUID, а не строки для идентификации типов интерфейса на этапе выполнения.
IDL-определение IUnknown можно найти в файле unknwn.idl из директории SDK, содержащей заголовочные файлы:
// unknwn.idl – system IDL file
// unknwn.idl – системный файл IDL
[ local, object, uuid (00000000-0000-0000-C000-000000000046) ] interface IUnknown
{
HRESULT QueryInterface([in] REFIID riid, [out] void **ppv);
ULONG AddRef(void); ULONG Release(void);
}
Атрибут local подавляет генерирование сетевого кода для этого интерфейса. Этот атрибут необходим для того, чтобы смягчить требования СОМ о том, что все методы при вызове с удаленных машин должны возвращать HRESULT. Как будет показано в следующих главах, интерфейс IUnknown трактуется особым образом при работе с удаленными объектами. Заметим, что фактические, то есть использующиеся на практике IDL-описания интерфейсов, которые содержатся в заголовках SDK, немного отличаются от определений, данных в этой книге. Фактические определения часто содержат дополнительные атрибуты для оптимизации генерируемого сетевого кода, которые не имеют отношения к нашему обсуждению. В случае сомнений обратитесь за полными определениями к последней версии заголовочных файлов SDK.
Интерфейс IUnknown является родительским для всех СОМ-интерфейсов. IUnknown – единственный интерфейс СОМ, который не наследует от другого интерфейса. Любой другой допустимый интерфейс СОМ должен быть прямым потомком IUnknown или какого-нибудь другого допустимого интерфейса СОМ, который, в свою очередь, должен сам наследовать или прямо от IUnknown, или от какого-нибудь другого допустимого интерфейса СОМ. Это означает, что на двоичном уровне все интерфейсы СОМ являются указателями на таблицы vtbl, которые начинаются с трех точек входа: QueryInterface, AddRef и Release. Все специфические для интерфейсов методы будут иметь точки входа в vtbl, которые появляются после этих трех общих точек входа.
class IExtensibleObject
{
public:
virtual void *Dynamic_Cast(const char* pszType) = 0;
virtual void DuplicatePointer(void) = 0;
virtual void DestroyPointer(void) = 0;
}
Для определения типа на этапе выполнения был применен метод Dynamic_Cast, аналогичный оператору C++ dynamic_cast. Для извещения объекта о том, что указатель интерфейса дублировался, использовался метод DuplicatePointer. Для сообщения объекту, что указатель интерфейса уничтожен и все используемые им ресурсы могут быть освобождены, был применен метод DestroyPointer. Вот как выглядит определение IUnknown на C++:
extern "С" const IID IID_IUnknown: interface IUnknown
{
virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, void **ppv) = 0;
virtual ULONG STDMETHODCALLTYPE AddRef(void) = 0;
virtual ULONG STDMETHODCALLTYPE Release(void) = 0;
};
Заголовочные файлы SDK дают псевдоним interface ключевому слову C++ struct, используя препроцессор С. Поскольку интерфейсы в СОМ определены не как классы, а как структуры, то для того, чтобы сделать методы интерфейса общедоступными, ключевое слово public не требуется. Чтобы создать для целевой платформы СОМ-совместимые стековые фреймы, необходим макрос STDMETHODCALLTYPE. Если целевыми являются платформы Win32, то при использовании компилятора Microsoft C++ этот макрос раскрывается в _stdcall.
IUnknown функционально эквивалентен IExtensibleObject. Метод QueryInterface используется для динамического определения типа и аналогичен С++-оператору dynamic_cast. Метод AddRef используется для сообщения объекту, что указатель интерфейса дублирован. Метод Release используется для сообщения объекту, что указатель интерфейса уничтожен и все ресурсы, которые объект поддерживал от имени клиента, могут быть отключены. Главное различие между IUnknown и интерфейсом, определенным в предыдущей главе, заключается в том, что IUnknown использует идентификаторы GUID, а не строки для идентификации типов интерфейса на этапе выполнения.
IDL-определение IUnknown можно найти в файле unknwn.idl из директории SDK, содержащей заголовочные файлы:
// unknwn.idl – system IDL file
// unknwn.idl – системный файл IDL
[ local, object, uuid (00000000-0000-0000-C000-000000000046) ] interface IUnknown
{
HRESULT QueryInterface([in] REFIID riid, [out] void **ppv);
ULONG AddRef(void); ULONG Release(void);
}
Атрибут local подавляет генерирование сетевого кода для этого интерфейса. Этот атрибут необходим для того, чтобы смягчить требования СОМ о том, что все методы при вызове с удаленных машин должны возвращать HRESULT. Как будет показано в следующих главах, интерфейс IUnknown трактуется особым образом при работе с удаленными объектами. Заметим, что фактические, то есть использующиеся на практике IDL-описания интерфейсов, которые содержатся в заголовках SDK, немного отличаются от определений, данных в этой книге. Фактические определения часто содержат дополнительные атрибуты для оптимизации генерируемого сетевого кода, которые не имеют отношения к нашему обсуждению. В случае сомнений обратитесь за полными определениями к последней версии заголовочных файлов SDK.
Интерфейс IUnknown является родительским для всех СОМ-интерфейсов. IUnknown – единственный интерфейс СОМ, который не наследует от другого интерфейса. Любой другой допустимый интерфейс СОМ должен быть прямым потомком IUnknown или какого-нибудь другого допустимого интерфейса СОМ, который, в свою очередь, должен сам наследовать или прямо от IUnknown, или от какого-нибудь другого допустимого интерфейса СОМ. Это означает, что на двоичном уровне все интерфейсы СОМ являются указателями на таблицы vtbl, которые начинаются с трех точек входа: QueryInterface, AddRef и Release. Все специфические для интерфейсов методы будут иметь точки входа в vtbl, которые появляются после этих трех общих точек входа.