Страница:
Чтобы наследовать от интерфейса IDL, нужно или определить базовый интерфейс в том же IDL-файле, или использовать директиву import, чтобы сделать внешнее IDL-определение базового интерфейса явным в данной области действия:
// calculator.idl
[object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)]
interface ICalculator : IUnknown
{
import «unknwn.idl»;
// bring in def. of IUnknown
// импортируем определение IUnknown
HRESULT Clear(void);
HRESULT Add([in] long n);
HRESULT Sum([out, retval] long *pn);
}
Оператор import может появляться или внутри определения интерфейса, как показано здесь, или предшествовать описанию интерфейса в глобальной области действия. В любом из этих случаев действия оператора import одинаковы, он может многократно импортировать один IDL-файл без всякого ущерба. Поскольку сгенерированный C/C++ заголовочный файл будет требовать С/С++-версии импортируемого IDL-файла, чтобы обеспечить наследование, оператор import из IDL-файла будет странслирован в команду #include в генерируемом заголовочном С/С++-файле:
// calculator.h – generated by MIDL
// calculator.h – генерированный MIDL
// bring in def. of IUnknown
// вводим определения IUnknown
#include «unknwn.h»
extern "C" const IID IID_ICalculator;
interface ICalculator : public IUnknown
{
virtual HRESULT STDMETHODCALLTYPE Clear(void) = 0;
virtual HRESULT STDMETHODCALLTYPE Add(long n) = 0;
virtual HRESULT STDMETHODCALLTYPE Sum(long *pn) = 0;
}
Компилятор MIDL также создаст С-файл, содержащий фактические определения всех GUID, имеющихся в исходном IDL-файле:
// calculator_i.с – generated by MIDL
const IID IID_ICalculator =
{ 0xBDA4A270, 0xA1BA, 0x11d0, { 0x8C, 0x2C,
0x00, 0х80, 0хC7, 0х39, 0x25, 0xBA } };
Каждый проект, который будет использовать этот интерфейс, должен или добавить calculator_i.c к своему файлу сборки (makefile), или включить calculator_i.c в один из исходных файлов на С или C++ с использованием препроцессора С. Если это не сделано, то идентификатору IID_ICalculator не будет выделено памяти для его 128-битного значения и проект не будет скомпонован по причине неразрешенных внешних идентификаторов.
СОМ не накладывает никаких ограничений на глубину иерархии интерфейсов при условии, что конечным базовым интерфейсом является IUnknown. Нижеследующий IDL является вполне допустимым и корректным для СОМ:
import «unknwn.idl»;
[object, uuid(DF12E151-A29A-11d0-8C2D-0080C73925BA)]
interface IAnimal : IUnknown {
HRESULT Eat(void);
}
[object, uuid(DF12E152-A29A-11d0-8C2D-0080C73925BA)]
interface ICat : IAnimal
{
HRESULT IgnoreMaster(void);
}
[object, uuid(DF12E153-A29A-11d0-8C2D-0080C73925BA)]
interface IDog : IAnimal
{
HRESULT Bark(void);
}
[object, uuid(DF12E154-A29A-11d0-8C2D-0080C73925BA)]
interface IPug : IDog
{
HRESULT Snore(void);
}
[object, uuid(DF12E155-A29A-11d0-8C2D-0080C73925BA)]
interface IOldPug : IPug
{
HRESULT SnoreLoudly(void);
}
СОМ накладывает одно ограничение на наследование интерфейсов: интерфейсы СОМ не могут быть прямыми потомками более чем одного интерфейса. Следующий фрагмент в СОМ недопустим:
[object, uuid(DF12E156-A29A-11d0-8C2D-0080C73925BA)]
interface ICatDog : ICat, IDog
{
// illegal, multiple bases
// неверно, несколько базовых интерфейсов
HRESULT Meowbark(void);
}
СОМ запрещает наследование от нескольких интерфейсов по целому ряду причин. Одна из них состоит в том, что двоичное представление результирующего абстрактного базового класса C++ не будет независимым от компилятора. В этом случае СОМ уже не будет являться двоичным стандартом, независимым от разработчика. Другая причина кроется в тесной связи между СОМ и DCE RPC. При ограничении наследования интерфейсов одним базовым интерфейсом преобразование между интерфейсами СОМ и интерфейсными векторами DCE RPC вполне однозначно. В конце концов, отсутствие поддержки нескольких базовых интерфейсов не является ограничением, так как каждая реализация может выбрать для открытия столько интерфейсов, сколько пожелает. Это означает, что основанный на СОМ Cat/Dog по-прежнему допустим на уровне реализации:
class CatDog : public ICat, public IDog
{
//
...
};
Клиент, желающий трактовать объект как Cat/Dog, просто использует QueryInterface для привязки к объекту обоих типов указателей. Если один из вызовов QueryInterface не достигает успеха, то данный объект не является Cat/Dog и клиент может справляться с этим, как сумеет. Поскольку реализации могут открывать несколько интерфейсов, то запрет для интерфейсов наследовать более чем от одного интерфейса является лишь небольшой потерей в смысле семантической информации или информации о типе.
СОМ поддерживает стандарт обозначений, который показывает, какие интерфейсы доступны из объекта. Этот способ придерживается философии СОМ относительно отделения интерфейса от реализации и не раскрывает никаких деталей реализации объекта иначе, чем через список выставляемых им интерфейсов.

Рисунок 2.4 показывает стандартное обозначение класса CatDog. Заметим, что из этой схемы можно сделать единственный вывод: если не произойдет катастрофических сбоев, объекты CatDog выставят четыре интерфейса: ICat, IDog, IAnimal и IUnknown.
Управление ресурсами и IUnknown
Приведение типов и IUnknown
Реализация IUnknown
// calculator.idl
[object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)]
interface ICalculator : IUnknown
{
import «unknwn.idl»;
// bring in def. of IUnknown
// импортируем определение IUnknown
HRESULT Clear(void);
HRESULT Add([in] long n);
HRESULT Sum([out, retval] long *pn);
}
Оператор import может появляться или внутри определения интерфейса, как показано здесь, или предшествовать описанию интерфейса в глобальной области действия. В любом из этих случаев действия оператора import одинаковы, он может многократно импортировать один IDL-файл без всякого ущерба. Поскольку сгенерированный C/C++ заголовочный файл будет требовать С/С++-версии импортируемого IDL-файла, чтобы обеспечить наследование, оператор import из IDL-файла будет странслирован в команду #include в генерируемом заголовочном С/С++-файле:
// calculator.h – generated by MIDL
// calculator.h – генерированный MIDL
// bring in def. of IUnknown
// вводим определения IUnknown
#include «unknwn.h»
extern "C" const IID IID_ICalculator;
interface ICalculator : public IUnknown
{
virtual HRESULT STDMETHODCALLTYPE Clear(void) = 0;
virtual HRESULT STDMETHODCALLTYPE Add(long n) = 0;
virtual HRESULT STDMETHODCALLTYPE Sum(long *pn) = 0;
}
Компилятор MIDL также создаст С-файл, содержащий фактические определения всех GUID, имеющихся в исходном IDL-файле:
// calculator_i.с – generated by MIDL
const IID IID_ICalculator =
{ 0xBDA4A270, 0xA1BA, 0x11d0, { 0x8C, 0x2C,
0x00, 0х80, 0хC7, 0х39, 0x25, 0xBA } };
Каждый проект, который будет использовать этот интерфейс, должен или добавить calculator_i.c к своему файлу сборки (makefile), или включить calculator_i.c в один из исходных файлов на С или C++ с использованием препроцессора С. Если это не сделано, то идентификатору IID_ICalculator не будет выделено памяти для его 128-битного значения и проект не будет скомпонован по причине неразрешенных внешних идентификаторов.
СОМ не накладывает никаких ограничений на глубину иерархии интерфейсов при условии, что конечным базовым интерфейсом является IUnknown. Нижеследующий IDL является вполне допустимым и корректным для СОМ:
import «unknwn.idl»;
[object, uuid(DF12E151-A29A-11d0-8C2D-0080C73925BA)]
interface IAnimal : IUnknown {
HRESULT Eat(void);
}
[object, uuid(DF12E152-A29A-11d0-8C2D-0080C73925BA)]
interface ICat : IAnimal
{
HRESULT IgnoreMaster(void);
}
[object, uuid(DF12E153-A29A-11d0-8C2D-0080C73925BA)]
interface IDog : IAnimal
{
HRESULT Bark(void);
}
[object, uuid(DF12E154-A29A-11d0-8C2D-0080C73925BA)]
interface IPug : IDog
{
HRESULT Snore(void);
}
[object, uuid(DF12E155-A29A-11d0-8C2D-0080C73925BA)]
interface IOldPug : IPug
{
HRESULT SnoreLoudly(void);
}
СОМ накладывает одно ограничение на наследование интерфейсов: интерфейсы СОМ не могут быть прямыми потомками более чем одного интерфейса. Следующий фрагмент в СОМ недопустим:
[object, uuid(DF12E156-A29A-11d0-8C2D-0080C73925BA)]
interface ICatDog : ICat, IDog
{
// illegal, multiple bases
// неверно, несколько базовых интерфейсов
HRESULT Meowbark(void);
}
СОМ запрещает наследование от нескольких интерфейсов по целому ряду причин. Одна из них состоит в том, что двоичное представление результирующего абстрактного базового класса C++ не будет независимым от компилятора. В этом случае СОМ уже не будет являться двоичным стандартом, независимым от разработчика. Другая причина кроется в тесной связи между СОМ и DCE RPC. При ограничении наследования интерфейсов одним базовым интерфейсом преобразование между интерфейсами СОМ и интерфейсными векторами DCE RPC вполне однозначно. В конце концов, отсутствие поддержки нескольких базовых интерфейсов не является ограничением, так как каждая реализация может выбрать для открытия столько интерфейсов, сколько пожелает. Это означает, что основанный на СОМ Cat/Dog по-прежнему допустим на уровне реализации:
class CatDog : public ICat, public IDog
{
//
...
};
Клиент, желающий трактовать объект как Cat/Dog, просто использует QueryInterface для привязки к объекту обоих типов указателей. Если один из вызовов QueryInterface не достигает успеха, то данный объект не является Cat/Dog и клиент может справляться с этим, как сумеет. Поскольку реализации могут открывать несколько интерфейсов, то запрет для интерфейсов наследовать более чем от одного интерфейса является лишь небольшой потерей в смысле семантической информации или информации о типе.
СОМ поддерживает стандарт обозначений, который показывает, какие интерфейсы доступны из объекта. Этот способ придерживается философии СОМ относительно отделения интерфейса от реализации и не раскрывает никаких деталей реализации объекта иначе, чем через список выставляемых им интерфейсов.
Рисунок 2.4 показывает стандартное обозначение класса CatDog. Заметим, что из этой схемы можно сделать единственный вывод: если не произойдет катастрофических сбоев, объекты CatDog выставят четыре интерфейса: ICat, IDog, IAnimal и IUnknown.
Управление ресурсами и IUnknown
Как было в случае с DuplicatePointer и DestroyPointer из предыдущей главы, методы AddRef и Release из IUnknown имеют очень простой протокол, которого должны придерживаться все, кто пользуется указателями этих интерфейсов. Эти правила освобождают клиента от необходимости управлять временем жизни объекта, когда несколько интерфейсных указателей могут указывать или не указывать на один и тот же объект. Клиентам необходимо только следовать простым правилам AddRef/Release единообразно для всех интерфейсных указателей, с которыми им приходится сталкиваться, а объект будет сам управлять своим временем жизни.
Спецификация модели компонентных объектов (Component Object Model Specification) содержит четкие определения правил подсчета ссылок СОМ. Понимание мотивировки этих определений имеет решающее значение при СОМ-программировании на C++. Эти правила СОМ о подсчете ссылок могут быть сведены к трем простым аксиомам:
Когда ненулевой указатель интерфейса копируется из одной ячейки памяти в другую, должен вызываться AddRef для извещения объекта о дополнительной ссылке.
Перед тем как произойдет перезапись той ячейки памяти, где содержится ненулевой указатель интерфейса, необходимо вызвать Release, чтобы известить объект, что ссылка уничтожается.
Избыточное количество вызовов AddRef и Release можно сократить, если иметь дополнительную информацию о связях между двумя и более ячейками памяти.
Аксиома о дополнительной информации введена главным образом для того, чтобы ввести возможность преобразования запутанных ситуаций в разумные и осмысленные идиомы программирования (например, стеки временных вызовов и сгенерированное компилятором занесение переменной в регистр не нуждаются в подсчете ссылок). Можно провести месяцы в поиске особых связей между переменными, содержащими явные указатели на интерфейс в программе и оптимизировать избыточные вызовы AddRef и Release , но поступать так было бы неосмотрительно. Выгода от удаления этих избыточных вызовов явно незначительна, так как даже в худшем случае, когда объект вызывается с расстояния более 8500 миль со средней скоростью передачи 14.4 кбит/сек, эти избыточные вызовы никогда не уйдут из вызывающего потока и нечасто требуют множество инструкций для выполнения.
Если руководствоваться приведенными выше тремя простыми аксиомами о подсчете ссылок в интерфейсных указателях, то можно записать это в виде руководящих принципов программирования, чтобы установить, когда вызывать и когда не вызывать AddRef и Release . Вот несколько типичных ситуаций, требующих вызова метода AddRef:
А1. Когда ненулевой интерфейсный указатель записывается в локальную переменную.
А2. Когда вызываемый объект пишет ненулевой интерфейсный указатель в параметр [out] или [in, out] метода или функции.
A3. Когда вызываемый объект возвращает ненулевой интерфейсный указатель как физический результат (physical result) функции.
А4. Когда ненулевой интерфейсный указатель пишется в элемент данных объекта.
Некоторые типичные ситуации, требующие вызова метода Release :
R1. Перед перезаписью ненулевой локальной переменной или элемента данных.
R2. Перед тем как покинуть область действия ненулевой локальной переменной.
R3. Когда вызываемый объект перезаписывает параметр [in,out] метода или функции, начальное значение которых отлично от нуля. Заметим, что параметры [out] предполагаются нулевыми при вводе и никогда не могут освобождаться вызываемым объектом.
R4. Перед перезаписью ненулевого элемента данных объекта.
R5. Перед завершением работы деструктора объекта, имеющего в качестве элемента данных ненулевой интерфейсный указатель.
Типичная ситуация, к которой применимо правило о дополнительной информации, возникает при передаче указателей интерфейсов функциям как параметрам [in]:
S1. Когда при вызове функции или метода ненулевой интерфейсный указатель передается через [in] -параметр, вызов AddRef и Release, не требуются, так как время жизни временной переменной в стеке является строгим подмножеством времени жизни выражения, использованного для инициализации формального аргумента.
Эти десять руководящих принципов охватывают ситуации, снова и снова возникающие при программировании в СОМ, и было бы неплохо их запомнить.
Чтобы конкретизировать правила подсчета ссылок в СОМ, предположим, что имеется глобальная функция, которая возвращает объекту интерфейсный указатель:
void GetObject([out] IUnknown **ppUnk);
и что имеется другая глобальная функция, которая выполняет некую полезную работу над объектом:
void UseObject([in] IUnknown *pUnk);
Написанный ниже код использует эти процедуры, чтобы управлять некоторыми объектами и возвращать интерфейсный указатель вызывающему объекту. Руководящие принципы, применимые к каждому оператору, указаны в комментариях к нему:
void GetAndUse(/* [out] */ IUnknown ** ppUnkOut)
{ IUnknown *pUnk1 = 0, *pUnk2 = 0; *ppUnkOut =0;
// R3
// get pointers to one (or two) objects
// получаем указатели на один (или два) объекта
GetObject(&pUnk1);
//A2
GetObject(&pUnk2);
//A1
// set pUnk2 to point to first object
// устанавливаем pUnk2, чтобы указать на первый объект
if (pUnk2) pUnk2->Release():
//R1
if (pUnk2 = pUnk1) pUnk2->AddRef():
//A1
// pass pUnk2 to some other function
// передаем pUnk2 какой-нибудь другой функции
UseObject(pUnk2);
//S1
// return pUnk2 to caller using ppUnkOut parameter
// возвращаем pUnk2 вызывающему объекту, используя
// параметр ppUnkOut
if (*ppUnkOut = pUnk2) (*ppUnkOut)->AddRef();
// A2
// falling out of scope so clean up
// выходит за область действия и поэтому освобождаем
if (pUnk1) pUnkl->Release();
//R2
if (pUnk2) pUnk2->Release();
//R2
}
Важно отметить, что в вышеприведенном коде правило A2 применяется дважды, но по двум разным причинам. При вызове GetObject код выступает как вызывающий объект, а реализация GetObject является вызываемым объектом. Это означает, что реализация GetObject является ответственной за вызов AddRef через параметр [out]. При перезаписи памяти, на которую ссылается ppUnkOut, код выступает как вызываемый объект и корректно вызывает AddRef через интерфейсный указатель перед возвратом управления вызывающему объекту.
Существуют некоторые тонкости относительно AddRef и Release, подлежащие обсуждению. Как AddRef, так и Release предназначались для возврата 32-битного целого числа без знака. Это целое число отражает общее количество оставшихся ссылок после применения операций AddRef или Release. Однако по целому ряду причин, связанных с многопоточным режимом, удаленным доступом и мультипроцессорной архитектурой, нельзя быть уверенным в том, что эта величина будет точно отражать общее число неосвобожденных интерфейсных указателей, и клиенту следует игнорировать ее, если только она не используется в целях диагностики при отладке.
Единственный случай, заслуживающий внимания, это когда Release возвращает нуль. Нулевой результат от Release надежно свидетельствует о том, что данный объект более не действителен ни в каком смысле. Однако обратное неверно. Это значит, что когда Release возвращает не нуль, нельзя утверждать, что объект еще работоспособен. Фактически, если Release был вызван указателем интерфейса столько же раз, сколько этим же указателем интерфейса был вызван AddRef , то данный указатель интерфейса недействителен и более не обеспечивает указание на действующий объект. В то же время возможно, что это – случайность, а объект все еще работоспособен благодаря другим, еще не освобожденным, указателям, и все может измениться в самый неподходящий момент. Чтобы однажды освобожденные (released) интерфейсные указатели более не использовались, можно, например, обнулять их сразу же после вызова метода Release:
inline void SafeRelease(IUnknown * &rpUnk)
{
if (rpUnk)
{
rpUnk->Release();
rpUnk = 0;
// rpUnk passed by reference
// rpUnk, переданный ссылкой
}
}
Когда этот способ применен, любое использование указателя интерфейса после его высвобождения немедленно вызовет ошибку доступа. Эта ошибка затем может быть достоверно воспроизведена и, можно надеяться, отловлена еще на этапе разработки.
Еще одна тонкость, относящаяся к AddRef и Release, состоит в выходе из блока. Функция GetAndUse , приведенная ранее, имеет только одну точку выхода. Это означает, что операторы, высвобождающие указатели интерфейса в конце функции, будут всегда выполняться ранее завершения работы функции. Если же функция завершит работу, не доходя до этих операторов – либо благодаря явному оператору return или же, что хуже, необработанному (unhandled) исключению C++, – то эти завершающие операторы будут пропущены и все ресурсы, удерживаемые неосвобожденными интерфейсными указателями, будут утеряны до окончания клиентской программы. Это означает, что к указателям интерфейса СОМ следует относиться с осторожностью, особенно при использовании их в средах, использующих исключения C++. Впрочем, это касается и других системных ресурсов, с которыми приходится работать, будь то семафоры или динамически распределяемая память. Далее в этой главе обсуждаются интеллектуальные СОМ-указатели, которые обеспечивают вызов Release во всех ситуациях.
Спецификация модели компонентных объектов (Component Object Model Specification) содержит четкие определения правил подсчета ссылок СОМ. Понимание мотивировки этих определений имеет решающее значение при СОМ-программировании на C++. Эти правила СОМ о подсчете ссылок могут быть сведены к трем простым аксиомам:
Когда ненулевой указатель интерфейса копируется из одной ячейки памяти в другую, должен вызываться AddRef для извещения объекта о дополнительной ссылке.
Перед тем как произойдет перезапись той ячейки памяти, где содержится ненулевой указатель интерфейса, необходимо вызвать Release, чтобы известить объект, что ссылка уничтожается.
Избыточное количество вызовов AddRef и Release можно сократить, если иметь дополнительную информацию о связях между двумя и более ячейками памяти.
Аксиома о дополнительной информации введена главным образом для того, чтобы ввести возможность преобразования запутанных ситуаций в разумные и осмысленные идиомы программирования (например, стеки временных вызовов и сгенерированное компилятором занесение переменной в регистр не нуждаются в подсчете ссылок). Можно провести месяцы в поиске особых связей между переменными, содержащими явные указатели на интерфейс в программе и оптимизировать избыточные вызовы AddRef и Release , но поступать так было бы неосмотрительно. Выгода от удаления этих избыточных вызовов явно незначительна, так как даже в худшем случае, когда объект вызывается с расстояния более 8500 миль со средней скоростью передачи 14.4 кбит/сек, эти избыточные вызовы никогда не уйдут из вызывающего потока и нечасто требуют множество инструкций для выполнения.
Если руководствоваться приведенными выше тремя простыми аксиомами о подсчете ссылок в интерфейсных указателях, то можно записать это в виде руководящих принципов программирования, чтобы установить, когда вызывать и когда не вызывать AddRef и Release . Вот несколько типичных ситуаций, требующих вызова метода AddRef:
А1. Когда ненулевой интерфейсный указатель записывается в локальную переменную.
А2. Когда вызываемый объект пишет ненулевой интерфейсный указатель в параметр [out] или [in, out] метода или функции.
A3. Когда вызываемый объект возвращает ненулевой интерфейсный указатель как физический результат (physical result) функции.
А4. Когда ненулевой интерфейсный указатель пишется в элемент данных объекта.
Некоторые типичные ситуации, требующие вызова метода Release :
R1. Перед перезаписью ненулевой локальной переменной или элемента данных.
R2. Перед тем как покинуть область действия ненулевой локальной переменной.
R3. Когда вызываемый объект перезаписывает параметр [in,out] метода или функции, начальное значение которых отлично от нуля. Заметим, что параметры [out] предполагаются нулевыми при вводе и никогда не могут освобождаться вызываемым объектом.
R4. Перед перезаписью ненулевого элемента данных объекта.
R5. Перед завершением работы деструктора объекта, имеющего в качестве элемента данных ненулевой интерфейсный указатель.
Типичная ситуация, к которой применимо правило о дополнительной информации, возникает при передаче указателей интерфейсов функциям как параметрам [in]:
S1. Когда при вызове функции или метода ненулевой интерфейсный указатель передается через [in] -параметр, вызов AddRef и Release, не требуются, так как время жизни временной переменной в стеке является строгим подмножеством времени жизни выражения, использованного для инициализации формального аргумента.
Эти десять руководящих принципов охватывают ситуации, снова и снова возникающие при программировании в СОМ, и было бы неплохо их запомнить.
Чтобы конкретизировать правила подсчета ссылок в СОМ, предположим, что имеется глобальная функция, которая возвращает объекту интерфейсный указатель:
void GetObject([out] IUnknown **ppUnk);
и что имеется другая глобальная функция, которая выполняет некую полезную работу над объектом:
void UseObject([in] IUnknown *pUnk);
Написанный ниже код использует эти процедуры, чтобы управлять некоторыми объектами и возвращать интерфейсный указатель вызывающему объекту. Руководящие принципы, применимые к каждому оператору, указаны в комментариях к нему:
void GetAndUse(/* [out] */ IUnknown ** ppUnkOut)
{ IUnknown *pUnk1 = 0, *pUnk2 = 0; *ppUnkOut =0;
// R3
// get pointers to one (or two) objects
// получаем указатели на один (или два) объекта
GetObject(&pUnk1);
//A2
GetObject(&pUnk2);
//A1
// set pUnk2 to point to first object
// устанавливаем pUnk2, чтобы указать на первый объект
if (pUnk2) pUnk2->Release():
//R1
if (pUnk2 = pUnk1) pUnk2->AddRef():
//A1
// pass pUnk2 to some other function
// передаем pUnk2 какой-нибудь другой функции
UseObject(pUnk2);
//S1
// return pUnk2 to caller using ppUnkOut parameter
// возвращаем pUnk2 вызывающему объекту, используя
// параметр ppUnkOut
if (*ppUnkOut = pUnk2) (*ppUnkOut)->AddRef();
// A2
// falling out of scope so clean up
// выходит за область действия и поэтому освобождаем
if (pUnk1) pUnkl->Release();
//R2
if (pUnk2) pUnk2->Release();
//R2
}
Важно отметить, что в вышеприведенном коде правило A2 применяется дважды, но по двум разным причинам. При вызове GetObject код выступает как вызывающий объект, а реализация GetObject является вызываемым объектом. Это означает, что реализация GetObject является ответственной за вызов AddRef через параметр [out]. При перезаписи памяти, на которую ссылается ppUnkOut, код выступает как вызываемый объект и корректно вызывает AddRef через интерфейсный указатель перед возвратом управления вызывающему объекту.
Существуют некоторые тонкости относительно AddRef и Release, подлежащие обсуждению. Как AddRef, так и Release предназначались для возврата 32-битного целого числа без знака. Это целое число отражает общее количество оставшихся ссылок после применения операций AddRef или Release. Однако по целому ряду причин, связанных с многопоточным режимом, удаленным доступом и мультипроцессорной архитектурой, нельзя быть уверенным в том, что эта величина будет точно отражать общее число неосвобожденных интерфейсных указателей, и клиенту следует игнорировать ее, если только она не используется в целях диагностики при отладке.
Единственный случай, заслуживающий внимания, это когда Release возвращает нуль. Нулевой результат от Release надежно свидетельствует о том, что данный объект более не действителен ни в каком смысле. Однако обратное неверно. Это значит, что когда Release возвращает не нуль, нельзя утверждать, что объект еще работоспособен. Фактически, если Release был вызван указателем интерфейса столько же раз, сколько этим же указателем интерфейса был вызван AddRef , то данный указатель интерфейса недействителен и более не обеспечивает указание на действующий объект. В то же время возможно, что это – случайность, а объект все еще работоспособен благодаря другим, еще не освобожденным, указателям, и все может измениться в самый неподходящий момент. Чтобы однажды освобожденные (released) интерфейсные указатели более не использовались, можно, например, обнулять их сразу же после вызова метода Release:
inline void SafeRelease(IUnknown * &rpUnk)
{
if (rpUnk)
{
rpUnk->Release();
rpUnk = 0;
// rpUnk passed by reference
// rpUnk, переданный ссылкой
}
}
Когда этот способ применен, любое использование указателя интерфейса после его высвобождения немедленно вызовет ошибку доступа. Эта ошибка затем может быть достоверно воспроизведена и, можно надеяться, отловлена еще на этапе разработки.
Еще одна тонкость, относящаяся к AddRef и Release, состоит в выходе из блока. Функция GetAndUse , приведенная ранее, имеет только одну точку выхода. Это означает, что операторы, высвобождающие указатели интерфейса в конце функции, будут всегда выполняться ранее завершения работы функции. Если же функция завершит работу, не доходя до этих операторов – либо благодаря явному оператору return или же, что хуже, необработанному (unhandled) исключению C++, – то эти завершающие операторы будут пропущены и все ресурсы, удерживаемые неосвобожденными интерфейсными указателями, будут утеряны до окончания клиентской программы. Это означает, что к указателям интерфейса СОМ следует относиться с осторожностью, особенно при использовании их в средах, использующих исключения C++. Впрочем, это касается и других системных ресурсов, с которыми приходится работать, будь то семафоры или динамически распределяемая память. Далее в этой главе обсуждаются интеллектуальные СОМ-указатели, которые обеспечивают вызов Release во всех ситуациях.
Приведение типов и IUnknown
В предыдущей главе обсуждалось, почему необходимо определять тип на этапе выполнения в динамически собранной системе. Язык C++ предусматривает разумный механизм для динамического определения типа с помощью оператора dynamic_cast. Хотя эта языковая возможность имеет собственную реализацию для каждого компилятора, в предыдущей главе было предложено средство урегулирования этого – добавление к каждому интерфейсу явного метода, являющегося семантическим эквивалентом dynamic_cast. Ниже приводится IDL-описание QueryInterface:
HRESULT QueryInterface([in] REFIID riid, [out] void **ppv);
Первый параметр (riid) является физическим именем запрошенного интерфейса. Второй параметр (ppv) указывает на переменную интерфейсного указателя, которая в случае успешного завершения будет содержать запрошенный указатель на интерфейс.
В ответ на запрос QueryInterface, если объект не поддерживает запрошенный тип интерфейса, он должен возвратить E_NOINTERFACE после установки *ppv в нулевое значение. Если же объект поддерживает запрошенный интерфейс, он должен перезаписать *ppv указателем запрошенного типа и возвратить HRESULT S_OK. Поскольку ppv является [out]-параметром, реализация QueryInterface должна выполнить AddRef для возвращаемого указателя перед тем, как вернуть управление вызывающему объекту (см. в этой главе выше руководящий принцип А2). Этот вызов AddRef должен быть согласован с вызовом Release со стороны клиента. Следующий код показывает динамическое определение типа с использованием оператора C++ dynamic_cast на примере иерархии типов Dog/Cat, описанного ранее в данной главе:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk)
{
IPug *pPug = 0;
pPug = dynamic_cast<IPug*> (pUnk);
if (pPug)
// the object is Pug-compatible
// объект совместим с Pug
pPug->Snore();
ICat *pCat = 0;
pCat = dynamic_cast<ICat*>(pUnk);
if (pCat)
// the object is Cat-compatible
// объект совместим с Cat
pCat->IgnoreMaster();
}
Если объект, переданный этой функции, совместим одновременно с ICat и с IDog, то задействованы обе функциональные возможности. Если же объект в действительности не совместим с ICat или с IDog, то данная функция просто проигнорирует пропущенный аспект объекта (или оба аспекта сразу). Ниже показан семантически эквивалентный вариант с использованием QueryInterface:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk)
{
HRESULT hr;
IPug *pPug = 0;
hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug);
if (SUCCEEDED(hr))
{
// the object is Pug-compatible
// объект совместим с Pug
pPug->Snore();
pPug->Release();
// R2
}
ICat *pCat = 0;
hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat);
if (SUCCEEDED(hr))
{
// the object is Cat-compatible
// объект совместим с Cat
pCat->IgnoreMaster();
pCat->Release(); // R2
}
}
Хотя имеются очевидные различия в синтаксисе, единственная существенная разница между двумя приведенными фрагментами кода состоит в том, что вариант, основанный на QueryInterface, подчиняется правилам подсчета ссылок СОМ.
Есть несколько тонкостей, связанных с QueryInterface и его употреблением. Метод QueryInterface может возвращать указатели только на тот же самый СОМ-объект, для которого он вызван. Глава 4 посвящена объяснению каждого нюанса этого оператора. Полезно, однако, отметить уже сейчас, что клиент не должен трактовать AddRef и Release как операции с объектом. Вместо этого следует рассматривать их как операции с указателем интерфейса. Это означает, что нижеследующий код ошибочен:
void BadCOMCode(/*[in]*/ IUnknown *pUnk)
{
ICat *pCat = 0;
IPug *pPug = 0;
HRESULT hr;
hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat);
if (FAILED(hr)) goto cleanup;
hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug);
if (FAILED(hr)) goto cleanup;
pPug->Bark();
pCat->IgnoreMaster();
cleanup:
if (pCat) pUnk->Release();
// pCat got AddRefed in QI
// pCat получил AddRef в QI
if (pPug) pUnk->Release();
// pDog got AddRefed in QI
// pDog получил AddRef в QI
}
Несмотря на то что все три указателя: pCat, pPug и pUnk – указывают на тот же самый объект, клиент не имеет права компенсировать AddRef, который происходит для pCat и pPug при вызове QueryInterface, вызовами Release для pUnk. Правильный вариант этого кода такой:
cleanup:
if (pCat) pCat->Release();
// use AddRefed ptr
// используем указатель AddRef
if (pPug) pPug->Release();
// use AddRefed ptr
// используем указатель AddRef
Здесь Release вызывается для того же интерфейсного указателя, для которого и AddRef (что произошло неявно, когда указатель был возвращен из QueryInterface). Это требование предоставляет разработчику значительную гибкость при реализации объекта. Например, объект может решить подсчитывать ссылки на каждый интерфейс, чтобы активным образом использовать ресурсы, которые обычно используются одним определенным интерфейсом на объект.
Еще одна тонкость относится ко второму параметру QueryInterface, имеющему тип void**. Весьма забавно то, что QueryInterface, являющийся основой системы типов СОМ, имеет довольно сомнительный в смысле типа аналог в C++:
HRESULT _stdcall QueryInterface(REFIID riid, void** ppv);
Как было отмечено ранее, клиенты вызывают QueryInterface, передавая объекту указатель на интерфейсный указатель в качестве второго параметра вместе с IID, который определяет тип ожидаемого интерфейсного указателя:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)&pPug);
К сожалению, для компилятора C++ таким же правильным выглядит и следующее:
IPug *pPug = 0; hr = punk->QueryInterface(IID_ICat, (void**)&pPug);
Даже еще более хитроумный вариант компилируется без ошибок:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)pPug);
Исходя из того, что правила наследования неприменимы к указателям, такое альтернативное определение QueryInterface нe облегчает проблему:
HRESULT QueryInterface(REFIID riid, IUnknown** ppv);
так как неявное приведение типа к родительскому типу (upcasting) применимо только к объектам и указателям на объекты, а не к указателям на указатели на объекты:
IDerived **ppd; IBase **ppb = ppd;
// illegal
// неверно
To же ограничение применимо в равной мере и к ссылкам на указатели. Следующее альтернативное определение вряд ли более удобно для использования клиентами:
HRESULT QueryInterface(const IID& riid, void* ppv);
так как позволяет клиентам отказаться от приведения типа (cast). К сожалению, это решение не уменьшает количества ошибок (обе из предшествующих ошибок все еще возможны), а устраняя необходимость приведения, уничтожает и видимый индикатор того, что устойчивость типов C++ может оказаться в опасности. Если желательна семантика QueryInterface, то выбор типов аргументов, сделанный корпорацией Microsoft, по крайней мере, разумен, если не надежен или изящен. Простейший путь избежать ошибок, связанных c QueryInterface,– это всегда быть уверенным в том, что IID соответствует типу указателя интерфейса, который проходит как второй параметр QueryInterface. На самом деле первый параметр QueryInterface описывает «форму» типа указателя второго параметра. Их связь может быть усилена на этапе компиляции с помощью такого макроса предпроцессора С:
#define IID_PPV_ARG(Type, Expr) IID_##type,
reinterpret_cast<void**>(static_cast<Type **>(Expr))
С помощью этого макроса[1] компилятор будет уверен в том, что выражение, использованное в приведенном ниже вызове QueryInterface, имеет правильный тип и что используется соответствующий уровень изоляции (indirecton):
IPug *pPug = 0; hr = punk->QueryInterface(IID_PPV_ARG(IPug, &pPug));
Этот макрос закрывает брешь, вызванную параметром void**, без каких-либо затрат на этапе выполнения.
HRESULT QueryInterface([in] REFIID riid, [out] void **ppv);
Первый параметр (riid) является физическим именем запрошенного интерфейса. Второй параметр (ppv) указывает на переменную интерфейсного указателя, которая в случае успешного завершения будет содержать запрошенный указатель на интерфейс.
В ответ на запрос QueryInterface, если объект не поддерживает запрошенный тип интерфейса, он должен возвратить E_NOINTERFACE после установки *ppv в нулевое значение. Если же объект поддерживает запрошенный интерфейс, он должен перезаписать *ppv указателем запрошенного типа и возвратить HRESULT S_OK. Поскольку ppv является [out]-параметром, реализация QueryInterface должна выполнить AddRef для возвращаемого указателя перед тем, как вернуть управление вызывающему объекту (см. в этой главе выше руководящий принцип А2). Этот вызов AddRef должен быть согласован с вызовом Release со стороны клиента. Следующий код показывает динамическое определение типа с использованием оператора C++ dynamic_cast на примере иерархии типов Dog/Cat, описанного ранее в данной главе:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk)
{
IPug *pPug = 0;
pPug = dynamic_cast<IPug*> (pUnk);
if (pPug)
// the object is Pug-compatible
// объект совместим с Pug
pPug->Snore();
ICat *pCat = 0;
pCat = dynamic_cast<ICat*>(pUnk);
if (pCat)
// the object is Cat-compatible
// объект совместим с Cat
pCat->IgnoreMaster();
}
Если объект, переданный этой функции, совместим одновременно с ICat и с IDog, то задействованы обе функциональные возможности. Если же объект в действительности не совместим с ICat или с IDog, то данная функция просто проигнорирует пропущенный аспект объекта (или оба аспекта сразу). Ниже показан семантически эквивалентный вариант с использованием QueryInterface:
void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk)
{
HRESULT hr;
IPug *pPug = 0;
hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug);
if (SUCCEEDED(hr))
{
// the object is Pug-compatible
// объект совместим с Pug
pPug->Snore();
pPug->Release();
// R2
}
ICat *pCat = 0;
hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat);
if (SUCCEEDED(hr))
{
// the object is Cat-compatible
// объект совместим с Cat
pCat->IgnoreMaster();
pCat->Release(); // R2
}
}
Хотя имеются очевидные различия в синтаксисе, единственная существенная разница между двумя приведенными фрагментами кода состоит в том, что вариант, основанный на QueryInterface, подчиняется правилам подсчета ссылок СОМ.
Есть несколько тонкостей, связанных с QueryInterface и его употреблением. Метод QueryInterface может возвращать указатели только на тот же самый СОМ-объект, для которого он вызван. Глава 4 посвящена объяснению каждого нюанса этого оператора. Полезно, однако, отметить уже сейчас, что клиент не должен трактовать AddRef и Release как операции с объектом. Вместо этого следует рассматривать их как операции с указателем интерфейса. Это означает, что нижеследующий код ошибочен:
void BadCOMCode(/*[in]*/ IUnknown *pUnk)
{
ICat *pCat = 0;
IPug *pPug = 0;
HRESULT hr;
hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat);
if (FAILED(hr)) goto cleanup;
hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug);
if (FAILED(hr)) goto cleanup;
pPug->Bark();
pCat->IgnoreMaster();
cleanup:
if (pCat) pUnk->Release();
// pCat got AddRefed in QI
// pCat получил AddRef в QI
if (pPug) pUnk->Release();
// pDog got AddRefed in QI
// pDog получил AddRef в QI
}
Несмотря на то что все три указателя: pCat, pPug и pUnk – указывают на тот же самый объект, клиент не имеет права компенсировать AddRef, который происходит для pCat и pPug при вызове QueryInterface, вызовами Release для pUnk. Правильный вариант этого кода такой:
cleanup:
if (pCat) pCat->Release();
// use AddRefed ptr
// используем указатель AddRef
if (pPug) pPug->Release();
// use AddRefed ptr
// используем указатель AddRef
Здесь Release вызывается для того же интерфейсного указателя, для которого и AddRef (что произошло неявно, когда указатель был возвращен из QueryInterface). Это требование предоставляет разработчику значительную гибкость при реализации объекта. Например, объект может решить подсчитывать ссылки на каждый интерфейс, чтобы активным образом использовать ресурсы, которые обычно используются одним определенным интерфейсом на объект.
Еще одна тонкость относится ко второму параметру QueryInterface, имеющему тип void**. Весьма забавно то, что QueryInterface, являющийся основой системы типов СОМ, имеет довольно сомнительный в смысле типа аналог в C++:
HRESULT _stdcall QueryInterface(REFIID riid, void** ppv);
Как было отмечено ранее, клиенты вызывают QueryInterface, передавая объекту указатель на интерфейсный указатель в качестве второго параметра вместе с IID, который определяет тип ожидаемого интерфейсного указателя:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)&pPug);
К сожалению, для компилятора C++ таким же правильным выглядит и следующее:
IPug *pPug = 0; hr = punk->QueryInterface(IID_ICat, (void**)&pPug);
Даже еще более хитроумный вариант компилируется без ошибок:
IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)pPug);
Исходя из того, что правила наследования неприменимы к указателям, такое альтернативное определение QueryInterface нe облегчает проблему:
HRESULT QueryInterface(REFIID riid, IUnknown** ppv);
так как неявное приведение типа к родительскому типу (upcasting) применимо только к объектам и указателям на объекты, а не к указателям на указатели на объекты:
IDerived **ppd; IBase **ppb = ppd;
// illegal
// неверно
To же ограничение применимо в равной мере и к ссылкам на указатели. Следующее альтернативное определение вряд ли более удобно для использования клиентами:
HRESULT QueryInterface(const IID& riid, void* ppv);
так как позволяет клиентам отказаться от приведения типа (cast). К сожалению, это решение не уменьшает количества ошибок (обе из предшествующих ошибок все еще возможны), а устраняя необходимость приведения, уничтожает и видимый индикатор того, что устойчивость типов C++ может оказаться в опасности. Если желательна семантика QueryInterface, то выбор типов аргументов, сделанный корпорацией Microsoft, по крайней мере, разумен, если не надежен или изящен. Простейший путь избежать ошибок, связанных c QueryInterface,– это всегда быть уверенным в том, что IID соответствует типу указателя интерфейса, который проходит как второй параметр QueryInterface. На самом деле первый параметр QueryInterface описывает «форму» типа указателя второго параметра. Их связь может быть усилена на этапе компиляции с помощью такого макроса предпроцессора С:
#define IID_PPV_ARG(Type, Expr) IID_##type,
reinterpret_cast<void**>(static_cast<Type **>(Expr))
С помощью этого макроса[1] компилятор будет уверен в том, что выражение, использованное в приведенном ниже вызове QueryInterface, имеет правильный тип и что используется соответствующий уровень изоляции (indirecton):
IPug *pPug = 0; hr = punk->QueryInterface(IID_PPV_ARG(IPug, &pPug));
Этот макрос закрывает брешь, вызванную параметром void**, без каких-либо затрат на этапе выполнения.
Реализация IUnknown
Имея описанные выше образцы клиентского использования, легко видеть, как реализовать методы IUnknown. Примем предложенную выше иерархию типов Dog/Cat. Чтобы определить С++-класс, который реализует интерфейсы IPug и ICat , нужно просто добавить к списку базовых классов самые последние в иерархии наследования версии интерфейсов:
class PugCat : public IPug, public ICat
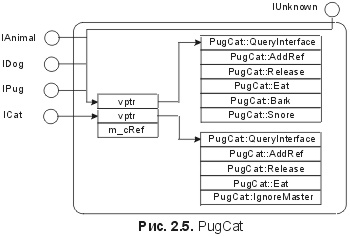
При использовании наследования компилятор C++ обеспечивает совместимость двоичного представления производного класса с каждым базовым классом. Для класса PugCat это означает, что все объекты PugCat будут содержать указатель vptr, указывающий на таблицу vtbl, совместимую с IPug. Объекты PugCat также будут содержать указатель vptr, указывающий на вторую таблицу vtbl, совместимую с ICat. Рисунок 2.5 показывает, как интерфейсы в качестве базовых классов соотносятся с представлением объектов.
Поскольку все функции-члены в СОМ-определениях интерфейса являются чисто виртуальными, производный класс должен обеспечивать реализацию каждого метода, имеющегося в любом из его интерфейсов. Методы, общие для двух или более интерфейсов (например, QueryInterface, AddRef и т. д.) нужно реализовывать только один раз, так как компилятор и компоновщик инициализируют все таблицы vtbl так, чтобы они указывали на одну реализацию метода. Таков естественный побочный эффект от использования множественного наследования в языке C++.
 Следующий код является определением класса, которое создает объекты, поддерживающие интерфейсы IPug и ICat:
Следующий код является определением класса, которое создает объекты, поддерживающие интерфейсы IPug и ICat:
class PugCat : public IPug, public ICat
{
LONG mcRef;
protected:
virtual ~PugCat(void);
public: PugCat(void);
// IUnknown methods
// методы IUnknown
STDMETHODIMP QueryInterface(REFIID riid, void **ppv);
STDMETHODIMP(ULONG) AddRef(void);
STDMETHODIMP(ULONG) Release(void);
// IAnimal methods
// методы IAnimal
STDMETHODIMP Eat(void);
// IDog methods
// методы IDog
STDMETHODIMP Bark(void);
// IPug methods
// методы IPug
STDMETHODIMP Snore(void);
// ICat methods
// методы ICat
STDMETHODIMP IgnoreMaster(void);
};
Отметим, что в классе должен быть реализован каждый метод, определенный в любом интерфейсе, от которого он наследует, так же, как и каждый метод, определенный в любых производных (implied) базовых интерфейсах (например, IDog, IAnimal ). Для создания стековых фреймов, совместимых с СОМ, необходимо использовать макросы STDMETHODIMP и STDMETHODIMP. При ориентации на платформы Win32, использующие компилятор Microsoft C++, заголовки SDK определяют эти два макроса следующим образом:
#define STDMETHODIMP HRESULT stdcall
#define STDMETHODIMP(type) type stdcall
Заголовочные файлы SDK также определяют макросы STDMETHOD и STDMETHOD , которые можно использовать при определении интерфейсов без IDL-компилятора. В серийно выпускаемом программировании на СОМ эти два макроса не нужны.
Реализация AddRef и Release чрезвычайно прозрачна. Элемент данных mcRef отслеживает, сколько неосвобожденных интерфейсных указателей удерживают объект. Конструктор класса приводит счетчик ссылок в нулевое состояние:
PugCat::PugCat(void) : mcRef(0)
// initialize reference count to zero
// устанавливаем счетчик ссылок в нуль
{ }
Реализация AddRef в классе фиксирует путем увеличения счетчика ссылок, что вызывающий объект продублировал указатель интерфейса. Измененное значение счетчика ссылок возвращается для целей диагностики:
STDMETHODIMP(ULONG) AddRef(void)
{ return ++mcRef; }
Реализация Release фиксирует уничтожение указателя интерфейса простым уменьшением счетчика ссылок, а также производит соответствующее действие, когда счетчик ссылок достигает нуля. Для объектов, находящихся в динамически распределяемой области памяти, это означает вызов оператора delete для уничтожения объекта:
class PugCat : public IPug, public ICat
При использовании наследования компилятор C++ обеспечивает совместимость двоичного представления производного класса с каждым базовым классом. Для класса PugCat это означает, что все объекты PugCat будут содержать указатель vptr, указывающий на таблицу vtbl, совместимую с IPug. Объекты PugCat также будут содержать указатель vptr, указывающий на вторую таблицу vtbl, совместимую с ICat. Рисунок 2.5 показывает, как интерфейсы в качестве базовых классов соотносятся с представлением объектов.
Поскольку все функции-члены в СОМ-определениях интерфейса являются чисто виртуальными, производный класс должен обеспечивать реализацию каждого метода, имеющегося в любом из его интерфейсов. Методы, общие для двух или более интерфейсов (например, QueryInterface, AddRef и т. д.) нужно реализовывать только один раз, так как компилятор и компоновщик инициализируют все таблицы vtbl так, чтобы они указывали на одну реализацию метода. Таков естественный побочный эффект от использования множественного наследования в языке C++.
class PugCat : public IPug, public ICat
{
LONG mcRef;
protected:
virtual ~PugCat(void);
public: PugCat(void);
// IUnknown methods
// методы IUnknown
STDMETHODIMP QueryInterface(REFIID riid, void **ppv);
STDMETHODIMP(ULONG) AddRef(void);
STDMETHODIMP(ULONG) Release(void);
// IAnimal methods
// методы IAnimal
STDMETHODIMP Eat(void);
// IDog methods
// методы IDog
STDMETHODIMP Bark(void);
// IPug methods
// методы IPug
STDMETHODIMP Snore(void);
// ICat methods
// методы ICat
STDMETHODIMP IgnoreMaster(void);
};
Отметим, что в классе должен быть реализован каждый метод, определенный в любом интерфейсе, от которого он наследует, так же, как и каждый метод, определенный в любых производных (implied) базовых интерфейсах (например, IDog, IAnimal ). Для создания стековых фреймов, совместимых с СОМ, необходимо использовать макросы STDMETHODIMP и STDMETHODIMP. При ориентации на платформы Win32, использующие компилятор Microsoft C++, заголовки SDK определяют эти два макроса следующим образом:
#define STDMETHODIMP HRESULT stdcall
#define STDMETHODIMP(type) type stdcall
Заголовочные файлы SDK также определяют макросы STDMETHOD и STDMETHOD , которые можно использовать при определении интерфейсов без IDL-компилятора. В серийно выпускаемом программировании на СОМ эти два макроса не нужны.
Реализация AddRef и Release чрезвычайно прозрачна. Элемент данных mcRef отслеживает, сколько неосвобожденных интерфейсных указателей удерживают объект. Конструктор класса приводит счетчик ссылок в нулевое состояние:
PugCat::PugCat(void) : mcRef(0)
// initialize reference count to zero
// устанавливаем счетчик ссылок в нуль
{ }
Реализация AddRef в классе фиксирует путем увеличения счетчика ссылок, что вызывающий объект продублировал указатель интерфейса. Измененное значение счетчика ссылок возвращается для целей диагностики:
STDMETHODIMP(ULONG) AddRef(void)
{ return ++mcRef; }
Реализация Release фиксирует уничтожение указателя интерфейса простым уменьшением счетчика ссылок, а также производит соответствующее действие, когда счетчик ссылок достигает нуля. Для объектов, находящихся в динамически распределяемой области памяти, это означает вызов оператора delete для уничтожения объекта: