Страница:
сохранитьрезультат на диске, используя специальное диалоговое окно.
Даже если бы уровень сложности выполнения задач был одинаковым для обоих подходов, концептуальная простота методов, описанных в этой книге, делала бы их более предпочтительными. В большинстве же случаев объем необходимой работы также оказывается намного меньшим, чем при использовании обычных интерфейсов.
5.4. Поиск строк и механизмы поиска
Прежде чем продолжить рассмотрение функции LEAP, имеет смысл рассмотреть несколько более подробно вопрос использования интерфейсов для поиска. Строкой(string) называется последовательность [33]символов. Обычные английские слова и предложения являются примерами строк. При поиске по строке (string search) происходит просмотр (обычно длинной) последовательности, называемой текстом, с целью обнаружения (обычно короткой) последовательности, указанной пользователем и называемой шаблоном (pattern). Каждый случай совпадения между подстрокой текста и заданной комбинацией называется объектом поиска (target). Например, при попытке найти в большом письме место, где вы писали о кошке по кличке «маленькая Татсу», наиболее подходящим объектом поиска будет маленькая Татсу, а еще более короткая строка Татсубудет хорошим шаблоном. Совпадение может быть полным, может зависеть от регистра символов или от других параметров (например, соответствие может быть по рифме). Наиболее распространенный критерий поиска, по которому легко искать, заключается в том, что строчные буквы в задаваемой комбинации соответствуют как строчным, так и прописным буквам в тексте, тогда как прописные буквы в задаваемой комбинации соответствуют только прописным буквам в тексте. Обычно поиск начинается от текущей позиции курсора и осуществляется вперед. В большинстве систем с помощью модальных пользовательских установок можно произвести поиск в обратном направлении (рис. 5.3).
 Рис. 5.3. Модальное диалоговое окно с модальными настройками типа и направления поиска
Рис. 5.3. Модальное диалоговое окно с модальными настройками типа и направления поиска
Интерфейсы к средствам поиска обычно строятся на основе двух подходов. Наиболее распространенным является поиск с разделителями(delimited search), который встречается в большинстве текстовых процессоров. В типичном поиске с разделителями пользователь включает режим, в котором любой введенный текст рассматривается как шаблон для поиска. Обычно для этого используется диалоговое окно, снабженное полем для ввода символов. После вызова диалогового окна пользователь вводит комбинацию символов и разделитель, в качестве которого обычно используется некий символ, запрещенный к отображению в шаблоне (например, Return). В большинстве диалоговых окон пользователь также может ограничить шаблон нажатием на кнопку OK, Search, Find или Find Next с помощью ГУВ. Когда объект поиска обнаружен, он выбирается, а курсор располагается сразу в конце выборки.
Этот традиционный метод является довольно злосчастным для пользователя, хотя большинство компьютерщиков настолько привыкли к этому, что уже не замечают никакого неудобства. Например, пользователь может ввести последовательность для поиска с опечаткой, но заметить ее слишком поздно, т. к. он уже нажал по привычке клавишу «Return». Поэтому ему придется сидеть и ждать, пока закончится поиск, который, как уже заранее известно, не даст результата. Большинство систем поиска являются непрерываемыми, и это является серьезной ошибкой разработчиков. Из-за того, что компьютер ждет, пока пользователь закончит ввод шаблона, по которому начнется поиск, поиск с разделителями часто вынуждает пользователя ждать без необходимости.
Менее распространенным методом является пошаговый поиск(incremental search), известный пример которого можно увидеть в текстовом редакторе EMACS, работающем под операционной системой UNIX (Stallman, 1993). В большинстве случаев использования пошагового поиска, так же как и при поиске с разделителями, пользователь должен сначала вызвать диалоговое окно, в котором имеется поле для ввода шаблона поиска. Когда пользователь вводит первый символ шаблона, система использует этот символ как полный шаблон и сразу же начинает поиск первого экземпляра этого символа в выбранном направлении. Если экземпляр этого первого символа обнаруживается до того, как введен следующий символ шаблона, то он выбирается, а курсор помещается сразу в конце выборки. Если же следующий символ шаблона вводится до того, как экземпляр обнаруживается, то этот символ добавляется к шаблону и поиск продолжается теперь уже в отношении экземпляра расширенного шаблона. Процесс повторяется по мере добавления символов к шаблону поиска.
При использовании клавиши «Backspace» или «Delete» для удаления символов из шаблона пошагового поиска поиск возвращается к предыдущему экземпляру, найденному по тому шаблону, который был до добавления к нему следующего символа. Пользователь может затем добавить символы к шаблону, чтобы продолжить поиск без сброса результатов уже выполненного поиска по неполному шаблону. Многие системы поиска не имеют этой полезной характеристики.
Пошаговый поиск имеет ряд других преимуществ в сравнении с поиском с разделителями. Пошаговый поиск требует меньше времени. Поиск начинается, как только первый символ шаблона введен. Система не ожидает того момента, когда шаблон будет введен полностью. При использовании поиска с разделителями компьютер ждет, пока пользователь полностью введет шаблон и обозначит его разделителем, после чего уже пользователь ждет, пока компьютер производит поиск. При использовании поиска с разделителями пользователь должен сначала предположить, по какому шаблону компьютер сможет отличить нужный объект от других подобных объектов, тогда как при использовании пошагового поиска пользователь сразу же может определить, что шаблон оказался достаточным, чтобы выявить нужный объект, потому что он уже появился на экране. Таким образом, как только пользователь видит, что нужная точка найдена, он может прекратить введение шаблона. Если же он введет слишком много символов, т. е. скорость ввода будет больше, чем скорость поиска, шаблон все равно будет введен, и курсор установится приблизительно в том месте, которое предполагается. Если пользователь ошибается при вводе шаблона в систему поиска с разделителями, для исправления ошибки он должен ждать до тех пор, пока поиск по неверному шаблону не завершится, – в лучшем случае пользователь может воспользоваться механизмом для остановки поиска, если такой предусмотрен. В большом тексте поиск может занимать значительный период времени. В хорошо разработанном пошаговом поиске пользователь может удалить неверно введенный символ в любое время и возвратиться к последнему найденному экземпляру. Поскольку использование клавиши Backspace для исправления ошибки может быть привычным, процесс исправления проходит довольно быстро, и поиск останавливается сразу же. Чтобы возобновить поиск, пользователь может ввести правильный символ.
Еще одним преимуществом пошагового поиска является то, что в нем имеется постоянная обратная связь во время введения символов шаблона, т. е. результаты поиска видны сразу. При использовании поиска с разделителями пользователь не знает, насколько введенный им шаблон является подходящим или даже насколько правильно он был набран, до тех пор пока ввод не закончен и попытка поиска не начата. С точки зрения построения интерфейса, пошаговый поиск имеет так много преимуществ, а поиск с разделителями – так мало, что, на мой взгляд, использование поиска с разделителями редко когда может быть предпочтительным. [34]Несмотря на то что почти все разработчики и пользователи признают, что пошаговый поиск более предпочтителен, почти все инструменты по разработке интерфейсов позволяют создавать средства поиска с разделителями и затрудняют или даже делают невозможным создание средства пошагового поиска. Примерами таких инструментов являются JavaScript и Visual Basic.
Пошаговый ввод шаблона поиска делает возможным изменять шаблон интерактивно прямо во время процесса поиска, а значит, позволяет пользователю оптимизировать поиск по получаемой обратной связи. Даже построение булевой модели поиска делается более эффективным, если результаты поиска отображаются по мере того, как пользователь уточняет шаблон. Найденный экземпляр должен появляться посередине экрана, а не наверху или внизу, так, чтобы материал до и после экземпляра был виден, таким образом, найденный экземпляр всегда отображается в своем контексте. Найденный экземпляр также должен всегда отображаться в одном и том же месте относительно экрана или окна, чтобы пользователь быстро выучил, где искать результаты. В компьютере Canon Cat найденный экземпляр всегда появлялся по вертикальному центру экрана. Он не должен отображаться на каком-то из краев экрана; таким образом, материал вокруг экземпляра всегда был виден.
Если в тексте не содержится экземпляра шаблона, поиск оказывается неудачным. Во многих системах в этом случае поиск прекращается и не может использоваться до тех пор, пока не нажата специальная клавиша (обычно «Enter» или «Return») или кнопка на экране. На экране появляется модальное сообщение, в котором говорится, что вы должны сделать необходимый поклон, прежде чем вам будет позволено продолжить пользование компьютером. В многоэкранных системах или в случаях, когда экран визуально перегружен, такое сообщение может совсем не попасть в локус вашего внимания, и вы можете совсем его не заметить. В результате вам может показаться, что компьютер не отвечает на нажатие клавиш, как будто бы он завис. При использовании же пошагового поиска вы без всякой специальной подсказки сможете заметить, что поиск не удался, потому что курсор в этом случае сразу же возвращается в начальную позицию, и дополнительные нажатия не дают никакого результата. Здесь же может быть полезным короткий звуковой сигнал или мигание на экране, особенно если поиск длился дольше периода действия кратковременной памяти (скажем, дольше 10 секунд), и поэтому пользователь забыл, как выглядел дисплей до начала поиска. Звуковой сигнал еще полезен для пользователей с ухудшенной зрительной способностью.
5.4.1. Разделители в шаблоне поиска
5.4.2. Единицы взаимодействия
5.5. Форма курсора и методы выделения
Даже если бы уровень сложности выполнения задач был одинаковым для обоих подходов, концептуальная простота методов, описанных в этой книге, делала бы их более предпочтительными. В большинстве же случаев объем необходимой работы также оказывается намного меньшим, чем при использовании обычных интерфейсов.
5.4. Поиск строк и механизмы поиска
Маленький шаг большого человечества.
Нейл Армстронг (1969)
Прежде чем продолжить рассмотрение функции LEAP, имеет смысл рассмотреть несколько более подробно вопрос использования интерфейсов для поиска. Строкой(string) называется последовательность [33]символов. Обычные английские слова и предложения являются примерами строк. При поиске по строке (string search) происходит просмотр (обычно длинной) последовательности, называемой текстом, с целью обнаружения (обычно короткой) последовательности, указанной пользователем и называемой шаблоном (pattern). Каждый случай совпадения между подстрокой текста и заданной комбинацией называется объектом поиска (target). Например, при попытке найти в большом письме место, где вы писали о кошке по кличке «маленькая Татсу», наиболее подходящим объектом поиска будет маленькая Татсу, а еще более короткая строка Татсубудет хорошим шаблоном. Совпадение может быть полным, может зависеть от регистра символов или от других параметров (например, соответствие может быть по рифме). Наиболее распространенный критерий поиска, по которому легко искать, заключается в том, что строчные буквы в задаваемой комбинации соответствуют как строчным, так и прописным буквам в тексте, тогда как прописные буквы в задаваемой комбинации соответствуют только прописным буквам в тексте. Обычно поиск начинается от текущей позиции курсора и осуществляется вперед. В большинстве систем с помощью модальных пользовательских установок можно произвести поиск в обратном направлении (рис. 5.3).
Интерфейсы к средствам поиска обычно строятся на основе двух подходов. Наиболее распространенным является поиск с разделителями(delimited search), который встречается в большинстве текстовых процессоров. В типичном поиске с разделителями пользователь включает режим, в котором любой введенный текст рассматривается как шаблон для поиска. Обычно для этого используется диалоговое окно, снабженное полем для ввода символов. После вызова диалогового окна пользователь вводит комбинацию символов и разделитель, в качестве которого обычно используется некий символ, запрещенный к отображению в шаблоне (например, Return). В большинстве диалоговых окон пользователь также может ограничить шаблон нажатием на кнопку OK, Search, Find или Find Next с помощью ГУВ. Когда объект поиска обнаружен, он выбирается, а курсор располагается сразу в конце выборки.
Этот традиционный метод является довольно злосчастным для пользователя, хотя большинство компьютерщиков настолько привыкли к этому, что уже не замечают никакого неудобства. Например, пользователь может ввести последовательность для поиска с опечаткой, но заметить ее слишком поздно, т. к. он уже нажал по привычке клавишу «Return». Поэтому ему придется сидеть и ждать, пока закончится поиск, который, как уже заранее известно, не даст результата. Большинство систем поиска являются непрерываемыми, и это является серьезной ошибкой разработчиков. Из-за того, что компьютер ждет, пока пользователь закончит ввод шаблона, по которому начнется поиск, поиск с разделителями часто вынуждает пользователя ждать без необходимости.
Менее распространенным методом является пошаговый поиск(incremental search), известный пример которого можно увидеть в текстовом редакторе EMACS, работающем под операционной системой UNIX (Stallman, 1993). В большинстве случаев использования пошагового поиска, так же как и при поиске с разделителями, пользователь должен сначала вызвать диалоговое окно, в котором имеется поле для ввода шаблона поиска. Когда пользователь вводит первый символ шаблона, система использует этот символ как полный шаблон и сразу же начинает поиск первого экземпляра этого символа в выбранном направлении. Если экземпляр этого первого символа обнаруживается до того, как введен следующий символ шаблона, то он выбирается, а курсор помещается сразу в конце выборки. Если же следующий символ шаблона вводится до того, как экземпляр обнаруживается, то этот символ добавляется к шаблону и поиск продолжается теперь уже в отношении экземпляра расширенного шаблона. Процесс повторяется по мере добавления символов к шаблону поиска.
При использовании клавиши «Backspace» или «Delete» для удаления символов из шаблона пошагового поиска поиск возвращается к предыдущему экземпляру, найденному по тому шаблону, который был до добавления к нему следующего символа. Пользователь может затем добавить символы к шаблону, чтобы продолжить поиск без сброса результатов уже выполненного поиска по неполному шаблону. Многие системы поиска не имеют этой полезной характеристики.
Пошаговый поиск имеет ряд других преимуществ в сравнении с поиском с разделителями. Пошаговый поиск требует меньше времени. Поиск начинается, как только первый символ шаблона введен. Система не ожидает того момента, когда шаблон будет введен полностью. При использовании поиска с разделителями компьютер ждет, пока пользователь полностью введет шаблон и обозначит его разделителем, после чего уже пользователь ждет, пока компьютер производит поиск. При использовании поиска с разделителями пользователь должен сначала предположить, по какому шаблону компьютер сможет отличить нужный объект от других подобных объектов, тогда как при использовании пошагового поиска пользователь сразу же может определить, что шаблон оказался достаточным, чтобы выявить нужный объект, потому что он уже появился на экране. Таким образом, как только пользователь видит, что нужная точка найдена, он может прекратить введение шаблона. Если же он введет слишком много символов, т. е. скорость ввода будет больше, чем скорость поиска, шаблон все равно будет введен, и курсор установится приблизительно в том месте, которое предполагается. Если пользователь ошибается при вводе шаблона в систему поиска с разделителями, для исправления ошибки он должен ждать до тех пор, пока поиск по неверному шаблону не завершится, – в лучшем случае пользователь может воспользоваться механизмом для остановки поиска, если такой предусмотрен. В большом тексте поиск может занимать значительный период времени. В хорошо разработанном пошаговом поиске пользователь может удалить неверно введенный символ в любое время и возвратиться к последнему найденному экземпляру. Поскольку использование клавиши Backspace для исправления ошибки может быть привычным, процесс исправления проходит довольно быстро, и поиск останавливается сразу же. Чтобы возобновить поиск, пользователь может ввести правильный символ.
Еще одним преимуществом пошагового поиска является то, что в нем имеется постоянная обратная связь во время введения символов шаблона, т. е. результаты поиска видны сразу. При использовании поиска с разделителями пользователь не знает, насколько введенный им шаблон является подходящим или даже насколько правильно он был набран, до тех пор пока ввод не закончен и попытка поиска не начата. С точки зрения построения интерфейса, пошаговый поиск имеет так много преимуществ, а поиск с разделителями – так мало, что, на мой взгляд, использование поиска с разделителями редко когда может быть предпочтительным. [34]Несмотря на то что почти все разработчики и пользователи признают, что пошаговый поиск более предпочтителен, почти все инструменты по разработке интерфейсов позволяют создавать средства поиска с разделителями и затрудняют или даже делают невозможным создание средства пошагового поиска. Примерами таких инструментов являются JavaScript и Visual Basic.
Пошаговый ввод шаблона поиска делает возможным изменять шаблон интерактивно прямо во время процесса поиска, а значит, позволяет пользователю оптимизировать поиск по получаемой обратной связи. Даже построение булевой модели поиска делается более эффективным, если результаты поиска отображаются по мере того, как пользователь уточняет шаблон. Найденный экземпляр должен появляться посередине экрана, а не наверху или внизу, так, чтобы материал до и после экземпляра был виден, таким образом, найденный экземпляр всегда отображается в своем контексте. Найденный экземпляр также должен всегда отображаться в одном и том же месте относительно экрана или окна, чтобы пользователь быстро выучил, где искать результаты. В компьютере Canon Cat найденный экземпляр всегда появлялся по вертикальному центру экрана. Он не должен отображаться на каком-то из краев экрана; таким образом, материал вокруг экземпляра всегда был виден.
Если в тексте не содержится экземпляра шаблона, поиск оказывается неудачным. Во многих системах в этом случае поиск прекращается и не может использоваться до тех пор, пока не нажата специальная клавиша (обычно «Enter» или «Return») или кнопка на экране. На экране появляется модальное сообщение, в котором говорится, что вы должны сделать необходимый поклон, прежде чем вам будет позволено продолжить пользование компьютером. В многоэкранных системах или в случаях, когда экран визуально перегружен, такое сообщение может совсем не попасть в локус вашего внимания, и вы можете совсем его не заметить. В результате вам может показаться, что компьютер не отвечает на нажатие клавиш, как будто бы он завис. При использовании же пошагового поиска вы без всякой специальной подсказки сможете заметить, что поиск не удался, потому что курсор в этом случае сразу же возвращается в начальную позицию, и дополнительные нажатия не дают никакого результата. Здесь же может быть полезным короткий звуковой сигнал или мигание на экране, особенно если поиск длился дольше периода действия кратковременной памяти (скажем, дольше 10 секунд), и поэтому пользователь забыл, как выглядел дисплей до начала поиска. Звуковой сигнал еще полезен для пользователей с ухудшенной зрительной способностью.
5.4.1. Разделители в шаблоне поиска
Другим большим недостатком поиска с разделителями является то, что разделитель, используемый для обозначения конца шаблона, не может быть отображен. Во многих случаях и другие разделители тоже не могут отображаться. Я просмотрел четыре популярных текстовых процессора. В одном из них использование Return вообще не допускалось. Во втором текстовом процессоре для того, чтобы вставить Return в шаблон поиска, пользователь должен набрать ‘r. В третьем текстовом процессоре в этих целях использовалась последовательность \\. В четвертом – Return можно было вставить в шаблон поиска с помощью специального диалогового окна с выпадающим меню, содержащим разные разделители (рис. 5.4). Однако было бы легче просто использовать клавишу «Return». В конце концов, именно таким образом вы вставляете этот разделитель в текст. Почему же при создании шаблона поиска должен использоваться другой метод? Основной принцип состоит в следующем:
одна и та же последовательность символов должна набираться одинаковым образом. Пользователь не должен в одном случае применять один метод, а в другом – другой. Иными словами, в отношении специальных символов не должно применяться ничего специального.
[35]
 Рис. 5.4.Открытое окно поиска в Word. Показан список символов, которые могут быть использованы. В улучшенном варианте пользователь мог бы помещать, например, символ табуляции с помощью нажатия клавиши «Tab». Обратите внимание на два обозначения символа табуляции, которые вставлены в поле поиска (Find what)
Рис. 5.4.Открытое окно поиска в Word. Показан список символов, которые могут быть использованы. В улучшенном варианте пользователь мог бы помещать, например, символ табуляции с помощью нажатия клавиши «Tab». Обратите внимание на два обозначения символа табуляции, которые вставлены в поле поиска (Find what)
Хотя пошаговый поиск лучше, чем поиск с разделителями, вариант пошагового поиска, который используется в EMACS, может быть все же улучшен. Например, курсор должен возникать не на последнем символе объекта поиска, а на первом. В общем, вы вряд ли можете управлять тем, каким будет последний символ в шаблоне поиска, поскольку вы вводите только те символы, которых достаточно для поиска нужного объекта. Поэтому вы не знаете точно, где окажется курсор после того, как поиск будет произведен. Если же курсор всегда будет устанавливаться на первом символе шаблона, вы можете знать, как отобразится объект поиска. Кроме того, это может быть полезным для быстрого перемещения курсора внутри текста, поскольку в локусе вашего внимания находится символ, на который вы хотите переместить курсор. Придумать шаблон, в котором этот символ является последним, намного труднее, чем просто ввести требуемый символ и последующие за ним другие символы.
В обычных пользовательских графических интерфейсах как пошаговый поиск, так и поиск с разделителями запускается модально, с помощью диалогового окна, тогда как использование клавиши «LEAP» является безмодальным. Идею использования для поиска квазирежима можно дополнить применением специальной кнопки на микрофоне (или ГУВ), удерживаемой для включения квазирежима, в котором вводимые слова, рисунки или рукописный текст могут включаться в шаблон поиска. Другие методы ввода имеют аналогичные средства для создания квазирежима поиска (Raskin и Winter, 1991).
Скорость пошагового поиска может быть увеличена с помощью некоторых приемов. Например, при вводе первого символа искомой строки компьютер сразу приступает к поиску первого экземпляра этого символа в тексте, после чего найденный экземпляр подсвечивается и переносится вместе со своим контекстом в окно экрана. Обычно этот процесс проходит быстро, поскольку в тексте имеется много потенциальных экземпляров и какой-то из них, с большой вероятностью, оказывается поблизости. Пока пользователь вводит следующий символ, поиск может продолжиться в отношении второго экземпляра первого символа и последующего возможного символа в порядке уменьшения частоты использования. Программа может сохранять ссылки на каждый из обнаруженных экземпляров. Как результат, при вводе второго символа компьютер может быть готов отобразить обнаруженный объект, создавая эффект мгновенного поиска.
Поиск строк также может быть ускорен и такими методами, как алгоритм Бойера-Муура (Moore и Boyer, 1977), в котором время поиска уменьшается по мере увеличения длины последовательности. Если пользователь возвращается в шаблоне поиска на одну позицию назад, сохранение ссылки на последнее обнаруженное место (причем для каждого символа последовательности) сделает возвращение чрезвычайно быстрым. Индексирование всех запоминающих устройств может сократить время поиска в локальных системах и сетях до миллисекунд. Скорость взаимодействия через глобальные сети или Интернет также зависит от применяемых методов индексирования. Пошаговый поиск в различных вариантах использовался в таких коммерческих продуктах, как IDE компании Borland, факсовая программа компании Global Village, компьютеры Canon Cat и SwyftWare.
Хотя пошаговый поиск лучше, чем поиск с разделителями, вариант пошагового поиска, который используется в EMACS, может быть все же улучшен. Например, курсор должен возникать не на последнем символе объекта поиска, а на первом. В общем, вы вряд ли можете управлять тем, каким будет последний символ в шаблоне поиска, поскольку вы вводите только те символы, которых достаточно для поиска нужного объекта. Поэтому вы не знаете точно, где окажется курсор после того, как поиск будет произведен. Если же курсор всегда будет устанавливаться на первом символе шаблона, вы можете знать, как отобразится объект поиска. Кроме того, это может быть полезным для быстрого перемещения курсора внутри текста, поскольку в локусе вашего внимания находится символ, на который вы хотите переместить курсор. Придумать шаблон, в котором этот символ является последним, намного труднее, чем просто ввести требуемый символ и последующие за ним другие символы.
В обычных пользовательских графических интерфейсах как пошаговый поиск, так и поиск с разделителями запускается модально, с помощью диалогового окна, тогда как использование клавиши «LEAP» является безмодальным. Идею использования для поиска квазирежима можно дополнить применением специальной кнопки на микрофоне (или ГУВ), удерживаемой для включения квазирежима, в котором вводимые слова, рисунки или рукописный текст могут включаться в шаблон поиска. Другие методы ввода имеют аналогичные средства для создания квазирежима поиска (Raskin и Winter, 1991).
Скорость пошагового поиска может быть увеличена с помощью некоторых приемов. Например, при вводе первого символа искомой строки компьютер сразу приступает к поиску первого экземпляра этого символа в тексте, после чего найденный экземпляр подсвечивается и переносится вместе со своим контекстом в окно экрана. Обычно этот процесс проходит быстро, поскольку в тексте имеется много потенциальных экземпляров и какой-то из них, с большой вероятностью, оказывается поблизости. Пока пользователь вводит следующий символ, поиск может продолжиться в отношении второго экземпляра первого символа и последующего возможного символа в порядке уменьшения частоты использования. Программа может сохранять ссылки на каждый из обнаруженных экземпляров. Как результат, при вводе второго символа компьютер может быть готов отобразить обнаруженный объект, создавая эффект мгновенного поиска.
Поиск строк также может быть ускорен и такими методами, как алгоритм Бойера-Муура (Moore и Boyer, 1977), в котором время поиска уменьшается по мере увеличения длины последовательности. Если пользователь возвращается в шаблоне поиска на одну позицию назад, сохранение ссылки на последнее обнаруженное место (причем для каждого символа последовательности) сделает возвращение чрезвычайно быстрым. Индексирование всех запоминающих устройств может сократить время поиска в локальных системах и сетях до миллисекунд. Скорость взаимодействия через глобальные сети или Интернет также зависит от применяемых методов индексирования. Пошаговый поиск в различных вариантах использовался в таких коммерческих продуктах, как IDE компании Borland, факсовая программа компании Global Village, компьютеры Canon Cat и SwyftWare.
5.4.2. Единицы взаимодействия
Пошаговый поиск является одним из примеров использования общего принципа разработки человекоориентированных интерфейсов, который заключается в следующем:
программа должна взаимодействовать с пользователем на основе наименьшей значимой единицы ввода. Взаимодействие с данными, вводимыми с помощью клавиатуры, должно быть познаковым, а не построчным. Взаимодействие с данными, вводимыми с помощью голосовых устройств, должно быть пословным, а для некоторых приложений даже может быть поморфемным и т. д.
Взаимодействие посредством последовательного ввода строки текста, т. е. строки, отделенной знаком Return, – это пережиток времен телетайпа, который должен быть передан в музеи вместе с оборудованием того времени. [36]Сегодня мы можем и должны иметь возможность пользоваться интерфейсами, способными реагировать на каждый вводимый символ во всех случаях, когда такая реакция может улучшить качество взаимодействия. Как и всегда, разработчики должны быть внимательны – например, посимвольное взаимодействие не должно приводить к выдаче сообщений об орфографических ошибках в середине набора слова, что может усложнить работу пользователя, владеющего слепым методом набора.
В маленьких текстах, для которых поиск строк был изначально придуман, он обычно проходил от текущей позиции курсора до конца текста. В текстах большего размера в случае, если до конца документа искомый объект так и не был обнаружен, обычно удобнее продолжить поиск с начала документа до позиции курсора, если пользователь забыл, что искомый объект находится выше. Неопубликованное тестирование, проведенное в компании Information Appliance, показало, что если поиск производится быстро, то цикличный поиск оказывается особенно удобным. «Быстрый» означает здесь, что между запуском поиска и его успешным либо неуспешным окончанием не остается времени на действия пользователя. Как правило, это время составляет порядка 250 мс. Во многих системах пользователь может выбрать, каким образом будет проходить поиск – либо циклично (по кругу), либо с остановкой в конце документа. Это порождает типичную проблему модальности. Если установлен нецикличный поиск, и пользователь не знает об этом, сообщение «строка не обнаружена» может привести к неверному пониманию, что в тексте нет экземпляров по запрошенному шаблону поиска. Часто я наблюдал, что в этом случае пользователи несколько раз запускали поиск повторно, т. к. ясно помнили, что видели такой экземпляр в тексте, и не понимали, почему поиск заканчивается безрезультатно. Может пройти несколько секунд или даже минут, прежде чем пользователь догадается, в чем состоит проблема, или же так и останется в недоумении. Если необходимо иметь разные виды поиска, можно избежать использования режимов, предусмотрев для каждого вида поиска соответствующую команду или экранную кнопку для запуска.
Во многих случаях модальности можно избежать с помощью набора кнопок для запуска каждого вида поиска. Такой набор может быть предусмотрен вместо окна установки параметров поиска, снабженного одной-единственной кнопкой запуска поиска по заданным условиям. Такой подход позволяет не только устранить модальность, но и сократить число нажатий. Кроме того, в локусе внимания пользователя в этом случае находится задача, которую он хочет выполнить, а не настройки для ее выполнения. На рис. 5.5 показано типичное диалоговое окно с настройками и кнопкой запуска, которое используется в Microsoft Word. Из рисунка видно, что с диалоговыми окнами этого типа связана и другая проблема: должны ли кнопки переключателя всегда находиться в указанном положении при открытии окна? Должны ли они быть в положении, в котором пользователь оставил их при последнем использовании? Или же они должны быть в некотором положении, установленном пользователем по умолчанию?
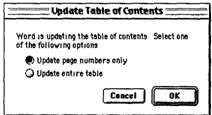 Рис. 5.5. Диалоговое окно, снабженное кнопками для соответствующего типа поиска и одной кнопкой запуска
Рис. 5.5. Диалоговое окно, снабженное кнопками для соответствующего типа поиска и одной кнопкой запуска
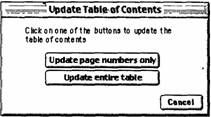 Рис. 5.6. Более эффективное диалоговое окно с несколькими кнопками запуска
Рис. 5.6. Более эффективное диалоговое окно с несколькими кнопками запуска
Все три варианта являются ошибочными. Если пользователь всегда обновляет оглавление полностью, то при первом варианте ему придется делать каждый раз по два щелчка мышью (или один щелчок и одно нажатие на кнопку «Return»). Если переключатель остается в том положении, в котором окно использовалось последний раз, пользователь не сможет пользоваться этим окном привычным образом, поскольку каждый раз ему придется останавливаться и проверять, в каком положении переключатель находится. Если же переключатель может устанавливаться пользователем в положение по умолчанию (см. раздел 3.2.2), то тем самым включается режим.
Диалоговое окно, изображенное на рис. 5.6, позволяет решить сразу все эти проблемы. Кроме того, по закону Фитса кнопки большого размера имеют преимущество по сравнению с набором переключателей. Если такое окно сделать прозрачным, то можно также отказаться от использования кнопки «Cancel» (см. раздел 5.2.3). В этом случае используемые две кнопки не должны быть прозрачными, чтобы пользователь мог видеть, что они являются активными.
Диалоговые окна для поиска с разделителями обычно снабжены устройством для сохранения текущего шаблона сразу после обнаружения последнего экземпляра. Такое устройство можно назвать «искать еще» или «найти далее». В некоторых вариантах оно запускается с помощью той же кнопки, которая использовалась для начального поиска. Если поиск является пошаговым, то команда для повторного поиска того же объекта является необходимой, поскольку в этом варианте нет никакой команды для запуска начального поиска. Применять для повторного поиска клавишу включения квазирежима «Search» не желательно, т. к. пользователь может нажать эту клавишу, а затем передумать и отпустить ее. В этом случае будет начат поиск, который пользователь не хотел запускать. В результате пользователь может потерять место в тексте, в котором он находился. Хотя использование системы глобального отката может исправить ситуацию, все же лучше вообще не создавать этой проблемы. Специальный метод для выполнения повторного поиска будет рассмотрен в разделе 5.6.
В больших по размеру текстах поиск может осуществляться по кругу (циклично) не только в локальном документе, но и далее, в автоматически расширяющихся областях вплоть до всего Интернета. [37]После того как поиск был выполнен по всему локальному документу, он может быть продолжен в отношении последующих документов папки, а затем перейти на начало первого документа папки и продолжиться до текущего, уже просмотренного документа. После циклического поиска внутри папки рассматривается следующая локальная область поиска и т. д. Если во время пошагового поиска, выполняемого таким образом, пользователь поймет, что процесс поиска слишком расширился, он может остановить его, убедившись, что в ближних областях искомого экземпляра нет. Текущую область поиска определить обычно легко, т. к. пользователь может видеть результаты поиска в своих контекстах, а не просто список файлов, как это делается во многих современных поисковых системах.
В общем случае пользователи будут применять более эффективные стратегии поиска, чем просто полагаться на такой метод автоматически расширяющегося поиска. Например, если вы ищете какой-то документ в текущей папке, то, скорее всего, вы станете искать символы документов, чтобы быстро просмотреть начало или заголовок каждого документа. Если нужный документ обнаружен, запускается пошаговый поиск в отношении целевого объекта. Таким образом, обеспечивается порядок, по которому поиск производится в первую очередь в выбранном документе, что позволяет применять более короткий шаблон на меньшей площади поиска. Если же вы не знаете, в каком документе искомый объект находится, или если вы не хотите искать с начала документа, вы можете применить сплошной поиск, который в любом случае обнаружит искомый объект.
Взаимодействие посредством последовательного ввода строки текста, т. е. строки, отделенной знаком Return, – это пережиток времен телетайпа, который должен быть передан в музеи вместе с оборудованием того времени. [36]Сегодня мы можем и должны иметь возможность пользоваться интерфейсами, способными реагировать на каждый вводимый символ во всех случаях, когда такая реакция может улучшить качество взаимодействия. Как и всегда, разработчики должны быть внимательны – например, посимвольное взаимодействие не должно приводить к выдаче сообщений об орфографических ошибках в середине набора слова, что может усложнить работу пользователя, владеющего слепым методом набора.
В маленьких текстах, для которых поиск строк был изначально придуман, он обычно проходил от текущей позиции курсора до конца текста. В текстах большего размера в случае, если до конца документа искомый объект так и не был обнаружен, обычно удобнее продолжить поиск с начала документа до позиции курсора, если пользователь забыл, что искомый объект находится выше. Неопубликованное тестирование, проведенное в компании Information Appliance, показало, что если поиск производится быстро, то цикличный поиск оказывается особенно удобным. «Быстрый» означает здесь, что между запуском поиска и его успешным либо неуспешным окончанием не остается времени на действия пользователя. Как правило, это время составляет порядка 250 мс. Во многих системах пользователь может выбрать, каким образом будет проходить поиск – либо циклично (по кругу), либо с остановкой в конце документа. Это порождает типичную проблему модальности. Если установлен нецикличный поиск, и пользователь не знает об этом, сообщение «строка не обнаружена» может привести к неверному пониманию, что в тексте нет экземпляров по запрошенному шаблону поиска. Часто я наблюдал, что в этом случае пользователи несколько раз запускали поиск повторно, т. к. ясно помнили, что видели такой экземпляр в тексте, и не понимали, почему поиск заканчивается безрезультатно. Может пройти несколько секунд или даже минут, прежде чем пользователь догадается, в чем состоит проблема, или же так и останется в недоумении. Если необходимо иметь разные виды поиска, можно избежать использования режимов, предусмотрев для каждого вида поиска соответствующую команду или экранную кнопку для запуска.
Во многих случаях модальности можно избежать с помощью набора кнопок для запуска каждого вида поиска. Такой набор может быть предусмотрен вместо окна установки параметров поиска, снабженного одной-единственной кнопкой запуска поиска по заданным условиям. Такой подход позволяет не только устранить модальность, но и сократить число нажатий. Кроме того, в локусе внимания пользователя в этом случае находится задача, которую он хочет выполнить, а не настройки для ее выполнения. На рис. 5.5 показано типичное диалоговое окно с настройками и кнопкой запуска, которое используется в Microsoft Word. Из рисунка видно, что с диалоговыми окнами этого типа связана и другая проблема: должны ли кнопки переключателя всегда находиться в указанном положении при открытии окна? Должны ли они быть в положении, в котором пользователь оставил их при последнем использовании? Или же они должны быть в некотором положении, установленном пользователем по умолчанию?
Все три варианта являются ошибочными. Если пользователь всегда обновляет оглавление полностью, то при первом варианте ему придется делать каждый раз по два щелчка мышью (или один щелчок и одно нажатие на кнопку «Return»). Если переключатель остается в том положении, в котором окно использовалось последний раз, пользователь не сможет пользоваться этим окном привычным образом, поскольку каждый раз ему придется останавливаться и проверять, в каком положении переключатель находится. Если же переключатель может устанавливаться пользователем в положение по умолчанию (см. раздел 3.2.2), то тем самым включается режим.
Диалоговое окно, изображенное на рис. 5.6, позволяет решить сразу все эти проблемы. Кроме того, по закону Фитса кнопки большого размера имеют преимущество по сравнению с набором переключателей. Если такое окно сделать прозрачным, то можно также отказаться от использования кнопки «Cancel» (см. раздел 5.2.3). В этом случае используемые две кнопки не должны быть прозрачными, чтобы пользователь мог видеть, что они являются активными.
Диалоговые окна для поиска с разделителями обычно снабжены устройством для сохранения текущего шаблона сразу после обнаружения последнего экземпляра. Такое устройство можно назвать «искать еще» или «найти далее». В некоторых вариантах оно запускается с помощью той же кнопки, которая использовалась для начального поиска. Если поиск является пошаговым, то команда для повторного поиска того же объекта является необходимой, поскольку в этом варианте нет никакой команды для запуска начального поиска. Применять для повторного поиска клавишу включения квазирежима «Search» не желательно, т. к. пользователь может нажать эту клавишу, а затем передумать и отпустить ее. В этом случае будет начат поиск, который пользователь не хотел запускать. В результате пользователь может потерять место в тексте, в котором он находился. Хотя использование системы глобального отката может исправить ситуацию, все же лучше вообще не создавать этой проблемы. Специальный метод для выполнения повторного поиска будет рассмотрен в разделе 5.6.
В больших по размеру текстах поиск может осуществляться по кругу (циклично) не только в локальном документе, но и далее, в автоматически расширяющихся областях вплоть до всего Интернета. [37]После того как поиск был выполнен по всему локальному документу, он может быть продолжен в отношении последующих документов папки, а затем перейти на начало первого документа папки и продолжиться до текущего, уже просмотренного документа. После циклического поиска внутри папки рассматривается следующая локальная область поиска и т. д. Если во время пошагового поиска, выполняемого таким образом, пользователь поймет, что процесс поиска слишком расширился, он может остановить его, убедившись, что в ближних областях искомого экземпляра нет. Текущую область поиска определить обычно легко, т. к. пользователь может видеть результаты поиска в своих контекстах, а не просто список файлов, как это делается во многих современных поисковых системах.
В общем случае пользователи будут применять более эффективные стратегии поиска, чем просто полагаться на такой метод автоматически расширяющегося поиска. Например, если вы ищете какой-то документ в текущей папке, то, скорее всего, вы станете искать символы документов, чтобы быстро просмотреть начало или заголовок каждого документа. Если нужный документ обнаружен, запускается пошаговый поиск в отношении целевого объекта. Таким образом, обеспечивается порядок, по которому поиск производится в первую очередь в выбранном документе, что позволяет применять более короткий шаблон на меньшей площади поиска. Если же вы не знаете, в каком документе искомый объект находится, или если вы не хотите искать с начала документа, вы можете применить сплошной поиск, который в любом случае обнаружит искомый объект.
5.5. Форма курсора и методы выделения
Цель как поиска с ограничителями, так и пошагового поиска строки обычно заключается в том, чтобы обнаружить в тексте некоторую строку и выделить ее. Пользователи стараются использовать как можно более короткие последовательности в шаблонах поиска, т. к. длинные последовательности трудно набирать, и в большинстве систем они должны быть набраны с точностью до каждого символа, чтобы соответствовать целевому объекту. Поэтому поиск строки обычно не применяется для выделения даже средних по размеру целевых объектов, длина которых больше, чем 10–15 символов, не говоря уже о действительно больших блоках текста. Поиск строки применяется для того, чтобы помочь пользователю обнаружить место, где расположена искомая выборка, после чего пользователь может применить уже другой метод для обозначения этой выборки (например, использовать ГУВ для перемещения курсора от одного конца выборки до другого). Однако, если края выборки нельзя видеть одновременно, следует использовать другой метод. Он состоит из следующих шагов: (1) обозначение одного края выборки с помощью той техники, которая используется в данной системе; (2) сделать видимым другой край выборки с помощью полос прокрутки; (3) обозначить другой край выборки. В большинстве систем обозначение второго края выборки позволяет выделить всю выборку.
Более эффективный подход заключается в том, чтобы создать такой механизм поиска, который позволили бы размещать курсор на конкретном символе. Два таких размещения курсора можно использовать для обозначения первого и последнего символа выборки. Таким образом, все множество механизмов, обычно используемых для поиска краев выборки (а именно: перемещение курсора, прокрутка, различные механизмы поиска страниц, поиска по шаблону и т. д.) и их обозначения заменяются одним механизмом, который используется два раза, что упрощает процесс изучения, использования и формирования привычек, а также упрощает внедрение.
Рассмотрим теперь графическую форму курсоров. В настоящее время наиболее распространенной формой текстовых курсоров является курсор, который помещается между символами, как это показано на рис. 5.7. Одной из проблем стандартного текстового курсора является то, что пользователи пытаются поместить его точно между символами, целясь на небольшой горизонтальный объект, который по размеру меньше, чем требуемый, что в соответствии с законом Фитса приводит к временным затратам. Кроме того, во время тестирований, проведенных в компании Information Appliance, мы с удивлением обнаружили, что эта распространенная форма курсора создает интересную когнитивную проблему, состоящую в том, что пользователь должен располагать курсор по-разному, в зависимости от того, какое действие он собирается совершить далее. В частности, чтобы удалить существующий символ с помощью клавиши «Backspace», требуется разместить курсор справа от символа (в английском или любом другом языке, который читается слева направо). Чтобы вставить какой-то символ рядом с существующим символом, необходимо поместить курсор слева от существующего символа (в этом случае существующий символ сдвинется вправо). Наше удивление было связано с тем, что использование стандартного курсора хорошо знакомо каждому пользователю, и поэтому никто не мог подумать, что курсор можно было бы рассматривать как потенциальный источник проблем.
Более эффективный подход заключается в том, чтобы создать такой механизм поиска, который позволили бы размещать курсор на конкретном символе. Два таких размещения курсора можно использовать для обозначения первого и последнего символа выборки. Таким образом, все множество механизмов, обычно используемых для поиска краев выборки (а именно: перемещение курсора, прокрутка, различные механизмы поиска страниц, поиска по шаблону и т. д.) и их обозначения заменяются одним механизмом, который используется два раза, что упрощает процесс изучения, использования и формирования привычек, а также упрощает внедрение.
Рассмотрим теперь графическую форму курсоров. В настоящее время наиболее распространенной формой текстовых курсоров является курсор, который помещается между символами, как это показано на рис. 5.7. Одной из проблем стандартного текстового курсора является то, что пользователи пытаются поместить его точно между символами, целясь на небольшой горизонтальный объект, который по размеру меньше, чем требуемый, что в соответствии с законом Фитса приводит к временным затратам. Кроме того, во время тестирований, проведенных в компании Information Appliance, мы с удивлением обнаружили, что эта распространенная форма курсора создает интересную когнитивную проблему, состоящую в том, что пользователь должен располагать курсор по-разному, в зависимости от того, какое действие он собирается совершить далее. В частности, чтобы удалить существующий символ с помощью клавиши «Backspace», требуется разместить курсор справа от символа (в английском или любом другом языке, который читается слева направо). Чтобы вставить какой-то символ рядом с существующим символом, необходимо поместить курсор слева от существующего символа (в этом случае существующий символ сдвинется вправо). Наше удивление было связано с тем, что использование стандартного курсора хорошо знакомо каждому пользователю, и поэтому никто не мог подумать, что курсор можно было бы рассматривать как потенциальный источник проблем.