ПРИМЕЧАНИЕ Для упрощения восприятия материала в тексте и на схемах в этой главе группа обозначается как сущность, содержащая VCN, LCN и длину группы. Ho на самом деле NTFS сжимает эту информацию на диске в пары «LCN – следующий VCN». Зная начальный VCN, NTFS может определить длину группы простым вычитанием начального VCN из следующего VCN.
B процессе работы системы NTFS ведет запись в другой важный файл метаданных – файл журналас именем $LogFile. NTFS использует его для регистрации всех операций, влияющих на структуру тома NTFS, в том числе для регистрации создания файлов и выполнения любых команд вроде Сору,модифицирующих структуру каталогов. Файл журнала используется и при восстановлении тома NTFS после аварии системы.
Еще один элемент MFT зарезервирован для корневого каталога (также обозначаемого как «\»). Его запись содержит индекс файлов и каталогов, хранящихся в корне структуры каталогов NTFS. Когда NTFS впервые получает запрос на открытие файла, она начинает его поиск с записи корневого каталога. Открыв файл, NTFS сохраняет файловую ссылку MFT для этого файла и поэтому в следующий раз, когда понадобится считать или записать тот же файл, сможет напрямую обратиться к его записи в MFT.
NTFS регистрирует распределение дискового пространства в файле битовой карты(bitmap file) с именем $Bitmap. Атрибут данных для файла битовой карты содержит битовую карту, каждый бит которой представляет кластер тома и сообщает, свободен кластер или выделен.
Файл защиты(security file) с именем $Secure хранит базу данных дескрипторов защиты, действующих в пределах тома. Дескрипторы защиты файлов и каталогов NTFS можно настраивать индивидуально, но для экономии места NTFS хранит настройки дескрипторов защиты в общем файле, который позволяет файлам и каталогам с одинаковыми параметрами защиты ссылаться на один и тот же дескриптор защиты. Такая оптимизация дает существенную экономию в большинстве сред, потому что в них целые деревья каталогов имеют одинаковые параметры защиты.
Другой системный файл, загрузочный(boot file), с именем $Boot хранит код начальной загрузки Windows. Для успешного запуска системы код начальной загрузки должен находиться на диске в определенном месте. При форматировании команда formatопределяет это место в виде файла, создавая для него запись в MFT. При этом NTFS следует своим правилам, согласно которым все данные хранятся на диске в виде файлов. Загрузочный файл, как и файлы метаданных NTFS, может быть защищен индивидуальным дескриптором защиты. B такой модели «на диске есть только файлы» код начальной загрузки может быть изменен путем обычного файлового ввода-вывода, хотя загрузочный файл защищен от редактирования.
NTFS поддерживает файл плохих кластеров(bad-cluster file) с именем $BadClus, в котором регистрируются все сбойные участки дискового тома, и файл тома(volume file) с именем $Volume, который содержит имя тома, версию NTFS, под которую отформатирован том, и бит, устанавливаемый при каком-либо повреждении диска. Если этот бит установлен, диск должен быть восстановлен утилитой Chkdsk. Файл сопоставления имен с буквами в верхнем регистре(uppercase file) с именем $UpCase включает таблицу трансляции букв между верхним и нижним регистрами. NTFS также поддерживает файл, содержащий таблицу определения атрибутов(attribute definition table), с именем IAttrDef; в нем определяются типы атрибутов, поддерживаемые томом, и указывается, являются ли они индексируемыми, следует ли их восстанавливать в ходе операции восстановления системы и т. д.
Некоторые файлы метаданных NTFS хранит в каталоге расширенных метаданных $Extend, в том числе помещая туда файл идентификаторов объектов($ObjId), файл квот($Quota), файл журнала регистрации изменений($UsnJrnl) и файл точек повторного разбора($Reparse). B этих файлах содержится информация, относящаяся к дополнительным возможностям NTFS. Файл идентификаторов объектов хранит идентификаторы объектов «файл», файл квот – значения квот и информацию о поведении томов, на которых используются квоты, файл точек повторного разбора – список файлов и каталогов, включающих данные точек повторного разбора, а в файле журнала изменений регистрируются изменения файлов и каталогов.
ЭКСПЕРИМЕНТ: просмотр информации NTFS
Для просмотра информации о NTFS-томе, в том числе о размещении и размере MFT и зоны MFT, вы можете использовать в Windows 2000 утилиту NTFSInfo (с сайта wwwsysinternals.com ),а в Windows XP или Windows Server 2003 – встроенную программу командной строки Fsutil.exe:
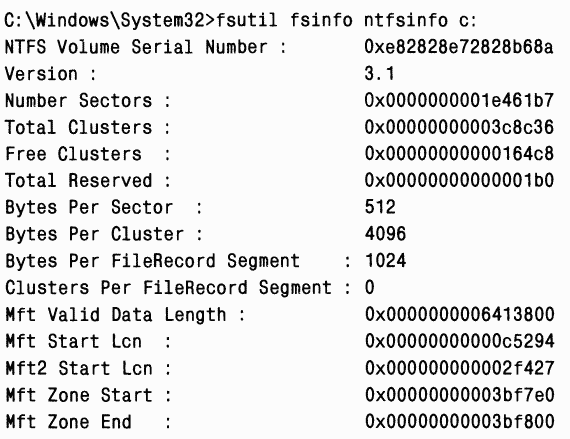
Структура файловых ссылок
Файл на томе NTFS идентифицируется 64-битным значением, которое называется файловой ссылкой(file reference). Файловая ссылка состоит из номера файла и номера последовательности. Номер файла равен позиции его записи в MFT минус 1 (или позиции базовой записи в MFT минус 1, если файл требует несколько записей). Номер последовательности в файловой ссылке увеличивается на 1 при каждом повторном использовании позиции записи в MFT, что позволяет NTFS проверять внутреннюю целостность файловой системы. Файловую ссылку иллюстрирует рис. 12-25.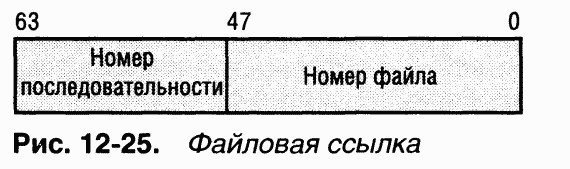
Записи о файлах
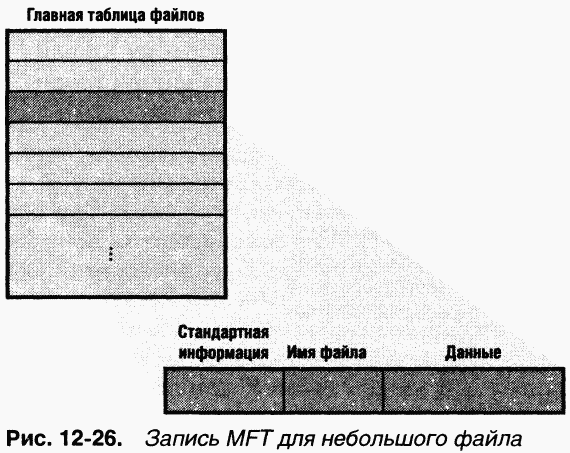
NTFS рассматривает файл не просто как хранилище текстовых или двоичных данных, а как совокупность пар атрибутов и их значений, одна из которых содержит данные файла (соответствующий атрибут называется неименованным атрибутом данных).Другие атрибуты включают имя файла,метку времени и, возможно, дополнительные именованные атрибуты данных. Запись МFТдля небольшого файла показана на рис. 12-26.
B таблице 12-4 перечислены атрибуты для файлов на томах NTFS (не у каждого файла есть все эти атрибуты).


Каждый атрибут в записи о файле идентифицируется кодом типа атрибута, имеет значение и необязательное имя. Значение атрибута представляет собой байтовый поток. Так, значением атрибута $FILENAME является имя файла, значением атрибута $DATA – произвольный набор байтов, сохраненный пользователем в файле.
У большинства атрибутов нет имен, хотя у $DATA и атрибутов, связанных с индексом, они обычно есть. Имена позволяют различать атрибуты файла, относящиеся к одному типу. Например, в файле с именованным потоком данных есть два атрибута $DATA: неименованный атрибут $DATA, хранящий неименованный по умолчанию поток данных, и именованный атрибут $DATA с именем дополнительного потока данных.
Имена файлов
NTFS и FAT допускают длину каждого имени файла в пути до 255 символов. Эти имена могут содержать Unicode-символы, точки и пробелы. Однако длина имен файлов в FAT, встроенной в MS-DOS, ограничена 8 символами (не-Unicode), за которыми следует расширение из трех символов, отделенное точкой. Рис. 12-27 иллюстрирует различные пространства имен файлов, поддерживаемые Windows, и показывает, как они перекрываются.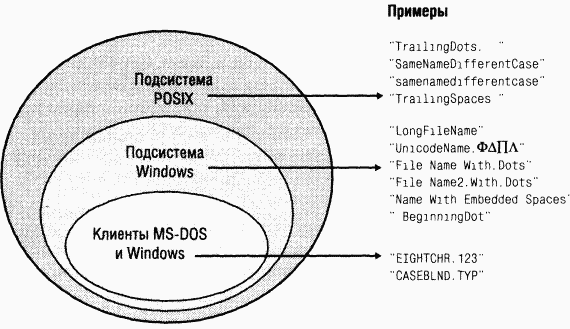
POSIX требует самого большого пространства имен из всех подсистем, поддерживаемых Windows. Поэтому пространство имен NTFS эквивалентно пространству имен POSIX. Подсистема POSIX может создавать имена, невидимые приложениям Windows и MS-DOS, в том числе имена с концевыми точками и концевыми пробелами. Создание файла в большом пространстве имен POSIX обычно не является проблемой, потому что вы создаете такой файл для использования подсистемой POSIX или ее клиентской системой.
Ho взаимосвязь между 32-разрядными Windows-приложениями и программами MS-DOS и 16-разрядной Windows намного теснее. Область, отведенная Windows на рис. 12-26, представляет имена файлов, которые подсистема Windows может создавать на томе NTFS, хотя такие имена невидимы программам MS-DOS и 1б-разрядной Windows. B эту группу входят имена файлов, не соответствующие формату «8.3» (длинные имена, имена с Unicode-символами, с несколькими точками или начинающиеся с точки, а также имена с внутренними пробелами). При создании файла с таким именем NTFS автоматически генерирует для него альтернативное имя в стиле MS-DOS. Windows показывает такие имена при использовании команды dirс ключом /x.
Имена MS-DOS – полнофункциональные псевдонимы файлов NTFS и хранятся в том же каталоге, что и длинные имена. Ha рис. 12-28 показана запись MFT для файла с автоматически сгенерированным MS-DOS-именем.
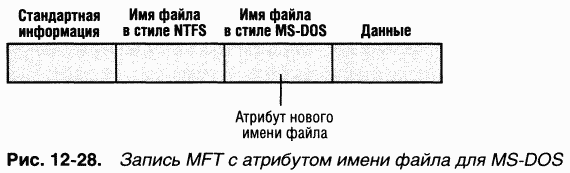
ПРИМЕЧАНИЕ Аналогичным образом реализуются жесткие связи POSIX. При создании жесткой связи с POSIX-файлом NTFS добавляет в запись MFT дополнительный атрибут имени файла. Однако эти две ситуации имеют одно отличие. Когда пользователь удаляет файл PO-SIX, у которого было несколько имен (жестких связей), запись о файле и сам файл остаются. Файл и его запись удаляются только после удаления последнего имени (жесткой связи). Если у файла есть и имя NTFS, и автоматически сгенерированное имя MS-DOS, пользователь может удалить файл по любому из этих имен.
Вот алгоритм, применяемый NTFS при генерации краткого MS-DOS-имени из длинного.
1. Удалить из длинного имени все символы, недопустимые в именах MS-DOS, включая пробелы и Unicode-символы. Удалить начальную и концевую точки, а также все внутренние точки, кроме последней.
2. Урезать часть строки перед точкой (если она есть) до шести символов и добавить строку «~n» (где n –порядковый номер, который начинается с 1; он нужен, чтобы различать файлы, урезание имен которых дает одинаковый результат). Урезать строку после точки (если она есть) до трех символов.
3. Преобразовать полученный набор символов в верхний регистр. MS-DOS нечувствительна к регистру букв в именах файлов, но эта операция гарантирует, что NTFS не сгенерирует для файла новое имя, отличающееся от старого лишь регистром.
4. Если сгенерированное имя дублирует уже имеющееся в каталоге, увеличить порядковый номер в строке «~n» на 1 (или на большее значение).
B таблице 12-5 показаны длинные имена файлов с рис. 12-26 и их MS-DOS-версии, сгенерированные NTFS. Приведенный выше алгоритм и примеры на рис. 12-26 должны дать вам представление об именах в стиле MS-DOS, генерируемых NTFS.
ПРИМЕЧАНИЕ Вы можете отключить генерацию кратких имен, присвоив параметру реестра HKLM\System\CurrentControlSet\Control\FileSystem\ NtfsDisable8dot3NameCreation значение типа DWORD, равное 1, хотя обычно это не рекомендуется (из-за вероятной несовместимости приложений, которые полагаются на такую функциональность).

Резидентные и нерезидентные атрибуты
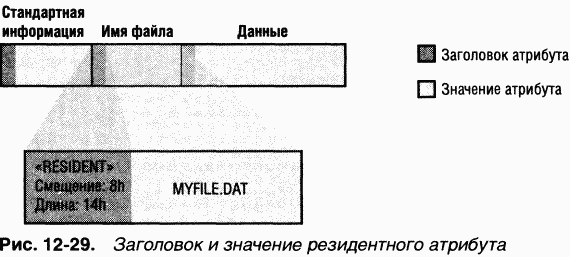
Если файл невелик, все его атрибуты и их значения (например, файловые данные) умещаются в одной записи файла. Когда значение атрибута хранится непосредственно в MFT, атрибут называется резидентный(например, все атрибуты на рис. 12-27 являются резидентными). Некоторые атрибуты всегда резидентны – по ним NTFS находит нерезидентные атрибуты. Так, атрибуты «стандартная информация» и «корень индекса» всегда резидентны.Каждый атрибут начинается со стандартного заголовка, в котором содержится информация об атрибуте, используемая NTFS для базового управления атрибутами. B заголовке, который всегда является резидентным, регистрируется, резидентно ли значение данного атрибута. B случае резидентных атрибутов заголовок также содержит смещение значения атрибута от начала заголовка и длину этого значения (рис. 12-29).
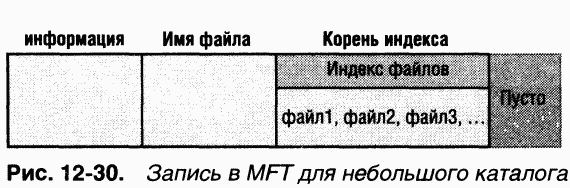
Как видно из рис. 12-30, атрибуты небольшого каталога, а также небольшого файла, могут быть резидентными в MFT Для небольшого каталога атрибут «корень индекса» содержит индекс файловых ссылок на файлы и подкаталоги этого каталога.
B случае нерезидентного атрибута (им может быть атрибут данных большого файла) в его заголовке содержится информация, нужная NTFS для поиска значения атрибута на диске. Ha рис. 12-31 показан нерезидентный атрибут данных, хранящийся в двух группах.
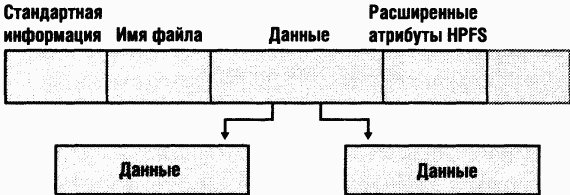
Среди стандартных атрибутов нерезидентными бывают лишь те, чей размер может увеличиваться. Для файлов такими атрибутами являются данные и список атрибутов (не показанный на рис. 12-31). Атрибуты «стандартная информация» и «имя файла» всегда резидентны.
B большом каталоге также могут быть нерезидентные атрибуты (или части атрибутов), как видно из рис. 12-32. B этом примере в записи MFT не хватает места для хранения индекса файлов, составляющих этот большой каталог. Часть индекса хранится в атрибуте корня индекса, а остальное – в нерезидентных группах, называемых индексными буферами(index buffers). Атрибуты корня индекса, выделенной группы индексов (index allocation) и битовой карты показаны здесь в упрощенной форме (подробнее о них см. следующий раздел). Атрибуты стандартной информации и имени файла всегда резидентны. Заголовок и по крайней мере часть значения атрибута корня индекса в случае каталогов также резидентны.
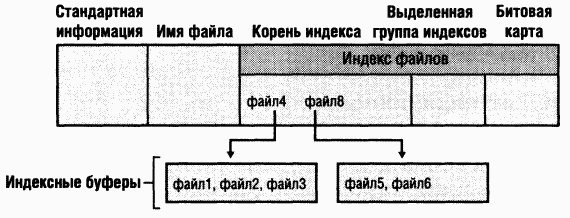
Когда атрибуты файла (или каталога) не умещаются в записи MFT и для них требуется отдельное место, NTFS отслеживает выделяемые группы посредством пар сопоставлений VCN-LCN. LCN представляют последовательность кластеров на всем томе, пронумерованных от 0 до n.VCN нумеруют от 0 до mтолько кластеры, принадлежащие конкретному файлу. Пример нумерации кластеров в группах нерезидентного атрибута данных приведен на рис. 12-33.
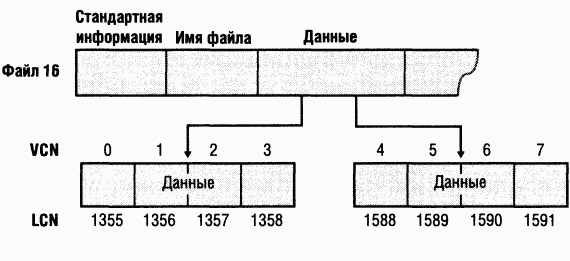
Если бы этот файл занимал больше двух групп, нумерация в третьей группе началась бы с VCN 8. Как показано на рис. 12-34, заголовок атрибута данных содержит сопоставления VCN-LCN для обоих групп, что позволяет NTFS легко находить выделенные под них области на диске.
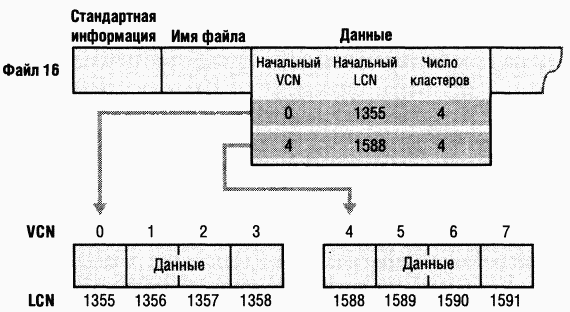
Хотя на рис. 12-33 показаны только группы данных, в группах могут храниться и другие атрибуты, если они не умещаются в записи MFT Когда у файла так много атрибутов, что они не умещаются в записи MFT, для хранения дополнительных атрибутов (или заголовков в случае нерезидентных атрибутов) используется вторая запись MFT При этом добавляется атрибут, называемый списком ampuбymoe(attribute list). Список атрибутов содержит имя и код типа каждого атрибута файла, а также файловую ссылку на запись MFT, в которой находится данный атрибут. Атрибут «список атрибутов» предназначен для тех случаев, когда файл становится настолько большим или фраг-ментированным, что одной записи MFT уже недостаточно для хранения большого объема сведений о сопоставлениях VCN-LCN, нужных для поиска всех групп. Список атрибутов обычно нужен файлам, у которых более 200 групп.
Сжатие данных и разреженные файлы
NTFS поддерживает сжатие по отдельным файлам, по каталогам и по томам (NTFS сжимает только пользовательские данные, не трогая метаданные файловой системы). Выяснить, сжат ли том, можно через Windows-функцию GetVolumeInformation.Чтобы получить реальный размер сжатого файла, используйте Windows-функцию GetCompressedFileSize.Наконец, проверить или изменить параметры сжатия для файла или каталога позволяет Windows-функция DeviceIoControl(см. управляющие коды файловой системы FSCTL_ GET_COMPRESSION и FSCT_SET_COMPRESSION в описании этой функции в Platform SDK). Учтите, что изменение степени сжатия применительно к файлу выполняется немедленно, а применительно к каталогу или тому – нет. Bo втором случае степень сжатия, заданная для каталога или тома, становится степенью сжатия по умолчанию для всех новых файлов и подкаталогов, создаваемых в каталоге или на томе.Следующий раздел является введением в сжатие данных в NTFS на примере простого случая компрессии разреженных данных. После него мы обсудим сжатие обычных и разреженных файлов.
Сжатие разреженных данных
Разреженными(sparse) называются данные (часто большого размера), в которых лишь малая часть отлична от нулевых значений. Пример разреженных данных – разреженная матрица. Как уже говорилось, для обозначения кластеров файла NTFS использует виртуальные номера кластеров (VCN) – от 0 до m. Каждый VCN соответствует логическому номеру кластера (LCN), который определяет местонахождение кластера на диске. Ha рис. 12-35 показаны группы (занимаемые участки дискового пространства) обычного (несжатого файла), а также их VCN и LCN.
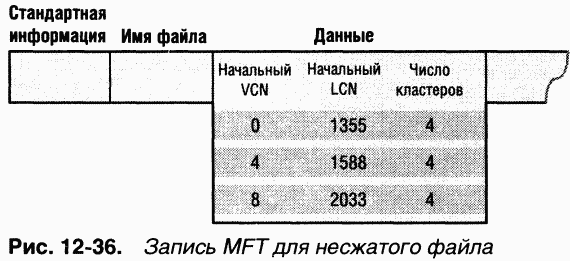
Ha рис. 12-37 изображены группы сжатого разреженного файла. Обратите внимание на то, что для некоторых диапазонов VCN файла (16-31 и 64-127) дисковое пространство не выделено.

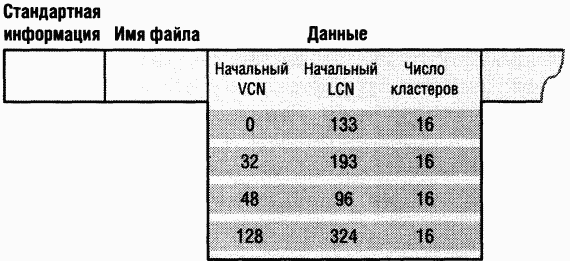
Когда программа читает данные из сжатого файла, NTFS проверяет запись MFT, чтобы выяснить, имеется ли сопоставление VCN-LCN для считываемого участка файла. Если программа обращается в невыделенную «дыру» в файле, значит, данные этой части файла состоят из нулей, и тогда NTFS возвращает нули, не обращаясь к диску. Если программа записывает в «дыру» ненулевые данные, NTFS автоматически выделяет дисковое пространство и записывает туда эти данные. Такой метод очень эффективен для разреженных файлов, содержащих много нулевых данных.
Сжатие неразреженных данных
Предыдущий пример сжатия разреженного файла довольно надуманный. Он описывает «сжатие» в том случае, когда целые области файла заполнены нулями, но на остальные файловые данные сжатие не оказывает никакого влияния. B большинстве файлов данные не являются разреженными, тем не менее их можно компрессировать по какому-нибудь алгоритму сжатия.B NTFS пользователи могут сжимать отдельные файлы или все файлы в каталоге. (Новые файлы, создаваемые в сжатом каталоге, сжимаются автоматически. Файлы, существовавшие в каталоге до его сжатия, должны быть сжаты индивидуально.) Сжимая файл, NTFS разбивает его необработанные данные на единицы сжатия(compression units) длиной по 16 кластеров. Некоторые последовательности данных в файле могут сжиматься недостаточно сильно или вообще не сжиматься, поэтому для каждой единицы сжатия NTFS определяет, будет ли при ее сжатии получен выигрыш хотя бы в один кластер. Если сжатие не позволяет освободить даже один кластер, NTFS выделяет 16-кластерную группу и записывает единицу сжатия на диск, не компрессируя ее данные. Если же данные можно сжать до 15 или менее кластеров, NTFS выделяет на диске ровно столько кластеров, сколько нужно для хранения сжатых данных, после чего записывает данные на диск. Рис. 12-39 иллюстрирует сжатие файла, состоящего из четырех групп. Незакрашенные области отражают дисковое пространство, которое файл будет занимать после сжатия. Первая, вторая и четвертая группы сжимаются, а третья – нет. Ho даже с одной несжатой группой достигается экономия 26 кластеров диска, т. е. длина файла уменьшается на 41%.

ПРИМЕЧАНИЕ Хотя на схемах, приведенных в этой главе, показаны непрерывные LCN, единицы сжатия не обязательно располагаются в физически смежных кластерах. Группы, занимающие несмежные кластеры, заставляют NTFS создавать несколько более сложные записи MFT, чем показанные на рис. 12-39 .
При записи данных в сжатый файл NTFS гарантирует, что каждая группа будет начинаться на виртуальной 16-кластерной границе. Таким образом, начальный VCN каждой группы кратен 16, и длина группы не превышает 16 кластеров. При работе со сжатым файлом NTFS единовременно считывает и записывает минимум одну единицу сжатия. Ho при записи сжатых данных NTFS пытается помещать единицы сжатия в физически смежные области, так чтобы их можно было считывать в ходе одной операции ввода-вывода. Размер единицы сжатия в 16 кластеров выбран для уменьшения внутренней фрагментации: чем больше размер единицы сжатия, тем меньше дискового пространства нужно для хранения данных. Размер единицы сжатия, равный l6 кластерам, основан на компромиссе между минимизацией размера сжатых файлов и замедлением операций чтения для программ, использующих прямой (произвольный) доступ к содержимому файлов. При каждом промахе кэша приходится декомпрессировать эквивалент l6 кластеров (вероятность промаха кэша при прямом доступе к файлу выше, чем при последовательном). Ha рис. 12-40 представлена запись MFT для сжатого файла, показанного на рис. 12-39 .
Одно из различий между этим сжатым файлом и сжатым разреженным файлом из более раннего примера в том, что в данном случае три группы имеют длину менее 16 кластеров. Считывание этой информации из записи MFT позволяет NTFS определить, сжаты ли данные в этом файле. Каждая группа короче l6 кластеров содержит сжатые данные, которые NTFS должна разархивировать при первом чтении группы в кэш. Группа, длина которой равна точно 16 кластерам, не содержит сжатых данных, а значит, не требует декомпрессии.

NTFS размещает сжатый файл на диске по возможности в смежных областях. Как указывают LCN, первые две группы сжатого файла на рис. 12-38 являются физически смежными, равно как и две последних. Если две и более группы расположены последовательно, NTFS выполняет опережающее чтение с диска – как и в случае обычных файлов. Поскольку чтение и декомпрессия непрерывных файловых данных выполняются асинхронно и еще до того, как программа запросит эти данные, то в последующих операциях чтения информация извлекается непосредственно из кэша, что значительно ускоряет процесс чтения.