Сервис файла журнала
Сервис файла журнала (log file service, LFS) – это набор процедур режима ядра, локализованных в драйвере NTFS, который она использует для доступа к файлу журнала. Хотя LFS изначально был разработан для того, чтобы предоставлять средства протоколирования и восстановления более чем одному клиенту, он используется только NTFS. Вызывающая программа, в данном случае NTFS, передает LFS указатель на открытый объект «файл», который определяет файл, выступающий в роли журнала. LFS либо инициализирует новый журнал, либо вызывает диспетчер кэша для доступа к существующему журналу через кэш, как показано на рис. 12-46.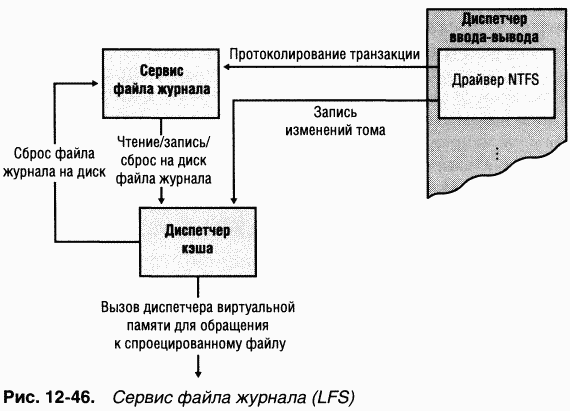
NTFS никогда не выполняет чтение/запись транзакций в журнал напрямую. LFS предоставляет сервисы, которые NTFS вызывает для открытия файла журнала, помещения в него записей, чтения записей из журнала в прямом и обратном порядке, сброса записей журнала до заданного LSN или установки логического начала журнала на больший LSN. B процессе восстановления NTFS вызывает LFS для чтения записей журнала в прямом направлении, чтобы повторить все транзакции, которые запротоколированы в журнале, но не записаны на диск в момент сбоя. NTFS также обращается к LFS для чтения записей в обратном направлении, чтобы отменить (или откатить) все транзакции, не полностью запротоколированные перед аварией системы, и установить начало файла журнала на запись с большим LSN после того, как старые записи журнала стали не нужны.
Вот как система обеспечивает восстановление тома.
1. Сначала NTFS вызывает LFS для записи в кэшируемый файл журнала любых транзакций, модифицирующих структуру тома.
2. NTFS модифицирует том (также в кэше).
3. Диспетчер кэша сообщает LFS сбросить файл журнала на диск. (Этот сброс реализуется LFS путем обратного вызова диспетчера кэша с указанием страниц памяти, подлежащих выводу на диск; см. рис. 12-46.)
4. Сбросив на диск журнал транзакций, диспетчер кэша записывает на диск изменения тома (результаты операций над метаданными). Эта последовательность действий гарантирует: если завершить изменение файловой системы не удастся, соответствующие транзакции можно будет считать из журнала и либо повторить, либо отменить в процессе восстановления файловой системы.
Восстановление файловой системы начинается автоматически при первом обращении к дисковому тому после перезагрузки. NTFS проверяет, применялись ли к тому транзакции, запротоколированные в журнале до сбоя, и, если нет, повторяет их. NTFS гарантирует и отмену транзакций, не полностью запротоколированных до сбоя, так что вызываемые ими изменения не появятся на томе.
Типы записей журнала
LFS позволяет своим клиентам помещать в журналы транзакций записи любого типа. NTFS использует несколько типов записей, два из которых – записи модификации(update records) и записи контрольной точки(checkpoint records) – будут рассмотрены в этом разделе.Записи модификации
K ним относится большинство записей, которые NTFS помещает в журнал транзакций. Каждая такая запись содержит два вида информации.(o) Информация для повтора (redo information)Описывает, как вновь применить к дисковому тому одну подоперацию полностью запротоколированной транзакции, если сбой системы произошел до того, как транзакция была переписана из кэша на диск.
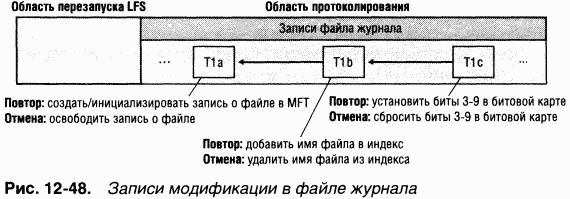
(o) Информация для отмены (undo information)Описывает, как обратить изменения, вызванные одной подоперацией транзакции, которая в момент сбоя была запротоколирована лишь частично. Ha рис. 12-48 показаны три записи модификации в файле журнала. Каждая запись представляет одну подоперацию транзакции, создающей новый файл. Информация для повтора в каждой записи модификации сообщает NTFS, как повторно применить данную подоперацию к дисковому тому, а информация для отмены – как откатить (отменить) эту подоперацию.
При восстановлении после сбоя системы NTFS просматривает журнал и повторяет все зафиксированные транзакции. Даже если NTFS и завершила транзакцию до момента сбоя системы, ей неизвестно, были ли изменения тома своевременно переписаны на диск диспетчером кэша. Модификации, выполненные в кэше, могли быть потеряны при сбое. Следовательно, NTFS выполняет зафиксированную транзакцию снова, чтобы гарантировать актуальность состояния диска.
После повтора всех зафиксированных транзакций NTFS отыскивает в журнале такие, которые не были зафиксированы к моменту сбоя, и откатывает каждую запротоколированную подоперацию. B случае, представленном на рис. 12-48, NTFS вначале должна была бы отменить подоперацию T1c, после чего перейти по указателям назад и отменить T1b. Переход по указателям в обратном направлении и отмена подопераций продолжались бы до тех пор, пока NTFS не достигла бы первой подоперации транзакции. Следуя указателям, NTFS определяет, сколько и какие записи модификации нужно отменить для того, чтобы откатить транзакцию.
Информация для повтора и отмены может быть выражена либо физически, либо логически. Физическое описание задает модификации тома как диапазоны байтов на диске, которые следует изменить, переместить и т. д., а логическое – представляет модификации в терминах операций, например «удалить файл A.dat». Как самый низкий уровень программного обеспечения, поддерживающего структуру файловой системы, NTFS использует записи модификации с физическими описаниями. Однако для программного обеспечения обработки транзакций и других приложений записи модификации в логическом виде могут быть удобнее, поскольку логическое представление обновлений тома компактнее физических. Логическое описание требует участия NTFS в выполнении действий, связанных с такими операциями, как удаление файла.
NTFS генерирует записи модификации (обычно несколько) для каждой из следующих транзакций:
(o)создание файла;
(o)удаление файла;
(o)расширение файла;
(o) урезаниефайла;
(o)установка файловой информации;
(o)переименование файла;
(o)изменение прав доступа к файлу
Информация для повтора и отмены в записи модификации должна быть очень точной, иначе при отмене транзакции, восстановлении после сбоя системы или даже в ходе нормальной работы NTFS может попытаться повторить транзакцию, которая уже выполнена, или, наоборот, отменить транзакцию, которая никогда не выполнялась либо уже отменена. Аналогичным образом NTFS может попытаться повторить или отменить транзакцию, включающую нескольких записей модификации, которые не все были применены к диску. Формат записей модификации должен гарантировать, что лишние операции повтора или отмены будут идемпотентными(idempo-tent), т. е. дадут нейтральный эффект. Например, установка уже установленного бита, не оказывает никакого действия, но изменение на противоположное значения бита, которое уже изменено, – оказывает. Файловая система также должна корректно обрабатывать переходные состояния тома.
Записи контрольной точки
Помимо записей модификации NTFS периодически помещает в файл журнала запись контрольной точки, как показано на рис. 12-49.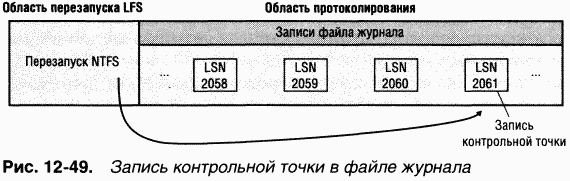
Хотя LFS представляет NTFS, будто журнал транзакций безразмерен, на самом деле он не бесконечен. Значительный размер журнала транзакций и частая вставка записей контрольной точки (операция, обычно освобождающая место в файле журнала) делают вероятность его переполнения достаточно малой. Тем не менее LFS учитывает такую возможность, отслеживая несколько значений:
(o)размер свободного пространства в журнале;
(o)размер пространства, необходимого для добавления в журнал следующей записи и для отмены этого действия (если это вдруг потребуется);
(o) размер пространства, нужного для отката всех активных (не зафиксированных) транзакций (если это вдруг потребуется).
Если в журнале не хватает места для суммы последних двух значений из списка, LFS сообщает об ошибке переполнения файла журнала, и NTFS генерирует исключение. Обработчик исключений NTFS откатывает текущую транзакцию и помещает ее в очередь для последующего перезапуска.
Чтобы освободить пространство в журнале транзакций, NTFS должна временно приостановить ввод-вывод в системе. Для этого она блокирует создание и удаление файлов, после чего запрашивает монопольный доступ ко всем системным файлам и разделяемый доступ ко всем пользовательским файлам. Постепенно активные транзакции либо завершаются успешно, либо вызывают исключение переполнения файла журнала. B последнем случае NTFS откатывает их, а затем помещает в очередь.
Заблокировав вышеописанным способом выполнение транзакций при операциях над файлами, NTFS вызывает диспетчер кэша для сброса на диск еще не записанных туда данных, в том числе данных файла журнала. После того как все успешно записано на диск, данные в журнале NTFS становятся ненужными. NTFS устанавливает начало журнала на текущую позицию, что делает журнал «пустым». Затем NTFS перезапускает транзакции, поставленные ранее в очередь. Так что за исключением короткой паузы в обработке ввода-вывода ошибка переполнения файла журнала не оказывает влияния на выполняемые программы.
Описанный сценарий – один из примеров того, как NTFS использует файл журнала не только для восстановления файловой системы, но и для исправления ошибок при нормальной работе.
Восстановление
NTFS автоматически выполняет восстановление диска при первом обращении к нему какой-либо программы после загрузки системы. (Если восстановление не требуется, весь процесс тривиален.) При восстановлении используются две таблицы, которые NTFS поддерживает в памяти.(o) Таблица транзакций(transaction table) – предназначена для отслеживания начатых, но еще не зафиксированных транзакций. B процессе восстановления результаты подопераций этих транзакций должны быть удалены с диска.
(o) Таблица измененных страниц(dirty page table) – в нее записывается информация о том, какие страницы кэша содержат изменения структуры файловой системы, еще не записанные на диск. Эти данные в процессе восстановления должны быть сброшены на диск.
Каждые 5 секунд NTFS добавляет в файл журнала транзакций запись контрольной точки. Непосредственно перед этим она обращается к LFS для сохранения в журнале текущей копии таблицы транзакций и таблицы измененных страниц. Затем NTFS запоминает в записи контрольной точки LSN записей журнала, содержащих копии таблиц. B начале процесса восстановления после сбоя NTFS обращается к LFS для поиска записей журнала транзакций, содержащих самую последнюю запись контрольной точки и самые последние копии упомянутых выше таблиц. Затем NTFS копирует эти таблицы в память.
Обычно за последней записью контрольной точки в журнале транзакций находится еще несколько записей модификации. Эти записи соответствуют обновлениям тома, произошедшим после того, как запись контрольной точки была помещена в журнал. NTFS должна обновить таблицу транзакций и таблицу измененных страниц, включив в них информацию из этих дополнительных записей. После обновления таблиц NTFS использует их, а также содержимое журнала транзакций для обновления собственно тома.
При восстановлении тома NTFS выполняет три прохода по журналу транзакций, загружая его в память на первом проходе, чтобы минимизировать объем дискового ввода-вывода. Каждый проход имеет свое назначение:
(o) анализ;
(o) повтор транзакций; (o) отмена транзакций.
Проход анализа
При проходе анализа(analysis pass) NTFS просматривает журнал транзакций в прямом направлении, начиная с последней операции контрольной точки, чтобы найти записи модификации и обновить скопированные ранее в память таблицы транзакций и измененных страниц. Обратите внимание, что операция контрольной точки помещает в журнал транзакций три записи, между которыми могут оказаться записи модификации (рис. 12-50). NTFS должна приступить к сканированию с начала операции контрольной точки.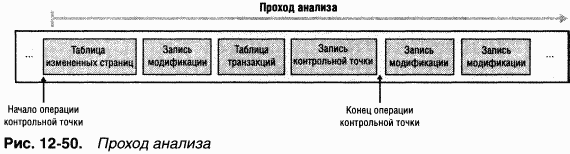
После того как таблицы в памяти приведены в актуальное состояние, NTFS просматривает их, чтобы определить LSN самой старой записи модификации, которая регистрирует операцию, не выполненную над диском. Таблица транзакций содержит LSN незафиксированных (незавершенных) транзакций, а таблица измененных страниц – LSN записей, соответствующих модификациям кэша, не отраженным на диске. LSN самой старой записи, найденной NTFS в этих двух таблицах, определяет, откуда начнется проход повтора. Однако, если последняя запись контрольной точки окажется более ранней, NTFS начнет проход повтора именно с нее.
Проход повтора
Ha проходе повтора(redo pass) NTFS сканирует журнал транзакций в прямом направлении, начиная с LSN самой старой записи, которая была обнаружена на проходе анализа (рис. 12-51). Она ищет записи модификации, относящиеся к обновлению страницы и содержащие модификации тома, которые были запротоколированы до сбоя системы, но не сброшены из кэша на диск. NTFS повторяет эти обновления в кэше.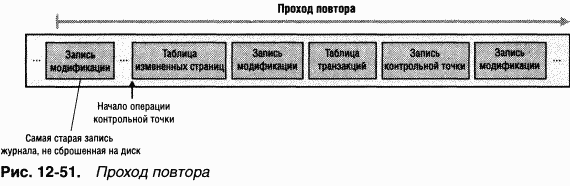
Проход отмены
Завершив проход повтора, NTFS начинает npoxoд отмены(undo pass), откатывая транзакции, не зафиксированные к моменту сбоя системы. Ha рис. 12-52 показаны две транзакции в журнале: транзакция 1 зафиксирована до сбоя системы, а транзакция 2 – нет. NTFS должна отменить транзакцию 2.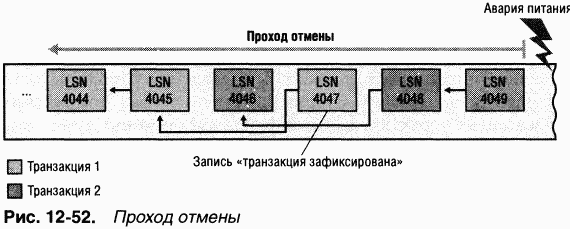
B таблице транзакций NTFS для каждой незавершенной транзакции хранится LSN записи модификации, помещенной в журнал последней. B данном примере таблица транзакций сообщает, что для транзакции 2 это запись с LSN 4049. NTFS выполняет откат транзакции 2, как показано на рис. 12-53 (справа налево).
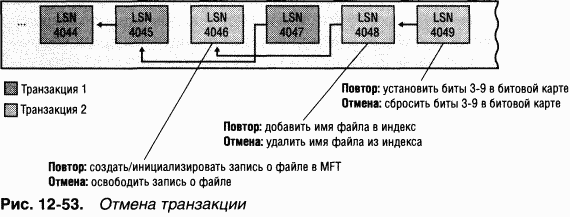
Когда проход отмены завершен, том возвращается в согласованное состояние. B этот момент NTFS сбрасывает на диск изменения кэша, чтобы гарантировать правильность содержимого тома. Далее NTFS записывает «пустую» область перезапуска, указывающую, что том находится в согласованном состоянии и что, если система сразу потерпит еще одну аварию, никакого восстановления не потребуется. Ha этом восстановление заканчивается.
NTFS гарантирует, что восстановление вернет том в некое существовавшее ранее целостное состояние, но не обязательно в непосредственно предшествовавшее сбою. NTFS не может дать такой гарантии, поскольку для большей производительности она использует алгоритм отложенной фиксации (lazy commit), а значит, сброс журнала транзакций из кэша на диск не выполняется немедленно всякий раз, когда добавляется запись «транзакция зафиксирована». Вместо этого несколько записей фиксации транзакций объединяются в пакет и записываются совместно – либо когда диспетчер кэша вызывает LFS для сброса журнала на диск, либо когда LFS помещает в журнал новую запись контрольной точки (каждые 5 секунд). Другая причина, по которой том не всегда возвращается к самому последнему состоянию, – в момент сбоя системы могли быть активны несколько параллельных транзакций, и одни записи фиксации этих транзакций были перенесены на диск, а другие – нет. Согласованное состояние тома, полученное в результате восстановления, отражает только те транзакции, чьи записи фиксации успели попасть на диск.
NTFS применяет журнал транзакций не только для восстановления тома, но и для других целей, реализация которых становится возможной за счет протоколирования транзакций. Файловые системы обязательно включают большой объем кода для обработки ошибок, возникающих в процессе обычного файлового ввода-вывода. Поскольку NTFS протоколирует каждую транзакцию, модифицирующую структуру тома, она может использовать журнал транзакций для восстановления после ошибок файловой системы и таким образом существенно упростить код обработки ошибок. Ошибка переполнения журнала транзакций, описанная ранее, – один из примеров использования протоколирования транзакций для обработки ошибок.
Большинство ошибок ввода-вывода, получаемых программой, не является ошибками файловой системы, и поэтому NTFS не может исправить их самостоятельно. Например, получив запрос на создание файла, NTFS может начать с создания записи в MFT, после чего ввести имя файла в индекс каталога. Однако при попытке выделить по своей битовой карте пространство для нового файла она может обнаружить, что диск заполнен, и запрос на создание файла удовлетворить не удастся. Тогда NTFS использует информацию из журнала транзакций для отмены уже выполненной части операции и освобождения структур данных, зарезервированных ею для файла. Затем ошибка «диск заполнен» возвращается вызывающей программе, которая и должна предпринять соответствующие действия.
Восстановление плохих кластеров в NTFS
Диспетчеры томов Windows – FtDisk (для базовых дисков) и LDM (для динамических) – могут восстанавливать данные из плохого (аварийного) сектора на отказоустойчивом томе, но, если жесткий диск не является SCSI-диском или если на нем больше нет резервных секторов, они не в состоянии заменить плохой сектор новым (подробнее о диспетчерах томов см. главу 10). B таком случае, когда файловая система считывает данные из плохого сектора, диспетчер томов восстанавливает информацию и возвращает ее вместе с соответствующим предупреждением.Файловая система FAT никак не обрабатывает это предупреждение. Более того, ни эта файловая система, ни диспетчеры томов не ведут учет плохих секторов, поэтому, чтобы диспетчер томов не повторял все время восстановление данных из плохого сектора, пользователь должен запустить утилиту Chkdsk или Format. Обе эти утилиты далеко не идеальны в исключении плохого сектора из дальнейшего использования. Chkdsk требует много времени для поиска и удаления плохих секторов, a Format уничтожает все данные в форматируемом разделе.
NTFS-эквивалент механизма замены секторов динамически заменяет кластер, содержащий плохой сектор, и ведет учет плохих кластеров, чтобы предотвратить их дальнейшее использование. (Вспомните, что NTFS адресуется к логическим кластерам, а не к физическим секторам.) Эта функциональность NTFS активизируется, если диспетчер томов не может заменить плохой сектор. Когда FtDisk возвращает предупреждение о плохом секторе или когда драйвер диска сообщает об ошибке, связанной с плохим сектором, NTFS выделяет новый кластер для замены того, который содержит плохой сектор. NTFS копирует данные, восстановленные диспетчером томов, в новый кластер, чтобы снова добиться избыточности данных.
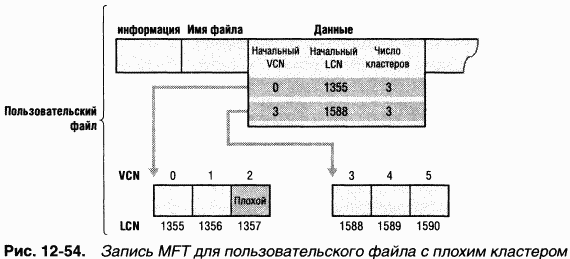
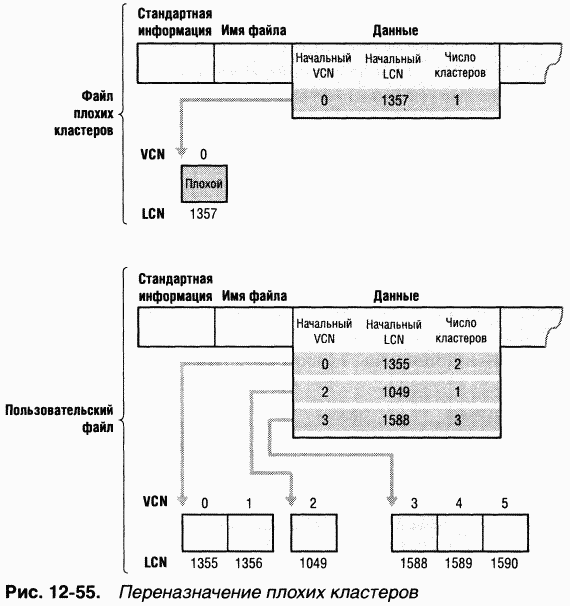
Ha рис. 12-54 показана запись MFT для пользовательского файла, в одном из групп которого имеется плохой сектор. Когда NTFS получает ошибку, связанную с плохим сектором, она присоединяет содержащий его кластер к своему файлу плохих кластеров. Это предотвращает повторное выделение данного кластера другому файлу. Затем NTFS выделяет новый кластер и изменяет сопоставление VCN-LCN для файла так, чтобы оно указывало на этот кластер. Данная процедура, известная как переназначение плохого кластера(bad-cluster remapping), иллюстрируется на рис. 12-55. Кластер номер 1357, содержащий плохой сектор, заменяется новым кластером с номером 1049.
Стандартная
Если том не сконфигурирован как отказоустойчивый, данные из плохого сектора восстановить нельзя. Когда том отформатирован для FAT и диспетчер томов не может восстановить данные, чтение из плохого сектора дает непредсказуемые результаты. Если в плохом секторе располагались какие-либо управляющие структуры файловой системы, может быть потерян целый файл или группа файлов (а иногда и весь диск). B лучшем случае будет потеряна часть данных файла (как правило, все файловые данные, расположенные в данном секторе и за ним). Более того, FAT скорее всего повторно выделит плохой сектор под другой файл, в результате чего проблема возникнет снова.
Ta же процедура восстановления используется, когда в аварийном секторе хранятся данные файловой системы. Если он находится на томе с избыточностью данных, NTFS динамически заменяет соответствующий кластер, используя данные, восстановленные диспетчером томов. Если том не избыточный, восстановить данные нельзя, и NTFS устанавливает в файле тома бит, указывающий, что том поврежден. При перезагрузке системы NTFS-утилита Chkdsk проверяет этот бит и, если он установлен, исправляет повреждение файловой системы, реконструируя метаданные NTFS.