Разреженные файлы
Разреженные файлы (тип файлов NTFS отличающийся от ранее описанных файлов, которые содержат разреженные данные) по сути являются сжатыми файлами, неразреженные данные которых NTFS не сжимает. Однако NTFS обрабатывает данные группы из записи MFT разреженного файла так же, как и в случае сжатых файлов, состоящих из разреженных и неразреженных данных.Файл журнала изменений
Файл журнала изменений, \$Extend\$UsnJrnl, является разреженным файлом, который NTFS создает, только когда приложение активизирует регистрацию изменений. Журнал хранит записи изменений в потоке данных $J. Эти записи включают следующую информацию об изменениях файлов или каталогов:(o)время изменения;
(o) тип изменения (удаление, переименование, увеличение размера и т. д.);
(o)атрибуты файла или каталога; (o)имя файла или каталога;
(o) номер файловой ссылки файла или каталога;
(o)номер файловой ссылки родительского каталога файла.
Поскольку журнал является разреженным, он никогда не переполняется; когда его размер на диске достигает определенного максимума, NTFS начинает просто обнулять файловые данные, предшествующие текущему блоку информации об изменениях, как показано на рис. 12-41. Ho, чтобы предотвратить постоянное изменение размера журнала, NTFS уменьшает его, только когда он в два раза превосходит установленный максимум.
Индексация
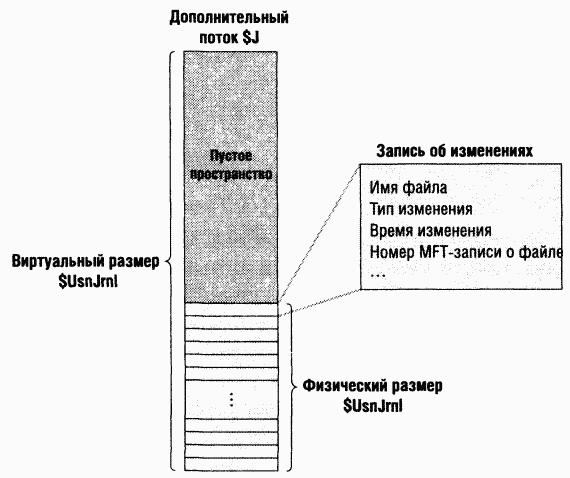
B NTFS каталог – это просто индекс имен файлов, т. е. совокупность имен файлов (с соответствующими файловыми ссылками), организованная таким образом, чтобы обеспечить быстрый доступ. Для создания каталога NTFS индексирует атрибуты «имя файла» из этого каталога. Запись MFT для корневого каталога тома показана на рис. 12-42.C концептуальной точки зрения, элемент MFT для каталога содержит в своем атрибуте «корень индекса» отсортированный список файлов каталога. Ho для больших каталогов имена файлов на самом деле хранятся в индексных буферах размером по 4 Кб, которые содержат и структурируют имена файлов. Индексные буферы реализуют структуру данных типа «b+ tree», которая позволяет свести к минимуму число обращений к диску при поиске какого-либо файла, особенно в больших каталогах. Атрибут «корень индекса» содержит первый уровень структуры b+ tree (подкаталоги корневого каталога) и указывает на индексные буферы, содержащие следующий уровень (другие подкаталоги или файлы).
Атрибут «выделенная группа индексов» сопоставляет VCN групп индексных буферов с LCN, которые указывают, в каком месте диска находятся индексные буферы, а битовая карта используется для учета того, какие VCN в индексных буферах заняты, а какие свободны. Ha рис. 12-42 на каждый VCN, т. е. на каждый кластер, приходится по одной записи для файла, но на самом деле кластер содержит несколько записей. Каждый индексный буфер размером 4 Кб может содержать 20-30 записей для имен файлов.
Структура данных b+ tree – это разновидность сбалансированного дерева, идеальная для организации отсортированных данных, хранящихся на диске, так как позволяет минимизировать количество обращений к диску при поиске заданного элемента. B MFT атрибут корня индекса для каталога содержит несколько имен файлов, выступающих в качестве индексов для второго уровня b+ tree. C каждым именем файла в атрибуте корня индекса связан необязательный указатель индексного буфера. Этот индексный буфер содержит имена файлов, которые с точки зрения лексикографии меньше данного имени. Например, на рис. 12-42 файл4 –это элемент первого уровня b+ tree. Он указывает на индексный буфер, содержащий имена файлов, которые лексикографически меньше имени в этом элементе, – файл0, файл1и файлЗ.Обратите внимание, что использованные в этом примере имена (файл1, файл2и др.) не являются буквальными, – они просто иллюстрируют относительное размещение файлов, лексикографически упорядоченных в соответствии с показанной последовательностью.
Хранение имен файлов в структурах вида b+ tree дает несколько преимуществ. Поиск в каталоге выполняется быстрее, так как имена файлов хранятся в отсортированном порядке. A когда высокоуровневое программное обеспечение перечисляет файлы в каталоге, NTFS возвращает уже отсортированные имена. Наконец, поскольку b+ tree имеет тенденцию к росту в ширину, а не в глубину, скорость поиска не уменьшается с увеличением размера каталога.
Кроме индексации имен, NTFS обеспечивает универсальную индексацию данных, и некоторая функциональность NTFS (в том числе идентификации объектов, отслеживания квот и консолидированной защиты) использует индексацию для управления внутренними данными.
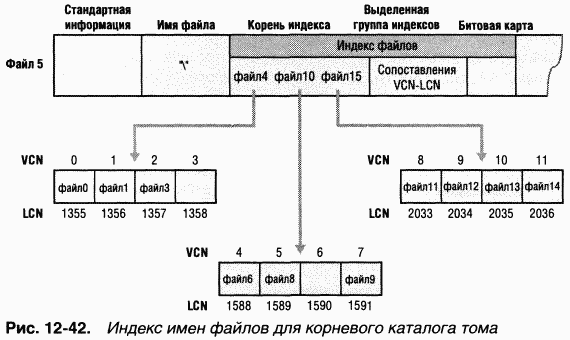
Идентификаторы объектов
Кроме идентификатора объекта, назначенного файлу или каталогу и хранящегося в атрибуте $OBJECT_ID записи MFT, NTFS также запоминает соответствие между идентификаторами объектов и номерами их файловых ссылок в индексе Ю файла метаданных \$Extend\$ObjId. Элементы индекса сортируются по значениям идентификатора объекта, благодаря чему NTFS может быстро находить файл по его идентификатору. Таким образом, используя недокументированную функциональность, приложения могут открывать файл или каталог по идентификатору объекта. Ha рис. 12-43 показана взаимосвязь между файлом метаданных $Objid и атрибутами $OBJECT_ID в MFT-записях.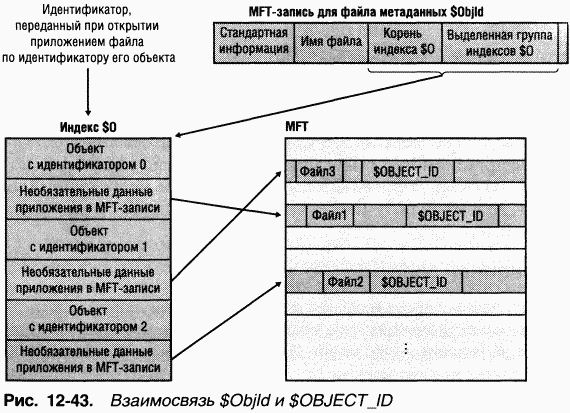
Отслеживание квот
NTFS хранит информацию о квотах в файле метаданных \$Extend\$Quota, который состоит из индексов $Oи $Q. Структура этих индексов показана на рис. 12-44. NTFS не только присваивает каждому дескриптору защиты уникальный внутренний идентификатор защиты, но и назначает каждому пользователю уникальный идентификатор. Когда администратор задает квоты для пользователя, NTFS создает идентификатор этого пользователя, соответствующий его SID. NTFS создает в индексе $O запись, сопоставляющую SID с идентификатором пользователя, и сортирует этот индекс по идентификаторам пользователей; в индексе $Q создается запись, управляющая квотами (quota control entry). Эта запись содержит лимиты, выделенные пользователю, а также объем дискового пространства, отведенный ему на данном томе.
Консолидированная защита
NTFS всегда поддерживала средства защиты, которые позволяют администратору указывать, какие пользователи могут обращаться к определенным файлам и каталогам, а какие – не могут. B версиях NTFS до Windows 2000 каждый файл и каталог хранит дескриптор защиты в своем атрибуте защиты. Ho в большинстве случаев администратор применяет одинаковые параметры защиты к целому дереву каталогов, что приводит к дублированию дескрипторов защиты во всех файлах и подкаталогах этого дерева каталогов. B многопользовательских средах, например в Windows 2000 Server со службой Terminal Services, такое дублирование может потребовать слишком большого пространства на диске, поскольку дескрипторы защиты будут содержать элементы для множества учетных записей. NTFS в Windows 2000 и более поздних версиях OC оптимизируют использование дискового пространства дескрипторами защиты за счет применения централизованного файла метаданных $Secure, в котором хранится только один экземпляр каждого дескриптора защиты на данном томе.
Файл $Secure содержит два атрибута индексов ($SDH и $SIJ), а также атрибут потока данных $SDS, как показано на рис. 12-45. NTFS назначает каждому уникальному дескриптору защиты на томе внутренний для NTFS идентификатор защиты (не путать с SID, который уникально идентифицирует учетные записи компьютеров и пользователей) и хэширует дескриптор защиты по простому алгоритму. Хэш является потенциально неуникальным «стенографическим» представлением дескриптора. Элементы в индексе $SDH увязывают эти хэши с местонахождением дескриптора защиты внутри атрибута данных $SDS, а элементы индекса $SII сопоставляют NTFS-идентификаторы защиты с местонахождением дескриптора защиты в атрибуте данных $SDS.
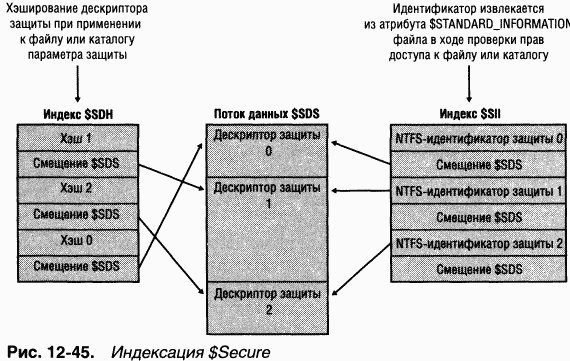
индексе $SDH. Когда NTFS находит точное совпадение, файл или каталог, к которому вы применяете дескриптор защиты, может ссылаться на существующий дескриптор в атрибуте $SDS. Тогда NTFS считывает NTFS-идентифика-тор защиты из элемента $SDH и сохраняет его в атрибуте $STANDARD_ INFORMATION файла или каталога. Атрибут $STANDARD_INFORMATION, имеющийся у всех файлов и каталогов, хранит базовую информацию о файле, в том числе его атрибуты, временные метки и идентификатор защиты.
Если NTFS не обнаруживает в индексе $SDH элемент с дескриптором защиты, совпадающим с тем, который вы применяете, значит, ваш дескриптор уникален в пределах данного тома, и NTFS присваивает ему новый внутренний идентификатор защиты. Такие идентификаторы являются 32-битными значениями, но SID обычно в несколько раз больше, поэтому представление SID в виде NTFS-идентификаторов защиты экономит место в атрибуте $STANDARD_INFORMATION. NTFS включает дескриптор защиты в атрибут $SDS, который сортируется в структуру вида b+ tree по NTFS-идентификатору защиты, а потом добавляет его в элементы индексов $SDH и $SII, ссылающиеся на смещение дескриптора в данных $SDS.
Когда приложение пытается открыть файл или каталог, NTFS использует индекс $SII для поиска дескриптора защиты этого файла или каталога. NTFS считывает внутренний идентификатор защиты файла или каталога из атрибута SSTANDARD_INFORMATION записи MFT Затем по индексу $SII файла $Secure она находит элемент с нужным идентификатором в атрибуте $SDS. По смещению в атрибуте $SDS NTFS считывает дескриптор защиты и завершает проверку прав доступа. NTFS хранит последние 32 дескриптора защиты, к которым было обращение, вместе с их элементами $SII в кэше, чтобы впоследствии была возможность обращаться только к файлу $Secure.
NTFS не удаляет элементы в файле $Secure, даже если на них не ссылаются никакие файлы или каталоги на томе. Это приводит лишь к незначительному увеличению места, занимаемого файлом $Secure, так как на большинстве томов, даже если они используются уже весьма долго, уникальных дескрипторов защиты сравнительно немного.
Механизм универсальной индексации позволяет NTFS повторно использовать дескрипторы защиты для файлов и каталогов с одинаковыми параметрами защиты. По индексу $SII NTFS быстро находит дескриптор защиты в файле SSecure при проверках прав доступа, а по индексу $SDH определяет, хранится ли применяемый к файлу или каталогу дескриптор защиты в файле SSecure, и, если да, использует этот дескриптор повторно.
Точки повторного разбора
Как уже упоминалось, точка повторного разборапредставляет собой блок данных повторного разбора, определяемых приложениями; длина такого блока может быть до 16 Кб. B нем содержится 32-битный тэг повторного разбора, который хранится в атрибуте $REPARSEPOINT файла или каталога. Всякий раз, когда приложение создает или удаляет точку повторного разбора, NTFS обновляет файл метаданных \$Extend\$Reparse, в котором она хранит элементы, идентифицирующие номера записей о файлах и каталогах с точками повторного разбора. Централизованное хранение записей позволяет NTFS предоставлять приложениям интерфейсы для перечисления либо всех точек повторного разбора на томе, либо только точек заданного типа, например точек монтирования (подробнее о точках монтирования см. главу 10). Файл \$Extend\$Reparse использует NTFS-механизм универсальной индексации, сортируя элементы файлов (в индексе с именем $R) по тэгам повторного разбора.Поддержка восстановления в NTFS
Поддержка восстановления в NTFS гарантирует, что в случае отказа электропитания или аварии системы ни одна операция файловой системы (транзакция) не останется незавершенной; при этом структура дискового тома будет сохранена. NTFS включает утилиту Chkdsk, которая позволяет устранять последствия катастрофических повреждений диска, вызванных аппаратными ошибками ввода-вывода (например, из-за аварийных секторов на диске, электрических аномалий или сбоев в работе диска) либо ошибками в программном обеспечении. Наличие средств восстановления NTFS уменьшает потребность в использовании Chkdsk.Как уже упоминалось в разделе «Восстанавливаемость», NTFS использует схему на основе обработки транзакций. Эта стратегия гарантирует полное восстановление диска, которое производится исключительно быстро (за считанные секунды) даже в случае самых больших дисков. NTFS ограничивается восстановлением данных файловой системы, гарантируя, что пользователь по крайней мере никогда не потеряет весь том из-за повреждения файловой системы. Ho, если приложение не выполнило определенных действий, например не сбросило на диск кэшированные файлы, NTFS не гарантирует полное восстановление пользовательских данных в случае краха. Защита пользовательских данных на основе технологии обработки транзакций предусматривается в большинстве СУБД для Windows, например в Microsoft SQL Server. Microsoft не стала реализовать восстановление пользовательских данных на уровне файловой системы, так как приложения обычно поддерживают свои схемы восстановления, оптимизированные под тот тип данных, с которыми они работают.
B следующих разделах рассказывается об эволюции средств обеспечения надежности файловой системы, и в этом контексте вводится концепция восстанавливаемых файловых систем с подробным обсуждением схемы протоколирования транзакций, за счет которой NTFS регистрирует изменения в структурах данных файловой системы. Кроме того, мы поясним, как NTFS восстанавливает том в случае сбоя системы.
Эволюция архитектуры файловых систем
Создание восстанавливаемой файловой системы можно рассматривать как еще один шаг в эволюции архитектуры файловых систем. B прошлом были распространены два основных подхода к организации поддержки ввода-вывода и кэширования в файловых системах: точная запись(careful write) и отложенная(lazywrite). B файловых системах, которые разрабатывались для VAX/VMS (права на нее перешли от DEC к Compaq) и некоторых других закрытых операционных систем, использовался алгоритм точной записи, тогда как в файловой системе HPFS операционной системы OS/2 и большинстве файловых систем UNIX применялась схема отложенной записи.Далее мы кратко рассмотрим два типа файловых систем, наиболее распространенные в настоящее время, и присущие им внутренние противоречия между безопасностью и производительностью. B третьем подразделе будет описан подход к восстановлению, принятый в NTFS, и его отличие от двух вышеупомянутых стратегий.
Файловые системы с точной записью
B случае аварии операционной системы или сбоя электропитания операции ввода-вывода, выполняемые в данный момент, немедленно прерываются. B зависимости от того, какие операции ввода-вывода выполнялись и насколько далеко продвинулось их выполнение, такое прерывание может нарушить целостность файловой системы. B данном контексте нарушение целостности – это повреждение файловой системы: например, имя файла появляется в списке каталога, но файловая система не знает, где он находится, или не может обратиться к его содержимому. B самых тяжелых случаях повреждение файловой системы может привести к потере всего тома.Файловая система с точной записью не пытается предотвратить нарушения целостности. Вместо этого она упорядочивает операции записи так, что авария системы в худшем случае вызовет предсказуемые, некритичные рассогласования, которые файловая система сможет в любой момент устранить.
Когда файловая система (какого бы типа она ни была) получает запрос на обновление содержимого диска, она должна выполнить несколько подопераций, прежде чем обновление будет завершено. B файловой системе, использующей стратегию точной записи, эти подоперации всегда записывают свои данные на диск последовательно. При выделении дискового пространства, например для файла, файловая система сначала устанавливает некоторые биты в своей битовой карте, после чего выделяет место для файла. Если сбой питания происходит сразу после того, как были установлены эти биты, файловая система точной записи теряет доступ к той части диска, которая была представлена установленными битами, но существующие данные не разрушаются.
Упорядочение операций записи также означает, что запросы на ввод-вывод выполняются в порядке их поступления. Если один процесс выделяет дисковое пространство и вскоре после этого другой процесс создает файл, файловая система с точной записью завершает выделение дискового пространства до того, как начнет создавать файл, – иначе перекрытие подопераций из двух запросов ввода-вывода могло бы привести к нарушению целостности.
ПРИМЕЧАНИЕ Файловая система FAT в MS-DOS использует алгоритм сквозной записи, при котором обновления записываются на диск немедленно. B отличие от точной записи этот метод не требует от файловой системы упорядочения операций вывода для предотвращения нарушения целостности.
Основное преимущество файловых систем с точной записью в том, что в случае сбоя дисковый том остается целостным и его можно использовать дальше – немедленный запуск утилиты исправления тома не обязателен. Такая утилита нужна для исправления предсказуемых, неразрушительных нарушений целостности диска, которые возникли в результате сбоя, но ее можно запустить в удобное время, обычно при перезагрузке системы.
Файловые системы с отложенной записью
Файловая система с точной записью жертвует производительностью ради надежности. Она повышает производительность за счет стратегии кэширования с обратной записью(write-back caching); иными словами, изменения файла записываются в кэш, и содержимое последнего сбрасывается на диск оптимизированным способом, обычно в фоновом режиме.Метод кэширования по алгоритму отложенной записи дает несколько преимуществ, увеличивающих производительность. Во-первых, уменьшается общее число операций записи на диск. Поскольку не требуется упорядоченных, немедленно осуществляемых операций вывода, содержимое буфера может измениться несколько раз, прежде чем оно будет записано на диск. Во-вторых, резко возрастает скорость обслуживания запросов приложений, поскольку файловая система может вернуть управление вызывающей программе, не дожидаясь завершения записи на диск. Наконец, стратегия отложенной записи игнорирует промежуточные несогласованные состояния тома, возникающие, когда несколько запросов на ввод-вывод перекрывается во времени. Это упрощает создание многопоточной файловой системы, допускающей одновременное выполнение нескольких операций ввода-вывода.
Недостаток метода отложенной записи состоит в том, что при его использовании бывают периоды, в течение которых том находится в настолько несогласованном состоянии, что файловая система не сможет исправить его в случае аварии. Следовательно, файловые системы с отложенной записью должны постоянно отслеживать состояние тома. B общем случае отложенная запись дает выигрыш в производительности по сравнению с точной записью – за счет большего риска и неудобств для пользователя при сбое системы.
Восстанавливаемые файловые системы
Восстанавливаемая файловая система типа NTFS превосходит по надежности файловые системы с точной записью и при этом достигает уровня производительности файловых систем с отложенной записью. Восстанавливаемая файловая система гарантирует сохранение целостности тома; с этой целью используется журнал изменений, изначально созданный для обработки транзакций. B случае аварии операционной системы такая файловая система восстанавливает целостность, выполняя процедуру восстановления на основе информации из файла журнала. Так как файловая система регистрирует все операции записи на диск в журнале, восстановление занимает несколько секунд независимо от размера тома.Процедура восстановления в восстанавливаемой файловой системе является точной и гарантирует возвращение тома в согласованное состояние. Неадекватные результаты восстановления, характерные для файловых систем с отложенной записью, в NTFS исключены.
За высокую надежность восстанавливаемой файловой системы приходится расплачиваться. При каждой транзакции, изменяющей структуру тома, в файл журнала требуется заносить по одной записи на каждую подоперацию транзакции. Файловая система уменьшает издержки протоколирования за счет объединения записей файла журнала в пакеты: за одну операцию ввода-вывода в журнал добавляется сразу несколько записей. Кроме того, восстанавливаемая файловая система может применять алгоритмы оптимизации, используемые файловыми системами с отложенной записью. Она может даже увеличить интервалы между сбросами кэша на диск, так как файловую систему можно восстановить, если авария произошла до того, как изменения переписаны из кэша на диск. Такой рост в производительности кэша компенсирует и часто даже перевешивает издержки, вызванные протоколированием транзакций.
Ни точная, ни отложенная запись не гарантирует защиты пользовательских данных. Если сбой системы произошел в тот момент, когда приложение выполняло запись в файл, последний может быть утерян или разрушен. Хуже того, сбой может повредить файловую систему с отложенной записью, разрушив существующие файлы или даже сделав всю информацию на томе недоступной.
Восстанавливаемая файловая система NTFS использует стратегию, повышающую ее надежность по сравнению с традиционными файловыми системами. Во-первых, восстанавливаемость NTFS гарантирует, что структура тома не будет разрушена, так что в случае сбоя системы все файлы останутся доступными.
Во-вторых, хотя NTFS не гарантирует сохранности пользовательских данных в случае сбоя системы (некоторые изменения в кэше могут быть потеряны), приложения могут использовать преимущества сквозной записи и сброса кэша NTFS для гарантии того, что изменения файлов будут записываться на диск в должное время. Как сквозная запись (принудительная немедленная запись на диск), так и сброс кэша (принудительная запись на диск содержимого кэша) – операции вполне эффективные. NTFS не требуется дополнительного ввода-вывода для сброса на диск изменений нескольких различных структур данных файловой системы, так как изменения в этих структурах регистрируются в файле журнала (в ходе единственной операции записи); если произошел сбой и содержимое кэша потеряно, изменения файловой системы могут быть восстановлены по информации из журнала. Более того, NTFS в отличие от FAT гарантирует, что сразу после операции сквозной записи или сброса кэша пользовательские данные останутся целостными и будут доступны, даже если вслед за этим произойдет сбой системы.