Поисковые движки читают также и метатег description (третий красный эллипс на рис. 2.18). Однако метатег description не оказывает никакого влияния на рейтинги поисковых движков (http://searchengineland.com/21-essential-seo-tips-techniques-11580).
Тем не менее метатег description играет ключевую роль, поскольку поисковые движки часто используют его как описание вашей страницы в результатах поиска. Поэтому хорошо написанный метатег description может иметь существенное влияние на количество кликов по вашему элементу в результатах поиска. Потраченное на этот тег время даст ценные результаты. На рис. 2.20 показан поиск по trip advisor, который является примером использования метатега description в качестве описания в результатах поиска.
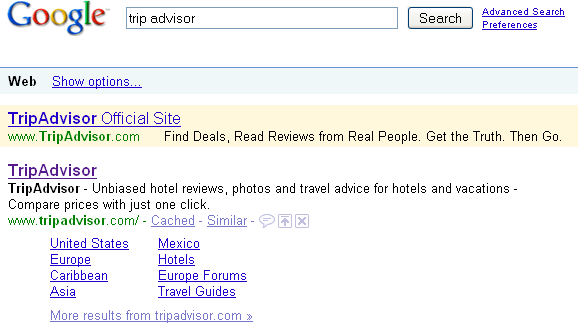 Рис. 2.20. Метатег description в результатах поиска
Рис. 2.20. Метатег description в результатах поиска
• плохо видящих людей, не имеющих возможности просматривать изображения;
• тех людей, которые отключают изображения для ускорения просмотра страниц (но это актуально только для тех, у кого нет высокоскоростного подключения к Интернету).
Поддержка плохо видящих людей остается основной причиной использования атрибута alt. Вы можете прочитать об этом на странице Web Accessibility Initiative по адресу: http://www.w3.org/WAI/.
Поисковые движки также читают и текст, содержащийся в атрибуте alt тега image. Этот тег используется для того, чтобы дать указание web-странице показать изображение. Вот пример тега изображения с сайта Alchemist Media:
Атрибут alt – это то, что читает поисковый движок. Движок интерпретирует его, чтобы определить, о чем это изображение, и чтобы лучше понять, о чем эта страница.
Последний элемент, который читают поисковые движки – это тег noscript. В общем случае поисковые движки не пытаются интерпретировать код JavaScript, который может присутствовать на web-странице (хотя это уже начинает меняться). Однако некоторые пользователи не разрешают выполнять код JavaScript при загрузке страниц (по данным авторов, таких пользователей примерно 2 %). Для этих пользователей в том месте, где на web-странице имеется JavaScript, не будет показано вообще ничего (если страница не содержит тега noscript).
Вот очень простой пример JavaScript, который это демонстрирует:
Тег noscript следует использовать только для того, чтобы обозначить содержимое JavaScript. (Размещение здесь другого контента или ссылок может быть интерпретировано поисковым движком как спам.) Кроме того, это предупреждение браузера может превратиться в поисковый фрагмент (а это уже будет плохо).
Например, несмотря на то, что поисковые движки могут обнаружить, что вы показываете изображение, но они не могут определить, изображение чего именно вы показываете (если не учитывать ту информацию, которую вы им даете в атрибуте alt). Однако они способны определить цвет пиксела и (во многих случаях) установить порнографический характер изображения по количеству телесного цвета в изображении JPEG. Поэтому поисковый движок не может сказать, что показано на изображении – Барт Симпсон, лодка, дом или торнадо. Кроме того, поисковые движки не распознают содержащийся в изображении текст. Поисковые движки экспериментируют с технологиями оптического распознавания символов (optical character recognition, OCR), чтобы извлекать текст из изображений, но эти технологии еще не имеют широкого применения при поиске.
Кроме того, обычный здравый смысл оптимизации всегда подсказывал, что поисковые движки не умеют читать Flash-файлы, но это несколько преувеличено. Поисковые движки уже начинают извлекать информацию из Flash-файлов, как это показано в объявлении компании Google по адресу http://googlewebmastercentral.blogspot.com/2008/06/improved-flash-indexing.html. Однако поисковому движку нелегко определить, что именно содержится во Flash. Одна из самых больших проблем состоит в том, что когда поисковые движки смотрят внутрь Flash, то они по-прежнему ищут текстовый контент, но Flash – это изобразительное средство и у дизайнера нет никаких причин (кроме поисковых движков), чтобы встраивать внутрь него текст. Здесь нет также никаких семантических подсказок, которые присутствуют в HTML-тексте (таких, как теги заголовков страниц, жирный текст и т. д.) даже тогда, когда HTML используется совместно с Flash.
Третий тип контента, который поисковые движки видеть не могут, – это изобразительные элементы всего того, что содержится во Flash, поэтому этот аспект Flash ведет себя точно так же, как изображения. Например, когда текст преобразуется в векторную форму (визуализируется графически), то текстовая информация (которую могут читать поисковые движки) теряется. Мы обсудим методы оптимизации Flash в главе 6.
Аудио– и видеофайлы поисковым движкам тоже читать непросто. Как и в случае изображений, эти данные анализировать нелегко. Есть несколько исключений, когда поисковые движки могут извлечь некоторое ограниченное количество данных (таких, как теги ID3 из файлов МР3 или текстовые примечания, изображения и маркеры глав из расширенных подкастов формата ААС). Однако в конечном итоге отличить видеоизображение игры в футбол от лесного пожара невозможно.
Поисковые движки не могут также прочитать никакого контента внутри программы. Поисковому движку нужно найти в исходном коде web-страницы текст, который удобочитаем для человеческого глаза (как мы уже говорили ранее). То, что вы можете видеть его после загрузки страницы в браузер, не помогает – он должен быть видим и читаться в исходном коде этой страницы.
Пример технологии, которая предоставляет значительное количество читаемого человеком (но не видимого поисковыми движками) контента, – это AJAX. AJAX (основанный на JavaScript метод динамического отображения контента на web-странице после извлечения данных из базы данных (без необходимости обновления всей страницы целиком)). Этот метод часто используется в инструментальных средствах, когда посетитель сайта может сделать ввод данных, а инструмент AJAX затем извлекает и отображает правильный контент.
Проблема возникает потому, что контент извлекается скриптом, работающем на клиентском компьютере (машине пользователя), после ввода информации пользователем. Это может привести к получению множества вариантов вывода. Кроме того, до этого ввода данных контент в коде HTML данной страницы отсутствует, так что поисковый движок его видеть не может.
Аналогичные проблемы возникают и с другими формами JavaScript, которые до выполнения действия пользователем не визуализируют контент в HTML.
В пятой версии HTML была создана конструкция, известная как тег embed, чтобы дать возможность встраивать в HTML-страницы дополнительные модули (программы, находящиеся на компьютере пользователя, а не на web-сервере вашего web-сайта). Этот тег часто используется для встраивания видео– и аудиофайлов в web-страницы. Тег embed говорит дополнительному модулю, где он должен искать используемый файл с данными. Встраиваемый при помощи дополнительных модулей контент совершенно невидим для поисковых движков.
Фреймы и плавающие рамки – это метод встраивания содержимого другой web-страницы в вашу web-страницу. Плавающие рамки используются чаще (чем обычные фреймы) для встраивания контента с другого web-сайта. Вы можете очень просто сделать плавающую рамку при помощи примерно такого кода:
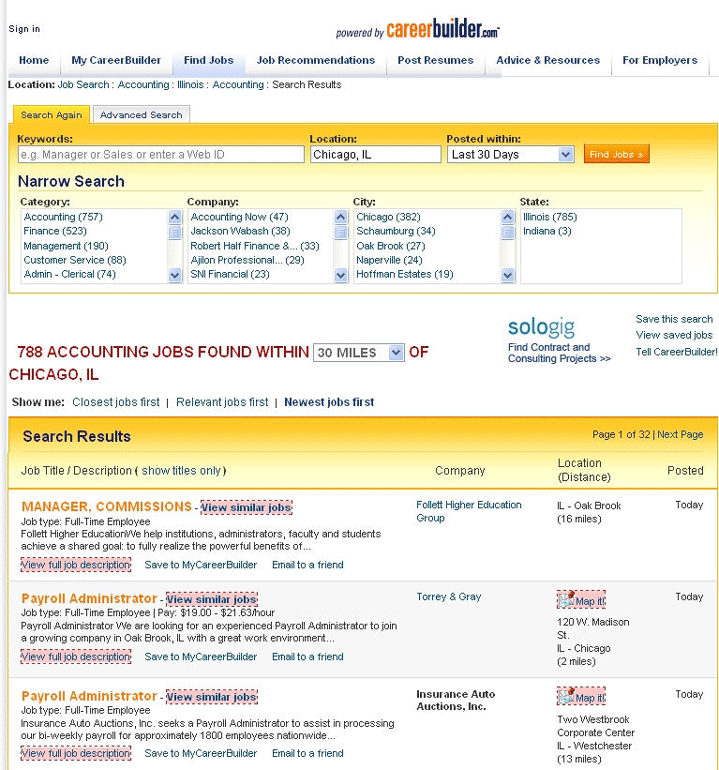 Рис. 2.21. Визуализированная в браузере страница с фреймами
Рис. 2.21. Визуализированная в браузере страница с фреймами
Это пример хорошей работы по втягиванию контента (при условии, что у вас есть разрешение на это) с другого сайта и размещению его на вашем сайте. Однако поисковые движки распознают фрейм для втягивания контента другого сайта и соответственно игнорируют контент внутри фрейма (поскольку это контент другого издателя). Иначе говоря, они не считают втянутый с другого сайта контент частью уникального контента вашей web-страницы.
http://forums.searchenginewatch.com/showthread.php?threadid=48) для связывания терминов и начать понимать web-страницы более похожим на человеческий образом.
Тем не менее метатег description играет ключевую роль, поскольку поисковые движки часто используют его как описание вашей страницы в результатах поиска. Поэтому хорошо написанный метатег description может иметь существенное влияние на количество кликов по вашему элементу в результатах поиска. Потраченное на этот тег время даст ценные результаты. На рис. 2.20 показан поиск по trip advisor, который является примером использования метатега description в качестве описания в результатах поиска.
ПримечаниеЧетвертый элемент, который читают поисковые движки, – это атрибут alt для изображений. Этот атрибут первоначально использовался для отображения хоть чего-нибудь в том случае, когда просмотр изображения был невозможен. Это было предназначено для двух групп пользователей:
Ключевые слова пользователя обычно показаны в результатах поиска жирным шрифтом. Иногда жирным шрифтом показываются и близкие синонимы. На рис. 2.20 есть такой пример: TripAdvisor в начале описания выделен жирным шрифтом.
• плохо видящих людей, не имеющих возможности просматривать изображения;
• тех людей, которые отключают изображения для ускорения просмотра страниц (но это актуально только для тех, у кого нет высокоскоростного подключения к Интернету).
Поддержка плохо видящих людей остается основной причиной использования атрибута alt. Вы можете прочитать об этом на странице Web Accessibility Initiative по адресу: http://www.w3.org/WAI/.
Поисковые движки также читают и текст, содержащийся в атрибуте alt тега image. Этот тег используется для того, чтобы дать указание web-странице показать изображение. Вот пример тега изображения с сайта Alchemist Media:
<img src="http://www.alchemistmedia.com/img/btob2009.jpg" alt="BtoB Interactive Marketing Guide" border="0" />Часть "src=" – это местонахождение того изображения, которое нужно показать. Та часть, которая начинается с alt и за которой следует BtoB Interactive Marketing Guide, считается атрибутом alt.
{kind=link}
Атрибут alt – это то, что читает поисковый движок. Движок интерпретирует его, чтобы определить, о чем это изображение, и чтобы лучше понять, о чем эта страница.
Последний элемент, который читают поисковые движки – это тег noscript. В общем случае поисковые движки не пытаются интерпретировать код JavaScript, который может присутствовать на web-странице (хотя это уже начинает меняться). Однако некоторые пользователи не разрешают выполнять код JavaScript при загрузке страниц (по данным авторов, таких пользователей примерно 2 %). Для этих пользователей в том месте, где на web-странице имеется JavaScript, не будет показано вообще ничего (если страница не содержит тега noscript).
Вот очень простой пример JavaScript, который это демонстрирует:
<script type="text/javascript">Тег noscript содержит текст "Your browser does not support JavaScript!". Поисковый движок прочитает этот текст и расценит его как информацию о web-странице. В этом примере вы могли также вставить в тег noscript текст типа "it is a Small World After All!" (Мир тесен в конце концов!).
document.write("It is a Small World After All!")
</script>
<noscript>Your browser does not support JavaScript!</noscript>
Тег noscript следует использовать только для того, чтобы обозначить содержимое JavaScript. (Размещение здесь другого контента или ссылок может быть интерпретировано поисковым движком как спам.) Кроме того, это предупреждение браузера может превратиться в поисковый фрагмент (а это уже будет плохо).
Чего не могут видеть поисковые движки
Целесообразно также сделать обзор тех типов контента, которые поисковые движки не могут видеть.Например, несмотря на то, что поисковые движки могут обнаружить, что вы показываете изображение, но они не могут определить, изображение чего именно вы показываете (если не учитывать ту информацию, которую вы им даете в атрибуте alt). Однако они способны определить цвет пиксела и (во многих случаях) установить порнографический характер изображения по количеству телесного цвета в изображении JPEG. Поэтому поисковый движок не может сказать, что показано на изображении – Барт Симпсон, лодка, дом или торнадо. Кроме того, поисковые движки не распознают содержащийся в изображении текст. Поисковые движки экспериментируют с технологиями оптического распознавания символов (optical character recognition, OCR), чтобы извлекать текст из изображений, но эти технологии еще не имеют широкого применения при поиске.
Кроме того, обычный здравый смысл оптимизации всегда подсказывал, что поисковые движки не умеют читать Flash-файлы, но это несколько преувеличено. Поисковые движки уже начинают извлекать информацию из Flash-файлов, как это показано в объявлении компании Google по адресу http://googlewebmastercentral.blogspot.com/2008/06/improved-flash-indexing.html. Однако поисковому движку нелегко определить, что именно содержится во Flash. Одна из самых больших проблем состоит в том, что когда поисковые движки смотрят внутрь Flash, то они по-прежнему ищут текстовый контент, но Flash – это изобразительное средство и у дизайнера нет никаких причин (кроме поисковых движков), чтобы встраивать внутрь него текст. Здесь нет также никаких семантических подсказок, которые присутствуют в HTML-тексте (таких, как теги заголовков страниц, жирный текст и т. д.) даже тогда, когда HTML используется совместно с Flash.
Третий тип контента, который поисковые движки видеть не могут, – это изобразительные элементы всего того, что содержится во Flash, поэтому этот аспект Flash ведет себя точно так же, как изображения. Например, когда текст преобразуется в векторную форму (визуализируется графически), то текстовая информация (которую могут читать поисковые движки) теряется. Мы обсудим методы оптимизации Flash в главе 6.
Аудио– и видеофайлы поисковым движкам тоже читать непросто. Как и в случае изображений, эти данные анализировать нелегко. Есть несколько исключений, когда поисковые движки могут извлечь некоторое ограниченное количество данных (таких, как теги ID3 из файлов МР3 или текстовые примечания, изображения и маркеры глав из расширенных подкастов формата ААС). Однако в конечном итоге отличить видеоизображение игры в футбол от лесного пожара невозможно.
Поисковые движки не могут также прочитать никакого контента внутри программы. Поисковому движку нужно найти в исходном коде web-страницы текст, который удобочитаем для человеческого глаза (как мы уже говорили ранее). То, что вы можете видеть его после загрузки страницы в браузер, не помогает – он должен быть видим и читаться в исходном коде этой страницы.
Пример технологии, которая предоставляет значительное количество читаемого человеком (но не видимого поисковыми движками) контента, – это AJAX. AJAX (основанный на JavaScript метод динамического отображения контента на web-странице после извлечения данных из базы данных (без необходимости обновления всей страницы целиком)). Этот метод часто используется в инструментальных средствах, когда посетитель сайта может сделать ввод данных, а инструмент AJAX затем извлекает и отображает правильный контент.
Проблема возникает потому, что контент извлекается скриптом, работающем на клиентском компьютере (машине пользователя), после ввода информации пользователем. Это может привести к получению множества вариантов вывода. Кроме того, до этого ввода данных контент в коде HTML данной страницы отсутствует, так что поисковый движок его видеть не может.
Аналогичные проблемы возникают и с другими формами JavaScript, которые до выполнения действия пользователем не визуализируют контент в HTML.
В пятой версии HTML была создана конструкция, известная как тег embed, чтобы дать возможность встраивать в HTML-страницы дополнительные модули (программы, находящиеся на компьютере пользователя, а не на web-сервере вашего web-сайта). Этот тег часто используется для встраивания видео– и аудиофайлов в web-страницы. Тег embed говорит дополнительному модулю, где он должен искать используемый файл с данными. Встраиваемый при помощи дополнительных модулей контент совершенно невидим для поисковых движков.
Фреймы и плавающие рамки – это метод встраивания содержимого другой web-страницы в вашу web-страницу. Плавающие рамки используются чаще (чем обычные фреймы) для встраивания контента с другого web-сайта. Вы можете очень просто сделать плавающую рамку при помощи примерно такого кода:
<iframe src ="http://accounting.careerbuilder.com" width="100 %" height="300"> <p>Your browser does not support iframes.</p>Фреймы обычно используются для подразделения контента web-сайта, но их можно использовать и для встраивания контента с других web-сайтов, как это представлено на рис. 2.21 с сайтом http://accounting.careerbuilder.com на web-сайте Chicago Tribune.
</iframe>
Это пример хорошей работы по втягиванию контента (при условии, что у вас есть разрешение на это) с другого сайта и размещению его на вашем сайте. Однако поисковые движки распознают фрейм для втягивания контента другого сайта и соответственно игнорируют контент внутри фрейма (поскольку это контент другого издателя). Иначе говоря, они не считают втянутый с другого сайта контент частью уникального контента вашей web-страницы.
http://forums.searchenginewatch.com/showthread.php?threadid=48) для связывания терминов и начать понимать web-страницы более похожим на человеческий образом.
Профессиональному специалисту по оптимизации не обязательно применять инструменты измерения семантической связности для оптимизации web-сайтов, но для тех продвинутых специалистов, которые хотят использовать каждую возможность, измерения семантической связности могут помочь в следующих областях:
• измерение целевых ключевых фраз;
• измерение ключевых фраз для включения в страницу по определенной теме;
• измерение связей текста (на других сайтах с высоким рейтингом);
• поиск страниц, которые предоставляют релевантные ссылки по теме.
Несмотря на то, что источник этого материала имеет сугубо технический характер, специалисту по оптимизации нужно знать только принципы, чтобы получить эту ценную информацию. Важно помнить, что несмотря на то, что мир информационного поиска имеет сотни технических и часто трудных для понимания терминов, их можно разделить на группы, которые способен понять даже новичок в области оптимизации.
В табл. 2.1 объясняются некоторые часто встречающиеся типы информационного поиска.
Таблица 2.1. Часто встречающиеся типы поиска
 Модели информационного поиска (поисковые движки) используют теорию нечетких множеств (ответвление нечеткой логики, созданной доктором Lotfi Zadeh в 1969 г.) для обнаружения семантической связности между двумя словами. Вместо использования словаря для обоснования связи двух слов, система информационного поиска может применить свои большие базы данных контента для угадывания этой связи.
Модели информационного поиска (поисковые движки) используют теорию нечетких множеств (ответвление нечеткой логики, созданной доктором Lotfi Zadeh в 1969 г.) для обнаружения семантической связности между двумя словами. Вместо использования словаря для обоснования связи двух слов, система информационного поиска может применить свои большие базы данных контента для угадывания этой связи.
Несмотря на то, что этот процесс может показаться сложным, основы его просты. Поисковые движки полагаются на машинную логику (правда/ложь, да/нет и т. д.). Машинная логика имеет некоторые преимущества перед человеческой, но она не способна мыслить подобно человеку. И те вещи, которые интуитивно понятны человеку, может быть очень сложно понять компьютеру. Например, апельсины и бананы – это фрукты, но апельсины и бананы не круглые. Для человека это интуитивно понятно.
Чтобы машина поняла эту концепцию и подобные ей, ключом может стать семантическая связность. Огромные знания человечества (содержащиеся в Интернете) могут быть занесены в индекс системы и проанализированы, чтобы искусственным образом создать те связи, которые уже создали люди. Таким образом, машина узнает, что апельсин круглый, а банан – нет (потому что она просканировала тысячи вхождений в свой индекс слов "банан" и "апельсин" и заметила, что "круглый" и "банан" вместе встречаются редко, а "апельсин" и "круглый" вместе встречаются часто).
Именно здесь вступает в игру нечеткая логика и применение теории нечетких множеств помогает компьютеру понять, как термины связаны (путем измерения того, как часто и в каком контексте они используются вместе).
На этом понятии основана родственная концепция латентного семантического анализа (latent semantic analysis, LSA). Его идея состоит в том, что, взяв огромный составной индекс из миллиардов web-страниц, поисковый движок может "выучить", какие слова связаны и какие концепции имеют отношение друг к другу.
Например, используя LSA, поисковый движок поймет, что trips (путешествия) в zoo (зоопарк) часто включают в себя viewing wildlife и animals (наблюдение за дикой природой и животными), причем это может быть частью tour (тура).
Теперь выполним поиск в Google по ~zoo ~trips (тильда – это оператор поиска, подробнее об этом далее в этой же главе). Google выводит "связанные" термины жирным шрифтом и распознает, какие термины часто встречаются совместно (вместе, на одной странице, либо в непосредственной близости) в его индексах.
Некоторые формы LSA имеют слишком высокую вычислительную стоимость. Например, в настоящее время поисковые движки недостаточно "умны" для того, чтобы "обучаться" так же, как это делают некоторые более новые обучающиеся компьютеры в Массачусетском технологическом институте. Например, они не могут узнать из своего индекса, что зебры и тигры – это полосатые животные, хотя они могут обнаружить, что "полосы" и "зебры" более семантически связаны, чем "полосы" и" утки".
Латентное семантическое индексирование (latent semantic indexing, LSI) делает еще один шаг вперед, используя семантический анализ для идентификации связанных web-страниц. Например, поисковый движок может заметить одну страницу (в которой говорится о докторах) и другую (в которой говорится о терапевтах) и на основе других общих слов, имеющихся в этих двух страницах, определить, что между этими страницами есть связь. В результате страница с упоминанием докторов может быть показана по запросу, в котором используется слово терапевт.
В такие технологии в течение многих лет вкладываются деньги. Например, в апреле 2003 г. компания Google приобрела компанию Applied Semantics (http://www.appliedsemantics.com/), которая известна своей технологией семантической обработки текста. Эта технология теперь работает в рекламной программе AdSense компании Google и, скорее всего, применяется также и в основных алгоритмах поиска.
Все это дает нам общее понятие о том, как поисковые движки распознают связи между словами, фразами и идеями в сети Интернет. Поскольку семантическая связность играет все большую роль в алгоритмах поисковых движков, то можно ожидать и большего акцента на теме страниц, сайтов и ссылок. В будущем будет очень важно реализовать способность поисковых движков к пониманию идей и тем, а также к распознаванию контента, ссылок и страниц, которые не очень хорошо соответствуют схеме web-сайта.
Анализ ссылок
При анализе ссылок поисковый движок измеряет, кто делает ссылки на сайт (или страницу) и что там говорится об этом сайте (странице). Он также хорошо представляет, кто с кем связан партнерскими отношениями (при помощи исторических данных по ссылкам, регистрационных записей о сайтах и прочих источников), кому стоит доверять (по авторитету ссылающихся сайтов и контекстуальным данным о сайте, на котором находится страница), кто ссылается на этот сайт, что они говорят об этом сайте и т. д.
Анализ ссылок идет гораздо дальше, чем подсчет количества имеющихся на данную web-страницу (или сайт) ссылок, поскольку ссылки не одинаковы. Ссылки с высокоавторитетной страницы высокоавторитетного сайта будут значить больше, чем другие ссылки с меньшим авторитетом. Сайт или страница могут быть признаны авторитетными после комбинированного анализа шаблонов ссылок и семантического анализа.
Предположим, что вас интересуют сайты об уходе за собаками. Чтобы определить коллекцию web-страниц, которые посвящены теме ухода за собаками, поисковый движок может использовать семантический анализ. Затем поисковый движок может определить, какие из этих сайтов по уходу за собаками имеют больше всего ссылок со всего множества сайтов по уходу за собаками. Эти сайты, скорее всего, и являются наиболее авторитетными по данной теме.
Реально такой анализ несколько сложнее. Например, представьте себе, что есть пять сайтов по уходу за собаками, имеющих множество ссылок по данной теме со страниц по всему Интернету:
• сайт А имеет 213 тематических ссылок;
• сайт В имеет 192 тематические ссылки;
• сайт С имеет 203 тематические ссылки;
• сайт D имеет 113 тематических ссылок;
• сайт Е имеет 122 тематические ссылки.
Далее может оказаться так, что сайт А, сайт В, сайт D и сайт Е – все они ссылаются друг на друга, но ни один из них не ссылается на сайт С. Большинство тематических ссылок сайта С приходит с других страниц, которые тематически релевантны, но имеют мало ссылок. При таком сценарии сайт С определенно не является авторитетным, поскольку на него не ссылаются "правильные" сайты.
Эта концепция группирования сайтов по их релевантности называется "соседством ссылок" (link neighborhood). Ваши соседи говорят что-то по теме вашего сайта, а количество и качество ссылок от ваших соседей говорит о важности вашего сайта для данной темы.
Степень, в которой поисковый движок полагается на оценку "соседства ссылок", не ясна и, скорее всего, она у разных движков разная. Кроме того, ссылки с нерелевантных страниц все равно помогают рейтингу целевых страниц. Тем не менее основная идея такова: ссылка с релевантного сайта должна учитываться как более ценная, чем ссылка с нерелевантного сайта.
Еще один фактор определения ценности ссылки – это способ ее реализации и место размещения. Например, сам использованный для ссылки текст (тот реальный текст, который попадет на вашу web-страницу, когда пользователь щелкнет ссылку) также является сильным сигналом для поискового движка.
Это называется "якорным текстом” (anchor text). И если этот текст насыщен ключевыми словами (релевантными для терминов вашего поиска), то он сделает для ваших рейтингов в поисковых движках больше, чем если бы эта ссылка не была насыщена ключевыми словами. Например, якорный текст Dog Grooming Salon будет для сайта салона по уходу за собаками гораздо более ценным, чем якорный текст Click here. Однако будьте осторожны. Если у вас есть 10 000 ссылок с якорным текстом Dog Grooming Salon и очень мало других ссылок на ваш сайт, то это выглядит неестественно и может привести к проблемам с вашим рейтингом.
Семантический анализ ценности ссылки – это не только якорный текст. Например, если у вас есть якорный текст Dog Grooming Salon на той странице, которая совсем не об уходе за собаками, то ценность такой ссылки меньше, чем когда эта страница посвящена уходу за собаками. Поисковые движки смотрят и на содержимое страницы, находящееся вокруг ссылки, и на общий контекст, и на авторитет того web-сайта, который дает ссылку.
Все эти факторы являются компонентами анализа ссылок, который мы обсудим более подробно в главе 7.
Анализ ссылок идет гораздо дальше, чем подсчет количества имеющихся на данную web-страницу (или сайт) ссылок, поскольку ссылки не одинаковы. Ссылки с высокоавторитетной страницы высокоавторитетного сайта будут значить больше, чем другие ссылки с меньшим авторитетом. Сайт или страница могут быть признаны авторитетными после комбинированного анализа шаблонов ссылок и семантического анализа.
Предположим, что вас интересуют сайты об уходе за собаками. Чтобы определить коллекцию web-страниц, которые посвящены теме ухода за собаками, поисковый движок может использовать семантический анализ. Затем поисковый движок может определить, какие из этих сайтов по уходу за собаками имеют больше всего ссылок со всего множества сайтов по уходу за собаками. Эти сайты, скорее всего, и являются наиболее авторитетными по данной теме.
Реально такой анализ несколько сложнее. Например, представьте себе, что есть пять сайтов по уходу за собаками, имеющих множество ссылок по данной теме со страниц по всему Интернету:
• сайт А имеет 213 тематических ссылок;
• сайт В имеет 192 тематические ссылки;
• сайт С имеет 203 тематические ссылки;
• сайт D имеет 113 тематических ссылок;
• сайт Е имеет 122 тематические ссылки.
Далее может оказаться так, что сайт А, сайт В, сайт D и сайт Е – все они ссылаются друг на друга, но ни один из них не ссылается на сайт С. Большинство тематических ссылок сайта С приходит с других страниц, которые тематически релевантны, но имеют мало ссылок. При таком сценарии сайт С определенно не является авторитетным, поскольку на него не ссылаются "правильные" сайты.
Эта концепция группирования сайтов по их релевантности называется "соседством ссылок" (link neighborhood). Ваши соседи говорят что-то по теме вашего сайта, а количество и качество ссылок от ваших соседей говорит о важности вашего сайта для данной темы.
Степень, в которой поисковый движок полагается на оценку "соседства ссылок", не ясна и, скорее всего, она у разных движков разная. Кроме того, ссылки с нерелевантных страниц все равно помогают рейтингу целевых страниц. Тем не менее основная идея такова: ссылка с релевантного сайта должна учитываться как более ценная, чем ссылка с нерелевантного сайта.
Еще один фактор определения ценности ссылки – это способ ее реализации и место размещения. Например, сам использованный для ссылки текст (тот реальный текст, который попадет на вашу web-страницу, когда пользователь щелкнет ссылку) также является сильным сигналом для поискового движка.
Это называется "якорным текстом” (anchor text). И если этот текст насыщен ключевыми словами (релевантными для терминов вашего поиска), то он сделает для ваших рейтингов в поисковых движках больше, чем если бы эта ссылка не была насыщена ключевыми словами. Например, якорный текст Dog Grooming Salon будет для сайта салона по уходу за собаками гораздо более ценным, чем якорный текст Click here. Однако будьте осторожны. Если у вас есть 10 000 ссылок с якорным текстом Dog Grooming Salon и очень мало других ссылок на ваш сайт, то это выглядит неестественно и может привести к проблемам с вашим рейтингом.
Семантический анализ ценности ссылки – это не только якорный текст. Например, если у вас есть якорный текст Dog Grooming Salon на той странице, которая совсем не об уходе за собаками, то ценность такой ссылки меньше, чем когда эта страница посвящена уходу за собаками. Поисковые движки смотрят и на содержимое страницы, находящееся вокруг ссылки, и на общий контекст, и на авторитет того web-сайта, который дает ссылку.
Все эти факторы являются компонентами анализа ссылок, который мы обсудим более подробно в главе 7.
Проблемные слова, устранение неоднозначности, разнообразие
Обратная сторона монеты – это слова, которые представляют собой постоянную проблему для поисковых движков. Одна из самых больших трудностей – это устранение неоднозначностей. Например, когда кто-то пишет boxers, то что он имеет в виду? Боксеров, породу собак или тип трусов? Еще один пример такого же типа – jaguar, который одновременно обозначает ягуара, марку машины, футбольную команду, операционную систему и гитару. Что конкретно имел в виду пользователь?
Поисковые движки все время работают с такими неоднозначными запросами. Эти два приведенных примера содержат в себе врожденные проблемы, но данная проблема гораздо шире. Например, если кто-то пишет такой запрос, как cars, то что он хочет?
• Почитать обзоры?
• Отправиться на автомобильный салон?
• Купить автомобиль?
• Почитать о новых автомобильных технологиях?
Запрос cars настолько общий, что нет никакого реального способа понять намерение пользователя по одному только запросу. (Исключением являются те случаи, когда предыдущие запросы этого же пользователя дают дополнительные подсказки, которыми поисковый движок может воспользоваться для улучшения определения намерения пользователя.)
Именно поэтому поисковые движки предлагают разнообразные результаты. Например, на рис. 2.22 показан другой общий поиск (по GDP).
 Рис. 2.22. Пример разнообразных результатов
Рис. 2.22. Пример разнообразных результатов
Это приводит нас к важной концепции ранжирования. Возможно, что строгий анализ релевантности и популярности ссылок на рис. 2.22 сам по себе и не дал бы попадания страницы Investopedia.com на первую страницу результатов, но потребность в разнообразии привела к повышению рейтинга этой страницы.
Строгая система ранжирования на основе релевантности и важности могла бы выдать множество дополнительных страниц с правительственных сайтов, обсуждающих GDP (валовый национальный продукт) Соединенных Штатов. Однако большинство пользователей, вероятно, будут вполне удовлетворены уже показанными правительственными страницами и показ дополнительного их количества, скорее всего, не поднимет уровень удовлетворения результатами поиска.
Внесение некоторого разнообразия позволяет компании Google дать удовлетворительный ответ тем пользователям, которые ищут нечто отличное от правительственных страниц. Проведенное компанией Google тестирование показало, что такой подход с разнообразием приводит к повышению уровня удовлетворения ее пользователей.
Например, данные по поискам без внесения разнообразия показали меньший процент кликов в страницах SERP, большее количество уточнений запросов, и даже более высокий процент выполненных затем похожих операций поиска.
Когда Google действительно серьезно подходит к устранению неоднозначности, он идет другим путем. Посмотрите страницы SERP на рис. 2.23.
 Рис. 2.23. Устранение неоднозначности в поисковых запросах
Рис. 2.23. Устранение неоднозначности в поисковых запросах
Такие результаты с устранением неоднозначности появляются во многих поисках, когда Google думает, что пользователь ищет нечто такое, чего не выдает его запрос. Особенно часто они появляются для очень общих поисковых фраз.
Идея преднамеренного внесения разнообразия в алгоритм имеет смысл и может повысить удовлетворенность пользователей для таких запросов, как:
• названия компаний (когда пользователи хотят получить как положительные, так и отрицательные отзывы, помимо официальных сайтов компании);
• поиски по товарам (когда результаты предложений с сайтов электронной коммерции могут забить страницы SERP, а Google пытается дать обзоры и некоммерческий релевантный контент);
• поиски новостей и по политическим вопросам (когда разумно предоставить слово всем сторонам проблемы, а не только блогам лево– или праворадикальной ориентации, которые хорошо приманивают ссылки).
Например, когда есть срочная новость (такая, как землетрясение), то поисковые движки начинают получать запросы уже через секунды, а первые статьи появляются в Интернете уже через 15 минут.
Поисковые движки все время работают с такими неоднозначными запросами. Эти два приведенных примера содержат в себе врожденные проблемы, но данная проблема гораздо шире. Например, если кто-то пишет такой запрос, как cars, то что он хочет?
• Почитать обзоры?
• Отправиться на автомобильный салон?
• Купить автомобиль?
• Почитать о новых автомобильных технологиях?
Запрос cars настолько общий, что нет никакого реального способа понять намерение пользователя по одному только запросу. (Исключением являются те случаи, когда предыдущие запросы этого же пользователя дают дополнительные подсказки, которыми поисковый движок может воспользоваться для улучшения определения намерения пользователя.)
Именно поэтому поисковые движки предлагают разнообразные результаты. Например, на рис. 2.22 показан другой общий поиск (по GDP).
Это приводит нас к важной концепции ранжирования. Возможно, что строгий анализ релевантности и популярности ссылок на рис. 2.22 сам по себе и не дал бы попадания страницы Investopedia.com на первую страницу результатов, но потребность в разнообразии привела к повышению рейтинга этой страницы.
Строгая система ранжирования на основе релевантности и важности могла бы выдать множество дополнительных страниц с правительственных сайтов, обсуждающих GDP (валовый национальный продукт) Соединенных Штатов. Однако большинство пользователей, вероятно, будут вполне удовлетворены уже показанными правительственными страницами и показ дополнительного их количества, скорее всего, не поднимет уровень удовлетворения результатами поиска.
Внесение некоторого разнообразия позволяет компании Google дать удовлетворительный ответ тем пользователям, которые ищут нечто отличное от правительственных страниц. Проведенное компанией Google тестирование показало, что такой подход с разнообразием приводит к повышению уровня удовлетворения ее пользователей.
Например, данные по поискам без внесения разнообразия показали меньший процент кликов в страницах SERP, большее количество уточнений запросов, и даже более высокий процент выполненных затем похожих операций поиска.
Когда Google действительно серьезно подходит к устранению неоднозначности, он идет другим путем. Посмотрите страницы SERP на рис. 2.23.
Такие результаты с устранением неоднозначности появляются во многих поисках, когда Google думает, что пользователь ищет нечто такое, чего не выдает его запрос. Особенно часто они появляются для очень общих поисковых фраз.
Идея преднамеренного внесения разнообразия в алгоритм имеет смысл и может повысить удовлетворенность пользователей для таких запросов, как:
• названия компаний (когда пользователи хотят получить как положительные, так и отрицательные отзывы, помимо официальных сайтов компании);
• поиски по товарам (когда результаты предложений с сайтов электронной коммерции могут забить страницы SERP, а Google пытается дать обзоры и некоммерческий релевантный контент);
• поиски новостей и по политическим вопросам (когда разумно предоставить слово всем сторонам проблемы, а не только блогам лево– или праворадикальной ориентации, которые хорошо приманивают ссылки).
Когда новизна имеет значение
В основном поисковым движкам имеет смысл выдавать результаты из старых источников, которые прошли проверку временем. Однако в некоторых случаях результаты должны выдаваться из новых источников информации.Например, когда есть срочная новость (такая, как землетрясение), то поисковые движки начинают получать запросы уже через секунды, а первые статьи появляются в Интернете уже через 15 минут.