Однако дело обстоит не так просто. Если мы повысим концентрацию аминокислоты или же быстрее будем охлаждать раствор, избирательность синтеза сразу исчезает. Точной копии полимерной молекулы таким способом получит нельзя.
Причина этого – природа связей, которыми одиночные молекулы глутаминовой кислоты присоединяются к матричному полимеру. Такие связи называют водородными. Ион водорода наиболее электроположителен, поэтому он охотно образует связи с электроотрицательными партнерами (вспомните хотя бы ион аммония NH4+). Не будь водородных связей между молекулами воды, она кипе бы при гораздо более низкой температуре, лед бы тонул в воде, и уже поэтому жизнь на Земле была бы невозможной.
Но этого мало. Эффект водородных связей имеет для жизни гораздо большее значение. Именно они определяют так называемую вторичную структуру молекул белков и нуклеиновых кислот.
В белках водородные связи образуются между кислородом в группировке CO—NH и водородом в амидной группе NH. Остатки любых аминокислот могут реагировать с любыми же, водородные связи в белках неспецифичны. Именно поэтому матричный синтез полиглутаминовой кислоты теряет специфичность, как только мы пытаемся его ускорить. А непреложное условие точного матричного копирования – точное спаривание молекул.
Белки – плохие матрицы, и поэтому они не могут размножаться сами.
А нуклеиновые кислоты? Вспомним их строение. Это, как и белки, длинные молекулы полимеров. Но в отличие от белков звенья полимера – не аминокислоты, а нуклеотиды —сахара-пентозы, к которым присоединены азотистые основания – гуанин, аденин, цитозин и тимин (в РНК тимин заменяется урацилом). Связываются звенья нуклеотидов фосфодиэфирными связями остатка фосфорной кислоты H3PO4.
Полипептидные цепи белков могут соединяться попарно водородными связями – это так называемая бета-структура белка. Но, как уже упоминалось, эти связи неспецифичны. Иное дело нуклеиновые кислоты. Здесь термодинамически выгоднее образование пар аденин – тимин (или аденин – урацил) и гуанин – цитозин. Эти пары называют каноническими. Все другие в обычных условиях неустойчивы. Поэтому в двойной спирали ДНК против гуанина в одной цепи всегда стоит цитозин в другой, а против аденина – тимин. И когда на одиночной цепи, как на матрице, строится новая, точность синтеза оказывается удовлетворительной для передачи генетической информации из поколения в поколение.
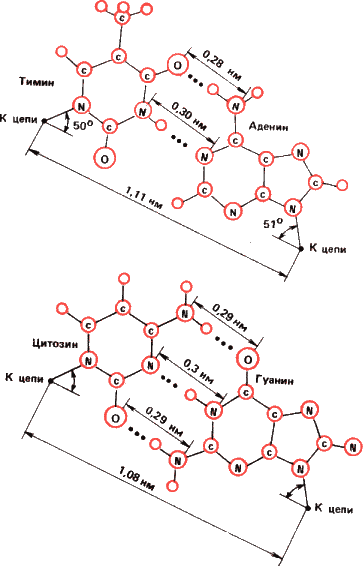
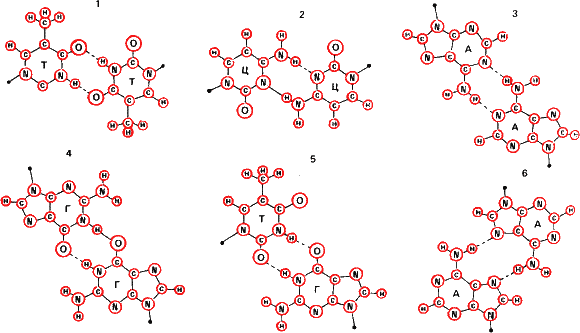 Рис 14. Почему матрицами жизни стали нуклеиновые кислоты? Потому что пары оснований А – Т (и А – У для комплексов ДНК – РНК и РНК – РНК) и Г – Ц наиболее термодинамически стабильны. Они показаны наверху, расстояние между основаниями дано в нанометрах, водородные связи показаны пунктиром. Все другие пары оснований (Т – Т. Ц – Ц, А – А, Г – Г, Т – Г), показанные на нижней часта рисунка, как минимум в десять раз менее прочны, чем пара А – Т и А – У. А пара Г – Ц самая стабильная из всех. Поэтому в точности спаривания оснований в ДНК и отсюда в точности матричного синтеза нет ничего удивительного или сверхъестественного. Это чистая термодинамика.
Рис 14. Почему матрицами жизни стали нуклеиновые кислоты? Потому что пары оснований А – Т (и А – У для комплексов ДНК – РНК и РНК – РНК) и Г – Ц наиболее термодинамически стабильны. Они показаны наверху, расстояние между основаниями дано в нанометрах, водородные связи показаны пунктиром. Все другие пары оснований (Т – Т. Ц – Ц, А – А, Г – Г, Т – Г), показанные на нижней часта рисунка, как минимум в десять раз менее прочны, чем пара А – Т и А – У. А пара Г – Ц самая стабильная из всех. Поэтому в точности спаривания оснований в ДНК и отсюда в точности матричного синтеза нет ничего удивительного или сверхъестественного. Это чистая термодинамика.
Мы видим существенное отличие от схемы Кольцова: согласно ей подобное притягивается к подобному, глутаминовая кислота – к остатку глутаминовой же кислоты в нашем опыте. При матрицировании ДНК (и РНК вирусов) притягиваются противоположные основания, комплементарные, образующие наиболее устойчивые пары с минимумом свободной энергии. Цепи в двойной спирали можно уподобить негативу и позитиву. Напомним, кстати, что и типографский шрифт, и печати, и чеканы для монет тоже не идентичные копии отпечатков, а их зеркальные отражения.
Как и при формулировке первой аксиомы, подчеркнем: главное не материальный субстрат, а матричный принцип его синтеза. Да, в земных условиях белки оказались плохими матрицами, а нуклеиновые кислоты хорошими. Но из этого не следует, что на других планетах во Вселенной дело обстоит так же. Гены там могут состоять из других соединений (каких, нам пока неведомо), но размножаться они должны, как и на Земле, матричным путем. Иначе мы опять попадем между преформизмом и эпигенезом, так что такая категоричность вполне обоснована.
Но мы живем на Земле. Поэтому сейчас мы должны вспомнить, как генетическая информация кодируется в нуклеиновых кислотах и как она трансформируется в молекулы белков. Это нам пригодится в дальнейшем. Рассмотрим принципы генетического кода – языка жизни. Ибо, как сказал Козьма Прутков: «…не зная законов языка ирокезского, можешь ли ты делать такое суждение по сему предмету, которое не было бы необоснованно и глупо?»
Алфавит белков. Уже говорилось, что аминокислотой может называться любое соединение, содержащее аминный(—NH2) и карбоксильный (—COOH) радикалы. Отсюда следует, что число возможных аминокислот должно быть очень велико, практически бесконечно. Тем более удивительно, что природа для построения белковых молекул использует из всего этого, не поддающегося учету разнообразия всего лишь двадцать аминокислот.
Это так называемые «магические». Может быть, по каким-то неясным причинам только они годятся для использования в жизненных процессах? Нет, аминокислоты, не входящие в число «магических», можно обнаружить в составе организмов, но только не в белках. Таковы, например, тироксин (известный гормон щитовидной железы) или же норвалин (α-аминомасляная кислота). Некоторые аминокислотные остатки, уже входя в состав белковой молекулы, модифицируются. Присоединив остаток фосфорной кислоты, серин превращается в фосфосерин (в казеине молока и пепсине желудочного сока).
Или же набор белковых аминокислот отражает их большую вероятность возникновения в период происхождения жизни? Трудно однозначно ответить на этот вопрос: ведь мы не можем точно восстановить условия, существовавшие на Земле четыре миллиарда лет назад. Однако в многочисленных опытах, моделировавших самые различные пути становления органических веществ из неорганических (таких, как вода, аммиак, углекислый газ, метан, водород и др.), удалось синтезировать большой набор аминокислот, гораздо более разнообразный, чем тот, который составляют двадцать «магических».
Да и сам анализ алфавита белков наводит на размышления. Все «магические» аминокислоты можно разделить на такие группы:
1. Производные углеводородов. В этом случае аминогруппа и кислотный радикал присоединяются к углеводороду из одного, двух, трех или четырех звеньев. Таковы глицин (Гли), аланин (Ала), валин (Вал), лейцин (Лей) и изолейцин (Илей). В дальнейшем мы будем пользоваться этими сокращениями.
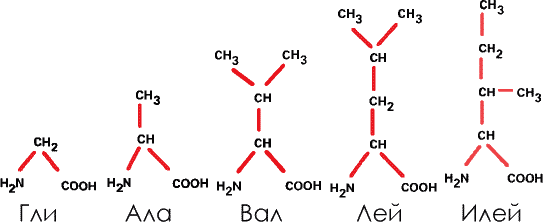
В эту группу входит единственная аминокислота, не содержащая асимметричного атома углерода (глицин). В прочих атомы углерода содержат разные радикалы, асимметричны, и потому эти аминокислоты могут быть представлены в правых и левых формах (а в белках – только в левых).
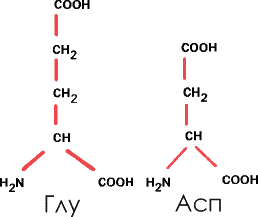
2. Кислые аминокислоты. Этот термин, напоминающий «масло масляное», означает, что они содержат еще один радикал —COOH, кроме того, который образует пептидную связь. Они и в белке сохраняют кислотные свойства. Это уже упоминавшаяся глутаминовая кислота (Глу) и аспарагиновая (Асп):
В некоторых белках вместо этих аминокислот имеются их амиды – глутамин и аспарагин. В таких случаях к боковой карбоксильной группе —COOH присоединяется молекула аммиака, и остаток вместо кислотных приобретает основные свойства:

Сокращенно их называют ГлуN и АспN, или же проще Глн и Асн. Так что, строго говоря, выражение «двадцать магических аминокислот» не совсем точно. В счет их входят и две простые аминокислоты и два их амида.
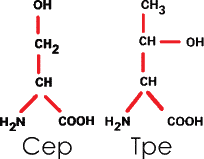
З. Содержащие оксигруппу —OH. Таковы серин (Сер) и треонин (Тре):
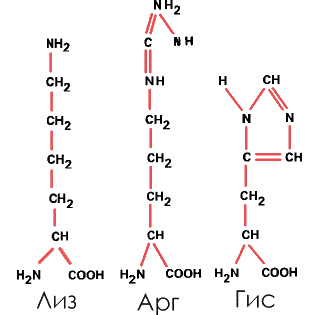
4. Основные – с аминогруппой в боковом радикале. Таковы лизин (Лиз), аргинин (Арг) и более сложная, содержащая имидазольную группу аминокислота гистидин (Гис):
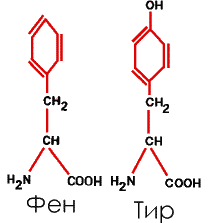
5. Ароматические, с бензольными кольцами в боковых радикалах – фенилаланин (Фен или Фал) и тирозин (Тир)
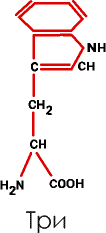
6. Группа гетероциклических (индолсодержащих) аминокислот включает лишь триптофан (Три):
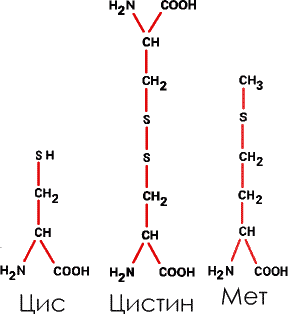
7. Зато целых три аминокислоты содержат в боковых радикалах атомы серы – это цистеин (Цис) цистин (димер цистеина, две молекулы цистеина «сросшиеся» вместе) и метионин (Мет):
8. И наконец, две аминокислоты, которым, строго говоря, не хватает одного атома водорода, чтобы так называться. У них аминная группа превращается в иминную, образуя пиррольное кольцо. Таковы иминокислоты пролин (Про) и его производное – оксипролин, то есть пролин, содержащий оксигруппу —OH:
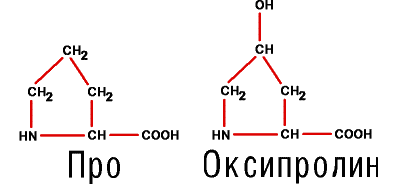
Добавим, что оксипролин и цистин возникают уже в белке из пролина и цистеина.
Вот из этих-то двадцати букв аминокислотного алфавита возникло чудовищное, не поддающееся учету разнообразие белковых молекул. Все могут белки: ускорять химические реакции и быть материалом для шерсти, волос и рога, переносить кислород железо и медь убивать бактерии, обезвреживать вирусы и яды, слагать оболочки клеток и распознавать другие клетки, сокращать мускулы и вызывать холодное свечение клеток. Одного не могут – размножаться сами. Информация об аминокислотных последовательностях в белках закодирована в нуклеотидных последовательностях ДНК и РНК.
И глядя на набор «магических» аминокислот, трудно отделаться от впечатления, что этот выбор природы случаен. Так уж получилось, что первые нуклеиновые кислоты приобрели способность к матричному синтезу полипептидных цепочек из двадцати магических». И этого оказалось достаточно, дальнейшее обогащение алфавита было просто не нужно.
А вот почему все аминокислоты в белках левые? Так, по-видимому, удобнее для матричного синтеза. Некоторые организмы синтезируют довольно сложные пептидные цепочки специального назначения нематричным путем. Таковы, например, некоторые антибиотики типа грамицидина или же пептиды, слагающие оболочки бактерий. В них жесткие запреты матричного синтеза снимаются, используются иные аминокислоты, кроме «магических», как в левой, так и в правой форме.
Вот как выглядит молекула грамицидина С:
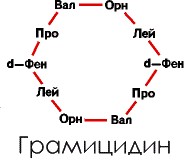
Достаточно одного взгляда на схему этой кольцевой молекулы, чтобы убедиться в невозможности ее синтеза на нуклеиновой матрице. Ведь в нее входят два остатка орнитина (Орн) – аминокислоты, не числящейся в магических и правый фенилаланин (d – фен). Действительно, синтезируют грамицидин С два фермента: один соединяет в цепочки две пятичленные последовательности, а другой сшивает их в кольцо. Вот эти ферменты синтезируются уже «настоящим» матричным путем.
Или же когда мы обнаруживаем в стенках капсул сибиреязвенной бациллы полипептид, состоящий из глутаминовой кислоты, мы вправе предположить, что он синтезируется нематричным путем. Ведь, во-первых, глутаминовая кислота в нем правая, во-вторых, пептидная связь образована в нем боковой (так называемой γ – карбоксильной) группой.
Но эти, как и другие подобные примеры, лишь подтверждают важность матричного синтеза. Без ферментов и здесь дело не обходится. И мы переходим к важному вопросу: молекулы белков состоят из двадцати аминокислот (точнее, аминокислотных остатков) в разных комбинациях. Молекулы нуклеиновых кислот собраны из четырех сортов нуклеиновых оснований. Каким сочетанием нуклеотидов в ДНК кодируется каждая из аминокислот? Каковы принципы генетического кода?
Генетический код. При слове «код» у любителей приключенческой литературы возникают определенные ассоциации. Но принцип кодирования известен не только разведчикам.
Каждый грамотный человек всю жизнь занимается перекодировкой информации.
Наше письмо – тоже код, в котором определенные символы-буквы соответствуют определенным звукам. В этом смысле можно уподобить буквы сочетаниям нуклеотидов в ДНК, а звуки – аминокислотам в белке. Между буквой и звуком нет какого-либо соответствия, кроме исторического. В этом и есть принцип кодирования. На пример, почему звук «А» мы обозначаем соответствующей буквой? Только потому, что древние греки позаимствовали из алфавита финикийцев знак α (видоизмененный знак – от семитского «алеф» – бык.[5]
 Это схематический рисунок головы быка). Если бы наши предки-славяне придумали алфавит сами, этот символ означал бы, наверное, не «А», а «Б» (бык) или «Г» (говядо – древнеславянское «бык»). Обозначают же японцы в своей слоговой азбуке – катакане звук «А» символом
Это схематический рисунок головы быка). Если бы наши предки-славяне придумали алфавит сами, этот символ означал бы, наверное, не «А», а «Б» (бык) или «Г» (говядо – древнеславянское «бык»). Обозначают же японцы в своей слоговой азбуке – катакане звук «А» символом
 – и ничего, понимают, потому что знают этот код. Так же как знаем свой код мы и как нуклеиновый код «знают» белоксинтезирующие системы клетки. Я подчеркиваю: именно клетки, потому что бесклеточные формы жизни – вирусы при стройке своих белков используют белоксинтезирующие системы хозяев.
– и ничего, понимают, потому что знают этот код. Так же как знаем свой код мы и как нуклеиновый код «знают» белоксинтезирующие системы клетки. Я подчеркиваю: именно клетки, потому что бесклеточные формы жизни – вирусы при стройке своих белков используют белоксинтезирующие системы хозяев.
Так как «магических» аминокислот двадцать, а оснований нуклеиновых кислотах всего четыре ясно, что каждое звено белковой цепи кодируется несколькими нуклеотидными звеньями, а именно тремя. Число сочетаний из четырех по три равняется 64. Стало быть, в коде ДНК 64 «буквы». Три из них соответствуют пробелам в типографском наборе. В средние века текст писали сплошняком, без пробелов, что, наверное, затрудняло чтение и сейчас создает трудности при расшифровке. Так, написанную слитно фразу из «Слова о полке Игореве» «исхотиюнакроватьирек» толковали «и схоти ю на кровать и рек…» или же «и схоти юнак ров (то есть могила. – Б. М.) а тьи рек». Если же сплошняком будет набран аминокислотный текст, смысла в подобном синтезе не будет. На бессмысленных, не соответствующим никаким аминокислотам сочетаниях нуклеотидов синтез обрывается – полипептидная цепочка готова.
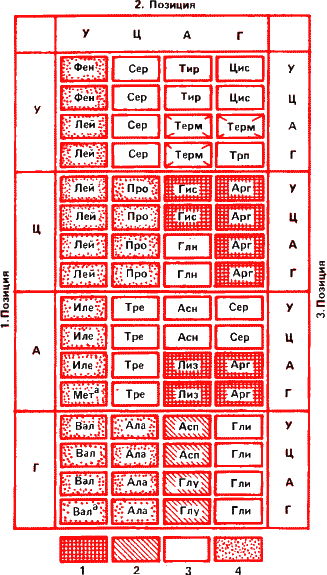 Рис. 16. Быть может, величайшее достижение биологии ХХ века – расшифровка генетического кода. На таблице показано, каким аминокислотам в белке соответствуют триплеты нуклеотидов в матричной РНК. Например, если в первой позиции стоит урацил, во второй цитозин и в третьей гуанин, то это сочетание кодирует аминокислоту серин. 1 – аминокислоты с положительно заряженной боковой цепью; 2 – отрицательно заряженные; З – полярные (имеющие сродство к молекулам воды); 4 – неполярные, гидрофобные, отталкивающие воду. Терм – терминирующие бессмысленные кодоны. На них синтез белка прерывается.
Рис. 16. Быть может, величайшее достижение биологии ХХ века – расшифровка генетического кода. На таблице показано, каким аминокислотам в белке соответствуют триплеты нуклеотидов в матричной РНК. Например, если в первой позиции стоит урацил, во второй цитозин и в третьей гуанин, то это сочетание кодирует аминокислоту серин. 1 – аминокислоты с положительно заряженной боковой цепью; 2 – отрицательно заряженные; З – полярные (имеющие сродство к молекулам воды); 4 – неполярные, гидрофобные, отталкивающие воду. Терм – терминирующие бессмысленные кодоны. На них синтез белка прерывается.
Остальные 61 триплет (кодон) соответствуют 20 аминокислотам. Такой код, когда несколько букв читаются одинаково, называется вырожденным. Например, лейцин, серин и аргинин кодируются шестью триплетами; пролин, валин и глицин – четырьмя; изолейцин – тремя; аспарагиновая и глутаминовая кислоты – двумя, а для метионина имеется лишь один кодон. Он же, если стоит в начале гена, исполняет роль заглавной буквы.
Это похоже на ситуацию в дореволюционном русском алфавите: тогда существовало два символа для звука «ф» (ферт и фита) и целых три для «и» («и» просто, «и» с точкой и ижица).
Первые исследователи полагали, что аминокислотные цепочки прямо собираются на нуклеотидных цепочках. Дело оказалось гораздо сложнее.
Во-первых, нет никакого стерического (морфологического) соответствия между кодоном и той аминокислотой, которую он кодирует. Соответствие между ним и достигается молекулой особой нуклеиновой кислоты, которую называли по-разному: РНК – посредник, адаптор, растворимая и, наконец, транспортная. На одном ее конце присоединена аминокислота, а на другом расположена последовательность комплементарная кодону (антикодон).
Во-вторых, матрицей для белкового синтеза служит не непосредственно ДНК, а копируемый с нее «рабочий чертеж» – РНК, получившая название информационной или матричной (мРНК).
Итак, мы должны различать процессы: матрицирование самого гена, то есть синтез ДНК на ДНК, синтез мРНК на ДНК и синтез белка на матрице мРНК. Первый процесс называется репликацией, второй – транскрипцией и третий – трансляцией.
Еще короче это выражается в так называемой «центральной догме» молекулярной биологии:
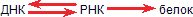
В предисловии я обещал строго придерживаться того набора фактов, которого требует школьная программа. Однако некоторые положения в ней излагаются слишком сжато, иные неверно, а многие любопытные достижения последних лет просто еще не дошли до учебников. Теперь самое время на них остановиться.
Полярность гена. Длинные цепочечные молекулы биополимеров – полипептидов и нуклеиновых кислот – полярны. Иными словами начало и конец цепи аминокислотных остатков и нуклеотидов различаются друг от друга.
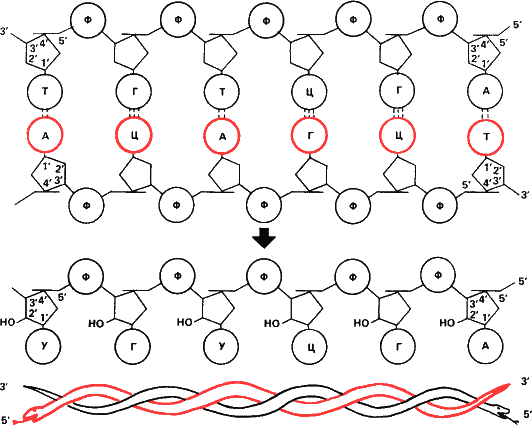 Рис. 15. Схема строения двухцепочечной ДНК и комплементарной ей РНК. Для простоты ДНК показана не закрученной в спираль, какой она обычно бывает в клетке. Такой участок может кодировать две аминокислоты – серин и цистеин. Ф – остаток фосфорной кислоты, А, Г, Ц, Т, У соответственно аденин, гуанин, цитозин, тимин, и урацил. Нетрудно видеть что смысловая цепь и комплементарная ей антипараллельны. 3’– конец одной стыкуется с 5’-концом другой. Синтез матричной РНК начинается 3’– конца смысловой цепи. Следовательно мРНК Нужно «читать» с 5’-конца. С него и начинается белковый синтез. Нагляднее принцип антипараллельности цепей дан на шуточной схеме внизу. Теперь представим себе, что обе нарисованные внизу змеи свернутся в кольцо и каждая возьмет в зубы собственный хвост, и мы получим точную копию кольцевой хромосомы некоторых фагов и бактерий.
Рис. 15. Схема строения двухцепочечной ДНК и комплементарной ей РНК. Для простоты ДНК показана не закрученной в спираль, какой она обычно бывает в клетке. Такой участок может кодировать две аминокислоты – серин и цистеин. Ф – остаток фосфорной кислоты, А, Г, Ц, Т, У соответственно аденин, гуанин, цитозин, тимин, и урацил. Нетрудно видеть что смысловая цепь и комплементарная ей антипараллельны. 3’– конец одной стыкуется с 5’-концом другой. Синтез матричной РНК начинается 3’– конца смысловой цепи. Следовательно мРНК Нужно «читать» с 5’-конца. С него и начинается белковый синтез. Нагляднее принцип антипараллельности цепей дан на шуточной схеме внизу. Теперь представим себе, что обе нарисованные внизу змеи свернутся в кольцо и каждая возьмет в зубы собственный хвост, и мы получим точную копию кольцевой хромосомы некоторых фагов и бактерий.
Нетрудно сообразить, почему полярны полипептиды, слагающие белки. Уже упоминалось, что аминокислоты имеют две функциональные группировки, сшивающие их в полипептид, – аминную и карбоксильную. Значит, у первого звена аминокислотной последовательности остается свободной аминная группа (—NH2), а у последнего – карбоксильная (—COOH). Так и говорят: N – конец и C – конец полипептида.
Полярны и нуклеиновые кислоты, но по другой причине. Остов как РНК, так и ДНК —пятичленные сахара – пентозы, сшитые остатками фосфорной кислоты (фосфодиэфирные связи). Чтобы различать атомы углерода в пятиугольнике пентозы, химики пронумеровали их, считая от того, к которому присоединено азотистое основание. Оказалось, что в природных нуклеиновых кислотах фосфодиэфирные связи образуются только между третьими и пятыми атомами углерода в пентозах (сокращенно: 3’ и 5’; читается: «три-штрих» и «пять-штрих»). Поэтому на одном конце любой нуклеиновой кислоты сахар присоединен к цепи 3’-атомом, на другом – 5’.
А теперь зададимся вопросом: в какую сторону «читается» ген – к 3’ или 5’? Теперь, когда генные инженеры уверенно расшифровывают нуклеотидные последовательности и синтезируют их, это вопрос отнюдь не праздный.
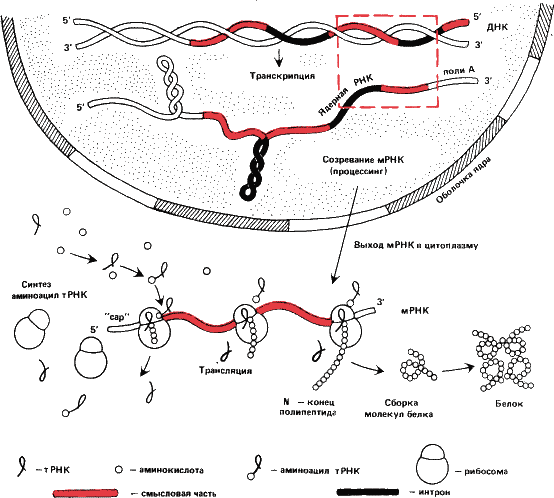
Рис. 17. Упрощенная схема передачи генетической информации с ДНК на белок. С находящейся в ядре ДНК снимается «рабочая копия» гена – гетерогенная ядерная РНК (этот процесс называется транскрипцией). Значительная, как правило, большая ее часть не кодирует аминокислотных последовательностей и отрезается ферментами – эндонуклеазами и отбрасывается. Тогда же вырезаются и «нечитаемые» вставки – интроны. Созревшая мРНК, получившая «шапочку» (cap – англ.) на 5’-конце и полиадениловую последовательность на З’-конце, через пору в ядерной оболочке выходит в цитоплазму (часто в виде комплексов с белком – информофер или информосом, на рисунке не показанных). В цитоплазме информация считывается с мРНК белоксинтезирующими аппаратами клетки – рибосомами (трансляция). Рибосомы гуськом идут по мРНК: каждый раз, когда рибосома смещается на три нуклеотида к З’-концу, к растущей полипептидной цепи прибавляется один аминокислотный остаток. Аминокислоты доставляются к рибосомам молекулами транспортной РНК (мРНК). Отдав аминокислоту, мРНК образует снова комплекс (аминоацил – мРНК) с другой и снова вовлекается в процесс. Полипептидная цепочка, оборвавшись на бессмысленном, терминирующем кодоне, свертывается специфичным образом. Это вторичная структура белка, поддерживаемая водородными связями; обычно это однонитчатая спираль (спираль Полинга – Кори). Спираль, в свою очередь, складывается, образуя третичную структуру. Наконец, многие белки состоят из более чем одной полипептидной цепи. Таков, например, гемоглобин, молекула которого состоит из четырех субъединиц. Это четвертичная структура.
Установлено, что полипептидные цепи в клетках синтезируются от N – конца к C – концу. Значит, у матричной РНК начало там, где кодируется N- конец. Оно соответствует 5’-концу РНК. В двойной спирали ДНК разобраться труднее. Дело в том, что слагающие ее нуклеотидные цепочки направлены в разные стороны, как говорят, антипараллельны. Иными словами, одна цепь направлена в сторону З’—5’, а другая 5’—З’.
Смысловая цепь, в которой закодирована аминокислотная последовательность «считывается» ферментом РНК-полимеразой с З’-конца. Образующаяся при этом мРНК, естественно, оказывается точным аналогом комплементарной цепи и будет начинаться с 5’-конца, с того, с которого начинается трансляция, то есть белковый синтез.
Но ведь с гена снимается не только «рабочий чертеж» мРНК. Ген и реплицируется, передаваясь из поколения в поколение, от матричной клетки к дочерним. Осуществляет этот процесс – репликацию – фермент ДНК полимераза.
Считается, что молекула ДНК-полимеразы садится на ДНК и движется по ней. При этом удваивается и смысловая цепь, и комплементарная к ней. Значит репликация смысловой цепи начинается с 3’-конца, как и транскрипция. Это аналогично тому как если бы мы перепечатывали текст с конца, а читали его, как и водится, с начала. В учебниках и популярных изданиях на это, как правило, не обращают внимания.
Последние годы ознаменовались сенсационными открытиями в изучении процессов репликации и трансляции. Природа подносила нам сюрприз каждый раз, когда начинало казаться, что уж теперь мы знаем об этих явлениях все.
Вот некоторые из сенсаций, за молодостью не попавшие в учебники.
Справедлива ли центральная догма? Мы уже упоминали, что генетическая информация передается от ДНК через РНК на белок, но не в обратную сторону. Это положение назвали центральной догмой молекулярной биологии. РНК-содержащие вирусы ее не нарушают. Просто у них выпадает начальное звено этой цели – ДНК. Генетическая информация передается из поколения в поколение закодированной в последовательностях РНК, с них же и считывается белок.
В принципе разница между ДНК и РНК не так уж и велика. Пентознофосфатный остов у РНК образует другой сахар – рибоза, который отличается от дезоксирибозы лишь наличием гидроксильной группы (OH). Набор оснований тот же, за тем исключением, что вместо тимина (5-метилурацила) в РНК содержится урацил (тот же тимин, только неметилированный). Недаром в природе встречаются ДНК, в состав которых входят и дезоксирибозы и рибозы. Такова, например, ДНК вируса герпеса, от которого на губах «высыпает лихорадка». Энергетические фабрики клеток – митохондрии – в значительной степени генетически автономны от ядра, они имеют свой геном, похожий на бактериальный. ДНК этого генома также содержит рибозу – от десяти до тридцати остатков на молекулу.
Все это не нарушало стройную догму. Тем большее смятение вызвало открытие синтеза ДНК на РНК. С. М. Гершензон писал еще в 1960 году о возможности подобного процесса, однако лишь сравнительно недавно был получен в значительных количествах фермент ревертаза (обратная транскриптаза), осуществляющий эту реакцию. Теперь этот фермент – обычный инструмент генных инженеров. Теперь мы можем дополнить центральную догму:
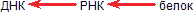
Например, РНК-содержащий вирус птичьего миэлобластоза может в результате обратной транскрипции стать ДНК-содержащим, встроиться в геном цыпленка и вызвать злокачественное перерождение клеток. Какую роль играет синтез ДНК на нити РНК в мире высших организмов, нам пока еще неизвестно.
Смысловая цепь: одна или две? Каких-нибудь пять лет назад все мы были твердо уверены, что матричная РНК синтезируется только на одной из двух цепей ДНК, получившей название смысловой. Вторая, комплементарная ей цепь нужна лишь для репликации ДНК и репарации – «починки» поврежденных участков. Если, например, жесткая радиация вырвет кусок из одной из цепей двойной спирали, специальные ферменты – репаразы заполняют брешь, пристроив на ее месте последовательность нуклеотидов, комплементарную оставшейся.
Причина этого – природа связей, которыми одиночные молекулы глутаминовой кислоты присоединяются к матричному полимеру. Такие связи называют водородными. Ион водорода наиболее электроположителен, поэтому он охотно образует связи с электроотрицательными партнерами (вспомните хотя бы ион аммония NH4+). Не будь водородных связей между молекулами воды, она кипе бы при гораздо более низкой температуре, лед бы тонул в воде, и уже поэтому жизнь на Земле была бы невозможной.
Но этого мало. Эффект водородных связей имеет для жизни гораздо большее значение. Именно они определяют так называемую вторичную структуру молекул белков и нуклеиновых кислот.
В белках водородные связи образуются между кислородом в группировке CO—NH и водородом в амидной группе NH. Остатки любых аминокислот могут реагировать с любыми же, водородные связи в белках неспецифичны. Именно поэтому матричный синтез полиглутаминовой кислоты теряет специфичность, как только мы пытаемся его ускорить. А непреложное условие точного матричного копирования – точное спаривание молекул.
Белки – плохие матрицы, и поэтому они не могут размножаться сами.
А нуклеиновые кислоты? Вспомним их строение. Это, как и белки, длинные молекулы полимеров. Но в отличие от белков звенья полимера – не аминокислоты, а нуклеотиды —сахара-пентозы, к которым присоединены азотистые основания – гуанин, аденин, цитозин и тимин (в РНК тимин заменяется урацилом). Связываются звенья нуклеотидов фосфодиэфирными связями остатка фосфорной кислоты H3PO4.
Полипептидные цепи белков могут соединяться попарно водородными связями – это так называемая бета-структура белка. Но, как уже упоминалось, эти связи неспецифичны. Иное дело нуклеиновые кислоты. Здесь термодинамически выгоднее образование пар аденин – тимин (или аденин – урацил) и гуанин – цитозин. Эти пары называют каноническими. Все другие в обычных условиях неустойчивы. Поэтому в двойной спирали ДНК против гуанина в одной цепи всегда стоит цитозин в другой, а против аденина – тимин. И когда на одиночной цепи, как на матрице, строится новая, точность синтеза оказывается удовлетворительной для передачи генетической информации из поколения в поколение.
Мы видим существенное отличие от схемы Кольцова: согласно ей подобное притягивается к подобному, глутаминовая кислота – к остатку глутаминовой же кислоты в нашем опыте. При матрицировании ДНК (и РНК вирусов) притягиваются противоположные основания, комплементарные, образующие наиболее устойчивые пары с минимумом свободной энергии. Цепи в двойной спирали можно уподобить негативу и позитиву. Напомним, кстати, что и типографский шрифт, и печати, и чеканы для монет тоже не идентичные копии отпечатков, а их зеркальные отражения.
Как и при формулировке первой аксиомы, подчеркнем: главное не материальный субстрат, а матричный принцип его синтеза. Да, в земных условиях белки оказались плохими матрицами, а нуклеиновые кислоты хорошими. Но из этого не следует, что на других планетах во Вселенной дело обстоит так же. Гены там могут состоять из других соединений (каких, нам пока неведомо), но размножаться они должны, как и на Земле, матричным путем. Иначе мы опять попадем между преформизмом и эпигенезом, так что такая категоричность вполне обоснована.
Но мы живем на Земле. Поэтому сейчас мы должны вспомнить, как генетическая информация кодируется в нуклеиновых кислотах и как она трансформируется в молекулы белков. Это нам пригодится в дальнейшем. Рассмотрим принципы генетического кода – языка жизни. Ибо, как сказал Козьма Прутков: «…не зная законов языка ирокезского, можешь ли ты делать такое суждение по сему предмету, которое не было бы необоснованно и глупо?»
Алфавит белков. Уже говорилось, что аминокислотой может называться любое соединение, содержащее аминный(—NH2) и карбоксильный (—COOH) радикалы. Отсюда следует, что число возможных аминокислот должно быть очень велико, практически бесконечно. Тем более удивительно, что природа для построения белковых молекул использует из всего этого, не поддающегося учету разнообразия всего лишь двадцать аминокислот.
Это так называемые «магические». Может быть, по каким-то неясным причинам только они годятся для использования в жизненных процессах? Нет, аминокислоты, не входящие в число «магических», можно обнаружить в составе организмов, но только не в белках. Таковы, например, тироксин (известный гормон щитовидной железы) или же норвалин (α-аминомасляная кислота). Некоторые аминокислотные остатки, уже входя в состав белковой молекулы, модифицируются. Присоединив остаток фосфорной кислоты, серин превращается в фосфосерин (в казеине молока и пепсине желудочного сока).
Или же набор белковых аминокислот отражает их большую вероятность возникновения в период происхождения жизни? Трудно однозначно ответить на этот вопрос: ведь мы не можем точно восстановить условия, существовавшие на Земле четыре миллиарда лет назад. Однако в многочисленных опытах, моделировавших самые различные пути становления органических веществ из неорганических (таких, как вода, аммиак, углекислый газ, метан, водород и др.), удалось синтезировать большой набор аминокислот, гораздо более разнообразный, чем тот, который составляют двадцать «магических».
Да и сам анализ алфавита белков наводит на размышления. Все «магические» аминокислоты можно разделить на такие группы:
1. Производные углеводородов. В этом случае аминогруппа и кислотный радикал присоединяются к углеводороду из одного, двух, трех или четырех звеньев. Таковы глицин (Гли), аланин (Ала), валин (Вал), лейцин (Лей) и изолейцин (Илей). В дальнейшем мы будем пользоваться этими сокращениями.
В эту группу входит единственная аминокислота, не содержащая асимметричного атома углерода (глицин). В прочих атомы углерода содержат разные радикалы, асимметричны, и потому эти аминокислоты могут быть представлены в правых и левых формах (а в белках – только в левых).
2. Кислые аминокислоты. Этот термин, напоминающий «масло масляное», означает, что они содержат еще один радикал —COOH, кроме того, который образует пептидную связь. Они и в белке сохраняют кислотные свойства. Это уже упоминавшаяся глутаминовая кислота (Глу) и аспарагиновая (Асп):
В некоторых белках вместо этих аминокислот имеются их амиды – глутамин и аспарагин. В таких случаях к боковой карбоксильной группе —COOH присоединяется молекула аммиака, и остаток вместо кислотных приобретает основные свойства:
Сокращенно их называют ГлуN и АспN, или же проще Глн и Асн. Так что, строго говоря, выражение «двадцать магических аминокислот» не совсем точно. В счет их входят и две простые аминокислоты и два их амида.
З. Содержащие оксигруппу —OH. Таковы серин (Сер) и треонин (Тре):
4. Основные – с аминогруппой в боковом радикале. Таковы лизин (Лиз), аргинин (Арг) и более сложная, содержащая имидазольную группу аминокислота гистидин (Гис):
5. Ароматические, с бензольными кольцами в боковых радикалах – фенилаланин (Фен или Фал) и тирозин (Тир)
6. Группа гетероциклических (индолсодержащих) аминокислот включает лишь триптофан (Три):
7. Зато целых три аминокислоты содержат в боковых радикалах атомы серы – это цистеин (Цис) цистин (димер цистеина, две молекулы цистеина «сросшиеся» вместе) и метионин (Мет):
8. И наконец, две аминокислоты, которым, строго говоря, не хватает одного атома водорода, чтобы так называться. У них аминная группа превращается в иминную, образуя пиррольное кольцо. Таковы иминокислоты пролин (Про) и его производное – оксипролин, то есть пролин, содержащий оксигруппу —OH:
Добавим, что оксипролин и цистин возникают уже в белке из пролина и цистеина.
Вот из этих-то двадцати букв аминокислотного алфавита возникло чудовищное, не поддающееся учету разнообразие белковых молекул. Все могут белки: ускорять химические реакции и быть материалом для шерсти, волос и рога, переносить кислород железо и медь убивать бактерии, обезвреживать вирусы и яды, слагать оболочки клеток и распознавать другие клетки, сокращать мускулы и вызывать холодное свечение клеток. Одного не могут – размножаться сами. Информация об аминокислотных последовательностях в белках закодирована в нуклеотидных последовательностях ДНК и РНК.
И глядя на набор «магических» аминокислот, трудно отделаться от впечатления, что этот выбор природы случаен. Так уж получилось, что первые нуклеиновые кислоты приобрели способность к матричному синтезу полипептидных цепочек из двадцати магических». И этого оказалось достаточно, дальнейшее обогащение алфавита было просто не нужно.
А вот почему все аминокислоты в белках левые? Так, по-видимому, удобнее для матричного синтеза. Некоторые организмы синтезируют довольно сложные пептидные цепочки специального назначения нематричным путем. Таковы, например, некоторые антибиотики типа грамицидина или же пептиды, слагающие оболочки бактерий. В них жесткие запреты матричного синтеза снимаются, используются иные аминокислоты, кроме «магических», как в левой, так и в правой форме.
Вот как выглядит молекула грамицидина С:
Достаточно одного взгляда на схему этой кольцевой молекулы, чтобы убедиться в невозможности ее синтеза на нуклеиновой матрице. Ведь в нее входят два остатка орнитина (Орн) – аминокислоты, не числящейся в магических и правый фенилаланин (d – фен). Действительно, синтезируют грамицидин С два фермента: один соединяет в цепочки две пятичленные последовательности, а другой сшивает их в кольцо. Вот эти ферменты синтезируются уже «настоящим» матричным путем.
Или же когда мы обнаруживаем в стенках капсул сибиреязвенной бациллы полипептид, состоящий из глутаминовой кислоты, мы вправе предположить, что он синтезируется нематричным путем. Ведь, во-первых, глутаминовая кислота в нем правая, во-вторых, пептидная связь образована в нем боковой (так называемой γ – карбоксильной) группой.
Но эти, как и другие подобные примеры, лишь подтверждают важность матричного синтеза. Без ферментов и здесь дело не обходится. И мы переходим к важному вопросу: молекулы белков состоят из двадцати аминокислот (точнее, аминокислотных остатков) в разных комбинациях. Молекулы нуклеиновых кислот собраны из четырех сортов нуклеиновых оснований. Каким сочетанием нуклеотидов в ДНК кодируется каждая из аминокислот? Каковы принципы генетического кода?
Генетический код. При слове «код» у любителей приключенческой литературы возникают определенные ассоциации. Но принцип кодирования известен не только разведчикам.
Каждый грамотный человек всю жизнь занимается перекодировкой информации.
Наше письмо – тоже код, в котором определенные символы-буквы соответствуют определенным звукам. В этом смысле можно уподобить буквы сочетаниям нуклеотидов в ДНК, а звуки – аминокислотам в белке. Между буквой и звуком нет какого-либо соответствия, кроме исторического. В этом и есть принцип кодирования. На пример, почему звук «А» мы обозначаем соответствующей буквой? Только потому, что древние греки позаимствовали из алфавита финикийцев знак α (видоизмененный знак – от семитского «алеф» – бык.[5]
Так как «магических» аминокислот двадцать, а оснований нуклеиновых кислотах всего четыре ясно, что каждое звено белковой цепи кодируется несколькими нуклеотидными звеньями, а именно тремя. Число сочетаний из четырех по три равняется 64. Стало быть, в коде ДНК 64 «буквы». Три из них соответствуют пробелам в типографском наборе. В средние века текст писали сплошняком, без пробелов, что, наверное, затрудняло чтение и сейчас создает трудности при расшифровке. Так, написанную слитно фразу из «Слова о полке Игореве» «исхотиюнакроватьирек» толковали «и схоти ю на кровать и рек…» или же «и схоти юнак ров (то есть могила. – Б. М.) а тьи рек». Если же сплошняком будет набран аминокислотный текст, смысла в подобном синтезе не будет. На бессмысленных, не соответствующим никаким аминокислотам сочетаниях нуклеотидов синтез обрывается – полипептидная цепочка готова.
Остальные 61 триплет (кодон) соответствуют 20 аминокислотам. Такой код, когда несколько букв читаются одинаково, называется вырожденным. Например, лейцин, серин и аргинин кодируются шестью триплетами; пролин, валин и глицин – четырьмя; изолейцин – тремя; аспарагиновая и глутаминовая кислоты – двумя, а для метионина имеется лишь один кодон. Он же, если стоит в начале гена, исполняет роль заглавной буквы.
Это похоже на ситуацию в дореволюционном русском алфавите: тогда существовало два символа для звука «ф» (ферт и фита) и целых три для «и» («и» просто, «и» с точкой и ижица).
Первые исследователи полагали, что аминокислотные цепочки прямо собираются на нуклеотидных цепочках. Дело оказалось гораздо сложнее.
Во-первых, нет никакого стерического (морфологического) соответствия между кодоном и той аминокислотой, которую он кодирует. Соответствие между ним и достигается молекулой особой нуклеиновой кислоты, которую называли по-разному: РНК – посредник, адаптор, растворимая и, наконец, транспортная. На одном ее конце присоединена аминокислота, а на другом расположена последовательность комплементарная кодону (антикодон).
Во-вторых, матрицей для белкового синтеза служит не непосредственно ДНК, а копируемый с нее «рабочий чертеж» – РНК, получившая название информационной или матричной (мРНК).
Итак, мы должны различать процессы: матрицирование самого гена, то есть синтез ДНК на ДНК, синтез мРНК на ДНК и синтез белка на матрице мРНК. Первый процесс называется репликацией, второй – транскрипцией и третий – трансляцией.
Еще короче это выражается в так называемой «центральной догме» молекулярной биологии:
В предисловии я обещал строго придерживаться того набора фактов, которого требует школьная программа. Однако некоторые положения в ней излагаются слишком сжато, иные неверно, а многие любопытные достижения последних лет просто еще не дошли до учебников. Теперь самое время на них остановиться.
Полярность гена. Длинные цепочечные молекулы биополимеров – полипептидов и нуклеиновых кислот – полярны. Иными словами начало и конец цепи аминокислотных остатков и нуклеотидов различаются друг от друга.
Нетрудно сообразить, почему полярны полипептиды, слагающие белки. Уже упоминалось, что аминокислоты имеют две функциональные группировки, сшивающие их в полипептид, – аминную и карбоксильную. Значит, у первого звена аминокислотной последовательности остается свободной аминная группа (—NH2), а у последнего – карбоксильная (—COOH). Так и говорят: N – конец и C – конец полипептида.
Полярны и нуклеиновые кислоты, но по другой причине. Остов как РНК, так и ДНК —пятичленные сахара – пентозы, сшитые остатками фосфорной кислоты (фосфодиэфирные связи). Чтобы различать атомы углерода в пятиугольнике пентозы, химики пронумеровали их, считая от того, к которому присоединено азотистое основание. Оказалось, что в природных нуклеиновых кислотах фосфодиэфирные связи образуются только между третьими и пятыми атомами углерода в пентозах (сокращенно: 3’ и 5’; читается: «три-штрих» и «пять-штрих»). Поэтому на одном конце любой нуклеиновой кислоты сахар присоединен к цепи 3’-атомом, на другом – 5’.
А теперь зададимся вопросом: в какую сторону «читается» ген – к 3’ или 5’? Теперь, когда генные инженеры уверенно расшифровывают нуклеотидные последовательности и синтезируют их, это вопрос отнюдь не праздный.
Рис. 17. Упрощенная схема передачи генетической информации с ДНК на белок. С находящейся в ядре ДНК снимается «рабочая копия» гена – гетерогенная ядерная РНК (этот процесс называется транскрипцией). Значительная, как правило, большая ее часть не кодирует аминокислотных последовательностей и отрезается ферментами – эндонуклеазами и отбрасывается. Тогда же вырезаются и «нечитаемые» вставки – интроны. Созревшая мРНК, получившая «шапочку» (cap – англ.) на 5’-конце и полиадениловую последовательность на З’-конце, через пору в ядерной оболочке выходит в цитоплазму (часто в виде комплексов с белком – информофер или информосом, на рисунке не показанных). В цитоплазме информация считывается с мРНК белоксинтезирующими аппаратами клетки – рибосомами (трансляция). Рибосомы гуськом идут по мРНК: каждый раз, когда рибосома смещается на три нуклеотида к З’-концу, к растущей полипептидной цепи прибавляется один аминокислотный остаток. Аминокислоты доставляются к рибосомам молекулами транспортной РНК (мРНК). Отдав аминокислоту, мРНК образует снова комплекс (аминоацил – мРНК) с другой и снова вовлекается в процесс. Полипептидная цепочка, оборвавшись на бессмысленном, терминирующем кодоне, свертывается специфичным образом. Это вторичная структура белка, поддерживаемая водородными связями; обычно это однонитчатая спираль (спираль Полинга – Кори). Спираль, в свою очередь, складывается, образуя третичную структуру. Наконец, многие белки состоят из более чем одной полипептидной цепи. Таков, например, гемоглобин, молекула которого состоит из четырех субъединиц. Это четвертичная структура.
Установлено, что полипептидные цепи в клетках синтезируются от N – конца к C – концу. Значит, у матричной РНК начало там, где кодируется N- конец. Оно соответствует 5’-концу РНК. В двойной спирали ДНК разобраться труднее. Дело в том, что слагающие ее нуклеотидные цепочки направлены в разные стороны, как говорят, антипараллельны. Иными словами, одна цепь направлена в сторону З’—5’, а другая 5’—З’.
Смысловая цепь, в которой закодирована аминокислотная последовательность «считывается» ферментом РНК-полимеразой с З’-конца. Образующаяся при этом мРНК, естественно, оказывается точным аналогом комплементарной цепи и будет начинаться с 5’-конца, с того, с которого начинается трансляция, то есть белковый синтез.
Но ведь с гена снимается не только «рабочий чертеж» мРНК. Ген и реплицируется, передаваясь из поколения в поколение, от матричной клетки к дочерним. Осуществляет этот процесс – репликацию – фермент ДНК полимераза.
Считается, что молекула ДНК-полимеразы садится на ДНК и движется по ней. При этом удваивается и смысловая цепь, и комплементарная к ней. Значит репликация смысловой цепи начинается с 3’-конца, как и транскрипция. Это аналогично тому как если бы мы перепечатывали текст с конца, а читали его, как и водится, с начала. В учебниках и популярных изданиях на это, как правило, не обращают внимания.
Последние годы ознаменовались сенсационными открытиями в изучении процессов репликации и трансляции. Природа подносила нам сюрприз каждый раз, когда начинало казаться, что уж теперь мы знаем об этих явлениях все.
Вот некоторые из сенсаций, за молодостью не попавшие в учебники.
Справедлива ли центральная догма? Мы уже упоминали, что генетическая информация передается от ДНК через РНК на белок, но не в обратную сторону. Это положение назвали центральной догмой молекулярной биологии. РНК-содержащие вирусы ее не нарушают. Просто у них выпадает начальное звено этой цели – ДНК. Генетическая информация передается из поколения в поколение закодированной в последовательностях РНК, с них же и считывается белок.
В принципе разница между ДНК и РНК не так уж и велика. Пентознофосфатный остов у РНК образует другой сахар – рибоза, который отличается от дезоксирибозы лишь наличием гидроксильной группы (OH). Набор оснований тот же, за тем исключением, что вместо тимина (5-метилурацила) в РНК содержится урацил (тот же тимин, только неметилированный). Недаром в природе встречаются ДНК, в состав которых входят и дезоксирибозы и рибозы. Такова, например, ДНК вируса герпеса, от которого на губах «высыпает лихорадка». Энергетические фабрики клеток – митохондрии – в значительной степени генетически автономны от ядра, они имеют свой геном, похожий на бактериальный. ДНК этого генома также содержит рибозу – от десяти до тридцати остатков на молекулу.
Все это не нарушало стройную догму. Тем большее смятение вызвало открытие синтеза ДНК на РНК. С. М. Гершензон писал еще в 1960 году о возможности подобного процесса, однако лишь сравнительно недавно был получен в значительных количествах фермент ревертаза (обратная транскриптаза), осуществляющий эту реакцию. Теперь этот фермент – обычный инструмент генных инженеров. Теперь мы можем дополнить центральную догму:
Например, РНК-содержащий вирус птичьего миэлобластоза может в результате обратной транскрипции стать ДНК-содержащим, встроиться в геном цыпленка и вызвать злокачественное перерождение клеток. Какую роль играет синтез ДНК на нити РНК в мире высших организмов, нам пока еще неизвестно.
Смысловая цепь: одна или две? Каких-нибудь пять лет назад все мы были твердо уверены, что матричная РНК синтезируется только на одной из двух цепей ДНК, получившей название смысловой. Вторая, комплементарная ей цепь нужна лишь для репликации ДНК и репарации – «починки» поврежденных участков. Если, например, жесткая радиация вырвет кусок из одной из цепей двойной спирали, специальные ферменты – репаразы заполняют брешь, пристроив на ее месте последовательность нуклеотидов, комплементарную оставшейся.