Страница:
#include ‹fcntl.h›
main() {
int fd;
char lilbuf[20], bigbuf[1024];
fd = open("/etc/passwd", O_RDONLY);
read(fd, lilbuf, 20);
read(fd, bigbuf, 1024);
read(fd, lilbuf, 20);
}
Рисунок 5.7. Пример программы чтения из файла
Рассмотрим программу, приведенную на Рисунке 5.7. Функция open возвращает дескриптор файла, который пользователь засылает в переменную fd и использует в последующих вызовах функции read. Выполняя функцию read, ядро проверяет, правильно ли задан параметр «дескриптор файла», а также был ли файл предварительно открыт процессом для чтения. Оно сохраняет значение адреса пользовательского буфера, количество считываемых байт и начальное смещение в байтах внутри файла (соответственно: lilbuf, 20 и 0), в пространстве процесса. В результате вычислений оказывается, что нулевое значение смещения соответствует нулевому блоку файла, и ядро возвращает точку входа в индекс, соответствующую нулевому блоку. Предполагая, что такой блок существует, ядро считывает полный блок размером 1024 байта в буфер, но по адресу lilbuf копирует только 20 байт. Оно увеличивает смещение внутри пространства процесса на 20 байт и сбрасывает счетчик данных в 0. Поскольку операция read выполнилась, ядро переустанавливает значение смещения в таблице файлов на 20, так что последующие операции чтения из файла с данным дескриптором начнутся с места, расположенного со смещением 20 байт от начала файла, а системная функция возвращает число байт, фактически прочитанных, т. е. 20.
При повторном вызове функции read ядро вновь проверяет корректность указания дескриптора и наличие соответствующего файла, открытого процессом для чтения, поскольку оно никак не может узнать, что запрос пользователя на чтение касается того же самого файла, существование которого было установлено во время последнего вызова функции. Ядро сохраняет в пространстве процесса пользовательский адрес bigbuf, количество байт, которые нужно прочитать процессу (1024), и начальное смещение в файле (20), взятое из таблицы файлов. Ядро преобразует смещение внутри файла в номер дискового блока, как раньше, и считывает блок. Если между вызовами функции read прошло непродолжительное время, есть шансы, что блок находится в буферном кеше. Однако, ядро не может полностью удовлетворить запрос пользователя на чтение за счет содержимого буфера, поскольку только 1004 байта из 1024 для данного запроса находятся в буфере. Поэтому оно копирует оставшиеся 1004 байта из буфера в пользовательскую структуру данных bigbuf и корректирует параметры в пространстве процесса таким образом, чтобы следующий шаг цикла чтения начинался в файле с байта 1024, при этом данные следует копировать по адресу байта 1004 в bigbuf в объеме 20 байт, чтобы удовлетворить запрос на чтение.
Теперь ядро переходит к началу цикла, содержащегося в алгоритме read. Оно преобразует смещение в байтах (1024) в номер логического блока (1), обращается ко второму блоку прямой адресации, номер которого хранится в индексе, и отыскивает точный дисковый блок, из которого будет производиться чтение. Ядро считывает блок из буферного кеша или с диска, если в кеше данный блок отсутствует. Наконец, оно копирует 20 байт из буфера по уточненному адресу в пользовательский процесс. Прежде чем выйти из системной функции, ядро устанавливает значение поля смещения в таблице файлов равным 1044, то есть равным значению смещения в байтах до места, куда будет производиться следующее обращение. В последнем вызове функции read из примера ядро ведет себя, как и в первом обращении к функции, за исключением того, что чтение из файла в данном случае начинается с байта 1044, так как именно это значение будет обнаружено в поле смещения той записи таблицы файлов, которая соответствует указанному дескриптору.
Пример показывает, насколько выгодно для запросов ввода-вывода работать с данными, начинающимися на границах блоков файловой системы и имеющими размер, кратный размеру блока. Это позволяет ядру избегать дополнительных итераций при выполнении цикла в алгоритме read и всех вытекающих последствий, связанных с дополнительными обращениями к индексу в поисках номера блока, который содержит данные, и с конкуренцией за использование буферного пула. Библиотека стандартных модулей ввода-вывода создана таким образом, чтобы скрыть от пользователей размеры буферов ядра; ее использование позволяет избежать потерь производительности, присущих процессам, работающим с небольшими порциями данных, из-за чего их функционирование на уровне файловой системы неэффективно (см. упражнение 5.4).
Выполняя цикл чтения, ядро определяет, является ли файл объектом чтения с продвижением: если процесс считывает последовательно два блока, ядро предполагает, что все очередные операции будут производить последовательное чтение, до тех пор, пока не будет утверждено обратное. На каждом шаге цикла ядро запоминает номер следующего логического блока в копии индекса, хранящейся в памяти, и на следующем шаге сравнивает номер текущего логического блока со значением, запомненным ранее. Если эти номера равны, ядро вычисляет номер физического блока для чтения с продвижением и сохраняет это значение в пространстве процесса для использования в алгоритме breada. Конечно же, пока процесс не считал конец блока, ядро не запустит алгоритм чтения с продвижением для следующего блока.
Обратившись к Рисунку 4.9, вспомним, что номера некоторых блоков в индексе или в блоках косвенной адресации могут иметь нулевое значение, пусть даже номера последующих блоков и ненулевые. Если процесс попытается прочитать данные из такого блока, ядро выполнит запрос, выделяя произвольный буфер в цикле read, очищая его содержимое и копируя данные из него по адресу пользователя. Этот случай не имеет ничего общего с тем случаем, когда процесс обнаруживает конец файла, говорящий о том, что после этого места запись информации никогда не производилась. Обнаружив конец файла, ядро не возвращает процессу никакой информации (см. упражнение 5.1).
Когда процесс вызывает системную функцию read, ядро блокирует индекс на время выполнения вызова. Впоследствии, этот процесс может приостановиться во время чтения из буфера, ассоциированного с данными или с блоками косвенной адресации в индексе. Если еще одному процессу дать возможность вносить изменения в файл в то время, когда первый процесс приостановлен, функция read может возвратить несогласованные данные. Например, процесс может считать из файла несколько блоков; если он приостановился во время чтения первого блока, а второй процесс собирался вести запись в другие блоки, возвращаемые данные будут содержать старые данные вперемешку с новыми. Таким образом, индекс остается заблокированным на все время выполнения вызова функции read для того, чтобы процессы могли иметь целостное видение файла, то есть видение того образа, который был у файла перед вызовом функции.
Ядро может выгружать процесс, ведущий чтение, в режим задачи на время между двумя вызовами функций и планировать запуск других процессов. Так как по окончании выполнения системной функции с индекса снимается блокировка, ничто не мешает другим процессам обращаться к файлу и изменять его содержимое. Со стороны системы было бы несправедливо держать индекс заблокированным все время от момента, когда процесс открыл файл, и до того момента, когда файл будет закрыт этим процессом, поскольку тогда один процесс будет держать все время файл открытым, тем самым не давая другим процессам возможности обратиться к файлу. Если файл имеет имя «/etc/ passwd», то есть является файлом, используемым в процессе регистрации для проверки пользовательского пароля, один пользователь может умышленно (или, возможно, неумышленно) воспрепятствовать регистрации в системе всех остальных пользователей. Чтобы предотвратить возникновение подобных проблем, ядро снимает с индекса блокировку по окончании выполнения каждого вызова системной функции, использующей индекс. Если второй процесс внесет изменения в файл между двумя вызовами функции read, производимыми первым процессом, первый процесс может прочитать непредвиденные данные, однако структуры данных ядра сохранят свою согласованность.
Предположим, к примеру, что ядро выполняет два процесса, конкурирующие между собой (Рисунок 5.8). Если допустить, что оба процесса выполняют операцию open до того, как любой из них вызывает системную функцию read или write, ядро может выполнять функции чтения и записи в любой из шести последовательностей: чтение1, чтение2, запись1, запись2, или чтение1, запись1, чтение2, запись2, или чтение1, запись1, запись2, чтение2 и т. д. Состав информации, считываемой процессом A, зависит от последовательности, в которой система выполняет функции, вызываемые двумя процессами; система не гарантирует, что данные в файле останутся такими же, какими они были после открытия файла. Использование возможности захвата файла и записей (раздел 5.4) позволяет процессу гарантировать сохранение целостности файла после его открытия.
#include ‹fcntl.h›
/* процесс A */
main() {
int fd;
char buf[512];
fd = open("/etc/passwd", O_RDONLY);
read(fd, buf, sizeof(buf)); /* чтение1 */
read(fd, buf, sizeof(buf)); /* чтение2 */
}
/* процесс B */
main() {
int fd, i;
char buf[512];
for (i = 0; i ‹ sizeof(buf); i++) buf[i] = 'a';
fd = open("/etc/passwd", O_WRONLY);
write(fd, buf, sizeof(buf)); /* запись1 */
write(fd, buf, sizeof(buf)); /* запись2 */
}
Рисунок 5.8. Процессы, ведущие чтение и запись файла
Наконец, программа на Рисунке 5.9 показывает, как процесс может открывать файл более одного раза и читать из него, используя разные файловые дескрипторы. Ядро работает со значениями смещений в таблице файлов, ассоциированными с двумя файловыми дескрипторами, независимо, и поэтому массивы buf1 и buf2 будут по завершении выполнения процесса идентичны друг другу при условии, что ни один процесс в это время не производил запись в файл «/etc/passwd».
#include ‹fcntl.h›
main() {
int fd1, fd2;
char buf1[512], buf2[512];
fd1 = open("/etc/passwd", O_RDONLY);
fd2 = open("/etc/passwd", O_RDONLY);
read(fd1, buf1, sizeof(buf1));
read(fd2, buf2, sizeof(buf2));
}
Рисунок 5.9. Чтение из файла с использованием двух дескрипторов
5.3 WRIТЕ
Синтаксис вызова системной функции write (писать):
number = write(fd, buffer, count);
где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако, если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, используя алгоритм alloc, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индекса. Если смещение в байтах совпадает со смещением для блока косвенной адресации, ядру, возможно, придется выделить несколько блоков для использования их в качестве блоков косвенной адресации и информационных блоков. Индекс блокируется на все время выполнения функции write, так как ядро может изменить индекс, выделяя новые блоки; разрешение другим процессам обращаться к файлу может разрушить индекс, если несколько процессов выделяют блоки одновременно, используя одни и те же значения смещений. Когда запись завершается, ядро корректирует размер файла в индексе, если файл увеличился в размере.
Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации.
Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части. Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись (раздел 3.4) данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (раздел 5.12). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге «/tmp» и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы.
number = write(fd, buffer, count);
где переменные fd, buffer, count и number имеют тот же смысл, что и для вызова системной функции read. Алгоритм записи в обычный файл похож на алгоритм чтения из обычного файла. Однако, если в файле отсутствует блок, соответствующий смещению в байтах до места, куда должна производиться запись, ядро выделяет блок, используя алгоритм alloc, и присваивает ему номер в соответствии с точным указанием места в таблице содержимого индекса. Если смещение в байтах совпадает со смещением для блока косвенной адресации, ядру, возможно, придется выделить несколько блоков для использования их в качестве блоков косвенной адресации и информационных блоков. Индекс блокируется на все время выполнения функции write, так как ядро может изменить индекс, выделяя новые блоки; разрешение другим процессам обращаться к файлу может разрушить индекс, если несколько процессов выделяют блоки одновременно, используя одни и те же значения смещений. Когда запись завершается, ядро корректирует размер файла в индексе, если файл увеличился в размере.
Предположим, к примеру, что процесс записывает в файл байт с номером 10240, наибольшим номером среди уже записанных в файле. Обратившись к байту в файле по алгоритму bmap, ядро обнаружит, что в файле отсутствует не только соответствующий этому байту блок, но также и нужный блок косвенной адресации. Ядро назначает дисковый блок в качестве блока косвенной адресации и записывает номер блока в копии индекса, хранящейся в памяти. Затем оно выделяет дисковый блок под данные и записывает его номер в первую позицию вновь созданного блока косвенной адресации.
Так же, как в алгоритме read, ядро входит в цикл, записывая на диск по одному блоку на каждой итерации. При этом на каждой итерации ядро определяет, будет ли производиться запись целого блока или только его части. Если записывается только часть блока, ядро в первую очередь считывает блок с диска для того, чтобы не затереть те части, которые остались без изменений, а если записывается целый блок, ядру не нужно читать весь блок, так как в любом случае оно затрет предыдущее содержимое блока. Запись осуществляется поблочно, однако ядро использует отложенную запись (раздел 3.4) данных на диск, запоминая их в кеше на случай, если они понадобятся вскоре другому процессу для чтения или записи, а также для того, чтобы избежать лишних обращений к диску. Отложенная запись, вероятно, наиболее эффективна для каналов, так как другой процесс читает канал и удаляет из него данные (раздел 5.12). Но даже для обычных файлов отложенная запись эффективна, если файл создается временно и вскоре будет прочитан. Например, многие программы, такие как редакторы и электронная почта, создают временные файлы в каталоге «/tmp» и быстро удаляют их. Использование отложенной записи может сократить количество обращений к диску для записи во временные файлы.
5.4 ЗАХВАТ ФАЙЛА И ЗАПИСИ
В первой версии системы UNIX, разработанной Томпсоном и Ричи, отсутствовал внутренний механизм, с помощью которого процессу мог бы быть обеспечен исключительный доступ к файлу. Механизм захвата был признан излишним, поскольку, как отмечает Ричи, «мы не имеем дела с большими базами данных, состоящими из одного файла, которые поддерживаются независимыми процессами» (см. [Ritchie 81]). Для того, чтобы повысить привлекательность системы UNIX для коммерческих пользователей, работающих с базами данных, в версию V системы ныне включены механизмы захвата файла и записи. Захват файла — это средство, позволяющее запретить другим процессам производить чтение или запись любой части файла, а захват записи — это средство, позволяющее запретить другим процессам производить ввод-вывод указанных записей (частей файла между указанными смещениями). В упражнении 5.9 рассматривается реализация механизма захвата файла и записи.
5.5 УКАЗАНИЕ МЕСТА В ФАЙЛЕ, ГДЕ БУДЕТ ВЫПОЛНЯТЬСЯ ВВОД-ВЫВОД — LSEEК
Обычное использование системных функций read и write обеспечивает последовательный доступ к файлу, однако процессы могут использовать вызов системной функции lseek для указания места в файле, где будет производиться ввод-вывод, и осуществления произвольного доступа к файлу. Синтаксис вызова системной функции:
position = lseek(fd, offset, reference);
где fd — дескриптор файла, идентифицирующий файл, offset — смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи. Например, в программе, приведенной на Рисунке 5.10, процесс открывает файл, считывает байт, а затем вызывает функцию lseek, чтобы заменить значение поля смещения в таблице файлов величиной, равной 1023 (с переменной reference, имеющей значение 1), и выполняет цикл. Таким образом, программа считывает каждый 1024-й байт файла. Если reference имеет значение 0, ядро осуществляет поиск от начала файла, а если 2, ядро ведет поиск от конца файла. Функция lseek ничего не должна делать, кроме операции поиска, которая позиционирует головку чтения-записи на указанный дисковый сектор. Для того, чтобы выполнить функцию lseek, ядро просто выбирает значение смещения из таблицы файлов; в последующих вызовах функций read и write смещение из таблицы файлов используется в качестве начального смещения.
#include ‹fcntl.h›
main(argc, argv)
int argc; char *argv[];
{
int fd, skval;
char c;
if (argc != 2) exit();
fd = open(argv[1], O_RDONLY);
if (fd == -1) exit();
while ((skval = read(fd, &c,1 )) == 1) {
printf("char %c\n", c);
skval = lseek(fd, 1023L, 1);
printf("new seek val %d\n", skval);
}
}
Рисунок 5.10. Программа, содержащая вызов системной функции lseek
position = lseek(fd, offset, reference);
где fd — дескриптор файла, идентифицирующий файл, offset — смещение в байтах, а reference указывает, является ли значение offset смещением от начала файла, смещением от текущей позиции ввода-вывода или смещением от конца файла. Возвращаемое значение, position, является смещением в байтах до места, где будет начинаться следующая операция чтения или записи. Например, в программе, приведенной на Рисунке 5.10, процесс открывает файл, считывает байт, а затем вызывает функцию lseek, чтобы заменить значение поля смещения в таблице файлов величиной, равной 1023 (с переменной reference, имеющей значение 1), и выполняет цикл. Таким образом, программа считывает каждый 1024-й байт файла. Если reference имеет значение 0, ядро осуществляет поиск от начала файла, а если 2, ядро ведет поиск от конца файла. Функция lseek ничего не должна делать, кроме операции поиска, которая позиционирует головку чтения-записи на указанный дисковый сектор. Для того, чтобы выполнить функцию lseek, ядро просто выбирает значение смещения из таблицы файлов; в последующих вызовах функций read и write смещение из таблицы файлов используется в качестве начального смещения.
#include ‹fcntl.h›
main(argc, argv)
int argc; char *argv[];
{
int fd, skval;
char c;
if (argc != 2) exit();
fd = open(argv[1], O_RDONLY);
if (fd == -1) exit();
while ((skval = read(fd, &c,1 )) == 1) {
printf("char %c\n", c);
skval = lseek(fd, 1023L, 1);
printf("new seek val %d\n", skval);
}
}
Рисунок 5.10. Программа, содержащая вызов системной функции lseek
5.6 CLOSЕ
Процесс закрывает открытый файл, когда процессу больше не нужно обращаться к нему. Синтаксис вызова системной функции close (закрыть):
close(fd);
где fd — дескриптор открытого файла. Ядро выполняет операцию закрытия, используя дескриптор файла и информацию из соответствующих записей в таблице файлов и таблице индексов. Если счетчик ссылок в записи таблицы файлов имеет значение, большее, чем 1, в связи с тем, что были обращения к функциям dup или fork, то это означает, что на запись в таблице файлов делают ссылку другие пользовательские дескрипторы, что мы увидим далее; ядро уменьшает значение счетчика и операция закрытия завершается. Если счетчик ссылок в таблице файлов имеет значение, равное 1, ядро освобождает запись в таблице и индекс в памяти, ранее выделенный системной функцией open (алгоритм iput). Если другие процессы все еще ссылаются на индекс, ядро уменьшает значение счетчика ссылок на индекс, но оставляет индекс процессам; в противном случае индекс освобождается для переназначения, так как его счетчик ссылок содержит 0. Когда выполнение системной функции close завершается, запись в таблице пользовательских дескрипторов файла становится пустой. Попытки процесса использовать данный дескриптор заканчиваются ошибкой до тех пор, пока дескриптор не будет переназначен другому файлу в результате выполнения другой системной функции. Когда процесс завершается, ядро проверяет наличие активных пользовательских дескрипторов файла, принадлежавших процессу, и закрывает каждый из них. Таким образом, ни один процесс не может оставить файл открытым после своего завершения.
На Рисунке 5.11, например, показаны записи из таблиц, приведенных на Рисунке 5.4, после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы «/etc/passwd» и «private» в индексах также уменьшились. Индекс для файла «private» находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу «private», пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в разделе 4.1.2.
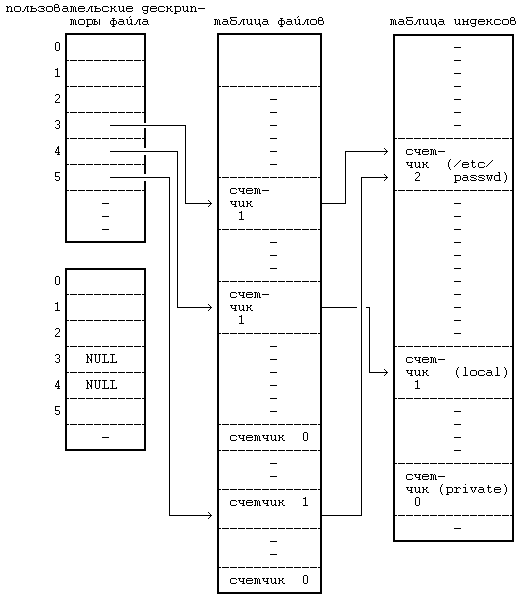
Рисунок 5.11. Таблицы после закрытия файла
close(fd);
где fd — дескриптор открытого файла. Ядро выполняет операцию закрытия, используя дескриптор файла и информацию из соответствующих записей в таблице файлов и таблице индексов. Если счетчик ссылок в записи таблицы файлов имеет значение, большее, чем 1, в связи с тем, что были обращения к функциям dup или fork, то это означает, что на запись в таблице файлов делают ссылку другие пользовательские дескрипторы, что мы увидим далее; ядро уменьшает значение счетчика и операция закрытия завершается. Если счетчик ссылок в таблице файлов имеет значение, равное 1, ядро освобождает запись в таблице и индекс в памяти, ранее выделенный системной функцией open (алгоритм iput). Если другие процессы все еще ссылаются на индекс, ядро уменьшает значение счетчика ссылок на индекс, но оставляет индекс процессам; в противном случае индекс освобождается для переназначения, так как его счетчик ссылок содержит 0. Когда выполнение системной функции close завершается, запись в таблице пользовательских дескрипторов файла становится пустой. Попытки процесса использовать данный дескриптор заканчиваются ошибкой до тех пор, пока дескриптор не будет переназначен другому файлу в результате выполнения другой системной функции. Когда процесс завершается, ядро проверяет наличие активных пользовательских дескрипторов файла, принадлежавших процессу, и закрывает каждый из них. Таким образом, ни один процесс не может оставить файл открытым после своего завершения.
На Рисунке 5.11, например, показаны записи из таблиц, приведенных на Рисунке 5.4, после того, как второй процесс закрывает соответствующие им файлы. Записи, соответствующие дескрипторам 3 и 4 в таблице пользовательских дескрипторов файлов, пусты. Счетчики в записях таблицы файлов теперь имеют значение 0, а сами записи пусты. Счетчики ссылок на файлы «/etc/passwd» и «private» в индексах также уменьшились. Индекс для файла «private» находится в списке свободных индексов, поскольку счетчик ссылок на него равен 0, но запись о нем не пуста. Если еще какой-нибудь процесс обратится к файлу «private», пока индекс еще находится в списке свободных индексов, ядро востребует индекс обратно, как показано в разделе 4.1.2.
Рисунок 5.11. Таблицы после закрытия файла
5.7 СОЗДАНИЕ ФАЙЛА
Системная функция open дает процессу доступ к существующему файлу, а системная функция creat создает в системе новый файл. Синтаксис вызова системной функции creat:
fd = creat(pathname, modes);
где переменные pathname, modes и fd имеют тот же смысл, что и в системной функции open. Если прежде такого файла не существовало, ядро создает новый файл с указанным именем и указанными правами доступа к нему; если же такой файл уже существовал, ядро усекает файл (освобождает все существующие блоки данных и устанавливает размер файла равным 0) при наличии соответствующих прав доступа к нему [16]. На Рисунке 5.12 приведен алгоритм создания файла.
алгоритм creat
входная информация:
имя файла
установки прав доступа к файлу
выходная информация: дескриптор файла
{
получить индекс для данного имени файла (алгоритм namei);
if (файл уже существует) {
if (доступ не разрешен) {
освободить индекс (алгоритм iput);
return (ошибку);
}
}
else { /* файл еще не существует */
назначить свободный индекс из файловой системы (алгоритм ialloc);
создать новую точку входа в родительском каталоге;
включить имя нового файла и номер вновь назначенного индекса;
}
выделить для индекса запись в таблице файлов, инициализировать счетчик;
if (файл существовал к моменту создания) освободить все блоки файла (алгоритм free);
снять блокировку (с индекса);
return (пользовательский дескриптор файла);
}
Рисунок 5.12. Алгоритм создания файла
Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге.
Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (раздел 4.6). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. в разделе 5.16.1).
Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать «новый» файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога.
Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.)
fd = creat(pathname, modes);
где переменные pathname, modes и fd имеют тот же смысл, что и в системной функции open. Если прежде такого файла не существовало, ядро создает новый файл с указанным именем и указанными правами доступа к нему; если же такой файл уже существовал, ядро усекает файл (освобождает все существующие блоки данных и устанавливает размер файла равным 0) при наличии соответствующих прав доступа к нему [16]. На Рисунке 5.12 приведен алгоритм создания файла.
алгоритм creat
входная информация:
имя файла
установки прав доступа к файлу
выходная информация: дескриптор файла
{
получить индекс для данного имени файла (алгоритм namei);
if (файл уже существует) {
if (доступ не разрешен) {
освободить индекс (алгоритм iput);
return (ошибку);
}
}
else { /* файл еще не существует */
назначить свободный индекс из файловой системы (алгоритм ialloc);
создать новую точку входа в родительском каталоге;
включить имя нового файла и номер вновь назначенного индекса;
}
выделить для индекса запись в таблице файлов, инициализировать счетчик;
if (файл существовал к моменту создания) освободить все блоки файла (алгоритм free);
снять блокировку (с индекса);
return (пользовательский дескриптор файла);
}
Рисунок 5.12. Алгоритм создания файла
Ядро проводит синтаксический анализ имени пути поиска, используя алгоритм namei и следуя этому алгоритму буквально, когда речь идет о разборе имен каталогов. Однако, когда дело касается последней компоненты имени пути поиска, а именно идентификатора создаваемого файла, namei отмечает смещение в байтах до первой пустой позиции в каталоге и запоминает это смещение в пространстве процесса. Если ядро не обнаружило в каталоге компоненту имени пути поиска, оно в конечном счете впишет имя компоненты в только что найденную пустую позицию. Если в каталоге нет пустых позиций, ядро запоминает смещение до конца каталога и создает новую позицию там. Оно также запоминает в пространстве процесса индекс просматриваемого каталога и держит индекс заблокированным; каталог становится по отношению к новому файлу родительским каталогом. Ядро не записывает пока имя нового файла в каталог, так что в случае возникновения ошибок ядру приходится меньше переделывать. Оно проверяет наличие у процесса разрешения на запись в каталог. Поскольку процесс будет производить запись в каталог в результате выполнения функции creat, наличие разрешения на запись в каталог означает, что процессам дозволяется создавать файлы в каталоге.
Предположив, что под данным именем ранее не существовало файла, ядро назначает новому файлу индекс, используя алгоритм ialloc (раздел 4.6). Затем оно записывает имя нового файла и номер вновь выделенного индекса в родительский каталог, а смещение в байтах сохраняет в пространстве процесса. Впоследствии ядро освобождает индекс родительского каталога, удерживаемый с того времени, когда в каталоге производился поиск имени файла. Родительский каталог теперь содержит имя нового файла и его индекс. Ядро записывает вновь выделенный индекс на диск (алгоритм bwrite), прежде чем записать на диск каталог с новым именем. Если между операциями записи индекса и каталога произойдет сбой системы, в итоге окажется, что выделен индекс, на который не ссылается ни одно из имен путей поиска в системе, однако система будет функционировать нормально. Если, с другой стороны, каталог был записан раньше вновь выделенного индекса и сбой системы произошел между ними, файловая система будет содержать имя пути поиска, ссылающееся на неверный индекс (более подробно об этом см. в разделе 5.16.1).
Если данный файл уже существовал до вызова функции creat, ядро обнаруживает его индекс во время поиска имени файла. Старый файл должен позволять процессу производить запись в него, чтобы можно было создать «новый» файл с тем же самым именем, так как ядро изменяет содержимое файла при выполнении функции creat: оно усекает файл, освобождая все информационные блоки по алгоритму free, так что файл будет выглядеть как вновь созданный. Тем не менее, владелец и права доступа к файлу остаются прежними: ядро не передает право собственности на файл владельцу процесса и игнорирует права доступа, указанные процессом в вызове функции. Наконец, ядро не проверяет наличие разрешения на запись в каталог, являющийся родительским для существующего файла, поскольку оно не меняет содержимого каталога.
Функция creat продолжает работу, выполняя тот же алгоритм, что и функция open. Ядро выделяет созданному файлу запись в таблице файлов, чтобы процесс мог читать из файла, а также запись в таблице пользовательских дескрипторов файла, и в конце концов возвращает указатель на последнюю запись в виде пользовательского дескриптора файла.)
5.8 СОЗДАНИЕ СПЕЦИАЛЬНЫХ ФАЙЛОВ
Системная функция mknod создает в системе специальные файлы, в число которых включаются поименованные каналы, файлы устройств и каталоги. Она похожа на функцию creat в том, что ядро выделяет для файла индекс. Синтаксис вызова системной функции mknod: