Страница:
2.6 УПРАЖНЕНИЯ
1. Рассмотрим следующий набор команд:
grep main a.c b.c c.c › grepout&
wc -1 ‹ grepout&
rm grepout&
Амперсанд (символ "&") в конце каждой командной строки говорит командному процессору shell о том, что команду следует выполнить на фоне, при этом shell может выполнять все командные строки параллельно. Почему это не равноценно следующей командной строке?
grep main a.c b.c c.c | wc -1
2. Рассмотрим пример программы, приведенный на Рисунке 2.7. Предположим, что в тот момент, когда при ее выполнении встретился комментарий, произошло переключение контекста и другой процесс убрал содержимое буфера из списка указателей с помощью следующих команд:
remove(gp)
struct queue *gp;
{
gp-›forp-›backp = gp-›backp;
gp-›backp-›forp = gp-›forp;
gp-›forp = gp-›backp = NULL;
}
Рассмотрим три случая:
Процесс убирает из списка с указателями структуру bp1.
Процесс убирает из списка с указателями структуру, следующую после структуры bp1.
Процесс убирает из списка структуру, которая первоначально следовала за bp1 до того, как структура bp была наполовину включена в указанный список.
В каком состоянии будет список после того, как первый процесс завершит выполнение части программы, расположенной после комментариев?
3. Что произошло бы в том случае, если ядро попыталось бы возобновить выполнение всех процессов, приостановленных по событию, но в системе не было бы к этому моменту ни одного такого процесса?
grep main a.c b.c c.c › grepout&
wc -1 ‹ grepout&
rm grepout&
Амперсанд (символ "&") в конце каждой командной строки говорит командному процессору shell о том, что команду следует выполнить на фоне, при этом shell может выполнять все командные строки параллельно. Почему это не равноценно следующей командной строке?
grep main a.c b.c c.c | wc -1
2. Рассмотрим пример программы, приведенный на Рисунке 2.7. Предположим, что в тот момент, когда при ее выполнении встретился комментарий, произошло переключение контекста и другой процесс убрал содержимое буфера из списка указателей с помощью следующих команд:
remove(gp)
struct queue *gp;
{
gp-›forp-›backp = gp-›backp;
gp-›backp-›forp = gp-›forp;
gp-›forp = gp-›backp = NULL;
}
Рассмотрим три случая:
Процесс убирает из списка с указателями структуру bp1.
Процесс убирает из списка с указателями структуру, следующую после структуры bp1.
Процесс убирает из списка структуру, которая первоначально следовала за bp1 до того, как структура bp была наполовину включена в указанный список.
В каком состоянии будет список после того, как первый процесс завершит выполнение части программы, расположенной после комментариев?
3. Что произошло бы в том случае, если ядро попыталось бы возобновить выполнение всех процессов, приостановленных по событию, но в системе не было бы к этому моменту ни одного такого процесса?
ГЛАВА 3. БУФЕР СВЕРХОПЕРАТИВНОЙ ПАМЯТИ (КЕШ)
Как уже говорилось в предыдущей главе, ядро операционной системы поддерживает файлы на внешних запоминающих устройствах большой емкости, таких как диски, и позволяет процессам сохранять новую информацию или вызывать ранее сохраненную информацию. Если процессу необходимо обратиться к информации файла, ядро выбирает информацию в оперативную память, где процесс сможет просматривать эту информацию, изменять ее и обращаться с просьбой о ее повторном сохранении в файловой системе. Вспомним для примера программу copy, приведенную на Рисунке 1.3: ядро читает данные из первого файла в память и затем записывает эти данные во второй файл. Подобно тому, как ядро должно заносить данные из файла в память, оно так же должно считывать в память и вспомогательные данные для работы с ними. Например, суперблок файловой системы содержит помимо всего прочего информацию о свободном пространстве, доступном файловой системе. Ядро считывает суперблок в память для того, чтобы иметь доступ к его информации, и возвращает его опять файловой системе, когда желает сохранить его содержимое. Похожая вещь происходит с индексом, который описывает размещение файла. Ядро системы считывает индекс в память, когда желает получить доступ к информации файла, и возвращает индекс вновь файловой системе, когда желает скорректировать размещение файла. Ядро обрабатывает такую вспомогательную информацию, не будучи прежде знакома с ней и не требуя для ее обработки запуска каких-либо процессов.
Ядро могло бы производить чтение и запись непосредственно с диска и на диск при всех обращениях к файловой системе, однако время реакции системы и производительность при этом были бы низкими из-за низкой скорости передачи данных с диска. По этой причине ядро старается свести к минимуму частоту обращений к диску, заведя специальную область внутренних информационных буферов, именуемую буферным кешем [7]и хранящую содержимое блоков диска, к которым перед этим производились обращения.
На Рисунке 2.1 показано, что модуль буферного кеша занимает в архитектуре ядра место между подсистемой управления файлами и драйверами устройств (ввода-вывода блоками). Перед чтением информации с диска ядро пытается считать что-нибудь из буфера кеша. Если в этом буфере отсутствует информация, ядро читает данные с диска и заносит их в буфер, используя алгоритм, который имеет целью поместить в буфере как можно больше необходимых данных. Аналогично, информация, записываемая на диск, заносится в буфер для того, чтобы находиться там, если ядро позднее попытается считать ее. Ядро также старается свести к минимуму частоту выполнения операций записи на диск, выясняя, должна ли информация действительно запоминаться на диске или это промежуточные данные, которые будут вскоре затерты. Алгоритмы более высокого уровня позволяют производить предварительное занесение данных в буфер кеша или задерживать запись данных с тем, чтобы усилить эффект использования буфера. В этой главе рассматриваются алгоритмы, используемые ядром при работе с буферами в сверхоперативной памяти.
Ядро могло бы производить чтение и запись непосредственно с диска и на диск при всех обращениях к файловой системе, однако время реакции системы и производительность при этом были бы низкими из-за низкой скорости передачи данных с диска. По этой причине ядро старается свести к минимуму частоту обращений к диску, заведя специальную область внутренних информационных буферов, именуемую буферным кешем [7]и хранящую содержимое блоков диска, к которым перед этим производились обращения.
На Рисунке 2.1 показано, что модуль буферного кеша занимает в архитектуре ядра место между подсистемой управления файлами и драйверами устройств (ввода-вывода блоками). Перед чтением информации с диска ядро пытается считать что-нибудь из буфера кеша. Если в этом буфере отсутствует информация, ядро читает данные с диска и заносит их в буфер, используя алгоритм, который имеет целью поместить в буфере как можно больше необходимых данных. Аналогично, информация, записываемая на диск, заносится в буфер для того, чтобы находиться там, если ядро позднее попытается считать ее. Ядро также старается свести к минимуму частоту выполнения операций записи на диск, выясняя, должна ли информация действительно запоминаться на диске или это промежуточные данные, которые будут вскоре затерты. Алгоритмы более высокого уровня позволяют производить предварительное занесение данных в буфер кеша или задерживать запись данных с тем, чтобы усилить эффект использования буфера. В этой главе рассматриваются алгоритмы, используемые ядром при работе с буферами в сверхоперативной памяти.
3.1 ЗАГОЛОВКИ БУФЕРА
Во время инициализации системы ядро выделяет место под совокупность буферов, потребность в которых определяется в зависимости от размера памяти и производительности системы. Каждый буфер состоит из двух частей: области памяти, в которой хранится информация, считываемая с диска, и заголовка буфера, который идентифицирует буфер. Поскольку существует однозначное соответствие между заголовками буферов и массивами данных, в нижеследующем тексте используется термин «буфер» в ссылках как на ту, так и на другую его составляющую, и о какой из частей буфера идет речь будет понятно из контекста.
Информация в буфере соответствует информации в одном логическом блоке диска в файловой системе, и ядро распознает содержимое буфера, просматривая идентифицирующие поля в его заголовке. Буфер представляет собой копию дискового блока в памяти; содержимое дискового блока отображается в буфер, но это отображение временное, поскольку оно имеет место до того момента, когда ядро примет решение отобразить в буфер другой дисковый блок. Один дисковый блок не может быть одновременно отображен в несколько буферов. Если бы два буфера содержали информацию для одного и того же дискового блока, ядро не смогло бы определить, в каком из буферов содержится текущая информация, и, возможно, возвратило бы на диск некорректную информацию. Предположим, например, что дисковый блок отображается в два буфера, A и B. Если ядро запишет данные сначала в буфер A, а затем в буфер B, дисковый блок будет содержать данные из буфера B, если в результате операций записи буфер заполнится до конца. Однако, если ядро изменит порядок, в котором оно копирует содержимое буферов на диск, на противоположный, дисковый блок будет содержать некорректные данные.
Заголовок буфера (Рисунок 3.1) содержит поле «номер устройства» и поле «номер блока», которые определяют файловую систему и номер блока с информацией на диске и однозначно идентифицируют буфер. Номер устройства — это логический номер файловой системы (см. раздел 2.2.1), а не физический номер устройства (диска). Заголовок буфера также содержит указатель на область памяти для буфера, размер которой должен быть не меньше размера дискового блока, и поле состояния, в котором суммируется информация о текущем состоянии буфера. Состояние буфера представляет собой комбинацию из следующих условий:
• буфер заблокирован (термины «заблокирован (недоступен)» и «занят» равнозначны, так же, как и понятия «свободен» и «доступен»),
• буфер содержит правильную информацию,
• ядро должно переписать содержимое буфера на диск перед тем, как переназначить буфер; это условие известно, как «задержка, вызванная записью»,
• ядро читает или записывает содержимое буфера на диск,
• процесс ждет освобождения буфера.
В заголовке буфера также содержатся два набора указателей, используемые алгоритмами выделения буфера, которые поддерживают общую структуру области буферов (буферного пула), о чем подробнее будет говориться в следующем разделе.
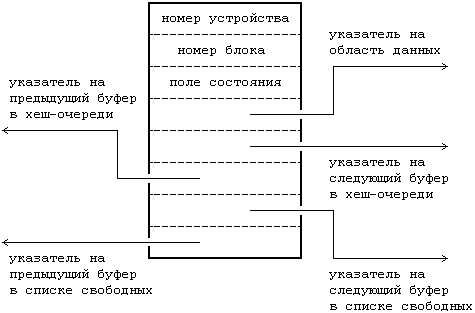 Рисунок 3.1. Заголовок буфера
Рисунок 3.1. Заголовок буфера
Информация в буфере соответствует информации в одном логическом блоке диска в файловой системе, и ядро распознает содержимое буфера, просматривая идентифицирующие поля в его заголовке. Буфер представляет собой копию дискового блока в памяти; содержимое дискового блока отображается в буфер, но это отображение временное, поскольку оно имеет место до того момента, когда ядро примет решение отобразить в буфер другой дисковый блок. Один дисковый блок не может быть одновременно отображен в несколько буферов. Если бы два буфера содержали информацию для одного и того же дискового блока, ядро не смогло бы определить, в каком из буферов содержится текущая информация, и, возможно, возвратило бы на диск некорректную информацию. Предположим, например, что дисковый блок отображается в два буфера, A и B. Если ядро запишет данные сначала в буфер A, а затем в буфер B, дисковый блок будет содержать данные из буфера B, если в результате операций записи буфер заполнится до конца. Однако, если ядро изменит порядок, в котором оно копирует содержимое буферов на диск, на противоположный, дисковый блок будет содержать некорректные данные.
Заголовок буфера (Рисунок 3.1) содержит поле «номер устройства» и поле «номер блока», которые определяют файловую систему и номер блока с информацией на диске и однозначно идентифицируют буфер. Номер устройства — это логический номер файловой системы (см. раздел 2.2.1), а не физический номер устройства (диска). Заголовок буфера также содержит указатель на область памяти для буфера, размер которой должен быть не меньше размера дискового блока, и поле состояния, в котором суммируется информация о текущем состоянии буфера. Состояние буфера представляет собой комбинацию из следующих условий:
• буфер заблокирован (термины «заблокирован (недоступен)» и «занят» равнозначны, так же, как и понятия «свободен» и «доступен»),
• буфер содержит правильную информацию,
• ядро должно переписать содержимое буфера на диск перед тем, как переназначить буфер; это условие известно, как «задержка, вызванная записью»,
• ядро читает или записывает содержимое буфера на диск,
• процесс ждет освобождения буфера.
В заголовке буфера также содержатся два набора указателей, используемые алгоритмами выделения буфера, которые поддерживают общую структуру области буферов (буферного пула), о чем подробнее будет говориться в следующем разделе.
3.2 СТРУКТУРА ОБЛАСТИ БУФЕРОВ (БУФЕРНОГО ПУЛА)
Ядро помещает информацию в область буферов, используя алгоритм поиска буферов, к которым наиболее долго не было обращений: после выделения буфера дисковому блоку нельзя использовать этот буфер для другого блока до тех пор, пока не будут задействованы все остальные буферы. Ядро управляет списком свободных буферов, который необходим для работы указанного алгоритма. Этот список представляет собой циклический перечень буферов с двунаправленными указателями и с формальными заголовками в начале и в конце перечня (Рисунок 3.2). Все буферы попадают в список при загрузке системы. Если нужен любой свободный буфер, ядро выбирает буфер из «головы» списка, но если в области буферов ищется определенный блок, может быть выбран буфер и из середины списка. И в том, и в другом случае буфер удаляется из списка свободных буферов. Если ядро возвращает буфер буферному пулу, этот буфер добавляется в хвост списка, либо в «голову» списка (в случае ошибки), но никогда не в середину. По мере удаления буферов из списка буфер с нужной информацией продвигается все ближе и ближе к «голове» списка (Рисунок 3.2). Следовательно, те буферы, которые находятся ближе к «голове» списка, в последний раз использовались раньше, чем буферы, находящиеся дальше от «головы» списка.
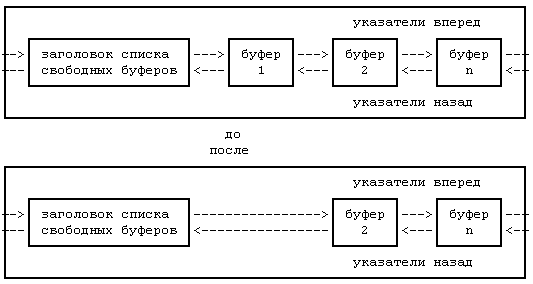 Рисунок 3.2. Список свободных буферов
Рисунок 3.2. Список свободных буферов
Когда ядро обращается к дисковому блоку, оно сначала ищет буфер с соответствующей комбинацией номеров устройства и блока. Вместо того, чтобы просматривать всю область буферов, ядро организует из буферов особые очереди, хешированные по номеру устройства и номеру блока. В хеш-очереди ядро устанавливает для буферов циклическую связь в виде списка с двунаправленными указателями, структура которого похожа на структуру списка свободных буферов. Количество буферов в хеш-очереди варьируется в течение всего времени функционирования системы, в чем мы еще убедимся дальше. Ядро вынуждено прибегать к функции хеширования, чтобы единообразно распределять буферы между хеш-очередями, однако функция хеширования должна быть несложной, чтобы не пострадала производительность системы. Администраторы системы задают количество хеш-очередей при генерации операционной системы.
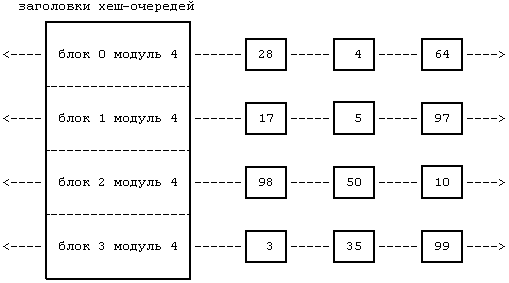 Рисунок 3.3. Буферы в хеш-очередях
Рисунок 3.3. Буферы в хеш-очередях
На Рисунке 3.3 изображены буферы в хеш-очередях: заголовки хеш-очередей показаны в левой части рисунка, а квадратиками в каждой строке показаны буферы в соответствующей хеш-очереди. Так, квадратики с числами 28, 4 и 64 представляют буферы в хеш-очереди для «блока 0 модуля 4». Пунктирным линиям между буферами соответствуют указатели вперед и назад вдоль хеш-очереди; для простоты на следующих рисунках этой главы данные указатели не показываются, но их присутствие подразумевается. Кроме того, на рисунке блоки идентифицируются только своими номерами и функция хеширования построена на использовании только номеров блоков; однако на практике также используется номер устройства.
Любой буфер всегда находится в хеш-очереди, но его положение в очереди не имеет значения. Как уже говорилось, никакая пара буферов не может одновременно содержать данные одного и того же дискового блока; поэтому каждый дисковый блок в буферном пуле существует в одной и только одной хеш-очереди и представлен в ней только один раз. Тем не менее, буфер может находиться в списке свободных буферов, если его статус «свободен». Поскольку буфер может быть одновременно в хеш-очереди и в списке свободных буферов, у ядра есть два способа его обнаружения. Ядро просматривает хеш-очередь, если ему нужно найти определенный буфер, и выбирает буфер из списка свободных буферов, если ему нужен любой свободный буфер. В следующем разделе будет показано, каким образом ядро осуществляет поиск определенных дисковых блоков в буферном кеше, а также как оно работает с буферами в хеш-очередях и в списке свободных буферов. Еще раз напомним: буфер всегда находится в хеш — очереди, а в списке свободных буферов может быть, но может и отсутствовать.
Когда ядро обращается к дисковому блоку, оно сначала ищет буфер с соответствующей комбинацией номеров устройства и блока. Вместо того, чтобы просматривать всю область буферов, ядро организует из буферов особые очереди, хешированные по номеру устройства и номеру блока. В хеш-очереди ядро устанавливает для буферов циклическую связь в виде списка с двунаправленными указателями, структура которого похожа на структуру списка свободных буферов. Количество буферов в хеш-очереди варьируется в течение всего времени функционирования системы, в чем мы еще убедимся дальше. Ядро вынуждено прибегать к функции хеширования, чтобы единообразно распределять буферы между хеш-очередями, однако функция хеширования должна быть несложной, чтобы не пострадала производительность системы. Администраторы системы задают количество хеш-очередей при генерации операционной системы.
На Рисунке 3.3 изображены буферы в хеш-очередях: заголовки хеш-очередей показаны в левой части рисунка, а квадратиками в каждой строке показаны буферы в соответствующей хеш-очереди. Так, квадратики с числами 28, 4 и 64 представляют буферы в хеш-очереди для «блока 0 модуля 4». Пунктирным линиям между буферами соответствуют указатели вперед и назад вдоль хеш-очереди; для простоты на следующих рисунках этой главы данные указатели не показываются, но их присутствие подразумевается. Кроме того, на рисунке блоки идентифицируются только своими номерами и функция хеширования построена на использовании только номеров блоков; однако на практике также используется номер устройства.
Любой буфер всегда находится в хеш-очереди, но его положение в очереди не имеет значения. Как уже говорилось, никакая пара буферов не может одновременно содержать данные одного и того же дискового блока; поэтому каждый дисковый блок в буферном пуле существует в одной и только одной хеш-очереди и представлен в ней только один раз. Тем не менее, буфер может находиться в списке свободных буферов, если его статус «свободен». Поскольку буфер может быть одновременно в хеш-очереди и в списке свободных буферов, у ядра есть два способа его обнаружения. Ядро просматривает хеш-очередь, если ему нужно найти определенный буфер, и выбирает буфер из списка свободных буферов, если ему нужен любой свободный буфер. В следующем разделе будет показано, каким образом ядро осуществляет поиск определенных дисковых блоков в буферном кеше, а также как оно работает с буферами в хеш-очередях и в списке свободных буферов. Еще раз напомним: буфер всегда находится в хеш — очереди, а в списке свободных буферов может быть, но может и отсутствовать.
3.3 МЕХАНИЗМ ПОИСКА БУФЕРА
Как показано на Рисунке 2.1, алгоритмы верхнего уровня, используемые ядром для подсистемы управления файлами, инициируют выполнение алгоритмов управления буферным кешем. При выборке блока алгоритмы верхнего уровня устанавливают логический номер устройства и номер блока, к которым они хотели бы получить доступ. Например, если процесс хочет считать данные из файла, ядро устанавливает, в какой файловой системе находится файл и в каком блоке файловой системы содержатся данные, о чем подробнее мы узнаем из главы 4. Собираясь считать данные из определенного дискового блока, ядро проверяет, находится ли блок в буферном пуле, и если нет, назначает для него свободный буфер. Собираясь записать данные в определенный дисковый блок, ядро проверяет, находится ли блок в буферном пуле, и если нет, назначает для этого блока свободный буфер. Для выделения буферов из пула в алгоритмах чтения и записи дисковых блоков используется операция getblk (Рисунок 3.4).
Рассмотрим в этом разделе пять возможных механизмов использования getblk для выделения буфера под дисковый блок.
1. Ядро обнаруживает блок в хеш-очереди, соответствующий ему буфер свободен.
2. Ядро не может обнаружить блок в хеш-очереди, поэтому оно выделяет буфер из списка свободных буферов.
3. Ядро не может обнаружить блок в хеш-очереди и, пытаясь выделить буфер из списка свободных буферов (как в случае 2), обнаруживает в списке буфер, который помечен как «занят на время записи». Ядро должно переписать этот буфер на диск и выделить другой буфер.
4. Ядро не может обнаружить блок в хеш-очереди, а список свободных буферов пуст.
5. Ядро обнаруживает блок в хеш-очереди, но его буфер в настоящий момент занят.
Обсудим каждый случай более подробно.
Осуществляя поиск блока в буферном пуле по комбинации номеров устройства и блока, ядро ищет хеш-очередь, которая бы содержала этот блок. Просматривая хеш-очередь, ядро придерживается списка с указателями, пока (как в первом случае) не найдет буфер с искомыми номерами устройства и блока. Ядро проверяет занятость блока и в том случае, если он свободен, помечает буфер «занятым» для того, чтобы другие процессы [8]не смогли к нему обратиться. Затем ядро удаляет буфер из списка свободных буферов, поскольку буфер не может одновременно быть занятым и находиться в указанном списке. Если другие процессы попытаются обратиться к блоку в то время, когда его буфер занят, они приостановятся до тех пор, пока буфер не освободится. На Рисунке 3.5 показан первый случай, когда ядро ищет блок 4 в хеш-очереди, помеченной как «блок 0 модуль 4». Обнаружив буфер, ядро удаляет его из списка свободных буферов, делая блоки 5 и 28 соседями в списке.
алгоритм getblk
входная информация: номер файловой системы номер блока
выходная информация: буфер, который можно использовать для блока
{
do if (буфер не найден) {
if (блок в хеш-очереди) {
if (буфер занят) { /* случай 5 */
sleep (до освобождения буфера);
continue; /* цикл с условием продолжения */
}
пометить буфер занятым; /* случай 1 */
удалить буфер из списка свободных буферов;
return буфер;
}
else { /* блока нет в хеш-очереди */
if (в списке нет свободных буферов) { /*случай 4*/
sleep (до освобождения любого буфера);
continue; /* цикл с условием продолжения */
}
удалить буфер из списка свободных буферов;
if (буфер помечен для отложенной переписи) { /* случай 3 */
асинхронная перепись содержимого буфера на диск;
continue; /* цикл с условием продолжения */
}
/* случай 2 — поиск свободного буфера */
удалить буфер из старой хеш-очереди;
включить буфер в новую хеш-очередь;
return буфер;
}
}
}
Рисунок 3.4. Алгоритм выделения буфера
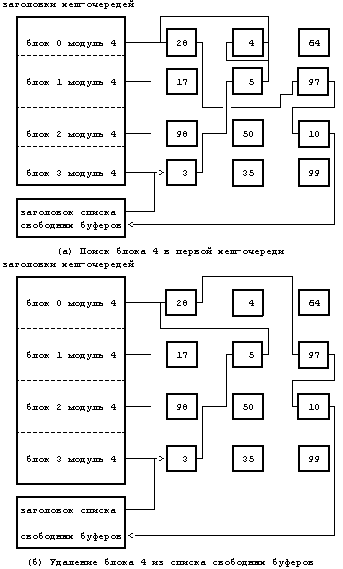
Рисунок 3.5. Поиск буфера — случай 1: буфер в хеш-очереди
алгоритм brelse
входная информация: заблокированный буфер
выходная информация: отсутствует
{
возобновить выполнение всех процессов при наступлении события, связанного с освобождением любого буфера;
возобновить выполнение всех процессов при наступлении события, связанного с освобождением данного буфера;
поднять приоритет прерывания процессора так, чтобы блокировать любые прерывания;
if (содержимое буфера верно и буфер не старый) поставить буфер в конец списка свободных буферов;
else поставить буфер в начало списка свободных буферов;
понизить приоритет прерывания процессора с тем, чтобы вновь разрешить прерывания;
разблокировать (буфер);
}
Рисунок 3.6. Алгоритм высвобождения буфера
Перед тем, как перейти к остальным случаям, рассмотрим, что произойдет с буфером после того, как он будет выделен блоку. Ядро системы сможет читать данные с диска в буфер и обрабатывать их или же переписывать данные в буфер и при желании на диск. Ядро оставляет у буфера пометку «занят»; другие процессы не могут обратиться к нему и изменить его содержимое, пока он занят, таким образом поддерживается целостность информации в буфере. Когда ядро заканчивает работу с буфером, оно освобождает буфер в соответствии с алгоритмом brelse (Рисунок 3.6). Возобновляется выполнение тех процессов, которые были приостановлены из-за того, что буфер был занят, а также те процессы, которые были приостановлены из-за того, что список свободных буферов был пуст. Как в том, так и в другом случае, высвобождение буфера означает, что буфер становится доступным для приостановленных процессов несмотря на то, что первый процесс, получивший буфер, заблокировал его и запретил тем самым получение буфера другими процессами (см. раздел 2.2.2.4). Ядро помещает буфер в конец списка свободных буферов, если только перед этим не произошла ошибка ввода-вывода или если буфер не помечен как «старый» — момент, который будет пояснен далее; в остальных случаях буфер помещается в начало списка. Теперь буфер свободен для использования любым процессом.
Ядро выполняет алгоритм brelse в случае, когда буфер процессу больше не нужен, а также при обработке прерывания от диска для высвобождения буферов, используемых при асинхронном вводе-выводе с диска и на диск (см. раздел 3.4). Ядро повышает приоритет прерывания работы процессора так, чтобы запретить возникновение любых прерываний от диска на время работы со списком свободных буферов, предупреждая искажение указателей буфера в результате вложенного выполнения алгоритма brelse. Похожие последствия могут произойти, если программа обработки прерываний запустит алгоритм brelse во время выполнения процессом алгоритма getblk, поэтому ядро повышает приоритет прерывания работы процессора и в стратегических моментах выполнения алгоритма getblk. Более подробно эти случаи мы разберем с помощью упражнений.
При выполнении алгоритма getblk имеет место случай 2, когда ядро просматривает хеш-очередь, в которой должен был бы находиться блок, но не находит его там. Так как блок не может быть ни в какой другой хеш-очереди, поскольку он не должен «хешироваться» в другом месте, следовательно, его нет в буферном кеше. Поэтому ядро удаляет первый буфер из списка свободных буферов; этот буфер был уже выделен другому дисковому блоку и также находится в хеш-очереди. Если буфер не помечен для отложенной переписи, ядро помечает буфер занятым, удаляет его из хеш-очереди, где он находится, назначает в заголовке буфера номера устройства и блока, соответствующие данному дисковому блоку, и помещает буфер в хеш-очередь. Ядро использует буфер, не переписав информацию, которую буфер прежде хранил для другого дискового блока. Тот процесс, который будет искать прежний дисковый блок, не обнаружит его в пуле и получит для него точно таким же образом новый буфер из списка свободных буферов. Когда ядро заканчивает работу с буфером, оно освобождает буфер вышеописанным способом. На Рисунке 3.7, например, ядро ищет блок 18, но не находит его в хеш-очереди, помеченной как «блок 2 модуль 4». Поэтому ядро удаляет первый буфер из списка свободных буферов (блок 3), назначает его блоку 18 и помещает его в соответствующую хеш-очередь.
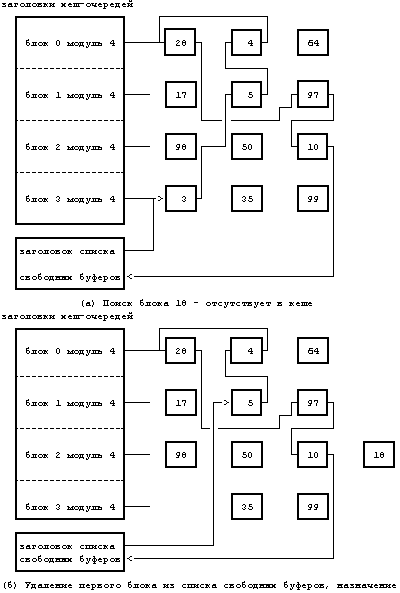 Рисунок 3.7. Второй случай выделения буфера
Рисунок 3.7. Второй случай выделения буфера
Если при выполнении алгоритма getblk имеет место случай 3, ядро так же должно выделить буфер из списка свободных буферов. Однако, оно обнаруживает, что удаляемый из списка буфер был помечен для отложенной переписи, поэтому прежде чем использовать буфер ядро должно переписать его содержимое на диск. Ядро приступает к асинхронной записи на диск и пытается выделить другой буфер из списка. Когда асинхронная запись заканчивается, ядро освобождает буфер и помещает его в начало списка свободных буферов. Буфер сам продвинулся от конца списка свободных буферов к началу списка. Если после асинхронной переписи ядру бы понадобилось поместить буфер в конец списка, буфер получил бы «зеленую улицу» по всему списку свободных буферов, результат такого перемещения противоположен действию алгоритма поиска буферов, к которым наиболее долго не было обращений. Например, если обратиться к Рисунку 3.8, ядро не смогло обнаружить блок 18, но когда попыталось выделить первые два буфера (по очереди) в списке свободных буферов, то оказалось, что они оба помечены для отложенной переписи. Ядро удалило их из списка, запустило операции переписи на диск в соответствующие блоки, и выделило третий буфер из списка, блок 4. Далее ядро присвоило новые значения полям буфера «номер устройства» и «номер блока» и включило буфер, получивший имя «блок 18», в новую хеш-очередь.
В четвертом случае (Рисунок 3.9) ядро, работая с процессом A, не смогло найти дисковый блок в соответствующей хеш-очереди и предприняло попытку выделить из списка свободных буферов новый буфер, как в случае 2. Однако, в списке не оказалось ни одного буфера, поэтому процесс A приостановился до тех пор, пока другим процессом не будет выполнен алгоритм brelse, высвобождающий буфер. Планируя выполнение процесса A, ядро вынуждено снова просматривать хеш-очередь в поисках блока. Оно не в состоянии немедленно выделить буфер из списка свободных буферов, так как возможна ситуация, когда свободный буфер ожидают сразу несколько процессов и одному из них будет выделен вновь освободившийся буфер, на который уже нацелился процесс A. Таким образом, алгоритм поиска блока снова гарантирует, что только один буфер включает содержимое дискового блока. На Рисунке 3.10 показана конкуренция между двумя процессами за освободившийся буфер.
Последний случай (Рисунок 3.11) наиболее сложный, поскольку он связан с комплексом взаимоотношений между несколькими процессами. Предположим, что ядро, работая с процессом A, ведет поиск дискового блока и выделяет буфер, но приостанавливает выполнение процесса перед освобождением буфера. Например, если процесс A попытается считать дисковый блок и выделить буфер, как в случае 2, то он приостановится до момента завершения передачи данных с диска. Предположим, что пока процесс A приостановлен, ядро активизирует второй процесс, B, который пытается обратиться к дисковому блоку, чей буфер был только что заблокирован процессом A. Процесс B (случай 5) обнаружит этот захваченный блок в хеш-очереди. Так как использовать захваченный буфер не разрешается и, кроме того, нельзя выделить для одного и того же дискового блока второй буфер, процесс B помечает буфер как «запрошенный» и затем приостанавливается до того момента, когда процесс A освободит данный буфер.
В конце концов процесс A освобождает буфер и замечает, что он запрошен. Тогда процесс A «будит» все процессы, приостановленные по событию «буфер становится свободным», включая и процесс B. Когда же ядро вновь запустит на выполнение процесс B, процесс B должен будет убедиться в том, что буфер свободен. Возможно, что третий процесс, C, ждал освобождения этого же буфера, и ядро запланировало активизацию процесса C раньше B; при этом процесс C мог приостановиться и оставить буфер заблокированным. Следовательно, процесс B должен проверить то, что блок действительно свободен.
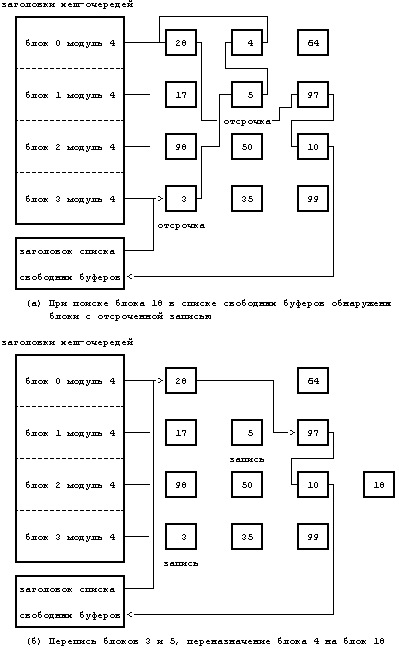 Рисунок 3.8. Третий случай выделения буфера
Рисунок 3.8. Третий случай выделения буфера
Рассмотрим в этом разделе пять возможных механизмов использования getblk для выделения буфера под дисковый блок.
1. Ядро обнаруживает блок в хеш-очереди, соответствующий ему буфер свободен.
2. Ядро не может обнаружить блок в хеш-очереди, поэтому оно выделяет буфер из списка свободных буферов.
3. Ядро не может обнаружить блок в хеш-очереди и, пытаясь выделить буфер из списка свободных буферов (как в случае 2), обнаруживает в списке буфер, который помечен как «занят на время записи». Ядро должно переписать этот буфер на диск и выделить другой буфер.
4. Ядро не может обнаружить блок в хеш-очереди, а список свободных буферов пуст.
5. Ядро обнаруживает блок в хеш-очереди, но его буфер в настоящий момент занят.
Обсудим каждый случай более подробно.
Осуществляя поиск блока в буферном пуле по комбинации номеров устройства и блока, ядро ищет хеш-очередь, которая бы содержала этот блок. Просматривая хеш-очередь, ядро придерживается списка с указателями, пока (как в первом случае) не найдет буфер с искомыми номерами устройства и блока. Ядро проверяет занятость блока и в том случае, если он свободен, помечает буфер «занятым» для того, чтобы другие процессы [8]не смогли к нему обратиться. Затем ядро удаляет буфер из списка свободных буферов, поскольку буфер не может одновременно быть занятым и находиться в указанном списке. Если другие процессы попытаются обратиться к блоку в то время, когда его буфер занят, они приостановятся до тех пор, пока буфер не освободится. На Рисунке 3.5 показан первый случай, когда ядро ищет блок 4 в хеш-очереди, помеченной как «блок 0 модуль 4». Обнаружив буфер, ядро удаляет его из списка свободных буферов, делая блоки 5 и 28 соседями в списке.
алгоритм getblk
входная информация: номер файловой системы номер блока
выходная информация: буфер, который можно использовать для блока
{
do if (буфер не найден) {
if (блок в хеш-очереди) {
if (буфер занят) { /* случай 5 */
sleep (до освобождения буфера);
continue; /* цикл с условием продолжения */
}
пометить буфер занятым; /* случай 1 */
удалить буфер из списка свободных буферов;
return буфер;
}
else { /* блока нет в хеш-очереди */
if (в списке нет свободных буферов) { /*случай 4*/
sleep (до освобождения любого буфера);
continue; /* цикл с условием продолжения */
}
удалить буфер из списка свободных буферов;
if (буфер помечен для отложенной переписи) { /* случай 3 */
асинхронная перепись содержимого буфера на диск;
continue; /* цикл с условием продолжения */
}
/* случай 2 — поиск свободного буфера */
удалить буфер из старой хеш-очереди;
включить буфер в новую хеш-очередь;
return буфер;
}
}
}
Рисунок 3.4. Алгоритм выделения буфера
Рисунок 3.5. Поиск буфера — случай 1: буфер в хеш-очереди
алгоритм brelse
входная информация: заблокированный буфер
выходная информация: отсутствует
{
возобновить выполнение всех процессов при наступлении события, связанного с освобождением любого буфера;
возобновить выполнение всех процессов при наступлении события, связанного с освобождением данного буфера;
поднять приоритет прерывания процессора так, чтобы блокировать любые прерывания;
if (содержимое буфера верно и буфер не старый) поставить буфер в конец списка свободных буферов;
else поставить буфер в начало списка свободных буферов;
понизить приоритет прерывания процессора с тем, чтобы вновь разрешить прерывания;
разблокировать (буфер);
}
Рисунок 3.6. Алгоритм высвобождения буфера
Перед тем, как перейти к остальным случаям, рассмотрим, что произойдет с буфером после того, как он будет выделен блоку. Ядро системы сможет читать данные с диска в буфер и обрабатывать их или же переписывать данные в буфер и при желании на диск. Ядро оставляет у буфера пометку «занят»; другие процессы не могут обратиться к нему и изменить его содержимое, пока он занят, таким образом поддерживается целостность информации в буфере. Когда ядро заканчивает работу с буфером, оно освобождает буфер в соответствии с алгоритмом brelse (Рисунок 3.6). Возобновляется выполнение тех процессов, которые были приостановлены из-за того, что буфер был занят, а также те процессы, которые были приостановлены из-за того, что список свободных буферов был пуст. Как в том, так и в другом случае, высвобождение буфера означает, что буфер становится доступным для приостановленных процессов несмотря на то, что первый процесс, получивший буфер, заблокировал его и запретил тем самым получение буфера другими процессами (см. раздел 2.2.2.4). Ядро помещает буфер в конец списка свободных буферов, если только перед этим не произошла ошибка ввода-вывода или если буфер не помечен как «старый» — момент, который будет пояснен далее; в остальных случаях буфер помещается в начало списка. Теперь буфер свободен для использования любым процессом.
Ядро выполняет алгоритм brelse в случае, когда буфер процессу больше не нужен, а также при обработке прерывания от диска для высвобождения буферов, используемых при асинхронном вводе-выводе с диска и на диск (см. раздел 3.4). Ядро повышает приоритет прерывания работы процессора так, чтобы запретить возникновение любых прерываний от диска на время работы со списком свободных буферов, предупреждая искажение указателей буфера в результате вложенного выполнения алгоритма brelse. Похожие последствия могут произойти, если программа обработки прерываний запустит алгоритм brelse во время выполнения процессом алгоритма getblk, поэтому ядро повышает приоритет прерывания работы процессора и в стратегических моментах выполнения алгоритма getblk. Более подробно эти случаи мы разберем с помощью упражнений.
При выполнении алгоритма getblk имеет место случай 2, когда ядро просматривает хеш-очередь, в которой должен был бы находиться блок, но не находит его там. Так как блок не может быть ни в какой другой хеш-очереди, поскольку он не должен «хешироваться» в другом месте, следовательно, его нет в буферном кеше. Поэтому ядро удаляет первый буфер из списка свободных буферов; этот буфер был уже выделен другому дисковому блоку и также находится в хеш-очереди. Если буфер не помечен для отложенной переписи, ядро помечает буфер занятым, удаляет его из хеш-очереди, где он находится, назначает в заголовке буфера номера устройства и блока, соответствующие данному дисковому блоку, и помещает буфер в хеш-очередь. Ядро использует буфер, не переписав информацию, которую буфер прежде хранил для другого дискового блока. Тот процесс, который будет искать прежний дисковый блок, не обнаружит его в пуле и получит для него точно таким же образом новый буфер из списка свободных буферов. Когда ядро заканчивает работу с буфером, оно освобождает буфер вышеописанным способом. На Рисунке 3.7, например, ядро ищет блок 18, но не находит его в хеш-очереди, помеченной как «блок 2 модуль 4». Поэтому ядро удаляет первый буфер из списка свободных буферов (блок 3), назначает его блоку 18 и помещает его в соответствующую хеш-очередь.
Если при выполнении алгоритма getblk имеет место случай 3, ядро так же должно выделить буфер из списка свободных буферов. Однако, оно обнаруживает, что удаляемый из списка буфер был помечен для отложенной переписи, поэтому прежде чем использовать буфер ядро должно переписать его содержимое на диск. Ядро приступает к асинхронной записи на диск и пытается выделить другой буфер из списка. Когда асинхронная запись заканчивается, ядро освобождает буфер и помещает его в начало списка свободных буферов. Буфер сам продвинулся от конца списка свободных буферов к началу списка. Если после асинхронной переписи ядру бы понадобилось поместить буфер в конец списка, буфер получил бы «зеленую улицу» по всему списку свободных буферов, результат такого перемещения противоположен действию алгоритма поиска буферов, к которым наиболее долго не было обращений. Например, если обратиться к Рисунку 3.8, ядро не смогло обнаружить блок 18, но когда попыталось выделить первые два буфера (по очереди) в списке свободных буферов, то оказалось, что они оба помечены для отложенной переписи. Ядро удалило их из списка, запустило операции переписи на диск в соответствующие блоки, и выделило третий буфер из списка, блок 4. Далее ядро присвоило новые значения полям буфера «номер устройства» и «номер блока» и включило буфер, получивший имя «блок 18», в новую хеш-очередь.
В четвертом случае (Рисунок 3.9) ядро, работая с процессом A, не смогло найти дисковый блок в соответствующей хеш-очереди и предприняло попытку выделить из списка свободных буферов новый буфер, как в случае 2. Однако, в списке не оказалось ни одного буфера, поэтому процесс A приостановился до тех пор, пока другим процессом не будет выполнен алгоритм brelse, высвобождающий буфер. Планируя выполнение процесса A, ядро вынуждено снова просматривать хеш-очередь в поисках блока. Оно не в состоянии немедленно выделить буфер из списка свободных буферов, так как возможна ситуация, когда свободный буфер ожидают сразу несколько процессов и одному из них будет выделен вновь освободившийся буфер, на который уже нацелился процесс A. Таким образом, алгоритм поиска блока снова гарантирует, что только один буфер включает содержимое дискового блока. На Рисунке 3.10 показана конкуренция между двумя процессами за освободившийся буфер.
Последний случай (Рисунок 3.11) наиболее сложный, поскольку он связан с комплексом взаимоотношений между несколькими процессами. Предположим, что ядро, работая с процессом A, ведет поиск дискового блока и выделяет буфер, но приостанавливает выполнение процесса перед освобождением буфера. Например, если процесс A попытается считать дисковый блок и выделить буфер, как в случае 2, то он приостановится до момента завершения передачи данных с диска. Предположим, что пока процесс A приостановлен, ядро активизирует второй процесс, B, который пытается обратиться к дисковому блоку, чей буфер был только что заблокирован процессом A. Процесс B (случай 5) обнаружит этот захваченный блок в хеш-очереди. Так как использовать захваченный буфер не разрешается и, кроме того, нельзя выделить для одного и того же дискового блока второй буфер, процесс B помечает буфер как «запрошенный» и затем приостанавливается до того момента, когда процесс A освободит данный буфер.
В конце концов процесс A освобождает буфер и замечает, что он запрошен. Тогда процесс A «будит» все процессы, приостановленные по событию «буфер становится свободным», включая и процесс B. Когда же ядро вновь запустит на выполнение процесс B, процесс B должен будет убедиться в том, что буфер свободен. Возможно, что третий процесс, C, ждал освобождения этого же буфера, и ядро запланировало активизацию процесса C раньше B; при этом процесс C мог приостановиться и оставить буфер заблокированным. Следовательно, процесс B должен проверить то, что блок действительно свободен.