Страница:
| владелец | mjb |
| группа | os |
| тип | обычный файл |
| права доступа | rwxr-xr-x |
| последнее обращение | 23 Окт 1984 13:45 |
| последнее изменение | 22 Окт 1984 10:30 |
| коррекция индекса | 23 Окт 1984 13:30 |
| размер | 6030 байт |
| дисковые адреса |
Рисунок 4.2. Пример дискового индекса
На Рисунке 4.2 показан дисковый индекс некоторого файла. Этот индекс принадлежит обычному файлу, владелец которого — «mjb» и размер которого 6030 байт. Система разрешает пользователю «mjb» производить чтение, запись и исполнение файла; членам группы «os» и всем остальным пользователям разрешается только читать или исполнять файл, но не записывать в него данные. Последний раз файл был прочитан 23 октября 1984 года в 13:45, запись последний раз производилась 22 октября 1984 года в 10:30. Индекс изменялся последний раз 23 октября 1984 года в 13:30, хотя никакая информация в это время в файл не записывалась. Ядро кодирует все вышеперечисленные данные в индексе. Обратите внимание на различие в записи на диск содержимого индекса и содержимого файла. Содержимое файла меняется только тогда, когда в файл производится запись. Содержимое индекса меняется как при изменении содержимого файла, так и при изменении владельца файла, прав доступа и набора указателей. Изменение содержимого файла автоматически вызывает коррекцию индекса, однако коррекция индекса еще не означает изменения содержимого файла.
Копия индекса в памяти, кроме полей дискового индекса, включает в себя и следующие поля:
• Состояние индекса в памяти, отражающее
- заблокирован ли индекс,
- ждет ли снятия блокировки с индекса какой-либо процесс,
- отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого индекса,
- отличается ли представление индекса в памяти от своей дисковой копии в результате изменения содержимого файла,
- находится ли файл в верхней точке (см. раздел 5.15).
• Логический номер устройства файловой системы, содержащей файл.
• Номер индекса. Так как индексы на диске хранятся в линейном массиве (см. раздел 2.2.1), ядро идентифицирует номер дискового индекса по его местоположению в массиве. В дисковом индексе это поле не нужно.
• Указатели на другие индексы в памяти. Ядро связывает индексы в хеш-очереди и включает их в список свободных индексов подобно тому, как связывает буферы в буферные хеш-очереди и включает их в список свободных буферов. Хеш-очередь идентифицируется в соответствии с логическим номером устройства и номером индекса. Ядро может располагать в памяти не более одной копии данного дискового индекса, но индексы могут находиться одновременно как в хеш-очереди, так и в списке свободных индексов.
• Счетчик ссылок, означающий количество активных экземпляров файла (таких, которые открыты).
Многие поля в копии индекса, с которой ядро работает в памяти, аналогичны полям в заголовке буфера, и управление индексами похоже на управление буферами. Индекс так же блокируется, в результате чего другим процессам запрещается работа с ним; эти процессы устанавливают в индексе специальный флаг, возвещающий о том, что выполнение обратившихся к индексу процессов следует возобновить, как только блокировка будет снята. Установкой других флагов ядро отмечает противоречия между дисковым индексом и его копией в памяти. Когда ядру нужно будет записать изменения в файл или индекс, ядро перепишет копию индекса из памяти на диск только после проверки этих флагов.
Наиболее разительным различием между копией индекса в памяти и заголовком буфера является наличие счетчика ссылок, подсчитывающего количество активных экземпляров файла. Индекс активен, когда процесс выделяет его, например, при открытии файла. Индекс находится в списке свободных индексов, только если значение его счетчика ссылок равно 0, и это значит, что ядро может переназначить свободный индекс в памяти другому дисковому индексу. Таким образом, список свободных индексов выступает в роли кеша для неактивных индексов. Если процесс пытается обратиться к файлу, чей индекс в этот момент отсутствует в индексном пуле, ядро переназначает свободный индекс из списка для использования этим процессом. С другой стороны, у буфера нет счетчика ссылок; он находится в списке свободных буферов тогда и только тогда, когда он разблокирован.
4.1.2 Обращение к индексам
Ядро идентифицирует индексы по имени файловой системы и номеру индекса и выделяет индексы в памяти по запросам соответствующих алгоритмов. Алгоритм iget назначает индексу место для копии в памяти (Рисунок 4.3); он почти идентичен алгоритму getblk для поиска дискового блока в буферном кеше. Ядро преобразует номера устройства и индекса в имя хеш-очереди и просматривает эту хеш-очередь в поисках индекса. Если индекс не обнаружен, ядро выделяет его из списка свободных индексов и блокирует его. Затем ядро готовится к чтению с диска в память индекса, к которому оно обращается. Ядро уже знает номера индекса и логического устройства и вычисляет номер логического блока на диске, содержащего индекс, с учетом того, сколько дисковых индексов помещается в одном дисковом блоке. Вычисления производятся по формуле
номер блока = ((номер индекса — 1) / число индексов в блоке) + начальный блок в списке индексов
где операция деления возвращает целую часть частного. Например, предположим, что блок 2 является начальным в списке индексов и что в каждом блоке помещаются 8 индексов, тогда индекс с номером 8 находится в блоке 2, а индекс с номером 9 — в блоке 3. Если же в дисковом блоке помещаются 16 индексов, тогда индексы с номерами 8 и 9 располагаются в дисковом блоке с номером 2, а индекс с номером 17 является первым индексом в дисковом блоке 3.
алгоритм iget
входная информация: номер индекса в файловой системе
выходная информация: заблокированный индекс
{
do {
if (индекс в индексном кеше) {
if (индекс заблокирован) {
sleep (до освобождения индекса);
continue; /* цикл с условием продолжения */
}
/* специальная обработка для точек монтирования (глава 5) */
if (индекс в списке свободных индексов) убрать из списка свободных индексов;
увеличить счетчик ссылок для индекса;
return (индекс);
}
/* индекс отсутствует в индексном кеше */
if (список свободных индексов пуст) return (ошибку);
убрать новый индекс из списка свободных индексов;
сбросить номер индекса и файловой системы;
убрать индекс из старой хеш-очереди, поместить в новую;
считать индекс с диска (алгоритм bread);
инициализировать индекс (например, установив счетчик ссылок в 1);
return(индекс);
}
}
Рисунок 4.3. Алгоритм выделения индексов в памяти
Если ядро знает номера устройства и дискового блока, оно читает блок, используя алгоритм bread (глава 2), затем вычисляет смещение индекса в байтах внутри блока по формуле:
((номер индекса – 1) mod (число индексов в блоке)) * размер дискового индекса
Например, если каждый дисковый индекс занимает 64 байта и в блоке помещаются 8 индексов, тогда индекс с номером 8 имеет адрес со смещением 448 байт от начала дискового блока. Ядро убирает индекс в памяти из списка свободных индексов, помещает его в соответствующую хеш-очередь и устанавливает значение счетчика ссылок равным 1. Ядро переписывает поля типа файла и владельца файла, установки прав доступа, число указателей на файл, размер файла и таблицу адресов из дискового индекса в память и возвращает заблокированный в памяти индекс.
Ядро манипулирует с блокировкой индекса и счетчиком ссылок независимо один от другого. Блокировка — это установка, которая действует на время выполнения системного вызова и имеет целью запретить другим процессам обращаться к индексу пока тот в работе (и возможно хранит противоречивые данные). Ядро снимает блокировку по окончании обработки системного вызова: блокировка индекса никогда не выходит за границы системного вызова. Ядро увеличивает значение счетчика ссылок с появлением каждой активной ссылки на файл. Например, в разделе 5.1 будет показано, как ядро увеличивает значение счетчика ссылок тогда, когда процесс открывает файл. Оно уменьшает значение счетчика ссылок только тогда, когда ссылка становится неактивной, например, когда процесс закрывает файл. Таким образом, установка счетчика ссылок сохраняется для множества системных вызовов. Блокировка снимается между двумя обращениями к операционной системе, чтобы позволить процессам одновременно производить разделенный доступ к файлу; установка счетчика ссылок действует между обращениями к операционной системе, чтобы предупредить переназначение ядром активного в памяти индекса. Таким образом, ядро может заблокировать и разблокировать выделенный индекс независимо от значения счетчика ссылок. Выделением и освобождением индексов занимаются и отличные от open системные операции, в чем мы и убедимся в главе 5.
Возвращаясь к алгоритму iget, заметим, что если ядро пытается взять индекс из списка свободных индексов и обнаруживает список пустым, оно сообщает об ошибке. В этом отличие от идеологии, которой следует ядро при работе с дисковыми буферами, где процесс приостанавливает свое выполнение до тех пор, пока буфер не освободится. Процессы контролируют выделение индексов на пользовательском уровне посредством запуска системных операций open и close и поэтому ядро не может гарантировать момент, когда индекс станет доступным. Следовательно, процесс, приостанавливающий свое выполнение в ожидании освобождения индекса, может никогда не возобновиться. Ядро скорее прервет выполнение системного вызова, чем оставит такой процесс в «зависшем» состоянии. Однако, процессы не имеют такого контроля над буферами. Поскольку процесс не может удержать буфер заблокированным в течение выполнения нескольких системных операций, ядро здесь может гарантировать скорое освобождение буфера, и процесс поэтому приостанавливается до того момента, когда он станет доступным.
В предшествующих параграфах рассматривался случай, когда ядро выделяет индекс, отсутствующий в индексном кеше. Если индекс находится в кеше, процесс (A) обнаружит его в хеш-очереди и проверит, не заблокирован ли индекс другим процессом (B). Если индекс заблокирован, процесс A приостанавливается и выставляет флаг у индекса в памяти, показывая, что он ждет освобождения индекса. Когда позднее процесс B разблокирует индекс, он «разбудит» все процессы (включая процесс A), ожидающие освобождения индекса. Когда же наконец процесс A сможет использовать индекс, он заблокирует его, чтобы другие процессы не могли к нему обратиться. Если первоначально счетчик ссылок имел значение, равное 0, индекс также появится в списке свободных индексов, поэтому ядро уберет его оттуда: индекс больше не является свободным. Ядро увеличивает значение счетчика ссылок и возвращает заблокированный индекс.
Если суммировать все вышесказанное, можно отметить, что алгоритм iget имеет отношение к начальной стадии системных вызовов, когда процесс впервые обращается к файлу. Этот алгоритм возвращает заблокированную индексную структуру со значением счетчика ссылок, на 1 большим, чем оно было раньше. Индекс в памяти содержит текущую информацию о состоянии файла. Ядро снимает блокировку с индекса перед выходом из системной операции, поэтому другие системные вызовы могут обратиться к индексу, если пожелают. В главе 5 рассматриваются эти случаи более подробно.
алгоритм iput /* разрешение доступа к индексу в памяти */
входная информация: указатель на индекс в памяти
выходная информация: отсутствует
{
заблокировать индекс если он еще не заблокирован;
уменьшить на 1 счетчик ссылок для индекса;
if (значение счетчика ссылок == 0) {
if (значение счетчика связей == 0) {
освободить дисковые блоки для файла (алгоритм free, раздел 4.7);
установить тип файла равным 0;
освободить индекс (алгоритм ifree, раздел 4.6);
}
if (к файлу обращались или изменился индекс или изменилось содержимое файла)
скорректировать дисковый индекс;
поместить индекс в список свободных индексов;
}
снять блокировку с индекса;
}
Рисунок 4.4. Освобождение индекса
номер блока = ((номер индекса — 1) / число индексов в блоке) + начальный блок в списке индексов
где операция деления возвращает целую часть частного. Например, предположим, что блок 2 является начальным в списке индексов и что в каждом блоке помещаются 8 индексов, тогда индекс с номером 8 находится в блоке 2, а индекс с номером 9 — в блоке 3. Если же в дисковом блоке помещаются 16 индексов, тогда индексы с номерами 8 и 9 располагаются в дисковом блоке с номером 2, а индекс с номером 17 является первым индексом в дисковом блоке 3.
алгоритм iget
входная информация: номер индекса в файловой системе
выходная информация: заблокированный индекс
{
do {
if (индекс в индексном кеше) {
if (индекс заблокирован) {
sleep (до освобождения индекса);
continue; /* цикл с условием продолжения */
}
/* специальная обработка для точек монтирования (глава 5) */
if (индекс в списке свободных индексов) убрать из списка свободных индексов;
увеличить счетчик ссылок для индекса;
return (индекс);
}
/* индекс отсутствует в индексном кеше */
if (список свободных индексов пуст) return (ошибку);
убрать новый индекс из списка свободных индексов;
сбросить номер индекса и файловой системы;
убрать индекс из старой хеш-очереди, поместить в новую;
считать индекс с диска (алгоритм bread);
инициализировать индекс (например, установив счетчик ссылок в 1);
return(индекс);
}
}
Рисунок 4.3. Алгоритм выделения индексов в памяти
Если ядро знает номера устройства и дискового блока, оно читает блок, используя алгоритм bread (глава 2), затем вычисляет смещение индекса в байтах внутри блока по формуле:
((номер индекса – 1) mod (число индексов в блоке)) * размер дискового индекса
Например, если каждый дисковый индекс занимает 64 байта и в блоке помещаются 8 индексов, тогда индекс с номером 8 имеет адрес со смещением 448 байт от начала дискового блока. Ядро убирает индекс в памяти из списка свободных индексов, помещает его в соответствующую хеш-очередь и устанавливает значение счетчика ссылок равным 1. Ядро переписывает поля типа файла и владельца файла, установки прав доступа, число указателей на файл, размер файла и таблицу адресов из дискового индекса в память и возвращает заблокированный в памяти индекс.
Ядро манипулирует с блокировкой индекса и счетчиком ссылок независимо один от другого. Блокировка — это установка, которая действует на время выполнения системного вызова и имеет целью запретить другим процессам обращаться к индексу пока тот в работе (и возможно хранит противоречивые данные). Ядро снимает блокировку по окончании обработки системного вызова: блокировка индекса никогда не выходит за границы системного вызова. Ядро увеличивает значение счетчика ссылок с появлением каждой активной ссылки на файл. Например, в разделе 5.1 будет показано, как ядро увеличивает значение счетчика ссылок тогда, когда процесс открывает файл. Оно уменьшает значение счетчика ссылок только тогда, когда ссылка становится неактивной, например, когда процесс закрывает файл. Таким образом, установка счетчика ссылок сохраняется для множества системных вызовов. Блокировка снимается между двумя обращениями к операционной системе, чтобы позволить процессам одновременно производить разделенный доступ к файлу; установка счетчика ссылок действует между обращениями к операционной системе, чтобы предупредить переназначение ядром активного в памяти индекса. Таким образом, ядро может заблокировать и разблокировать выделенный индекс независимо от значения счетчика ссылок. Выделением и освобождением индексов занимаются и отличные от open системные операции, в чем мы и убедимся в главе 5.
Возвращаясь к алгоритму iget, заметим, что если ядро пытается взять индекс из списка свободных индексов и обнаруживает список пустым, оно сообщает об ошибке. В этом отличие от идеологии, которой следует ядро при работе с дисковыми буферами, где процесс приостанавливает свое выполнение до тех пор, пока буфер не освободится. Процессы контролируют выделение индексов на пользовательском уровне посредством запуска системных операций open и close и поэтому ядро не может гарантировать момент, когда индекс станет доступным. Следовательно, процесс, приостанавливающий свое выполнение в ожидании освобождения индекса, может никогда не возобновиться. Ядро скорее прервет выполнение системного вызова, чем оставит такой процесс в «зависшем» состоянии. Однако, процессы не имеют такого контроля над буферами. Поскольку процесс не может удержать буфер заблокированным в течение выполнения нескольких системных операций, ядро здесь может гарантировать скорое освобождение буфера, и процесс поэтому приостанавливается до того момента, когда он станет доступным.
В предшествующих параграфах рассматривался случай, когда ядро выделяет индекс, отсутствующий в индексном кеше. Если индекс находится в кеше, процесс (A) обнаружит его в хеш-очереди и проверит, не заблокирован ли индекс другим процессом (B). Если индекс заблокирован, процесс A приостанавливается и выставляет флаг у индекса в памяти, показывая, что он ждет освобождения индекса. Когда позднее процесс B разблокирует индекс, он «разбудит» все процессы (включая процесс A), ожидающие освобождения индекса. Когда же наконец процесс A сможет использовать индекс, он заблокирует его, чтобы другие процессы не могли к нему обратиться. Если первоначально счетчик ссылок имел значение, равное 0, индекс также появится в списке свободных индексов, поэтому ядро уберет его оттуда: индекс больше не является свободным. Ядро увеличивает значение счетчика ссылок и возвращает заблокированный индекс.
Если суммировать все вышесказанное, можно отметить, что алгоритм iget имеет отношение к начальной стадии системных вызовов, когда процесс впервые обращается к файлу. Этот алгоритм возвращает заблокированную индексную структуру со значением счетчика ссылок, на 1 большим, чем оно было раньше. Индекс в памяти содержит текущую информацию о состоянии файла. Ядро снимает блокировку с индекса перед выходом из системной операции, поэтому другие системные вызовы могут обратиться к индексу, если пожелают. В главе 5 рассматриваются эти случаи более подробно.
алгоритм iput /* разрешение доступа к индексу в памяти */
входная информация: указатель на индекс в памяти
выходная информация: отсутствует
{
заблокировать индекс если он еще не заблокирован;
уменьшить на 1 счетчик ссылок для индекса;
if (значение счетчика ссылок == 0) {
if (значение счетчика связей == 0) {
освободить дисковые блоки для файла (алгоритм free, раздел 4.7);
установить тип файла равным 0;
освободить индекс (алгоритм ifree, раздел 4.6);
}
if (к файлу обращались или изменился индекс или изменилось содержимое файла)
скорректировать дисковый индекс;
поместить индекс в список свободных индексов;
}
снять блокировку с индекса;
}
Рисунок 4.4. Освобождение индекса
4.1.3 Освобождение индексов
В том случае, когда ядро освобождает индекс (алгоритм iput, Рисунок 4.4), оно уменьшает значение счетчика ссылок для него. Если это значение становится равным 0, ядро переписывает индекс на диск в том случае, когда копия индекса в памяти отличается от дискового индекса. Они различаются, если изменилось содержимое файла, если к файлу производилось обращение или если изменились владелец файла либо права доступа к файлу. Ядро помещает индекс в список свободных индексов, наиболее эффективно располагая индекс в кеше на случай, если он вскоре понадобится вновь. Ядро может также освободить все связанные с файлом информационные блоки и индекс, если число ссылок на файл равно 0.
4.2 СТРУКТУРА ФАЙЛА ОБЫЧНОГО ТИПА
Как уже говорилось, индекс включает в себя таблицу адресов расположения информации файла на диске. Так как каждый блок на диске адресуется по своему номеру, в этой таблице хранится совокупность номеров дисковых блоков. Если бы данные файла занимали непрерывный участок на диске (то есть файл занимал бы линейную последовательность дисковых блоков), то для обращения к данным в файле было бы достаточно хранить в индексе адрес начального блока и размер файла. Однако, такая стратегия размещения данных не позволяет осуществлять простое расширение и сжатие файлов в файловой системе без риска фрагментации свободного пространства памяти на диске. Более того, ядру пришлось бы выделять и резервировать непрерывное пространство в файловой системе перед выполнением операций, могущих привести к увеличению размера файла.
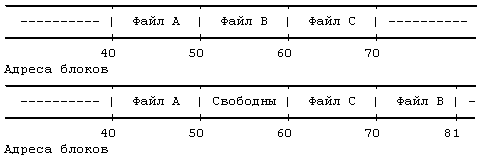
Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства
Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов.
В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла.
Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку «прямая адресация» на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку «одинарная косвенная адресация», указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку «двойная косвенная адресация», содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку «тройная косвенная адресация», содержит список номеров блоков двойной косвенной адресации.
В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля «размер файла» в индексе — 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32).
Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На Рисунке 4.8 представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске.

Рисунок 4.6. Блоки прямой и косвенной адресации в индексе
10 блоков прямой адресации по 1 Кбайту каждый = 10 Кбайт
1 блок косвенной адресации с 256 блоками прямой адресации = 256 Кбайт
1 блок двойной косвенной адресации с 256 блоками косвенной адресации = 64 Мбайта
1 блок тройной косвенной адресации с 256 блоками двойной косвенной адресации = 16 Гбайт
Рисунок 4.7. Объем файла в байтах при размере блока 1 Кбайт
алгоритм bmap /* отображение адреса смещения в байтах от начала логического файла на адрес блока в файловой системе */
входная информация:
(1) индекс
(2) смещение в байтах
выходная информация:
(1) номер блока в файловой системе
(2) смещение в байтах внутри блока
(3) число байт ввода-вывода в блок
(4) номер блока с продвижением
{
вычислить номер логического блока в файле исходя из заданного смещения в байтах;
вычислить номер начального байта в блоке для ввода-вывода; /* выходная информация 2 */
вычислить количество байт для копирования пользователю; /* выходная информация 3 */
проверить возможность чтения с продвижением, пометить индекс; /* выходная информация 4 */
определить уровень косвенности;
do (пока уровень косвенности другой) {
определить указатель в индексе или блок косвенной адресации исходя из номера логического блока в файле;
получить номер дискового блока из индекса или из блока косвенной адресации;
освободить буфер от данных, полученных в результате выполнения предыдущей операции чтения с диска (алгоритм brelse);
if (число уровней косвенности исчерпано) return (номер блока);
считать дисковый блок косвенной адресации (алгоритм bread);
установить номер логического блока в файле исходя из уровня косвенности;
}
}
Рисунок 4.8. Преобразование адреса смещения в номер блока в файловой системе
Рассмотрим формат файла в блоках (Рисунок 4.9) и предположим, что дисковый блок занимает 1024 байта. Если процессу нужно обратиться к байту, имеющему смещение от начала файла, равное 9000, в результате вычислений ядро приходит к выводу, что этот байт располагается в блоке прямой адресации с номером 8 (начиная с 0). Затем ядро обращается к блоку с номером 367; 808-й байт в этом блоке (если вести отсчет с 0) и является 9000-м байтом в файле. Если процессу нужно обратиться по адресу, указанному смещением 350000 байт от начала файла, он должен считать блок двойной косвенной адресации, который на рисунке имеет номер 9156. Так как блок косвенной адресации имеет место для 256 номеров блоков, первым байтом, к которому будет получен доступ в результате обращения к блоку двойной косвенной адресации, будет байт с номером 272384 (256К + 10К); таким образом, байт с номером 350000 будет иметь в блоке двойной косвенной адресации номер 77616. Поскольку каждый блок одинарной косвенной адресации позволяет обращаться к 256 Кбайтам, байт с номером 350000 должен располагаться в нулевом блоке одинарной косвенной адресации для блока двойной косвенной адресации, а именно в блоке 331. Так как в каждом блоке прямой адресации для блока одинарной косвенной адресации хранится 1 Кбайт, байт с номером 77616 находится в 75-м блоке прямой адресации для блока одинарной косвенной адресации, а именно в блоке 3333. Наконец, байт с номером в файле 350000 имеет в блоке 3333 номер 816.
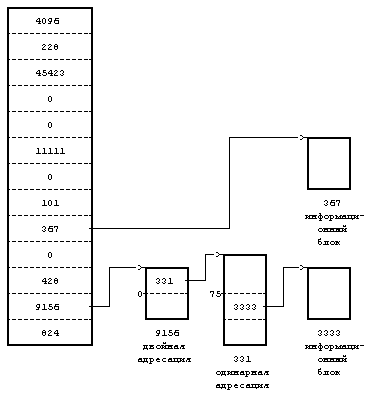
Рисунок 4.9. Размещение блоков в файле и его индексе
При ближайшем рассмотрении Рисунка 4.9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (см. следующую главу). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам.
Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта! [11]Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро.
В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5.
Рисунок 4.5. Размещение непрерывных файлов и фрагментация свободного пространства
Предположим, например, что пользователь создает три файла, A, B и C, каждый из которых занимает 10 дисковых блоков, а также что система выделила для размещения этих трех файлов непрерывное место. Если потом пользователь захочет добавить 5 блоков с информацией к среднему файлу, B, ядру придется скопировать файл B в то место в файловой системе, где найдется окно размером 15 блоков. В дополнение к затратам ресурсов на проведение этой операции дисковые блоки, занимаемые информацией файла B, станут неиспользуемыми, если только они не понадобятся файлам размером не более 10 блоков (Рисунок 4.5). Ядро могло бы минимизировать фрагментацию пространства памяти, периодически запуская процедуры чистки памяти, уплотняющие имеющуюся память, но это потребовало бы дополнительного расхода временных и системных ресурсов.
В целях повышения гибкости ядро присоединяет к файлу по одному блоку, позволяя информации файла быть разбросанной по всей файловой системе. Но такая схема размещения усложняет задачу поиска данных. Таблица адресов содержит список номеров блоков, содержащих принадлежащую файлу информацию, однако простые вычисления показывают, что линейным списком блоков файла в индексе трудно управлять. Если логический блок занимает 1 Кбайт, то файлу, состоящему из 10 Кбайт, потребовался бы индекс на 10 номеров блоков, а файлу, состоящему из 100 Кбайт, понадобился бы индекс на 100 номеров блоков. Либо пусть размер индекса будет варьироваться в зависимости от размера файла, либо пришлось бы установить относительно жесткое ограничение на размер файла.
Для того, чтобы небольшая структура индекса позволяла работать с большими файлами, таблица адресов дисковых блоков приводится в соответствие со структурой, представленной на Рисунке 4.6. Версия V системы UNIX работает с 13 точками входа в таблицу адресов индекса, но принципиальные моменты не зависят от количества точек входа. Блок, имеющий пометку «прямая адресация» на рисунке, содержит номера дисковых блоков, в которых хранятся реальные данные. Блок, имеющий пометку «одинарная косвенная адресация», указывает на блок, содержащий список номеров блоков прямой адресации. Чтобы обратиться к данным с помощью блока косвенной адресации, ядро должно считать этот блок, найти соответствующий вход в блок прямой адресации и, считав блок прямой адресации, обнаружить данные. Блок, имеющий пометку «двойная косвенная адресация», содержит список номеров блоков одинарной косвенной адресации, а блок, имеющий пометку «тройная косвенная адресация», содержит список номеров блоков двойной косвенной адресации.
В принципе, этот метод можно было бы распространить и на поддержку блоков четверной косвенной адресации, блоков пятерной косвенной адресации и так далее, но на практике оказывается достаточно имеющейся структуры. Предположим, что размер логического блока в файловой системе 1 Кбайт и что номер блока занимает 32 бита (4 байта). Тогда в блоке может храниться до 256 номеров блоков. Расчеты показывают (Рисунок 4.7), что максимальный размер файла превышает 16 Гбайт, если использовать в индексе 10 блоков прямой адресации и 1 одинарной косвенной адресации, 1 двойной косвенной адресации и 1 тройной косвенной адресации. Если же учесть, что длина поля «размер файла» в индексе — 32 бита, то размер файла в действительности ограничен 4 Гбайтами (2 в степени 32).
Процессы обращаются к информации в файле, задавая смещение в байтах. Они рассматривают файл как поток байтов и ведут подсчет байтов, начиная с нулевого адреса и заканчивая адресом, равным размеру файла. Ядро переходит от байтов к блокам: файл начинается с нулевого логического блока и заканчивается блоком, номер которого определяется исходя из размера файла. Ядро обращается к индексу и превращает логический блок, принадлежащий файлу, в соответствующий дисковый блок. На Рисунке 4.8 представлен алгоритм bmap пересчета смещения в байтах от начала файла в номер физического блока на диске.
Рисунок 4.6. Блоки прямой и косвенной адресации в индексе
10 блоков прямой адресации по 1 Кбайту каждый = 10 Кбайт
1 блок косвенной адресации с 256 блоками прямой адресации = 256 Кбайт
1 блок двойной косвенной адресации с 256 блоками косвенной адресации = 64 Мбайта
1 блок тройной косвенной адресации с 256 блоками двойной косвенной адресации = 16 Гбайт
Рисунок 4.7. Объем файла в байтах при размере блока 1 Кбайт
алгоритм bmap /* отображение адреса смещения в байтах от начала логического файла на адрес блока в файловой системе */
входная информация:
(1) индекс
(2) смещение в байтах
выходная информация:
(1) номер блока в файловой системе
(2) смещение в байтах внутри блока
(3) число байт ввода-вывода в блок
(4) номер блока с продвижением
{
вычислить номер логического блока в файле исходя из заданного смещения в байтах;
вычислить номер начального байта в блоке для ввода-вывода; /* выходная информация 2 */
вычислить количество байт для копирования пользователю; /* выходная информация 3 */
проверить возможность чтения с продвижением, пометить индекс; /* выходная информация 4 */
определить уровень косвенности;
do (пока уровень косвенности другой) {
определить указатель в индексе или блок косвенной адресации исходя из номера логического блока в файле;
получить номер дискового блока из индекса или из блока косвенной адресации;
освободить буфер от данных, полученных в результате выполнения предыдущей операции чтения с диска (алгоритм brelse);
if (число уровней косвенности исчерпано) return (номер блока);
считать дисковый блок косвенной адресации (алгоритм bread);
установить номер логического блока в файле исходя из уровня косвенности;
}
}
Рисунок 4.8. Преобразование адреса смещения в номер блока в файловой системе
Рассмотрим формат файла в блоках (Рисунок 4.9) и предположим, что дисковый блок занимает 1024 байта. Если процессу нужно обратиться к байту, имеющему смещение от начала файла, равное 9000, в результате вычислений ядро приходит к выводу, что этот байт располагается в блоке прямой адресации с номером 8 (начиная с 0). Затем ядро обращается к блоку с номером 367; 808-й байт в этом блоке (если вести отсчет с 0) и является 9000-м байтом в файле. Если процессу нужно обратиться по адресу, указанному смещением 350000 байт от начала файла, он должен считать блок двойной косвенной адресации, который на рисунке имеет номер 9156. Так как блок косвенной адресации имеет место для 256 номеров блоков, первым байтом, к которому будет получен доступ в результате обращения к блоку двойной косвенной адресации, будет байт с номером 272384 (256К + 10К); таким образом, байт с номером 350000 будет иметь в блоке двойной косвенной адресации номер 77616. Поскольку каждый блок одинарной косвенной адресации позволяет обращаться к 256 Кбайтам, байт с номером 350000 должен располагаться в нулевом блоке одинарной косвенной адресации для блока двойной косвенной адресации, а именно в блоке 331. Так как в каждом блоке прямой адресации для блока одинарной косвенной адресации хранится 1 Кбайт, байт с номером 77616 находится в 75-м блоке прямой адресации для блока одинарной косвенной адресации, а именно в блоке 3333. Наконец, байт с номером в файле 350000 имеет в блоке 3333 номер 816.
Рисунок 4.9. Размещение блоков в файле и его индексе
При ближайшем рассмотрении Рисунка 4.9 обнаруживается, что несколько входов для блока в индексе имеют значение 0 и это значит, что в данных записях информация о логических блоках отсутствует. Такое имеет место, если в соответствующие блоки файла никогда не записывалась информация и по этой причине у номеров блоков остались их первоначальные нулевые значения. Для таких блоков пространство на диске не выделяется. Подобное расположение блоков в файле вызывается процессами, запускающими системные операции lseek и write (см. следующую главу). В следующей главе также объясняется, каким образом ядро обрабатывает системные вызовы операции read, с помощью которой производится обращение к блокам.
Преобразование адресов с большими смещениями, в частности с использованием блоков тройной косвенной адресации, является сложной процедурой, требующей от ядра обращения уже к трем дисковым блокам в дополнение к индексу и информационному блоку. Даже если ядро обнаружит блоки в буферном кеше, операция останется дорогостоящей, так как ядру придется многократно обращаться к буферному кешу и приостанавливать свою работу в ожидании снятия блокировки с буферов. Насколько эффективен этот алгоритм на практике? Это зависит от того, как используется система, а также от того, кто является пользователем и каков состав задач, вызывающий потребность в более частом обращении к большим или, наоборот, маленьким файлам. Однако, как уже было замечено [Mullender 84], большинство файлов в системе UNIX имеет размер, не превышающий 10 Кбайт и даже 1 Кбайта! [11]Поскольку 10 Кбайт файла располагаются в блоках прямой адресации, к большей части данных, хранящихся в файлах, доступ может производиться за одно обращение к диску. Поэтому в отличие от обращения к большим файлам, работа с файлами стандартного размера протекает быстро.
В двух модификациях только что описанной структуры индекса предпринимается попытка использовать размерные характеристики файла. Основной принцип в реализации файловой системы BSD 4.2 [McKusick 84] состоит в том, что чем больше объем данных, к которым ядро может получить доступ за одно обращение к диску, тем быстрее протекает работа с файлом. Это свидетельствует в пользу увеличения размера логического блока на диске, поэтому в системе BSD разрешается иметь логические блоки размером 4 или 8 Кбайт. Однако, увеличение размера блоков на диске приводит к увеличению фрагментации блоков, при которой значительные участки дискового пространства остаются неиспользуемыми. Например, если размер логического блока 8 Кбайт, тогда файл размером 12 Кбайт занимает 1 полный блок и половину второго блока. Другая половина второго блока (4 Кбайта) фактически теряется; другие файлы не могут использовать ее для хранения данных. Если размеры файлов таковы, что число байт, попавших в последний блок, является равномерно распределенной величиной, то средние потери дискового пространства составляют полблока на каждый файл; объем теряемого дискового пространства достигает в файловой системе с логическими блоками размером 4 Кбайта 45% [McKusick 84]. Выход из этой ситуации в системе BSD состоит в выделении только части блока (фрагмента) для размещения оставшейся информации файла. Один дисковый блок может включать в себя фрагменты, принадлежащие нескольким файлам. Некоторые подробности этой реализации исследуются на примере упражнения в главе 5.