Страница:
do while(буфер не будет обнаружен)
{
P(семафор хеш-очереди);
if (блок находится в хеш-очереди) {
if (операция CP(семафор буфера) завершается неудачно) { /* буфер занят */
V(семафор хеш-очереди);
P(семафор буфера); /* приостанов до момента освобождения */
if (операция CP(семафор хеш-очереди) завершается неудачно) {
V(семафор буфера);
continue; /* выход в цикл "выполнять" */
}
else if (номер устройства или номер блока изменились) {
V(семафор буфера);
V(семафор хеш-очереди);
}
}
do while(операция CP(семафор списка свободных буферов) не завершится успешно);
/* "кольцевой цикл" */
пометить буфер занятым;
убрать буфер из списка свободных буферов;
V(семафор списка свободных буферов);
V(семафор хеш-очереди);
return буфер;
}
else
/* буфер отсутствует в хеш-очереди здесь начинается выполнение оставшейся части алгоритма */
}
}
Рисунок 12.14. Выделение буфера с использованием семафоров
На Рисунке 12.14 показана первая часть алгоритма getblk, реализованная в многопроцессорной системе с использованием семафоров. Просматривая буферный кеш в поисках указанного блока, ядро с помощью операции P захватывает семафор, принадлежащий хеш-очереди. Если над семафором уже кем-то произведена операция данного типа, текущий процесс приостанавливается до тех пор, пока процесс, захвативший семафор, не освободит его, выполнив операцию V. Когда текущий процесс получает право исключительного контроля над хеш-очередью, он приступает к поиску подходящего буфера. Предположим, что буфер находится в хеш-очереди. Ядро (процесс A) пытается захватить буфер, но если оно использует операцию P и если буфер уже захвачен, ядру придется приостановить свою работу, оставив хеш-очередь заблокированной и не допуская таким образом обращений к ней со стороны других процессов, даже если последние ведут поиск незахваченных буферов. Пусть вместо этого процесс A захватывает буфер, используя операцию CP; если операция завершается успешно, буфер становится открытым для процесса. Процесс A захватывает семафор, принадлежащий списку свободных буферов, выполняя операцию CP, поскольку семафор захватывается на непродолжительное время и, следовательно, приостанавливать свою работу, выполняя операцию P, процесс просто не имеет возможности. Ядро убирает буфер из списка свободных буферов, снимает блокировку со списка и с хеш-очереди и возвращает захваченный буфер. Предположим, что операция CP над буфером завершилась неудачно из-за того, что семафор, принадлежащий буферу, оказался захваченным. Процесс A освобождает семафор, связанный с хеш-очередью, и приостанавливается, пытаясь выполнить операцию P над семафором буфера. Операция P над семафором будет выполняться, несмотря на то, что операция CP уже потерпела неудачу. По завершении выполнения операции процесс A получает власть над буфером. Так как в оставшейся части алгоритма предполагается, что буфер и хеш-очередь захвачены, процесс A теперь пытается захватить хеш-очередь [34]. Поскольку очередность захвата здесь (сначала семафор буфера, потом семафор очереди) обратна вышеуказанной очередности, над семафором выполняется операция CP. Если попытка захвата заканчивается неудачей, имеет место обычная обработка, требующаяся по ходу задачи. Но если захват удается, ядро не может быть уверено в том, что захвачен корректный буфер, поскольку содержимое буфера могло быть ранее изменено другим процессом, обнаружившим буфер в списке свободных буферов и захватившим на время его семафор. Процесс A, ожидая освобождения семафора, не имеет ни малейшего представления о том, является ли интересующий его буфер тем буфером, который ему нужен, и поэтому прежде всего он должен убедиться в правильности содержимого буфера; если проверка дает отрицательный результат, алгоритм запускается сначала. Если содержимое буфера корректно, процесс A завершает выполнение алгоритма.
Оставшуюся часть алгоритма можно рассмотреть в качестве упражнения.
12.3.3.2 Wait
12.3.3.3 Драйверы
12.3.3.4 Фиктивные процессы
12.4 СИСТЕМА TUNIS
12.5 УЗКИЕ МЕСТА В ФУНКЦИОНИРОВАНИИ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
12.6 УПРАЖНЕНИЯ
ГЛАВА 13. РАСПРЕДЕЛЕННЫЕ СИСТЕМЫ
13.1 ПЕРИФЕРИЙНЫЕ ПРОЦЕССОРЫ
P(семафор хеш-очереди);
if (блок находится в хеш-очереди) {
if (операция CP(семафор буфера) завершается неудачно) { /* буфер занят */
V(семафор хеш-очереди);
P(семафор буфера); /* приостанов до момента освобождения */
if (операция CP(семафор хеш-очереди) завершается неудачно) {
V(семафор буфера);
continue; /* выход в цикл "выполнять" */
}
else if (номер устройства или номер блока изменились) {
V(семафор буфера);
V(семафор хеш-очереди);
}
}
do while(операция CP(семафор списка свободных буферов) не завершится успешно);
/* "кольцевой цикл" */
пометить буфер занятым;
убрать буфер из списка свободных буферов;
V(семафор списка свободных буферов);
V(семафор хеш-очереди);
return буфер;
}
else
/* буфер отсутствует в хеш-очереди здесь начинается выполнение оставшейся части алгоритма */
}
}
Рисунок 12.14. Выделение буфера с использованием семафоров
На Рисунке 12.14 показана первая часть алгоритма getblk, реализованная в многопроцессорной системе с использованием семафоров. Просматривая буферный кеш в поисках указанного блока, ядро с помощью операции P захватывает семафор, принадлежащий хеш-очереди. Если над семафором уже кем-то произведена операция данного типа, текущий процесс приостанавливается до тех пор, пока процесс, захвативший семафор, не освободит его, выполнив операцию V. Когда текущий процесс получает право исключительного контроля над хеш-очередью, он приступает к поиску подходящего буфера. Предположим, что буфер находится в хеш-очереди. Ядро (процесс A) пытается захватить буфер, но если оно использует операцию P и если буфер уже захвачен, ядру придется приостановить свою работу, оставив хеш-очередь заблокированной и не допуская таким образом обращений к ней со стороны других процессов, даже если последние ведут поиск незахваченных буферов. Пусть вместо этого процесс A захватывает буфер, используя операцию CP; если операция завершается успешно, буфер становится открытым для процесса. Процесс A захватывает семафор, принадлежащий списку свободных буферов, выполняя операцию CP, поскольку семафор захватывается на непродолжительное время и, следовательно, приостанавливать свою работу, выполняя операцию P, процесс просто не имеет возможности. Ядро убирает буфер из списка свободных буферов, снимает блокировку со списка и с хеш-очереди и возвращает захваченный буфер. Предположим, что операция CP над буфером завершилась неудачно из-за того, что семафор, принадлежащий буферу, оказался захваченным. Процесс A освобождает семафор, связанный с хеш-очередью, и приостанавливается, пытаясь выполнить операцию P над семафором буфера. Операция P над семафором будет выполняться, несмотря на то, что операция CP уже потерпела неудачу. По завершении выполнения операции процесс A получает власть над буфером. Так как в оставшейся части алгоритма предполагается, что буфер и хеш-очередь захвачены, процесс A теперь пытается захватить хеш-очередь [34]. Поскольку очередность захвата здесь (сначала семафор буфера, потом семафор очереди) обратна вышеуказанной очередности, над семафором выполняется операция CP. Если попытка захвата заканчивается неудачей, имеет место обычная обработка, требующаяся по ходу задачи. Но если захват удается, ядро не может быть уверено в том, что захвачен корректный буфер, поскольку содержимое буфера могло быть ранее изменено другим процессом, обнаружившим буфер в списке свободных буферов и захватившим на время его семафор. Процесс A, ожидая освобождения семафора, не имеет ни малейшего представления о том, является ли интересующий его буфер тем буфером, который ему нужен, и поэтому прежде всего он должен убедиться в правильности содержимого буфера; если проверка дает отрицательный результат, алгоритм запускается сначала. Если содержимое буфера корректно, процесс A завершает выполнение алгоритма.
Оставшуюся часть алгоритма можно рассмотреть в качестве упражнения.
12.3.3.2 Wait
многопроцессорная версия алгоритма wait
{
для (;;) { /* цикл */
перебор всех процессов-потомков:
if (потомок находится в состоянии "прекращения существования") return ;
P(zombie_semaphore); /* начальное значение — 0 */
}
}
Рисунок 12.15. Многопроцессорная версия алгоритма wait
Из главы 7 мы уже знаем о том, что во время выполнения системной функции wait процесс приостанавливает свою работу до момента завершения выполнения своего потомка. В многопроцессорной системе перед процессом встает задача не упустить при выполнении алгоритма wait потомка, прекратившего существование с помощью функции exit; если, например, в то время, пока на одном процессоре процесс-родитель запускает функцию wait, на другом процессоре его потомок завершил свою работу, родителю нет необходимости приостанавливать свое выполнение в ожидании завершения второго потомка. В каждой записи таблицы процессов имеется семафор, именуемый zombie_semaphore и имеющий в начале нулевое значение. Этот семафор используется при организации взаимодействия wait/exit (Рисунок 12.15). Когда потомок завершает работу, он выполняет над семафором своего родителя операцию V, выводя родителя из состояния приостанова, если тот перешел в него во время исполнения функции wait. Если потомок завершился раньше, чем родитель запустил функцию wait, этот факт будет обнаружен родителем, который тут же выйдет из состояния ожидания. Если оба процесса исполняют функции exit и wait параллельно, но потомок исполняет функцию exit уже после того, как родитель проверил его статус, операция V, выполненная потомком, воспрепятствует переходу родителя в состояние приостанова. В худшем случае процесс-родитель просто повторяет цикл лишний раз.
{
для (;;) { /* цикл */
перебор всех процессов-потомков:
if (потомок находится в состоянии "прекращения существования") return ;
P(zombie_semaphore); /* начальное значение — 0 */
}
}
Рисунок 12.15. Многопроцессорная версия алгоритма wait
Из главы 7 мы уже знаем о том, что во время выполнения системной функции wait процесс приостанавливает свою работу до момента завершения выполнения своего потомка. В многопроцессорной системе перед процессом встает задача не упустить при выполнении алгоритма wait потомка, прекратившего существование с помощью функции exit; если, например, в то время, пока на одном процессоре процесс-родитель запускает функцию wait, на другом процессоре его потомок завершил свою работу, родителю нет необходимости приостанавливать свое выполнение в ожидании завершения второго потомка. В каждой записи таблицы процессов имеется семафор, именуемый zombie_semaphore и имеющий в начале нулевое значение. Этот семафор используется при организации взаимодействия wait/exit (Рисунок 12.15). Когда потомок завершает работу, он выполняет над семафором своего родителя операцию V, выводя родителя из состояния приостанова, если тот перешел в него во время исполнения функции wait. Если потомок завершился раньше, чем родитель запустил функцию wait, этот факт будет обнаружен родителем, который тут же выйдет из состояния ожидания. Если оба процесса исполняют функции exit и wait параллельно, но потомок исполняет функцию exit уже после того, как родитель проверил его статус, операция V, выполненная потомком, воспрепятствует переходу родителя в состояние приостанова. В худшем случае процесс-родитель просто повторяет цикл лишний раз.
12.3.3.3 Драйверы
В многопроцессорной реализации вычислительной системы на базе компьютеров AT&T 3B20 семафоры в структуру загрузочного кода драйверов не включаются, а операции типа P и V выполняются в точках входа в каждый драйвер (см. [Bach 84]). В главе 10 мы говорили о том, что интерфейс, реализуемый драйверами устройств, характеризуется очень небольшим числом точек входа (на практике их около 20). Защита драйверов осуществляется на уровне точек входа в них:
P(семафор драйвера);
открыть (драйвер);
V(семафор драйвера);
Если для всех точек входа в драйвер использовать один и тот же семафор, но при этом для разных драйверов — разные семафоры, критический участок программы драйвера будет исполняться процессом монопольно. Семафоры могут назначаться как отдельному устройству, так и классам устройств. Так, например, отдельный семафор может быть связан и с отдельным физическим терминалом и со всеми терминалами сразу. В первом случае быстродействие системы выше, ибо процессы, обращающиеся к терминалу, не захватывают семафор, имеющий отношение к другим терминалам, как во втором случае. Драйверы некоторых устройств, однако, поддерживают внутреннюю связь с другими драйверами; в таких случаях использование одного семафора для класса устройств облегчает понимание задачи. В качестве альтернативы в вычислительной системе 3B20A предоставлена возможность такого конфигурирования отдельных устройств, при котором программы драйвера запускаются на точно указанных процессорах.
Проблемы возникают тогда, когда драйвер прерывает работу системы и его семафор захвачен: программа обработки прерываний не может быть вызвана, так как иначе возникла бы угроза разрушения данных. С другой стороны, ядро не может оставить прерывание необработанным. Система 3B20A выстраивает прерывания в очередь и ждет момента освобождения семафора, когда вызов программы обработки прерываний не будет иметь опасные последствия.
P(семафор драйвера);
открыть (драйвер);
V(семафор драйвера);
Если для всех точек входа в драйвер использовать один и тот же семафор, но при этом для разных драйверов — разные семафоры, критический участок программы драйвера будет исполняться процессом монопольно. Семафоры могут назначаться как отдельному устройству, так и классам устройств. Так, например, отдельный семафор может быть связан и с отдельным физическим терминалом и со всеми терминалами сразу. В первом случае быстродействие системы выше, ибо процессы, обращающиеся к терминалу, не захватывают семафор, имеющий отношение к другим терминалам, как во втором случае. Драйверы некоторых устройств, однако, поддерживают внутреннюю связь с другими драйверами; в таких случаях использование одного семафора для класса устройств облегчает понимание задачи. В качестве альтернативы в вычислительной системе 3B20A предоставлена возможность такого конфигурирования отдельных устройств, при котором программы драйвера запускаются на точно указанных процессорах.
Проблемы возникают тогда, когда драйвер прерывает работу системы и его семафор захвачен: программа обработки прерываний не может быть вызвана, так как иначе возникла бы угроза разрушения данных. С другой стороны, ядро не может оставить прерывание необработанным. Система 3B20A выстраивает прерывания в очередь и ждет момента освобождения семафора, когда вызов программы обработки прерываний не будет иметь опасные последствия.
12.3.3.4 Фиктивные процессы
Когда ядро выполняет переключение контекста в однопроцессорной системе, оно функционирует в контексте процесса, уступающего управление (см. главу 6). Если в системе нет процессов, готовых к запуску, ядро переходит в состояние простоя в контексте процесса, выполнявшегося последним. Получив прерывание от таймера или других периферийных устройств, оно обрабатывает его в контексте того же процесса.
В многопроцессорной системе ядро не может простаивать в контексте процесса, выполнявшегося последним. Посмотрим, что произойдет после того, как процесс, приостановивший свою работу на процессоре A, выйдет из состояния приостанова. Процесс в целом готов к запуску, но он запускается не сразу же по выходе из состояния приостанова, даже несмотря на то, что его контекст уже находится в распоряжении процессора A. Если этот процесс выбирается для запуска процессором B, последний переключается на его контекст и возобновляет его выполнение. Когда в результате прерывания процессор A выйдет из простоя, он будет продолжать свою работу в контексте процесса A до тех пор, пока не произведет переключение контекста. Таким образом, в течение короткого промежутка времени с одним и тем же адресным пространством (в частности, со стеком ядра) будут вести работу (и, что весьма вероятно, производить запись) сразу два процессора.
Решение этой проблемы состоит в создании некоторого фиктивного процесса; когда процессор находится в состоянии простоя, ядро переключается на контекст фиктивного процесса, делая этот контекст текущим для бездействующего процессора. Контекст фиктивного процесса состоит только из стека ядра; этот процесс не является выполнимым и не выбирается для запуска. Поскольку каждый процессор простаивает в контексте своего собственного фиктивного процесса, навредить друг другу процессоры уже не могут.
В многопроцессорной системе ядро не может простаивать в контексте процесса, выполнявшегося последним. Посмотрим, что произойдет после того, как процесс, приостановивший свою работу на процессоре A, выйдет из состояния приостанова. Процесс в целом готов к запуску, но он запускается не сразу же по выходе из состояния приостанова, даже несмотря на то, что его контекст уже находится в распоряжении процессора A. Если этот процесс выбирается для запуска процессором B, последний переключается на его контекст и возобновляет его выполнение. Когда в результате прерывания процессор A выйдет из простоя, он будет продолжать свою работу в контексте процесса A до тех пор, пока не произведет переключение контекста. Таким образом, в течение короткого промежутка времени с одним и тем же адресным пространством (в частности, со стеком ядра) будут вести работу (и, что весьма вероятно, производить запись) сразу два процессора.
Решение этой проблемы состоит в создании некоторого фиктивного процесса; когда процессор находится в состоянии простоя, ядро переключается на контекст фиктивного процесса, делая этот контекст текущим для бездействующего процессора. Контекст фиктивного процесса состоит только из стека ядра; этот процесс не является выполнимым и не выбирается для запуска. Поскольку каждый процессор простаивает в контексте своего собственного фиктивного процесса, навредить друг другу процессоры уже не могут.
12.4 СИСТЕМА TUNIS
Пользовательский интерфейс системы Tunis совместим с аналогичным интерфейсом системы UNIX, но ядро этой системы, разработанное на языке Concurrent Euclid, состоит из процессов, управляющих каждой частью системы. Проблема взаимного исключения решается в системе Tunis довольно просто, так как в каждый момент времени исполняется не более одной копии управляемого ядром процесса, кроме того, процессы работают только с теми структурами данных, которые им принадлежат. Системные процессы активизируются запросами на ввод, защиту очереди запросов осуществляет процедура программного монитора. Эта процедура усиливает взаимное исключение, разрешая доступ к своей исполняемой части в каждый момент времени не более, чем одному процессу. Механизм монитора отличается от механизма семафоров тем, что, во-первых, благодаря последним усиливается модульность программ (операции P и V присутствуют на входе в процедуру монитора и на выходе из нее), а во-вторых, сгенерированный компилятором код уже содержит элементы синхронизации. Холт отмечает, что разработка таких систем облегчается, если используется язык, поддерживающий мониторы и включающий понятие параллелизма (см. [Holt 83], стр.190). При всем при этом внутренняя структура системы Tunis отличается от традиционной реализации системы UNIX радикальным образом.
12.5 УЗКИЕ МЕСТА В ФУНКЦИОНИРОВАНИИ МНОГОПРОЦЕССОРНЫХ СИСТЕМ
В данной главе нами были рассмотрены два метода реализации многопроцессорных версий системы UNIX: конфигурация, состоящая из главного и подчиненного процессоров, в которой только один процессор (главный) функционирует в режиме ядра, и метод, основанный на использовании семафоров и допускающий одновременное исполнение в режиме ядра всех имеющихся в системе процессов. Оба метода инвариантны к количеству процессоров, однако говорить о том, что с ростом числа процессоров общая производительность системы увеличивается с линейной скоростью, нельзя. Потери производительности возникают, во-первых, как следствие конкуренции за ресурсы памяти, которая выражается в увеличении продолжительности обращения к памяти. Во-вторых, в схеме, основанной на использовании семафоров, к этой конкуренции добавляется соперничество за семафоры; процессы зачастую обнаруживают семафоры захваченными, больше процессов находится в очереди, долгое время ожидая получения доступа к семафорам. Первая схема, основанная на использовании главного и подчиненного процессоров, тоже не лишена недостатков: по мере увеличения числа процессоров главный процессор становится узким местом в системе, поскольку только он один может функционировать в режиме ядра. Несмотря на то, что более внимательное техническое проектирование позволяет сократить конкуренцию до разумного минимума и в некоторых случаях приблизить скорость повышения производительности системы при увеличении числа процессоров к линейной (см., например, [Beck 85]), все построенные с использованием современной технологии многопроцессорные системы имеют предел, за которым расширение состава процессоров не сопровождается увеличением производительности системы.
12.6 УПРАЖНЕНИЯ
1. Решите проблему функционирования многопроцессорных систем таким образом, чтобы все процессоры в системе могли функционировать в режиме ядра, но не более одного одновременно. Такое решение будет отличаться от первой из предложенных в тексте схем, где только один процессор (главный) предназначен для реализации функций ядра. Как добиться того, чтобы в режиме ядра в каждый момент времени находился только один процессор? Какую стратегию обработки прерываний при этом можно считать приемлемой?
2. Используя системные функции работы с разделяемой областью памяти, протестируйте программу, реализующую семафорную блокировку (Рисунок 12.6). Последовательности операций P-V над семафором могут независимо один от другого выполнять несколько процессов. Каким образом в программе следует реализовать индикацию и обработку ошибок?
3. Разработайте алгоритм выполнения операции CP (условный тип операции P), используя текст алгоритма операции P.
4. Объясните, зачем в алгоритмах операций P и V (Рисунки 12.8 и 12.9) нужна блокировка прерываний. В какие моменты ее следует осуществлять?
5. Почему при выполнении "циклической блокировки" вместо строки:
while (! CP(семафор));
ядро не может использовать операцию P безусловного типа? (В качестве наводящего вопроса: что произойдет в том случае, если процесс запустит операцию P и приостановится?)
6. Обратимся к алгоритму getblk, приведенному в главе 3. Опишите реализацию алгоритма в многопроцессорной системе для случая, когда блок отсутствует в буферном кеше.
*7. Предположим, что при выполнении алгоритма выделения буфера возникла чрезвычайно сильная конкуренция за семафор, принадлежащий списку свободных буферов. Разработайте схему ослабления конкуренции за счет разбиения списка свободных буферов на два подсписка.
*8. Предположим, что у терминального драйвера имеется семафор, значение которого при инициализации сбрасывается в 0 и по которому процессы приостанавливают свою работу в случае переполнения буфера вывода на терминал. Когда терминал готов к приему следующей порции данных, он выводит из состояния ожидания все процессы, приостановленные по семафору. Разработайте схему возобновления процессов, использующую операции типа P и V. В случае необходимости введите дополнительные флаги и семафоры. Как должна вести себя схема в том случае, если процессы выводятся из состояния ожидания по прерыванию, но при этом текущий процессор не имеет возможности блокировать прерывания на других процессорах?
*9. Если точки входа в драйвер защищаются семафорами, должно соблюдаться условие освобождения семафора в случае перехода процесса в состояние приостанова. Как это реализуется на практике? Каким образом должна производиться обработка прерываний, поступающих в то время, пока семафор драйвера заблокирован?
10. Обратимся к системным функциям установки и контроля системного времени (глава 8). Разные процессоры могут иметь различную тактовую частоту. Как в этом случае указанные функции должны работать?
2. Используя системные функции работы с разделяемой областью памяти, протестируйте программу, реализующую семафорную блокировку (Рисунок 12.6). Последовательности операций P-V над семафором могут независимо один от другого выполнять несколько процессов. Каким образом в программе следует реализовать индикацию и обработку ошибок?
3. Разработайте алгоритм выполнения операции CP (условный тип операции P), используя текст алгоритма операции P.
4. Объясните, зачем в алгоритмах операций P и V (Рисунки 12.8 и 12.9) нужна блокировка прерываний. В какие моменты ее следует осуществлять?
5. Почему при выполнении "циклической блокировки" вместо строки:
while (! CP(семафор));
ядро не может использовать операцию P безусловного типа? (В качестве наводящего вопроса: что произойдет в том случае, если процесс запустит операцию P и приостановится?)
6. Обратимся к алгоритму getblk, приведенному в главе 3. Опишите реализацию алгоритма в многопроцессорной системе для случая, когда блок отсутствует в буферном кеше.
*7. Предположим, что при выполнении алгоритма выделения буфера возникла чрезвычайно сильная конкуренция за семафор, принадлежащий списку свободных буферов. Разработайте схему ослабления конкуренции за счет разбиения списка свободных буферов на два подсписка.
*8. Предположим, что у терминального драйвера имеется семафор, значение которого при инициализации сбрасывается в 0 и по которому процессы приостанавливают свою работу в случае переполнения буфера вывода на терминал. Когда терминал готов к приему следующей порции данных, он выводит из состояния ожидания все процессы, приостановленные по семафору. Разработайте схему возобновления процессов, использующую операции типа P и V. В случае необходимости введите дополнительные флаги и семафоры. Как должна вести себя схема в том случае, если процессы выводятся из состояния ожидания по прерыванию, но при этом текущий процессор не имеет возможности блокировать прерывания на других процессорах?
*9. Если точки входа в драйвер защищаются семафорами, должно соблюдаться условие освобождения семафора в случае перехода процесса в состояние приостанова. Как это реализуется на практике? Каким образом должна производиться обработка прерываний, поступающих в то время, пока семафор драйвера заблокирован?
10. Обратимся к системным функциям установки и контроля системного времени (глава 8). Разные процессоры могут иметь различную тактовую частоту. Как в этом случае указанные функции должны работать?
ГЛАВА 13. РАСПРЕДЕЛЕННЫЕ СИСТЕМЫ
В предыдущей главе нами были рассмотрены сильносвязанные многопроцессорные системы с общей памятью, общими структурами данных ядра и общим пулом, из которого процессы вызываются на выполнение. Часто, однако, бывает желательно в целях обеспечения совместного использования ресурсов распределять процессоры таким образом, чтобы они были автономны от операционной среды и условий эксплуатации. Пусть, например, пользователю персональной ЭВМ нужно обратиться к файлам, находящимся на более крупной машине, но сохранить при этом контроль над персональной ЭВМ. Несмотря на то, что отдельные программы, такие как uucp, поддерживают передачу файлов по сети и другие сетевые функции, их использование не будет скрыто от пользователя, поскольку пользователь знает о том, что он работает в сети. Кроме того, надо заметить, что программы, подобные текстовым редакторам, с удаленными файлами, как с обычными, не работают. Пользователи должны располагать стандартным набором функций системы UNIX и, за исключением возможной потери в быстродействии, не должны ощущать пересечения машинных границ. Так, например, работа системных функций open и read с файлами на удаленных машинах не должна отличаться от их работы с файлами, принадлежащими локальным системам.
Архитектура распределенной системы представлена на Рисунке 13.1. Каждый компьютер, показанный на рисунке, является автономным модулем, состоящим из ЦП, памяти и периферийных устройств. Соответствие модели не нарушается даже несмотря на то, что компьютер не располагает локальной файловой системой: он должен иметь периферийные устройства для связи с другими машинами, а все принадлежащие ему файлы могут располагаться и на ином компьютере. Физическая память, доступная каждой машине, не зависит от процессов, выполняемых на других машинах. Этой особенностью распределенные системы отличаются от сильносвязанных многопроцессорных систем, рассмотренных в предыдущей главе. Соответственно, и ядро системы на каждой машине функционирует независимо от внешних условий эксплуатации распределенной среды.
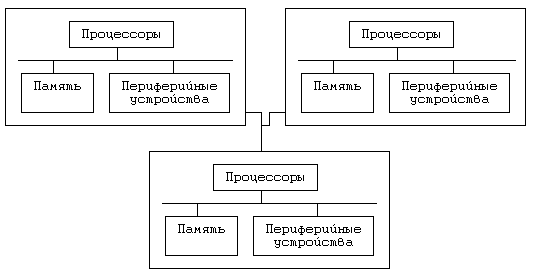 Рисунок 13.1. Модель системы с распределенной архитектурой
Рисунок 13.1. Модель системы с распределенной архитектурой
Распределенные системы, хорошо описанные в литературе, традиционно делятся на следующие категории:
• периферийные системы, представляющие собой группы машин, отличающихся ярковыраженной общностью и связанных с одной (обычно более крупной) машиной. Периферийные процессоры делят свою нагрузку с центральным процессором и переадресовывают ему все обращения к операционной системе. Цель периферийной системы состоит в увеличении общей производительности сети и в предоставлении возможности выделения процессора одному процессу в операционной среде UNIX. Система запускается как отдельный модуль; в отличие от других моделей распределенных систем, периферийные системы не обладают реальной автономией, за исключением случаев, связанных с диспетчеризацией процессов и распределением локальной памяти.
• распределенные системы типа "Newcastle", позволяющие осуществлять дистанционную связь по именам удаленных файлов в библиотеке (название взято из статьи "The Newcastle Connection" — см. [Brownbridge 82]). Удаленные файлы имеют спецификацию (составное имя), которая в указании пути поиска содержит специальные символы или дополнительную компоненту имени, предшествующую корню файловой системы. Реализация этого метода не предполагает внесения изменений в ядро системы, вследствие этого он более прост, чем другие методы, рассматриваемые в этой главе, но менее гибок.
• абсолютно "прозрачные" распределенные системы, в которых для обращения к файлам, расположенным на других машинах, достаточно указания их стандартных составных имен; распознавание этих файлов как удаленных входит в обязанности ядра. Маршруты поиска файлов, указанные в их составных именах, пересекают машинные границы в точках монтирования, сколько бы таких точек ни было сформировано при монтировании файловых систем на дисках.
В настоящей главе мы рассмотрим архитектуру каждой модели; все приводимые сведения базируются не на результатах конкретных разработок, а на информации, публиковавшейся в различных технических статьях. При этом предполагается, что забота об адресации, маршрутизации, управлении потоками, обнаружении и исправлении ошибок возлагается на модули протоколов и драйверы устройств, другими словами, что каждая модель не зависит от используемой сети. Примеры использования системных функций, приводимые в следующем разделе для периферийных систем, работают аналогичным образом и для систем типа Newcastle и для абсолютно "прозрачных" систем, о которых пойдет речь позже; поэтому в деталях мы их рассмотрим один раз, а в разделах, посвященных другим типам систем, остановимся в основном на особенностях, отличающих эти модели от всех остальных.
Архитектура распределенной системы представлена на Рисунке 13.1. Каждый компьютер, показанный на рисунке, является автономным модулем, состоящим из ЦП, памяти и периферийных устройств. Соответствие модели не нарушается даже несмотря на то, что компьютер не располагает локальной файловой системой: он должен иметь периферийные устройства для связи с другими машинами, а все принадлежащие ему файлы могут располагаться и на ином компьютере. Физическая память, доступная каждой машине, не зависит от процессов, выполняемых на других машинах. Этой особенностью распределенные системы отличаются от сильносвязанных многопроцессорных систем, рассмотренных в предыдущей главе. Соответственно, и ядро системы на каждой машине функционирует независимо от внешних условий эксплуатации распределенной среды.
Распределенные системы, хорошо описанные в литературе, традиционно делятся на следующие категории:
• периферийные системы, представляющие собой группы машин, отличающихся ярковыраженной общностью и связанных с одной (обычно более крупной) машиной. Периферийные процессоры делят свою нагрузку с центральным процессором и переадресовывают ему все обращения к операционной системе. Цель периферийной системы состоит в увеличении общей производительности сети и в предоставлении возможности выделения процессора одному процессу в операционной среде UNIX. Система запускается как отдельный модуль; в отличие от других моделей распределенных систем, периферийные системы не обладают реальной автономией, за исключением случаев, связанных с диспетчеризацией процессов и распределением локальной памяти.
• распределенные системы типа "Newcastle", позволяющие осуществлять дистанционную связь по именам удаленных файлов в библиотеке (название взято из статьи "The Newcastle Connection" — см. [Brownbridge 82]). Удаленные файлы имеют спецификацию (составное имя), которая в указании пути поиска содержит специальные символы или дополнительную компоненту имени, предшествующую корню файловой системы. Реализация этого метода не предполагает внесения изменений в ядро системы, вследствие этого он более прост, чем другие методы, рассматриваемые в этой главе, но менее гибок.
• абсолютно "прозрачные" распределенные системы, в которых для обращения к файлам, расположенным на других машинах, достаточно указания их стандартных составных имен; распознавание этих файлов как удаленных входит в обязанности ядра. Маршруты поиска файлов, указанные в их составных именах, пересекают машинные границы в точках монтирования, сколько бы таких точек ни было сформировано при монтировании файловых систем на дисках.
В настоящей главе мы рассмотрим архитектуру каждой модели; все приводимые сведения базируются не на результатах конкретных разработок, а на информации, публиковавшейся в различных технических статьях. При этом предполагается, что забота об адресации, маршрутизации, управлении потоками, обнаружении и исправлении ошибок возлагается на модули протоколов и драйверы устройств, другими словами, что каждая модель не зависит от используемой сети. Примеры использования системных функций, приводимые в следующем разделе для периферийных систем, работают аналогичным образом и для систем типа Newcastle и для абсолютно "прозрачных" систем, о которых пойдет речь позже; поэтому в деталях мы их рассмотрим один раз, а в разделах, посвященных другим типам систем, остановимся в основном на особенностях, отличающих эти модели от всех остальных.
13.1 ПЕРИФЕРИЙНЫЕ ПРОЦЕССОРЫ
Архитектура периферийной системы показана на Рисунке 13.2. Цель такой конфигурации состоит в повышении общей производительности сети за счет перераспределения выполняемых процессов между центральным и периферийными процессорами. У каждого из периферийных процессоров нет в распоряжении других локальных периферийных устройств, кроме тех, которые ему нужны для связи с центральным процессором. Файловая система и все устройства находятся в распоряжении центрального процессора. Предположим, что все пользовательские процессы исполняются на периферийном процессоре и между периферийными процессорами не перемещаются; будучи однажды переданы процессору, они пребывают на нем до момента завершения. Периферийный процессор содержит облегченный вариант операционной системы, предназначенный для обработки локальных обращений к системе, управления прерываниями, распределения памяти, работы с сетевыми протоколами и с драйвером устройства связи с центральным процессором.
При инициализации системы на центральном процессоре ядро по линиям связи загружает на каждом из периферийных процессоров локальную операционную систему. Любой выполняемый на периферии процесс связан с процессом-спутником, принадлежащим центральному процессору (см. [Birrell 84]); когда процесс, протекающий на периферийном процессоре, вызывает системную функцию, которая нуждается в услугах исключительно центрального процессора, периферийный процесс связывается со своим спутником и запрос поступает на обработку на центральный процессор. Процесс-спутник исполняет системную функцию и посылает результаты обратно на периферийный процессор. Взаимоотношения периферийного процесса со своим спутником похожи на отношения клиента и сервера, подробно рассмотренные нами в главе 11: периферийный процесс выступает клиентом своего спутника, поддерживающего функции работы с файловой системой. При этом удаленный процесс-сервер имеет только одного клиента. В разделе 13.4 мы рассмотрим процессы-серверы, имеющие несколько клиентов.
 Рисунок 13.2. Конфигурация периферийной системы
Рисунок 13.2. Конфигурация периферийной системы
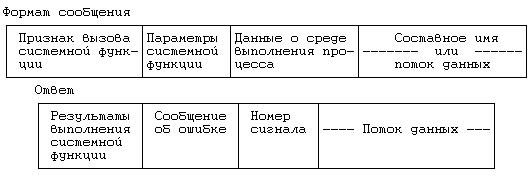 Рисунок 13.3. Форматы сообщений
Рисунок 13.3. Форматы сообщений
Когда периферийный процесс вызывает системную функцию, которую можно обработать локально, ядру нет надобности посылать запрос процессу-спутнику. Так, например, в целях получения дополнительной памяти процесс может вызвать для локального исполнения функцию sbrk. Однако, если требуются услуги центрального процессора, например, чтобы открыть файл, ядро кодирует информацию о передаваемых вызванной функции параметрах и условиях выполнения процесса в некое сообщение, посылаемое процессу-спутнику (Рисунок 13.3). Сообщение включает в себя признак, из которого следует, что системная функция выполняется процессом-спутником от имени клиента, передаваемые функции параметры и данные о среде выполнения процесса (например, пользовательский и групповой коды идентификации), которые для разных функций различны. Оставшаяся часть сообщения представляет собой данные переменной длины (например, составное имя файла или данные, предназначенные для записи функцией write).
Процесс-спутник ждет поступления запросов от периферийного процесса; при получении запроса он декодирует сообщение, определяет тип системной функции, исполняет ее и преобразует результаты в ответ, посылаемый периферийному процессу. Ответ, помимо результатов выполнения системной функции, включает в себя сообщение об ошибке (если она имела место), номер сигнала и массив данных переменной длины, содержащий, например, информацию, прочитанную из файла. Периферийный процесс приостанавливается до получения ответа, получив его, производит расшифровку и передает результаты пользователю. Такова общая схема обработки обращений к операционной системе; теперь перейдем к более детальному рассмотрению отдельных функций.
Для того, чтобы объяснить, каким образом работает периферийная система, рассмотрим ряд функций: getppid, open, write, fork, exit и signal. Функция getppid довольно проста, поскольку она связана с простыми формами запроса и ответа, которыми обмениваются периферийный и центральный процессоры. Ядро на периферийном процессоре формирует сообщение, имеющее признак, из которого следует, что запрашиваемой функцией является функция getppid, и посылает запрос центральному процессору. Процесс-спутник на центральном процессоре читает сообщение с периферийного процессора, расшифровывает тип системной функции, исполняет ее и получает идентификатор своего родителя. Затем он формирует ответ и передает его периферийному процессу, находящемуся в состоянии ожидания на другом конце линии связи. Когда периферийный процессор получает ответ, он передает его процессу, вызвавшему системную функцию getppid. Если же периферийный процесс хранит данные (такие, как идентификатор процесса-родителя) в локальной памяти, ему вообще не придется связываться со своим спутником.
При инициализации системы на центральном процессоре ядро по линиям связи загружает на каждом из периферийных процессоров локальную операционную систему. Любой выполняемый на периферии процесс связан с процессом-спутником, принадлежащим центральному процессору (см. [Birrell 84]); когда процесс, протекающий на периферийном процессоре, вызывает системную функцию, которая нуждается в услугах исключительно центрального процессора, периферийный процесс связывается со своим спутником и запрос поступает на обработку на центральный процессор. Процесс-спутник исполняет системную функцию и посылает результаты обратно на периферийный процессор. Взаимоотношения периферийного процесса со своим спутником похожи на отношения клиента и сервера, подробно рассмотренные нами в главе 11: периферийный процесс выступает клиентом своего спутника, поддерживающего функции работы с файловой системой. При этом удаленный процесс-сервер имеет только одного клиента. В разделе 13.4 мы рассмотрим процессы-серверы, имеющие несколько клиентов.
Когда периферийный процесс вызывает системную функцию, которую можно обработать локально, ядру нет надобности посылать запрос процессу-спутнику. Так, например, в целях получения дополнительной памяти процесс может вызвать для локального исполнения функцию sbrk. Однако, если требуются услуги центрального процессора, например, чтобы открыть файл, ядро кодирует информацию о передаваемых вызванной функции параметрах и условиях выполнения процесса в некое сообщение, посылаемое процессу-спутнику (Рисунок 13.3). Сообщение включает в себя признак, из которого следует, что системная функция выполняется процессом-спутником от имени клиента, передаваемые функции параметры и данные о среде выполнения процесса (например, пользовательский и групповой коды идентификации), которые для разных функций различны. Оставшаяся часть сообщения представляет собой данные переменной длины (например, составное имя файла или данные, предназначенные для записи функцией write).
Процесс-спутник ждет поступления запросов от периферийного процесса; при получении запроса он декодирует сообщение, определяет тип системной функции, исполняет ее и преобразует результаты в ответ, посылаемый периферийному процессу. Ответ, помимо результатов выполнения системной функции, включает в себя сообщение об ошибке (если она имела место), номер сигнала и массив данных переменной длины, содержащий, например, информацию, прочитанную из файла. Периферийный процесс приостанавливается до получения ответа, получив его, производит расшифровку и передает результаты пользователю. Такова общая схема обработки обращений к операционной системе; теперь перейдем к более детальному рассмотрению отдельных функций.
Для того, чтобы объяснить, каким образом работает периферийная система, рассмотрим ряд функций: getppid, open, write, fork, exit и signal. Функция getppid довольно проста, поскольку она связана с простыми формами запроса и ответа, которыми обмениваются периферийный и центральный процессоры. Ядро на периферийном процессоре формирует сообщение, имеющее признак, из которого следует, что запрашиваемой функцией является функция getppid, и посылает запрос центральному процессору. Процесс-спутник на центральном процессоре читает сообщение с периферийного процессора, расшифровывает тип системной функции, исполняет ее и получает идентификатор своего родителя. Затем он формирует ответ и передает его периферийному процессу, находящемуся в состоянии ожидания на другом конце линии связи. Когда периферийный процессор получает ответ, он передает его процессу, вызвавшему системную функцию getppid. Если же периферийный процесс хранит данные (такие, как идентификатор процесса-родителя) в локальной памяти, ему вообще не придется связываться со своим спутником.