Страница:
Примером setuid-программы является программа, реализующая команду mkdir. В разделе 5.8 уже говорилось о том, что создать каталог может только процесс, выполняющийся под управлением суперпользователя. Для того, чтобы предоставить возможность создания каталогов простым пользователям, команда mkdir была выполнена в виде setuid-программы, принадлежащей корню системы и имеющей права суперпользователя. На время исполнения команды mkdir процесс получает права суперпользователя, создает каталог, используя функцию mknod, и предоставляет права собственности и доступа к каталогу истинному пользователю процесса.
7.7 ИЗМЕНЕНИЕ РАЗМЕРА ПРОЦЕССА
7.8 КОМАНДНЫЙ ПРОЦЕССОР SHELL
7.9 ЗАГРУЗКА СИСТЕМЫ И НАЧАЛЬНЫЙ ПРОЦЕСС
7.10 ВЫВОДЫ
7.11 УПРАЖНЕНИЯ
7.7 ИЗМЕНЕНИЕ РАЗМЕРА ПРОЦЕССА
С помощью системной функции brk процесс может увеличивать и уменьшать размер области данных. Синтаксис вызова функции:
brk(endds);
где endds — старший виртуальный адрес области данных процесса (адрес верхней границы). С другой стороны, пользователь может обратиться к функции следующим образом:
oldendds = sbrk(increment);
где oldendds — текущий адрес верхней границы области, increment — число байт, на которое изменяется значение oldendds в результате выполнения функции. Sbrk — это имя стандартной библиотечной подпрограммы на Си, вызывающей функцию brk. Если размер области данных процесса в результате выполнения функции увеличивается, вновь выделяемое пространство имеет виртуальные адреса, смежные с адресами увеличиваемой области; таким образом, виртуальное адресное пространство процесса расширяется. При этом ядро проверяет, не превышает ли новый размер процесса максимально-допустимое значение, принятое для него в системе, а также не накладывается ли новая область данных процесса на виртуальное адресное пространство, отведенное ранее для других целей (Рисунок 7.26). Если все в порядке, ядро запускает алгоритм growreg, присоединяя к области данных внешнюю память (например, таблицы страниц) и увеличивая значение поля, описывающего размер процесса. В системе с замещением страниц ядро также отводит под новую область пространство основной памяти и обнуляет его содержимое; если свободной памяти нет, ядро освобождает память путем выгрузки процесса (более подробно об этом мы поговорим в главе 9). Если с помощью функции brk процесс уменьшает размер области данных, ядро освобождает часть ранее выделенного адресного пространства; когда процесс попытается обратиться к данным по виртуальным адресам, принадлежащим освобожденному пространству, он столкнется с ошибкой адресации.
алгоритм brk
входная информация: новый адрес верхней границы области данных
выходная информация: старый адрес верхней границы области данных
{
заблокировать область данных процесса;
if (размер области увеличивается)
if (новый размер области имеет недопустимое значение) {
снять блокировку с области;
return (ошибку);
}
изменить размер области (алгоритм growreg);
обнулить содержимое присоединяемого пространства;
снять блокировку с области данных;
}
Рисунок 7.26. Алгоритм выполнения функции brk
На Рисунке 7.27 приведен пример программы, использующей функцию brk, и выходные данные, полученные в результате ее прогона на машине AT&T 3B20. Вызвав функцию signal и распорядившись принимать сигналы о нарушении сегментации (segmentation violation), процесс обращается к подпрограмме sbrk и выводит на печать первоначальное значение адреса верхней границы области данных. Затем в цикле, используя счетчик символов, процесс заполняет область данных до тех пор, пока не обратится к адресу, расположенному за пределами области, тем самым давая повод для сигнала о нарушении сегментации. Получив сигнал, функция обработки сигнала вызывает подпрограмму sbrk для того, чтобы присоединить к области дополнительно 256 байт памяти; процесс продолжается с точки прерывания, заполняя информацией вновь выделенное пространство памяти и т. д. На машинах со страничной организацией памяти, таких как 3B20, наблюдается интересный феномен. Страница является наименьшей единицей памяти, с которой работают механизмы аппаратной защиты, поэтому аппаратные средства не в состоянии установить ошибку в граничной ситуации, когда процесс пытается записать информацию по адресам, превышающим верхнюю границу области данных, но принадлежащим т. н. „полулегальной“ странице (странице, не полностью занятой областью данных процесса). Это видно из результатов выполнения программы, выведенных на печать (Рисунок 7.27): первый раз подпрограмма sbrk возвращает значение 140924, то есть адрес, не дотягивающий 388 байт до конца страницы, которая на машине 3B20 имеет размер 2 Кбайта. Однако процесс получит ошибку только в том случае, если обратится к следующей странице памяти, то есть к любому адресу, начиная с 141312. Функция обработки сигнала прибавляет к адресу верхней границы области 256, делая его равным 141180 и, таким образом, оставляя его в пределах текущей страницы. Следовательно, процесс тут же снова получит ошибку, выдав на печать адрес 141312. Исполнив подпрограмму sbrk еще раз, ядро выделяет под данные процесса новую страницу памяти, так что процесс получает возможность адресовать дополнительно 2 Кбайта памяти, до адреса 143360, даже если верхняя граница области располагается ниже. Получив ошибку, процесс должен будет восемь раз обратиться к подпрограмме sbrk, прежде чем сможет продолжить выполнение основной программы. Таким образом, процесс может иногда выходить за официальную верхнюю границу области данных, хотя это и нежелательный момент в практике программирования.
Когда стек задачи переполняется, ядро автоматически увеличивает его размер, выполняя алгоритм, похожий на алгоритм функции brk. Первоначально стек задачи имеет размер, достаточный для хранения параметров функции exec, однако при выполнении процесса этот стек может переполниться. Переполнение стека приводит к ошибке адресации, свидетельствующей о попытке процесса обратиться к ячейке памяти за пределами отведенного адресного пространства. Ядро устанавливает причину возникновения ошибки, сравнивая текущее значение указателя вершины стека с размером области стека. При расширении области стека ядро использует точно такой же механизм, что и для области данных. На выходе из прерывания процесс имеет область стека необходимого для продолжения работы размера.
#include ‹signal.h›
char *cp;
int callno;
main() {
char *sbrk();
extern catcher();
signal(SIGSEGV, catcher);
cp = sbrk(0);
printf("original brk value %u\n", cp);
for (;;) *cp++ = 1;
}
catcher(signo)
int signo;
{
callno++;
printf("caught sig %d %dth call at addr %u\n", signo, callno, cp);
sbrk(256);
signal(SIGSEGV, catcher);
}
original brk value 140924
caught sig 11 1th call at addr 141312
caught sig 11 2th call at addr 141312
caught sig 11 3th call at addr 143360
…(тот же адрес печатается до 10-го вызова подпрограммы sbrk)
caught sig 11 10th call at addr 143360
caught sig 11 11th call at addr 145408
…(тот же адрес печатается до 18-го вызова подпрограммы sbrk)
caught sig 11 18th call at addr 145408
caught sig 11 19th call at addr 145408
-
-
Рисунок 7.27. Пример программы, использующей функцию brk, и результаты ее контрольного прогона
brk(endds);
где endds — старший виртуальный адрес области данных процесса (адрес верхней границы). С другой стороны, пользователь может обратиться к функции следующим образом:
oldendds = sbrk(increment);
где oldendds — текущий адрес верхней границы области, increment — число байт, на которое изменяется значение oldendds в результате выполнения функции. Sbrk — это имя стандартной библиотечной подпрограммы на Си, вызывающей функцию brk. Если размер области данных процесса в результате выполнения функции увеличивается, вновь выделяемое пространство имеет виртуальные адреса, смежные с адресами увеличиваемой области; таким образом, виртуальное адресное пространство процесса расширяется. При этом ядро проверяет, не превышает ли новый размер процесса максимально-допустимое значение, принятое для него в системе, а также не накладывается ли новая область данных процесса на виртуальное адресное пространство, отведенное ранее для других целей (Рисунок 7.26). Если все в порядке, ядро запускает алгоритм growreg, присоединяя к области данных внешнюю память (например, таблицы страниц) и увеличивая значение поля, описывающего размер процесса. В системе с замещением страниц ядро также отводит под новую область пространство основной памяти и обнуляет его содержимое; если свободной памяти нет, ядро освобождает память путем выгрузки процесса (более подробно об этом мы поговорим в главе 9). Если с помощью функции brk процесс уменьшает размер области данных, ядро освобождает часть ранее выделенного адресного пространства; когда процесс попытается обратиться к данным по виртуальным адресам, принадлежащим освобожденному пространству, он столкнется с ошибкой адресации.
алгоритм brk
входная информация: новый адрес верхней границы области данных
выходная информация: старый адрес верхней границы области данных
{
заблокировать область данных процесса;
if (размер области увеличивается)
if (новый размер области имеет недопустимое значение) {
снять блокировку с области;
return (ошибку);
}
изменить размер области (алгоритм growreg);
обнулить содержимое присоединяемого пространства;
снять блокировку с области данных;
}
Рисунок 7.26. Алгоритм выполнения функции brk
На Рисунке 7.27 приведен пример программы, использующей функцию brk, и выходные данные, полученные в результате ее прогона на машине AT&T 3B20. Вызвав функцию signal и распорядившись принимать сигналы о нарушении сегментации (segmentation violation), процесс обращается к подпрограмме sbrk и выводит на печать первоначальное значение адреса верхней границы области данных. Затем в цикле, используя счетчик символов, процесс заполняет область данных до тех пор, пока не обратится к адресу, расположенному за пределами области, тем самым давая повод для сигнала о нарушении сегментации. Получив сигнал, функция обработки сигнала вызывает подпрограмму sbrk для того, чтобы присоединить к области дополнительно 256 байт памяти; процесс продолжается с точки прерывания, заполняя информацией вновь выделенное пространство памяти и т. д. На машинах со страничной организацией памяти, таких как 3B20, наблюдается интересный феномен. Страница является наименьшей единицей памяти, с которой работают механизмы аппаратной защиты, поэтому аппаратные средства не в состоянии установить ошибку в граничной ситуации, когда процесс пытается записать информацию по адресам, превышающим верхнюю границу области данных, но принадлежащим т. н. „полулегальной“ странице (странице, не полностью занятой областью данных процесса). Это видно из результатов выполнения программы, выведенных на печать (Рисунок 7.27): первый раз подпрограмма sbrk возвращает значение 140924, то есть адрес, не дотягивающий 388 байт до конца страницы, которая на машине 3B20 имеет размер 2 Кбайта. Однако процесс получит ошибку только в том случае, если обратится к следующей странице памяти, то есть к любому адресу, начиная с 141312. Функция обработки сигнала прибавляет к адресу верхней границы области 256, делая его равным 141180 и, таким образом, оставляя его в пределах текущей страницы. Следовательно, процесс тут же снова получит ошибку, выдав на печать адрес 141312. Исполнив подпрограмму sbrk еще раз, ядро выделяет под данные процесса новую страницу памяти, так что процесс получает возможность адресовать дополнительно 2 Кбайта памяти, до адреса 143360, даже если верхняя граница области располагается ниже. Получив ошибку, процесс должен будет восемь раз обратиться к подпрограмме sbrk, прежде чем сможет продолжить выполнение основной программы. Таким образом, процесс может иногда выходить за официальную верхнюю границу области данных, хотя это и нежелательный момент в практике программирования.
Когда стек задачи переполняется, ядро автоматически увеличивает его размер, выполняя алгоритм, похожий на алгоритм функции brk. Первоначально стек задачи имеет размер, достаточный для хранения параметров функции exec, однако при выполнении процесса этот стек может переполниться. Переполнение стека приводит к ошибке адресации, свидетельствующей о попытке процесса обратиться к ячейке памяти за пределами отведенного адресного пространства. Ядро устанавливает причину возникновения ошибки, сравнивая текущее значение указателя вершины стека с размером области стека. При расширении области стека ядро использует точно такой же механизм, что и для области данных. На выходе из прерывания процесс имеет область стека необходимого для продолжения работы размера.
#include ‹signal.h›
char *cp;
int callno;
main() {
char *sbrk();
extern catcher();
signal(SIGSEGV, catcher);
cp = sbrk(0);
printf("original brk value %u\n", cp);
for (;;) *cp++ = 1;
}
catcher(signo)
int signo;
{
callno++;
printf("caught sig %d %dth call at addr %u\n", signo, callno, cp);
sbrk(256);
signal(SIGSEGV, catcher);
}
original brk value 140924
caught sig 11 1th call at addr 141312
caught sig 11 2th call at addr 141312
caught sig 11 3th call at addr 143360
…(тот же адрес печатается до 10-го вызова подпрограммы sbrk)
caught sig 11 10th call at addr 143360
caught sig 11 11th call at addr 145408
…(тот же адрес печатается до 18-го вызова подпрограммы sbrk)
caught sig 11 18th call at addr 145408
caught sig 11 19th call at addr 145408
-
-
Рисунок 7.27. Пример программы, использующей функцию brk, и результаты ее контрольного прогона
7.8 КОМАНДНЫЙ ПРОЦЕССОР SHELL
Теперь у нас есть достаточно материала, чтобы перейти к объяснению принципов работы командного процессора shell. Сам командный процессор намного сложнее, чем то, что мы о нем здесь будем излагать, однако взаимодействие процессов мы уже можем рассмотреть на примере реальной программы. На Рисунке 7.28 приведен фрагмент основного цикла программы shell, демонстрирующий асинхронное выполнение процессов, переназначение вывода и использование каналов.
/* чтение командной строки до символа конца файла */
while (read(stdin, buffer, numchars)) {
/* синтаксический разбор командной строки */
if (/* командная строка содержит & */) amper = 1;
else amper = 0;
/* для команд, не являющихся конструкциями командного языка shell */
if (fork() == 0) {
/* переадресация ввода-вывода? */
if (/* переадресация вывода */) {
fd = creat(newfile, fmask);
close(stdout);
dup(fd);
close(fd); /* stdout теперь переадресован */
}
if (/* используются каналы */) {
pipe(fildes);
if (fork() == 0) {
/* первая компонента командной строки */
close(stdout);
dup(fildes[1]);
close(fildes[1]);
close(fildes[0]); /* стандартный вывод направляется в канал */
/* команду исполняет порожденный процесс */
execlp(command1, command1, 0);
}
/* вторая компонента командной строки */
close(stdin);
dup(fildes[0]) ;
close(fildes[0]);
close(fildes[1]); /* стандартный ввод будет производиться из канала */
}
execve(command2, command2, 0);
}
/* с этого места продолжается выполнение родительского процесса… процесс-родитель ждет завершения выполнения потомка, если это вытекает из введенной строки * /
if (amper == 0) retid = wait(&status);
}
Рисунок 7.28. Основной цикл программы shell
Shell считывает командную строку из файла стандартного ввода и интерпретирует ее в соответствии с установленным набором правил. Дескрипторы файлов стандартного ввода и стандартного вывода, используемые регистрационным shell'ом, как правило, указывают на терминал, с которого пользователь регистрируется в системе (см. главу 10). Если shell узнает во введенной строке конструкцию собственного командного языка (например, одну из команд cd, for, while и т. п.), он исполняет команду своими силами, не прибегая к созданию новых процессов; в противном случае команда интерпретируется как имя исполняемого файла.
Командные строки простейшего вида содержат имя программы и несколько параметров, например:
who
grep -n include *.c
ls -l
Shell „ветвится“ (fork) и порождает новый процесс, который и запускает программу, указанную пользователем в командной строке. Родительский процесс (shell) дожидается завершения потомка и повторяет цикл считывания следующей команды.
Если процесс запускается асинхронно (на фоне основной программы), как в следующем примере
nroff -mm bigdocument&
shell анализирует наличие символа амперсанд (&) и заносит результат проверки во внутреннюю переменную amper. В конце основного цикла shell обращается к этой переменной и, если обнаруживает в ней признак наличия символа, не выполняет функцию wait, а тут же повторяет цикл считывания следующей команды.
Из рисунка видно, что процесс-потомок по завершении функции fork получает доступ к командной строке, принятой shell'ом. Для того, чтобы переадресовать стандартный вывод в файл, как в следующем примере
nroff -mm bigdocument › output
процесс-потомок создает файл вывода с указанным в командной строке именем; если файл не удается создать (например, не разрешен доступ к каталогу), процесс-потомок тут же завершается. В противном случае процесс-потомок закрывает старый файл стандартного вывода и переназначает с помощью функции dup дескриптор этого файла новому файлу. Старый дескриптор созданного файла закрывается и сохраняется для запускаемой программы. Подобным же образом shell переназначает и стандартный ввод и стандартный вывод ошибок.
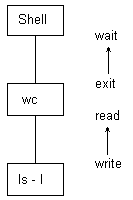
Рисунок 7.29. Взаимосвязь между процессами, исполняющими командную строку ls -l|wc
Из приведенного текста программы видно, как shell обрабатывает командную строку, используя один канал. Допустим, что командная строка имеет вид:
ls -l|wc
После создания родительским процессом нового процесса процесс-потомок создает канал. Затем процесс-потомок создает свое ответвление; он и его потомок обрабатывают по одной компоненте командной строки. „Внучатый“ процесс исполняет первую компоненту строки (ls): он собирается вести запись в канал, поэтому он закрывает старый файл стандартного вывода, передает его дескриптор каналу и закрывает старый дескриптор записи в канал, в котором (в дескрипторе) уже нет необходимости. Родитель (wc) „внучатого“ процесса (ls) является потомком основного процесса, реализующего программу shell'а (см.Рисунок 7.29). Этот процесс (wc) закрывает свой файл стандартного ввода и передает его дескриптор каналу, в результате чего канал становится файлом стандартного ввода. Затем закрывается старый и уже не нужный дескриптор чтения из канала и исполняется вторая компонента командной строки. Оба порожденных процесса выполняются асинхронно, причем выход одного процесса поступает на вход другого. Тем временем основной процесс дожидается завершения своего потомка (wc), после чего продолжает свою обычную работу: по завершении процесса, выполняющего команду wc, вся командная строка является обработанной. Shell возвращается в цикл и считывает следующую командную строку.
/* чтение командной строки до символа конца файла */
while (read(stdin, buffer, numchars)) {
/* синтаксический разбор командной строки */
if (/* командная строка содержит & */) amper = 1;
else amper = 0;
/* для команд, не являющихся конструкциями командного языка shell */
if (fork() == 0) {
/* переадресация ввода-вывода? */
if (/* переадресация вывода */) {
fd = creat(newfile, fmask);
close(stdout);
dup(fd);
close(fd); /* stdout теперь переадресован */
}
if (/* используются каналы */) {
pipe(fildes);
if (fork() == 0) {
/* первая компонента командной строки */
close(stdout);
dup(fildes[1]);
close(fildes[1]);
close(fildes[0]); /* стандартный вывод направляется в канал */
/* команду исполняет порожденный процесс */
execlp(command1, command1, 0);
}
/* вторая компонента командной строки */
close(stdin);
dup(fildes[0]) ;
close(fildes[0]);
close(fildes[1]); /* стандартный ввод будет производиться из канала */
}
execve(command2, command2, 0);
}
/* с этого места продолжается выполнение родительского процесса… процесс-родитель ждет завершения выполнения потомка, если это вытекает из введенной строки * /
if (amper == 0) retid = wait(&status);
}
Рисунок 7.28. Основной цикл программы shell
Shell считывает командную строку из файла стандартного ввода и интерпретирует ее в соответствии с установленным набором правил. Дескрипторы файлов стандартного ввода и стандартного вывода, используемые регистрационным shell'ом, как правило, указывают на терминал, с которого пользователь регистрируется в системе (см. главу 10). Если shell узнает во введенной строке конструкцию собственного командного языка (например, одну из команд cd, for, while и т. п.), он исполняет команду своими силами, не прибегая к созданию новых процессов; в противном случае команда интерпретируется как имя исполняемого файла.
Командные строки простейшего вида содержат имя программы и несколько параметров, например:
who
grep -n include *.c
ls -l
Shell „ветвится“ (fork) и порождает новый процесс, который и запускает программу, указанную пользователем в командной строке. Родительский процесс (shell) дожидается завершения потомка и повторяет цикл считывания следующей команды.
Если процесс запускается асинхронно (на фоне основной программы), как в следующем примере
nroff -mm bigdocument&
shell анализирует наличие символа амперсанд (&) и заносит результат проверки во внутреннюю переменную amper. В конце основного цикла shell обращается к этой переменной и, если обнаруживает в ней признак наличия символа, не выполняет функцию wait, а тут же повторяет цикл считывания следующей команды.
Из рисунка видно, что процесс-потомок по завершении функции fork получает доступ к командной строке, принятой shell'ом. Для того, чтобы переадресовать стандартный вывод в файл, как в следующем примере
nroff -mm bigdocument › output
процесс-потомок создает файл вывода с указанным в командной строке именем; если файл не удается создать (например, не разрешен доступ к каталогу), процесс-потомок тут же завершается. В противном случае процесс-потомок закрывает старый файл стандартного вывода и переназначает с помощью функции dup дескриптор этого файла новому файлу. Старый дескриптор созданного файла закрывается и сохраняется для запускаемой программы. Подобным же образом shell переназначает и стандартный ввод и стандартный вывод ошибок.
Рисунок 7.29. Взаимосвязь между процессами, исполняющими командную строку ls -l|wc
Из приведенного текста программы видно, как shell обрабатывает командную строку, используя один канал. Допустим, что командная строка имеет вид:
ls -l|wc
После создания родительским процессом нового процесса процесс-потомок создает канал. Затем процесс-потомок создает свое ответвление; он и его потомок обрабатывают по одной компоненте командной строки. „Внучатый“ процесс исполняет первую компоненту строки (ls): он собирается вести запись в канал, поэтому он закрывает старый файл стандартного вывода, передает его дескриптор каналу и закрывает старый дескриптор записи в канал, в котором (в дескрипторе) уже нет необходимости. Родитель (wc) „внучатого“ процесса (ls) является потомком основного процесса, реализующего программу shell'а (см.Рисунок 7.29). Этот процесс (wc) закрывает свой файл стандартного ввода и передает его дескриптор каналу, в результате чего канал становится файлом стандартного ввода. Затем закрывается старый и уже не нужный дескриптор чтения из канала и исполняется вторая компонента командной строки. Оба порожденных процесса выполняются асинхронно, причем выход одного процесса поступает на вход другого. Тем временем основной процесс дожидается завершения своего потомка (wc), после чего продолжает свою обычную работу: по завершении процесса, выполняющего команду wc, вся командная строка является обработанной. Shell возвращается в цикл и считывает следующую командную строку.
7.9 ЗАГРУЗКА СИСТЕМЫ И НАЧАЛЬНЫЙ ПРОЦЕСС
Для того, чтобы перевести систему из неактивное состояние в активное, администратор выполняет процедуру „начальной загрузки“. На разных машинах эта процедура имеет свои особенности, однако во всех случаях она реализует одну и ту же цель: загрузить копию операционной системы в основную память машины и запустить ее на исполнение. Обычно процедура начальной загрузки включает в себя несколько этапов. Переключением клавиш на пульте машины администратор может указать адрес специальной программы аппаратной загрузки, а может, нажав только одну клавишу, дать команду машине запустить процедуру загрузки, исполненную в виде микропрограммы. Эта программа может состоять из нескольких команд, подготавливающих запуск другой программы. В системе UNIX процедура начальной загрузки заканчивается считыванием с диска в память блока начальной загрузки (нулевого блока). Программа, содержащаяся в этом блоке, загружает из файловой системы ядро ОС (например, из файла с именем „/unix“ или с другим именем, указанным администратором). После загрузки ядра системы в память управление передается по стартовому адресу ядра и ядро запускается на выполнение (алгоритм start Рисунок 7.30).
Ядро инициализирует свои внутренние структуры данных. Среди прочих структур ядро создает связные списки свободных буферов и индексов, хеш-очереди для буферов и индексов, инициализирует структуры областей, точки входа в таблицы страниц и т. д. По окончании этой фазы ядро монтирует корневую файловую систему и формирует среду выполнения нулевого процесса, среди всего прочего создавая пространство процесса, инициализируя нулевую точку входа в таблице процесса и делая корневой каталог текущим для процесса.
Когда формирование среды выполнения процесса заканчивается, система исполняется уже в виде нулевого процесса. Нулевой процесс „ветвится“, запуская алгоритм fork прямо из ядра, поскольку сам процесс исполняется в режиме ядра. Порожденный нулевым новый процесс, процесс 1, запускается в том же режиме и создает свой пользовательский контекст, формируя область данных и присоединяя ее к своему адресному пространству. Он увеличивает размер области до надлежащей величины и переписывает программу загрузки из адресного пространства ядра в новую область: эта программа теперь будет определять контекст процесса 1. Затем процесс 1 сохраняет регистровый контекст задачи, „возвращается“ из режима ядра в режим задачи и исполняет только что переписанную программу. В отличие от нулевого процесса, который является процессом системного уровня, выполняющимся в режиме ядра, процесс 1 относится к пользовательскому уровню. Код, исполняемый процессом 1, включает в себя вызов системной функции exec, запускающей на выполнение программу из файла „/etc/init“. Обычно процесс 1 именуется процессом init, поскольку он отвечает за инициализацию новых процессов.
алгоритм start /* процедура начальной загрузки системы */
входная информация: отсутствует
выходная информация: отсутствует
{
проинициализировать все структуры данных ядра;
псевдо-монтирование корня;
сформировать среду выполнения процесса 0;
создать процесс 1;
{
/* процесс 1 */
выделить область;
подключить область к адресному пространству процесса init ;
увеличить размер области для копирования в нее исполняемого кода;
скопировать из пространства ядра в адресное пространство процесса код программы, исполняемой процессом;
изменить режим выполнения: вернуться из режима ядра в режим задачи;
/* процесс init далее выполняется самостоятельно — в результате выхода в режим задачи, init исполняет файл „/etc/init“ и становится „обычным“ пользовательским процессом, производящим обращения к системным функциям */
}
/* продолжение нулевого процесса */
породить процессы ядра;
/* нулевой процесс запускает программу подкачки, управляющую распределением адресного пространства процессов между основной памятью и устройствами выгрузки. Это бесконечный цикл; нулевой процесс обычно приостанавливает свою работу, если необходимости в нем больше нет. */
исполнить программу, реализующую алгоритм подкачки;
}
Рисунок 7.30. Алгоритм загрузки системы
Казалось бы, зачем ядру копировать программу, запускаемую с помощью функции exec, в адресное пространство процесса 1? Он мог бы обратиться к внутреннему варианту функции прямо из ядра, однако, по сравнению с уже описанным алгоритмом это было бы гораздо труднее реализовать, ибо в этом случае функции exec пришлось бы производить анализ имен файлов в пространстве ядра, а не в пространстве задачи. Подобная деталь, требующаяся только для процесса init, усложнила бы программу реализации функции exec и отрицательно отразилась бы на скорости выполнения функции в более общих случаях.
Процесс init (Рисунок 7.31) выступает диспетчером процессов, который порождает процессы, среди всего прочего позволяющие пользователю регистрироваться в системе. Инструкции о том, какие процессы нужно создать, считываются процессом init из файла „/etc/inittab“. Строки файла включают в себя идентификатор состояния „id“ (однопользовательский режим, многопользовательский и т. д.), предпринимаемое действие (см. упражнение 7.43) и спецификацию программы, реализующей это действие (см. Рисунок 7.32). Процесс init просматривает строки файла до тех пор, пока не обнаружит идентификатор состояния, соответствующего тому состоянию, в котором находится процесс, и создает процесс, исполняющий программу с указанной спецификацией. Например, при запуске в многопользовательском режиме (состояние 2) процесс init обычно порождает getty-процессы, управляющие функционированием терминальных линий, входящих в состав системы. Если регистрация пользователя прошла успешно, getty-процесс, пройдя через процедуру login, запускает на исполнение регистрационный shell (см. главу 10). Тем временем процесс init находится в состоянии ожидания (wait), наблюдая за прекращением существования своих потомков, а также „внучатых“ процессов, оставшихся „сиротами“ после гибели своих родителей.
Процессы в системе UNIX могут быть либо пользовательскими, либо управляющими, либо системными. Большинство из них составляют пользовательские процессы, связанные с пользователями через терминалы. Управляющие процессы не связаны с конкретными пользователями, они выполняют широкий спектр системных функций, таких как администрирование и управление сетями, различные периодические операции, буферизация данных для вывода на устройство построчной печати и т. д. Процесс init может порождать управляющие процессы, которые будут существовать на протяжении всего времени жизни системы, в различных случаях они могут быть созданы самими пользователями. Они похожи на пользовательские процессы тем, что они исполняются в режиме задачи и прибегают к услугам системы путем вызова соответствующих системных функций.
Системные процессы выполняются исключительно в режиме ядра. Они могут порождаться нулевым процессом (например, процесс замещения страниц vhand), который затем становится процессом подкачки. Системные процессы похожи на управляющие процессы тем, что они выполняют системные функции, при этом они обладают большими возможностями приоритетного выполнения, поскольку лежащие в их основе программные коды являются составной частью ядра. Они могут обращаться к структурам данных и алгоритмам ядра, не прибегая к вызову системных функций, отсюда вытекает их исключительность. Однако, они не обладают такой же гибкостью, как управляющие процессы, поскольку для того, чтобы внести изменения в их программы, придется еще раз перекомпилировать ядро.
алгоритм init /* процесс init, в системе именуемый „процесс 1“ */
входная информация: отсутствует
выходная информация: отсутствует
{
fd = open("/etc/inittab", O_RDONLY);
while (line_read(fd, buffer)) { /* читать каждую строку файла */
if (invoked state != buffer state) continue; /* остаться в цикле while */
/* найден идентификатор соответствующего состояния */
if (fork() == 0) {
execl("процесс указан в буфере");
exit();
}
/* процесс init не дожидается завершения потомка */
/* возврат в цикл while */
}
while ((id = wait((int*) 0)) != -1) {
/* проверка существования потомка; если потомок прекратил существование, рассматривается возможность его перезапуска, в противном случае, основной процесс просто продолжает работу */
}
}
Рисунок 7.31. Алгоритм выполнения процесса init
Формат: идентификатор, состояние, действие, спецификация процесса
Поля разделены между собой двоеточиями
Комментарии в конце строки начинаются с символа '# '
co::respawn:/etc/getty console console #Консоль в машзале
46:2:respawn:/etc/getty -t 60 tty46 4800H #комментарии
Рисунок 7.32. Фрагмент файла inittab
Ядро инициализирует свои внутренние структуры данных. Среди прочих структур ядро создает связные списки свободных буферов и индексов, хеш-очереди для буферов и индексов, инициализирует структуры областей, точки входа в таблицы страниц и т. д. По окончании этой фазы ядро монтирует корневую файловую систему и формирует среду выполнения нулевого процесса, среди всего прочего создавая пространство процесса, инициализируя нулевую точку входа в таблице процесса и делая корневой каталог текущим для процесса.
Когда формирование среды выполнения процесса заканчивается, система исполняется уже в виде нулевого процесса. Нулевой процесс „ветвится“, запуская алгоритм fork прямо из ядра, поскольку сам процесс исполняется в режиме ядра. Порожденный нулевым новый процесс, процесс 1, запускается в том же режиме и создает свой пользовательский контекст, формируя область данных и присоединяя ее к своему адресному пространству. Он увеличивает размер области до надлежащей величины и переписывает программу загрузки из адресного пространства ядра в новую область: эта программа теперь будет определять контекст процесса 1. Затем процесс 1 сохраняет регистровый контекст задачи, „возвращается“ из режима ядра в режим задачи и исполняет только что переписанную программу. В отличие от нулевого процесса, который является процессом системного уровня, выполняющимся в режиме ядра, процесс 1 относится к пользовательскому уровню. Код, исполняемый процессом 1, включает в себя вызов системной функции exec, запускающей на выполнение программу из файла „/etc/init“. Обычно процесс 1 именуется процессом init, поскольку он отвечает за инициализацию новых процессов.
алгоритм start /* процедура начальной загрузки системы */
входная информация: отсутствует
выходная информация: отсутствует
{
проинициализировать все структуры данных ядра;
псевдо-монтирование корня;
сформировать среду выполнения процесса 0;
создать процесс 1;
{
/* процесс 1 */
выделить область;
подключить область к адресному пространству процесса init ;
увеличить размер области для копирования в нее исполняемого кода;
скопировать из пространства ядра в адресное пространство процесса код программы, исполняемой процессом;
изменить режим выполнения: вернуться из режима ядра в режим задачи;
/* процесс init далее выполняется самостоятельно — в результате выхода в режим задачи, init исполняет файл „/etc/init“ и становится „обычным“ пользовательским процессом, производящим обращения к системным функциям */
}
/* продолжение нулевого процесса */
породить процессы ядра;
/* нулевой процесс запускает программу подкачки, управляющую распределением адресного пространства процессов между основной памятью и устройствами выгрузки. Это бесконечный цикл; нулевой процесс обычно приостанавливает свою работу, если необходимости в нем больше нет. */
исполнить программу, реализующую алгоритм подкачки;
}
Рисунок 7.30. Алгоритм загрузки системы
Казалось бы, зачем ядру копировать программу, запускаемую с помощью функции exec, в адресное пространство процесса 1? Он мог бы обратиться к внутреннему варианту функции прямо из ядра, однако, по сравнению с уже описанным алгоритмом это было бы гораздо труднее реализовать, ибо в этом случае функции exec пришлось бы производить анализ имен файлов в пространстве ядра, а не в пространстве задачи. Подобная деталь, требующаяся только для процесса init, усложнила бы программу реализации функции exec и отрицательно отразилась бы на скорости выполнения функции в более общих случаях.
Процесс init (Рисунок 7.31) выступает диспетчером процессов, который порождает процессы, среди всего прочего позволяющие пользователю регистрироваться в системе. Инструкции о том, какие процессы нужно создать, считываются процессом init из файла „/etc/inittab“. Строки файла включают в себя идентификатор состояния „id“ (однопользовательский режим, многопользовательский и т. д.), предпринимаемое действие (см. упражнение 7.43) и спецификацию программы, реализующей это действие (см. Рисунок 7.32). Процесс init просматривает строки файла до тех пор, пока не обнаружит идентификатор состояния, соответствующего тому состоянию, в котором находится процесс, и создает процесс, исполняющий программу с указанной спецификацией. Например, при запуске в многопользовательском режиме (состояние 2) процесс init обычно порождает getty-процессы, управляющие функционированием терминальных линий, входящих в состав системы. Если регистрация пользователя прошла успешно, getty-процесс, пройдя через процедуру login, запускает на исполнение регистрационный shell (см. главу 10). Тем временем процесс init находится в состоянии ожидания (wait), наблюдая за прекращением существования своих потомков, а также „внучатых“ процессов, оставшихся „сиротами“ после гибели своих родителей.
Процессы в системе UNIX могут быть либо пользовательскими, либо управляющими, либо системными. Большинство из них составляют пользовательские процессы, связанные с пользователями через терминалы. Управляющие процессы не связаны с конкретными пользователями, они выполняют широкий спектр системных функций, таких как администрирование и управление сетями, различные периодические операции, буферизация данных для вывода на устройство построчной печати и т. д. Процесс init может порождать управляющие процессы, которые будут существовать на протяжении всего времени жизни системы, в различных случаях они могут быть созданы самими пользователями. Они похожи на пользовательские процессы тем, что они исполняются в режиме задачи и прибегают к услугам системы путем вызова соответствующих системных функций.
Системные процессы выполняются исключительно в режиме ядра. Они могут порождаться нулевым процессом (например, процесс замещения страниц vhand), который затем становится процессом подкачки. Системные процессы похожи на управляющие процессы тем, что они выполняют системные функции, при этом они обладают большими возможностями приоритетного выполнения, поскольку лежащие в их основе программные коды являются составной частью ядра. Они могут обращаться к структурам данных и алгоритмам ядра, не прибегая к вызову системных функций, отсюда вытекает их исключительность. Однако, они не обладают такой же гибкостью, как управляющие процессы, поскольку для того, чтобы внести изменения в их программы, придется еще раз перекомпилировать ядро.
алгоритм init /* процесс init, в системе именуемый „процесс 1“ */
входная информация: отсутствует
выходная информация: отсутствует
{
fd = open("/etc/inittab", O_RDONLY);
while (line_read(fd, buffer)) { /* читать каждую строку файла */
if (invoked state != buffer state) continue; /* остаться в цикле while */
/* найден идентификатор соответствующего состояния */
if (fork() == 0) {
execl("процесс указан в буфере");
exit();
}
/* процесс init не дожидается завершения потомка */
/* возврат в цикл while */
}
while ((id = wait((int*) 0)) != -1) {
/* проверка существования потомка; если потомок прекратил существование, рассматривается возможность его перезапуска, в противном случае, основной процесс просто продолжает работу */
}
}
Рисунок 7.31. Алгоритм выполнения процесса init
Формат: идентификатор, состояние, действие, спецификация процесса
Поля разделены между собой двоеточиями
Комментарии в конце строки начинаются с символа '# '
co::respawn:/etc/getty console console #Консоль в машзале
46:2:respawn:/etc/getty -t 60 tty46 4800H #комментарии
Рисунок 7.32. Фрагмент файла inittab
7.10 ВЫВОДЫ
В данной главе были рассмотрены системные функции, предназначенные для работы с контекстом процесса и для управления выполнением процесса. Системная функция fork создает новый процесс, копируя для него содержимое всех областей, подключенных к родительскому процессу. Особенность реализации функции fork состоит в том, что она выполняет инициализацию сохраненного регистрового контекста порожденного процесса, таким образом этот процесс начинает выполняться, не дожидаясь завершения функции, и уже в теле функции начинает осознавать свою предназначение как потомка. Все процессы завершают свое выполнение вызовом функции exit, которая отсоединяет области процесса и посылает его родителю сигнал „гибель потомка“. Процесс-родитель может совместить момент продолжения своего выполнения с моментом завершения процесса-потомка, используя системную функцию wait. Системная функция exec дает процессу возможность запускать на выполнение другие программы, накладывая содержимое исполняемого файла на свое адресное пространство. Ядро отсоединяет области, ранее занимаемые процессом, и назначает процессу новые области в соответствии с потребностями исполняемого файла. Совместное использование областей команд и наличие режима „sticky-bit“ дают возможность более рационально использовать память и экономить время, затрачиваемое на подготовку к запуску программ. Простым пользователям предоставляется возможность получать привилегии других пользователей, даже суперпользователя, благодаря обращению к услугам системной функции setuid и setuid-программ. С помощью функции brk процесс может изменять размер своей области данных. Функция signal дает процессам возможность управлять своей реакцией на поступающие сигналы. При получении сигнала производится обращение к специальной функции обработки сигнала с внесением соответствующих изменений в стек задачи и в сохраненный регистровый контекст задачи. Процессы могут сами посылать сигналы, используя системную функцию kill, они могут также контролировать получение сигналов, предназначенных группе процессов, прибегая к услугам функции setpgrp.
Командный процессор shell и процесс начальной загрузки init используют стандартные обращения к системным функциям, производя набор операций, в других системах обычно выполняемых ядром. Shell интерпретирует команды пользователя, переназначает стандартные файлы ввода-вывода данных и выдачи ошибок, порождает процессы, организует каналы между порожденными процессами, синхронизирует свое выполнение с этими процессами и формирует коды, возвращаемые командами. Процесс init тоже порождает различные процессы, в частности, управляющие работой пользователя за терминалом. Когда такой процесс завершается, init может породить для выполнения той же самой функции еще один процесс, если это вытекает из информации файла „/etc/inittab“.
Командный процессор shell и процесс начальной загрузки init используют стандартные обращения к системным функциям, производя набор операций, в других системах обычно выполняемых ядром. Shell интерпретирует команды пользователя, переназначает стандартные файлы ввода-вывода данных и выдачи ошибок, порождает процессы, организует каналы между порожденными процессами, синхронизирует свое выполнение с этими процессами и формирует коды, возвращаемые командами. Процесс init тоже порождает различные процессы, в частности, управляющие работой пользователя за терминалом. Когда такой процесс завершается, init может породить для выполнения той же самой функции еще один процесс, если это вытекает из информации файла „/etc/inittab“.
7.11 УПРАЖНЕНИЯ
1. Запустите с терминала программу, приведенную на Рисунке 7.33. Переадресуйте стандартный вывод данных в файл и сравните результаты между собой.
main() {
printf("hello\n“);
if (fork() == 0) printf("world\n“);
}
Рисунок 7.33. Пример модуля, содержащего вызов функции fork и обращение к стандартному выводу
2. Разберитесь в механизме работы программы, приведенной на Рисунке 7.34, и сравните ее результаты с результатами программы на Рисунке 7.4.
main() {
printf("hello\n“);
if (fork() == 0) printf("world\n“);
}
Рисунок 7.33. Пример модуля, содержащего вызов функции fork и обращение к стандартному выводу
2. Разберитесь в механизме работы программы, приведенной на Рисунке 7.34, и сравните ее результаты с результатами программы на Рисунке 7.4.