Страница:
Основные различия между этими двумя режимами:
В режиме задачи процессы имеют доступ только к своим собственным инструкциям и данным, но не к инструкциям и данным ядра (либо других процессов). Однако в режиме ядра процессам уже доступны адресные пространства ядра и пользователей. Например, виртуальное адресное пространство процесса может быть поделено на адреса, доступные только в режиме ядра, и на адреса, доступные в любом режиме.
Некоторые машинные команды являются привилегированными и вызывают возникновение ошибок при попытке их использования в режиме задачи. Например, в машинном языке может быть команда, управляющая регистром состояния процессора; процессам, выполняющимся в режиме задачи, она недоступна.
Рисунок 1.5. Процессы и режимы их выполнения
Проще говоря, любое взаимодействие с аппаратурой описывается в терминах режима ядра и режима задачи и протекает одинаково для всех пользовательских программ, выполняющихся в этих режимах. Операционная система хранит внутренние записи о каждом процессе, выполняющемся в системе. На Рисунке 1.5 показано это разделение: ядро делит процессы A, B, C и D, расположенные вдоль горизонтальной оси, аппаратные средства вводят различия между режимами выполнения, расположенными по вертикали.
Несмотря на то, что система функционирует в одном из двух режимов, ядро действует от имени пользовательского процесса. Ядро не является какой-то особой совокупностью процессов, выполняющихся параллельно с пользовательскими, оно само выступает составной частью любого пользовательского процесса. Сделанный вывод будет скорее относиться к «ядру», распределяющему ресурсы, или к «ядру», производящему различные операции, и это будет означать, что процесс, выполняемый в режиме ядра, распределяет ресурсы и производит соответствующие операции. Например, командный процессор shell считывает вводной поток с терминала с помощью запроса к операционной системе. Ядро операционной системы, выступая от имени процессора shell, управляет функционированием терминала и передает вводимые символы процессору shell. Shell переходит в режим задачи, анализирует поток символов, введенных пользователем и выполняет заданную последовательность действий, которые могут потребовать выполнения и других системных операций.
1.5.1 Прерывания и особые ситуации
1.5.2 Уровни прерывания процессора
1.5.3 Распределение памяти
1.6 ВЫВОДЫ
ГЛАВА 2. ВВЕДЕНИЕ В АРХИТЕКТУРУ ЯДРА ОПЕРАЦИОННОЙ СИСТЕМЫ
2.1 АРХИТЕКТУРА ОПЕРАЦИОННОЙ СИСТЕМЫ UNIХ
2.2 ВВЕДЕНИЕ В ОСНОВНЫЕ ПОНЯТИЯ СИСТЕМЫ
2.2.1 Обзор особенностей подсистемы управления файлами
2.2.2 Процессы
В режиме задачи процессы имеют доступ только к своим собственным инструкциям и данным, но не к инструкциям и данным ядра (либо других процессов). Однако в режиме ядра процессам уже доступны адресные пространства ядра и пользователей. Например, виртуальное адресное пространство процесса может быть поделено на адреса, доступные только в режиме ядра, и на адреса, доступные в любом режиме.
Некоторые машинные команды являются привилегированными и вызывают возникновение ошибок при попытке их использования в режиме задачи. Например, в машинном языке может быть команда, управляющая регистром состояния процессора; процессам, выполняющимся в режиме задачи, она недоступна.
| Процессы | ||||
|---|---|---|---|---|
| A | B | C | D | |
| Режим ядра | Я | . | . | Я |
| Режим задачи | . | З | З | . |
Рисунок 1.5. Процессы и режимы их выполнения
Проще говоря, любое взаимодействие с аппаратурой описывается в терминах режима ядра и режима задачи и протекает одинаково для всех пользовательских программ, выполняющихся в этих режимах. Операционная система хранит внутренние записи о каждом процессе, выполняющемся в системе. На Рисунке 1.5 показано это разделение: ядро делит процессы A, B, C и D, расположенные вдоль горизонтальной оси, аппаратные средства вводят различия между режимами выполнения, расположенными по вертикали.
Несмотря на то, что система функционирует в одном из двух режимов, ядро действует от имени пользовательского процесса. Ядро не является какой-то особой совокупностью процессов, выполняющихся параллельно с пользовательскими, оно само выступает составной частью любого пользовательского процесса. Сделанный вывод будет скорее относиться к «ядру», распределяющему ресурсы, или к «ядру», производящему различные операции, и это будет означать, что процесс, выполняемый в режиме ядра, распределяет ресурсы и производит соответствующие операции. Например, командный процессор shell считывает вводной поток с терминала с помощью запроса к операционной системе. Ядро операционной системы, выступая от имени процессора shell, управляет функционированием терминала и передает вводимые символы процессору shell. Shell переходит в режим задачи, анализирует поток символов, введенных пользователем и выполняет заданную последовательность действий, которые могут потребовать выполнения и других системных операций.
1.5.1 Прерывания и особые ситуации
Система UNIX позволяет таким устройства, как внешние устройства ввода-вывода и системные часы, асинхронно прерывать работу центрального процессора. По получении сигнала прерывания ядро операционной системы сохраняет свой текущий контекст (застывший образ выполняемого процесса), устанавливает причину прерывания и обрабатывает прерывание. После того, как прерывание будет обработано ядром, прерванный контекст восстановится и работа продолжится так, как будто ничего не случилось. Устройствам обычно приписываются приоритеты в соответствии с очередностью обработки прерываний. В процессе обработки прерываний ядро учитывает их приоритеты и блокирует обслуживание прерывания с низким приоритетом на время обработки прерывания с более высоким приоритетом.
Особые ситуации связаны с возникновением незапланированных событий, вызванных процессом, таких как недопустимая адресация, задание привилегированных команд, деление на ноль и т. д. Они отличаются от прерываний, которые вызываются событиями, внешними по отношению к процессу. Особые ситуации возникают прямо «посредине» выполнения команды, и система, обработав особую ситуацию, пытается перезапустить команду; считается, что прерывания возникают между выполнением двух команд, при этом система после обработки прерывания продолжает выполнение процесса уже начиная со следующей команды. Для обработки прерываний и особых ситуаций в системе UNIX используется один и тот же механизм.
Особые ситуации связаны с возникновением незапланированных событий, вызванных процессом, таких как недопустимая адресация, задание привилегированных команд, деление на ноль и т. д. Они отличаются от прерываний, которые вызываются событиями, внешними по отношению к процессу. Особые ситуации возникают прямо «посредине» выполнения команды, и система, обработав особую ситуацию, пытается перезапустить команду; считается, что прерывания возникают между выполнением двух команд, при этом система после обработки прерывания продолжает выполнение процесса уже начиная со следующей команды. Для обработки прерываний и особых ситуаций в системе UNIX используется один и тот же механизм.
1.5.2 Уровни прерывания процессора
Ядро иногда обязано предупреждать возникновение прерываний во время критических действий, могущих в случае прерывания запортить информацию. Например, во время обработки списка с указателями возникновение прерывания от диска для ядра нежелательно, т. к. при обработке прерывания можно запортить указатели, что можно увидеть на примере в следующей главе. Обычно имеется ряд привилегированных команд, устанавливающих уровень прерывания процессора в слове состояния процессора. Установка уровня прерывания на определенное значение отсекает прерывания этого и более низких уровней, разрешая обработку только прерываний с более высоким приоритетом. На Рисунке 1.6 показана последовательность уровней прерывания. Если ядро игнорирует прерывания от диска, в этом случае игнорируются и все остальные прерывания, кроме прерываний от часов и машинных сбоев.
 Рисунок 1.6. Стандартные уровни прерываний
Рисунок 1.6. Стандартные уровни прерываний
1.5.3 Распределение памяти
Ядро постоянно располагается в оперативной памяти, наряду с выполняющимся в данный момент процессом (или частью его, по меньшей мере). В процессе компиляции программа-компилятор генерирует последовательность адресов, являющихся адресами переменных и информационных структур, а также адресами инструкций и функций. Компилятор генерирует адреса для виртуальной машины так, словно на физической машине не будет выполняться параллельно с транслируемой ни одна другая программа.
Когда программа запускается на выполнение, ядро выделяет для нее место в оперативной памяти, при этом совпадение виртуальных адресов, сгенерированных компилятором, с физическими адресами совсем необязательно. Ядро, взаимодействуя с аппаратными средствами, транслирует виртуальные адреса в физические, т. е. отображает адреса, сгенерированные компилятором, в физические, машинные адреса. Такое отображение опирается на возможности аппаратных средств, поэтому компоненты системы UNIX, занимающиеся им, являются машинно-зависимыми. Например, отдельные вычислительные машины имеют специальное оборудование для подкачки выгруженных страниц памяти. Главы 6 и 9 посвящены более подробному рассмотрению вопросов, связанных с распределением памяти, и исследованию их соотношения с аппаратными средствами.
Когда программа запускается на выполнение, ядро выделяет для нее место в оперативной памяти, при этом совпадение виртуальных адресов, сгенерированных компилятором, с физическими адресами совсем необязательно. Ядро, взаимодействуя с аппаратными средствами, транслирует виртуальные адреса в физические, т. е. отображает адреса, сгенерированные компилятором, в физические, машинные адреса. Такое отображение опирается на возможности аппаратных средств, поэтому компоненты системы UNIX, занимающиеся им, являются машинно-зависимыми. Например, отдельные вычислительные машины имеют специальное оборудование для подкачки выгруженных страниц памяти. Главы 6 и 9 посвящены более подробному рассмотрению вопросов, связанных с распределением памяти, и исследованию их соотношения с аппаратными средствами.
1.6 ВЫВОДЫ
В этой главе описаны полная структура системы UNIX, взаимоотношения между процессами, выполняющимися в режиме задачи и в режиме ядра, а также аппаратная среда функционирования ядра операционной системы. Процессы выполняются в режиме задачи или в режиме ядра, в котором они пользуются услугами системы благодаря наличию набора обращений к операционной системе. Архитектура системы поддерживает такой стиль программирования, при котором из небольших программ, выполняющих только отдельные функции, но хорошо, составляются более сложные программы, использующие механизм каналов и переназначение ввода-вывода.
Обращения к операционной системе позволяют процессам производить операции, которые иначе не выполняются. В дополнение к обработке подобных обращений ядро операционной системы осуществляет общие учетные операции, управляет планированием процессов, распределением памяти и защитой процессов в оперативной памяти, обслуживает прерывания, управляет файлами и устройствами и обрабатывает особые ситуации, возникающие в системе. В функции ядра системы UNIX намеренно не включены многие функции, являющиеся частью других операционных систем, поскольку набор обращений к системе позволяет процессам выполнять все необходимые операции на пользовательском уровне. В следующей главе содержится более детальная информация о ядре, описывающая его архитектуру и вводящая некоторые основные понятия, которые используются при описании его функционирования.
Обращения к операционной системе позволяют процессам производить операции, которые иначе не выполняются. В дополнение к обработке подобных обращений ядро операционной системы осуществляет общие учетные операции, управляет планированием процессов, распределением памяти и защитой процессов в оперативной памяти, обслуживает прерывания, управляет файлами и устройствами и обрабатывает особые ситуации, возникающие в системе. В функции ядра системы UNIX намеренно не включены многие функции, являющиеся частью других операционных систем, поскольку набор обращений к системе позволяет процессам выполнять все необходимые операции на пользовательском уровне. В следующей главе содержится более детальная информация о ядре, описывающая его архитектуру и вводящая некоторые основные понятия, которые используются при описании его функционирования.
ГЛАВА 2. ВВЕДЕНИЕ В АРХИТЕКТУРУ ЯДРА ОПЕРАЦИОННОЙ СИСТЕМЫ
В предыдущей главе был сделан только поверхностный обзор особенностей операционной среды UNIX. В этой главе основное внимание уделяется ядру операционной системы, делается обзор его архитектуры и излагаются в общих чертах основные понятия и структуры, существенные для понимания всего последующего материала книги.
2.1 АРХИТЕКТУРА ОПЕРАЦИОННОЙ СИСТЕМЫ UNIХ
Как уже ранее было замечено (см. [Christian 83], стр.239), в системе UNIX создается иллюзия того, что файловая система имеет «места» и что у процессов есть «жизнь». Обе сущности, файлы и процессы, являются центральными понятиями модели операционной системы UNIX. На Рисунке 2.1 представлена блок-схема ядра системы, отражающая состав модулей, из которых состоит ядро, и их взаимосвязи друг с другом. В частности, на ней слева изображена файловая подсистема, а справа подсистема управления процессами, две главные компоненты ядра. Эта схема дает логическое представление о ядре, хотя в действительности в структуре ядра имеются отклонения от модели, поскольку отдельные модули испытывают внутреннее воздействие со стороны других модулей.
Схема на Рисунке 2.1 имеет три уровня: уровень пользователя, уровень ядра и уровень аппаратуры. Обращения к операционной системе и библиотеки составляют границу между пользовательскими программами и ядром, проведенную на Рисунке 1.1. Обращения к операционной системе выглядят так же, как обычные вызовы функций в программах на языке Си, и библиотеки устанавливают соответствие между этими вызовами функций и элементарными системными операциями, о чем более подробно см. в главе 6. При этом программы на ассемблере могут обращаться к операционной системе непосредственно, без использования библиотеки системных вызовов. Программы часто обращаются к другим библиотекам, таким как библиотека стандартных подпрограмм ввода-вывода, достигая тем самым более полного использования системных услуг. Для этого во время компиляции библиотеки связываются с программами и частично включаются в программу пользователя. Далее мы проиллюстрируем эти моменты на примере.
На рисунке совокупность обращений к операционной системе разделена на те обращения, которые взаимодействуют с подсистемой управления файлами, и те, которые взаимодействуют с подсистемой управления процессами. Файловая подсистема управляет файлами, размещает записи файлов, управляет свободным пространством, доступом к файлам и поиском данных для пользователей. Процессы взаимодействуют с подсистемой управления файлами, используя при этом совокупность специальных обращений к операционной системе, таких как open (для того, чтобы открыть файл на чтение или запись), close, read, write, stat (запросить атрибуты файла), chown (изменить запись с информацией о владельце файла) и chmod (изменить права доступа к файлу). Эти и другие операции рассматриваются в главе 5.
Подсистема управления файлами обращается к данным, которые хранятся в файле, используя буферный механизм, управляющий потоком данных между ядром и устройствами внешней памяти. Буферный механизм, взаимодействуя с драйверами устройств ввода-вывода блоками, инициирует передачу данных к ядру и обратно. Драйверы устройств являются такими модулями в составе ядра, которые управляют работой периферийных устройств. Устройства ввода-вывода блоками относятся программы пользователя
 Рисунок 2.1. Блок-схема ядра операционной системы
Рисунок 2.1. Блок-схема ядра операционной системы
к типу запоминающих устройств с произвольной выборкой; их драйверы построены таким образом, что все остальные компоненты системы воспринимают эти устройства как запоминающие устройства с произвольной выборкой. Например, драйвер запоминающего устройства на магнитной ленте позволяет ядру системы воспринимать это устройство как запоминающее устройство с произвольной выборкой. Подсистема управления файлами также непосредственно взаимодействует с драйверами устройств «неструктурированного» ввода-вывода, без вмешательства буферного механизма. К устройствам неструктурированного ввода-вывода, иногда именуемым устройствами посимвольного ввода-вывода (текстовыми), относятся устройства, отличные от устройств ввода-вывода блоками.
Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов. Подсистема управления файлами и подсистема управления процессами взаимодействуют между собой, когда файл загружается в память на выполнение (см. главу 7): подсистема управления процессами читает в память исполняемые файлы перед тем, как их выполнить.
Примерами обращений к операционной системе, используемых при управлении процессами, могут служить fork (создание нового процесса), exec (наложение образа программы на выполняемый процесс), exit (завершение выполнения процесса), wait (синхронизация продолжения выполнения основного процесса с моментом выхода из порожденного процесса), brk (управление размером памяти, выделенной процессу) и signal (управление реакцией процесса на возникновение экстраординарных событий). Глава 7 посвящена рассмотрению этих и других системных вызовов.
Модуль распределения памяти контролирует выделение памяти процессам. Если в какой-то момент система испытывает недостаток в физической памяти для запуска всех процессов, ядро пересылает процессы между основной и внешней памятью с тем, чтобы все процессы имели возможность выполняться. В главе 9 описываются два способа управления распределением памяти: выгрузка (подкачка) и замещение страниц. Программу подкачки иногда называют планировщиком, т. к. она «планирует» выделение памяти процессам и оказывает влияние на работу планировщика центрального процессора. Однако в дальнейшем мы будем стараться ссылаться на нее как на «программу подкачки», чтобы избежать путаницы с планировщиком центрального процессора.
Модуль «планировщик» распределяет между процессами время центрального процессора. Он планирует очередность выполнения процессов до тех пор, пока они добровольно не освободят центральный процессор, дождавшись выделения какого-либо ресурса, или до тех пор, пока ядро системы не выгрузит их после того, как их время выполнения превысит заранее определенный квант времени. Планировщик выбирает на выполнение готовый к запуску процесс с наивысшим приоритетом; выполнение предыдущего процесса (приостановленного) будет продолжено тогда, когда его приоритет будет наивысшим среди приоритетов всех готовых к запуску процессов. Существует несколько форм взаимодействия процессов между собой, от асинхронного обмена сигналами о событиях до синхронного обмена сообщениями.
Наконец, аппаратный контроль отвечает за обработку прерываний и за связь с машиной. Такие устройства, как диски и терминалы, могут прерывать работу центрального процессора во время выполнения процесса. При этом ядро системы после обработки прерывания может возобновить выполнение прерванного процесса. Прерывания обрабатываются не самими процессами, а специальными функциями ядра системы, перечисленными в контексте выполняемого процесса.
Схема на Рисунке 2.1 имеет три уровня: уровень пользователя, уровень ядра и уровень аппаратуры. Обращения к операционной системе и библиотеки составляют границу между пользовательскими программами и ядром, проведенную на Рисунке 1.1. Обращения к операционной системе выглядят так же, как обычные вызовы функций в программах на языке Си, и библиотеки устанавливают соответствие между этими вызовами функций и элементарными системными операциями, о чем более подробно см. в главе 6. При этом программы на ассемблере могут обращаться к операционной системе непосредственно, без использования библиотеки системных вызовов. Программы часто обращаются к другим библиотекам, таким как библиотека стандартных подпрограмм ввода-вывода, достигая тем самым более полного использования системных услуг. Для этого во время компиляции библиотеки связываются с программами и частично включаются в программу пользователя. Далее мы проиллюстрируем эти моменты на примере.
На рисунке совокупность обращений к операционной системе разделена на те обращения, которые взаимодействуют с подсистемой управления файлами, и те, которые взаимодействуют с подсистемой управления процессами. Файловая подсистема управляет файлами, размещает записи файлов, управляет свободным пространством, доступом к файлам и поиском данных для пользователей. Процессы взаимодействуют с подсистемой управления файлами, используя при этом совокупность специальных обращений к операционной системе, таких как open (для того, чтобы открыть файл на чтение или запись), close, read, write, stat (запросить атрибуты файла), chown (изменить запись с информацией о владельце файла) и chmod (изменить права доступа к файлу). Эти и другие операции рассматриваются в главе 5.
Подсистема управления файлами обращается к данным, которые хранятся в файле, используя буферный механизм, управляющий потоком данных между ядром и устройствами внешней памяти. Буферный механизм, взаимодействуя с драйверами устройств ввода-вывода блоками, инициирует передачу данных к ядру и обратно. Драйверы устройств являются такими модулями в составе ядра, которые управляют работой периферийных устройств. Устройства ввода-вывода блоками относятся программы пользователя
к типу запоминающих устройств с произвольной выборкой; их драйверы построены таким образом, что все остальные компоненты системы воспринимают эти устройства как запоминающие устройства с произвольной выборкой. Например, драйвер запоминающего устройства на магнитной ленте позволяет ядру системы воспринимать это устройство как запоминающее устройство с произвольной выборкой. Подсистема управления файлами также непосредственно взаимодействует с драйверами устройств «неструктурированного» ввода-вывода, без вмешательства буферного механизма. К устройствам неструктурированного ввода-вывода, иногда именуемым устройствами посимвольного ввода-вывода (текстовыми), относятся устройства, отличные от устройств ввода-вывода блоками.
Подсистема управления процессами отвечает за синхронизацию процессов, взаимодействие процессов, распределение памяти и планирование выполнения процессов. Подсистема управления файлами и подсистема управления процессами взаимодействуют между собой, когда файл загружается в память на выполнение (см. главу 7): подсистема управления процессами читает в память исполняемые файлы перед тем, как их выполнить.
Примерами обращений к операционной системе, используемых при управлении процессами, могут служить fork (создание нового процесса), exec (наложение образа программы на выполняемый процесс), exit (завершение выполнения процесса), wait (синхронизация продолжения выполнения основного процесса с моментом выхода из порожденного процесса), brk (управление размером памяти, выделенной процессу) и signal (управление реакцией процесса на возникновение экстраординарных событий). Глава 7 посвящена рассмотрению этих и других системных вызовов.
Модуль распределения памяти контролирует выделение памяти процессам. Если в какой-то момент система испытывает недостаток в физической памяти для запуска всех процессов, ядро пересылает процессы между основной и внешней памятью с тем, чтобы все процессы имели возможность выполняться. В главе 9 описываются два способа управления распределением памяти: выгрузка (подкачка) и замещение страниц. Программу подкачки иногда называют планировщиком, т. к. она «планирует» выделение памяти процессам и оказывает влияние на работу планировщика центрального процессора. Однако в дальнейшем мы будем стараться ссылаться на нее как на «программу подкачки», чтобы избежать путаницы с планировщиком центрального процессора.
Модуль «планировщик» распределяет между процессами время центрального процессора. Он планирует очередность выполнения процессов до тех пор, пока они добровольно не освободят центральный процессор, дождавшись выделения какого-либо ресурса, или до тех пор, пока ядро системы не выгрузит их после того, как их время выполнения превысит заранее определенный квант времени. Планировщик выбирает на выполнение готовый к запуску процесс с наивысшим приоритетом; выполнение предыдущего процесса (приостановленного) будет продолжено тогда, когда его приоритет будет наивысшим среди приоритетов всех готовых к запуску процессов. Существует несколько форм взаимодействия процессов между собой, от асинхронного обмена сигналами о событиях до синхронного обмена сообщениями.
Наконец, аппаратный контроль отвечает за обработку прерываний и за связь с машиной. Такие устройства, как диски и терминалы, могут прерывать работу центрального процессора во время выполнения процесса. При этом ядро системы после обработки прерывания может возобновить выполнение прерванного процесса. Прерывания обрабатываются не самими процессами, а специальными функциями ядра системы, перечисленными в контексте выполняемого процесса.
2.2 ВВЕДЕНИЕ В ОСНОВНЫЕ ПОНЯТИЯ СИСТЕМЫ
В это разделе дается обзор некоторых основных информационных структур, используемых ядром системы, и более подробно описывается функционирование модулей ядра, показанных на Рисунке 2.1.
2.2.1 Обзор особенностей подсистемы управления файлами
Внутреннее представление файла описывается в индексе, который содержит описание размещения информации файла на диске и другую информацию, такую как владелец файла, права доступа к файлу и время доступа. Термин «индекс» (inode) широко используется в литературе по системе UNIX. Каждый файл имеет один индекс, но может быть связан с несколькими именами, которые все отражаются в индексе. Каждое имя является указателем. Когда процесс обращается к файлу по имени, ядро системы анализирует по очереди каждую компоненту имени файла, проверяя права процесса на просмотр входящих в путь поиска каталогов, и в конце концов возвращает индекс файла. Например, если процесс обращается к системе:
open("/fs2/mjb/rje/sourcefile", 1);
ядро системы возвращает индекс для файла «/fs2/mjb/rje/sourcefile». Если процесс создает новый файл, ядро присваивает этому файлу неиспользуемый индекс. Индексы хранятся в файловой системе (и это мы еще увидим), однако при обработке файлов ядро заносит их в таблицу индексов в оперативной памяти.
Ядро поддерживает еще две информационные структуры, таблицу файлов и пользовательскую таблицу дескрипторов файла. Таблица файлов выступает глобальной структурой ядра, а пользовательская таблица дескрипторов файла выделяется под процесс. Если процесс открывает или создает файл, ядро выделяет в каждой таблице элемент, корреспондирующий с индексом файла. Элементы в этих трех структурах — в пользовательской таблице дескрипторов файла, в таблице файлов и в таблице индексов — хранят информацию о состоянии файла и о доступе пользователей к нему. В таблице файлов хранится смещение в байтах от начала файла до того места, откуда начнет выполняться следующая команда пользователя read или write, а также информация о правах доступа к открываемому процессу. Таблица дескрипторов файла идентифицирует все открытые для процесса файлы. На Рисунке 2.2 показаны эти таблицы и связи между ними. В системных операциях open (открыть) и creat (создать) ядро возвращает дескриптор файла, которому соответствует указатель в таблице дескрипторов файла. При выполнении операций read (читать) и write (писать) ядро использует дескриптор файла для входа в таблицу дескрипторов и, следуя указателям на таблицу файлов и на таблицу индексов, находит информацию в файле. Более подробно эти информационные структуры рассматриваются в главах 4 и 5. Сейчас достаточно сказать, что использование этих таблиц обеспечивает различную степень разделения доступа к файлу.
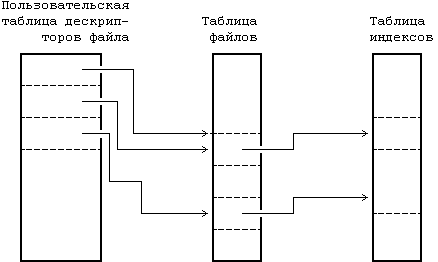 Рисунок 2.2. Таблицы файлов, дескрипторов файла и индексов
Рисунок 2.2. Таблицы файлов, дескрипторов файла и индексов
Обычные файлы и каталоги хранятся в системе UNIX на устройствах ввода-вывода блоками, таких как магнитные ленты или диски. Поскольку существует некоторое различие во времени доступа к этим устройствам, при установке системы UNIX на лентах размещают файловые системы. С годами бездисковые автоматизированные рабочие места станут общим случаем, и файлы будут располагаться в удаленной системе, доступ к которой будет осуществляться через сеть (см. главу 13). Для простоты, тем не менее, в последующем тексте подразумевается использование дисков. В системе может быть несколько физических дисков, на каждом из которых может размещаться одна и более файловых систем. Разбивка диска на несколько файловых систем облегчает администратору управление хранимыми данными. На логическом уровне ядро имеет дело с файловыми системами, а не с дисками, при этом каждая система трактуется как логическое устройство, идентифицируемое номером. Преобразование адресов логического устройства (файловой системы) в адреса физического устройства (диска) и обратно выполняется дисковым драйвером. Термин «устройство» в этой книге используется для обозначения логического устройства, кроме специально оговоренных случаев.
Файловая система состоит из последовательности логических блоков длиной 512, 1024, 2048 или другого числа байт, кратного 512, в зависимости от реализации системы. Размер логического блока внутри одной файловой системы постоянен, но может варьироваться в разных файловых системах в данной конфигурации. Использование логических блоков большого размера увеличивает скорость передачи данных между диском и памятью, поскольку ядро сможет передать больше информации за одну дисковую операцию, и сокращает количество продолжительных операций. Например, чтение 1 Кбайта с диска за одну операцию осуществляется быстрее, чем чтение 512 байт за две. Однако, если размер логического блока слишком велик, полезный объем памяти может уменьшиться, это будет показано в главе 5. Для простоты термин «блок» в этой книге будет использоваться для обозначения логического блока, при этом подразумевается логический блок размером 1 Кбайт, кроме специально оговоренных случаев.
 Рисунок 2.3. Формат файловой системы
Рисунок 2.3. Формат файловой системы
Файловая система имеет следующую структуру (Рисунок 2.3).
• Блок загрузки располагается в начале пространства, отведенного под файловую систему, обычно в первом секторе, и содержит программу начальной загрузки, которая считывается в машину при загрузке или инициализации операционной системы. Хотя для запуска системы требуется только один блок загрузки, каждая файловая система имеет свой (пусть даже пустой) блок загрузки.
• Суперблок описывает состояние файловой системы — какого она размера, сколько файлов может в ней храниться, где располагается свободное пространство, доступное для файловой системы, и другая информация.
• Список индексов в файловой системе располагается вслед за суперблоком. Администраторы указывают размер списка индексов при генерации файловой системы. Ядро операционной системы обращается к индексам, используя указатели в списке индексов. Один из индексов является корневым индексом файловой системы: это индекс, по которому осуществляется доступ к структуре каталогов файловой системы после выполнения системной операции mount (монтировать) (раздел 5.14).
• Информационные блоки располагаются сразу после списка индексов и содержат данные файлов и управляющие данные. Отдельно взятый информационный блок может принадлежать одному и только одному файлу в файловой системе.
open("/fs2/mjb/rje/sourcefile", 1);
ядро системы возвращает индекс для файла «/fs2/mjb/rje/sourcefile». Если процесс создает новый файл, ядро присваивает этому файлу неиспользуемый индекс. Индексы хранятся в файловой системе (и это мы еще увидим), однако при обработке файлов ядро заносит их в таблицу индексов в оперативной памяти.
Ядро поддерживает еще две информационные структуры, таблицу файлов и пользовательскую таблицу дескрипторов файла. Таблица файлов выступает глобальной структурой ядра, а пользовательская таблица дескрипторов файла выделяется под процесс. Если процесс открывает или создает файл, ядро выделяет в каждой таблице элемент, корреспондирующий с индексом файла. Элементы в этих трех структурах — в пользовательской таблице дескрипторов файла, в таблице файлов и в таблице индексов — хранят информацию о состоянии файла и о доступе пользователей к нему. В таблице файлов хранится смещение в байтах от начала файла до того места, откуда начнет выполняться следующая команда пользователя read или write, а также информация о правах доступа к открываемому процессу. Таблица дескрипторов файла идентифицирует все открытые для процесса файлы. На Рисунке 2.2 показаны эти таблицы и связи между ними. В системных операциях open (открыть) и creat (создать) ядро возвращает дескриптор файла, которому соответствует указатель в таблице дескрипторов файла. При выполнении операций read (читать) и write (писать) ядро использует дескриптор файла для входа в таблицу дескрипторов и, следуя указателям на таблицу файлов и на таблицу индексов, находит информацию в файле. Более подробно эти информационные структуры рассматриваются в главах 4 и 5. Сейчас достаточно сказать, что использование этих таблиц обеспечивает различную степень разделения доступа к файлу.
Обычные файлы и каталоги хранятся в системе UNIX на устройствах ввода-вывода блоками, таких как магнитные ленты или диски. Поскольку существует некоторое различие во времени доступа к этим устройствам, при установке системы UNIX на лентах размещают файловые системы. С годами бездисковые автоматизированные рабочие места станут общим случаем, и файлы будут располагаться в удаленной системе, доступ к которой будет осуществляться через сеть (см. главу 13). Для простоты, тем не менее, в последующем тексте подразумевается использование дисков. В системе может быть несколько физических дисков, на каждом из которых может размещаться одна и более файловых систем. Разбивка диска на несколько файловых систем облегчает администратору управление хранимыми данными. На логическом уровне ядро имеет дело с файловыми системами, а не с дисками, при этом каждая система трактуется как логическое устройство, идентифицируемое номером. Преобразование адресов логического устройства (файловой системы) в адреса физического устройства (диска) и обратно выполняется дисковым драйвером. Термин «устройство» в этой книге используется для обозначения логического устройства, кроме специально оговоренных случаев.
Файловая система состоит из последовательности логических блоков длиной 512, 1024, 2048 или другого числа байт, кратного 512, в зависимости от реализации системы. Размер логического блока внутри одной файловой системы постоянен, но может варьироваться в разных файловых системах в данной конфигурации. Использование логических блоков большого размера увеличивает скорость передачи данных между диском и памятью, поскольку ядро сможет передать больше информации за одну дисковую операцию, и сокращает количество продолжительных операций. Например, чтение 1 Кбайта с диска за одну операцию осуществляется быстрее, чем чтение 512 байт за две. Однако, если размер логического блока слишком велик, полезный объем памяти может уменьшиться, это будет показано в главе 5. Для простоты термин «блок» в этой книге будет использоваться для обозначения логического блока, при этом подразумевается логический блок размером 1 Кбайт, кроме специально оговоренных случаев.
Файловая система имеет следующую структуру (Рисунок 2.3).
• Блок загрузки располагается в начале пространства, отведенного под файловую систему, обычно в первом секторе, и содержит программу начальной загрузки, которая считывается в машину при загрузке или инициализации операционной системы. Хотя для запуска системы требуется только один блок загрузки, каждая файловая система имеет свой (пусть даже пустой) блок загрузки.
• Суперблок описывает состояние файловой системы — какого она размера, сколько файлов может в ней храниться, где располагается свободное пространство, доступное для файловой системы, и другая информация.
• Список индексов в файловой системе располагается вслед за суперблоком. Администраторы указывают размер списка индексов при генерации файловой системы. Ядро операционной системы обращается к индексам, используя указатели в списке индексов. Один из индексов является корневым индексом файловой системы: это индекс, по которому осуществляется доступ к структуре каталогов файловой системы после выполнения системной операции mount (монтировать) (раздел 5.14).
• Информационные блоки располагаются сразу после списка индексов и содержат данные файлов и управляющие данные. Отдельно взятый информационный блок может принадлежать одному и только одному файлу в файловой системе.
2.2.2 Процессы
В этом разделе мы рассмотрим более подробно подсистему управления процессами. Даются разъяснения по поводу структуры процесса и некоторых информационных структур, используемых при распределении памяти под процессы. Затем дается предварительный обзор диаграммы состояния процессов и затрагиваются различные вопросы, связанные с переходами из одного состояния в другое.
Процессом называется последовательность операций при выполнении программы, которые представляют собой наборы байтов, интерпретируемые центральным процессором как машинные инструкции (т. н. «текст»), данные и стековые структуры. Создается впечатление, что одновременно выполняется множество процессов, поскольку их выполнение планируется ядром, и, кроме того, несколько процессов могут быть экземплярами одной программы. Выполнение процесса заключается в точном следовании набору инструкций, который является замкнутым и не передает управление набору инструкций другого процесса; он считывает и записывает информацию в раздел данных и в стек, но ему недоступны данные и стеки других процессов. Одни процессы взаимодействуют с другими процессами и с остальным миром посредством обращений к операционной системе.
С практической точки зрения процесс в системе UNIX является объектом, создаваемым в результате выполнения системной операции fork. Каждый процесс, за исключением нулевого, порождается в результате запуска другим процессом операции fork. Процесс, запустивший операцию fork, называется родительским, а вновь созданный процесс — порожденным. Каждый процесс имеет одного родителя, но может породить много процессов. Ядро системы идентифицирует каждый процесс по его номеру, который называется идентификатором процесса (PID). Нулевой процесс является особенным процессом, который создается «вручную» в результате загрузки системы; после порождения нового процесса (процесс 1) нулевой процесс становится процессом подкачки. Процесс 1, известный под именем init, является предком любого другого процесса в системе и связан с каждым процессом особым образом, описываемым в главе 7.
Пользователь, транслируя исходный текст программы, создает исполняемый файл, который состоит из нескольких частей:
• набора «заголовков», описывающих атрибуты файла,
• текста программы,
• представления на машинном языке данных, имеющих начальные значения при запуске программы на выполнение, и указания на то, сколько пространства памяти ядро системы выделит под неинициализированные данные, так называемые bss [6](ядро устанавливает их в 0 в момент запуска),
• других секций, таких как информация символических таблиц.
Для программы, приведенной на Рисунке 1.3, текст исполняемого файла представляет собой сгенерированный код для функций main и copy, к определенным данным относится переменная version (вставленная в программу для того, чтобы в последней имелись некоторые определенные данные), а к неопределенным — массив buffer. Компилятор с языка Си для системы версии V создает отдельно текстовую секцию по умолчанию, но не исключается возможность включения инструкций программы и в секцию данных, как в предыдущих версиях системы.
Процессом называется последовательность операций при выполнении программы, которые представляют собой наборы байтов, интерпретируемые центральным процессором как машинные инструкции (т. н. «текст»), данные и стековые структуры. Создается впечатление, что одновременно выполняется множество процессов, поскольку их выполнение планируется ядром, и, кроме того, несколько процессов могут быть экземплярами одной программы. Выполнение процесса заключается в точном следовании набору инструкций, который является замкнутым и не передает управление набору инструкций другого процесса; он считывает и записывает информацию в раздел данных и в стек, но ему недоступны данные и стеки других процессов. Одни процессы взаимодействуют с другими процессами и с остальным миром посредством обращений к операционной системе.
С практической точки зрения процесс в системе UNIX является объектом, создаваемым в результате выполнения системной операции fork. Каждый процесс, за исключением нулевого, порождается в результате запуска другим процессом операции fork. Процесс, запустивший операцию fork, называется родительским, а вновь созданный процесс — порожденным. Каждый процесс имеет одного родителя, но может породить много процессов. Ядро системы идентифицирует каждый процесс по его номеру, который называется идентификатором процесса (PID). Нулевой процесс является особенным процессом, который создается «вручную» в результате загрузки системы; после порождения нового процесса (процесс 1) нулевой процесс становится процессом подкачки. Процесс 1, известный под именем init, является предком любого другого процесса в системе и связан с каждым процессом особым образом, описываемым в главе 7.
Пользователь, транслируя исходный текст программы, создает исполняемый файл, который состоит из нескольких частей:
• набора «заголовков», описывающих атрибуты файла,
• текста программы,
• представления на машинном языке данных, имеющих начальные значения при запуске программы на выполнение, и указания на то, сколько пространства памяти ядро системы выделит под неинициализированные данные, так называемые bss [6](ядро устанавливает их в 0 в момент запуска),
• других секций, таких как информация символических таблиц.
Для программы, приведенной на Рисунке 1.3, текст исполняемого файла представляет собой сгенерированный код для функций main и copy, к определенным данным относится переменная version (вставленная в программу для того, чтобы в последней имелись некоторые определенные данные), а к неопределенным — массив buffer. Компилятор с языка Си для системы версии V создает отдельно текстовую секцию по умолчанию, но не исключается возможность включения инструкций программы и в секцию данных, как в предыдущих версиях системы.