Страница:
Поскольку в указанном поле в начальных записях таблицы может храниться отрицательное или нулевое значение, программа обработки прерываний должна найти в таблице первую запись с положительным значением поля и уменьшить его. Пусть, например, функции a соответствует "время до запуска", равное -2 (Рисунок 8.10), то есть перед тем, как функция a была выбрана на выполнение, система получила 2 прерывания по таймеру. При условии, что функция b 2 тика назад уже была в таблице, ядро пропускает запись, соответствующую функции a, и уменьшает значение поля "время до запуска" для функции b.
8.3.3 Построение профиля
8.3.4 Учет и статистика
8.3.5 Поддержание времени в системе
8.4 ВЫВОДЫ
8.5 УПРАЖНЕНИЯ
ГЛАВА 9. АЛГОРИТМЫ УПРАВЛЕНИЯ ПАМЯТЬЮ
9.1 СВОПИНГ
9.1.1 Управление пространством на устройстве выгрузки
8.3.3 Построение профиля
Построение профиля ядра включает в себя измерение продолжительности выполнения системы в режиме задачи против режима ядра, а также продолжительности выполнения отдельных процедур ядра. Драйвер параметров ядра следит за относительной эффективностью работы модулей ядра, замеряя параметры работы системы в момент прерывания по таймеру. Драйвер параметров имеет список адресов ядра (главным образом, функций ядра); эти адреса ранее были загружены процессом путем обращения к драйверу параметров. Если построение профиля ядра возможно, программа обработки прерывания по таймеру запускает подпрограмму обработки прерываний, принадлежащую драйверу параметров, которая определяет, в каком из режимов — ядра или задачи — работал процессор в момент прерывания. Если процессор работал в режиме задачи, система построения профиля увеличивает значение параметра, описывающего продолжительность выполнения в режиме задачи, если же процессор работал в режиме ядра, система увеличивает значение внутреннего счетчика, соответствующего счетчику команд. Пользовательские процессы могут обращаться к драйверу параметров, чтобы получить значения параметров ядра и различную статистическую информацию.
 Рисунок 8.11. Адреса некоторых алгоритмов ядра
Рисунок 8.11. Адреса некоторых алгоритмов ядра
На Рисунке 8.11 приведены гипотетические адреса некоторых процедур ядра. Пусть в результате 10 измерений, проведенных в моменты поступления прерываний по таймеру, были получены следующие значения счетчика команд: 110, 330, 145, адрес в пространстве задачи, 125, 440, 130, 320, адрес в пространстве задачи и 104. Ядро сохранит при этом те значения, которые показаны на рисунке. Анализ этих значений показывает, что система провела 20 % своего времени в режиме задачи (user) и 50 % времени потратила на выполнение алгоритма bread в режиме ядра.
Если измерение параметров ядра выполняется в течение длительного периода времени, результаты измерений приближаются к истинной картине использования системных ресурсов. Тем не менее, описываемый механизм не учитывает время, потраченное на обработку прерываний по таймеру и выполнение процедур, блокирующих поступление прерываний данного типа, поскольку таймер не может прерывать выполнение критических отрезков программ и, таким образом, не может в это время обращаться к подпрограмме обработки прерываний драйвера параметров. В этом недостаток описываемого механизма, ибо критические отрезки программ ядра чаще всего наиболее важны для измерений. Следовательно, результаты измерения параметров ядра содержат определенную долю приблизительности. Уайнбергер [Weinberger 84] описал механизм включения счетчиков в главных блоках программы, таких как "if-then" и "else", с целью повышения точности измерения частоты их выполнения. Однако, данный механизм увеличивает время счета программ на 50-200 %, поэтому его использование в качестве постоянного механизма измерения параметров ядра нельзя признать рациональным.
На пользовательском уровне для измерения параметров выполнения процессов можно использовать системную функцию profil:
profil(buff, bufsize, offset, scale);
где buff — адрес массива в пространстве задачи, bufsize — размер массива, offset — виртуальный адрес подпрограммы пользователя (обычно, первой по счету), scale — способ отображения виртуальных адресов задачи на адрес массива. Ядро трактует аргумент "scale" как двоичную дробь с фиксированной точкой слева. Так, например, значение аргумента в шестнадцатиричной системе счисления, равное 0xffff, соответствует однозначному отображению счетчика команд на адреса массива, значение, равное 0x7fff, соответствует размещению в одном слове массива buff двух адресов программы, 0x3fff — четырех адресов программы и т. д. Ядро хранит параметры, передаваемые при вызове системной функции, в пространстве процесса. Если таймер прерывает выполнение процесса тогда, когда он находится в режиме задачи, программа обработки прерываний проверяет значение счетчика команд в момент прерывания, сравнивает его со значением аргумента offset и увеличивает содержимое ячейки памяти, адрес которой является функцией от bufsize и scale.
Рассмотрим в качестве примера программу, приведенную на Рисунке 8.12, измеряющую продолжительность выполнения функций f и g. Сначала процесс, используя системную функцию signal, делает указание при получении сигнала о прерывании вызывать функцию theend, затем он вычисляет диапазон адресов программы, в пределах которых будет производиться измерение продолжительности (начиная с адреса функции main и кончая адресом функции theend), и, наконец, запускает функцию profil, сообщая ядру о том, что он собирается начать измерение. В результате выполнения программы в течение 10 секунд на несильно загруженной машине AT&T 3B20 были получены данные, представленные на Рисунке 8.13. Адрес функции f превышает адрес начала профилирования на 204 байта; поскольку текст функции f имеет размер 12 байт, а размер целого числа в машине AT&T 3B20 равен 4 байтам, адреса функции f отображаются на элементы массива buf с номерами 51, 52 и 53. По такому же принципу адреса функции g отображаются на элементы buf c номерами 54, 55 и 56. Элементы buf с номерами 46, 48 и 49 предназначены для адресов, принадлежащих циклу функции main. В обычном случае диапазон адресов, в пределах которого выполняется измерение параметров, определяется в результате обращения к таблице идентификаторов для данной программы, где указываются адреса программных секций. Пользователи сторонятся функции profil из-за того, что она кажется им слишком сложной; вместо нее они используют при компиляции программ на языке Си параметр, сообщающий компилятору о необходимости сгенерировать код, следящий за ходом выполнения процессов.
#include ‹signal.h›
int buffer[4096];
main() {
int offset, endof, scale, eff, gee, text;
extern theend(), f(), g();
signal(SIGINT, theend);
endof = (int) theend;
offset = (int) main; /* вычисляется количество слов в тексте программы */
text = (endof - offset + sizeof(int) - 1) / sizeof(int);
scale = Oxffff;
printf("смещение до начала %d до конца %d длина текста %d\n", offset, endof, text);
eff = (int) f;
gee = (int) g;
printf("f %d g %d fdiff %d gdiff %d\n", eff ,gee, eff - offset, gee - offset);
profil(buffer, sizeof(int) * text, offset, scale);
for (;;) {
f(); g();
}
}
f() {}
g() {}
theend() {
int i;
for (i = 0; i ‹ 4096; i++) if (buffer[i]) printf("buf[%d] = %d\n", i, buffer[i]);
exit();
}
Рисунок 8.12. Программа, использующая системную функцию profil
смещение до начала 212 до конца 440 длина текста 57
f 416 g 428 fdiff 204 gdiff 216
buf[46] = 50
buf[48] = 8585216
buf[49] = 151
buf[51] = 12189799
buf[53] = 65
buf[54] = 10682455
buf[56] = 67
Рисунок 8.13. Пример результатов выполнения программы, использующей системную функцию profil
На Рисунке 8.11 приведены гипотетические адреса некоторых процедур ядра. Пусть в результате 10 измерений, проведенных в моменты поступления прерываний по таймеру, были получены следующие значения счетчика команд: 110, 330, 145, адрес в пространстве задачи, 125, 440, 130, 320, адрес в пространстве задачи и 104. Ядро сохранит при этом те значения, которые показаны на рисунке. Анализ этих значений показывает, что система провела 20 % своего времени в режиме задачи (user) и 50 % времени потратила на выполнение алгоритма bread в режиме ядра.
Если измерение параметров ядра выполняется в течение длительного периода времени, результаты измерений приближаются к истинной картине использования системных ресурсов. Тем не менее, описываемый механизм не учитывает время, потраченное на обработку прерываний по таймеру и выполнение процедур, блокирующих поступление прерываний данного типа, поскольку таймер не может прерывать выполнение критических отрезков программ и, таким образом, не может в это время обращаться к подпрограмме обработки прерываний драйвера параметров. В этом недостаток описываемого механизма, ибо критические отрезки программ ядра чаще всего наиболее важны для измерений. Следовательно, результаты измерения параметров ядра содержат определенную долю приблизительности. Уайнбергер [Weinberger 84] описал механизм включения счетчиков в главных блоках программы, таких как "if-then" и "else", с целью повышения точности измерения частоты их выполнения. Однако, данный механизм увеличивает время счета программ на 50-200 %, поэтому его использование в качестве постоянного механизма измерения параметров ядра нельзя признать рациональным.
На пользовательском уровне для измерения параметров выполнения процессов можно использовать системную функцию profil:
profil(buff, bufsize, offset, scale);
где buff — адрес массива в пространстве задачи, bufsize — размер массива, offset — виртуальный адрес подпрограммы пользователя (обычно, первой по счету), scale — способ отображения виртуальных адресов задачи на адрес массива. Ядро трактует аргумент "scale" как двоичную дробь с фиксированной точкой слева. Так, например, значение аргумента в шестнадцатиричной системе счисления, равное 0xffff, соответствует однозначному отображению счетчика команд на адреса массива, значение, равное 0x7fff, соответствует размещению в одном слове массива buff двух адресов программы, 0x3fff — четырех адресов программы и т. д. Ядро хранит параметры, передаваемые при вызове системной функции, в пространстве процесса. Если таймер прерывает выполнение процесса тогда, когда он находится в режиме задачи, программа обработки прерываний проверяет значение счетчика команд в момент прерывания, сравнивает его со значением аргумента offset и увеличивает содержимое ячейки памяти, адрес которой является функцией от bufsize и scale.
Рассмотрим в качестве примера программу, приведенную на Рисунке 8.12, измеряющую продолжительность выполнения функций f и g. Сначала процесс, используя системную функцию signal, делает указание при получении сигнала о прерывании вызывать функцию theend, затем он вычисляет диапазон адресов программы, в пределах которых будет производиться измерение продолжительности (начиная с адреса функции main и кончая адресом функции theend), и, наконец, запускает функцию profil, сообщая ядру о том, что он собирается начать измерение. В результате выполнения программы в течение 10 секунд на несильно загруженной машине AT&T 3B20 были получены данные, представленные на Рисунке 8.13. Адрес функции f превышает адрес начала профилирования на 204 байта; поскольку текст функции f имеет размер 12 байт, а размер целого числа в машине AT&T 3B20 равен 4 байтам, адреса функции f отображаются на элементы массива buf с номерами 51, 52 и 53. По такому же принципу адреса функции g отображаются на элементы buf c номерами 54, 55 и 56. Элементы buf с номерами 46, 48 и 49 предназначены для адресов, принадлежащих циклу функции main. В обычном случае диапазон адресов, в пределах которого выполняется измерение параметров, определяется в результате обращения к таблице идентификаторов для данной программы, где указываются адреса программных секций. Пользователи сторонятся функции profil из-за того, что она кажется им слишком сложной; вместо нее они используют при компиляции программ на языке Си параметр, сообщающий компилятору о необходимости сгенерировать код, следящий за ходом выполнения процессов.
#include ‹signal.h›
int buffer[4096];
main() {
int offset, endof, scale, eff, gee, text;
extern theend(), f(), g();
signal(SIGINT, theend);
endof = (int) theend;
offset = (int) main; /* вычисляется количество слов в тексте программы */
text = (endof - offset + sizeof(int) - 1) / sizeof(int);
scale = Oxffff;
printf("смещение до начала %d до конца %d длина текста %d\n", offset, endof, text);
eff = (int) f;
gee = (int) g;
printf("f %d g %d fdiff %d gdiff %d\n", eff ,gee, eff - offset, gee - offset);
profil(buffer, sizeof(int) * text, offset, scale);
for (;;) {
f(); g();
}
}
f() {}
g() {}
theend() {
int i;
for (i = 0; i ‹ 4096; i++) if (buffer[i]) printf("buf[%d] = %d\n", i, buffer[i]);
exit();
}
Рисунок 8.12. Программа, использующая системную функцию profil
смещение до начала 212 до конца 440 длина текста 57
f 416 g 428 fdiff 204 gdiff 216
buf[46] = 50
buf[48] = 8585216
buf[49] = 151
buf[51] = 12189799
buf[53] = 65
buf[54] = 10682455
buf[56] = 67
Рисунок 8.13. Пример результатов выполнения программы, использующей системную функцию profil
8.3.4 Учет и статистика
В момент поступления прерывания по таймеру система может выполняться в режиме ядра или задачи, а также находиться в состоянии простоя (бездействия). Состояние простоя означает, что все процессы приостановлены в ожидании наступления события. Для каждого состояния процессора ядро имеет внутренние счетчики, устанавливаемые при каждом прерывании по таймеру. Позже пользовательские процессы могут проанализировать накопленную ядром статистическую информацию.
В пространстве каждого процесса имеются два поля для записи продолжительности времени, проведенного процессом в режиме ядра и задачи. В ходе обработки прерываний по таймеру ядро корректирует значение поля, соответствующего текущему режиму выполнения процесса. Процессы-родители собирают статистику о своих потомках при выполнении функции wait, беря за основу информацию, поступающую от завершающих свое выполнение потомков.
В пространстве каждого процесса имеется также одно поле для ведения учета использования памяти. В ходе обработки прерывания по таймеру ядро вычисляет общий объем памяти, занимаемый текущим процессом, исходя из размера частных областей процесса и его долевого участия в использовании разделяемых областей памяти. Если, например, процесс использует области данных и стека размером 25 и 40 Кбайт, соответственно, и разделяет с четырьмя другими процессами одну область команд размером 50 Кбайт, ядро назначает процессу 75 Кбайт памяти (50К/5 + 25К + 40К). В системе с замещением страниц ядро вычисляет объем используемой памяти путем подсчета числа используемых в каждой области страниц. Таким образом, если прерываемый процесс имеет две частные области и еще одну область разделяет с другим процессом, ядро назначает ему столько страниц памяти, сколько содержится в этих частных областях, плюс половину страниц, принадлежащих разделяемой области. Вся указанная информация отражается в учетной записи при завершении процесса и может быть использована для расчетов с заказчиками машинного времени.
В пространстве каждого процесса имеются два поля для записи продолжительности времени, проведенного процессом в режиме ядра и задачи. В ходе обработки прерываний по таймеру ядро корректирует значение поля, соответствующего текущему режиму выполнения процесса. Процессы-родители собирают статистику о своих потомках при выполнении функции wait, беря за основу информацию, поступающую от завершающих свое выполнение потомков.
В пространстве каждого процесса имеется также одно поле для ведения учета использования памяти. В ходе обработки прерывания по таймеру ядро вычисляет общий объем памяти, занимаемый текущим процессом, исходя из размера частных областей процесса и его долевого участия в использовании разделяемых областей памяти. Если, например, процесс использует области данных и стека размером 25 и 40 Кбайт, соответственно, и разделяет с четырьмя другими процессами одну область команд размером 50 Кбайт, ядро назначает процессу 75 Кбайт памяти (50К/5 + 25К + 40К). В системе с замещением страниц ядро вычисляет объем используемой памяти путем подсчета числа используемых в каждой области страниц. Таким образом, если прерываемый процесс имеет две частные области и еще одну область разделяет с другим процессом, ядро назначает ему столько страниц памяти, сколько содержится в этих частных областях, плюс половину страниц, принадлежащих разделяемой области. Вся указанная информация отражается в учетной записи при завершении процесса и может быть использована для расчетов с заказчиками машинного времени.
8.3.5 Поддержание времени в системе
Ядро увеличивает показание системных часов при каждом прерывании по таймеру, измеряя время в таймерных тиках от момента загрузки системы. Это значение возвращается процессу через системную функцию time и дает возможность определять общее время выполнения процесса. Время первоначального запуска процесса сохраняется ядром в адресном пространстве процесса при исполнении системной функции fork, в момент завершения процесса это значение вычитается из текущего времени, результат вычитания и составляет реальное время выполнения процесса. В другой переменной таймера, устанавливаемой с помощью системной функции stime и корректируемой раз в секунду, хранится календарное время.
8.4 ВЫВОДЫ
В настоящей главе был описан основной алгоритм диспетчеризации процессов в системе UNIX. С каждым процессом в системе связывается приоритет планирования, значение которого появляется в момент перехода процесса в состояние приостанова и периодически корректируется программой обработки прерываний по таймеру. Приоритет, присваиваемый процессу в момент перехода в состояние приостанова, имеет значение, зависящее от того, какой из алгоритмов ядра исполнялся процессом в этот момент. Значение приоритета, присваиваемое процессу во время выполнения программой обработки прерываний по таймеру (или в тот момент, когда процесс возвращается из режима ядра в режим задачи), зависит от того, сколько времени процесс занимал ЦП: процесс получает низкий приоритет, если он обращался к ЦП, и высокий — в противном случае. Системная функция nice дает процессу возможность влиять на собственный приоритет путем добавления параметра, участвующего в пересчете приоритета. В главе были также рассмотрены системные функции, связанные с временем выполнения системы и протекающих в ней процессов: с установкой и получением системного времени, получением времени выполнения процессов и установкой сигналов "будильника". Кроме того, описаны функции программы обработки прерываний по таймеру, которая следит за временем в системе, управляет таблицей ответных сигналов, собирает статистику, а также подготавливает запуск планировщика процессов, программы подкачки и "сборщика" страниц. Программа подкачки и "сборщик" страниц являются объектами рассмотрения в следующей главе.
8.5 УПРАЖНЕНИЯ
1. При переводе процессов в состояние приостанова ядро назначает процессу, ожидающему снятия блокировки с индекса, более высокий приоритет по сравнению с процессом, ожидающим освобождения буфера. Точно так же, процессы, ожидающие ввода с терминала, получают более высокий приоритет по сравнению с процессами, ожидающими возможности производить вывод на терминал. Объясните причины такого поведения ядра.
*2. В алгоритме обработки прерываний по таймеру предусмотрен пересчет приоритетов и перезапуск процессов на выполнение с интервалом в 1 секунду. Придумайте алгоритм, в котором интервал перезапуска динамически меняется в зависимости от степени загрузки системы. Перевесит ли выигрыш усилия по усложнению алгоритма?
3. В шестой редакции системы UNIX для расчета продолжительности ИЦП текущим процессом используется следующая формула:
decay(ИЦП) = max (пороговый приоритет, ИЦП-10);
а в седьмой редакции:
decay(ИЦП) =.8 * ИЦП;
Приоритет процесса в обеих редакциях вычисляется по формуле:
приоритет = ИЦП/16 + (базовый уровень приоритета);
Повторите пример на Рисунке 8.4, используя приведенные формулы.
4.Проделайте еще раз пример на Рисунке 8.4 с семью процессами вместо трех, а затем измените частоту прерываний по таймеру с 60 на 100 прерываний в секунду. Прокомментируйте результат.
5.Разработайте схему, в которой система накладывает ограничение на продолжительность выполнения процесса, при превышении которого процесс завершается. Каким образом пользователь должен отличать такой процесс от процессов, для которых не должны существовать подобные ограничения? Каким образом должна работать схема, если единственным условием является ее запуск из shell'а?
6. Когда процесс выполняет системную функцию wait и обнаруживает прекратившего существование потомка, ядро приплюсовывает к его ИЦП значение поля ИЦП потомка. Чем объясняется такое "наказание" процесса-родителя?
7. Команда nice запускает последующую команду с передачей ей указанного значения, например:
nice 6 nroff -mm big_memo › output
Напишите на языке Си программу, реализующую команду nice.
8. Проследите на примере Рисунка 8.4, каким образом будет осуществляться диспетчеризация процессов в том случае, если значение, передаваемое функцией nice для процесса A, равно 5 или -5.
9. Проведите эксперимент с системной функцией renice x y, где x — код идентификации процесса (активного), а y — новое значение nice для указанного процесса.
10. Вернемся к примеру, приведенному на Рисунке 8.6. Предположим, что группе, в которую входит процесс A, выделяется 33 % процессорного времени, а группе, в которую входит процесс B, — 66 % процессорного времени. В какой последовательности будут исполняться процессы? Обобщите алгоритм вычисления приоритетов таким образом, чтобы значение группового ИЦП усреднялось.
11. Выполните команду date. Команда без аргументов выводит текущую дату:
указав аргумент, например:
date mmddhhmmyy
(супер)пользователь может установить текущую дату в системе (соответственно, месяц, число, часы, минуты и год). Так,
date 0911205084
устанавливает в качестве текущего времени 11 сентября 1984 года 8:50 пополудни.
12. В программах можно использовать функцию пользовательского уровня sleep:
sleep(seconds);
с помощью которой выполнение программы приостанавливается на указанное число секунд. Разработайте ее алгоритм, в котором используйте системные функции alarm и pause. Что произойдет, если процесс вызовет функцию alarm раньше функции sleep? Рассмотрите две возможности: 1) действие ранее вызванной функции alarm истекает в то время, когда процесс находится в состоянии приостанова, 2) действие ранее вызванной функции alarm истекает после завершения функции sleep.
*13. Обратимся еще раз к последней проблеме. Ядро может выполнить переключение контекста во время исполнения функции sleep между вызовами alarm и pause. Тогда есть опасность, что процесс получит сигнал alarm до того, как вызовет функцию pause. Что произойдет в этом случае? Как вовремя распознать эту ситуацию?
*2. В алгоритме обработки прерываний по таймеру предусмотрен пересчет приоритетов и перезапуск процессов на выполнение с интервалом в 1 секунду. Придумайте алгоритм, в котором интервал перезапуска динамически меняется в зависимости от степени загрузки системы. Перевесит ли выигрыш усилия по усложнению алгоритма?
3. В шестой редакции системы UNIX для расчета продолжительности ИЦП текущим процессом используется следующая формула:
decay(ИЦП) = max (пороговый приоритет, ИЦП-10);
а в седьмой редакции:
decay(ИЦП) =.8 * ИЦП;
Приоритет процесса в обеих редакциях вычисляется по формуле:
приоритет = ИЦП/16 + (базовый уровень приоритета);
Повторите пример на Рисунке 8.4, используя приведенные формулы.
4.Проделайте еще раз пример на Рисунке 8.4 с семью процессами вместо трех, а затем измените частоту прерываний по таймеру с 60 на 100 прерываний в секунду. Прокомментируйте результат.
5.Разработайте схему, в которой система накладывает ограничение на продолжительность выполнения процесса, при превышении которого процесс завершается. Каким образом пользователь должен отличать такой процесс от процессов, для которых не должны существовать подобные ограничения? Каким образом должна работать схема, если единственным условием является ее запуск из shell'а?
6. Когда процесс выполняет системную функцию wait и обнаруживает прекратившего существование потомка, ядро приплюсовывает к его ИЦП значение поля ИЦП потомка. Чем объясняется такое "наказание" процесса-родителя?
7. Команда nice запускает последующую команду с передачей ей указанного значения, например:
nice 6 nroff -mm big_memo › output
Напишите на языке Си программу, реализующую команду nice.
8. Проследите на примере Рисунка 8.4, каким образом будет осуществляться диспетчеризация процессов в том случае, если значение, передаваемое функцией nice для процесса A, равно 5 или -5.
9. Проведите эксперимент с системной функцией renice x y, где x — код идентификации процесса (активного), а y — новое значение nice для указанного процесса.
10. Вернемся к примеру, приведенному на Рисунке 8.6. Предположим, что группе, в которую входит процесс A, выделяется 33 % процессорного времени, а группе, в которую входит процесс B, — 66 % процессорного времени. В какой последовательности будут исполняться процессы? Обобщите алгоритм вычисления приоритетов таким образом, чтобы значение группового ИЦП усреднялось.
11. Выполните команду date. Команда без аргументов выводит текущую дату:
указав аргумент, например:
date mmddhhmmyy
(супер)пользователь может установить текущую дату в системе (соответственно, месяц, число, часы, минуты и год). Так,
date 0911205084
устанавливает в качестве текущего времени 11 сентября 1984 года 8:50 пополудни.
12. В программах можно использовать функцию пользовательского уровня sleep:
sleep(seconds);
с помощью которой выполнение программы приостанавливается на указанное число секунд. Разработайте ее алгоритм, в котором используйте системные функции alarm и pause. Что произойдет, если процесс вызовет функцию alarm раньше функции sleep? Рассмотрите две возможности: 1) действие ранее вызванной функции alarm истекает в то время, когда процесс находится в состоянии приостанова, 2) действие ранее вызванной функции alarm истекает после завершения функции sleep.
*13. Обратимся еще раз к последней проблеме. Ядро может выполнить переключение контекста во время исполнения функции sleep между вызовами alarm и pause. Тогда есть опасность, что процесс получит сигнал alarm до того, как вызовет функцию pause. Что произойдет в этом случае? Как вовремя распознать эту ситуацию?
ГЛАВА 9. АЛГОРИТМЫ УПРАВЛЕНИЯ ПАМЯТЬЮ
Алгоритм планирования использования процессорного времени, рассмотренный в предыдущей главе, в сильной степени зависит от выбранной стратегии управления памятью. Процесс может выполняться, если он хотя бы частично присутствует в основной памяти; ЦП не может исполнять процесс, полностью выгруженный во внешнюю память. Тем не менее, основная память — чересчур дефицитный ресурс, который зачастую не может вместить все активные процессы в системе. Если, например, в системе имеется основная память объемом 8 Мбайт, то девять процессов размером по 1 Мбайту каждый уже не смогут в ней одновременно помещаться. Какие процессы в таком случае следует размещать в памяти (хотя бы частично), а какие нет, решает подсистема управления памятью, она же управляет участками виртуального адресного пространства процесса, не резидентными в памяти. Она следит за объемом доступного пространства основной памяти и имеет право периодически переписывать процессы на устройство внешней памяти, именуемое устройством выгрузки, освобождая в основной памяти дополнительное место. Позднее ядро может вновь поместить данные с устройства выгрузки в основную память.
В ранних версиях системы UNIX процессы переносились между основной памятью и устройством выгрузки целиком и, за исключением разделяемой области команд, отдельные независимые части процесса не могли быть объектами перемещения. Такая стратегия управления памятью называется свопингом (подкачкой). Такую стратегию имело смысл реализовывать на машине типа PDP-11, где максимальный размер процесса составлял 64 Кбайта. При использовании этой стратегии размер процесса ограничивается объемом физической памяти, доступной в системе. Система BSD (версия 4.0) явилась главным полигоном для применения другой стратегии, стратегии "подкачки по обращению" (demand paging), в соответствии с которой основная память обменивается с внешней не процессами, а страницами памяти; эта стратегия поддерживается и в последних редакциях версии V системы UNIX. Держать в основной памяти весь выполняемый процесс нет необходимости, и ядро загружает в память только отдельные страницы по запросу выполняющегося процесса, ссылающегося на них. Преимущество стратегии подкачки по обращению состоит в том, что благодаря ей отображение виртуального адресного пространства процесса на физическую память машины становится более гибким: допускается превышение размером процесса объема доступной физической памяти и одновременное размещение в основной памяти большего числа процессов. Преимущество стратегии свопинга состоит в простоте реализации и облегчении "надстроечной" части системы. Обе стратегии управления памятью рассматриваются в настоящей главе.
В ранних версиях системы UNIX процессы переносились между основной памятью и устройством выгрузки целиком и, за исключением разделяемой области команд, отдельные независимые части процесса не могли быть объектами перемещения. Такая стратегия управления памятью называется свопингом (подкачкой). Такую стратегию имело смысл реализовывать на машине типа PDP-11, где максимальный размер процесса составлял 64 Кбайта. При использовании этой стратегии размер процесса ограничивается объемом физической памяти, доступной в системе. Система BSD (версия 4.0) явилась главным полигоном для применения другой стратегии, стратегии "подкачки по обращению" (demand paging), в соответствии с которой основная память обменивается с внешней не процессами, а страницами памяти; эта стратегия поддерживается и в последних редакциях версии V системы UNIX. Держать в основной памяти весь выполняемый процесс нет необходимости, и ядро загружает в память только отдельные страницы по запросу выполняющегося процесса, ссылающегося на них. Преимущество стратегии подкачки по обращению состоит в том, что благодаря ей отображение виртуального адресного пространства процесса на физическую память машины становится более гибким: допускается превышение размером процесса объема доступной физической памяти и одновременное размещение в основной памяти большего числа процессов. Преимущество стратегии свопинга состоит в простоте реализации и облегчении "надстроечной" части системы. Обе стратегии управления памятью рассматриваются в настоящей главе.
9.1 СВОПИНГ
Описание алгоритма свопинга можно разбить на три части: управление пространством на устройстве выгрузки, выгрузка процессов из основной памяти и подкачка процессов в основную память.
9.1.1 Управление пространством на устройстве выгрузки
Устройство выгрузки является устройством блочного типа, которое представляет собой конфигурируемый раздел диска. Тогда как обычно ядро выделяет место для файлов по одному блоку за одну операцию, на устройстве выгрузки пространство выделяется группами смежных блоков. Пространство, выделяемое для файлов, используется статическим образом; поскольку схема назначения пространства под файлы действует в течение длительного периода времени, ее гибкость понимается в смысле сокращения числа случаев фрагментации и, следовательно, объемов неиспользуемого пространства в файловой системе. Выделение пространства на устройстве выгрузки, напротив, является временным, в сильной степени зависящим от механизма диспетчеризации процессов. Процесс, размещаемый на устройстве выгрузки, в конечном итоге вернется в основную память, освобождая место на внешнем устройстве. Поскольку время является решающим фактором и с учетом того, что ввод-вывод данных за одну мультиблочную операцию происходит быстрее, чем за несколько одноблочных операций, ядро выделяет на устройстве выгрузки непрерывное пространство, не беря во внимание возможную фрагментацию.
Так как схема выделения пространства на устройстве выгрузки отличается от схемы, используемой для файловых систем, структуры данных, регистрирующие свободное пространство, должны также отличаться. Пространство, свободное в файловых системах, описывается с помощью связного списка свободных блоков, доступ к которому осуществляется через суперблок файловой системы, информация о свободном пространстве на устройстве выгрузки собирается в таблицу, именуемую "карта памяти устройства". Карты памяти, помимо устройства выгрузки, используются и другими системными ресурсами (например, драйверами некоторых устройств), они дают возможность распределять память устройства (в виде смежных блоков) по методу первого подходящего.
Каждая строка в карте памяти состоит из адреса распределяемого ресурса и количества доступных единиц ресурса; ядро интерпретирует элементы строки в соответствии с типом карты. В самом начале карта памяти состоит из одной строки, содержащей адрес и общее количество ресурсов. Если карта описывает распределение памяти на устройстве выгрузки, ядро трактует каждую единицу ресурса как группу дисковых блоков, а адрес — как смещение в блоках от начала области выгрузки. Первоначальный вид карты памяти для устройства выгрузки, состоящего из 10000 блоков с начальным адресом, равным 1, показан на Рисунке 9.1. Выделяя и освобождая ресурсы, ядро корректирует карту памяти, заботясь о том, чтобы в ней постоянно содержалась точная информация о свободных ресурсах в системе.
На Рисунке 9.2 представлен алгоритм выделения пространства с помощью карт памяти (malloc). Ядро просматривает карту в поисках первой строки, содержащей количество единиц ресурса, достаточное для удовлетворения запроса. Если запрос покрывает все количество единиц, содержащееся в строке, ядро удаляет строку и уплотняет карту (то есть в карте становится на одну строку меньше). В противном случае ядро переустанавливает адрес и число оставшихся единиц в строке в соответствии с числом единиц, выделенных по запросу. На Рисунке 9.3 показано, как меняется вид карты памяти для устройства выгрузки после выделения 100, 50 и вновь 100 единиц ресурса. В конечном итоге карта памяти принимает вид, показывающий, что первые 250 единиц ресурса выделены по запросам, и что теперь остались свободными 9750 единиц, начиная с адреса 251.
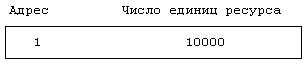 Рисунок 9.1. Первоначальный вид карты памяти для устройства выгрузки
Рисунок 9.1. Первоначальный вид карты памяти для устройства выгрузки
алгоритм malloc /* алгоритм выделения пространства с использованием карты памяти */
входная информация:
(1) адрес /* указывает на тип используемой карты */
(2) требуемое число единиц ресурса
выходная информация:
адрес — в случае успешного завершения
0 — в противном случае
{
for (каждой строки карты) {
if (требуемое число единиц ресурса располагается в строке карты) {
if (требуемое число == числу единиц в строке)
удалить строку из карты;
else отрегулировать стартовый адрес в строке;
return (первоначальный адрес строки);
}
}
return (0);
}
Рисунок 9.2. Алгоритм выделения пространства с помощью карт памяти
Освобождая ресурсы, ядро ищет для них соответствующее место в карте по адресу. При этом возможны три случая:
1. Освободившиеся ресурсы полностью закрывают пробел в карте памяти. Другими словами, они имеют смежные адреса с адресами ресурсов из строк, непосредственно предшествующей и следующей за данной. В этом случае ядро объединяет вновь освободившиеся ресурсы с ресурсами из указанных строк в одну строку карты памяти.
Так как схема выделения пространства на устройстве выгрузки отличается от схемы, используемой для файловых систем, структуры данных, регистрирующие свободное пространство, должны также отличаться. Пространство, свободное в файловых системах, описывается с помощью связного списка свободных блоков, доступ к которому осуществляется через суперблок файловой системы, информация о свободном пространстве на устройстве выгрузки собирается в таблицу, именуемую "карта памяти устройства". Карты памяти, помимо устройства выгрузки, используются и другими системными ресурсами (например, драйверами некоторых устройств), они дают возможность распределять память устройства (в виде смежных блоков) по методу первого подходящего.
Каждая строка в карте памяти состоит из адреса распределяемого ресурса и количества доступных единиц ресурса; ядро интерпретирует элементы строки в соответствии с типом карты. В самом начале карта памяти состоит из одной строки, содержащей адрес и общее количество ресурсов. Если карта описывает распределение памяти на устройстве выгрузки, ядро трактует каждую единицу ресурса как группу дисковых блоков, а адрес — как смещение в блоках от начала области выгрузки. Первоначальный вид карты памяти для устройства выгрузки, состоящего из 10000 блоков с начальным адресом, равным 1, показан на Рисунке 9.1. Выделяя и освобождая ресурсы, ядро корректирует карту памяти, заботясь о том, чтобы в ней постоянно содержалась точная информация о свободных ресурсах в системе.
На Рисунке 9.2 представлен алгоритм выделения пространства с помощью карт памяти (malloc). Ядро просматривает карту в поисках первой строки, содержащей количество единиц ресурса, достаточное для удовлетворения запроса. Если запрос покрывает все количество единиц, содержащееся в строке, ядро удаляет строку и уплотняет карту (то есть в карте становится на одну строку меньше). В противном случае ядро переустанавливает адрес и число оставшихся единиц в строке в соответствии с числом единиц, выделенных по запросу. На Рисунке 9.3 показано, как меняется вид карты памяти для устройства выгрузки после выделения 100, 50 и вновь 100 единиц ресурса. В конечном итоге карта памяти принимает вид, показывающий, что первые 250 единиц ресурса выделены по запросам, и что теперь остались свободными 9750 единиц, начиная с адреса 251.
алгоритм malloc /* алгоритм выделения пространства с использованием карты памяти */
входная информация:
(1) адрес /* указывает на тип используемой карты */
(2) требуемое число единиц ресурса
выходная информация:
адрес — в случае успешного завершения
0 — в противном случае
{
for (каждой строки карты) {
if (требуемое число единиц ресурса располагается в строке карты) {
if (требуемое число == числу единиц в строке)
удалить строку из карты;
else отрегулировать стартовый адрес в строке;
return (первоначальный адрес строки);
}
}
return (0);
}
Рисунок 9.2. Алгоритм выделения пространства с помощью карт памяти
Освобождая ресурсы, ядро ищет для них соответствующее место в карте по адресу. При этом возможны три случая:
1. Освободившиеся ресурсы полностью закрывают пробел в карте памяти. Другими словами, они имеют смежные адреса с адресами ресурсов из строк, непосредственно предшествующей и следующей за данной. В этом случае ядро объединяет вновь освободившиеся ресурсы с ресурсами из указанных строк в одну строку карты памяти.