Страница:
Второй модификацией рассмотренной классической структуры индекса является идея хранения в индексе информации файла (см. [Mullender 84]). Если увеличить размер индекса так, чтобы индекс занимал весь дисковый блок, небольшая часть блока может быть использована для собственно индексных структур, а оставшаяся часть — для хранения конца файла и даже во многих случаях для хранения файла целиком. Основное преимущество такого подхода заключается в том, что необходимо только одно обращение к диску для считывания индекса и всей информации, если файл помещается в индексном блоке.
4.3 КАТАЛОГИ
4.4 ПРЕВРАЩЕНИЕ СОСТАВНОГО ИМЕНИ ФАЙЛА (ПУТИ ПОИСКА) В ИДЕНТИФИКАТОР ИНДЕКСА
4.5 СУПЕРБЛОК
4.6 НАЗНАЧЕНИЕ ИНДЕКСА НОВОМУ ФАЙЛУ
4.7 ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВ
4.3 КАТАЛОГИ
Из главы 1 напомним, что каталоги являются файлами, из которых строится иерархическая структура файловой системы; они играют важную роль в превращении имени файла в номер индекса. Каталог — это файл, содержимым которого является набор записей, состоящих из номера индекса и имени файла, включенного в каталог. Составное имя — это строка символов, завершающаяся пустым символом и разделяемая наклонной чертой («/») на несколько компонент. Каждая компонента, кроме последней, должна быть именем каталога, но последняя компонента может быть именем файла, не являющегося каталогом. В версии V системы UNIX длина каждой компоненты ограничивается 14 символами; таким образом, вместе с 2 байтами, отводимыми на номер индекса, размер записи каталога составляет 16 байт.
Смещение в байтах внутри каталога Номер индекса (2 байта) Имя файла
Рисунок 4.10. Формат каталога /etc
На Рисунке 4.10 показан формат каталога «etc». В каждом каталоге имеются файлы, в качестве имен которых указаны точка и две точки ("." и «..») и номера индексов у которых совпадают с номерами индексов данного каталога и родительского каталога, соответственно. Номер индекса для файла "." в каталоге «/etc» имеет адрес со смещением 0 и значение 83. Номер индекса для файла «..» имеет адрес со смещением 16 от начала каталога и значение 2. Записи в каталоге могут быть пустыми, при этом номер индекса равен 0. Например, запись с адресом 224 в каталоге «/etc» пустая, несмотря на то, что она когда-то содержала точку входа для файла с именем «crash». Программа mkfs инициализирует файловую систему таким образом, что номера индексов для файлов "." и «..» в корневом каталоге совпадают с номером корневого индекса файловой системы.
Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога. Права доступа к каталогу имеют следующий смысл: право чтения дает процессам возможность читать данные из каталога; право записи позволяет процессу создавать новые записи в каталоге или удалять старые (с помощью системных операций creat, mknod, link и unlink), в результате чего изменяется содержимое каталога; право исполнения позволяет процессу производить поиск в каталоге по имени файла (поскольку «исполнять» каталог бессмысленно). На примере Упражнения 4.6 показана разница между чтением и поиском в каталоге.
Смещение в байтах внутри каталога Номер индекса (2 байта) Имя файла
| 0 | 83 | . |
| 16 | 2 | .. |
| 32 | 1798 | init |
| 48 | 1276 | fsck |
| 64 | 85 | clri |
| 80 | 1268 | motd |
| 96 | 1799 | mount |
| 112 | 88 | mknod |
| 128 | 2114 | passwd |
| 144 | 1717 | umount |
| 160 | 1851 | checklist |
| 176 | 92 | fsdbld |
| 192 | 84 | config |
| 208 | 1432 | getty |
| 224 | 0 | crash |
| 240 | 95 | mkfs |
| 256 | 188 | inittab |
Рисунок 4.10. Формат каталога /etc
На Рисунке 4.10 показан формат каталога «etc». В каждом каталоге имеются файлы, в качестве имен которых указаны точка и две точки ("." и «..») и номера индексов у которых совпадают с номерами индексов данного каталога и родительского каталога, соответственно. Номер индекса для файла "." в каталоге «/etc» имеет адрес со смещением 0 и значение 83. Номер индекса для файла «..» имеет адрес со смещением 16 от начала каталога и значение 2. Записи в каталоге могут быть пустыми, при этом номер индекса равен 0. Например, запись с адресом 224 в каталоге «/etc» пустая, несмотря на то, что она когда-то содержала точку входа для файла с именем «crash». Программа mkfs инициализирует файловую систему таким образом, что номера индексов для файлов "." и «..» в корневом каталоге совпадают с номером корневого индекса файловой системы.
Ядро хранит данные в каталоге так же, как оно это делает в файле обычного типа, используя индексную структуру и блоки с уровнями прямой и косвенной адресации. Процессы могут читать данные из каталогов таким же образом, как они читают обычные файлы, однако исключительное право записи в каталог резервируется ядром, благодаря чему обеспечивается правильность структуры каталога. Права доступа к каталогу имеют следующий смысл: право чтения дает процессам возможность читать данные из каталога; право записи позволяет процессу создавать новые записи в каталоге или удалять старые (с помощью системных операций creat, mknod, link и unlink), в результате чего изменяется содержимое каталога; право исполнения позволяет процессу производить поиск в каталоге по имени файла (поскольку «исполнять» каталог бессмысленно). На примере Упражнения 4.6 показана разница между чтением и поиском в каталоге.
4.4 ПРЕВРАЩЕНИЕ СОСТАВНОГО ИМЕНИ ФАЙЛА (ПУТИ ПОИСКА) В ИДЕНТИФИКАТОР ИНДЕКСА
Начальное обращение к файлу производится по его составному имени (имени пути поиска), как в командах open, chdir (изменить каталог) или link. Поскольку внутри системы ядро работает с индексами, а не с именами путей поиска, оно преобразует имена путей поиска в идентификаторы индексов, чтобы производить доступ к файлам. Алгоритм namei производит поэлементный анализ составного имени, ставя в соответствие каждой компоненте имени индекс и каталог и в конце концов возвращая идентификатор индекса для введенного имени пути поиска (Рисунок 4.11).
Из главы 2 напомним, что каждый процесс связан с текущим каталогом (и протекает в его рамках); рабочая область, отведенная под задачу пользователя, содержит указатель на индекс текущего каталога. Текущим каталогом первого из процессов в системе, нулевого процесса, является корневой каталог. Путь к текущему каталогу каждого нового процесса берет начало от текущего каталога процесса, являющегося родительским по отношению к данному (см. раздел 5.10). Процессы изменяют текущий каталог, запрашивая выполнение системной операции chdir (изменить каталог). Все поиски файлов по имени начинаются с текущего каталога процесса, если только имя пути поиска не предваряется наклонной чертой, указывая, что поиск нужно начинать с корневого каталога. В любом случае ядро может легко обнаружить индекс каталога, с которого начинается поиск. Текущий каталог хранится в рабочей области процесса, а корневой индекс системы хранится в глобальной переменной [12].
алгоритм namei /* превращение имени пути поиска в индекс */
входная информация: имя пути поиска
выходная информация: заблокированный индекс
{
if (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget);
else индекс = индексу текущего каталога (алгоритм iget);
выполнить (пока путь поиска не кончился) {
считать следующую компоненту имени пути поиска;
проверить соответствие рабочего индекса каталогу и права доступа;
if (рабочий индекс соответствует корню и компонента имени «..») continue; /* цикл с условием продолжения */
считать каталог (рабочий индекс), повторяя алгоритмы bmap, bread и brelse;
if (компонента соответствует записи в каталоге (рабочем индексе)) {
получить номер индекса для совпавшей компоненты;
освободить рабочий индекс (алгоритм iput);
рабочий индекс = индексу совпавшей компоненты (алгоритм iget);
}
else /* компонента отсутствует в каталоге */ return (нет индекса);
}
return (рабочий индекс);
}
Рисунок 4.11. Алгоритм превращения имени пути поиска в индекс
Алгоритм namei использует при анализе составного имени пути поиска промежуточные индексы; назовем их рабочими индексами. Индекс каталога, откуда поиск берет начало, является первым рабочим индексом. На каждой итерации цикла алгоритма ядро проверяет совпадение рабочего индекса с индексом каталога. В противном случае, нарушилось бы утверждение, что только файлы, не являющиеся каталогами, могут быть листьями дерева файловой системы. Процесс также должен иметь право производить поиск в каталоге (разрешения на чтение недостаточно). Код идентификации пользователя для процесса должен соответствовать коду индивидуального или группового владельца файла и должно быть предоставлено право исполнения, либо поиск нужно разрешить всем пользователям. В противном случае, поиск не получится.
Ядро выполняет линейный поиск файла в каталоге, ассоциированном с рабочим индексом, пытаясь найти для компоненты имени пути поиска подходящую запись в каталоге. Исходя из адреса смещения в байтах внутри каталога (начиная с 0), оно определяет местоположение дискового блока в соответствии с алгоритмом bmap и считывает этот блок, используя алгоритм bread. По имени компоненты ядро производит в блоке поиск, представляя содержимое блока как последовательность записей каталога. При обнаружении совпадения ядро переписывает номер индекса из данной точки входа, освобождает блок (алгоритм brelse) и старый рабочий индекс (алгоритм iput), и переназначает индекс найденной компоненты (алгоритм iget). Новый индекс становится рабочим индексом. Если ядро не находит в блоке подходящего имени, оно освобождает блок, прибавляет к адресу смещения число байтов в блоке, превращает новый адрес смещения в номер дискового блока (алгоритм bmap) и читает следующий блок. Ядро повторяет эту процедуру до тех пор, пока имя компоненты пути поиска не совпадет с именем точки входа в каталоге, либо до тех пор, пока не будет достигнут конец каталога.
Предположим, например, что процессу нужно открыть файл «/etc/passwd». Когда ядро начинает анализировать имя файла, оно наталкивается на наклонную черту («/») и получает индекс корня системы. Сделав корень текущим рабочим индексом, ядро наталкивается на строку «etc». Проверив соответствие текущего индекса каталогу («/») и наличие у процесса права производить поиск в каталоге, ядро ищет в корневом каталоге файл с именем «etc». Оно просматривает корневой каталог блок за блоком и исследует каждую запись в блоке, пока не обнаружит точку входа для файла «etc». Найдя эту точку входа, ядро освобождает индекс, отведенный для корня (алгоритм iput), и выделяет индекс файлу «etc» (алгоритм iget) в соответствии с номером индекса в обнаруженной записи. Удостоверившись в том, что «etc» является каталогом, а также в том, что имеются необходимые права производить поиск, ядро просматривает каталог «etc» блок за блоком в поисках записи, соответствующей файлу «passwd». Если посмотреть на Рисунок 4.10, можно увидеть, что запись о файле «passwd» является девятой записью в каталоге. Обнаружив ее, ядро освобождает индекс, выделенный файлу «etc», и выделяет индекс файлу «passwd», после чего — поскольку имя пути поиска исчерпано — возвращает этот индекс процессу.
Естественно задать вопрос об эффективности линейного поиска в каталоге записи, соответствующей компоненте имени пути поиска. Ричи показывает (см. [Ritchie 78b], стр.1968), что линейный поиск эффективен, поскольку он ограничен размером каталога. Более того, ранние версии системы UNIX не работали еще на машинах с большим объемом памяти, поэтому значительный упор был сделан на простые алгоритмы, такие как алгоритмы линейного поиска. Более сложные схемы поиска потребовали бы отличной, более сложной, структуры каталога, и возможно работали бы медленнее даже в небольших каталогах по сравнению со схемой линейного поиска.
Из главы 2 напомним, что каждый процесс связан с текущим каталогом (и протекает в его рамках); рабочая область, отведенная под задачу пользователя, содержит указатель на индекс текущего каталога. Текущим каталогом первого из процессов в системе, нулевого процесса, является корневой каталог. Путь к текущему каталогу каждого нового процесса берет начало от текущего каталога процесса, являющегося родительским по отношению к данному (см. раздел 5.10). Процессы изменяют текущий каталог, запрашивая выполнение системной операции chdir (изменить каталог). Все поиски файлов по имени начинаются с текущего каталога процесса, если только имя пути поиска не предваряется наклонной чертой, указывая, что поиск нужно начинать с корневого каталога. В любом случае ядро может легко обнаружить индекс каталога, с которого начинается поиск. Текущий каталог хранится в рабочей области процесса, а корневой индекс системы хранится в глобальной переменной [12].
алгоритм namei /* превращение имени пути поиска в индекс */
входная информация: имя пути поиска
выходная информация: заблокированный индекс
{
if (путь поиска берет начало с корня) рабочий индекс = индексу корня (алгоритм iget);
else индекс = индексу текущего каталога (алгоритм iget);
выполнить (пока путь поиска не кончился) {
считать следующую компоненту имени пути поиска;
проверить соответствие рабочего индекса каталогу и права доступа;
if (рабочий индекс соответствует корню и компонента имени «..») continue; /* цикл с условием продолжения */
считать каталог (рабочий индекс), повторяя алгоритмы bmap, bread и brelse;
if (компонента соответствует записи в каталоге (рабочем индексе)) {
получить номер индекса для совпавшей компоненты;
освободить рабочий индекс (алгоритм iput);
рабочий индекс = индексу совпавшей компоненты (алгоритм iget);
}
else /* компонента отсутствует в каталоге */ return (нет индекса);
}
return (рабочий индекс);
}
Рисунок 4.11. Алгоритм превращения имени пути поиска в индекс
Алгоритм namei использует при анализе составного имени пути поиска промежуточные индексы; назовем их рабочими индексами. Индекс каталога, откуда поиск берет начало, является первым рабочим индексом. На каждой итерации цикла алгоритма ядро проверяет совпадение рабочего индекса с индексом каталога. В противном случае, нарушилось бы утверждение, что только файлы, не являющиеся каталогами, могут быть листьями дерева файловой системы. Процесс также должен иметь право производить поиск в каталоге (разрешения на чтение недостаточно). Код идентификации пользователя для процесса должен соответствовать коду индивидуального или группового владельца файла и должно быть предоставлено право исполнения, либо поиск нужно разрешить всем пользователям. В противном случае, поиск не получится.
Ядро выполняет линейный поиск файла в каталоге, ассоциированном с рабочим индексом, пытаясь найти для компоненты имени пути поиска подходящую запись в каталоге. Исходя из адреса смещения в байтах внутри каталога (начиная с 0), оно определяет местоположение дискового блока в соответствии с алгоритмом bmap и считывает этот блок, используя алгоритм bread. По имени компоненты ядро производит в блоке поиск, представляя содержимое блока как последовательность записей каталога. При обнаружении совпадения ядро переписывает номер индекса из данной точки входа, освобождает блок (алгоритм brelse) и старый рабочий индекс (алгоритм iput), и переназначает индекс найденной компоненты (алгоритм iget). Новый индекс становится рабочим индексом. Если ядро не находит в блоке подходящего имени, оно освобождает блок, прибавляет к адресу смещения число байтов в блоке, превращает новый адрес смещения в номер дискового блока (алгоритм bmap) и читает следующий блок. Ядро повторяет эту процедуру до тех пор, пока имя компоненты пути поиска не совпадет с именем точки входа в каталоге, либо до тех пор, пока не будет достигнут конец каталога.
Предположим, например, что процессу нужно открыть файл «/etc/passwd». Когда ядро начинает анализировать имя файла, оно наталкивается на наклонную черту («/») и получает индекс корня системы. Сделав корень текущим рабочим индексом, ядро наталкивается на строку «etc». Проверив соответствие текущего индекса каталогу («/») и наличие у процесса права производить поиск в каталоге, ядро ищет в корневом каталоге файл с именем «etc». Оно просматривает корневой каталог блок за блоком и исследует каждую запись в блоке, пока не обнаружит точку входа для файла «etc». Найдя эту точку входа, ядро освобождает индекс, отведенный для корня (алгоритм iput), и выделяет индекс файлу «etc» (алгоритм iget) в соответствии с номером индекса в обнаруженной записи. Удостоверившись в том, что «etc» является каталогом, а также в том, что имеются необходимые права производить поиск, ядро просматривает каталог «etc» блок за блоком в поисках записи, соответствующей файлу «passwd». Если посмотреть на Рисунок 4.10, можно увидеть, что запись о файле «passwd» является девятой записью в каталоге. Обнаружив ее, ядро освобождает индекс, выделенный файлу «etc», и выделяет индекс файлу «passwd», после чего — поскольку имя пути поиска исчерпано — возвращает этот индекс процессу.
Естественно задать вопрос об эффективности линейного поиска в каталоге записи, соответствующей компоненте имени пути поиска. Ричи показывает (см. [Ritchie 78b], стр.1968), что линейный поиск эффективен, поскольку он ограничен размером каталога. Более того, ранние версии системы UNIX не работали еще на машинах с большим объемом памяти, поэтому значительный упор был сделан на простые алгоритмы, такие как алгоритмы линейного поиска. Более сложные схемы поиска потребовали бы отличной, более сложной, структуры каталога, и возможно работали бы медленнее даже в небольших каталогах по сравнению со схемой линейного поиска.
4.5 СУПЕРБЛОК
До сих пор в этой главе описывалась структура файла, при этом предполагалось, что индекс предварительно связывался с файлом и что уже были определены дисковые блоки, содержащие информацию. В следующих разделах описывается, каким образом ядро назначает индексы и дисковые блоки. Чтобы понять эти алгоритмы, рассмотрим структуру суперблока.
Суперблок состоит из следующих полей:
• размер файловой системы,
• количество свободных блоков в файловой системе,
• список свободных блоков, имеющихся в файловой системе,
• индекс следующего свободного блока в списке свободных блоков,
• размер списка индексов,
• количество свободных индексов в файловой системе,
• список свободных индексов в файловой системе,
• следующий свободный индекс в списке свободных индексов,
• заблокированные поля для списка свободных блоков и свободных индексов,
• флаг, показывающий, что в суперблок были внесены изменения.
В оставшейся части главы будет объяснено, как пользоваться массивами, указателями и замками блокировки. Ядро периодически переписывает суперблок на диск, если в суперблок были внесены изменения, для того, чтобы обеспечивалась согласованность с данными, хранящимися в файловой системе.
Суперблок состоит из следующих полей:
• размер файловой системы,
• количество свободных блоков в файловой системе,
• список свободных блоков, имеющихся в файловой системе,
• индекс следующего свободного блока в списке свободных блоков,
• размер списка индексов,
• количество свободных индексов в файловой системе,
• список свободных индексов в файловой системе,
• следующий свободный индекс в списке свободных индексов,
• заблокированные поля для списка свободных блоков и свободных индексов,
• флаг, показывающий, что в суперблок были внесены изменения.
В оставшейся части главы будет объяснено, как пользоваться массивами, указателями и замками блокировки. Ядро периодически переписывает суперблок на диск, если в суперблок были внесены изменения, для того, чтобы обеспечивалась согласованность с данными, хранящимися в файловой системе.
4.6 НАЗНАЧЕНИЕ ИНДЕКСА НОВОМУ ФАЙЛУ
Для выделения известного индекса, то есть индекса, для которого предварительно определен собственный номер (и номер файловой системы), ядро использует алгоритм iget. В алгоритме namei, например, ядро определяет номер индекса, устанавливая соответствие между компонентой имени пути поиска и именем в каталоге. Другой алгоритм, ialloc, выполняет назначение дискового индекса вновь создаваемому файлу.
Как уже говорилось в главе 2, в файловой системе имеется линейный список индексов. Индекс считается свободным, если поле его типа хранит нулевое значение. Если процессу понадобился новый индекс, ядро теоретически могло бы произвести поиск свободного индекса в списке индексов. Однако, такой поиск обошелся бы дорого, поскольку потребовал бы по меньшей мере одну операцию чтения (допустим, с диска) на каждый индекс. Для повышения производительности в суперблоке файловой системы хранится массив номеров свободных индексов в файловой системе.
алгоритм ialloc /* выделение индекса */
входная информация: файловая система
выходная информация: заблокированный индекс
{
do {
if (суперблок заблокирован) {
sleep (пока суперблок не освободится);
continue; /* цикл с условием продолжения */
}
if (список индексов в суперблоке пуст) {
заблокировать суперблок; выбрать запомненный индекс для поиска свободных индексов;
искать на диске свободные индексы до тех пор, пока суперблок не заполнится или пока не будут найдены все свободные индексы (алгоритмы bread и brelse);
снять блокировку с суперблока;
возобновить выполнение процесса (как только суперблок освободится);
if (на диске отсутствуют свободные индексы) return (нет индексов);
запомнить индекс с наибольшим номером среди найденных для последующих поисков свободных индексов;
}
/* список индексов в суперблоке не пуст */
выбрать номер индекса из списка индексов в суперблоке;
получить индекс (алгоритм iget);
if (индекс после всего этого не свободен) { /*!!! */
переписать индекс на диск;
освободить индекс (алгоритм iput);
continue; /* цикл с условием продолжения */
}
/* индекс свободен */
инициализировать индекс;
переписать индекс на диск;
уменьшить счетчик свободных индексов в файловой системе;
return (индекс);
}
}
Рисунок 4.12. Алгоритм назначения новых индексов
На Рисунке 4.12 приведен алгоритм ialloc назначения новых индексов. По причинам, о которых пойдет речь ниже, ядро сначала проверяет, не заблокировал ли какой-либо процесс своим обращением список свободных индексов в суперблоке. Если список номеров индексов в суперблоке не пуст, ядро назначает номер следующего индекса, выделяет для вновь назначенного дискового индекса свободный индекс в памяти, используя алгоритм iget (читая индекс с диска, если необходимо), копирует дисковый индекс в память, инициализирует поля в индексе и возвращает индекс заблокированным. Затем ядро корректирует дисковый индекс, указывая, что к индексу произошло обращение. Ненулевое значение поля типа файла говорит о том, что дисковый индекс назначен. В простейшем случае с индексом все в порядке, но в условиях конкуренции делается необходимым проведение дополнительных проверок, на чем мы еще кратко остановимся. Грубо говоря, конкуренция возникает, когда несколько процессов вносят изменения в общие информационные структуры, так что результат зависит от очередности выполнения процессов, пусть даже все процессы будут подчиняться протоколу блокировки. Здесь предполагается, например, что процесс мог бы получить уже используемый индекс. Конкуренция связана с проблемой взаимного исключения, описанной в главе 2, с одним замечанием: различные схемы блокировки решают проблему взаимного исключения, но не могут сами по себе решить все проблемы конкуренции.
Если список свободных индексов в суперблоке пуст, ядро просматривает диск и помещает в суперблок как можно больше номеров свободных индексов. При этом ядро блок за блоком считывает индексы с диска и наполняет список номеров индексов в суперблоке до отказа, запоминая индекс с номером, наибольшим среди найденных. Назовем этот индекс «запомненным»; это последний индекс, записанный в суперблок. В следующий раз, когда ядро будет искать на диске свободные индексы, оно использует запомненный индекс в качестве стартовой точки, благодаря чему гарантируется, что ядру не придется зря тратить время на считывание дисковых блоков, в которых свободные индексы наверняка отсутствуют. После формирования нового набора номеров свободных индексов ядро запускает алгоритм назначения индекса с самого начала. Всякий раз, когда ядро назначает дисковый индекс, оно уменьшает значение счетчика свободных индексов, записанное в суперблоке.
Рассмотрим две пары массивов номеров свободных индексов (Рисунок 4.13). Если список свободных индексов в суперблоке имеет вид первого массива на Рисунке 4.13(а) при назначении индекса ядром, то значение указателя на следующий номер индекса уменьшается до 18 и выбирается индекс с номером 48. Если же список выглядит как первый массив на Рисунке 4.13(б), ядро заметит, что массив пуст и обратится в поисках свободных индексов к диску, при этом поиск будет производиться, начиная с индекса с номером 470, который был ранее запомнен. Когда ядро заполнит список свободных индексов в суперблоке до отказа, оно запомнит последний индекс в качестве начальной точки для последующих просмотров диска. Ядро производит назначение файлу только что выбранного с диска индекса (под номером 471 на рисунке) и продолжает прерванную обработку.
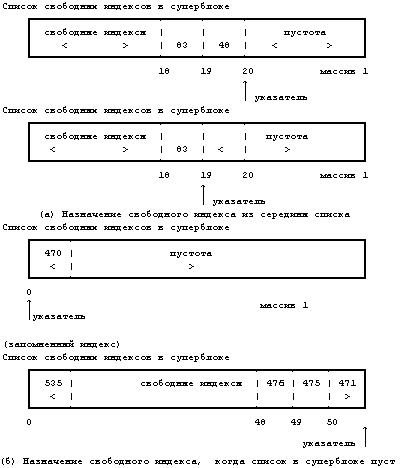 Рисунок 4.13. Два массива номеров свободных индексов
Рисунок 4.13. Два массива номеров свободных индексов
алгоритм ifree /* освобождение индекса */
входная информация: номер индекса в файловой системе
выходная информация: отсутствует
{
увеличить на 1 счетчик свободных индексов в файловой системе;
if (суперблок заблокирован) return;
if (список индексов заполнен) {
if (номер индекса меньше номера индекса, запомненного для последующего просмотра)
запомнить для последующего просмотра номер введенного индекса;
}
в противном случае сохранить номер индекса в списке индексов;
return;
}
Рисунок 4.14. Алгоритм освобождения индекса
Алгоритм освобождения индекса построен значительно проще. Увеличив на единицу общее количество доступных в файловой системе индексов, ядро проверяет наличие блокировки у суперблока. Если он заблокирован, ядро, чтобы предотвратить конкуренцию, немедленно сообщает: номер индекса отсутствует в суперблоке, но индекс может быть найден на диске и доступен для переназначения. Если список не заблокирован, ядро проверяет, имеется ли место для новых номеров индексов и если да, помещает номер индекса в список и выходит из алгоритма. Если список полон, ядро не сможет в нем сохранить вновь освобожденный индекс. Оно сравнивает номер освобожденного индекса с номером запомненного индекса. Если номер освобожденного индекса меньше номера запомненного, ядро запоминает номер вновь освобожденного индекса, выбрасывая из суперблока номер старого запомненного индекса. Индекс не теряется, поскольку ядро может найти его, просматривая список индексов на диске. Ядро поддерживает структуру списка в суперблоке таким образом, что последний номер, выбираемый им из списка, и есть номер запомненного индекса. В идеале не должно быть свободных индексов с номерами, меньшими, чем номер запомненного индекса, но возможны и исключения.
Рассмотрим два примера освобождения индексов. Если в списке свободных индексов в суперблоке еще есть место для новых номеров свободных индексов (как на Рисунке 4.13(а)), ядро помещает в список новый номер, переставляет указатель на следующий свободный индекс и продолжает выполнение процесса. Но если список свободных индексов заполнен (Рисунок 4.15), ядро сравнивает номер освобожденного индекса с номером запомненного индекса, с которого начнется просмотр диска в следующий раз. Если вначале список свободных индексов имел вид, как на Рисунке 4.15(а), то когда ядро освобождает индекс с номером 499, оно запоминает его и выталкивает номер 535 из списка. Если затем ядро освобождает индекс с номером 601, содержимое списка свободных индексов не изменится. Когда позднее ядро использует все индексы из списка свободных индексов в суперблоке, оно обратится в поисках свободных индексов к диску, при этом, начав просмотр с индекса с номером 499, оно снова обнаружит индексы 535 и 601.

Рисунок 4.15. Размещение номеров свободных индексов в суперблоке

Рисунок 4.16. Конкуренция в назначении индексов
В предыдущем параграфе описывались простые случаи работы алгоритмов. Теперь рассмотрим случай, когда ядро назначает новый индекс и затем копирует его в память. В алгоритме предполагается, что ядро может и обнаружить, что индекс уже назначен. Несмотря на редкость такой ситуации, обсудим этот случай (с помощью Рисунков 4.16 и 4.17). Пусть у нас есть три процесса, A, B и C, и пусть ядро, действуя от имени процесса A [13], назначает индекс I, но приостанавливает выполнение процесса перед тем, как скопировать дисковый индекс в память. Алгоритмы iget (вызванный алгоритмом ialloc) и bread (вызванный алгоритмом iget) дают процессу A достаточно возможностей для приостановления своей работы. Предположим, что пока процесс A приостановлен, процесс B пытается назначить новый индекс, но обнаруживает, что список свободных индексов в суперблоке пуст. Процесс B просматривает диск в поисках свободных индексов, и начинает это делать с индекса, имеющего меньший номер по сравнению с индексом, назначенным процессом A. Возможно, что процесс B обнаружит индекс I на диске свободным, так как процесс A все еще приостановлен, а ядро еще не знает, что этот индекс собираются назначить. Процесс B, не осознавая опасности, заканчивает просмотр диска, заполняет суперблок свободными (предположительно) индексами, назначает индекс и уходит со сцены. Однако, индекс I остается в списке номеров свободных индексов в суперблоке. Когда процесс A возобновляет выполнение, он заканчивает назначение индекса I. Теперь допустим, что процесс C затем затребовал индекс и случайно выбрал индекс I из списка в суперблоке. Когда он обратится к копии индекса в памяти, он обнаружит из установки типа файла, что индекс уже назначен. Ядро проверяет это условие и, обнаружив, что этот индекс назначен, пытается назначить другой. Немедленная перепись скорректированного индекса на диск после его назначения в соответствии с алгоритмом ialloc снижает опасность конкуренции, поскольку поле типа файла будет содержать пометку о том, что индекс использован.
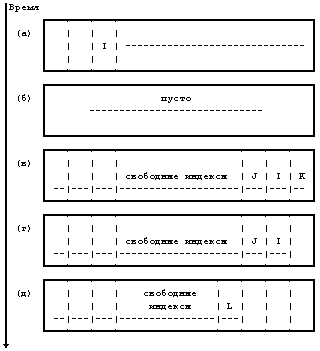
Рисунок 4.17. Конкуренция в назначении индексов (продолжение)
Блокировка списка индексов в суперблоке при чтении с диска устраняет другие возможности для конкуренции. Если суперблок не заблокирован, процесс может обнаружить, что он пуст, и попытаться заполнить его с диска, время от времени приостанавливая свое выполнение до завершения операции ввода-вывода. Предположим, что второй процесс так же пытается назначить новый индекс и обнаруживает, что список пуст. Он тоже попытается заполнить список с диска. В лучшем случае, оба процесса продублируют друг друга и потратят энергию центрального процессора. В худшем, участится конкуренция, подобная той, которая описана в предыдущем параграфе. Сходным образом, если процесс, освобождая индекс, не проверил наличие блокировки списка, он может затереть номера индексов уже в списке свободных индексов, пока другой процесс будет заполнять этот список информацией с диска. И опять участится конкуренция вышеописанного типа. Несмотря на то, что ядро более или менее удачно управляется с ней, производительность системы снижается. Установка блокировки для списка свободных индексов в суперблоке устраняет такую конкуренцию.
Как уже говорилось в главе 2, в файловой системе имеется линейный список индексов. Индекс считается свободным, если поле его типа хранит нулевое значение. Если процессу понадобился новый индекс, ядро теоретически могло бы произвести поиск свободного индекса в списке индексов. Однако, такой поиск обошелся бы дорого, поскольку потребовал бы по меньшей мере одну операцию чтения (допустим, с диска) на каждый индекс. Для повышения производительности в суперблоке файловой системы хранится массив номеров свободных индексов в файловой системе.
алгоритм ialloc /* выделение индекса */
входная информация: файловая система
выходная информация: заблокированный индекс
{
do {
if (суперблок заблокирован) {
sleep (пока суперблок не освободится);
continue; /* цикл с условием продолжения */
}
if (список индексов в суперблоке пуст) {
заблокировать суперблок; выбрать запомненный индекс для поиска свободных индексов;
искать на диске свободные индексы до тех пор, пока суперблок не заполнится или пока не будут найдены все свободные индексы (алгоритмы bread и brelse);
снять блокировку с суперблока;
возобновить выполнение процесса (как только суперблок освободится);
if (на диске отсутствуют свободные индексы) return (нет индексов);
запомнить индекс с наибольшим номером среди найденных для последующих поисков свободных индексов;
}
/* список индексов в суперблоке не пуст */
выбрать номер индекса из списка индексов в суперблоке;
получить индекс (алгоритм iget);
if (индекс после всего этого не свободен) { /*!!! */
переписать индекс на диск;
освободить индекс (алгоритм iput);
continue; /* цикл с условием продолжения */
}
/* индекс свободен */
инициализировать индекс;
переписать индекс на диск;
уменьшить счетчик свободных индексов в файловой системе;
return (индекс);
}
}
Рисунок 4.12. Алгоритм назначения новых индексов
На Рисунке 4.12 приведен алгоритм ialloc назначения новых индексов. По причинам, о которых пойдет речь ниже, ядро сначала проверяет, не заблокировал ли какой-либо процесс своим обращением список свободных индексов в суперблоке. Если список номеров индексов в суперблоке не пуст, ядро назначает номер следующего индекса, выделяет для вновь назначенного дискового индекса свободный индекс в памяти, используя алгоритм iget (читая индекс с диска, если необходимо), копирует дисковый индекс в память, инициализирует поля в индексе и возвращает индекс заблокированным. Затем ядро корректирует дисковый индекс, указывая, что к индексу произошло обращение. Ненулевое значение поля типа файла говорит о том, что дисковый индекс назначен. В простейшем случае с индексом все в порядке, но в условиях конкуренции делается необходимым проведение дополнительных проверок, на чем мы еще кратко остановимся. Грубо говоря, конкуренция возникает, когда несколько процессов вносят изменения в общие информационные структуры, так что результат зависит от очередности выполнения процессов, пусть даже все процессы будут подчиняться протоколу блокировки. Здесь предполагается, например, что процесс мог бы получить уже используемый индекс. Конкуренция связана с проблемой взаимного исключения, описанной в главе 2, с одним замечанием: различные схемы блокировки решают проблему взаимного исключения, но не могут сами по себе решить все проблемы конкуренции.
Если список свободных индексов в суперблоке пуст, ядро просматривает диск и помещает в суперблок как можно больше номеров свободных индексов. При этом ядро блок за блоком считывает индексы с диска и наполняет список номеров индексов в суперблоке до отказа, запоминая индекс с номером, наибольшим среди найденных. Назовем этот индекс «запомненным»; это последний индекс, записанный в суперблок. В следующий раз, когда ядро будет искать на диске свободные индексы, оно использует запомненный индекс в качестве стартовой точки, благодаря чему гарантируется, что ядру не придется зря тратить время на считывание дисковых блоков, в которых свободные индексы наверняка отсутствуют. После формирования нового набора номеров свободных индексов ядро запускает алгоритм назначения индекса с самого начала. Всякий раз, когда ядро назначает дисковый индекс, оно уменьшает значение счетчика свободных индексов, записанное в суперблоке.
Рассмотрим две пары массивов номеров свободных индексов (Рисунок 4.13). Если список свободных индексов в суперблоке имеет вид первого массива на Рисунке 4.13(а) при назначении индекса ядром, то значение указателя на следующий номер индекса уменьшается до 18 и выбирается индекс с номером 48. Если же список выглядит как первый массив на Рисунке 4.13(б), ядро заметит, что массив пуст и обратится в поисках свободных индексов к диску, при этом поиск будет производиться, начиная с индекса с номером 470, который был ранее запомнен. Когда ядро заполнит список свободных индексов в суперблоке до отказа, оно запомнит последний индекс в качестве начальной точки для последующих просмотров диска. Ядро производит назначение файлу только что выбранного с диска индекса (под номером 471 на рисунке) и продолжает прерванную обработку.
алгоритм ifree /* освобождение индекса */
входная информация: номер индекса в файловой системе
выходная информация: отсутствует
{
увеличить на 1 счетчик свободных индексов в файловой системе;
if (суперблок заблокирован) return;
if (список индексов заполнен) {
if (номер индекса меньше номера индекса, запомненного для последующего просмотра)
запомнить для последующего просмотра номер введенного индекса;
}
в противном случае сохранить номер индекса в списке индексов;
return;
}
Рисунок 4.14. Алгоритм освобождения индекса
Алгоритм освобождения индекса построен значительно проще. Увеличив на единицу общее количество доступных в файловой системе индексов, ядро проверяет наличие блокировки у суперблока. Если он заблокирован, ядро, чтобы предотвратить конкуренцию, немедленно сообщает: номер индекса отсутствует в суперблоке, но индекс может быть найден на диске и доступен для переназначения. Если список не заблокирован, ядро проверяет, имеется ли место для новых номеров индексов и если да, помещает номер индекса в список и выходит из алгоритма. Если список полон, ядро не сможет в нем сохранить вновь освобожденный индекс. Оно сравнивает номер освобожденного индекса с номером запомненного индекса. Если номер освобожденного индекса меньше номера запомненного, ядро запоминает номер вновь освобожденного индекса, выбрасывая из суперблока номер старого запомненного индекса. Индекс не теряется, поскольку ядро может найти его, просматривая список индексов на диске. Ядро поддерживает структуру списка в суперблоке таким образом, что последний номер, выбираемый им из списка, и есть номер запомненного индекса. В идеале не должно быть свободных индексов с номерами, меньшими, чем номер запомненного индекса, но возможны и исключения.
Рассмотрим два примера освобождения индексов. Если в списке свободных индексов в суперблоке еще есть место для новых номеров свободных индексов (как на Рисунке 4.13(а)), ядро помещает в список новый номер, переставляет указатель на следующий свободный индекс и продолжает выполнение процесса. Но если список свободных индексов заполнен (Рисунок 4.15), ядро сравнивает номер освобожденного индекса с номером запомненного индекса, с которого начнется просмотр диска в следующий раз. Если вначале список свободных индексов имел вид, как на Рисунке 4.15(а), то когда ядро освобождает индекс с номером 499, оно запоминает его и выталкивает номер 535 из списка. Если затем ядро освобождает индекс с номером 601, содержимое списка свободных индексов не изменится. Когда позднее ядро использует все индексы из списка свободных индексов в суперблоке, оно обратится в поисках свободных индексов к диску, при этом, начав просмотр с индекса с номером 499, оно снова обнаружит индексы 535 и 601.
Рисунок 4.15. Размещение номеров свободных индексов в суперблоке
Рисунок 4.16. Конкуренция в назначении индексов
В предыдущем параграфе описывались простые случаи работы алгоритмов. Теперь рассмотрим случай, когда ядро назначает новый индекс и затем копирует его в память. В алгоритме предполагается, что ядро может и обнаружить, что индекс уже назначен. Несмотря на редкость такой ситуации, обсудим этот случай (с помощью Рисунков 4.16 и 4.17). Пусть у нас есть три процесса, A, B и C, и пусть ядро, действуя от имени процесса A [13], назначает индекс I, но приостанавливает выполнение процесса перед тем, как скопировать дисковый индекс в память. Алгоритмы iget (вызванный алгоритмом ialloc) и bread (вызванный алгоритмом iget) дают процессу A достаточно возможностей для приостановления своей работы. Предположим, что пока процесс A приостановлен, процесс B пытается назначить новый индекс, но обнаруживает, что список свободных индексов в суперблоке пуст. Процесс B просматривает диск в поисках свободных индексов, и начинает это делать с индекса, имеющего меньший номер по сравнению с индексом, назначенным процессом A. Возможно, что процесс B обнаружит индекс I на диске свободным, так как процесс A все еще приостановлен, а ядро еще не знает, что этот индекс собираются назначить. Процесс B, не осознавая опасности, заканчивает просмотр диска, заполняет суперблок свободными (предположительно) индексами, назначает индекс и уходит со сцены. Однако, индекс I остается в списке номеров свободных индексов в суперблоке. Когда процесс A возобновляет выполнение, он заканчивает назначение индекса I. Теперь допустим, что процесс C затем затребовал индекс и случайно выбрал индекс I из списка в суперблоке. Когда он обратится к копии индекса в памяти, он обнаружит из установки типа файла, что индекс уже назначен. Ядро проверяет это условие и, обнаружив, что этот индекс назначен, пытается назначить другой. Немедленная перепись скорректированного индекса на диск после его назначения в соответствии с алгоритмом ialloc снижает опасность конкуренции, поскольку поле типа файла будет содержать пометку о том, что индекс использован.
Рисунок 4.17. Конкуренция в назначении индексов (продолжение)
Блокировка списка индексов в суперблоке при чтении с диска устраняет другие возможности для конкуренции. Если суперблок не заблокирован, процесс может обнаружить, что он пуст, и попытаться заполнить его с диска, время от времени приостанавливая свое выполнение до завершения операции ввода-вывода. Предположим, что второй процесс так же пытается назначить новый индекс и обнаруживает, что список пуст. Он тоже попытается заполнить список с диска. В лучшем случае, оба процесса продублируют друг друга и потратят энергию центрального процессора. В худшем, участится конкуренция, подобная той, которая описана в предыдущем параграфе. Сходным образом, если процесс, освобождая индекс, не проверил наличие блокировки списка, он может затереть номера индексов уже в списке свободных индексов, пока другой процесс будет заполнять этот список информацией с диска. И опять участится конкуренция вышеописанного типа. Несмотря на то, что ядро более или менее удачно управляется с ней, производительность системы снижается. Установка блокировки для списка свободных индексов в суперблоке устраняет такую конкуренцию.
4.7 ВЫДЕЛЕНИЕ ДИСКОВЫХ БЛОКОВ
Когда процесс записывает данные в файл, ядро должно выделять из файловой системы дисковые блоки под информационные блоки прямой адресации и иногда под блоки косвенной адресации. Суперблок файловой системы содержит массив, используемый для хранения номеров свободных дисковых блоков в файловой системе. Сервисная программа mkfs («make file system» — создать файловую систему) организует информационные блоки в файловой системе в виде списка с указателями так, что каждый элемент списка указывает на дисковый блок, в котором хранится массив номеров свободных дисковых блоков, а один из элементов массива хранит номер следующего блока данного списка.