Страница:
Для новичка было бы полезным совсем не использовать ударение, а произносить каждый слог с одинаковым усилением (если только он наверняка не знает, что этот слог является ударным).
Некоторые мусульманские имена состоят из двух частей, которые, по существу, неразделимы. Однако многие новички (и журналисты) опускают первую часть, расценивая вторую как фамилию. Это равносильно тому, чтобы изменить фамилию MacArthur (МакАртур) на Arthur («Артур»). К примеру, Abû-Yazîd (Абу-Язид) и Yazîd (Язид) – это два разных человека так же, как lbn-S‘ad (Ибн-Саад) и S‘ad (Саад), ‘Abd-al-Malik-Абд-аль-Малик) и Mâlik (Малик). (Еще большим нарушением, чем сокращение ‘Abd-al-Malik до Malik, является усечение имени до ‘Abd-al-: расценивать формы Abdul, Abul или Ibnul как отдельные имена считается варварством, подобные формы не существуют в оригинальном написании, не говоря уже об их употреблении.) В данной работе подобные составные имена пишутся через дефис. Однако некоторые авторы пишут их по отдельности. Поэтому начинающему исследователю следует мысленно восстанавливать в этих именах дефис, чтобы избежать путаницы.
Транслитерация
Транслитерация с арабского языка
Транслитерация с персидского, турецкого и урду
Некоторые мусульманские имена состоят из двух частей, которые, по существу, неразделимы. Однако многие новички (и журналисты) опускают первую часть, расценивая вторую как фамилию. Это равносильно тому, чтобы изменить фамилию MacArthur (МакАртур) на Arthur («Артур»). К примеру, Abû-Yazîd (Абу-Язид) и Yazîd (Язид) – это два разных человека так же, как lbn-S‘ad (Ибн-Саад) и S‘ad (Саад), ‘Abd-al-Malik-Абд-аль-Малик) и Mâlik (Малик). (Еще большим нарушением, чем сокращение ‘Abd-al-Malik до Malik, является усечение имени до ‘Abd-al-: расценивать формы Abdul, Abul или Ibnul как отдельные имена считается варварством, подобные формы не существуют в оригинальном написании, не говоря уже об их употреблении.) В данной работе подобные составные имена пишутся через дефис. Однако некоторые авторы пишут их по отдельности. Поэтому начинающему исследователю следует мысленно восстанавливать в этих именах дефис, чтобы избежать путаницы.
Транслитерация
В научных работах на английском языке все больше возрастает тенденция к униформизму транслитерации исламских языков, особенно арабского. Хотя даже сейчас многие авторы расходятся во мнениях. В книгах, написанных в прошлом столетии и в начале этого века, представлено огромное разнообразие систем (и в то же время существует недостаток единой системности). Серьезный читатель, ознакомившийся не с одним и не с двумя трудами, должен уметь использовать как вариации старых систем, так и новые[3].
Как уже упоминалось в предыдущем разделе Введения, в транслитерации существуют три практических требования: письменная обратимость, когда оригинальная письменная форма может быть восстановлена из транслитерации; устная узнаваемость – читатель должен следовать руководству по произношению, чтобы слово было узнаваемо в устной речи; и устойчивость – это означает, что изменения слова должны оставаться минимальными, а оно – узнаваемым при опущении диакритических знаков. Для соблюдения всех трех требований нужно создать отдельную систему перевода с каждого языка. Например, в арабском и персидском не просто различается произношение, это два абсолютно разных языка. Следовательно, для них требуются не только различные транскрипции, но и отдельные транслитерации[4]. Некоторые ученые, заинтересованные только в письменной обратимости, постарались создать единую систему транслитерации написании, не говоря уже об их употреблении.) В данной работе подобные составные имена пишутся через дефис. Однако некоторые авторы пишут их по отдельности. Поэтому начинающему исследователю следует мысленно восстанавливать в этих именах дефис, чтобы избежать путаницы. всех языков с использованием латинского шрифта. Но они сталкиваются с той же проблемой. Буквы латинского алфавита по-разному расцениваются в различных языках, например в английском или французском. И хотя ученые могут работать с международной системой транслитерации, простой читатель столкнется с некоторыми трудностями. Поэтому было бы полезно создать раздельные системы транслитерации для самых распространенных языков. По возможности, эти системы должны включать в себя как можно больше элементов транскрипции. Ученые смогут работать с французской или немецкой системой транслитерации так же, как, например, с обычными нововведениями в языках. А у рядового читателя не возникнет трудностей при дальнейшем изучении материала.
Скрупулезный автор создаст общий список букв, которые он использует для транслитерации в соответствии с их порядком в арабском (или персидском и др.) алфавите. Также он может указать ссылку на другие публикации, где есть подобный список. Для корреляции термина из одной работы с термином из другой читателю потребуется вновь найти эти буквы в указанных списках. В зависимости от их позиции читатель сможет сказать, формируют ли они тот же самый термин или другой. В приведенных ниже таблицах используется этот регулярный порядок. Там же указаны наиболее предпочтительные транслитерации и добавлены некоторые альтернативы.

Как уже упоминалось в предыдущем разделе Введения, в транслитерации существуют три практических требования: письменная обратимость, когда оригинальная письменная форма может быть восстановлена из транслитерации; устная узнаваемость – читатель должен следовать руководству по произношению, чтобы слово было узнаваемо в устной речи; и устойчивость – это означает, что изменения слова должны оставаться минимальными, а оно – узнаваемым при опущении диакритических знаков. Для соблюдения всех трех требований нужно создать отдельную систему перевода с каждого языка. Например, в арабском и персидском не просто различается произношение, это два абсолютно разных языка. Следовательно, для них требуются не только различные транскрипции, но и отдельные транслитерации[4]. Некоторые ученые, заинтересованные только в письменной обратимости, постарались создать единую систему транслитерации написании, не говоря уже об их употреблении.) В данной работе подобные составные имена пишутся через дефис. Однако некоторые авторы пишут их по отдельности. Поэтому начинающему исследователю следует мысленно восстанавливать в этих именах дефис, чтобы избежать путаницы. всех языков с использованием латинского шрифта. Но они сталкиваются с той же проблемой. Буквы латинского алфавита по-разному расцениваются в различных языках, например в английском или французском. И хотя ученые могут работать с международной системой транслитерации, простой читатель столкнется с некоторыми трудностями. Поэтому было бы полезно создать раздельные системы транслитерации для самых распространенных языков. По возможности, эти системы должны включать в себя как можно больше элементов транскрипции. Ученые смогут работать с французской или немецкой системой транслитерации так же, как, например, с обычными нововведениями в языках. А у рядового читателя не возникнет трудностей при дальнейшем изучении материала.
Скрупулезный автор создаст общий список букв, которые он использует для транслитерации в соответствии с их порядком в арабском (или персидском и др.) алфавите. Также он может указать ссылку на другие публикации, где есть подобный список. Для корреляции термина из одной работы с термином из другой читателю потребуется вновь найти эти буквы в указанных списках. В зависимости от их позиции читатель сможет сказать, формируют ли они тот же самый термин или другой. В приведенных ниже таблицах используется этот регулярный порядок. Там же указаны наиболее предпочтительные транслитерации и добавлены некоторые альтернативы.
Транслитерация с арабского языка
Транслитерация, обозначенная в таблице как «Английский», обычно используется в англоязычных научных публикациях[5]. В эту систему включены несколько диграфов (например, th или sh). В некоторых публикациях эти диграфы объединяются чертой, проведенной под парой. В редких случаях, когда пара не образует диграф, эти знаки стараются разделить, например, апострофом[6]. (Так, символами t’h будет означаться произношение, аналогичное at home.) Наиболее серьезные отклонения от этих букв можно найти в английских научных работах. Некоторые пуристы, выражая свою неприязнь к диграфам, заменяют их «международными» буквами, широко распространенными в Европе. В Энциклопедии ислама, переведенной на несколько языков, представлено сочетание двух «английских» вариантов j и q. В ранних работах и в журналистской практике существует бесчисленное множество вариантов транслитерации. Очень часто даже в английских работах они опираются на французские фонетические модели. Научная система других западных языков довольно схожа с английской, исключение составляет только вариативность диграфов. Так, например, английский sh во французском обозначается как ch, а в немецком как sch; или английский j во французском будет dj, а в немецком dsch.
Помимо неизменяемых согласных, присутствующих в арабской письменности, и гласных, стоит упомянуть и другие особенности арабского правописания. Здесь вариативность возникает благодаря природе арабского письма. Обычная форма написания в арабском дает слишком мало информации, необходимой для идентификации термина. Например, при написании опускаются «короткие» гласные, необходимые в любой системе транслитерации. Более того, транслитерация с тщательной транскрипцией может смутить обычного читателя некоторыми фактическими элементами слова. Без сомнения, каждая система должна быть компромиссной, но еще важнее подчеркнуть в ней элемент обратимости.
Существует два самых важных пункта научного компромисса. Так, некоторые арабские согласные не включены в алфавит как отдельные единицы. Например, символ h с определенной пометкой может означать t, поэтому иногда его произносят как h, а иногда как t. Подобное происходит только, если он стоит после а в конце слова. В данной работе мы подчеркиваем, что после короткого а идет h, а после долгого а читается t. Многие просто опускают звук после короткого а или лишь отмечают, что если следующее слово начинается с артикля, то следует произносить t[7]. Так, вместо Kûfah они пишут Kûfa. Второй компромисс связан с вопросом артикля. В определенных случаях арабский артикль – al (-ал) «ассимилируется» с идущим за ним существительным. В результате / (а) исчезает, а первая буква слова удваивается[8]. Авторы, соблюдающие наиболее точные транскрипции, обычно записывают артикль как – ar или – as, перед r или s и т. п., чтобы обеспечить правильное произношение. Другие авторы, и мы следуем именно этой системе, оставляют в артикле 1, даже если она не произносится. Ведь в случае исчезновения этой буквы новичок может оказаться в затруднительном положении, так как многие из них воспринимают артикль только с 1 (также эта форма отвечает арабскому написанию, которое библиотекарь должен уметь распознавать). Именно поэтому я пишу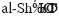 (аль-Шафи и), а не
(аль-Шафи и), а не 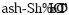 (аш-Шафии), как это слово произносится.
(аш-Шафии), как это слово произносится.
Также следует перечислить менее значительные детали. Некоторые конечные гласные, записанные в арабском как долгие, но произносимые как краткие, здесь транслитерируются как долгие. Хотя некоторые авторы помечают их как краткие. Что касается конечной – а, которая в арабском пишется как – у, я предпочитаю обозначать ее – à. Существуют авторы, которые записывают ее как долгий – â. Следуя правилам для гласных и согласных, я пишу сочетания – iyy– и – uww-; другие писатели могут использовать – îy– и – ûw-. Исключение представляет только окончание, которое по правилам пишется как – iyy-. Здесь я употребил – î. чтобы соответствовать наречиям персидского, турецкого, урду и арабского языка, где эти окончания неизменно присутствуют. Например, я записываю al-Bukhârî (аль-Бухарии) вместо al-Bukhâriyy (аль-Бухарии). Есть авторы, которые используют просто – i; некоторые восстанавливают частичную последовательность, употребляя – iy. Хамза (’) в начале слова всегда опускается. Грамматические окончания, опущенные в паузе, всегда понижаются.
Помимо неизменяемых согласных, присутствующих в арабской письменности, и гласных, стоит упомянуть и другие особенности арабского правописания. Здесь вариативность возникает благодаря природе арабского письма. Обычная форма написания в арабском дает слишком мало информации, необходимой для идентификации термина. Например, при написании опускаются «короткие» гласные, необходимые в любой системе транслитерации. Более того, транслитерация с тщательной транскрипцией может смутить обычного читателя некоторыми фактическими элементами слова. Без сомнения, каждая система должна быть компромиссной, но еще важнее подчеркнуть в ней элемент обратимости.
Существует два самых важных пункта научного компромисса. Так, некоторые арабские согласные не включены в алфавит как отдельные единицы. Например, символ h с определенной пометкой может означать t, поэтому иногда его произносят как h, а иногда как t. Подобное происходит только, если он стоит после а в конце слова. В данной работе мы подчеркиваем, что после короткого а идет h, а после долгого а читается t. Многие просто опускают звук после короткого а или лишь отмечают, что если следующее слово начинается с артикля, то следует произносить t[7]. Так, вместо Kûfah они пишут Kûfa. Второй компромисс связан с вопросом артикля. В определенных случаях арабский артикль – al (-ал) «ассимилируется» с идущим за ним существительным. В результате / (а) исчезает, а первая буква слова удваивается[8]. Авторы, соблюдающие наиболее точные транскрипции, обычно записывают артикль как – ar или – as, перед r или s и т. п., чтобы обеспечить правильное произношение. Другие авторы, и мы следуем именно этой системе, оставляют в артикле 1, даже если она не произносится. Ведь в случае исчезновения этой буквы новичок может оказаться в затруднительном положении, так как многие из них воспринимают артикль только с 1 (также эта форма отвечает арабскому написанию, которое библиотекарь должен уметь распознавать). Именно поэтому я пишу
(аль-Шафи и), а не (аш-Шафии), как это слово произносится.Также следует перечислить менее значительные детали. Некоторые конечные гласные, записанные в арабском как долгие, но произносимые как краткие, здесь транслитерируются как долгие. Хотя некоторые авторы помечают их как краткие. Что касается конечной – а, которая в арабском пишется как – у, я предпочитаю обозначать ее – à. Существуют авторы, которые записывают ее как долгий – â. Следуя правилам для гласных и согласных, я пишу сочетания – iyy– и – uww-; другие писатели могут использовать – îy– и – ûw-. Исключение представляет только окончание, которое по правилам пишется как – iyy-. Здесь я употребил – î. чтобы соответствовать наречиям персидского, турецкого, урду и арабского языка, где эти окончания неизменно присутствуют. Например, я записываю al-Bukhârî (аль-Бухарии) вместо al-Bukhâriyy (аль-Бухарии). Есть авторы, которые используют просто – i; некоторые восстанавливают частичную последовательность, употребляя – iy. Хамза (’) в начале слова всегда опускается. Грамматические окончания, опущенные в паузе, всегда понижаются.
Транслитерация с персидского, турецкого и урду
В данной работе я транслитерирую технические термины в единой форме, обычно арабской. Но если оригинальная форма слова является персидской или турецкой, то в форме этих языков. Так, например, в разных языках варьируются имена и названия местностей[9]. У отдельных авторов нередко встречаются изначально арабские термины в персидской или других формах. Бывают случаи, когда эти технические термины возникают в современной романизированной турецкой форме. Например, в таких работах hadîth упоминается как hadîs. Соответственно, читатель может учитывать эти примечания при работе с подобными материалами. В ходе работы он может столкнуться со словами как из арабского, так и из других языков.
Транслитерация других исламизированных языков представляет некоторые трудности. Они недостаточно систематизированы учеными. И в первую очередь это касается персидского языка, из которого (а не напрямую из арабского) турецкий, урду и другие языки заимствовали алфавит. Некоторые исламисты, чаще всего арабисты, обращаются с персидскими словами так, словно они арабские. При этом они добавляют лишь четыре буквы: р, ch, zh, g. (Zh произносится как s в pleasure; ch звучит как в church; те, кто избегают диграфов, используют для этого звука č, а для zh употребляют ž.) И все же в персидском языке очень много слов и имен, заимствованных из арабского. Иногда бывает сложно разобраться, к какому языку отнести контекст слова. В подобной ситуации такая тактика арабистов помогает избежать многих вопросов, и также с точки зрения обратимости алфавита (не принимая во внимание транскрипцию) их система работает довольно хорошо.
Но не стоит забывать, что персидский – это самостоятельный отдельный язык. Его алфавит строится по собственным правилам, и лучше его рассматривать как отдельную систему. Но желательно, чтобы эта система минимально отличалась от арабской. К сожалению, ни одна система идеально не подходит для транслитерации персидского языка, особенно с использованием частичной транскрипции. Приведенный ниже список включает наиболее предпочтительные системы и некоторые альтернативы. (Стандартные формы из арабского языка указаны в круглых скобках.)
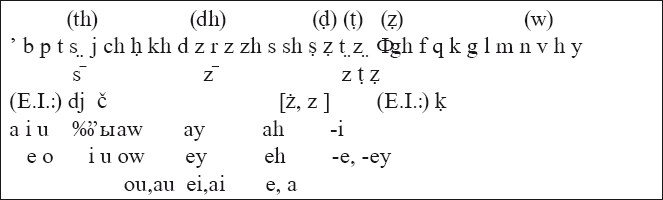 В первом ряду представлена самая распространенная система, отличающаяся от вышеупомянутой арабской. Однако она создает определенные трудности при прочтении z (в дополнение к тому, что диакритические метки неудобны при печати, особенно если необходимо подчеркивание), так как характер ее использования значительно отличается от арабской z. Во втором ряду показана более новая система. В ней t и s используются так же, как и в арабском. Так удается избежать конфликта, связанного с z. (Формы, заключенные в скобки, представляют собой альтернативы z.)[10]
В первом ряду представлена самая распространенная система, отличающаяся от вышеупомянутой арабской. Однако она создает определенные трудности при прочтении z (в дополнение к тому, что диакритические метки неудобны при печати, особенно если необходимо подчеркивание), так как характер ее использования значительно отличается от арабской z. Во втором ряду показана более новая система. В ней t и s используются так же, как и в арабском. Так удается избежать конфликта, связанного с z. (Формы, заключенные в скобки, представляют собой альтернативы z.)[10]
В новой системе все диакритические знаки (исключая а, означающий долгий гласный) представляют нефонетические различия. Эти различия указывают на вариативность персидского правописания, а не на произношение. Отсюда вытекает определенная тенденция транслитерации с персидского, в которой игнорируются все нефонетические различия в персидском произношении. В итоге, будучи своего рода транскрипцией, эта транслитерация может игнорировать диакритические знаки в целом. Первый ряд гласных демонстрирует транслитерацию, близкую к арабскому. Во второй строке представлена транслитерация, схожая с транскрипцией. В третьей строке указаны возможные варианты.
В данной работе я следовал новой системе (s, z и т. д.), в соответствии с ней я передавал согласные и выбрал z вместо z. Однако гласные новой системы довольно редко появляются в научных трудах, и для передачи индо-персидского они крайне неуместны. В результате я оставил систему гласных, близкую к арабской (используя также ê и ô для индо-персидского), исключение составили лишь соединительные персидские гласные, которые я обозначил – е и – уе. В целом персидские слова я передаю как арабские заимствования с учетом различия четырех букв (w: v, th: s-, dh: z-, d:ż). Сочетания из арабского пишутся слитно (при этом артикль ассимилируется), а не через дефис[11].
Все персидские согласные произносятся примерно как английские, невзирая на диакритические знаки (которые не важны для персидского произношения). Однако стоит отметить, что kh и gh произносятся как в арабском, a q обычно звучит как gh (иногда его так же транслитерируют). S – всегда свистящий, g – всегда твердый, как в слове go, zh – как z в azure, w после kh – всегда немая. Гласные произносятся так же, как в арабском языке, за исключением долгого â, который звучит примерно как а в all; краткого е, который похож на е в bed; и aw как au в слове bureau. В конечном – ah h – немая, а само сочетание звучит как е bed. В некоторых словах û передается как ô, и î, ê. Эти слова до сих пор так произносятся в Индии и соответственно передаются с индо-персидского.
Исконно турецкие имена, а также слова из урду, встречаются в этой работе крайне редко. После республиканской реформы 1928 года современный турецкий язык перешел на латинский алфавит (тюрки Советского Союза используют при письме сочетание латиницы и кириллицы). Практически все согласные произносятся так же, как в английском. Исключение составляют лишь с, который звучит как английский ); 9 похож на ch; ğ слегка приближен к арабскому звуку gh; j схож с французским j (z в слове azure); ş произносится как английский sh. (S, конечно, более свистящий, a g более твердый). Гласные а, е, i, о, и сходны с итальянским вариантом; ö, ü звучат как в немецком (или французские ей и и); i без точки (иногда этот знак помечен кружком или полукругом) – слегка приглушенный гласный, такой же, как в русском языке.
Однако республиканский алфавит не распространяется ни на другие тюркские языки, ни на османский турецкий. В частности причиной является то, что в его характеристике конфликтуют особенности английского языка и система персидского и арабского. В результате за рамками узкого контекста может возникнуть путаница.
Османский турецкий язык использует арабоперсидский алфавит. Здесь в качестве основы для согласных мы можем воспользоваться нашей персидской системой. Однако ее стоит дополнить формой g, которая произносится как п (в оригинальном звучании как ng), в данной работе этот звук передается знаком п. Также q мы заменим к, что позволит избежать многочисленных аналогий с нормами современной латиницы и кириллицы. В зависимости от местности и периода произношение меняется. Поэтому в некоторых словах g произносится как у или ż, a ţ может звучать как d, и т. п. Конечные взрывные обычно не произносятся. Кроме того, написание тоже варьируется. В подобных случаях разумнее следовать стамбульскому произношению, но не написанию. Довольно часто различие между при транслитерации передается контекстным гласным. В подобных случаях допустимо опускать диакритические знаки. Гласные лучше всего представлены в республиканском латинском алфавите. Здесь арабский aw превращается в ev, а ау становится еу. Хотя три долгих гласных из персидско-арабского продолжают сохранять свои качественные (но не количественные) свойства и могут иметь соответствующие пометки, особой необходимости в этом нет. (Редакторы турецкой версии Encyclopaedia of l slam разработали специальную систему для османского турецкого:
при транслитерации передается контекстным гласным. В подобных случаях допустимо опускать диакритические знаки. Гласные лучше всего представлены в республиканском латинском алфавите. Здесь арабский aw превращается в ev, а ау становится еу. Хотя три долгих гласных из персидско-арабского продолжают сохранять свои качественные (но не количественные) свойства и могут иметь соответствующие пометки, особой необходимости в этом нет. (Редакторы турецкой версии Encyclopaedia of l slam разработали специальную систему для османского турецкого: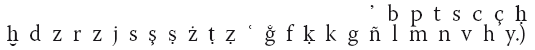
Другие тюркские языки, использующие персидскую письменность, в данной работе при необходимости уподобляются либо османскому турецкому, либо персидскому языку. Отчасти причиной стала трудность воспроизведения имени в его оригинальной турецкой форме.
Транслитерацию с урду (исламский язык в Индии) невозможно рассматривать без учета системы хинди, опирающейся на санскритский алфавит. Но не стоит забывать, что это разные самостоятельные языки. Более того, урду нуждается и в более ранней персидской транслитерации (в которой арабский d заменен на z). В основном урду опирается именно на эту систему. Помимо букв, характерных для персидского, транслитерация урду включает в себя гласные ё и 6, а также пять согласных: четыре «ретрофлексивные» согласные, которые записываются (как и в хинди) t, d, г (все они совершенно отличны от арабских), и знак назализации гласного п (или п, или тильда над гласным). Многие согласные в урду произносятся с придыханием, этим обусловлено появление h. Стоит помнить, что h означает выдох после паузы, а не формирование фрикативного звука. Поэтому th нужно читать как сильную t, аналогично с dh, th, ah, ph, bh, kh, gh, chh, jh, rh. Следовательно, если рассматривать kh и gh как диграфы, то в рамках индийского контекста каждый из них может означать два разных согласных: фрикативный kh и gh в персидском и арабском и kh и gh, произнесенные с придыханием. (Дублирование th и dh не встречается в данном контексте.) Когда диграфы передают фрикативный звук, они могут быть объединены снизу черточкой, соответственно, если они звучат как аспираты, черточка отсутствует. (В хинди английский ch часто записывается как с, а ch с придыханием, который транслитерируется chh, выглядит как ch.)
Транслитерация других исламизированных языков представляет некоторые трудности. Они недостаточно систематизированы учеными. И в первую очередь это касается персидского языка, из которого (а не напрямую из арабского) турецкий, урду и другие языки заимствовали алфавит. Некоторые исламисты, чаще всего арабисты, обращаются с персидскими словами так, словно они арабские. При этом они добавляют лишь четыре буквы: р, ch, zh, g. (Zh произносится как s в pleasure; ch звучит как в church; те, кто избегают диграфов, используют для этого звука č, а для zh употребляют ž.) И все же в персидском языке очень много слов и имен, заимствованных из арабского. Иногда бывает сложно разобраться, к какому языку отнести контекст слова. В подобной ситуации такая тактика арабистов помогает избежать многих вопросов, и также с точки зрения обратимости алфавита (не принимая во внимание транскрипцию) их система работает довольно хорошо.
Но не стоит забывать, что персидский – это самостоятельный отдельный язык. Его алфавит строится по собственным правилам, и лучше его рассматривать как отдельную систему. Но желательно, чтобы эта система минимально отличалась от арабской. К сожалению, ни одна система идеально не подходит для транслитерации персидского языка, особенно с использованием частичной транскрипции. Приведенный ниже список включает наиболее предпочтительные системы и некоторые альтернативы. (Стандартные формы из арабского языка указаны в круглых скобках.)
В новой системе все диакритические знаки (исключая а, означающий долгий гласный) представляют нефонетические различия. Эти различия указывают на вариативность персидского правописания, а не на произношение. Отсюда вытекает определенная тенденция транслитерации с персидского, в которой игнорируются все нефонетические различия в персидском произношении. В итоге, будучи своего рода транскрипцией, эта транслитерация может игнорировать диакритические знаки в целом. Первый ряд гласных демонстрирует транслитерацию, близкую к арабскому. Во второй строке представлена транслитерация, схожая с транскрипцией. В третьей строке указаны возможные варианты.
В данной работе я следовал новой системе (s, z и т. д.), в соответствии с ней я передавал согласные и выбрал z вместо z. Однако гласные новой системы довольно редко появляются в научных трудах, и для передачи индо-персидского они крайне неуместны. В результате я оставил систему гласных, близкую к арабской (используя также ê и ô для индо-персидского), исключение составили лишь соединительные персидские гласные, которые я обозначил – е и – уе. В целом персидские слова я передаю как арабские заимствования с учетом различия четырех букв (w: v, th: s-, dh: z-, d:ż). Сочетания из арабского пишутся слитно (при этом артикль ассимилируется), а не через дефис[11].
Все персидские согласные произносятся примерно как английские, невзирая на диакритические знаки (которые не важны для персидского произношения). Однако стоит отметить, что kh и gh произносятся как в арабском, a q обычно звучит как gh (иногда его так же транслитерируют). S – всегда свистящий, g – всегда твердый, как в слове go, zh – как z в azure, w после kh – всегда немая. Гласные произносятся так же, как в арабском языке, за исключением долгого â, который звучит примерно как а в all; краткого е, который похож на е в bed; и aw как au в слове bureau. В конечном – ah h – немая, а само сочетание звучит как е bed. В некоторых словах û передается как ô, и î, ê. Эти слова до сих пор так произносятся в Индии и соответственно передаются с индо-персидского.
Исконно турецкие имена, а также слова из урду, встречаются в этой работе крайне редко. После республиканской реформы 1928 года современный турецкий язык перешел на латинский алфавит (тюрки Советского Союза используют при письме сочетание латиницы и кириллицы). Практически все согласные произносятся так же, как в английском. Исключение составляют лишь с, который звучит как английский ); 9 похож на ch; ğ слегка приближен к арабскому звуку gh; j схож с французским j (z в слове azure); ş произносится как английский sh. (S, конечно, более свистящий, a g более твердый). Гласные а, е, i, о, и сходны с итальянским вариантом; ö, ü звучат как в немецком (или французские ей и и); i без точки (иногда этот знак помечен кружком или полукругом) – слегка приглушенный гласный, такой же, как в русском языке.
Однако республиканский алфавит не распространяется ни на другие тюркские языки, ни на османский турецкий. В частности причиной является то, что в его характеристике конфликтуют особенности английского языка и система персидского и арабского. В результате за рамками узкого контекста может возникнуть путаница.
Османский турецкий язык использует арабоперсидский алфавит. Здесь в качестве основы для согласных мы можем воспользоваться нашей персидской системой. Однако ее стоит дополнить формой g, которая произносится как п (в оригинальном звучании как ng), в данной работе этот звук передается знаком п. Также q мы заменим к, что позволит избежать многочисленных аналогий с нормами современной латиницы и кириллицы. В зависимости от местности и периода произношение меняется. Поэтому в некоторых словах g произносится как у или ż, a ţ может звучать как d, и т. п. Конечные взрывные обычно не произносятся. Кроме того, написание тоже варьируется. В подобных случаях разумнее следовать стамбульскому произношению, но не написанию. Довольно часто различие между
при транслитерации передается контекстным гласным. В подобных случаях допустимо опускать диакритические знаки. Гласные лучше всего представлены в республиканском латинском алфавите. Здесь арабский aw превращается в ev, а ау становится еу. Хотя три долгих гласных из персидско-арабского продолжают сохранять свои качественные (но не количественные) свойства и могут иметь соответствующие пометки, особой необходимости в этом нет. (Редакторы турецкой версии Encyclopaedia of l slam разработали специальную систему для османского турецкого:Другие тюркские языки, использующие персидскую письменность, в данной работе при необходимости уподобляются либо османскому турецкому, либо персидскому языку. Отчасти причиной стала трудность воспроизведения имени в его оригинальной турецкой форме.
Транслитерацию с урду (исламский язык в Индии) невозможно рассматривать без учета системы хинди, опирающейся на санскритский алфавит. Но не стоит забывать, что это разные самостоятельные языки. Более того, урду нуждается и в более ранней персидской транслитерации (в которой арабский d заменен на z). В основном урду опирается именно на эту систему. Помимо букв, характерных для персидского, транслитерация урду включает в себя гласные ё и 6, а также пять согласных: четыре «ретрофлексивные» согласные, которые записываются (как и в хинди) t, d, г (все они совершенно отличны от арабских), и знак назализации гласного п (или п, или тильда над гласным). Многие согласные в урду произносятся с придыханием, этим обусловлено появление h. Стоит помнить, что h означает выдох после паузы, а не формирование фрикативного звука. Поэтому th нужно читать как сильную t, аналогично с dh, th, ah, ph, bh, kh, gh, chh, jh, rh. Следовательно, если рассматривать kh и gh как диграфы, то в рамках индийского контекста каждый из них может означать два разных согласных: фрикативный kh и gh в персидском и арабском и kh и gh, произнесенные с придыханием. (Дублирование th и dh не встречается в данном контексте.) Когда диграфы передают фрикативный звук, они могут быть объединены снизу черточкой, соответственно, если они звучат как аспираты, черточка отсутствует. (В хинди английский ch часто записывается как с, а ch с придыханием, который транслитерируется chh, выглядит как ch.)